







在当前的技术环境下,深度学习模型面临着尺寸和计算需求不断增长的压力,这直接影响了其在资源受限环境中的实用性。为此,int8量化技术作为一种解决方案,被广泛探讨和应用,其主要目的是减小模型尺寸并提升计算效率。
int8量化的核心原理
int8量化的核心在于将模型中的32位浮点数转换为8位整数。这种转换通过使用缩放因子(scale)和偏移量(offset)完成,以确保转换后的整数能够尽可能准确地表示原始的浮点数。此过程不仅缩减了数据存储的空间,还能在执行模型推理时降低计算资源的消耗。
Q=clip(S*R+Z,-128,127)
int8量化在实际中的运用
这种量化技术特别适用于那些资源有限的设备,如移动设备和嵌入式系统等。在这些设备上,通过int8量化,模型不仅占用的存储空间更小,而且运行速度更快,使得深度学习技术能够在这类设备上得到更好的实际应用。
为了方便读者清楚的看到int8量化技术的使用,我们借助DeepLn算力云平台来展示这项技术。DeepLn算力云是一个稳定、好用、超具性价比的GPU算力租用平台,十分方便好用。
首先我们进入到DeepLn算力云网站,在算力市场上选择自己心仪的服务器,这价格简直是白菜价。
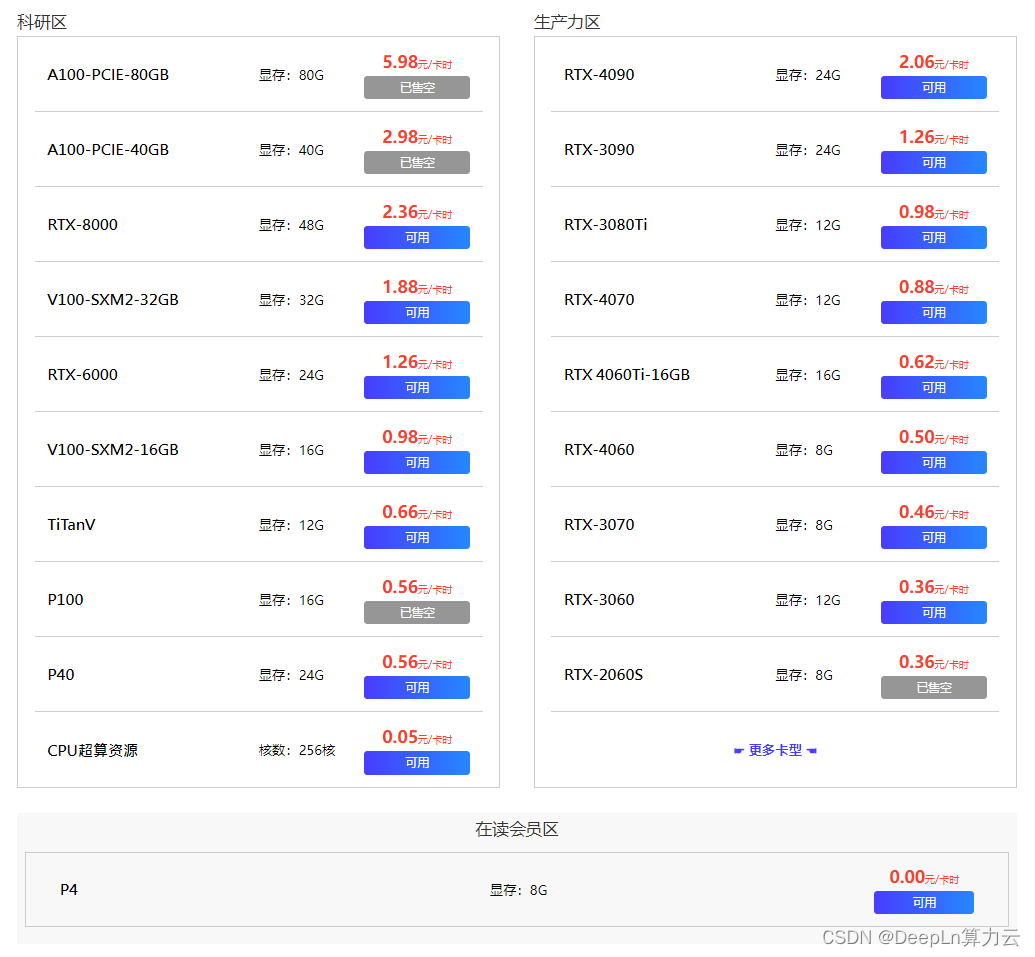
选择好心仪的服务器后,我们还可以提前选择服务器内的conda环境和pip package,DeepLn的服务器中预置了常用的深度学习package,极大的节省了我们装配环境的时间精力。
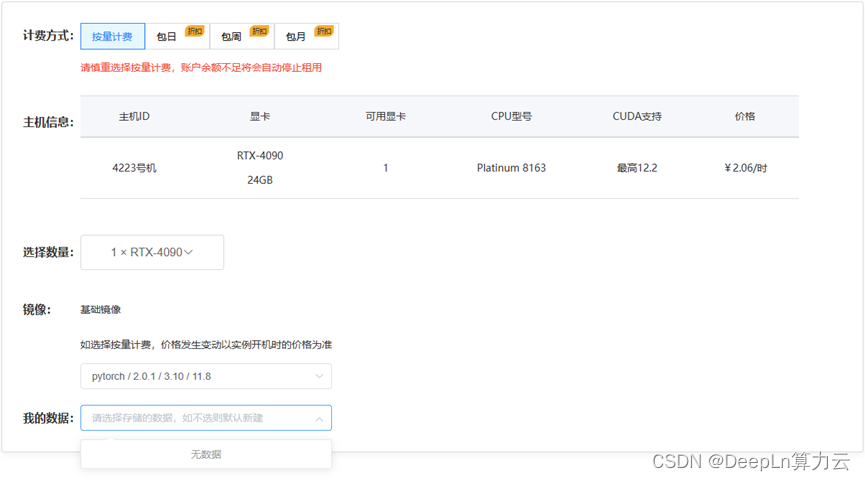
进入控制台,我们只需要点击code-server,即可进入在线的服务器环境,当然也可以通过ssh连接使用。
进入服务器环境后,我们就可以通过jupyter notebook或者python环境执行代码了,为了方便读者阅读,我们在这里使用jupyter notebook演示在Pytorch官网(https://pytorch.org/tutorials/advanced/static_quantization_tutorial.html)中的模型静态量化。
首先我们加载一些必要的package,这些package已经在DeepLn算力云的服务器中预置好了。
import os
import sys
import time
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision
from torchvision import datasets
import torchvision.transforms as transforms
# Set up warnings
import warnings
warnings.filterwarnings(
action='ignore',
category=DeprecationWarning,
module=r'.*'
)
warnings.filterwarnings(
action='default',
module=r'torch.ao.quantization'
)
# Specify random seed for repeatable results
torch.manual_seed(191009)
接着,我们定义MobileNetV2 模型架构,并进行了一些值得注意的修改。
from torch.ao.quantization import QuantStub, DeQuantStub
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes, momentum=0.1),
# Replace with ReLU
nn.ReLU(inplace=False)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1:
# pw
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
layers.extend([
# dw
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup, momentum=0.1),
])
self.conv = nn.Sequential(*layers)
# Replace torch.add with floatfunctional
self.skip_add = nn.quantized.FloatFunctional()
def forward(self, x):
if self.use_res_connect:
return self.skip_add.add(x, self.conv(x))
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
"""
MobileNet V2 main class
Args:
num_classes (int): Number of classes
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
inverted_residual_setting: Network structure
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
Set to 1 to turn off rounding
"""
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
if inverted_residual_setting is None:
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
# only check the first element, assuming user knows t,c,n,s are required
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
# building first layer
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
features = [ConvBNReLU(3, input_channel, stride=2)]
# building inverted residual blocks
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1))
