







requests 的安装
如果本地 Python 环境没有安装 requests,可以在
命令提示符窗口输入命令
pip install requests,安装 requests 模块,如下图所示。
requests 的常用方法
requests 可以用来模拟浏览器请求,下面介绍实现方法。以 GET 请求为例,实现代码如下所示:
res = requests.get(url, params=params, headers=headers)
参数说明:
- url :需要抓取的 URL 地址;
- params : 网址带参请求的方法,字典类型;
- headers : 请求头。
以百度搜索为例,现在有这样一个网址https://www.baidu.com/s?wd=requests,由主要网址 https://www.baidu.com/s 和参数 wd 组成,需要发起 GET 请求,方法有两种。 方法一:
import requests # 导包
url = 'https://www.baidu.com/s?wd=requests'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
response = requests.get(url, headers=header) #模拟 get 请求
response.encoding = 'utf-8' # 指定编码
print(response.text) # 打印网页信息文本
方法二:
import requests # 导包
url = 'https://www.baidu.com/s'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
params = {'wd': 'requests'} # 定义参数
response = requests.get(url, params=params, headers=header) #模拟 get 请求
response.encoding = 'utf-8' # 指定编码
print(response.text) # 打印网页信息文本
以上两种方法,都可以得到同一个网页的信息。可以看出,与 urllib 相比,requests 代码更加简洁。
上述代码还用到了响应对象(response)的属性,比如response.encoding和response.text,响应对象还有一些其它属性:
- encoding :响应字符编码 res.encoding = ‘utf-8’;
- text :字符串,网站源码;
- content :字节流,字符串网站源码;
- status_code :HTTP 响应码;
- url :实际数据的 URL 地址。
接下来演示一下 POST 请求,代码同样非常简洁,实现代码如下所示:
res = requests.post(url, data=data, headers=headers)
参数说明:
- url :需要抓取的 URL 地址;
- data : 提交常见的 form 表单的方法,字典类型;
- headers : 请求头。
以豆瓣登录为例,登录网址为https://www.douban.com/,但这只是登录页面网址。为了找到真正的登录网址,需要打开开发者工具,然后在网页上实际进行登录操作,在Network项目下,选中文件basic,可以得到 post 请求的网址为https://accounts.douban.com/j/mobile/login/basic,如下图所示: 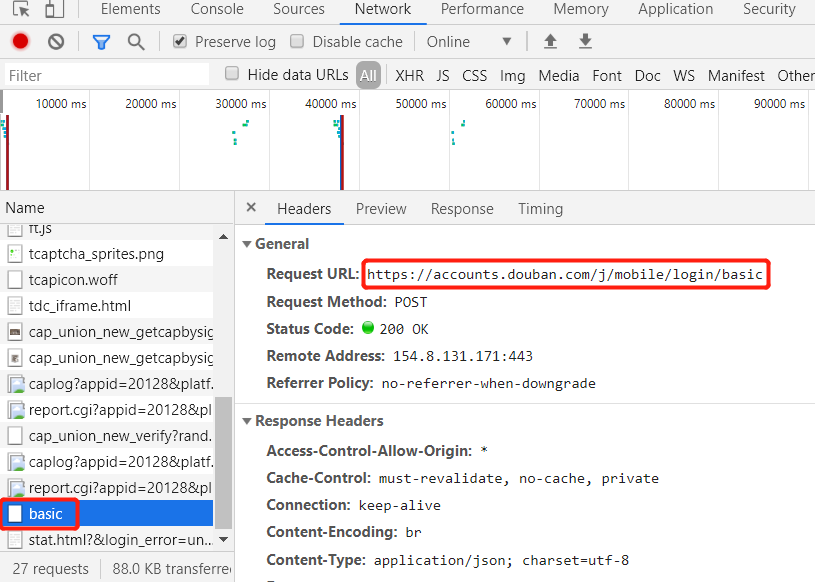 如果将上图的页面往下拉,可以看到 data 参数为:
如果将上图的页面往下拉,可以看到 data 参数为: 
以下代码演示了模拟登录的 POST 请求:
import requests # 导包
# 模拟请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
# 定义 data 信息
data = {
