







中国大学MOOC 如何抓包和进行采集
目标网站
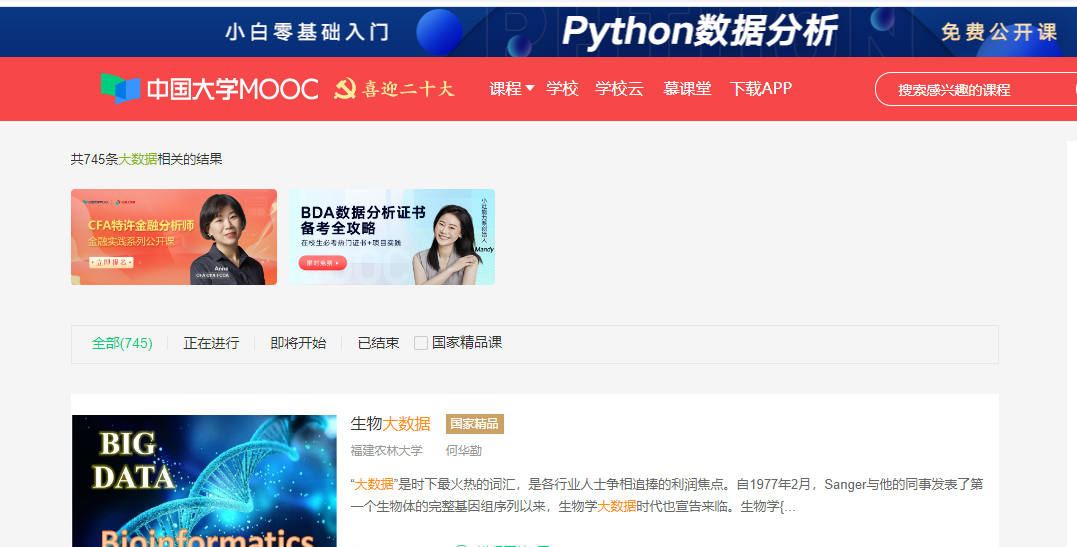
网站
https://www.icourse163.org/
由于这次爬取的是json的数据接口爬取,要抓包,还有为了响应数据,要登录自己的账号,用自己的cookie让服务器识别不是其它非法请求
抓包
按f12快捷键打开网络调试控制台,或者在网页点击鼠标右键弹出
后面点击检查 进入网络调试控制台,这个是在谷歌浏览器打开的,其它浏览器不一样,不过原理一样的
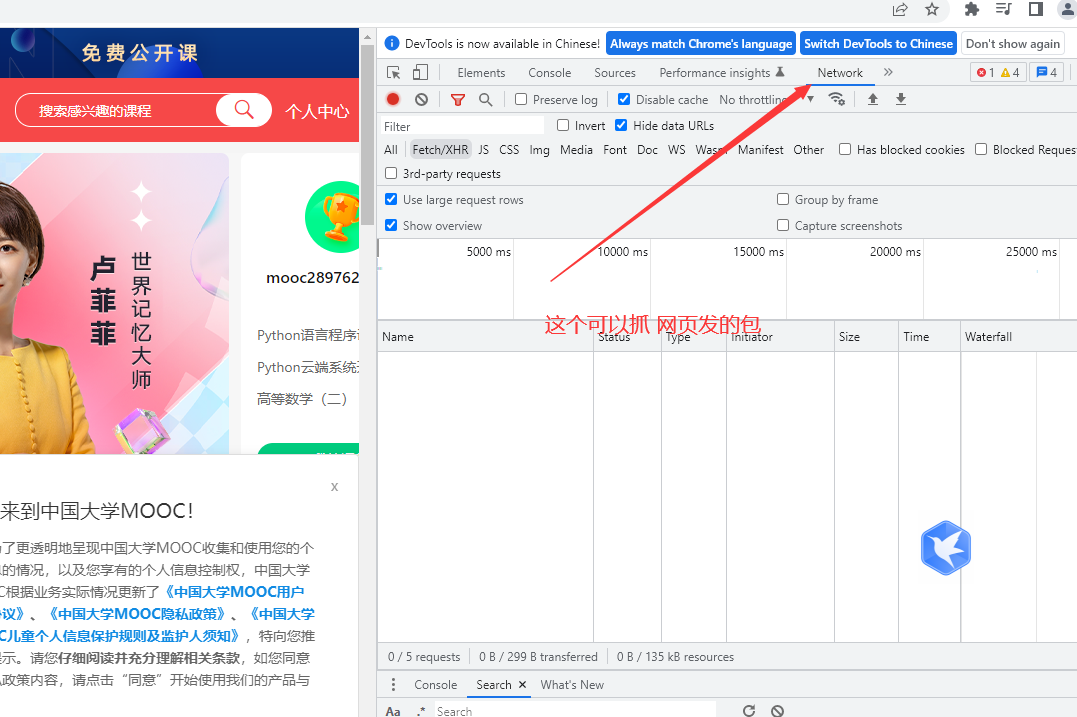
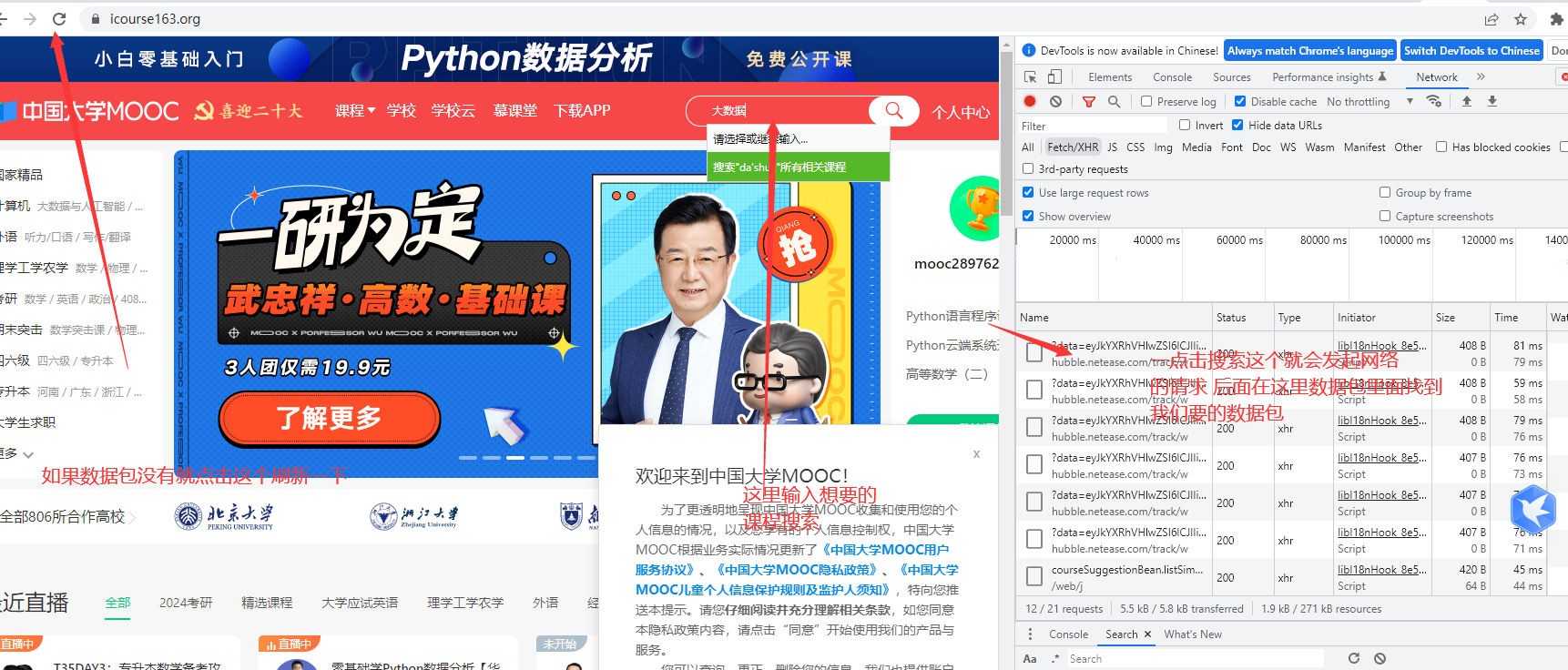
后面跳转到这个页面
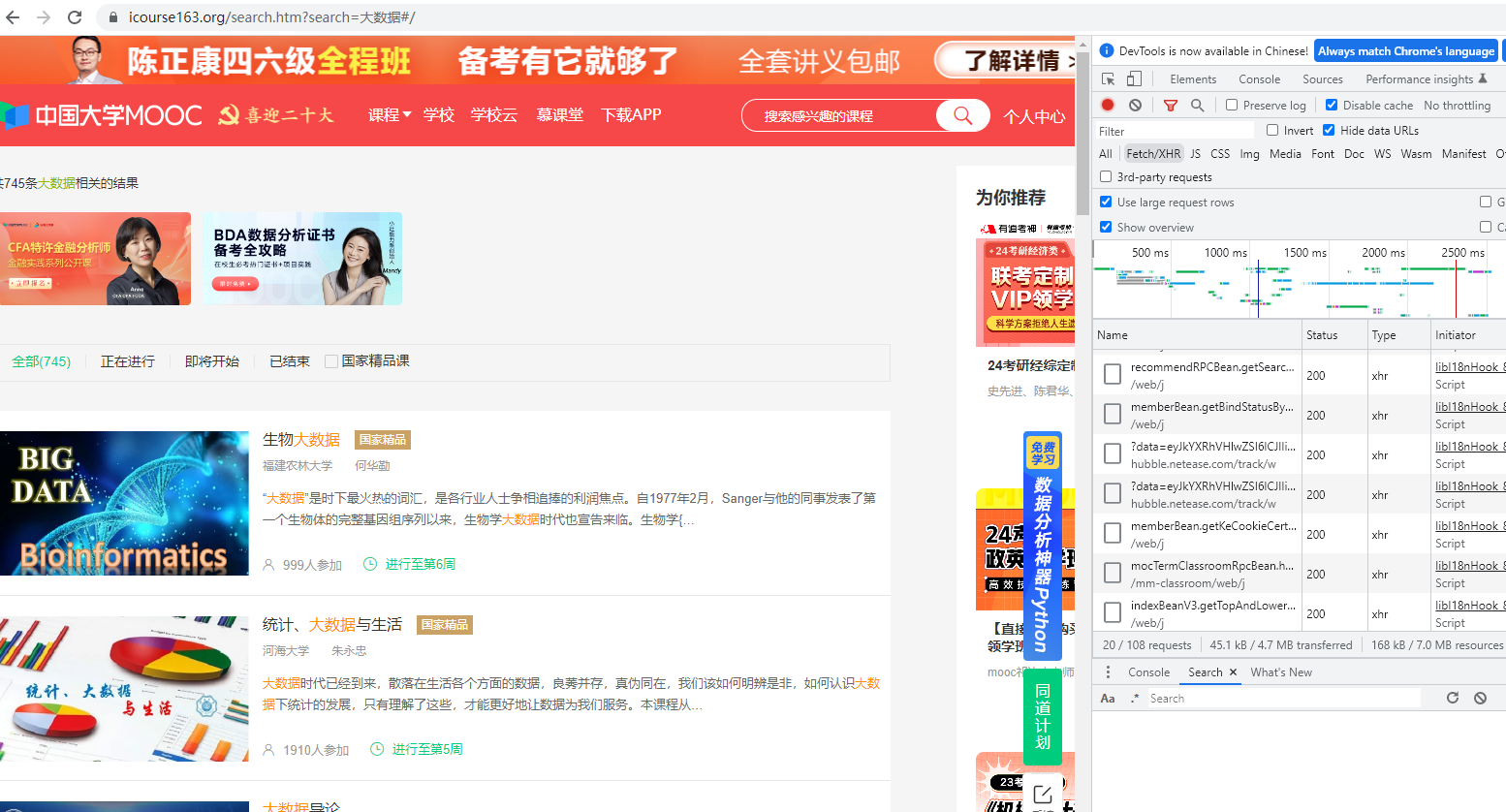
后面在网络那边找自己要的数据包
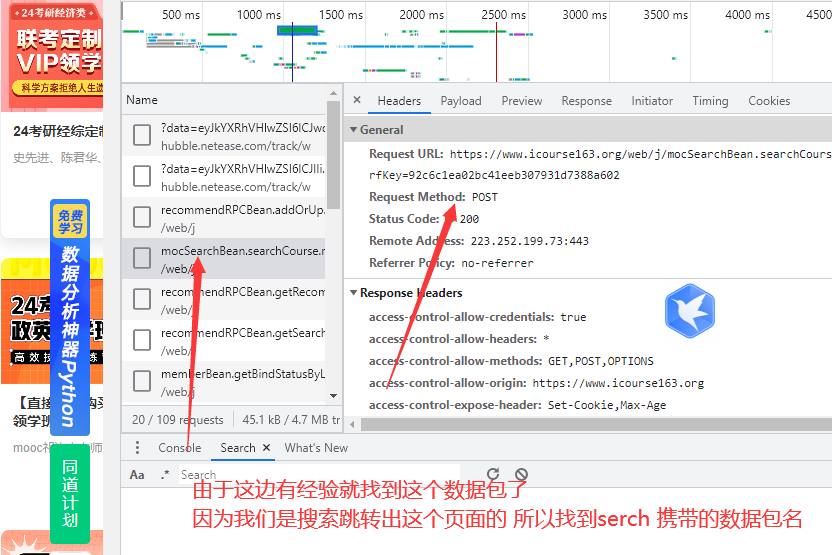
发现是post请求
这个是浏览器发起post请求携带的数据参数
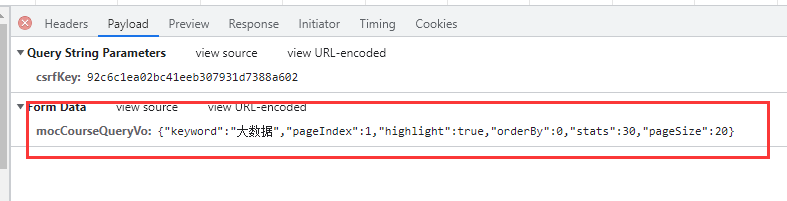

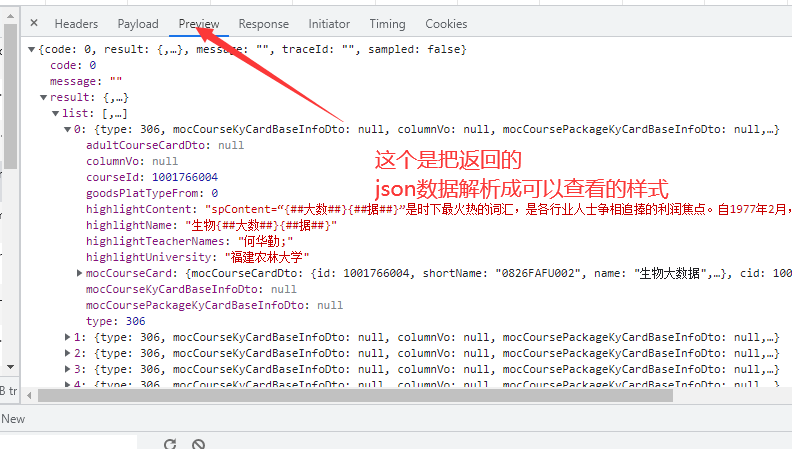
