










 本文介绍了一种使用Python爬虫技术从上海排名网站抓取中国大学排名数据的方法。通过访问特定URL并解析JSON数据,实现了对大学排名、学校名称、总分及类型的抓取,并展示了排名前30的大学信息。
本文介绍了一种使用Python爬虫技术从上海排名网站抓取中国大学排名数据的方法。通过访问特定URL并解析JSON数据,实现了对大学排名、学校名称、总分及类型的抓取,并展示了排名前30的大学信息。
加上这一篇,我已经有三篇都是写 ”中国大学排名的爬取“小案例了,那我为什么又写一遍呢?还不是之前的代码不能成功爬取数据了。
那我怎么知道的呢?有网友反馈说,运行代码返回 None

我运行了一下,还真是:

可参考下列步骤,可以成功爬取到你想要的数据
1、进入 网址 ,可参考的下面的步骤,找到这些信息存储的地方:

2、在浏览器输入网址 :https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2020
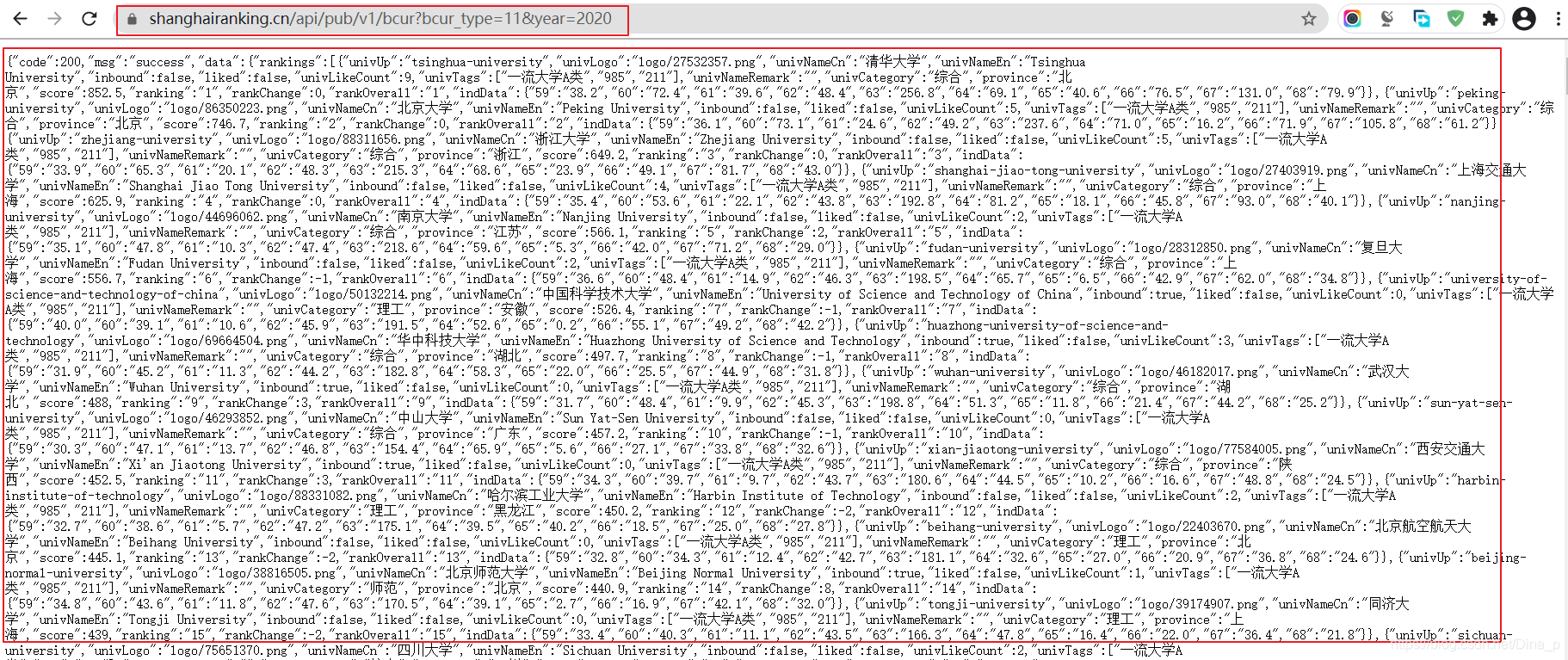
3、找出我们需要的信息,以 清华大学为例子

4、接下来就是开写代码了,可参考下面的代码:
import json
import requests
def getHTMLText(url):
'''从网络上获取大学排名网页内容'''
try:
r = requests.get(url, timeout=40)
# #如果状态不是200,就会引发HTTPError异常
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def printUnivList(ulist, html,num):
'''提取 html 网页内容中 前 num 名大学信息到 ulist列表中 '''
data = json.loads(html) #对数据进行解码
# 提取 数据 rankings 包含的内容
content = data['data']['rankings']
# 把 学校的相关信息放到 ulist 里面
for i in range(num):
index = content[i]['rankOverall']
name = content[i]['univNameCn']
score = content[i]['score']
category = content[i]['univCategory']
ulist.append([index, name, score,category])
# 打印前 num 名的大学
tplt ="{0:^10}\t{1:{3}^10}\t{2:^10}\t{4:^10}" # {1:{3}^10} 中的 {3} 代表取第三个参数
print(tplt.format("排名 ","学校名称","总分",chr(12288),"类型")) # chr(12288) 代表中文空格
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288),u[3])) # chr(12288) 代表中文空格
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2020'
html = getHTMLText(url)# 获取大学排名内容
printUnivList(uinfo, html, 30)#输出 排名前30 的大学内容
main()5、运行以上代码,就可以爬取到我么想要的内容了

本文若有不妥的地方,望指出,谢谢。

















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









