






前言
在上一章【课程总结】Day13(下):人脸识别和MTCNN模型中,我们初步了解了人脸识别的概念以及MTCNN的网络结构,借助开源项目的代码,初步在本地实现了MTCNN的数据预处理、训练和预测过程。本章内容,我们将深入MTCNN的代码,理解数据预处理、训练和预测过程。
预处理过程分析理解
标注数据文件
首先,我们先了解一下CelebA数据集的标注文件内容:
list_landmarks_celeba文件内容
202599
lefteye_x lefteye_y righteye_x righteye_y nose_x nose_y leftmouth_x leftmouth_y rightmouth_x rightmouth_y
000001.jpg 165 184 244 176 196 249 194 271 266 260
000002.jpg 140 204 220 204 168 254 146 289 226 289
000003.jpg 244 104 264 105 263 121 235 134 251 140
- 第一行:代表数据的数量,例如:202599条数据
- 第二行:代表数据的表头信息,例如:lefteye_x是左眼的x坐标,lefteye_y是右眼的y坐标。
- 第三行:代表一条标注数据,对应图片中5个关键点的坐标位置(这里的坐标位置对应是在原图中的坐标位置)
list_bbox_celeba文件内容
202599
image_id x_1 y_1 width height
000001.jpg 95 71 226 313
000002.jpg 72 94 221 306
000003.jpg 216 59 91 126
000004.jpg 622 257 564 781
- 第一行:同样代表数据的数量
- 第二行:同样代表数据的表头
- 第三行:代表一条人脸框的数据,x_1代表左上角点的x坐标,y_1代表右上角y坐标,width是框的宽度,height是框的高度
预处理过程
generate_samples的主要过程是:
- 创建样本数据的保存目录
- 读取标注信息
- 通过for循环,依次遍历每一行的标注信息
- (核心部分)处理单行标注信息,生成正负样本,即
process_annotation函数 - 保存正负样本到对应目录。
- 由于MTCNN原始代码中的预处理过程可读性不高,所以我将generate_samples进行了重构,重构后代码可读性会更高一些。
- 重构后的完整代码请见Github仓库
def generate_samples(face_size, max_samples=-1):
"""
生成指定大小的人脸样本,并保存到文件中。
参数:
face_size (int): 生成的人脸图像尺寸
max_samples (int): 最大生成样本数量,设置为 -1 表示不限制
"""
if not os.path.exists(DST_PATH):
os.makedirs(DST_PATH)
paths, base_path = create_directories(DST_PATH, face_size)
# 新建标注文件
files = open_label_files(base_path)
# 样本计数
counters = {'positive': 0, 'negative': 0, 'part': 0}
# 读取标注信息
with open(LANMARKS_PATH) as f:
landmarks_list = f.readlines()
with open(LABEL_PATH) as f:
anno_list = f.readlines()
for i, (anno_line, landmarks) in enumerate(zip(anno_list, landmarks_list)):
print(f"positive:{counters['positive']}, \
negative:{counters['negative']}, \
part:{counters['part']}")
# 跳过前两行
if i < 2:
continue
# 如果处理了指定数量的样本,则退出循环
if max_samples > 0 and i > max_samples:
break
# 处理单行标注信息,生成正负样本
samples = process_annotation(
face_size, anno_line, landmarks
)
# 保存正负样本到文件
save_samples(
samples,
files, base_path, counters
)
for file in files.values():
file.close()
代码解析:
- 该函数的主要功能是:
- 读取标注文件list_landmarks_celeba和list_bbox_celeba
- 调用
process_annotation()函数处理标注信息,生成正负样本 - 调用
save_samples()函数保存正负样本到文件
- 其中核心逻辑是
process_annotation()函数,接下来我们从process_annotation函数入手,梳理其主要逻辑。
process_annotation函数解析
def process_annotation(face_size, anno_line, landmarks):
"""
处理单行注释信息,生成正负样本。
参数:
anno_line (str): 一行注释信息,格式为 "image_filename x1 y1 w h"
face_size (int): 生成的人脸图像尺寸
landmarks (str): 关键点标注字符串
返回:
samples (list): 生成的样本列表
"""
# 5个关键点
_landmarks = landmarks.split()
# 使用列表解析和解包一次性获取所有关键点的坐标
landmarks = [float(x) for x in _landmarks[1:11]]
# 解析注释行,获取图像文件名和人脸位置信息
strs = parse_annotation_line(anno_line)
image_filename = strs[0].strip()
x1, y1, w, h = map(int, strs[1:])
# 标签矫正
x1, y1, x2, y2, w, h = adjust_bbox(x1, y1, w, h)
# 判断坐标是否符合要求
if max(w, h) < 40 or x1 < 0 or x2 < 0 or y1 < 0 or y2 < 0:
# 不符合要求的图片,返回[]不做处理
return []
boxes = [[x1, y1, x2, y2]]
# 计算人脸中心点坐标
cx = w / 2 + x1
cy = h / 2 + y1
# 最大边长
max_side = max(w, h)
# 打开图像文件
image_filepath = os.path.join(IMG_PATH, image_filename)
with Image.open(image_filepath) as img:
# 解析出宽度和高度
img_w, img_h = img.size
# 生成候选的裁剪框
samples = []
for crop_box in generate_crop_boxes(cx, cy, max_side, img_w, img_h):
# 处理每个候选裁剪框,生成正负样本
sample = process_crop_box(img, face_size, max_side, crop_box, boxes, landmarks )
if sample:
samples.append(sample)
return samples
代码解析:
- process_annotation的主要功能是:
- 计算人脸中心点坐标和最大边长
- 调用
generate_crop_boxes()生成候选裁剪框
- 核心逻辑在
generate_crop_boxes()生成候选裁剪框和process_crop_box()处理候选裁剪框两个函数,我们依次分析这两个函数。
generate_crop_boxes函数解析
def generate_crop_boxes(cx, cy, max_side, img_w, img_h):
"""
根据给定的人脸中心点坐标和尺寸,生成5个候选的裁剪框。
参数:
cx (float): 人脸中心点的 x 坐标
cy (float): 人脸中心点的 y 坐标
max_side (int): 人脸框的最大边长
img_w (int): 图像宽度
img_h (int): 图像高度
返回:
crop_boxes (list): 一个包含5个裁剪框坐标的列表,每个裁剪框的格式为 [x1, y1, x2, y2]
max_sides (list): 一个包含5个裁剪框最大边长的列表
"""
crop_boxes = []
max_sides = []
for _ in range(5):
# 随机偏移中心点坐标以及边长
seed = float_num[np.random.randint(0, len(float_num))]
# 最大边长随机偏移
_max_side = max_side + np.random.randint(int(-max_side * seed), int(max_side * seed))
# 中心点x坐标随机偏移
_cx = cx + np.random.randint(int(-cx * seed), int(cx * seed))
# 中心点y坐标随机偏移
_cy = cy + np.random.randint(int(-cy * seed), int(cy * seed))
# 得到偏移后的坐标值(方框)
_x1 = _cx - _max_side / 2
_y1 = _cy - _max_side / 2
_x2 = _x1 + _max_side
_y2 = _y1 + _max_side
# 偏移过大,偏出图像了,此时,不能用,应该再次尝试偏移
if _x1 < 0 or _y1 < 0 or _x2 > img_w or _y2 > img_h:
continue
# 添加裁剪框坐标和最大边长到列表中
crop_boxes.append(np.array([_x1, _y1, _x2, _y2]))
max_sides.append(_max_side)
return crop_boxes, max_sides
为了便于理解,我们通过一段测试代码,将上述随机生成的裁剪框画出来,以便更加形象地看到裁剪框。

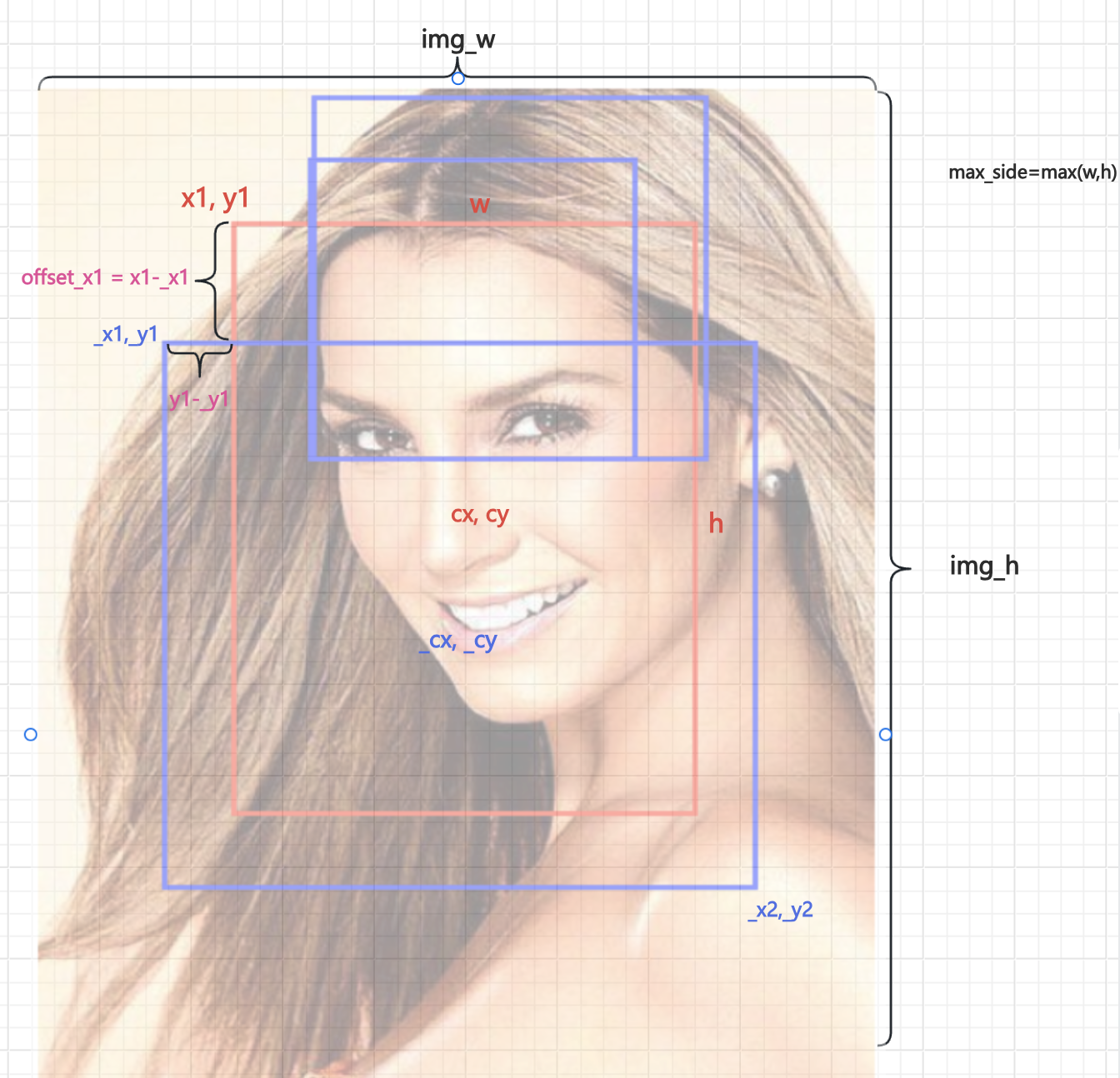
- 红色框:代表标注数据对应的人脸框
- 蓝色框:代表随机生成的裁剪框
篇幅原因,测试代码不再赘述,相关代码可以在github代码仓库下的\doc\CelebA.ipynb找到。
代码解析:
seed是在已定义的float_num中进行随机取数,后续用于随机偏移的系数。查看float_num中数值的分布,正:偏:负=2:2:6=1:1:3,这可以使得负样本的比例更多一些。
float_num = [0.1, 0.1, 0.3, 0.5, 0.95, 0.95, 0.99, 0.99, 0.99, 0.99]
_max_side是人脸框(红框)最大边长的随机偏移,计算方法是np.random.randint(int(-max_side * seed), int(max_side * seed))生成一个随机整数,范围在 [-max_side * seed, max_side * seed] 之间
例如,如果原始人脸框的最大边长是 100 像素,而 seed 取值为 0.2,那么 _max_side 的取值范围就会在 100 + (-100 * 0.2) ~ 100 + (100 * 0.2) 之间,也就是 80 ~ 120 像素之间。
_cx和_cy是根据人脸框中心点cx和cy随机偏移得到新中心点
将上述的变量画图理解如下:
process_crop_box函数解析
def process_crop_box(img, face_size, _max_side, crop_box, boxes, landmarks):
"""
处理单个裁剪框,生成正负样本。
参数:
img (Image): 原始图像
crop_box (list): 裁剪框坐标 [x1, y1, x2, y2]
boxes (list): 人脸框坐标列表
face_size (int): 生成的人脸图像尺寸
返回:
sample (dict): 样本信息 {'image': image, 'label': label, 'bbox_offsets': offsets, 'landmark_offsets': landmark_offsets}
"""
x1, y1, x2, y2 = boxes[0][:4]
_x1, _y1, _x2, _y2 = crop_box[:4]
px1, py1, px2, py2, px3, py3, px4, py4, px5, py5 = landmarks
offset_x1 = (x1 - _x1) / _max_side
