




一、kafka架构
1.1Kafka基础知识
1.1.1 Kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多生产者、多订阅者,基于zookeeper协 调的分布式日志系统(也可以当做MQ系统),常见可以用于webynginx日志、访问日志,消息服务等等,Linkedin于 2010年贡献给了Apache基会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的⽅式提供消息持久化能⼒,即使对TB级以上数据也能保证常数时间的访问性能。
- ⾼吞吐率。即使在⾮常廉价的商⽤机器上也能做到单机⽀持每秒100K条消息的传输。
- ⽀持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时⽀持离线数据处理和实时数据处理。
- ⽀持在线⽔平扩展

kafka是一种发布-订阅模式, 对于消息中间件,消息分推拉两种模式。Kafka只有消息的拉取,没有推送,可以通过轮询实现消息的推送。
1.Kafka在一个或多个可以跨越多个数据中心的服务器上作为集群运行。
2.Kafka集群中按照主题分类管理,一个主题可以有多个分区,一个分区可以有多个副本分区。
3.每个记录由一个键,一个值和一个时间戳组成。
Kafka具有四个核心API:
1.ProducerAPI:允许应用程序将记录流发布到一个或多个Kafka主题。
2.ConsumerAPI:允许应用程序订阅一个或多个主题并处理为其生成的记录流。
3.StreamsAPI:允许应用程序充当流处理器,使用一个或多个主题的输入流,并生成一个或多个输出主题的输出流,从而有效地将输入流转换为输出流。
4.ConnectorAPI:允许构建和运行将Kafka主题连接到现有应用程序或数据系统的可重用生产者或使用者。例如,关系数据库的连接器可能会捕获对表的所有更改。
1.1.2 Kafka优势
- 高吞吐量:单机每秒处理几十上百万的消息量。即使存储了许多TB的消息,它也保持稳定的性能。
- 高性能:单节点支持上千个客户端,并保证零停机和零数据丢失。
- 持久化数据存储:将消息持久化到磁盘。通过将数据持久化到硬盘以及replication防止数据丢失。
- 分布式系统,无需停机就可扩展机器。
- 可靠性-kafka是分布式,分区,复制和容错的。
- 客户端状态维护:消息被处理的状态是在Consumer端维护,而不是由server端维护。当失败时能自动平衡。
- 支持online和offline的场景。
- 支持多种客户端语言。Kafka支持Java、.NET、PHP、Python等多种语言。
1.1.3 Kafka应用场景
-
日志收集
一个公司可以用Kafka可以收集各种服务的Log,通过Kafka以统一接口服务的方式开放给各种Consumer。
-
消息系统
解耦生产者和消费者、缓存消息等。
-
用户活动跟踪
用来记录web用户或者APP用户的各种活动,如网页搜索、搜索、点击,用户数据收集然后进行用户行为分析。
-
运营指标
Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
-
流式处理
比如Spark Streaming和Storm。
1.1.4 Kafka核心概念
消息和批次
Kafka的数据单元称为消息。可以把消息看成是数据库里的一个“数据行”或一条“记录”,消息由字节数组组成。
消息有键,键也是⼀个字节数组。当消息以⼀种可控的⽅式写⼊不同的分区时,会⽤到键。
为了提⾼效率,消息被分批写⼊Kafka。批次就是⼀组消息,这些消息属于同⼀个主题和分区。
把消息分成批次可以减少⽹络开销。批次越⼤,单位时间内处理的消息就越多,单个消息的传输时间就越⻓。批次数据会被压缩,这样可以提升数据的传输和存储能⼒,但是需要更多的计算处理
模式
消息模式(schema)有许多可用的选项,以便于理解。如JSON和XML,但是它们缺乏强类型处理能力。Kafka的
许多开发者喜欢使用Apache Avro。Avro提供了一种紧凑的序列化格式,模式和消息体分开。当模式发生变化时,不需要重新生成代码,它还支持强类型和模式进化,其版本既向前兼容,也向后兼容。
