







 本文介绍了使用Scrapy爬取B站UP主信息的过程,包括UP主的mid、昵称、性别等,并通过递归方式获取关注列表和粉丝列表。尽管B站限制只能访问前5页数据,但作者提出通过选择高人气UP主作为起始点以增加爬取信息量。项目包含start.py、user.py、items.py、pipelines.py和settings.py等文件,初步运行已爬取约1000条数据。
本文介绍了使用Scrapy爬取B站UP主信息的过程,包括UP主的mid、昵称、性别等,并通过递归方式获取关注列表和粉丝列表。尽管B站限制只能访问前5页数据,但作者提出通过选择高人气UP主作为起始点以增加爬取信息量。项目包含start.py、user.py、items.py、pipelines.py和settings.py等文件,初步运行已爬取约1000条数据。
思路分析
本次爬取的信息,包括UP主的mid、昵称、性别、头像的链接、个人简介、粉丝数、关注数、播放数、获赞数。
我的思路是,首先,选择一位B站比较火的UP主(这里以机智的党妹为例),然后,爬取其信息,再获取其关注列表中的用户和粉丝列表中的用户,重复上述操作。这相当于采用了递归的方式进行爬取。
下面我们来分析一下如何获取UP主的信息、关注列表和粉丝列表。

用户信息请求的URL:
https://api.bilibili.com/x/space/acc/info?mid=466272

粉丝数和关注数请求的URL:
https://api.bilibili.com/x/relation/stat?vmid=466272

获赞数和播放数请求的URL:
https://api.bilibili.com/x/space/upstat?mid=466272

粉丝列表请求的URL:
https://api.bilibili.com/x/relation/followers?vmid=466272&pn=1&ps=20
关注列表请求的URL:
https://api.bilibili.com/x/relation/followings?vmid=466272&pn=1&ps=20


这两个的分析方法其实都差不多,这里只分析其中的一个。
上面URL中的pn代表页数,ps好像是代表一次获取的用户数目,每次固定是20个(ps这个参数,我也没细看,不过这个参数并不重要)
本来以为到这里就可以了,直接写个for循环依次遍历每一页就行了,可是。。。。。。

这个系统限制,只能访问前5页是什么鬼。ε=(´ο`*)))唉,难道是我没登陆的问题吗?赶紧手忙脚乱的登上我的B站账号,不过,没有任何卵用,看来是B站做了限制,就只能提取前5页的数据。对于这个问题,我一直没找到解决的方法,不知道各位爬虫大佬有没有好的解决方法呀!
但是,按照我这个思路去爬取的话,还是可以爬到很多用户的,毕竟是递归爬取嘛。如果觉得爬取的用户数不够,还可以在B站的每一个分区中,选取知名UP主(粉丝数多的)作为起始URL进行爬取,这样效果会好一些。
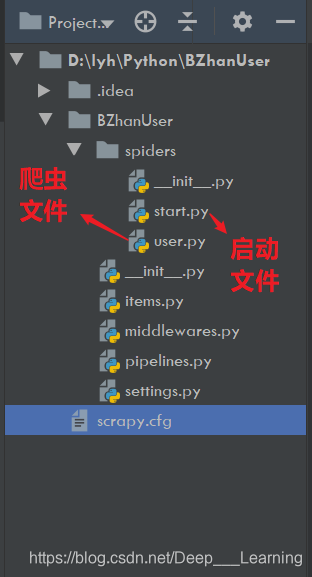
项目目录
代码
start.py
# !/usr/bin/env python
# —*— coding: utf-8 —*—
# @Time: 2020/2/19 16:24
# @Author: Martin
# @File: start.py
# @Software:PyCharm
from scrapy import cmdline
cmdline.execute("scrapy crawl user".split())
# cmdline.execute("scrapy crawl user --nolog".split())
user.py
# -*- coding: utf-8 -*-
import scrapy
import json
from scrapy.http import Request
from BZhanUser.items import BzhanuserItem
class UserSpider(scrapy.Spider):
name = 'user'
allowed_domains = ['bilibili.com']
start_urls = ['https://api.bilibili.com/x/space/acc/info?mid=466272']
def parse(self, response):
data = json.loads(response.body)['data']
mid = data['mid']
name = data['name']
sex = data['sex']
face = data['face']
sign = data['sign']
# 粉丝数和关注数
url1 = 'https://api.bilibili.com/x/relation/stat?vmid=' + str(mid)
yield Request(url=url1, callback=self.parse_page1,
meta={
'mid': mid, 'name': name, 'sex': sex, 'face': face, 'sign': sign} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2099
2099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