# make it nn.Sequential
self.features = nn.Sequential(*features)
self.quant = QuantStub()
self.dequant = DeQuantStub()
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, num_classes),
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.quant(x)
x = self.features(x)
x = x.mean([2, 3])
x = self.classifier(x)
x = self.dequant(x)
return x
# Fuse Conv+BN and Conv+BN+Relu modules prior to quantization
# This operation does not change the numerics
def fuse_model(self, is_qat=False):
fuse_modules = torch.ao.quantization.fuse_modules_qat if is_qat else torch.ao.quantization.fuse_modules
for m in self.modules():
if type(m) == ConvBNReLU:
fuse_modules(m, ['0', '1', '2'], inplace=True)
if type(m) == InvertedResidual:
for idx in range(len(m.conv)):
if type(m.conv[idx]) == nn.Conv2d:
fuse_modules(m.conv, [str(idx), str(idx + 1)], inplace=True)
接着,我们定义一些辅助函数:
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f'):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def evaluate(model, criterion, data_loader, neval_batches):
model.eval()
top1 = AverageMeter('Acc@1', ':6.2f')
top5 = AverageMeter('Acc@5', ':6.2f')
cnt = 0
with torch.no_grad():
for image, target in data_loader:
output = model(image)
loss = criterion(output, target)
cnt += 1
acc1, acc5 = accuracy(output, target, topk=(1, 5))
print('.', end = '')
top1.update(acc1[0], image.size(0))
top5.update(acc5[0], image.size(0))
if cnt >= neval_batches:
return top1, top5
return top1, top5
def load_model(model_file):
model = MobileNetV2()
state_dict = torch.load(model_file)
model.load_state_dict(state_dict)
model.to('cpu')
return model
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
最后,我们定义数据集和数据加载器:
def prepare_data_loaders(data_path):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
dataset = torchvision.datasets.ImageNet(
data_path, split="train", transform=transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
dataset_test = torchvision.datasets.ImageNet(
data_path, split="val", transform=transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]))
train_sampler = torch.utils.data.RandomSampler(dataset)
test_sampler = torch.utils.data.SequentialSampler(dataset_test)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=train_batch_size,
sampler=train_sampler)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=eval_batch_size,
sampler=test_sampler)
return data_loader, data_loader_test
然后我们来加载预训练的模型,并且查看模型的精度和大小:
data_path = '~/.data/imagenet'
saved_model_dir = 'data/'
float_model_file = 'mobilenet_pretrained_float.pth'
scripted_float_model_file = 'mobilenet_quantization_scripted.pth'
scripted_quantized_model_file = 'mobilenet_quantization_scripted_quantized.pth'
train_batch_size = 30
eval_batch_size = 50
data_loader, data_loader_test = prepare_data_loaders(data_path)
criterion = nn.CrossEntropyLoss()
