







老师非常注重抄袭现象!!!
老师非常注重抄袭现象!!!
老师非常注重抄袭现象!!!
大致流程
- 加载作业环境
sudo docker pull dingms/ucas-bdms-hw-u64-2019:16.04
查看当前环境 sudo docker images`
-
运行容器
sudo docker run -itd dingms/ucas-bdms-hw-u64-2019:16.04 /bin/bash -
查看正在运行的容器
sudo docker ps -
主机和容器之间复制文件
sudo docker cp <src> <dest>
eg:
sudo docker cp Hw1Grp5.java 50aef7f6b80e:/home/bdms/homework/hw1/example -
进入正在运行的容器
sudo docker exec -it <docker ID>/bin/bash -
先打开ssh
service ssh stop
service ssh start -
再运行hdfs
start-dfs.sh
jps查看当前节点进程
cd /home/bdms/homework/hw1/input进入当前文件目录下,把lineitem.tbl上传到hdfs用于测试代码 -
将lineitem.tbl传入hdfs
hadoop fs -mkdir /hw1 hadoop fs -put lineitem.tbl/hw1 hadoop fs -ls -R /hw1
- 查看hadoop文件
hadoop fs -ls /(加路径)
编写代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.log4j.*;
public class Hw1Grp5 {
private static String table_name = "Result";
private static byte[] column_family = "res".getBytes();
public static void main(String[] args)throws IOException, URISyntaxException {
if (args.length != 3) {
System.out.println("Input Error");
System.exit(1);
}
// input eg:java Hw1GrpX R=<file> select:R1,gt,5.1 distinct:R2,R3,R5
String file_path = args[0].substring(args[0].indexOf("=")+1).trim(); //R=<file>
String select=args[1].substring(args[1].indexOf(":")+1).trim(); //select:R1,gt,5.1
String distinct=args[2].substring(args[2].indexOf(":")+1).trim();//distinct:R2,R3,R5
List<String> data_initial = readDataFromFile(file_path,select,distinct);
//duplicate removal
String last_word = "";
ArrayList<String> data_sorted = new ArrayList<String>(data_initial);
Collections.sort(data_sorted);
ArrayList<String> data_duplicate_removal= new ArrayList<String>();
for (String temp : data_sorted) {
// System.out.println("LOG: "+remp+" & "+lastWord);
// temp == lastWord NOT WORK! should use `equals()`
if (!temp.equals(last_word)) data_duplicate_removal.add(temp);
last_word = new String(temp);
}
//Insert Hbase
InsertHbase(data_duplicate_removal, distinct, table_name, column_family);
System.out.println("success!");
}