topic
每条发布到Kafka集群的消息都有⼀个类别,这个类别被称为Topic。
物理上不同Topic的消息分开存储。
主题就好⽐数据库的表,尤其是分库分表之后的逻辑表。
主题可以被分为若干分区,一个主题通过分区分布于Kafka集群中,提供了横向扩展的能力。
Partition
- 主题可以被分为若干个分区,一个分区就是一个提交日志。
- 消息以追加的方式写入分区,然后以先入先出的顺序读取。
- 无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
- Kafka 通过分区来实现数据冗余和伸缩性。
- 在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
- 一个主题的不同partition,可以在一个broker上
Replicas
Kafka 使⽤主题来组织数据,每个主题被分为若⼲个分区,每个分区有多个副本。那些副本被保存在broker 上,每个broker 可以保存成百上千个属于不同主题和分区的副本。
同一个分区的副本分布在不同的broker上,所以副本数不能超过broker数
副本有以下两种类型:
-
⾸领副本
每个分区都有⼀个⾸领副本。为了保证⼀致性,所有⽣产者请求和消费者请求都会经过这个副本。
-
跟随者副本
⾸领以外的副本都是跟随者副本。跟随者副本不处理来⾃客户端的请求,它们唯⼀的任务就是从⾸领那⾥复制消息,保持与⾸领⼀致的状态。如果⾸领发⽣崩溃,其中的⼀个跟随者会被提升为新⾸领。
跟随者副本包括同步副本和不同步副本,在发⽣⾸领副本切换的时候,只有同步副本可以切换为⾸领副本。
Broker和集群

一个独立的Kafka 服务器被称为broker,是集群的组成部分。
broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存
broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
单个broker可以轻松处理数千个分区以及每秒百万级的消息量。
broker 是集群的组成部分。每个集群都有⼀个broker 同时充当了集群控制器的⻆⾊(⾃动从集群的活跃成员中选举出来)。
如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的⼀个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的⼀个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数⽬少于N个,那么⼀个broker存储该topic的⼀个或多个partition。在实际⽣产环境中,尽量避免这种情况的发⽣,这种情况容易导致Kafka集群数据不均衡。
控制器负责管理⼯作:
- 将分区分配给broker
- 监控broker
在集群中,⼀个分区从属于⼀个broker,该broker 被称为分区的⾸领。一个分区在其他broker上可能还存在副本分区,分区的复制提供了消息冗余,⾼可⽤。副本分区不负责处理消息的读写。
Producer
生产者创建消息。

该⻆⾊将消息发布到Kafka的topic中。broker接收到⽣产者发送的消息后,将该消息追加到当前⽤于追加数据的 segment ⽂件中。
⼀般情况下,⼀个消息会被发布到⼀个特定的主题上。
- 默认情况下通过轮询把消息均衡地分布到主题的所有分区上。
- 在某些情况下,⽣产者会把消息直接写到指定的分区。这通常是通过消息键和分区器来实现的,分区器为键⽣成⼀个散列值,并将其映射到指定的分区上。这样可以保证包含同⼀个键的消息会被写到同⼀个分区上。
- ⽣产者也可以使⽤⾃定义的分区器,根据不同的业务规则将消息映射到分区。
Consumer
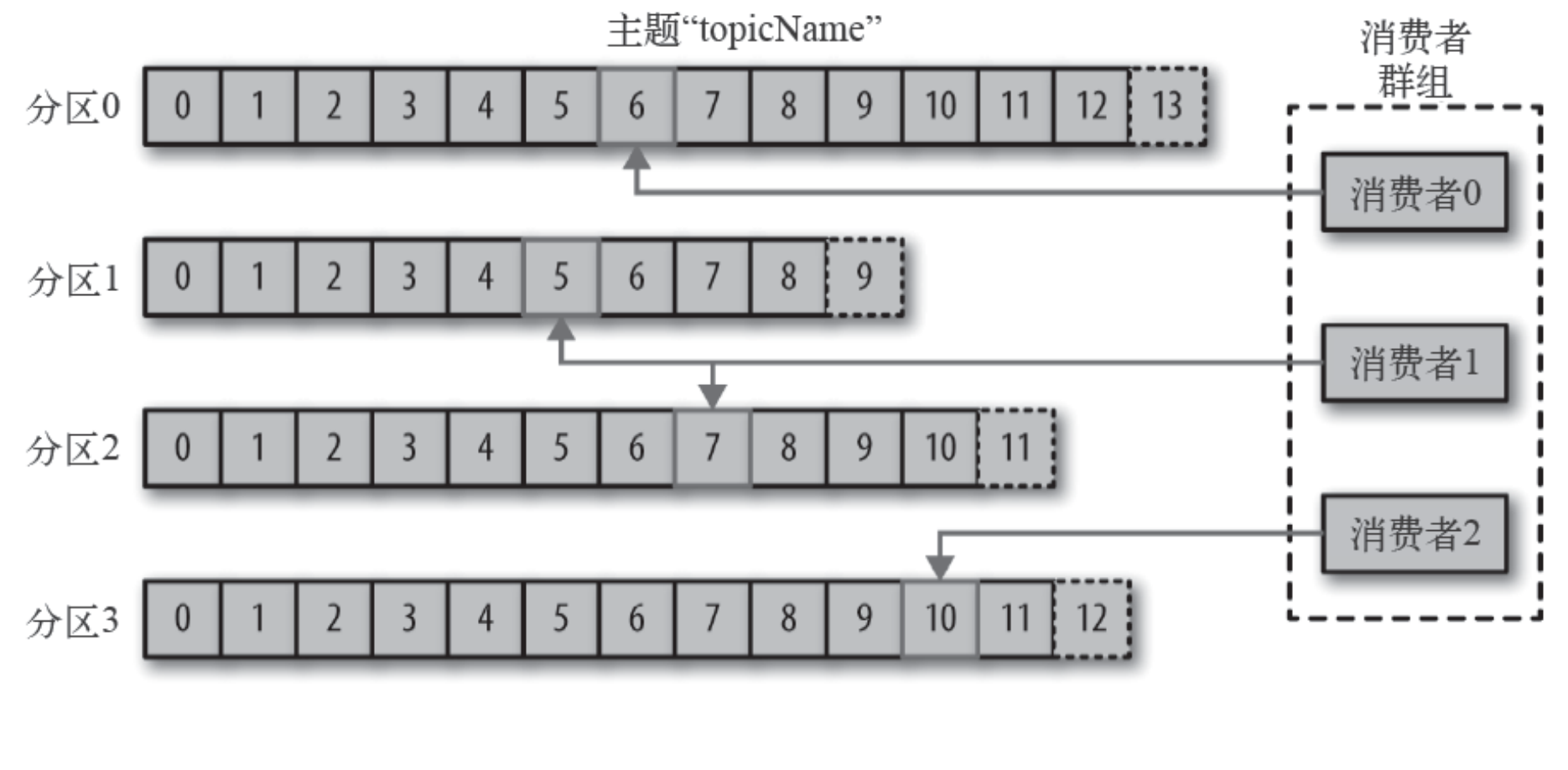
消费者读取消息
- 消费者订阅⼀个或多个主题,并按照消息⽣成的顺序读取它们。
- 消费者通过检查消息的偏移量来区分已经读取过的消息。偏移量是另⼀种元数据,它是⼀个不断递增的整数值,在创建消息时,Kafka 会把它添加到消息⾥。对于某个消费组,在给定的分区⾥,每个消息的偏移量都是唯⼀的。消费者把每个分区最后读取的消息偏移量保存在Zookeeper 或Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