下面进入python写代码模拟Post请求的步骤

post请求一般要携带参数进行一个提交
data={
这个里面是刚刚查看那个里面携带的参数
}
这里携带是参数是
data={
'mocCourseQueryVo': '{"keyword":"大数据","pageIndex":1,"highlight":true,"orderBy":0,"stats":30,"pageSize":20}'}

先参数不携带cookie进行一个请求试试 代码如下
# _*_ coding:utf-8 _*_
import json
import requests
url='https://www.icourse163.org/web/j/mocSearchBean.searchCourse.rpc?csrfKey=c650905faf964e9885ec570cecc883e9'
data={
'mocCourseQueryVo': '{"keyword":"大数据","pageIndex":1,"highlight":true,"orderBy":0,"stats":30,"pageSize":20}'}
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
resp=requests.post(url=url,headers=headers,data=data)
print(resp.json())

发现服务器识别为非法跨域请求,不行,还是要我们登录的账号的cookie才能我们想要的数据
并且这里的data构建也和一般的不一样
一般我们构建的时候是这样的
resp=requests.post(url=url,headers=headers,json=json.dumps(data))
要把 data的数据转出 json的数据后面提交给服务器,

如果再强行转就和上面一样请求不了
# _*_ coding:utf-8 _*_
import json
import requests
url='https://www.icourse163.org/web/j/mocSearchBean.searchCourse.rpc?csrfKey=c650905faf964e9885ec570cecc883e9'
data={
'mocCourseQueryVo': '{"keyword":"大数据","pageIndex":1,"highlight":true,"orderBy":0,"stats":30,"pageSize":20}'}
