







训练模型一般都是先处理 数据的输入问题 和 预处理问题。Pytorch提供了几个有用的工具:torch.utils.data.Dataset类 和 torch.utils.data.DataLoader类 。
流程是先把 原始数据 转变成 torch.utils.data.Dataset类 随后再把得到的***torch.utils.data.Dataset类*** 当作一个参数传递给 torch.utils.data.DataLoader类,得到一个数据加载器,这个数据加载器每次可以返回一个 Batch 的数据供模型训练使用。
这一过程通常可以让我们把一张 生图 通过标准化、resize等操作转变成我们需要的 [B,C,H,W] 形状的 Tensor。
1. 直接用Pytorch的子模块 torchvision 准备好的数据
torchvision一般随着pytorch的安装也会安装到本地,直接导入就可以使用了。trochvision包含了 1.常用数据集;2.常用模型框架;3.数据转换方法。其中它提供的数据集就已经是一个***Dataset类*** 了。torchvison.datasets就是专门提供各类常用数据集的模块。
以下是可供使用的数据集:
['CIFAR10', 'CIFAR100', 'Caltech101', 'Caltech256', 'CelebA']
['Cityscapes', 'CocoCaptions', 'CocoDetection', 'DatasetFolder', 'EMNIST']
['FakeData', 'FashionMNIST', 'Flickr30k', 'Flickr8k', 'HMDB51']
['ImageFolder', 'ImageNet', 'KMNIST', 'Kinetics400', 'LSUN']
['LSUNClass', 'MNIST', 'Omniglot', 'PhotoTour', 'Places365']
['QMNIST', 'SBDataset', 'SBU', 'SEMEION', 'STL10']
['SVHN', 'UCF101', 'USPS', 'VOCDetection', 'VOCSegmentation']
['VisionDataset']
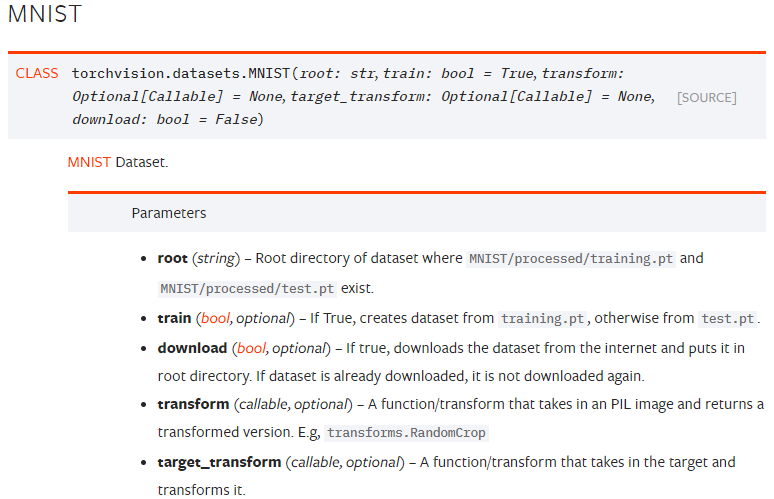
下图是 MNIST类 的文档说明
以加载MNIST为例,运行以下代码:
from torchvision import datasets, transforms
# 导入训练集
trainDataset = datasets.MNIST(root=r'./data',
transform=transforms.ToTensor(),
train=True,
download=True)
# 导入测试集
testDataset = datasets.MNIST(root=r'data',
transform=transforms.ToTensor(),
train=False,
download=True)
看看我们得到了什么,本质上看,我们得到的 trainDataset 和 testDataset 都是 torch.utils.data.Dataset 的子类,它俩最重要的特性是有__getitem__和__len__方法,这意味着它俩可以用 value[index]的方式访问内部元素(可以当作列表用)。
之所以提到这个是为 torch.utils.data.DataLoader 做准备。pytorch官方解释如下:
The most important argument ofDataLoaderconstructor isdataset, which indicates a dataset object to load data from. PyTorch supports two different types ofdataset:
*map-style datasets
*iterable-style datasets
我们得到的Dataset子类就是map-style datasets类型的。而iterable-style datasets类型最重要是包含了__iter__()方法,本质上是个迭代器,用next()访问内部元素的。
让我们实际输出这两个数据集一下看看我们得到了什么:
(1)
print("trainDataset 的类型:", type(trainDataset))
>>> trainDataset 的类型: <class 'torchvision.datasets.mnist.MNIST'>
(2)
print("trainDataset 的长度:", len(trainDataset))
>>> trainDataset 的长度: 60000
(3)
print("trainDataset[0] 的类型:", type(trainDataset[0]))
print("trainDataset[0] 的长度:", len(trainDataset[0]))
>>> trainDataset[0] 的类型: <class 'tuple'>
trainDataset[0] 的长度: 2
(4)
