







JVM之字节码文件
文章目录
1.字节码文件的数据类型
字节码文件拥有两种类型:
- 字节数据直接量:这是最基本的数据类型、共细分为u1,u2,u4,u8分别代表1字节、2字节、4字节、8字节
- 表类型,它是由基本数据类型或者其他表构成,它是一个复合类型
2.字节码文件的基本结构
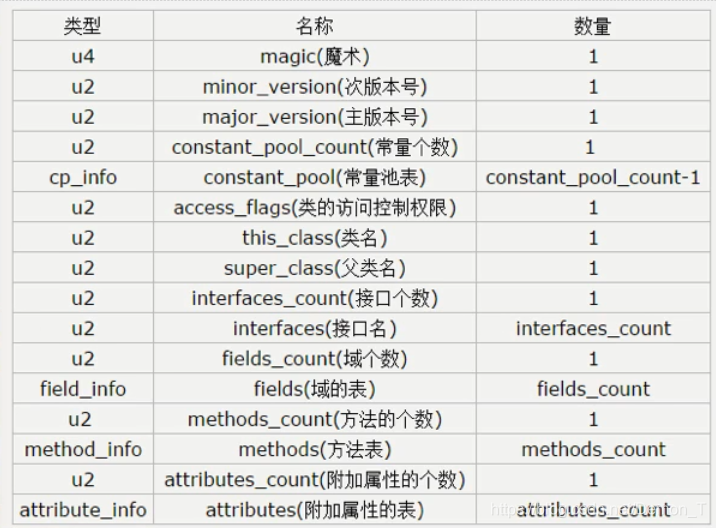
使用javap-verbose分析一个字节码文件时,一个字节码文件包括魔数、版本号、常量池、类信息、类的构造方法、累的方法信息、类变量与成员变量等信息。字节码文件的结构如下图所示 :
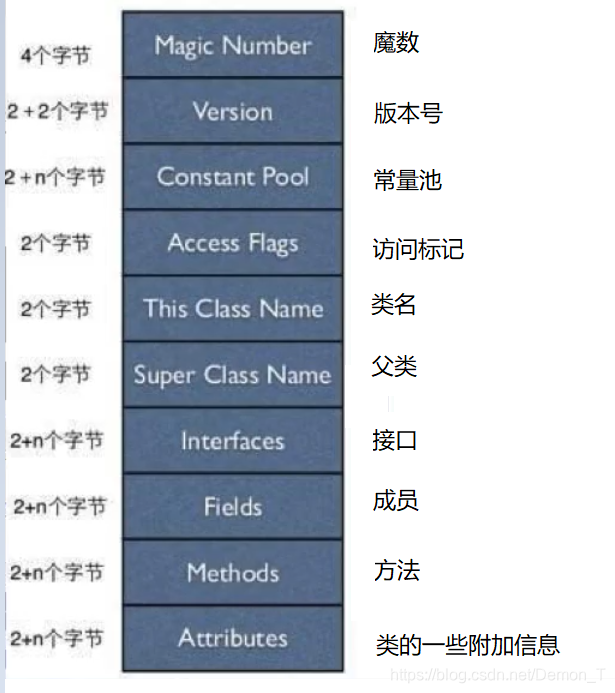
魔数: 在Java字节码文件中,前面的四个字节被称为魔数,魔数的值都固定为CAFEBABE,这可以理解成魔数是一个java字节码文件的一个和法标志,如果一个字节码文件的魔数不为CAFEBABE,那它就不是一个合法的字节码文件,当然如果一个字节码文件的魔数符合标准,也不一定就是合法的字节码文件,比如我用UE打开一个字节码文件,然后除了魔数以外的二进制信息乱改一气,这样被我胡改的字节码文件,虽然魔数正确,但是肯定不是合法的,面对非法的字节码文件,JVM是不会加载的。
版本号: 魔数的后四个字节为版本号,前两个字节叫做 minor version(次版本号),后面两个字节叫做 major version (主版本号)。加载字节码文件的版本号为00 00 00 34,那么次版本号为0,主版本号为52,所以该文件的版本为1.8.0
可以通过java -version命令来证明这一点。
 其中1.8是主版本号,0是次版本号,_181是更新号。
其中1.8是主版本号,0是次版本号,_181是更新号。
常量池:
紧接着版本号的字节即从第9个字节开始就是常量池的入口,一个Java类中定义的很多信息都是由常量池保存和维护的,我们可以把常量池理解为一个.class文件的资源仓库,比如Java类中定义的方法与成员的信息,都是存储在常量池中。
常量池中主要存储两类常量:
- 字面量 :字面量如文本字符串,Java中声 明为fina1的常量值
- 符号引用:而符号引用如类和接口的全局限定名,字段的名称和描述符,方法的名称和描述符等。
常量池的总体结构
Java类所对应的常量池由两部分组成
-
常量池数量
紧接着版本号的后两个字节(即第9和第10字节),由于不同的字节码文件的常量池大小是不固定的,所以要有常量池数量这个值。
需要注意的一点是,常量池中的元素个数 = 常量池数量 - 1,因为目的是满足某些常量池索引值的数据在特定情况下需要表达 [ 不引用任何一个常量 ]的含义;根本原因在于,索引为0也是一个常量(保留常量),只不过它不位于常量表中,这个常量就对应nu11值;所以,常量池的索引从1而非0开始。 -
常量池数组(常量表):
常量池数组的结构和一般我们认知的数组是不同的。它的每个元素的类型和结构可以是不同的,所以每个元素的字节长度也是不同的。但是每个元素的第一个字节都是一个u1类型,该字节是个标志位,JVM在解析常量池时,会根据这个u1类型来获取元素的具体类型
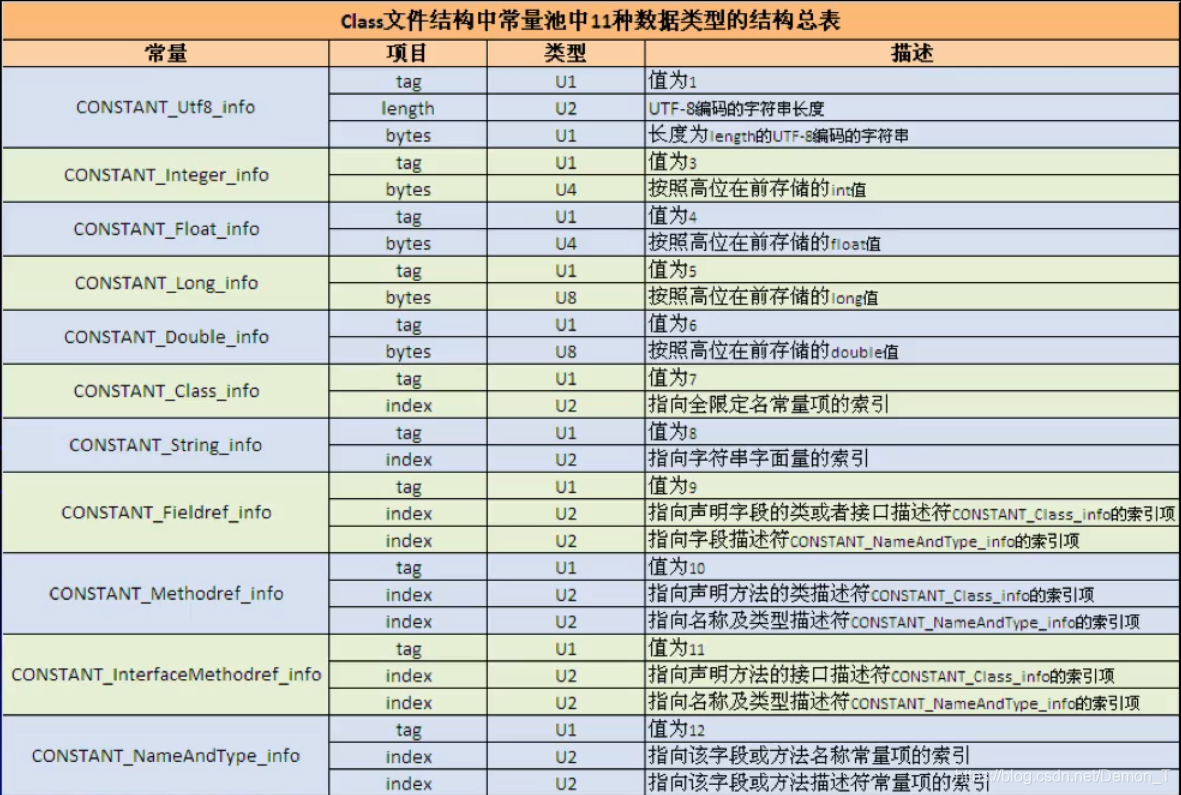 注: 上表中有11中常量池结构,JDK1.7之后扩展到了14个,都与动态代码有关,这里不与说明。