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'cookie': '自己的cookie'
'origin': 'https://www.icourse163.org',
}
resp=requests.post(url=url,headers=headers,json=json.dumps(data))
print(resp)
print(resp.json())

请求服务器是成功的,但是服务器不返回数据,因为你提交的参数格式不对,不是json的格式,识别不了
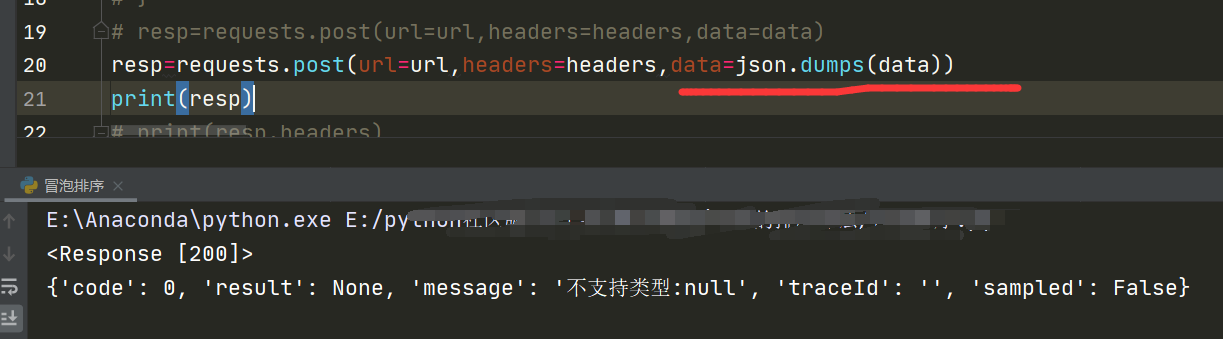
这样也一样
所有这里那个数据直接传就可以了 正确的请求代码如下
# _*_ coding:utf-8 _*_
import json
import requests
url='https://www.icourse163.org/web/j/mocSearchBean.searchCourse.rpc?csrfKey=c650905faf964e9885ec570cecc883e9'
data={
'mocCourseQueryVo': '{"keyword":"大数据","pageIndex":1,"highlight":true,"orderBy":0,"stats":30,"pageSize":20}'}