private static List<String> readDataFromFile(String file_path, String select, String distinct) throws IOException {
String select_requirement[] = select.split(",");//select条件数据处理
String select_col = select_requirement[0].substring(1);//选择 第7列
String select_symbol = select_requirement[1];//条件 大于小于gt
String select_value = select_requirement[2];//条件 1800
int select_col_int = Integer.valueOf(select_col);//选择第7列 字符串型转为整形
String select_symbol_string = select_symbol;//条件 大于gt
double select_value_double = Double.valueOf(select_value);//字符串转为double型 条件 1800.0
String[] tmp_distinct_columns = distinct.split(",");//投影列 R3R4R5
int[] distinct_columns_int = new int[tmp_distinct_columns.length];
for(int i=0; i<tmp_distinct_columns.length; i++)//只要数字 3 4 5列
distinct_columns_int[i] = Integer.valueOf(tmp_distinct_columns[i].substring(1));
// Loading prepare
FileSystem fs = FileSystem.get(URI.create(file_path), new Configuration());
FSDataInputStream in_stream = fs.open(new Path(file_path));
BufferedReader br = new BufferedReader(new InputStreamReader(in_stream));
// Filter
String line = null;
List<String> data_list = new LinkedList<String>();//列表 字符串型
while( ( line=br.readLine() )!=null ){
String[] line_data = line.split("\\|");
double select_columns_double = Double.valueOf(line_data[select_col_int]);
if( Require_Judge(select_symbol_string, select_columns_double, select_value_double) ){
String key = "";
for(int i:distinct_columns_int) key += line_data[i] + "|";
data_list.add(key);
}
}
br.close();
fs.close();
return data_list;
}
private static boolean Require_Judge(String select_symbol_string, double select_columns_double, double select_value_double) {
boolean result = (
select_symbol_string.equals("eq") && select_columns_double == select_value_double ||
select_symbol_string.equals("gt") && select_columns_double > select_value_double ||
select_symbol_string.equals("ge") && select_columns_double >= select_value_double ||
select_symbol_string.equals("le") && select_columns_double <= select_value_double ||
select_symbol_string.equals("lt") && select_columns_double < select_value_double ||