- 消费者是消费组的⼀部分。群组保证每个分区只能被⼀个消费者使⽤。
- 如果⼀个消费者失效,消费组⾥的其他消费者可以接管失效消费者的⼯作,再平衡,分区重新分配。
Offset

生产者Offset:消息写入的时候,每一个分区都有一个offset,这个offset就是生产者的offset,同时也是这个分区的最新最大的offset。
消费者Offset:某个分区的offset情况,生产者写入的offset是最新最大的值是12,而当Consumer A进行消费时,从0开始消费,一直消费到了9,消费者的offset就记录在9,Consumer B就纪录在了11。等下⼀次他们再来消费时,他们可以选择接着上⼀次的位置消费,当然也可以选择从头消费,或者跳到最近的记录并从“现在”开始消费。
AR
分区中的所有副本统称为AR(Assigned Repllicas),AR=ISR+OSR。
ISR
所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。
消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进⾏同步,同步期间内follower副本相对于leader副本⽽⾔会有⼀定程度的滞后。对于这种滞后可以有“⼀定程度”忍受,这个忍受的范围可以通过参数进⾏配置
OSR
与leader副本同步滞后过多的副本(不包括leader)副本,组成OSR(Out-Sync Relipcas)。
在正常情况下,所有的follower副本都应该与leader副本保持⼀定程度的同步,即AR=ISR,OSR集合为空
HW

HW是High Watermak的缩写, 俗称⾼⽔位,它表示了⼀个特定消息的偏移量(offset),是该分区的所有副本集中最小的LEO
LEO
LEO是Log End Offset的缩写,它表示了当前⽇志⽂件中下⼀条待写⼊消息的offset。
1.2 Kafka配置
1.2.1 生产者配置
KafkaProducer 的创建需要指定的参数和含义:
| 参数名称 | 描述 |
|---|---|
| retry.backoff.ms | 在向⼀个指定的主题分区重发消息的时候,重试之间的等待时间。⽐如3次重试,每次重试之后等待该时间⻓度,再接着重试。在⼀些失败的场景,避免了密集循环的重新发送请求。long型值,默认100。可选值:[0,…] |
| retries | retries重试次数当消息发送出现错误的时候,系统会重发消息。跟客户端收到错误时重发⼀样。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则在重试此失败消息的时候,其他的消息可能发送成功了 |
| request.timeout.ms | 客户端等待请求响应的最⼤时⻓。如果服务端响应超时,则会重发请求,除⾮达到重试次数。该设置应该⽐replica.lag.time.max.ms (a broker configuration)要⼤,以免在服务器延迟时间内重发消息。int类型值,默认:30000,可选值:[0,…] |
| interceptor.classes | 在⽣产者接收到该消息,向Kafka集群传输之前,由序列化器处理之前,可以通过拦截器对消息进⾏处理。要求拦截器类必须实现org.apache.kafka.clients.producer.ProducerInterceptor接⼝。默认没有拦截器。Map<String, Object> configs中通过List集合配置多个拦截器类名。 |
| acks | 默认值:all。acks=0:⽣产者不等待broker对消息的确认,只要将消息放到缓冲区,就认为消息已经发送完成。该情形不能保证broker是否真的收到了消息,retries配置也不会⽣效。发送的消息的返回的消息偏移量永远是-1。 acks=1表示消息只需要写到主分区即可,然后就响应客户端,⽽不等待副本分区的确认。在该情形下,如果主分区收到消息确认之后就宕机了,⽽副本分区还没来得及同步该消息,则该消息丢失。 acks=all⾸领分区会等待所有的ISR副本分区确认记录。该处理保证了只要有⼀个ISR副本分区存活,消息就不会丢失。这是Kafka最强的可靠性保证,等效于acks=-1 |