注: 上表中有11中常量池结构,JDK1.7之后扩展到了14个,都与动态代码有关,这里不与说明。
常量池中的描述信息
-
在JVM规范中,每个成员变量和方法都有相对应的描述信息
成员的描述信息:描述该成员的类型
方法的描述信息:描述方法的参数列表(数量、类型、数据)和返回值类型 -
描述符
2.1 八大基本类型以及void类型都使用一个大写字母来表示
B-byte,C-char,D-double,F-float,I-int,J-long,S-short,z-boolean,V-void2.2 对象类型用大写字母L + 类的全限定名来表示(全限定名中的 . 要替换成 / )。
比如String类型就可以表示成 Ljava/lang/String;2.3 对于数组类型来说用一个前置的 [ 和数组元素类型来表示
比如 int[ ] 就可以描述成 [ I ,String[ ][ ]可以描述成 [ [ java/lang/String;2.4 对于方法的描述符,(参数类型) + 返回值类型
比如 String getRealnamebyIdAndNickname(int id, String name)的描述符为: (I, Ljava/lang/String;) Ljava/lang/String;可能大家觉的描述符很怪,但是我们要我们要明白,描述符不是给人看的,而是给电脑看的,所以在可读性方面就差一些,这样描述有一个好处,可以尽量的减少字节码文件的大小。
访问标志
访问标志信息是常量池之后的两个字节,它代表一个类是不是public、或者是不是abstract或者final等修饰信息。字节码文件中存储这两个字节会映射到一张表上去。比如 0x0021,就代表这个类是ACC_PUBLIC、ACC_SUPER,这个两字节的十六进制值,是多个值的并集,即或运算的结果,因为一个类既可以是public也可以是abstract
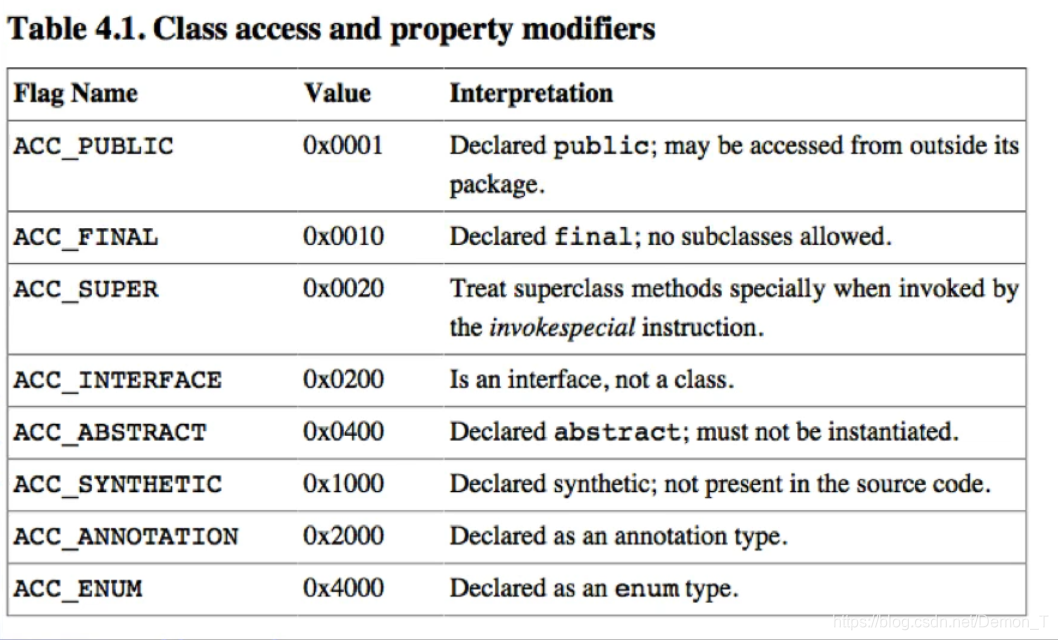 注: 这张访问标志表并不全
注: 这张访问标志表并不全
类名称
访问标记之后的两个字节,用来索引常量池中的类的全限定名
父类名称
类名称之后的两个字节,用来索引常量池中的父类的全限定名
成员变量
成员变量数量:接口之后的两个字节
成员变量数组:该数组中的每一个元素,都遵循一个成员变量结构
 access_flags: 两个字节,表示一个成员变量的权限
access_flags: 两个字节,表示一个成员变量的权限
name_index:两个字节, 表示一个索引值,可以在常量池中找到对应的成员变量名称
descriptor_index:两个字节, 表示一个索引值,可以在常量池中找到对应的成员变量的描述符。
attributes_count: 该成员存储的附加属性数组的元素数量
attributes:成员存储的附加属性数组
方法
方法比较复杂
方法的总体结构和方法的结构几乎一致
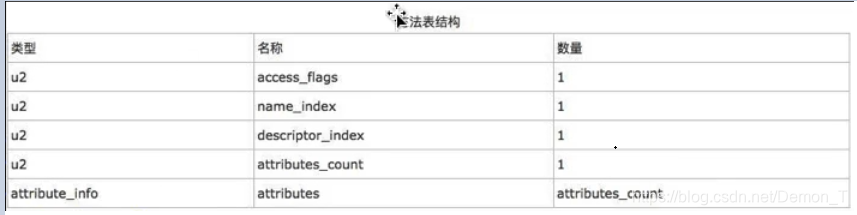
跟字段不一样的是每个方法基本都有一个Code属性
不同的属性由attribute_name_index来区分
