







一、简介
1.1、消息队列简介
1.1.1、什么是消息队列
消息队列,英文名:Message Queue,经常缩写为MQ。从字面上来理解,消息队列是一种用来存储消息的队列。来看一下下面的代码:
// 1. 创建一个保存字符串的队列
Queue<String> stringQueue = new LinkedList<String>();
// 2. 往消息队列中放入消息
stringQueue.offer("hello");
// 3. 从消息队列中取出消息并打印
System.out.println(stringQueue.poll());
上述代码,创建了一个队列,先往队列中添加了一个消息,然后又从队列中取出了一个消息。这说明了队列是可以用来存取消息的。
我们可以简单理解消息队列就是将需要传输的数据存放在队列中。
1.1.2、消息队列中间件
- 消息队列——用于存放消息的组件
- 程序员可以将消息放入到队列中,也可以从消息队列中获取消息
- 很多时候消息队列不是一个永久性的存储,是作为临时存储存在的(设定一个期限:设置消息在MQ中保存10天)
- 消息队列中间件:消息队列的组件,例如:Kafka、Active MQ、RabbitMQ、RocketMQ、ZeroMQ
RabbitMQ
RabbitMQ开始是用在电信业务的可靠通信的,也是少有的几款支持AMQP协议的产品之一。
优点:
-
轻量级,快速,部署使用方便
-
支持灵活的路由配置。RabbitMQ中,在生产者和队列之间有一个交换器模块。根据配置的路由规则,生产者发送的消息可以发送到不同的队列中。路由规则很灵活,还可以自己实现。
-
RabbitMQ的客户端支持大多数的编程语言,支持AMQP协议。
缺点:
-
如果有大量消息堆积在队列中,性能会急剧下降
-
每秒处理几万到几十万的消息。如果应用要求高的性能,不要选择RabbitMQ。
-
RabbitMQ是Erlang开发的,功能扩展和二次开发代价很高。
RocketMQ
借鉴了Kafka的设计并做了很多改进,几乎具备了消息队列应该具备的所有特性和功能。
优点:
-
RocketMQ主要用于有序,事务,流计算,消息推送,日志流处理,binlog分发等场景。
-
经过了历次的双11考验,性能,稳定性可靠性没的说。
-
java开发,阅读源代码、扩展、二次开发很方便。
-
对电商领域的响应延迟做了很多优化。
-
每秒处理几十万的消息,同时响应在毫秒级。如果应用很关注响应时间,可以使用RocketMQ。
-
性能比RabbitMQ高一个数量级。
-
支持死信队列,DLX 是一个非常有用的特性。它可以处理异常情况下,消息不能够被消费者正确消费而被置入死信队列中的情况,后续分析程序可以通过消费这个死信队列中的内容来分析当时所遇到的异常情况,进而可以改善和优化系统。
