







 本文探讨了在Java中使用Stream API处理数据时,排序(sort)与去重(distinct)操作的顺序对结果的影响。通过示例代码展示了在不同顺序下执行sort和distinct操作可能导致结果不一致的情况,特别是在并行流(parallel)中。作者推测这可能是由于并行流缺乏稳定性导致去重失败,并指出在某些情况下,无序流或去除排序约束可以提高效率。博客还引用了官方文档关于并行流中distinct操作的说明,强调了保持稳定性的成本和可能的优化策略。
本文探讨了在Java中使用Stream API处理数据时,排序(sort)与去重(distinct)操作的顺序对结果的影响。通过示例代码展示了在不同顺序下执行sort和distinct操作可能导致结果不一致的情况,特别是在并行流(parallel)中。作者推测这可能是由于并行流缺乏稳定性导致去重失败,并指出在某些情况下,无序流或去除排序约束可以提高效率。博客还引用了官方文档关于并行流中distinct操作的说明,强调了保持稳定性的成本和可能的优化策略。
场景:某条记录,数据库里存储了N条记录,这些记录的特点是,除了ID和一个scanTime外,其他的字段都是一样的(定时生成一条记录,所以如果业务没改变的话字段都相同,主键区分记录,scanTime为当前时间),现在想要做的是,相同记录只要一个,并且返回时间最新的数据
问题:使用stream的sort和distinct先后顺序不同会导致结果不一致
Demo: 以下代码并没有主键的信息,id只是一个普通的字段
import lombok.Getter;
import lombok.Setter;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
@Setter
public class Event implements Comparable {
private String id;
private String name;
private String path;
private String scanTime;
@Override
public int compareTo(Object obj) {
if (obj instanceof Event) {
Event event = (Event) obj;
if (Long.parseLong(this.scanTime) <= Long.parseLong(event.scanTime)) {
return 1;
}
}
return -1;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null || getClass() != obj.getClass()) {
return false;
}
Event that = (Event) obj;
return Objects.equals(id, that.id) && Objects.equals(name, that.name)
&& Objects.equals(path, that.path);
}
@Override
public int hashCode() {
return Objects.hash(id, name, path);
}
private static List<Event> generateInput() {
int size = 20000;
List<Event> rtn = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
Event cur = new Event();
double v = Math.random() * 1000000000;
cur.setId("id" + i);
cur.setName("name");
cur.setPath("path");
cur.setScanTime(String.valueOf((int) v));
rtn.add(cur);
}
for (int i = 0; i < size; i++) {
Event cur = new Event();
double v = Math.random() * 1000000000;
cur.setId("id" + i);
cur.setName("name");
cur.setPath("path");
cur.setScanTime(String.valueOf((int) v));
rtn.add(cur);
}
for (int i = 0; i < size; i++) {
Event cur = new Event();
double v = Math.random() * 1000000000;
cur.setId("id" + i);
cur.setName("name");
cur.setPath("path");
cur.setScanTime(String.valueOf((int) v));
rtn.add(cur);
}
Collections.shuffle(rtn);
return rtn;
}
public static void main(String[] args) {
List<Event> events = generateInput();
// System.out.println("events = " + events);
for (int i = 0; i < 3; i++) {
List<Event> collect = events.stream()
.sorted()
.distinct()
.collect(Collectors.toList());
System.out.println( " num = " + collect.size());
// Collections.shuffle(events);
}
for (int i = 0; i < 3; i++) {
List<Event> collect = events.stream()
.sorted()
.parallel()
.distinct()
.collect(Collectors.toList());
System.out.println(" num = " + collect.size());
// Collections.shuffle(events);
}
for (int i = 0; i < 3; i++) {
List<Event> collect = events.stream()
.distinct()
.sorted()
.collect(Collectors.toList());
System.out.println(" num = " + collect.size());
// Collections.shuffle(events);
}
}
}
结果:这个59997每次可能不同,有时59998 59999 60000不等
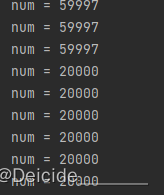
初步判断:sort并行流处理导致在distinct时去重失败,加parallel也只是为了归并上面处理的流后再进行去重处理,暂时没有证实
Preserving stability for distinct() in parallel pipelines is relatively expensive (requires that the operation act as a full barrier, with substantial buffering overhead), and stability is often not needed. Using an unordered stream source (such as generate(Supplier)) or removing the ordering constraint with BaseStream.unordered() may result in significantly more efficient execution for distinct() in parallel pipelines, if the semantics of your situation permit.
所以是sort后dinstinct 没有barrier ,sort后的流也不是distinct 想要的order,➕了parallel 后直接自动加barrier ,就像硬上了一个锁一样,其实这样效率挺差的

















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