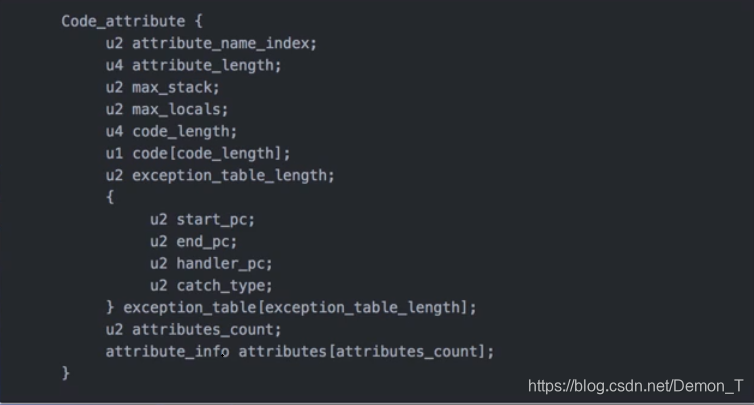 max_statck: 代表了操作数栈的深度的最大值,在方法执行的任意时刻,操作数栈都不会超过这个深度,虚拟机运行时需要根据这个值来分配栈帧(stack Frame)中的操作栈深度
max_statck: 代表了操作数栈的深度的最大值,在方法执行的任意时刻,操作数栈都不会超过这个深度,虚拟机运行时需要根据这个值来分配栈帧(stack Frame)中的操作栈深度
max_locals: 代表了局部变量所需的存储空间。在这里max_locals的单位是Slot是虚拟机为局部变量分配内存所使用的的最小单位,不超过4字节的局部变量占用1个Slot,像double和long这样的栈占8字节的类型占2个Slot。
codeLength和code[codeLength]对应的是字节码指令的长度和字节码指令
code属性一般有三个
| 属性名称 | 含义 |
|---|---|
| LineNumberTable | Java源码的行号和字节码指令的对应关系 |
| LocalVariableTable | 方法的局部变量描述 |
| stackMapTable | JDK1.6中的新增属性,供新的类型检查验证器(Type Checker)检查和处理目标方法的局部变量和操作数栈所需要的类型是否匹配 |
LineNumberTable的结构
| 类型 | 名称 | 数量及说明 |
|---|---|---|
| u2 | attribute_name_index | 1 |
| u4 | attribute_length | 1 |
| u2 | line_number_table_length | 1 |
| line_number_info | line_number_table | line_number_table_length |
line_number_table 包含了start_pc和line_number两个u2类型的数据项
LocalVariableTable属性
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | atrrribute_name_index | 1 |
| u4 | attribute_length | 1 |
| u2 | local_variable_table_length | 1 |
| local_variable_info | local_variable_table | local_variable_table_length |
local_variable_info结构
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | start_pc | 1 |
| u2 | length | 1 |
| u2 | name_index | 1 |
| u2 | descriptor_index | 1 |
| u2 | idnex | 1 |
statt_pc 和 length属性分别代表了这个局部变量的生命周期开始的字节码偏移量以及长度,两者结合起来就决定了这个局部变量在这个字节码文件中的而作用域。
name_index和descriptor_index都是常量池中的索引
index是这个局部变量在栈帧局部变量表中的Slot位置
除了code属性之外还有很多属性,还有一个属性比较常用------SourceFile属性