| batch.size | 当多个消息发送到同⼀个分区的时候,⽣产者尝试将多个记录作为⼀个批来处理。批处理提⾼了客户端和服务器的处理效率。该配置项以字节为单位控制默认批的⼤⼩。所有的批⼩于等于该值。发送给broker的请求将包含多个批次,每个分区⼀个,并包含可发送的数据。如果该值设置的⽐较⼩,会限制吞吐量(设置为0会完全禁⽤批处理)。如果设置的很⼤,⼜有⼀点浪费内存,因为Kafka会永远分配这么⼤的内存来参与到消息的批整合中。 |
| client.id | ⽣产者发送请求的时候传递给broker的id字符串。⽤于在broker的请求⽇志中追踪什么应⽤发送了什么消息。⼀般该id是跟业务有关的字符串。 |
| compression.type | ⽣产者发送的所有数据的压缩⽅式。默认是none,也就是不压缩。⽀持的值:none、gzip、snappy和lz4。压缩是对于整个批来讲的,所以批处理的效率也会影响到压缩的⽐例。 |
| send.buffer.bytes | TCP发送数据的时候使⽤的缓冲区(SO_SNDBUF)⼤⼩。如果设置为0,则使⽤操作系统默认的。 |
| buffer.memory | ⽣产者可以⽤来缓存等待发送到服务器的记录的总内存字节。如果记录的发送速度超过了将记录发送到服务器的速度,则⽣产者将阻塞max.block.ms的时间,此后它将引发异常。此设置应⼤致对应于⽣产者将使⽤的总内存,但并⾮⽣产者使⽤的所有内存都⽤于缓冲。⼀些额外的内存将⽤于压缩(如果启⽤了压缩)以及维护运⾏中的请求。long型数据。默认值:33554432,可选值:[0,…] |
| connections.max.idle.ms | 当连接空闲时间达到这个值,就关闭连接。long型数据,默认:540000 |
| linger.ms | ⽣产者在发送请求传输间隔会对需要发送的消息进⾏累积,然后作为⼀个批次发送。⼀般情况是消息的发送的速度⽐消息累积的速度慢。有时客户端需要减少请求的次数,即使是在发送负载不⼤的情况下。该配置设置了⼀个延迟,⽣产者不会⽴即将消息发送到broker,⽽是等待这么⼀段时间以累积消息,然后将这段时间之内的消息作为⼀个批次发送。该设置是批处理的另⼀个上限:⼀旦批消息达到了batch.size指定的值,消息批会⽴即发送,如果积累的消息字节数达不到batch.size的值,可以设置该毫秒值,等待这么⻓时间之后,也会发送消息批。该属性默认值是0(没有延迟)。如果设置linger.ms=5,则在⼀个请求发送之前先等待5ms。long型值,默认:0,可选值:[0,…] |
| max.block.ms | 控制KafkaProducer.send()和KafkaProducer.partitionsFor()阻塞的时⻓。当缓存满了或元数据不可⽤的时候,这些⽅法阻塞。在⽤户提供的序列化器和分区器的阻塞时间不计⼊。long型值,默认:60000,可选值:[0,…] |
| max.request.size | 单个请求的最⼤字节数。该设置会限制单个请求中消息批的消息个数,以免单个请求发送太多的数据。服务器有⾃⼰的限制批⼤⼩的设置,与该配置可能不⼀样。int类型值,默认1048576,可选值:[0,…] |
| partitioner.class | 实现了接⼝org.apache.kafka.clients.producer.Partitioner 的分区器实现类。默认值为:org.apache.kafka.clients.producer.internals.DefaultPartitioner |
| receive.buffer.bytes | TCP接收缓存(SO_RCVBUF),如果设置为-1,则使⽤操作系统默认的值。int类型值,默认32768,可选值:[-1,…] |
| security.protocol | 跟broker通信的协议:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.string类型值,默认:PLAINTEXT |