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'cookie': '自己的cookie'
'origin': 'https://www.icourse163.org',
}
resp=requests.post(url=url,headers=headers,data=data)
print(resp)
print(resp.json())

json数据在线解析
数据返回成功,后面把这个返回数据去json在线解析 可以解析出json数据出
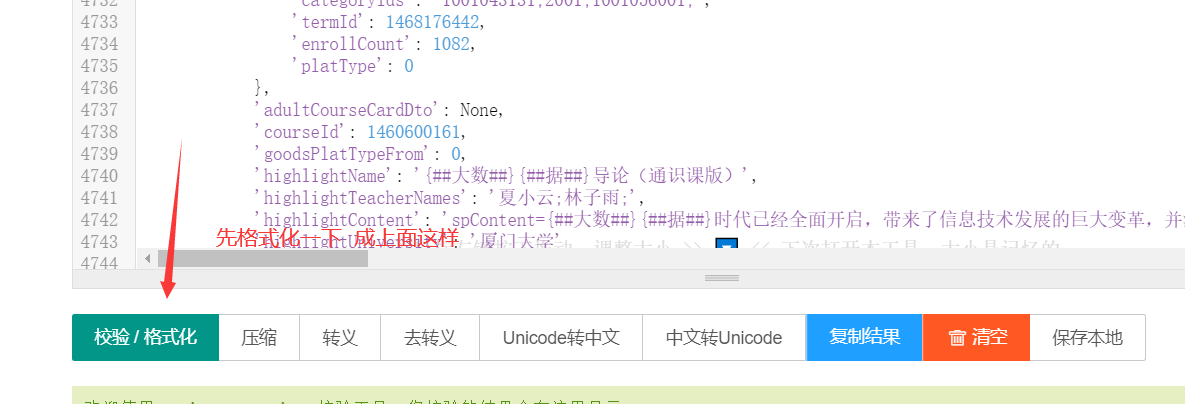
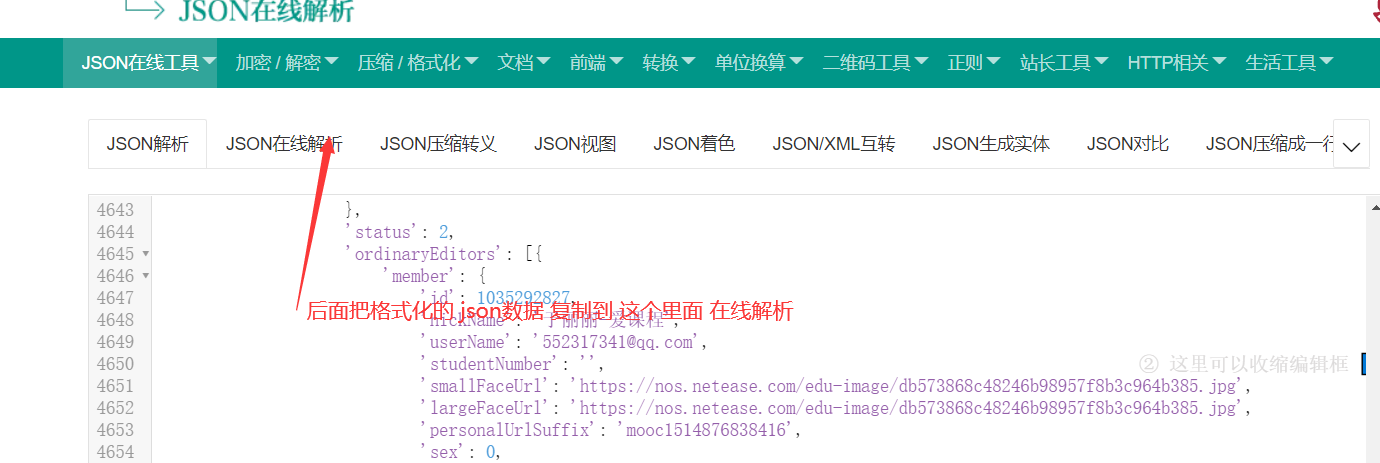

解析结果如上
代码如下“
# _*_ coding:utf-8 _*_
import json
import requests
url='https://www.icourse163.org/web/j/mocSearchBean.searchCourse.rpc?csrfKey=c650905faf964e9885ec570cecc883e9'