SourceFile属性结构
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | atrribute_name_index | 1 |
| u4 | atribute_length | 1 |
| u2 | sourceFile_index | 1 |
通过sourceFile_index就可以在常量池中索引到相关的源文件名
总体来说简单的字节码文件都可以用以上的套路来看
3.字节码中的< init >和< cinit >
< init >就是常量池中构造方法的名字
//这个程序简单的应该不用我多少了
package com.mec.aboutByteSFile;
public class MyTest1 {
private int a = 1;
public int getA() {
return a;
}
public void setA(int a) {
this.a = a;
}
}
我们主要目的是看一下反编译的结果
//这仅仅是构造方法的反编译结果
/*
首先,在源代码中我们必过没有书写构造方法,也就是说在字节码层面,会自动生成一个无参构造方法,主要看code属性里的内容。 args_size=1 都无惨构造了怎么还有一个参数,其这一个参数是this,只不过是在字节码层面的,这也是我们可以在在构造方法中调用this的原因。
而且在这个构造方中该会对局部变量a进行赋值
6: putfield #12 // Field a:I
也就是说,对局部变量赋值的字节码语句本质在构造方法中的字节码中
*/
public com.mec.aboutByteSFile.MyTest1();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: invokespecial #10 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_1
6: putfield #12 // Field a:I
9: return
LineNumberTable:
line 3: 0
line 4: 4
line 3: 9
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this Lcom/mec/aboutByteSFile/MyTest1;
< cinit > 如果有静态成员,常量池中就出现了一个名字为< cinit >的方法名
我们对上面的程序做一下改动增加一个静态成员
package com.mec.aboutByteSFile;
public class MyTest1 {
private int a = 1;
private static int b = 3;
public int getA() {
return a;
}
public void setA(int a) {
this.a = a;
}
}
//code属性中 1: putstatic #11 // Field b:I
//对静态成员进行了赋值,其实不仅是静态成员的赋值,静态块中的代码在字节码文件中也在其中。(这里就不了)
static {};
descriptor: ()V
flags: ACC_STATIC
Code:
stack=1, locals=0, args_size=0
0: iconst_3
1: putstatic #11 // Field b:I
4: return
LineNumberTable:
line 5: 0
LocalVariableTable:
Start Length Slot Name Signature
4.字节码层面的异常处理机制及局部变量
4.1java异常处理机制:
- 统一采用异常表的方式进行异常处理
- 在JDK 1.4.2之前并不是采用异常表来处理异常的,而是采用特定的指令方式
- 当一个程序中有finally关键字时,现代的JVM会将finally语句块的字节码追加到catch字节码内容的后面,换句话说程序中每一个catch字节码块后面都有重复的一个finally代码块的字节码。
异常表如下所示:
| 起始下标和长度 | 目标下标 | 异常类型 |
|---|---|---|
| 这两部分可以得到try所对应的代码块的助记符的起始与长度 | catch代码段对应的助记符位置 | 异常类型,如果是any那就代表除了已知异常类型的其他异常类型 |
举个例子
package com.mec.aboutByteSFile;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
public class MyTest2 {
public void test() {
try {
InputStream in = new FileInputStream("wo ai wei yi ma");
ServerSocket socket = new ServerSocket(54188);
socket.accept();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
System.out.println("hello");
}
}
}
将这个代码进行Javap - verbose进行反编译,下图是test方法的异常表和助记符

 就拿异常表的第一行来说吧
就拿异常表的第一行来说吧
from 0 to18 :这里的0 ~ 25包括0,不包括25,就是0到24
0到24意思是如果这部分的字节码出了异常会从target :28开始执行,也就是执行catch中的内容
除了try catch处理异常还有一种方式叫做 throws。
抛出去的异常会记录在与code属性平级的Exceptions属性中
package com.mec.aboutByteSFile;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
public class MyTest2{
public void test() throws FileNotFoundException {
try {
InputStream in = new FileInputStream("wo ai wei yi ma");
ServerSocket socket = new ServerSocket(54188);
socket.accept();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
System.out.println("hello");
