









一、算法流程
step1:计算信息熵
step2: 划分数据集
step3: 创建决策树
step4: 利用决策树分类
二、信息熵Entropy、信息增益Gain
重点:选择一个属性进行分支。注意信息熵计算公式。
决策树作为典型的分类算法,基本思路是不断选取产生信息增益最大的属性来划分样例集和,构造决策树。信息增益定义为结点与其子结点的信息熵之差。
1.信息熵计算公式
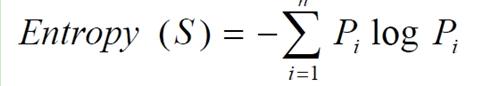
Pi为子集合中不同性(二元分类即正样例和负样例)的样例的比例。其中n代表有n个分类类别(比如假设是二分类问题,那么n=2)。分别计算着2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分支前的信息熵。
选中一个属性xi来进行分支,分支规则:如果xi=vx,则将样本分到树的一个分支;过不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵H1和H2,计算出分支后的总信息熵H’=p1*H1+p2*H2,那么此时的信息增益为ΔH=H-H’。以信息增益为原则,把所有的属性都测试一遍,选择一个使增益最大的属性作为本次分支属性。
2.信息增益计算公式
定义:样本按照某属性划分时造成熵减少的期望,可以区分训练样本中正负样本的能力。

三、ID3算法
常规决策树通常为C4.5决策树,其核心是ID3算法。构造树的基本思想是随着树深度增加,节点的熵迅速地降低,熵降低的速度越快越好,目标就是构建高度最矮的决策树。根据信息熵减小的梯度顺序决定构建树节点。
四、几个对数换底公式
logc(A/B) = logcA -logcB
logAB = logcB / logcA
五、优缺点总结
优点:
1.计算量简单,可解释性强,比较适合处理有确实属性值的样本,能处理不相关的特征;
2.对中间值缺失不敏感,可以处理不相关特征数据
缺点:容易过拟合(改进的方案有RF随机森林,减小过拟合现象)
数据类型:数值型、标称型
六、决策树变种
决策树的剪枝可以减少过拟合的现象,但还是不够,更多的还是利用模型组合,决策树的几个变种GBRT和RF将在下面两篇文章中提到。















 1183
1183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