offset_y1 = (y1 - _y1) / _max_side
offset_x2 = (x2 - _x2) / _max_side
offset_y2 = (y2 - _y2) / _max_side
offset_px1 = (px1 - _x1) / _max_side
offset_py1 = (py1 - _y1) / _max_side
offset_px2 = (px2 - _x1) / _max_side
offset_py2 = (py2 - _y1) / _max_side
offset_px3 = (px3 - _x1) / _max_side
offset_py3 = (py3 - _y1) / _max_side
offset_px4 = (px4 - _x1) / _max_side
offset_py4 = (py4 - _y1) / _max_side
offset_px5 = (px5 - _x1) / _max_side
offset_py5 = (py5 - _y1) / _max_side
face_crop = img.crop(crop_box)
face_resize = face_crop.resize((face_size, face_size), Image.Resampling.LANCZOS)
iou = IOU(torch.tensor([x1, y1, x2, y2]), torch.tensor([crop_box[:4]]))
if iou > 0.7: # 正样本
label = 1
elif 0.4 < iou < 0.6: # 部分样本
label = 2
elif iou < 0.2: # 负样本
label = 0
else:
return None # 不符合任何条件的样本不处理
return {
'image': face_resize,
'label': label,
'bbox_offsets': (offset_x1, offset_y1, offset_x2, offset_y2),
'landmark_offsets': (offset_px1, offset_py1, offset_px2, offset_py2, offset_px3, offset_py3, offset_px4, offset_py4, offset_px5, offset_py5)
}
代码解析:
- 第一步,接收传入的参数boxes、crop_box以及landmarks,分别解析原图人框、一个随机裁剪框的坐标和关键点坐标
- (精髓)第二步,根据原图人框(红色) - 随机裁剪框(蓝图) / 随机裁剪框的最大边长,求得偏移率
晓华老师提到这段代码非常精妙,仔细理解,其精妙之处在于:
第一点:因为P网络、R网络、O网络要处理的是正方形方图,所以在generate_crop_boxes()中使用max_side的做法,可以将图片转为正方形,方便后续的训练而不用再进行裁剪操作;
第二点:因为机器学习要进行数据归一化处理,而offset_x1 = (x1 - _x1) / _max_side计算的偏移率刚好是以0为中心,满足了归一化的要求;
第三点:因为信息蕴含在数据的相对大小的原则,所以在数据存储记录时,只要相对大小不丢,信息是不会缺失的。那么通过以上做法,我们原本要记录的信息个数做了优化减少,从4个(原图坐标)+4个(裁剪图坐标)+10个(5个关键点坐标)变为4个(裁剪图偏移量)+1个(最大边长)+10个(关键点偏移量),这会降低数据的存储代价和计算代价,同时又可以通过反解随时求得前面的坐标值。
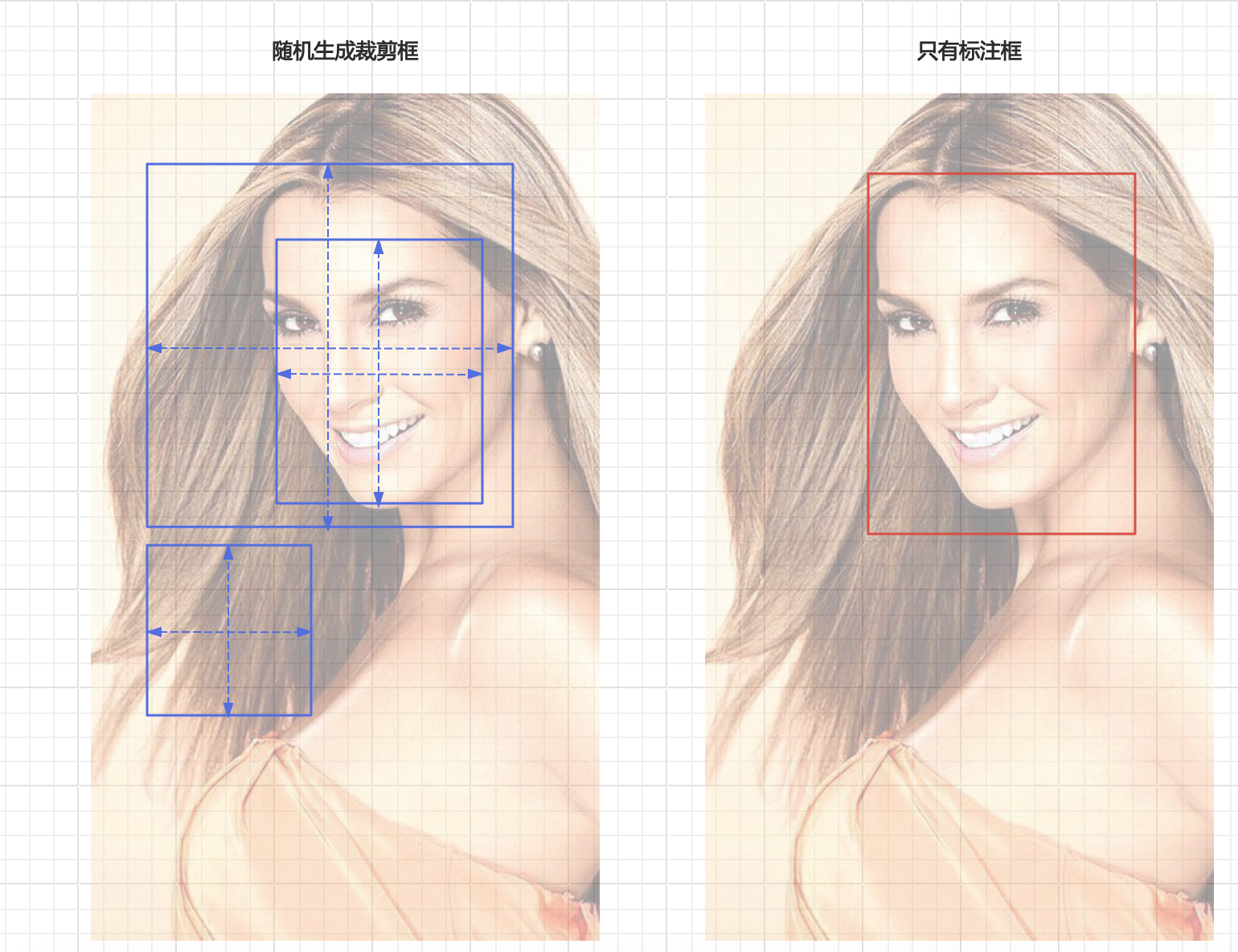
第四点:因为generate_crop_boxes()是通过随机生成不同的裁剪框,随机生成过程中可能生成更好套住脸的框,这一过程本身就是anchor-free随机生长的思想体现(如下图左侧);相比较如果训练数据不做随机生成裁剪框(如下图右侧),直接训练的标注框的坐标位置,那么机器在预测时就只有在脸框时与训练的相契合时才能识别是脸部,这应该是anchor-base的思想。
- 第三步,计算原图与裁剪图的iou,如果>0.7则为正样本;介于0.4~0.6之间是偏样本;如果<0.2则为负样本
save_samples函数解析
最后将生成的样本,保存到对应的文件中。
def save_samples(samples, files, base_path, counters):
"""
保存正负样本到文件中。
参数:
samples (list): 样本列表, 每个元素为一个字典, 包含 'image', 'label', 'bbox_offsets', 'landmark_offsets'
files (dict): 包含正负样本输出文件的字典
base_path (str): 输出文件的基础路径
counters (dict): 样本计数器字典
"""
for sample in samples:
image = sample['image']
label = sample['label']
bbox_offsets = sample['bbox_offsets']
landmark_offsets = sample['landmark_offsets']
if label == 1:
category = 'positive'
counters['positive'] += 1
elif label == 2:
category = 'part'
counters['part'] += 1
else:
category = 'negative'
counters['negative'] += 1
filename = f"{category}/{counters[category]}.jpg"
image.save(os.path.join(base_path, filename))
try:
bbox_str = ' '.join(map(str, bbox_offsets))
landmark_str = ' '.join(map(str, landmark_offsets))
files[category].write(f"{filename} {label} {bbox_str} {landmark_str}\n")
except IOError as e:
print(f"Error writing to file: {e}")
保存后的数据内容格式为:
negative/1.jpg 0 -2.1306818181818183 -2.909090909090909 -0.8238636363636364 -0.8863636363636364 -1.6420454545454546 -1.9772727272727273 -0.7443181818181818 -2.0681818181818183 -1.2897727272727273 -1.2386363636363635 -1.3125 -0.9886363636363636 -0.4943181818181818 -1.1136363636363635
negative/2.jpg 0 -0.14335664335664336 -1.9125874125874125 0.24125874125874125 -1.0944055944055944 0.15034965034965034 -1.3531468531468531 0.7097902097902098 -1.3531468531468531 0.34615384615384615 -1.0034965034965035 0.19230769230769232 -0.7587412587412588 0.7517482517482518 -0.7587412587412588
训练过程分析理解
训练过程参照深度学习的基本流程,分要进行批量化打包数据、构建模型、定义损失函数、定义训练过程。
批量化打包数据
# 构建自定义的脸部识别数据集
# 数据集使用CelebA数据集的图片和标签
import torch
import os
import numpy as np
from torch.utils.data import DataLoader, Dataset
from PIL import Image
class FaceDataset(Dataset):
def __init__(self, path):
super().__init__()
self.path = path
self.datasets = []
self._read_annos()
def _read_annos(self):
with open(os.path.join(self.path, "positive.txt")) as f:
self.datasets.extend(f.readlines())
with open(os.path.join(self.path, "negative.txt")) as f:
self.datasets.extend(f.readlines())
with open(os.path.join(self.path, "part.txt")) as f:
self.datasets.extend(f.readlines())
def __len__(self):
return len(self.datasets)
def __getitem__(self, idx):
strs = self.datasets[idx].strip().split()
# 文件名字
img_name = strs[0]
# 取出类别
cls = torch.tensor([int(strs[1])], dtype=torch.float32)
# 将所有偏置转为float类型
strs[2:] = [float(x) for x in strs[2:]]
# bbox的偏置
offset = torch.tensor(strs[2:6], dtype=torch.float32)
# landmark的偏置
point = torch.tensor(strs[6:16], dtype=torch.float32)
# 打开图像
img = Image.open(os.path.join(self.path, img_name))
# 数据调整到 [-1, 1]之间
img_data = torch.tensor((np.array(img) / 255. - 0.5) / 0.5, dtype=torch.float32)
# [H, W, C] --> [C, H ,W]
img_data = img_data.permute(2, 0, 1)
return img_data, cls, offset, point
代码解析:
- 以上代码使用的是标准的自定义数据集方式,即:声明一个类继承Dataset类,同时实现回调函数__len__()和__getitem__()即可。
构建模型
这部分内容已在【课程总结】Day13(下):人脸识别和MTCNN模型定义,本文不再赘述。
遗留问题:有些文章中部分MTCNN使用的激活函数是nn.PReLU,待了解与ReLU的区别。
筹备训练
class Trainer:
def __init__(self, net, param_path, data_path):
# 检测是否有GPU
self.device = 'cuda:0' if torch.cuda.is_available() else "cpu"
# 把模型搬到device
self.net = net.to(self.device)
self.param_path = param_path
# 打包数据
self.datasets = FaceDataset(data_path)
# 定义损失函数:类别判断(分类任务)
self.cls_loss_func = torch.nn.BCELoss()
# 定义损失函数:框的偏置回归
self.offset_loss_func = torch.nn.MSELoss()
# 定义损失函数:关键点的偏置回归
self.point_loss_func = torch.nn.MSELoss()
# 定义优化器
self.optimizer = torch.optim.Adam(params=self.net.parameters(), lr=1e-3)
def compute_loss(self, out_cls, out_offset, out_point, cls, offset, point, landmark):
# 选取置信度为0,1的正负样本求置信度损失
cls_mask = torch.lt(cls, 2)
cls_loss = self.cls_loss_func(torch.masked_select(out_cls, cls_mask),
torch.masked_select(cls, cls_mask))
# 选取正样本和部分样本求偏移率的损失
offset_mask = torch.gt(cls, 0)
offset_loss = self.offset_loss_func(torch.masked_select(out_offset, offset_mask),