| max.in.flight.requests.per.connection | 单个连接上未确认请求的最⼤数量。达到这个数量,客户端阻塞。如果该值⼤于1,且存在失败的请求,在重试的时候消息顺序不能保证。int类型值,默认5。可选值:[1,…] |
| reconnect.backoff.max.ms | 对于每个连续的连接失败,每台主机的退避将成倍增加,直⾄达到此最⼤值。在计算退避增量之后,添加20%的随机抖动以避免连接⻛暴。long型值,默认1000,可选值:[0,…] |
| reconnect.backoff.ms | 尝试重连指定主机的基础等待时间。避免了到该主机的密集重连。该退避时间应⽤于该客户端到broker的所有连接。long型值,默认50。可选值:[0,…] |
| key.serializer | 实现了接⼝org.apache.kafka.common.serialization.Serializer的key序列化类。 |
| value.serializer | 实现了接⼝org.apache.kafka.common.serialization.Serializer的value序列化类。 |
其他参数可以从org.apache.kafka.clients.producer.ProducerConfig中找到。
1.2.2 服务端参数配置
$KAFKA_HOME/config/server.properties⽂件中的配置
| 参数 | 说明 |
|---|---|
| zookeeper.connect | 该参数⽤于配置Kafka要连接的Zookeeper/集群的地址。 它的值是⼀个字符串,使⽤逗号分隔Zookeeper的多个地址。Zookeeper的单个地址是host:port形式的,可以在最后添加Kafka在Zookeeper中的根节点路径 zookeeper.connect=192.168.0.102:2181,192.168.0.103:2181,192.168.0.104:2181/kafka |
| listeners | ⽤于配置broker监听的URI以及监听器名称列表,使⽤逗号隔开多个URI及监听器名称。如果监听器名称代表的不是安全协议,必须配置 listener.security.protocol.map。每个监听器必须使⽤不同的⽹络端⼝。 |
| inter.broker.listener.name | ⽤于配置broker之间通信使⽤的监听器名称,该名称必须在advertised.listeners列表中。inter.broker.listener.name=EXTERNAL |
| listener.security.protocol.map | 监听器名称和安全协议的映射配置。⽐如,可以将内外⽹隔离,即使它们都使⽤SSL。listener.security.protocol.map=INTERNAL:SSL,EXTERNAL:SSL每个监听器的名称只能在map中出现⼀次。 |
| advertised.listeners | 需要将该地址发布到zookeeper供客户端使⽤。 可以在zookeeper的 get /myKafka/brokers/ids/<broker.id>中找到。如果不设置此条⽬,就使⽤listeners的配置。 跟listeners不同,该条⽬不能使⽤0.0.0.0⽹络端⼝。 advertised.listeners的地址必须是listeners中配置的或配置的⼀部分。 |
| broker.id | 该属性⽤于唯⼀标记⼀个Kafka的Broker,它的值是⼀个任意integer值。 当Kafka以分布式集群运⾏的时候,尤为重要。 最好该值跟该Broker所在的物理主机有关的,如果主机名为 192.168.100.101,则broker.id=101等等。 |
| log.dirs | 通过该属性的值,指定Kafka在磁盘上保存消息的⽇志⽚段的⽬录。 它是⼀组⽤逗号分隔的本地⽂件系统路径。如果指定了多个路径,那么broker 会根据“最少使⽤”原则,把同⼀个分区的⽇志⽚段保存到同⼀个路径下。 broker 会往拥有最少数⽬分区的路径新增分区,⽽不是往拥有最⼩磁盘空间的路径新增分区。 |