print("trainDataset[0][0] 的类型:", type(trainDataset[0][0]))
print("trainDataset[0][0] 的形状:", trainDataset[0][0].shape)
>>> trainDataset[0][0] 的类型: <class 'torch.Tensor'>
trainDataset[0][0] 的形状: torch.Size([1, 28, 28])
(5)
print("trainDataset[0][1] 的类型:", type(trainDataset[0][1]))
print("trainDataset[0][1] :", trainDataset[0][1])
>>> trainDataset[0][1] 的类型: <class 'int'>
trainDataset[0][1] : 5
总结一下就是我们的 trainDataset包含了60000个tuple,每个tuple第一项是一个形状为 [1,28,28] 的 Tensor,即样本值,第二项则是一个 int类型的标签值。
2. 自定义dataset类进行数据的读取以及初始化。
前文我们是把 torchvision 准备好的MNIST数据集拿来用了,那如何用只有图片和标签的 row data 构建与前文类似的 Dataset 呢?
- 自己定义的dataset类需要继承: Dataset
- 需要实现必要的魔法方法:
–__init__魔法方法里面进行读取数据文件
–__getitem__魔法方法进行支持下标访问
–__len__魔法方法返回自定义数据集的大小,方便后期遍历
**注:**自定义Dataset类只需要我们做到 1个父类继承,3个魔术方法。一般
__init__负责加载全部原始数据,初始化之类的。__getitem__负责按索引取出某个数据,并对该数据做预处理。但是对于如何加载原始数据以及如何预处理数据完全是由自己定义的,包括我们用dataset[index]取出的数据的组织形式都是完全自行定义的。
本文下面的示例代码有两个关键的函数:load_data()、load_data_wrapper()就体现出了这种自定义。原始数据是mnist.pkl.gz。load_data_wrapper()通过一系列操作返回了三个列表,每个列表都是包含了数个元组,元组又是由样本值和标签值构成的。这意味着我把样本组织为了元组的形式,那么这个 自定义Dataset类 每次也是返回这样的元组供模型使用。所以我们只是受限于1个父类继承,3个魔术方法。其他部分完全可以有我们自己根据需要来定义。
示例如下:
class MyDataset(Dataset):
def __init__(self, path, dataset_type="train", transform=None):
self.path = path
self.transform = transform
self.dataset_type = dataset_type
self.training_data, self.validation_data, self.test_data = self.load_data_wrapper()
def __getitem__(self, index):
if self.dataset_type == "test":
img, target = self.test_data[index][0], self.test_data[index][1]
if self.transform is not None:
img = self.transform(img)
target = self.transform(target)
elif self.dataset_type == "valid":
img, target = self.validation_data[index][0], self.validation_data[index][1]
if self.transform is not None:
img = self.transform(img)
target = self.transform(target)
else:
img, target = self.training_data[index][0], self.training_data[index][1]
if self.transform is not None:
img = self.transform(img)
target = self.transform(target)
return img, target
def __len__(self):
if self.dataset_type == "test":
return len(self.test_data)
elif self.dataset_type == "valid":
return len(self.validation_data)
else:
return len(self.training_data)
def load_data(self):
"""Return the MNIST data as a tuple containing the training data,
the validation data, and the test data.