}
}
}

4.2局部变量表
package com.mec.aboutByteSFile;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
public class MyTest2 {
public void test() {
try {
InputStream in = new FileInputStream("wo ai wei yi ma");
ServerSocket socket = new ServerSocket(54188);
socket.accept();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
System.out.println("hello");
}
}
}
 这是test方法的局部变量表,我们从源码可以看出,我们只有4个局部变量,为什么局部变量表中还多了一个,因为所有的实例方法(非静态方法)都会在编译阶段在字节码层面怎加了一个在源码层面不可见的参数----this,并在运行阶段给它赋值,构造方法也是如此,所以这也可以从字节码层面来说明为什么实例方法中可以使用this。
这是test方法的局部变量表,我们从源码可以看出,我们只有4个局部变量,为什么局部变量表中还多了一个,因为所有的实例方法(非静态方法)都会在编译阶段在字节码层面怎加了一个在源码层面不可见的参数----this,并在运行阶段给它赋值,构造方法也是如此,所以这也可以从字节码层面来说明为什么实例方法中可以使用this。
5.栈帧(stack Frame)
栈帧是一种帮助虚拟机进行方法的执行和方法调用的一种数据结构
它包含方法的局部变量表、动态链接、返回地址、操作数栈等信息
每一个方法从调用开始到执行完成的过程,就对应着一个栈帧在虚拟机栈里面从入栈到出栈的过程。
符号引用和局部i引用
部分符号引用在类加载阶段就被转换成直接引用,这个过程叫做静态解析,也有部分符号引用会在运行过程中,当使用到该方法时,才将符号引用变为直接引用,这个过程叫做动态链接。
静态解析的四种场景:
- 静态方法
- 构造方法
- 父类方法
- 私有方法(不能被重载,不存在多态)
6.分派
关于方法的调用有五种字节码指令
| 字节码指令 | 功能 |
|---|---|
| invokeinterface | 调用接口中的方法,实际是运行期决定的,在运行期间确定到底调用该接口哪一个对象的特定方法 |
| invokestatic | 调用静态方法 |
| invokespecial | 调用自己的私有方法、构造方法、以及父类方法 |
| invokevirtual | 调用虚方法,运行期间动态查找的过程 |
| invokedynamic | 动态调用方法 |
6.1 方法的重载(静态分派)
package com.mec.aboutByteSFile;
/**
* 关于方法的静态分派
* 对于 GrandPa g1 = new Father();
* GrandPa是g1的静态类型,而g1的实际类型(真正指向的类型)为Father
*有这样一个结论,变量的静态类型不会发生变化,而变量的实际类型会发生变化(这也是Java多态的一种体现),
*一个变量的实际类型会在程序运行期间确定
*/