select_symbol_string.equals("ne") && select_columns_double != select_value_double );
return result;
}
private static void InsertHbase(ArrayList<String> data_duplicate_removal, String distinct, String table_name, byte[] column_family) throws IOException {
HBaseAdmin hAdmin = new HBaseAdmin(HBaseConfiguration.create());// configure HBase
TableName tn = TableName.valueOf(table_name);
if (hAdmin.tableExists(tn)) {
hAdmin.disableTable(tn);
hAdmin.deleteTable(tn);
}
HTableDescriptor htd = new HTableDescriptor(tn);// create table descriptor
htd.addFamily(new HColumnDescriptor(column_family));// create column descriptor
hAdmin.createTable(htd);
// System.out.println("Table " + tableName + " created.");
String[] columns_name = distinct.split(",");//R3 R4 R5
HTable table = new HTable(HBaseConfiguration.create(), TableName.valueOf(table_name));
int key = 0;
for (String temp : data_duplicate_removal) {
Put put = new Put(("" + key++).getBytes());
String[] tem = temp.split("\\|");
for (int j = 0; j < columns_name.length; j++)
put.add(column_family, columns_name[j].getBytes(), tem[j].getBytes());
table.put(put);
}
table.close();
}
}
注意:在容器中编译运行时要把中文注释删掉。
检查
-
先将文件名改为
组号 _学号_hw1.java
使用mv命令:mv 文件1路径 文件2路径
eg:mv test1.java test2.java -
将 hw1-check文件夹复制到容器
sudo docker cp hw1-check <容器ID>:/home/bdms/homework/hw1/example
复制文件一般先进入改文件路径下 -
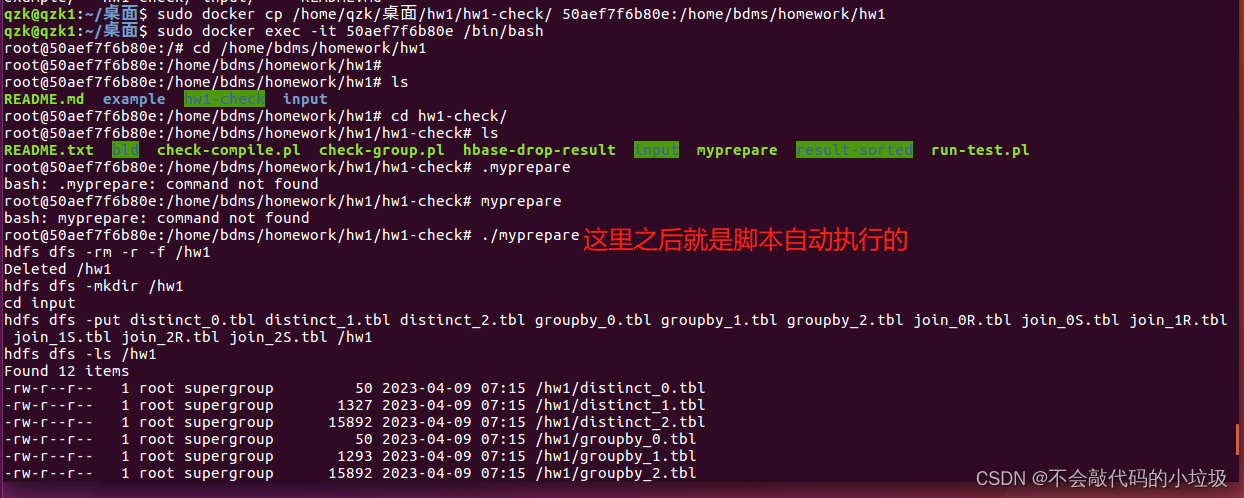
在容器环境下进入到刚刚复制过来的hw1-check文件目录下
分别执行:-
./myprepare把输入文件上传到hdfs
-
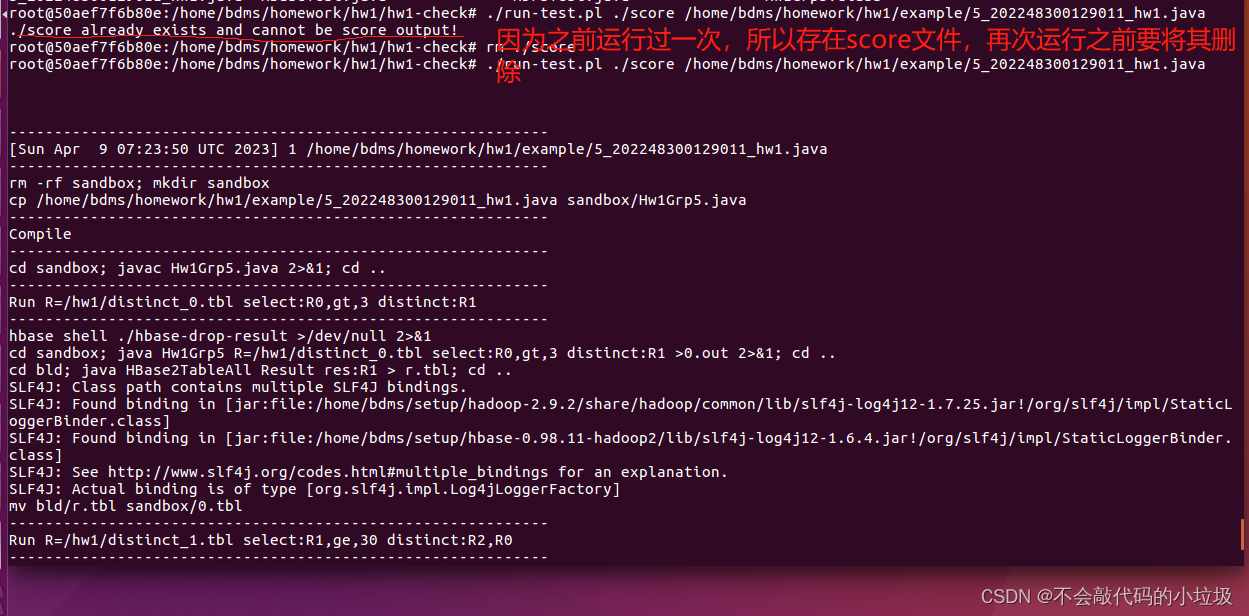
./check-group.pl <your-java-file>检查文件命名格式

-
./check-compile.pl <your-java-file>检查是否能编译成功

-
./run-test.pl ./score <your-java-file>运行
-
-
之后会得到分数,你的分数会在run-test.pl测试3个输入案例,您将每个案例得一分。因此输出满分为3。
cat score查看分数
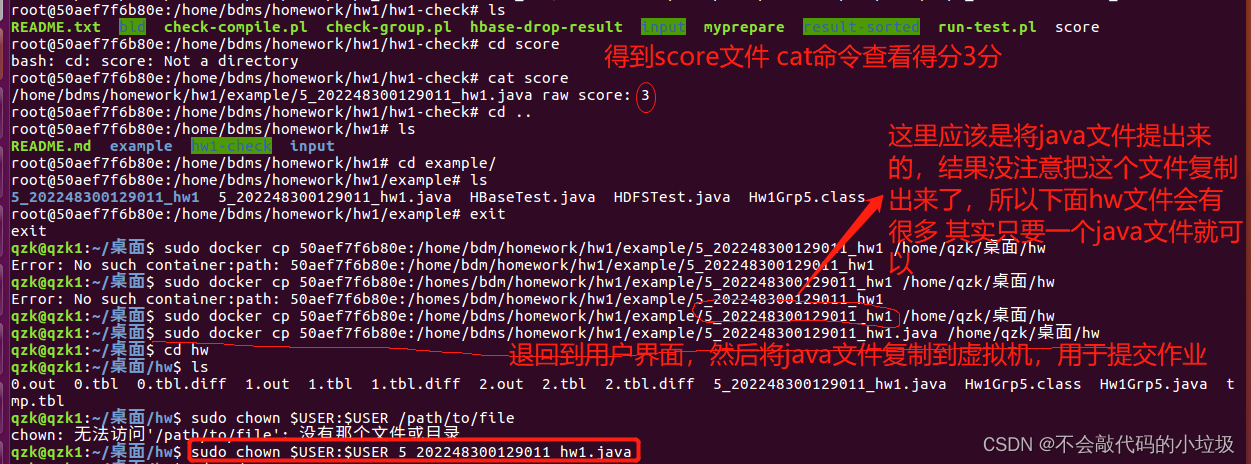
如果你复制到虚拟机的文件没有权限操作,导致你无法打开或者复制到自己电脑上时,使用这个命令对提出来的java文件修改权限
sudo chown $USER:$USER <文件名> -
如果再次测试得分,需要先删除score文件,再运行
rm ./score
./run-test.pl ./score <your-java-file>















 5885
5885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









