







1 架构设计
1.1 系统架构
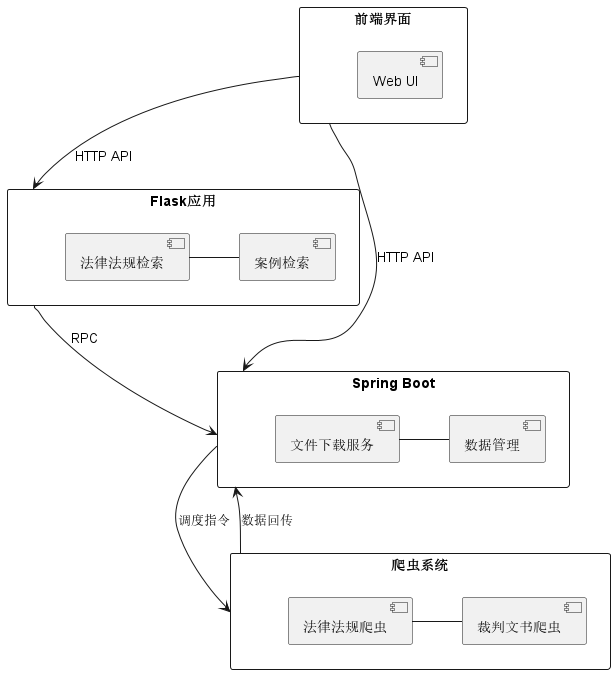
1.2 技术栈
数据库:MySQL 8.0
后端框架:Flask + Spring Boot
爬虫技术:Python + Requests
文件存储:数据库BLOB字段
2 数据库设计
2.1 法律法规表(law)
sql
CREATE TABLE `law` (
`id` BIGINT PRIMARY KEY AUTO_INCREMENT,
`title` VARCHAR(255) NOT NULL COMMENT '法律标题',
`enacting_authority` VARCHAR(100) NOT NULL COMMENT '制定机关',
`legal_nature` VARCHAR(50) NOT NULL COMMENT '法律性质',
`validity_status` VARCHAR(20) NULL COMMENT '时效状态',
`publish_date` DATE NULL COMMENT '公布日期',
`content` TEXT COMMENT '正文内容',
`file_content` LONGBLOB COMMENT '文件内容',
`file_type` VARCHAR(10) COMMENT '文件类型',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
`update_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`type` VARCHAR(20) NOT NULL COMMENT '法律类型',
INDEX `idx_title` (`title`),
INDEX `idx_authority` (`enacting_authority`),
INDEX `idx_update_time` (`update_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.2 诉讼案例表(law_suit)
sql
CREATE TABLE 案件信息 (
案件ID INT PRIMARY KEY AUTO_INCREMENT,
案号 VARCHAR(100),
案件名称 TEXT,
法院 VARCHAR(100),
所属地区 VARCHAR(50),
案件类型 VARCHAR(50),
案件类型摘要源 TEXT,
审理程序 VARCHAR(50),
裁判日期 DATE,
公开日期 DATE,
当事人 TEXT,
案由 TEXT,
法律依据 TEXT,
全文 TEXT,
INDEX idx_裁判日期 (裁判日期),
INDEX idx_案号 (案号),
INDEX idx_法院 (法院)
);
2.3 爬取历史表(crawl_history)
sql
CREATE TABLE `crawl_history` (
`id` INT AUTO_INCREMENT PRIMARY KEY,
`crawl_type` VARCHAR(20) NOT NULL,
`start_time` DATETIME NOT NULL,
`end_time` DATETIME,
`new_items` INT DEFAULT 0,
`updated_items` INT DEFAULT 0,
`status` VARCHAR(20) DEFAULT 'running',
`error_message` TEXT,
INDEX `idx_crawl_time` (`start_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3 模块详细设计
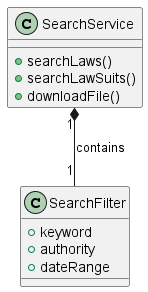
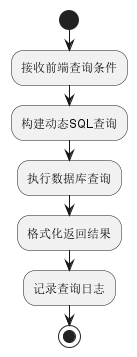
3.1 数据检索模块
类图:
流程图:
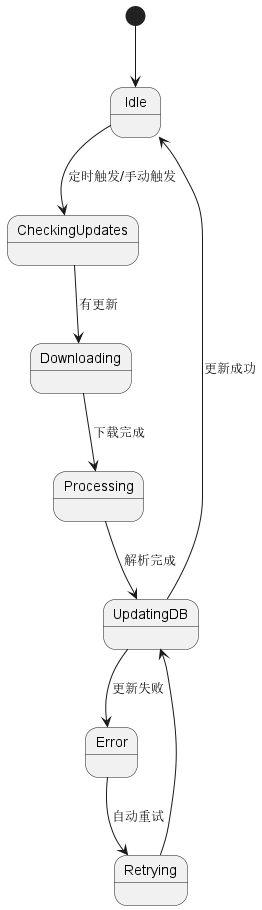
3.2 数据更新模块
状态图:
时序图:
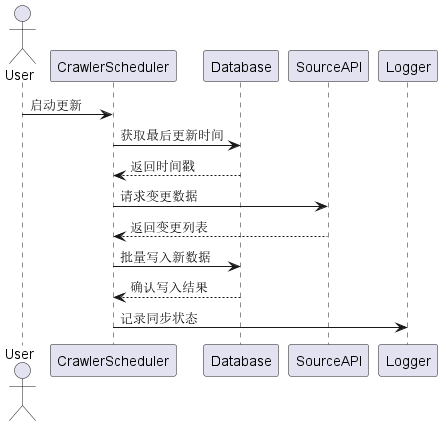
4 接口设计
4.1 检索接口
GET /api/laws
参数:
keyword: 标题关键词
authority: 发布机关
status: 效力状态
startDate/endDate: 发布时间范围
响应:
json
{
"code": 200,
"data": [
{
"id": 1,
"title": "中华人民共和国宪法",
"authority": "全国人民代表大会",
"publishDate": "2018-03-11"
}
]
}
4.2 文件下载接口
GET /api/laws/{id}/download
响应头:
Content-Type: application/pdf
Content-Disposition: attachment; filename="xxx.pdf"
4.3 数据更新接口
POST /api/crawler/start
参数:
type: full/incremental
force: true/false
响应:
json
{
"code": 200,
"message": "爬取任务已启动"
}
5 异常处理设计
5.1 错误代码表
代码 类型 描述
4001 数据不存在 请求的法律/案例不存在
4002 参数无效 查询参数格式错误
5001 数据库错误 数据库操作失败
5002 文件损坏 下载文件验证失败
5003 爬取失败 数据更新任务失败
5.2 异常处理流程
捕获底层异常
记录详细错误日志
转换为标准错误代码
返回友好错误信息
重要操作重试机制
6. 数据库部署
主从复制:配置MySQL主从同步
定期备份:每日全量备份+binlog
性能监控:配置慢查询告警
7. 爬虫服务部署
独立部署:与Web应用分离
资源限制:限制CPU/内存使用
日志轮转:每日切割日志文件
8. 数据更新策略
增量更新:每日4次(00:00,06:00,12:00,18:00)
全量更新:每周日凌晨2点
异常重试:失败后间隔10分钟重试3次
9. 测试计划
9.1 单元测试
数据库操作测试
检索条件构建测试
文件下载完整性测试
9.2 集成测试
爬虫全流程测试
检索功能端到端测试
高并发访问测试
9.3 性能测试
大数据量检索测试(>100万条)
连续更新稳定性测试(72小时)
混合负载压力测试


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