The ``training_data`` is returned as a tuple with two entries.
The first entry contains the actual training images. This is a
numpy ndarray with 50,000 entries. Each entry is, in turn, a
numpy ndarray with 784 values, representing the 28 * 28 = 784
pixels in a single MNIST image.
The second entry in the ``training_data`` tuple is a numpy ndarray
containing 50,000 entries. Those entries are just the digit
values (0...9) for the corresponding images contained in the first
entry of the tuple.
The ``validation_data`` and ``test_data`` are similar, except
each contains only 10,000 images.
This is a nice data format, but for use in neural networks it's
helpful to modify the format of the ``training_data`` a little.
That's done in the wrapper function ``load_data_wrapper()``, see
below.
"""
f = gzip.open(self.path, 'rb')
training_data, validation_data, test_data = pickle.load(f, encoding='bytes')
f.close()
return training_data, validation_data, test_data
def load_data_wrapper(self):
"""Return a tuple containing ``(training_data, validation_data,
test_data)``. Based on ``load_data``, but the format is more
convenient for use in our implementation of neural networks.
In particular, ``training_data`` is a list containing 50,000
2-tuples ``(x, y)``. ``x`` is a 784-dimensional numpy.ndarray
containing the input image. ``y`` is a 10-dimensional
numpy.ndarray representing the unit vector corresponding to the
correct digit for ``x``.
``validation_data`` and ``test_data`` are lists containing 10,000
2-tuples ``(x, y)``. In each case, ``x`` is a 784-dimensional
numpy.ndarry containing the input image, and ``y`` is the
corresponding classification, i.e., the digit values (integers)
corresponding to ``x``.
Obviously, this means we're using slightly different formats for
the training data and the validation / test data. These formats
turn out to be the most convenient for use in our neural network
code."""
tr_d, va_d, te_d = self.load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [self.vectorized_result(y) for y in tr_d[1]]
training_data = list(zip(training_inputs, training_results))
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = list(zip(validation_inputs, va_d[1]))
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = list(zip(test_inputs, te_d[1]))
return training_data, validation_data, test_data
@staticmethod
def vectorized_result(j):
"""Return a 10-dimensional unit vector with a 1.0 in the jth
position and zeroes elsewhere. This is used to convert a digit
(0...9) into a corresponding desired output from the neural
network."""
e = np.zeros((10, 1))
e[j] = 1.0
return e
mytrainDataset = MyDataset(path=r'mnist.pkl.gz', transform=transforms.ToTensor())
print("trainDataset 的类型:", type(mytrainDataset))
print("trainDataset 的长度:", len(mytrainDataset))
print("trainDataset[0] 的类型:", type(mytrainDataset[0]))
print("trainDataset[0] 的长度:", len(mytrainDataset[0]))
print("trainDataset[0][0] 的类型:", type(mytrainDataset[0][0]))
print("trainDataset[0][0] 的形状:", mytrainDataset[0][0].shape)
print("trainDataset[0][1] 的类型:", type(mytrainDataset[0][1]))
print("trainDataset[0][1] :", mytrainDataset[0][1].shape)
输出为:
trainDataset 的类型: <class '__main__.MyDataset'>
trainDataset 的长度: 50000
trainDataset[0] 的类型: <class 'tuple'>
trainDataset[0] 的长度: 2
trainDataset[0][0] 的类型: <class 'torch.Tensor'>
trainDataset[0][0] 的形状: torch.Size([1, 784, 1])
trainDataset[0][1] 的类型: <class 'torch.Tensor'>
trainDataset[0][1] : torch.Size([1, 10, 1])
总结
用原始数据都造出来的 Dataset子类 其实就是一个静态的数据池,这个数据池支持我们用 索引 得到某个数据,想要让这个数据池流动起来,源源不断地输出 Batch 还需要下一个工具 DataLoader类 。所以我们把创建的 Dataset子类 当参数传入 即将构建的DataLoader类才是使用Dataset子类最终目。















 2798
2798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