1.2.3 消费者参数配置
| 配置项 | 说明 |
|---|---|
| bootstrap.servers | 建⽴到Kafka集群的初始连接⽤到的host/port列表。 客户端会使⽤这⾥指定的所有的host/port来建⽴初始连接。 这个配置仅会影响发现集群所有节点的初始连接。 形式:host1:port1,host2:port2… 这个配置中不需要包含集群中所有的节点信息。 最好不要配置⼀个,以免配置的这个节点宕机的时候连不上。 |
| group.id | ⽤于定义当前消费者所属的消费组的唯⼀字符串。 如果使⽤了消费组的功能subscribe(topic),或使⽤了基于Kafka的偏移量管理机制,则应该配置group.id。 |
| auto.commit.interval.ms | 如果设置了enable.auto.commit的值为true,则该值定义了消费者偏移量向Kafka提交的频率。 |
| auto.offset.reset | 如果Kafka中没有初始偏移量或当前偏移量在服务器中不存在(⽐如数据被删掉了): earliest:⾃动重置偏移量到最早的偏移量。 latest:⾃动重置偏移量到最后⼀个 none:如果没有找到该消费组以前的偏移量没有找到,就抛异常。 其他值:向消费者抛异常。 |
| fetch.min.bytes | 服务器对每个拉取消息的请求返回的数据量最⼩值。 如果数据量达不到这个值,请求等待,以让更多的数据累积,达到这个值之后响应请求。 默认设置是1个字节,表示只要有⼀个字节的数据,就⽴即响应请求,或者在没有数据的时候请求超时。 将该值设置为⼤⼀点⼉的数字,会让服务器等待稍微⻓⼀点⼉的时间以累积数据。 如此则可以提⾼服务器的吞吐量,代价是额外的延迟时间。 |
| fetch.max.wait.ms | 如果服务器端的数据量达不到fetch.min.bytes的话,服务器端不能⽴即响应请求。该时间⽤于配置服务器端阻塞请求的最⼤时⻓。 |
| fetch.max.bytes | 服务器给单个拉取请求返回的最⼤数据量。 消费者批量拉取消息,如果第⼀个⾮空消息批次的值⽐该值⼤,消息批也会返回,以让消费者可以接着进⾏。 即该配置并不是绝对的最⼤值。 broker可以接收的消息批最⼤值通过message.max.bytes(broker配置)或max.message.bytes(主题配置)来指定。需要注意的是,消费者⼀般会并发拉取请求。 |
| enable.auto.commit | 如果设置为true,则消费者的偏移量会周期性地在后台提交。 |
| connections.max.idle.ms | 在这个时间之后关闭空闲的连接。 |
| check.crcs | ⾃动计算被消费的消息的CRC32校验值。 可以确保在传输过程中或磁盘存储过程中消息没有被破坏。 它会增加额外的负载,在追求极致性能的场合禁⽤。 |
| exclude.internal.topics | 是否内部主题应该暴露给消费者。如果该条⽬设置为true,则只能先订阅再拉取。 |
| isolation.level | 控制如何读取事务消息。 如果设置了read_committed,消费者的poll()⽅法只会返回已经提交的事务消息。如果设置了read_uncommitted(默认值),消费者的poll⽅法返回所有的消息,即使是已经取消的事务消息。⾮事务消息以上两种情况都返回。 消息总是以偏移量的顺序返回。 read_committed只能返回到达LSO的消息。在LSO之后出现的消息只能等待相关的事务提交之后才能看到。结果,read_committed模式,如果有为提交的事务,消费者不能读取到直到HW的消息。read_committed的seekToEnd⽅法返回LSO。 |
| heartbeat.interval.ms | 当使⽤消费组的时候,该条⽬指定消费者向消费者协调器发送⼼跳的时间间隔。 ⼼跳是为了确保消费者会话的活跃状态,同时在消费者加⼊或离开消费组的时候⽅便进⾏再平衡。 该条⽬的值必须⼩于session.timeout.ms,也不应该⾼于session.timeout.ms的1/3。可以将其调整得更⼩,以控制正常重新平衡的预期时间。 |