public class MyTest3 {
//方法的重载是一种静态行为,也就是说参数的类型是在编译期间确定的
//再说直白点,方法重载的参数类型看的是静态类型,静态类型决定使用哪一个版本的重载
public void test(GrandPa grandPa) {
System.out.println("grandPa");
}
public void test(Father father) {
System.out.println("father");
}
public void test(Son son) {
System.out.println("son");
}
public static void main(String[] args) {
GrandPa g1 = new Father();
GrandPa g2 = new Son();
MyTest3 myTest3 = new MyTest3();
myTest3.test(g1);
myTest3.test(g2);
}
}
class GrandPa {
}
class Father extends GrandPa{
}
class Son extends Father{
}
运行结果:

6.2方法的重写(动态分配)
invokevirtual在运行时大致分为以下步骤:
1.找到操作数栈栈顶的第一个元素所指向的实际类型,记作C
2.如果在C中找到了与常量池中描述符和简单名称都符合的方法,找到后检查方法权限,返回它的直接引用,查找结束,如果不通过则返回java,lang.IllegalAccessError异常
3.否则根据上下级关系,依次对C的的父类,进行第二步
4.如果还没找到就抛出java.lang.AbstractMethodError异常
package com.mec.aboutByteSFile;
/**
* 方法的动态分派
* 是否为方法的动态分派主要看方法的接收者
* 比如f1.test(); text方法的方法接受者就为f1
* 方法的重载的静态的,是编译期行为,方法的重写是动态的,试运行期行为。
*/
public class MyTest4 {
public static void main(String[] args) {
Frult f1 = new Apple();
Frult f2 = new Orange();
f1.test();
f2.test();
f1.test();
}
}
class Frult {
public void a() {
test();
}
public void test() {
System.out.println("frult");
}
}
class Apple extends Frult{
@Override
public void test() {
System.out.println("apple");
}
}
class Orange extends Frult{
@Override
public void test() {
System.out.println("orange");
}
}
运行结果:
 我们将看一下上述程序的字节码
我们将看一下上述程序的字节码
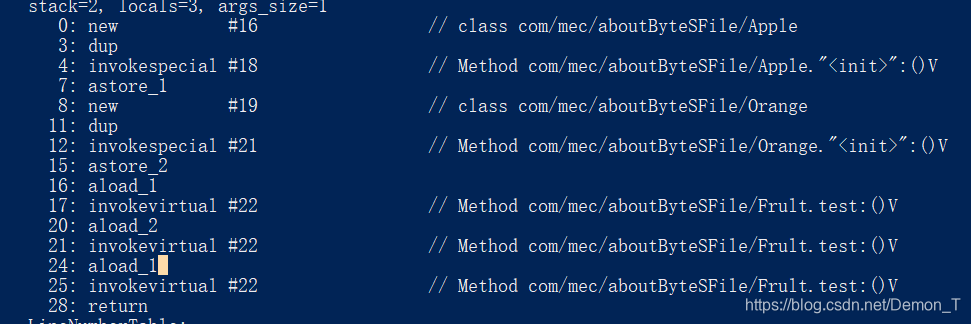
重点看一下