torch.masked_select(offset, offset_mask))
if landmark:
point_loss = self.point_loss_func(torch.masked_select(out_point, offset_mask),
torch.masked_select(point, offset_mask))
return cls_loss, offset_loss, point_loss
else:
return cls_loss, offset_loss, None
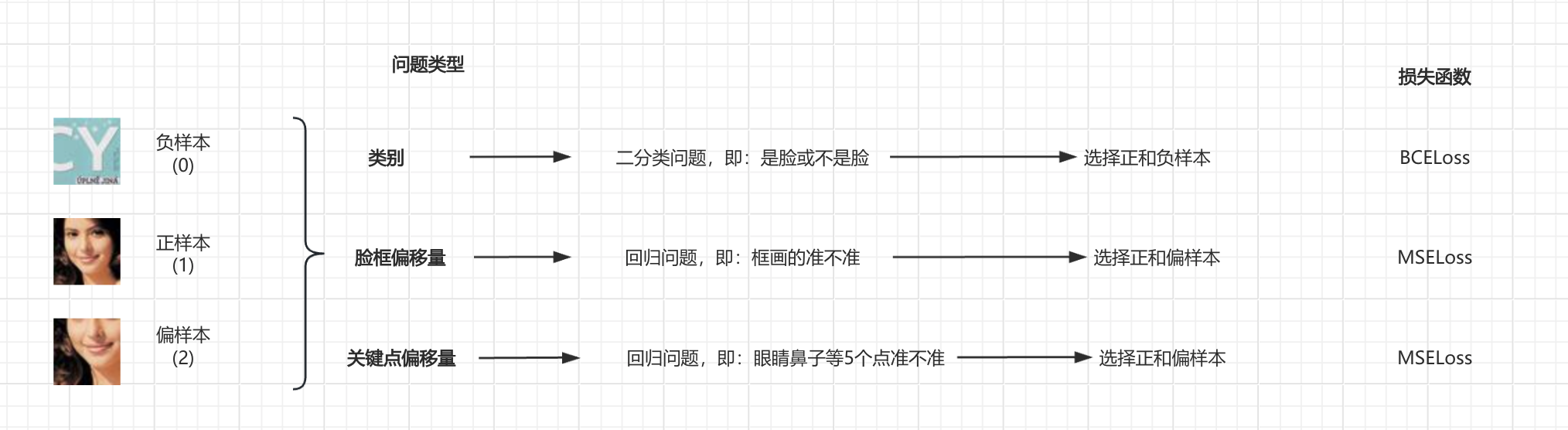
代码解析:
如上图所示,因为我们要预测的内容既有分类问题,也有回归问题,所以需要根据对应情况选择损失函数。
- 在类别方面,我们的样本虽然有正、负、偏样本,但是我们要训练模型的主要是:是脸或不是脸,所以其本质是个二分类问题,损失函数选择了BCELoss;
- 在脸框偏移量和关键点偏移量,都属于回归问题,所以损失函数选择了MSELoss。
- Mean Squared Error (MSE) Loss:
适用场景: 回归问题,希望预测值和真实值之间的差异最小化。例如房价预测、股票价格预测等。- Binary Cross-Entropy (BCE) Loss:
适用场景: 二分类问题,预测结果为0或1。例如垃圾邮件分类、图像二分类等。- Categorical Cross-Entropy (CCE) Loss:
适用场景: 多分类问题,预测结果为多个类别中的一个。例如图像分类、文本分类等。- Focal Loss:
适用场景: 类别不平衡的分类问题,可以提高模型对于难分类样本的关注度。- Dice Loss:
适用场景: 图像分割任务,可以提高模型对于边界区域的关注度。
定义训练过程
def train(self, epochs, landmark=False):
"""
- 断点续传 --> 短点续训
- transfer learning 迁移学习
- pretrained model 预训练
:param epochs: 训练的轮数
:param landmark: 是否为landmark任务
:return:
"""
# 加载上次训练的参数
if os.path.exists(self.param_path):
self.net.load_state_dict(torch.load(self.param_path))
print("加载参数文件,继续训练 ...")
else:
print("没有参数文件,全新训练 ...")
# 封装数据加载器
dataloader = DataLoader(self.datasets, batch_size=32, shuffle=True)
# 定义列表存储损失值
cls_losses = []
offset_losses = []
point_losses = []
total_losses = []
for epoch in range(epochs):
# 训练一轮
for i, (img_data, _cls, _offset, _point) in enumerate(dataloader):
# 数据搬家 [32, 3, 12, 12]
img_data = img_data.to(self.device)
_cls = _cls.to(self.device)
_offset = _offset.to(self.device)
_point = _point.to(self.device)
if landmark:
# O-Net输出三个
out_cls, out_offset, out_point = self.net(img_data)
out_point = out_point.view(-1, 10)
else:
# O-Net输出两个
out_cls, out_offset = self.net(img_data)
out_point = None
# [B, C, H, W] 转换为 [B, C]
out_cls = out_cls.view(-1, 1)
out_offset = out_offset.view(-1, 4)
if landmark:
out_point = out_point.view(-1, 10)
# 计算损失
cls_loss, offset_loss, point_loss = self.compute_loss(out_cls, out_offset, out_point,
_cls, _offset, _point, landmark)
if landmark:
loss = cls_loss + offset_loss + point_loss
else:
loss = cls_loss + offset_loss
# 打印损失
if landmark:
print(f"Epoch [{epoch+1}/{epochs}], loss:{loss.item():.4f}, cls_loss:{cls_loss.item():.4f}, "
f"offset_loss:{offset_loss.item():.4f}, point_loss:{point_loss.item():.4f}")
else:
print(f"Epoch [{epoch+1}/{epochs}], loss:{loss.item():.4f}, cls_loss:{cls_loss.item():.4f}, "
f"offset_loss:{offset_loss.item():.4f}")
# 存储损失值
cls_losses.append(cls_loss.item())
offset_losses.append(offset_loss.item())
if landmark:
point_losses.append(point_loss.item())
total_losses.append(loss.item())
# 清空梯度
self.optimizer.zero_grad()
# 梯度回传
loss.backward()
# 优化
self.optimizer.step()
# 保存模型(参数)
# torch.save(self.net.state_dict(), self.param_path)
# 保存整个模型
torch.save(self.net, self.param_path)
# 绘制损失曲线
self.plot_losses(cls_losses, offset_losses, point_losses, total_losses, landmark)
print("训练完成!")