| session.timeout.ms | 当使⽤Kafka的消费组的时候,消费者周期性地向broker发送⼼跳数据,表明⾃⼰的存在。 如果经过该超时时间还没有收到消费者的⼼跳,则broker将消费者从消费组移除,并启动再平衡。 该值必须在broker配置group.min.session.timeout.ms和group.max.session.timeout.ms之间。 |
| max.poll.records | ⼀次调⽤poll()⽅法返回的记录最⼤数量。 |
| max.poll.interval.ms | 使⽤消费组的时候调⽤poll()⽅法的时间间隔。 该条⽬指定了消费者调⽤poll()⽅法的最⼤时间间隔。 如果在此时间内消费者没有调⽤poll()⽅法,则broker认为消费者失败,触发再平衡,将分区分配给消费组中其他消费者。 |
| max.partition.fetch.bytes | 对每个分区,服务器返回的最⼤数量。消费者按批次拉取数据。 如果⾮空分区的第⼀个记录⼤于这个值,批处理依然可以返回,以保证消费者可以进⾏下去。 broker接收批的⼤⼩由message.max.bytes(broker参数)或max.message.bytes(主题参数)指定。fetch.max.bytes⽤于限制消费者单次请求的数据量。 |
| send.buffer.bytes | ⽤于TCP发送数据时使⽤的缓冲⼤⼩(SO_SNDBUF),-1表示使⽤OS默认的缓冲区⼤⼩。 |
| retry.backoff.ms | 在发⽣失败的时候如果需要重试,则该配置表示客户端等待多⻓时间再发起重试。 该时间的存在避免了密集循环。 |
| request.timeout.ms | 客户端等待服务端响应的最⼤时间。如果该时间超时,则客户端要么重新发起请求,要么如果重试耗尽,请求失败。 |
| reconnect.backoff.ms | 重新连接主机的等待时间。避免了重连的密集循环。 该等待时间应⽤于该客户端到broker的所有连接。 |
| reconnect.backoff.max.ms | 重新连接到反复连接失败的broker时要等待的最⻓时间(以毫秒为单位)。 如果提供此选项,则对于每个连续的连接失败,每台主机的退避将成倍增加,直⾄达到此最⼤值。 在计算退避增量之后,添加20%的随机抖动以避免连接⻛暴。 |
| receive.buffer.bytes | TCP连接接收数据的缓存(SO_RCVBUF)。-1表示使⽤操作系统的默认值。 |
| partition.assignment.strategy | 当使⽤消费组的时候,分区分配策略的类名。 |
| metrics.sample.window.ms | 计算指标样本的时间窗⼝。 |
| metrics.recording.level | 指标的最⾼记录级别。 |
| metrics.num.samples | ⽤于计算指标⽽维护的样本数量 |
| interceptor.classes | 拦截器类的列表。默认没有拦截器拦截器是消费者的拦截器,该拦截器需要实现org.apache.kafka.clients.consumer.ConsumerInterceptor接⼝。拦截器可⽤于对消费者接收到的消息进⾏拦截处理。 |
1.2.4 主题配置

1.3 Kafka 使用
1.3.1 Kafka API 使用
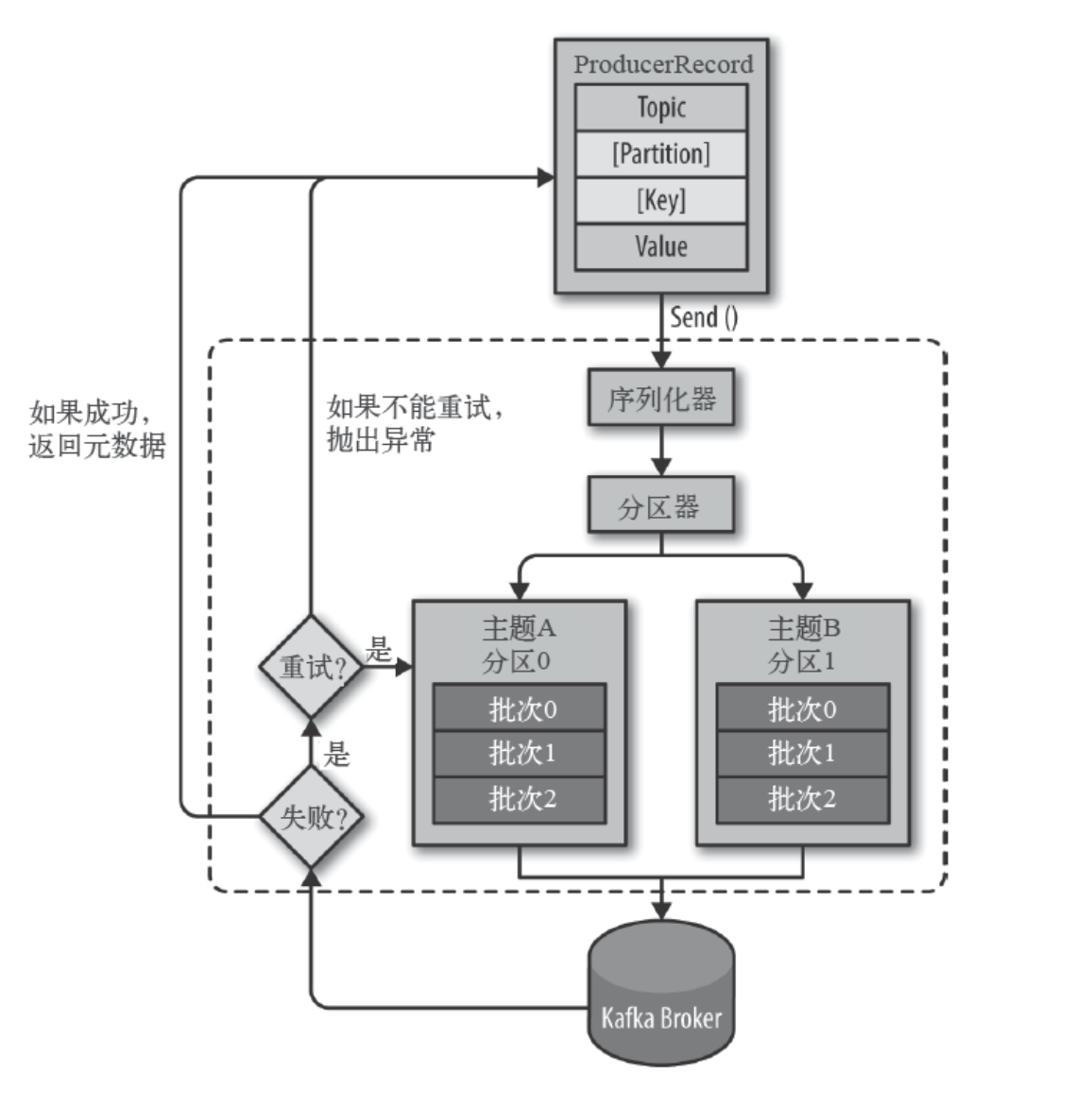
⽣产者主要的对象有: KafkaProducer , ProducerRecord 。
其中 KafkaProducer 是⽤于发送消息的类, ProducerRecord 类⽤于封装Kafka的消息。
消费者⽣产消息后,需要broker端的确认,可以同步确认,也可以异步确认。
同步确认效率低,异步确认效率⾼,但是需要设置回调对象。
添加Maven依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<!--高版本兼容低版本-->
<version>1.0.2</version>
</dependency>1.2.3.4.5.6.