"name": "账号",
"password": "密码",
}
url = "https://accounts.douban.com/j/mobile/login/basic"
response = requests.post(url=url, headers=header, data=data) # 模拟登录请求
response.encoding = "utf-8" # 定义编码
html_content = response.text
print(html_content) # 打印网页信息
例如:
import requests
def get_html(url):
'''
两个参数
:param url:统一资源定位符,请求网址
:param headers:请求头
:return:html
'''
# ***************** Begin ******************** #
# 补充请求头
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
# get请求网页
response=requests.get(url=url,headers=headers)
response.encoding='utf-8'
html=response.text
# 获取网页信息文本
# ***************** End ******************** #
return html
requests进阶
cookie的使用
当你浏览某网站时,Web 服务器会修改修改你电脑上的 Cookies 文件,它是一个非常小的文本文件,可以记录你的用户 ID 、密码、浏览过的网页、停留的时间等信息。 当你再次来到该网站时,网站通过读取 Cookies 文件,得知你的相关信息,从而做出相应的动作,如在页面显示欢迎你的标语,或者让你不用输入 ID、密码就直接登录等等。
下面演示如何在 requests 中使用 Cookies, 以百度搜索为例,在开发者工具查看请求头信息如下:
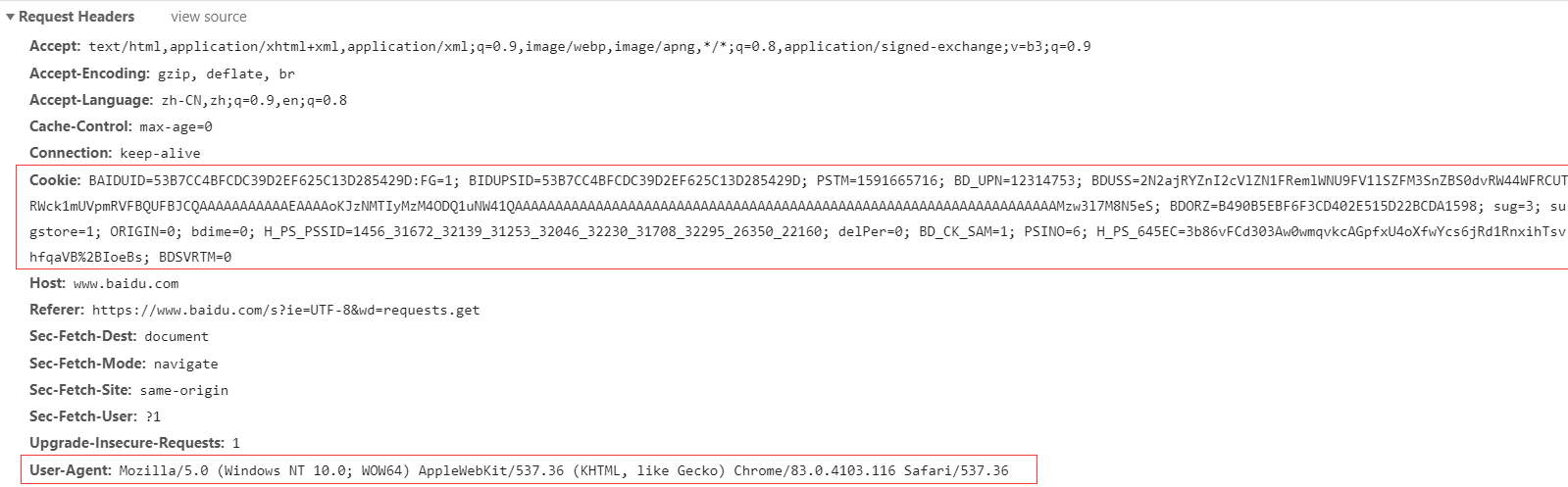
方法一 将得到的 Cookies 信息写入请求头,模拟 GET 请求:
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36',
"Cookie": "BAIDUID=53B7CC4BFCDC39D2EF625C13D285429D:FG=1; BIDUPSID=53B7CC4BFCDC39D2EF625C13D285429D; "
"PSTM=1591665716; BD_UPN=12314753; BDUSS=2N2ajRYZnI2cVlZN1FRemlWNU9FV1lSZFM3SnZBS0dvRW44WFRCUTRWck1mUVpmR"
"VFBQUFBJCQAAAAAAAAAAAEAAAAoKJzNMTIyMzM4ODQ1uNW41QAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
"AAAAAAAAAAAAMzw3l7M8N5eS; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; sug=3; sugstore=1; ORIGIN=0; bdime=0; "
"H_PS_PSSID=1456_31672_32139_31253_32046_32230_31708_32295_26350_22160; delPer=0; BD_CK_SAM=1; PSINO=6; "
"H_PS_645EC=3b86vFCd303Aw0wmqvkcAGpfxU4oXfwYcs6jRd1RnxihTsvhfqaVB%2BIoeBs; BDSVRTM=0"
}
response = requests.get(url=url, headers=header)
方法二(不推荐) 也可将 cookie 写成字典的形式,传入请求方法中:
cookies = {"BAIDUID": "53B7CC4BFCDC39D2EF625C13D285429D:FG=1", "BIDUPSID": "53B7CC4BFCDC39D2EF625C13D285429D",
"PSTM": "1591665716", "BD_UPN": "12314753", "sug": "3", "sugstore": "1", "ORIGIN": "0", "bdime": "0",
"H_PS_PSSID": "1456_31672_32139_31253_32046_32230_31708_32295_26350_22160", "delPer": "0", " BD_CK_SAM": "1",
"PSINO": "6", "H_PS_645EC": "3b86vFCd303Aw0wmqvkcAGpfxU4oXfwYcs6jRd1RnxihTsvhfqaVB%2BIoeBs", "BDSVRTM": "0",
"BDUSS": "2N2ajRYZnI2cVlZN1FRemlWNU9FV1lSZFM3SnZBS0dvRW44WFRCUTRWck1mUVpmRVFBQUFBJCQ"
"AAAAAAAAAAAEAAAAoKJzNMTIyMzM4ODQ1uNW41QAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAMzw3l7M8N5eS; BDORZ=B490B5EBF6F3CD402E515D"
"22BCDA1598",
}
response = requests.get(url=url, headers=header, cookies=cookies)
session 的使用
http 协议是无状态的,也就是每个请求都是独立的。那么登录后的一系列动作,都需要用 cookie 来验证身份是否是登录状态,为了高效的管理会话,保持会话,于是就有了 session 。 session 是一种管理用户状态和信息的机制,与 cookies 的不同的是,session 的数据是保存在服务器端。说的明白点就是 session 相当于一个虚拟的浏览器,在这个浏览器上处于一种保持登录的状态。
下面演示如何在 requests 中使用 session。 创建会话的代码如下:
sess = requests.session()
使用会话发出请求提交表单的代码如下:
data = {
"name": "XXXXX",
"password": "XXXXX",
}
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
response = sess.post(url, headers=header, data=data)
登录成功后,会话会生成 cookie 以及请求头,再次访问网站,直接发出请求即可,代码如下:
response_home = sess.get(url=url)
例如:
def get_html(url):
'''
两个参数
:param url:统一资源定位符,请求网址
:param headers:请求头
:return html 网页的源码
:return sess 创建的会话
'''
# ***************** Begin ******************** #
sess = requests.session()
data = {
"name": "XXXXX",
"password": "XXXXX",
}
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
response = sess.post(url,headers=header,data=data)
html = sess.get(url=url).text
# ****************** End ********************* #
return html, sess
















 2958
2958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