invokevirtual #22 // Method com/mec/aboutByteSFile/Frult.test:()V
不管是调用哪个方法,在编译阶段我们只能知道该方法所属的静态类型类
这里有一个结论:相同的符号引用,在运行过程中转换为直接引用时得到的结果可能是不同的。
接下来大家看另一个例子
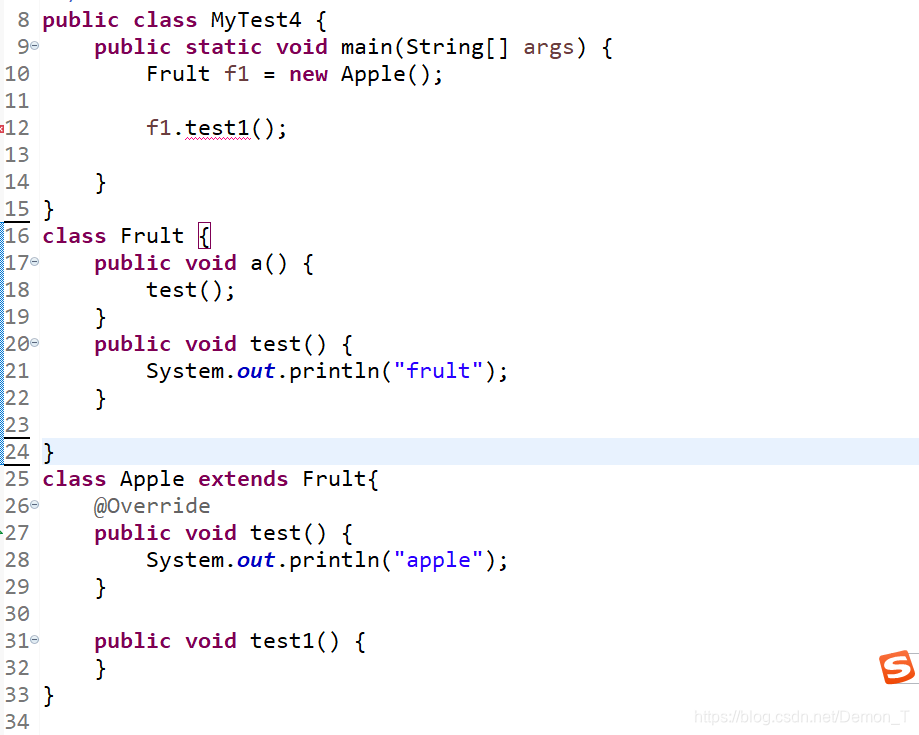 编译都通不过,我相信这个例子在初学java时都会遇到,我们抛开Java的语法规范在字节码层面分析一下,为什么程序连编译阶段都通过不了。
编译都通不过,我相信这个例子在初学java时都会遇到,我们抛开Java的语法规范在字节码层面分析一下,为什么程序连编译阶段都通过不了。
原因是在字节码层面,调用test1方法时,会调用invokevirtual指令,按理来说该指令的参数应该为 Method com/mec/aboutByteSFile/Frult.test1:()V
这就发生了问题Frult类中并没有test1方法,所以连编译都通过不了。
我们知道动态分派是在程序运行时进行的,为了挺高程序运行的效率,所以Jvm会在类的方法区建立一张虚方法表的的数据结构。这张表储存着每个虚方法的入口地址,假设A类继承了B类,但是A类并没有重写B类的test方法,但是A类也是可以调用test方法的,因为存在继承关系,B类会拥有test方法的入口地址,A类并不是把test方法的相关信息复制一份放在自己的虚方法表中,而是A类直接拥有B类表中的入口地址。
比如Object类时所有类的父类,也就是说每一个类在不重写Object类中的方法的情况下,都会直接的拥有Object类中的所有可用方法的入口地址
当然如果A重写B类中的test方法,那么在A的虚表中就会有重写的这个方法的入口地址
7.指令集
Java编译请输出的指令流,基本上是一种基于栈的指令集架构,与之相对应的另一套常用的指令集是基于寄存器的指令集。
我们具体说一下基于栈的指令集和基于寄存器的区别
举个例子我们用两套指令集来计算 2 -1
- 基于栈的指令集:
iconst_1 //将操作数1入栈
iconst_2 //将操作数2入栈
isub //将 2 出栈 再将1出栈,进行减法操作,计算出结果,将结果放回栈顶
istore_0//将栈顶的值放回到局部变量表的第0个Slot中。
- 基于寄存器等的指令集
mov eax 2 //将操作数2放入到寄存器exa中
sub eax 1 //将寄存器eax中的值取出来减1,将结果放回eax中
从上面的这个例子,我们可以得出第一个结论:
如果执行同样的操作,基于栈的指令集执行的代码行数要多于基于寄存器的指令集,虽然由有相关的优化操作,但是基于栈的指令集总体的执行效率要比基于寄存器的指令集的效率低一些
我们再看看两者其他的区别:
基于栈的指令集,基于栈的操作,会经常的进行入栈与出栈,这些都是在内存中进行的,所以相对于CPU执行效率慢一些,但是它最大的优点是可移植,寄存器右硬件提供,基于寄存器的指令集难免要遇到硬件差异,如果使用基于栈的指令集,不会直接使用寄存器。
关于基于栈的操作集的优化
虚拟机会自行将一些访问最频繁的数据放到寄存器中来保证性能


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