生产者
同步等待消息确认:
public class MyProducer1 {
public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
Map<String, Object> configs = new HashMap<>();
// 设置连接Kafka的初始连接⽤到的服务器地址
// 如果是集群,则可以通过此初始连接发现集群中的其他broker
configs.put("bootstrap.servers", "192.168.0.102:9092");
// 设置key的序列化器
configs.put("key.serializer", IntegerSerializer.class);
// 设置value的序列化器
configs.put("value.serializer", StringSerializer.class);
configs.put("acks", "1");
KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(configs);
// ⽤于封装Producer的消息
ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>(
"topic_1", // 主题名称
0, // 分区编号,现在只有⼀个分区,所以是0
0, // 数字作为key
"message 0" // 字符串作为value
);
// 发送消息,同步等待消息的确认
Future<RecordMetadata> future = producer.send(record);
RecordMetadata metadata = future.get(3000, TimeUnit.MILLISECONDS);
System.out.println("主题:" + metadata.topic()
+ "\n分区:" + metadata.partition()
+ "\n偏移量:" + metadata.offset()
+ "\n序列化的key字节:" + metadata.serializedKeySize()
+ "\n序列化的value字节:" + metadata.serializedValueSize()
+ "\n时间戳:" + metadata.timestamp());
// 关闭⽣产者
producer.close();
}
}
异步等待消息确认:
public class MyProducer2 {
public static void main(String[] args) {
Map<String, Object> configs = new HashMap<>();
configs.put("bootstrap.servers", "192.168.0.102:9092");
configs.put("key.serializer", IntegerSerializer.class);
configs.put("value.serializer", StringSerializer.class);
KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(configs);
ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>(
"topic_1", 0, 1, "message 2");
// 使⽤回调异步等待消息的确认
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("主题:" + metadata.topic()
+ "\n分区:" + metadata.partition()
+ "\n偏移量:" + metadata.offset()
+ "\n序列化的key字节:" + metadata.serializedKeySize()
+ "\n序列化的value字节:" + metadata.serializedValueSize()
+ "\n时间戳:" + metadata.timestamp());
} else {
System.out.println("有异常:" + exception.getMessage());
}
}
});
// 关闭连接
producer.close();
}
}
消费者:
public class MyConsumer1 {
public static void main(String[] args) {
Map<String, Object> configs = new HashMap<>();
// 指定bootstrap.servers属性作为初始化连接Kafka的服务器。
// 如果是集群,则会基于此初始化连接发现集群中的其他服务器。
configs.put("bootstrap.servers", "192.168.0.102:9092");
// key的反序列化器
configs.put("key.deserializer", IntegerDeserializer.class);
// value的反序列化器
configs.put("value.deserializer", StringDeserializer.class);
// 设置消费组
configs.put("group.id", "consumer.demo");
// 创建消费者对象
KafkaConsumer<Integer, String> consumer = new KafkaConsumer<Integer, String>(configs);
// 可以使用正则表达式批量订阅主题
// final Pattern pattern = Pattern.compile("topic_\\d")
final Pattern pattern = Pattern.compile("topic_[0-9]");
final List<String> topics = Arrays.asList("topic_1");
// 消费者订阅主题或分区
// consumer.subscribe(pattern);
// consumer.subscribe(pattern, new ConsumerRebalanceListener() {
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
partitions.forEach(tp -> {
System.out.println("剥夺的分区:" + tp.partition());
});
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
partitions.forEach(tp -> {
System.out.println(tp.partition());
});
}
});
// 拉取订阅主题的消息
final ConsumerRecords<Integer, String> records = consumer.poll(3_000);
// 获取topic_1主题的消息
final Iterable<ConsumerRecord<Integer, String>> topic1Iterable = records.records("topic_1");
// 遍历topic_1主题的消息
topic1Iterable.forEach(record -> {
System.out.println("========================================");
System.out.println("消息头字段:" + Arrays.toString(record.headers().toArray()));
System.out.println("消息的key:" + record.key());
System.out.println("消息的偏移量:" + record.offset());
System.out.println("消息的分区号:" + record.partition());
System.out.println("消息的序列化key字节数:" + record.serializedKeySize());
System.out.println("消息的序列化value字节数:" + record.serializedValueSize());
System.out.println("消息的时间戳:" + record.timestamp());
System.out.println("消息的时间戳类型:" + record.timestampType());
System.out.println("消息的主题:" + record.topic());
System.out.println("消息的值:" + record.value());
});
// 关闭消费者
consumer.close();
}
}
1.3.2 springboot Kafka 使用
pom.xml 依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
application.properties
spring.application.name=demo-02-producer-consumer
server.port=8080
# ⽤于建⽴初始连接的broker地址
spring.kafka.bootstrap-servers=192.168.0.102:9092
# producer⽤到的key和value的序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.IntegerSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 默认的批处理记录数
spring.kafka.producer.batch-size=16384
# 32MB的总发送缓存
spring.kafka.producer.buffer-memory=33554432
# consumer⽤到的key和value的反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.IntegerDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# consumer的消费组id
spring.kafka.consumer.group-id=spring-kafka-02-consumer
# 是否⾃动提交消费者偏移量
spring.kafka.consumer.enable-auto-commit=true
# 每隔100ms向broker提交⼀次偏移量
spring.kafka.consumer.auto-commit-interval 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









