






点击左上角蓝字,关注“锅外的大佬”
专注分享国外最新技术内容
1.引言
Microservices(微服务)是新软件项目中所青睐的架构设计。随着从单一系统到分布式系统的演化不仅发生在应用程序空间中,而且发生在数据存储中,管理数据成为最困难的挑战之一,然而,要从这种类型的方法中获得最大的收益,需要克服前面的几个需求。本文研究了将数据作为服务实现的一些考虑事项。
在遵循微服务设计指南时,我们找到一些对数据处理的参考。其中一些常见的方向包括:
每个服务的使用各自的私有数据库实现松散耦合。
拥抱最终一致性。
为最终一致性事务实现
saga pattern。使用
Command Query Responsibility Segregation(CQRS)和API组合。
考虑到这一点,当将松耦合作为体系架构中的一个基本部分时,共享数据库现在就变成了一个反模式,使得事务和查询变得更加困难。每个服务使用数据存储都需要封装数据,而与体系架构的其他域的交互应该只发生在API级别,这鼓励我们隐藏数据实现细节。因此,使用诸如Spring Boot这样的轻量级框架只是微服务之旅的第一步。
2.查询的挑战
因为每个服务都有数据存储,所以我们需要使其可供其他服务使用,从而成为该域的入口点。由于所有数据调用都发生在服务级别,并且根据它们的域,当需要组合数据视图时,传统的table join(表连接)不再是我们在共享数据库实现中使用的方案。此外,我们无法编写查询私有数据存储并聚合数据的服务,因为它违反了封装设计。
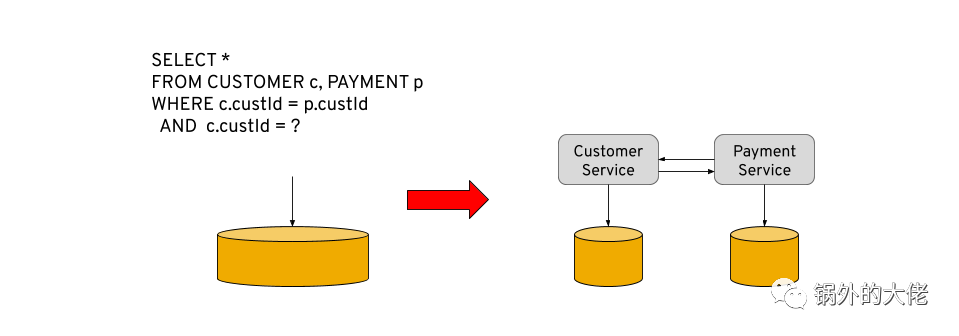
为了解决前面的挑战,我们需要回到微服务体系架构中,使用成熟的企业集成模式(Enterprise Integration Patterns, EIP),比如 content enrichment(内容浓缩)和aggregator( 聚合器)。大多数时候,这些模式被重新命名为API组合模式,通常在API网关之类的组件中实现。
通常,API组合模式涉及到添加另一个服务,该服务使用所需的信息调用底层数据服务来组合所需的数据视图。如下图所示,它将首先查询客户服务的基本信息,然后使用该信息从支付服务检索该客户的历史记录。

乍一看,这看起来像是一个简单的组合任务,然而,业务通常需要对数据的使用方式进行越来越多的控制,并向此类服务添加更多的逻辑。对要检索的数据量、消费终端用户的权限等的限制是常见的业务需求,这使得实现这类服务成为一项全职维护任务。
另一方面,Command Query Responsibility Segregation(CQRS)试图解决查询挑战,侧重于维护从多个源事件聚合的一个或多个物化的数据集。结果,系统的复杂性随着事件总线现在的要求而增加。我们将在以后的文章中讨论这种模式。
3.分布式数据集成
正如前面所讨论的,微服务的分布式特性使得服务与服务的通信和服务组合对于成功实现至关重要。尝试以一种主流的方式从头开始实现所有的服务,尽管这是可能的,但并不总是建议这样做,特别是在已存在专门的工具并帮助我们简化工作的情况下。
实际上,从头开始编码所有内容,通过服务使数据可用于外部消费的例子是可以避免的。我们可以公开不同商店中的数据,不仅是使用现有框架的关系数据库,这些框架可以帮助我们实现API组合模式,还可以使用简单的数据即微服务服务。
分布式数据集中集成通过一个统一的API提供对任何存储实现中的数据的集成访问。数据集成允许连接和统一数据,即使数据存储在SQL或JDBC之外的不止一种数据源中。与数据库管理系统相反,它不应该存储任何数据,而应该作为一个single point(单点)接口来优化访问数据源。
显然,这种框架应该与微服务的分布式特性相兼容。因此,引擎和实现应该是轻量级的,并且能够作为容器部署在云环境中。它应该具有在运行时独立执行组件的灵活性,比如Spring Boot或将其嵌入到应用程序中。
4.总结
综上所述,除了在微服务体系架构中构建服务之外,还需要使用通常已证实的实践,如 Enterprise Integration Patterns(企业集成模式)和Data Integration techniques(数据集成技术)。在以轻量级和分布式方式提供安全访问层的同时,查询不同数据源并将其连接以显示有意义信息的能力,可以简化您的应用程序。而且,正如 Christian Posta在他的微服务最难的部分:数据中所说,数据、数据集成、数据边界、企业使用模式、分布式系统理论、时间等都是微服务的难点(因为微服务实际上就是分布式系统!)
出处:spring for all 翻译组

●Spring WebClient vs. RestTemplate
右上角按钮分享给更多人哦~![]()
![]()

来都来了,点个在看再走吧~~~
















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