data={
'mocCourseQueryVo': '{"keyword":"大数据","pageIndex":1,"highlight":true,"orderBy":0,"stats":30,"pageSize":20}'}
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'cookie': '自己的cookie',
}
resp=requests.post(url=url,headers=headers,data=data)
print(resp)
print(resp.json())
a=resp.json()['result']['list']
print(a[0]['mocCourseCard'])
data=a[0]['mocCourseCard']
print(data)
根据字典和列表取值,获取里面的想要的数据
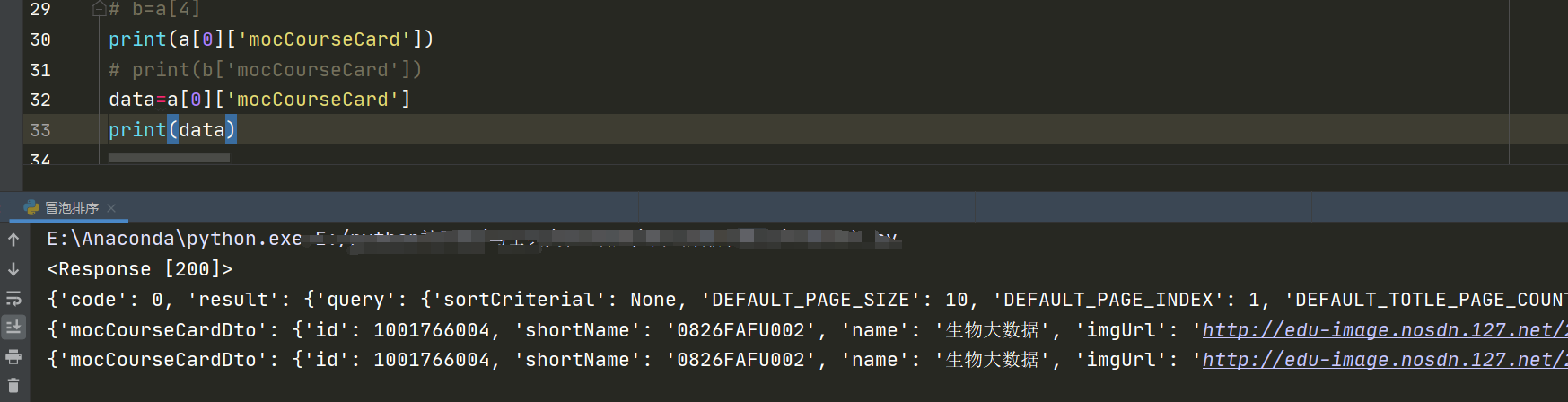
存储的代码就不写了。如果有需要的可以自己写一下

















 4661
4661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