代码解析:
在训练保存模型文件时,一般有两种方式:
- 方式一:保存整个神经网络的的结构信息和模型参数信息
# 保存训练完的网络的各层参数(即weights和bias)
torch.save(net.state_dict(),path):
# 加载保存到path中的各层参数到神经网络
net.load_state_dict(torch.load(path)):
- 方式二:只保存神经网络的训练模型参数
# 保存整个模型方法
torch.save(net,path):
# 加载整个模型方法
net = torch.load(path)
一般情况下,官方推荐使用第一种方式,原因是保存内容的少,速度也快,所以我在原有的示例代码改为了方式一。
我在保存和加载模型时,还遇到两个问题,作为经验分享记录下来:
- 如果在GPU机器上训练好模型,然后在使用CPU机器上加载模型预测是不可以的,torch会提示错误。
- 如果CPU机器是apple M3芯片,上述保存和加载模型会遇到(Segmentation Fault)的错误,查看github上的issue,该问题暂未解决。
开始训练
from train import model_mtcnn as nets
import os
import train.train as train
if __name__ == '__main__':
current_path = os.path.dirname(os.path.abspath(__file__))
# 权重存放地址
base_path = os.path.join(current_path, "model")
model_path = os.path.join(base_path, "p_net.pth")
# 数据存放地址
data_path = os.path.join(current_path, "datasets/train/12")
# 如果没有这个参数存放目录,则创建一个目录
if not os.path.exists(base_path):
os.makedirs(base_path)
# 构建模型
pnet = nets.PNet()
# 开始训练
t = train.Trainer(pnet, model_path, data_path)
t.train(100)
代码解析:
- 因为我们需要分别训练P-Net、R-Net、O-Net,所以分别实现了train_pnet.py、train_rnet.py、train_onet.py
预测过程分析理解
预测过程大体上可以分为:初始化、预处理、P-Net预测、R-Net预测、O-Net预测五个部分。
初始化和预处理
class Detector(object):
def __init__(self,
pnet_path,
rnet_path,
onet_path,
softnms=False,
thresholds=(0.6, 0.6, 0.95),
factor=0.709):
"""
初始化
"""
# 三个网络的置信度阈值
self.thresholds = thresholds
# 缩放因子
self.factor = factor
# 是否启用softnms
self.softnms = softnms
# 构建模型
self.pnet = nets.PNet().to(device)
self.rnet = nets.RNet().to(device)
self.onet = nets.ONet().to(device)
# 加载参数
# self.pnet.load_state_dict(torch.load(pnet_path))
# self.rnet.load_state_dict(torch.load(rnet_path))
# self.onet.load_state_dict(torch.load(onet_path))
# 加载整个模型
self.pnet = torch.load(pnet_path).to(device)
self.rnet = torch.load(rnet_path).to(device)
self.onet = torch.load(onet_path).to(device)
# 设为评估模式
self.pnet.eval()
self.rnet.eval()
self.onet.eval()
# 跟训练时做相同的预处理
self.img_transfrom = transforms.Compose([
# 转张量 [0, 1]
transforms.ToTensor(),
# [0,1] --> [-1, 1]
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
代码解析:
这部分代码的作用主要是:
- 声明了一个Detector类,用于实现人脸检测器
- 初始化__init__函数中,加载训练好的模型
- 将图像转换为张量:将图像从PIL格式或NumPy数组格式转换为PyTorch张量,并将像素值从0-255的范围缩放到0-1的范围。
- 标准化:对张量进行标准化处理,将像素值从0-1的范围转换到-1到1的范围。
transforms.Compose
transforms.Compose是一个工具,它接受一个由多个图像变换操作组成的列表,并将这些操作按顺序应用到输入图像上。这样可以将多个图像处理步骤组合在一起,形成一个预处理管道。transforms.ToTensor()
transforms.ToTensor()将一个PIL图像或NumPy数组转换为一个PyTorch张量(Tensor)。
输入:一个PIL图像或NumPy数组,像素值范围为0-255。
输出:一个PyTorch张量,像素值范围为0-1。transforms.Normalize(mean, std)
transforms.Normalize(mean, std)对张量进行标准化处理。它将每个通道的像素值减去给定的均值(mean),然后除以给定的标准差(std)。这一步通常用于使输入数据具有零均值和单位方差,从而有助于加速神经网络的训练和提高模型的收敛性。
在上述代码中,mean=[0.5, 0.5, 0.5]和std=[0.5, 0.5, 0.5]表示对每个通道(红、绿、蓝)进行相同的标准化处理。
P-Net网络预测
def pnet_detect(self, image):
"""
P-Net 检测
- 传入的是 原始图像 的 Image对象
"""
boxes = []
print("P-Net 检测")
# 遵从坐标习惯 H, W --> W, H
w, h = image.size
print("原始图像:", image.size)
min_side = min(w, h)
scale = 1
scale_time = 1
# 统计PNet检测的数量
nums = 0
# 图像金字塔
while min_side > 12:
# 图像预处理
img_data = self.img_transfrom(image).to(device)
# 添加批量维度 [3, h, w] --> [1, 3, h, w ]
img_data.unsqueeze_(0)
# print(f"第 {scale_time} 次检测 ")
# print("输入图像:", img_data.shape)
# 通过pnet模型,也就是正向传播
with torch.no_grad():
_cls, _offset = self.pnet(img_data)
# [1, 1, H, W]
print("输出置信度:", _cls.shape)
print("输出bbox偏置:", _offset.shape)
nums += _cls.shape[-1] * _cls.shape[-2]
# 将数据搬到CPU上计算 [1, 1, 295, 445]
_cls = _cls[0][0].data.cpu() # [295, 445]
_offset = _offset[0].data.cpu() # [4, 295, 445]
indexes = torch.nonzero(_cls > self.thresholds[0])
# 处理
boxes.extend(self.box(indexes, _cls, _offset, scale))
# 计算新的尺寸
scale *= self.factor
_w = int(w * scale)
_h = int(h * scale)
# 缩放图像(构建图像金字塔)
image = image.resize((_w, _h))
min_side = min(_w, _h)
scale_time += 1
# 打印PNet的检测次数
print(nums)
# 没有做去重复
if self.softnms:
return tool.soft_nms(torch.stack(boxes).numpy(), 0.3)
# return tool.nms(torch.stack(boxes).numpy(), 0.3)
boxes = torch.stack(boxes)
return boxes[nms(boxes[:, :4], boxes[:, 4], 0.3)].numpy()
代码解析:
这部分代码包含内容较多,我们分解为以下几部分分别理解:
构建图像金字塔:
while min_side > 12:
# 图像预处理
img_data = self.img_transfrom(image).to(device)
# 添加批量维度 [3, h, w] --> [1, 3, h, w ]
img_data.unsqueeze_(0)
#(中间代码省略....)