float_model = load_model(saved_model_dir + float_model_file).to('cpu')
# Next, we'll "fuse modules"; this can both make the model faster by saving on memory access
# while also improving numerical accuracy. While this can be used with any model, this is
# especially common with quantized models.
print('\n Inverted Residual Block: Before fusion \n\n', float_model.features[1].conv)
float_model.eval()
# Fuses modules
float_model.fuse_model()
# Note fusion of Conv+BN+Relu and Conv+Relu
print('\n Inverted Residual Block: After fusion\n\n',float_model.features[1].conv)
num_eval_batches = 1000
print("Size of baseline model")
print_size_of_model(float_model)
top1, top5 = evaluate(float_model, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
torch.jit.save(torch.jit.script(float_model), saved_model_dir + scripted_float_model_file)
在整个模型中,我们在 50,000 张图像的 eval 数据集上获得了 71.9% 的准确率。接下来,让我们尝试模型训练后静态量化方法。
num_calibration_batches = 32
myModel = load_model(saved_model_dir + float_model_file).to('cpu')
myModel.eval()
# Fuse Conv, bn and relu
myModel.fuse_model()
# Specify quantization configuration
# Start with simple min/max range estimation and per-tensor quantization of weights
myModel.qconfig = torch.ao.quantization.default_qconfig
print(myModel.qconfig)
torch.ao.quantization.prepare(myModel, inplace=True)
# Calibrate first
print('Post Training Quantization Prepare: Inserting Observers')
print('\n Inverted Residual Block:After observer insertion \n\n', myModel.features[1].conv)
# Calibrate with the training set
evaluate(myModel, criterion, data_loader, neval_batches=num_calibration_batches)
print('Post Training Quantization: Calibration done')
# Convert to quantized model
torch.ao.quantization.convert(myModel, inplace=True)
# You may see a user warning about needing to calibrate the model. This warning can be safely ignored.
# This warning occurs because not all modules are run in each model runs, so some
# modules may not be calibrated.
print('Post Training Quantization: Convert done')
print('\n Inverted Residual Block: After fusion and quantization, note fused modules: \n\n',myModel.features[1].conv)
print("Size of model after quantization")
print_size_of_model(myModel)
top1, top5 = evaluate(myModel, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
对于这个量化模型,我们看到 eval 数据集的准确率为 56.7%。这是因为我们使用了一个简单的最小值/最大值观察器来确定量化参数。尽管如此,我们确实将模型的大小缩小到略低于 3.6 MB,几乎减少了 4 倍。我们发现,通过在DeepLn算力云服务器中使用模型量化,确实有效的减少了模型的大小。
优化int8量化的方法
为了最大化int8量化的效益,研究者和开发者可以采取多种优化策略。其中包括精心选择量化算法以适应特定的应用需求,精确调整缩放因子和偏移量以最小化信息损失,以及实施量化感知训练,这种训练方法能够在模型训练阶段就考虑到量化的影响,从而优化模型参数。
此外,使用适当的校准数据集进行模型量化前的校准也是非常关键的,这有助于确保量化模型能够在实际应用中保持高效和精确。
结语
通过在DeepLn算力云平台中深入探索int8量化的机制和优化方法,我们能够更有效地部署深度学习模型到各种计算受限的环境中。未来的研究将继续聚焦于如何提高量化算法的效率和精确性,以适应日益增长的应用需求。这将为深度学习技术的进一步普及和应用开辟更广阔的道路。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}