# 计算新的尺寸
scale *= self.factor
_w = int(w * scale)
_h = int(h * scale)
# 缩放图像(构建图像金字塔)
image = image.resize((_w, _h))
min_side = min(_w, _h)
scale_time += 1
- 通过
while循环,计算输入图像的最小边长min_side,直到最小边长小于12退出循环。 - 在每次循环中,通过
image.resize将当前图像缩放至新的尺寸(_w, _h),并将其赋值给image变量。
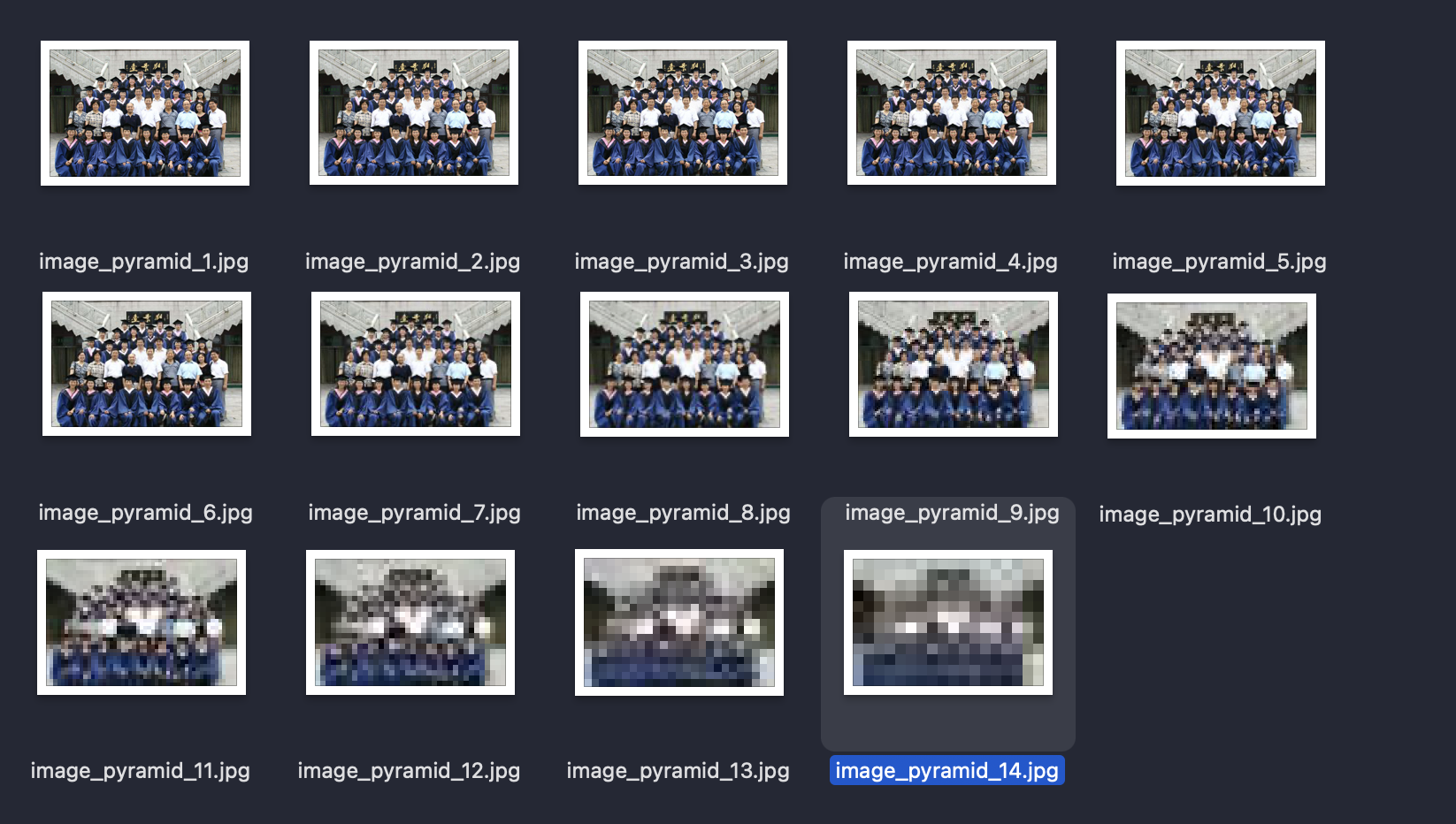
P-Net前向预测
# (省略...)
# 图像预处理
img_data = self.img_transfrom(image).to(device)
# 添加批量维度 [3, h, w] --> [1, 3, h, w ]
img_data.unsqueeze_(0)
# print(f"第 {scale_time} 次检测 ")
# print("输入图像:", img_data.shape)
# 通过pnet模型,也就是正向传播
with torch.no_grad():
_cls, _offset = self.pnet(img_data)
# [1, 1, H, W]
print("输出置信度:", _cls.shape)
print("输出bbox偏置:", _offset.shape)
# 将数据搬到CPU上计算 [1, 1, 295, 445]
_cls = _cls[0][0].data.cpu() # [295, 445]
_offset = _offset[0].data.cpu() # [4, 295, 445]
indexes = torch.nonzero(_cls > self.thresholds[0])
# (省略...)
- 将准备好的img_data输入到self.pnet模型中进行前向传播,得到输出的置信度_cls和边界框偏移量_offset。
_cls是 P-Net 输出的分类结果张量,表示每个像素点的置信度(confidence score),即该位置是否包含人脸的概率。self.thresholds[0]是一个阈值,对应thresholds=(0.6, 0.6, 0.95)中的0.6。_cls > self.thresholds[0]会生成一个布尔张量,形状与 _cls 相同,元素值为 True 表示该位置的置信度大于阈值,False 表示置信度小于或等于阈值。torch.nonzero()是 PyTorch 的一个函数,用于获取输入张量中所有非零元素的索引,它会返回一个二维张量,其中每一行表示 _cls 中一个大于阈值的位置的索引。indexes保存的是 _cls 张量中所有大于 self.thresholds[0] 的元素的索引位置。
import torch
# 假设_cls 的值为:
_cls = torch.tensor([[[[0.1, 0.7, 0.4],
[0.8, 0.2, 0.9],
[0.5, 0.3, 0.6]]]])
self_thresholds = [0.5]
_cls = _cls[0][0].data.cpu() # [3, 3]
_cls > self.thresholds[0]
# tensor([[False, True, False],
# [ True, False, True],
# [False, False, True]])
torch.nonzero(_cls > self.thresholds[0])
# tensor([[0, 1],
# [1, 0],
# [1, 2],
# [2, 2]])
# [0, 1]对应的值是 0.7,它在 _cls中的位置是(0, 0),所以返回的是 [0, 1]。
# [0, 0]对应的值是 0.8,它在 _cls中的位置是(0, 1),所以返回的是 [0, 0]。
在求得indexes后,通过boxes.extend(self.box(indexes, _cls, _offset, scale))反向求解人脸的框。
反向求解box框
def box(self, indexes, cls, offset, scale, stride=2, side_len=12):
# 反向解码,映射到原始图像上
# P-Net 反解坐标
# 左上角坐标
# anchor 的坐标是死的
# 求映射到原图中的
# 左上角的坐标
_x1 = (indexes[:, 1] * stride) / scale
_y1 = (indexes[:, 0] * stride) / scale
# 右下角坐标
_x2 = (indexes[:, 1] * stride + side_len) / scale
_y2 = (indexes[:, 0] * stride + side_len) / scale
# 边长
side = _x2 - _x1
# 取出有效框
offset = offset[:, indexes[:, 0], indexes[:, 1]]
# 通过误差和标准框,计算出真实预测框
x1 = (_x1 + side * offset[0])
y1 = (_y1 + side * offset[1])
x2 = (_x2 + side * offset[2])
y2 = (_y2 + side * offset[3])
# (n,)
cls = cls[indexes[:, 0], indexes[:, 1]]
# (n, 5)
result = torch.stack([x1, y1, x2, y2, cls], dim=1)
return result
如图所示

indexes[:, 1]: 这是从 indexes 中提取的第二列,表示这些元素在特征图宽度方向上的索引。stride: 这是 P-Net 的步长,表示在特征图上每移动一步在原图上对应的像素距离。scale: 这是当前图像金字塔的缩放比例,表示特征图相对于原始图像的缩放因子。- 通过
(indexes[:, 1] * stride) / scale将特征图上的坐标映射回原图坐标系 - 通过计算side边长和offset,反向求解出真实预测框的坐标。
- 最后返回真实预测框的坐标以及置信度。
NMS求最终框
return boxes[nms(boxes[:, :4], boxes[:, 4], 0.3)].numpy()
对特征框进行排序,通过NMS求得最终的框。
R-Net网络预测
def rnet_detect(self, image, pnet_boxes):
"""
R-Net 检测
"""
boxes = []
img_dataset = []
# 取出PNet的框,转为正方形,转成tensor,方便后面用tensor去索引
square_boxes = torch.from_numpy(tool.convert_to_square(pnet_boxes))
for box in square_boxes:
_x1 = int(box[0])
_y1 = int(box[1])
_x2 = int(box[2])
_y2 = int(box[3])
# crop裁剪的时候超出原图大小的坐标会自动填充为黑色
img_crop = image.crop([_x1, _y1, _x2, _y2])
# 转为24*24,也就是RNet输入
img_crop = img_crop.resize((24, 24))
img_data = self.img_transfrom(img_crop).to(device)
img_dataset.append(img_data)
# (n,1) (n,4)
_cls, _offset = self.rnet(torch.stack(img_dataset))
_cls = _cls.data.cpu()
_offset = _offset.data.cpu()
# (14,)
indexes = torch.nonzero(_cls > self.thresholds[1])[:, 0]
# (n,5)
box = square_boxes[indexes]
# (n,)
_x1 = box[:, 0]
_y1 = box[:, 1]
_x2 = box[:, 2]
_y2 = box[:, 3]
side = _x2 - _x1
# (n,4)
offset = _offset[indexes]
# (n,)
x1 = _x1 + side * offset[:, 0]
y1 = _y1 + side * offset[:, 1]
x2 = _x2 + side * offset[:, 2]
y2 = _y2 + side * offset[:, 3]
# (n,)
cls = _cls[indexes][:, 0]
# np.array([x1, y1, x2, y2, cls]) (5,n)
boxes.extend(torch.stack([x1, y1, x2, y2, cls], dim=1))
if len(boxes) == 0:
return np.array([])
boxes = torch.stack(boxes)
return boxes[nms(boxes[:, :4], boxes[:, 4], 0.3)].numpy()
代码解析:
R-Net预测过程与P-Net类似,只是R-Net的输入除了图像之外还有P-Net的预测结果。
O-Net网络预测
def onet_detect(self, image, rnet_boxes):
"""
O-Net 检测
"""
boxes = []
img_dataset = []
square_boxes = tool.convert_to_square(rnet_boxes)
for box in square_boxes:
_x1 = int(box[0])
_y1 = int(box[1])
_x2 = int(box[2])
_y2 = int(box[3])
img_crop = image.crop([_x1, _y1, _x2, _y2])
img_crop = img_crop.resize((48, 48))
img_data = self.img_transfrom(img_crop).to(device)
img_dataset.append(img_data)
_cls, _offset, _point = self.onet(torch.stack(img_dataset))
_cls = _cls.data.cpu().numpy()
_offset = _offset.data.cpu().numpy()
_point = _point.data.cpu().numpy()
# 0.95
indexes, _ = np.where(_cls > self.thresholds[2])
# (n,5)
box = square_boxes[indexes]
# (n,)
_x1 = box[:, 0]
_y1 = box[:, 1]
_x2 = box[:, 2]
_y2 = box[:, 3]
side = _x2 - _x1
# (n,4)
offset = _offset[indexes]
# (n,)
x1 = _x1 + side * offset[:, 0]
y1 = _y1 + side * offset[:, 1]
x2 = _x2 + side * offset[:, 2]
y2 = _y2 + side * offset[:, 3]
# (n,)
cls = _cls[indexes][:, 0]
# (n,10)
point = _point[indexes]
px1 = _x1 + side * point[:, 0]
py1 = _y1 + side * point[:, 1]
px2 = _x1 + side * point[:, 2]
py2 = _y1 + side * point[:, 3]
px3 = _x1 + side * point[:, 4]
py3 = _y1 + side * point[:, 5]
px4 = _x1 + side * point[:, 6]
py4 = _y1 + side * point[:, 7]
px5 = _x1 + side * point[:, 8]
py5 = _y1 + side * point[:, 9]
# np.array([x1, y1, x2, y2, cls, px1, py1, px2, py2, px3, py3, px4, py4, px5, py5]) (15,n)
boxes.extend(np.stack([x1, y1, x2, y2, cls, px1, py1, px2, py2, px3, py3, px4, py4, px5, py5], axis=1))
if len(boxes) == 0:
return np.array([])
# return tool.nms(np.stack(boxes), 0.3, isMin=True)
return NMS(np.stack(boxes), 0.3, isMin=True)
代码解析:
O-Net预测过程与R-Net类似,只是O-Net网络除了预测人物框之外,还需要预测五个关键点,五个关键点的反向求解与Box的反向求解过程类似。
遗留待探索问题
问题1:为什么要有偏样本
问题2:为什么训练过程损失率是不定的
问题3:如何增加新的标签进行训练
问题4:如何将三个模型合成一个过程
内容小结
- 数据预处理
- 标注的原始数据是不能直接灌入模型训练的,需要进行预处理,包括归一化、裁剪、旋转、翻转、缩放等。
- 数据的存储、计算需要考究计算代价,这也是最考验问题思考和解决能力的地方。
- 谨记"信息蕴含在数据的相对大小"之中,所以无论是数据归一化还是数据存储,可以考虑通过计算数据比例(相对于原来的比例)来进行处理。
- 模型训练
- MTCNN的训练过程需要三个网络,分别是P-Net、R-Net、O-Net,训练过程需要分别训练三个网络。
- MTCNN的训练过程与其他深度学习的训练过程类似,包括自定义datasets、模型搭建、筹备训练、训练及保存模型等。
- 模型保存时有两种方式,一种是保存模型参数,另一种是保存模型结构+模型参数,官方推荐使用后者。
- 模型预测
- 预测过程大体上可以分为:初始化、预处理、P-Net预测、R-Net预测、O-Net预测五个部分。
- P-Net预测时会生成不同的图像金字塔,然后进行预测;预测后会返回置信度
_cls和人脸框偏移量_offset - 反解求人脸框box时,会先通过置信度求得特征图的宽高,然后再通过步长、缩放系数、偏移量等,求得原图中的真实框。
- R-Net与O-Net的预测过程类似,O-Net的预测过程会增加关键点的预测。
- 其他
- 代码实现还是要遵照编程规范(例如:单个函数的代码行控制在200行左右),提升代码的可读性。















 5753
5753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