缺点:
- 跟周边系统的整合和兼容不是很好。
Kafka
高可用,几乎所有相关的开源软件都支持,满足大多数的应用场景,尤其是大数据和流计算领域,
-
Kafka高效,可伸缩,消息持久化。支持分区、副本和容错。
-
对批处理和异步处理做了大量的设计,因此Kafka可以得到非常高的性能。
-
每秒处理几十万异步消息消息,如果开启了压缩,最终可以达到每秒处理2000w消息的级别。
-
但是由于是异步的和批处理的,延迟也会高,不适合电商场景。
1.1.2.1、为什么叫Kafka呢
Kafka的架构师jay kreps非常喜欢franz kafka(弗兰兹·卡夫卡),并且觉得kafka这个名字很酷,因此取了个和消息传递系统完全不相干的名称kafka,该名字并没有特别的含义。
1.1.3、消息队列的应用场景
1.1.3.1、异步处理
电商网站中,新的用户注册时,需要将用户的信息保存到数据库中,同时还需要额外发送注册的邮件通知、以及短信注册码给用户。但因为发送邮件、发送注册短信需要连接外部的服务器,需要额外等待一段时间,此时,就可以使用消息队列来进行异步处理,从而实现快速响应。
- 可以将一些比较耗时的操作放在其他系统中,通过消息队列将需要进行处理的消息进行存储,其他系统可以消费消息队列中的数据
- 比较常见的:发送短信验证码、发送邮件
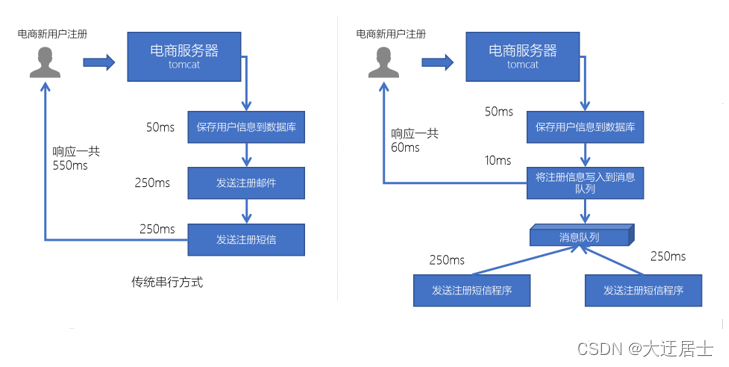
1.1.3.2、系统解耦
- 原先一个微服务是通过接口(HTTP)调用另一个微服务,这时候耦合很严重,只要接口发生变化就会导致系统不可用
- 使用消息队列可以将系统进行解耦合,现在第一个微服务可以将消息放入到消息队列中,另一个微服务可以从消息队列中把消息取出来进行处理。进行系统解耦
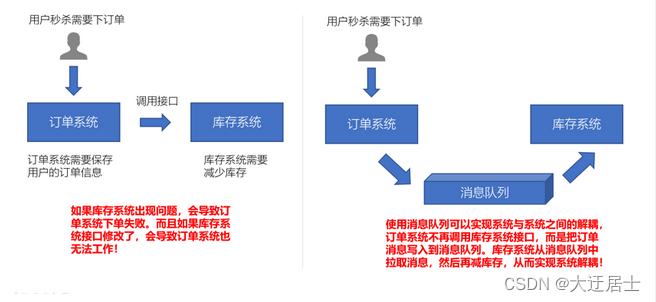
1.1.3.3、流量削峰
- 因为消息队列是低延迟、高可靠、高吞吐的,可以应对大量并发
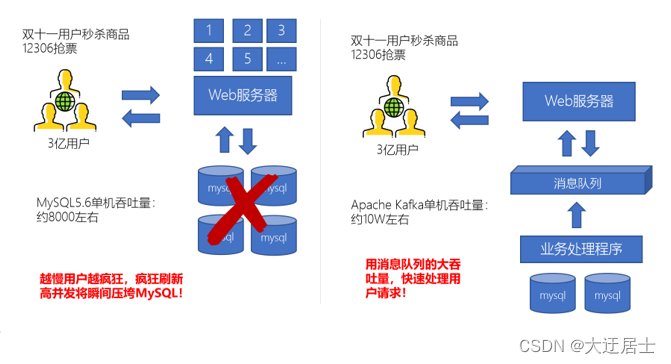
1.1.3.4、日志处理(大数据领域常见)
大型电商网站(淘宝、京东、国美、苏宁…)、App(抖音、美团、滴滴等)等需要分析用户行为,要根据用户的访问行为来发现用户的喜好以及活跃情况,需要在页面上收集大量的用户访问信息。
- 可以使用消息队列作为临时存储,或者一种通信管道
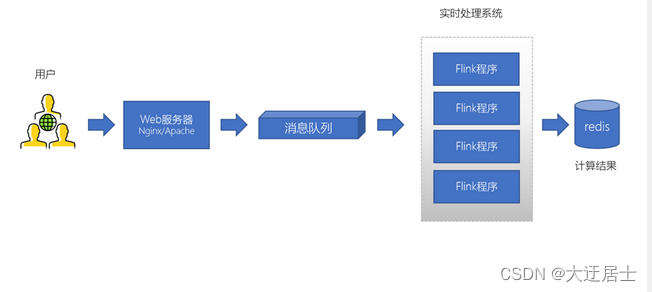
1.1.4、生产者、消费者模型
我们之前学习过Java的服务器开发,Java服务器端开发的交互模型是这样的:
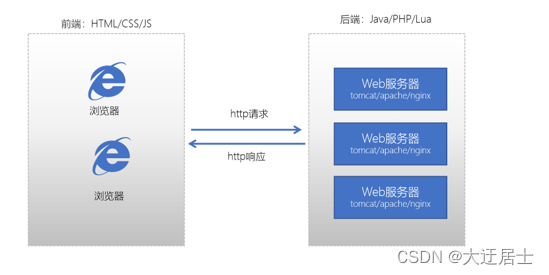
我们之前也学习过使用Java JDBC来访问操作MySQL数据库,它的交互模型是这样的:
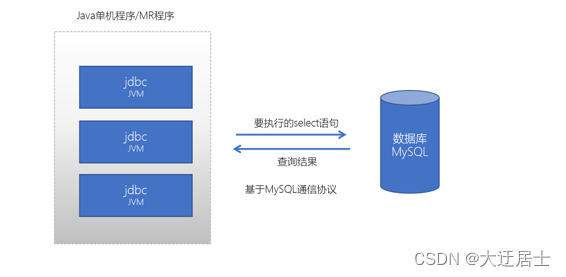
它也是一种请求响应模型,只不过它不再是基于http协议,而是基于MySQL数据库的通信协议。而如果我们基于消息队列来编程,此时的交互模式成为:生产者、消费者模型。
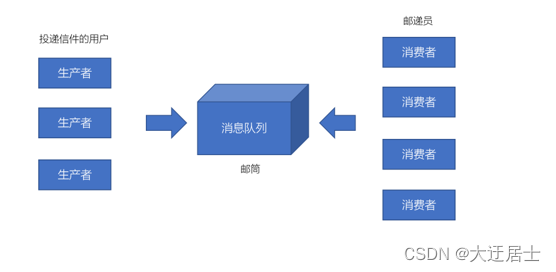
- 生产者、消费者模型
- 生产者负责将消息生产到MQ中
- 消费者负责从MQ中获取消息
- 生产者和消费者是解耦的,可能是生产者一个程序、消费者是另外一个程序
1.1.5、消息队列的两种模式
1.1.5.1、点对点模式
消息发送者生产消息发送到消息队列中,然后消息接收者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
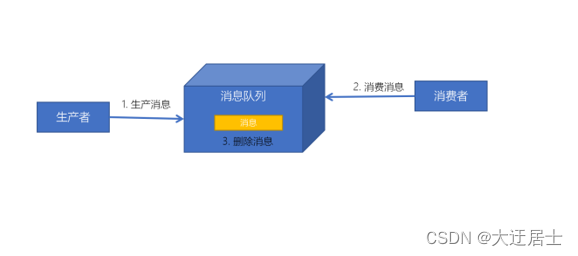
点对点模式特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
1.1.5.2、发布订阅模式
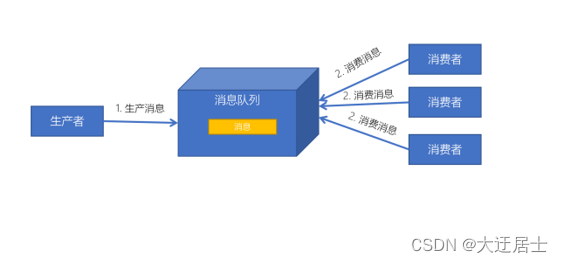
发布/订阅模式特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
1.2、Kafka简介
Kafka官网:http://kafka.apache.org
1.2.1、什么是Kafka
Kafka是由Apache软件基金会开发的一个开源流平台,由Scala和Java编写。Kafka的Apache官网是这样介绍Kakfa的。
Apache Kafka是一个分布式流平台。一个分布式的流平台应该包含3点关键的能力:
- 发布和订阅流数据流,类似于消息队列或者是企业消息传递系统
- 以容错的持久化方式存储数据流
- 处理数据流
我们重点关键三个部分的关键词:
- Publish and subscribe:发布与订阅
- Store:存储
- Process:处理
特性
-
高吞吐量:单机每秒处理几十上百万的消息量。即使存储了TB及消息,也保持稳定的性能。
-
零拷贝 减少内核态到用户态的拷贝,磁盘通过sendfile实现DMA 拷贝Socket buffer
-
顺序读写 充分利用磁盘顺序读写的超高性能
-
页缓存mmap,将磁盘文件映射到内存, 用户通过修改内存就能修改磁盘文件。
-
-
高性能:单节点支持上千个客户端,并保证零停机和零数据丢失。
-
持久化:将消息持久化到磁盘。通过将数据持久化到硬盘以及replication防止数据丢失。
-
分布式系统,易扩展。所有的组件均为分布式的,无需停机即可扩展机器。
-
可靠性 - Kafka是分布式,分区,复制和容错的。
-
客户端状态维护:消息被处理的状态是在Consumer端维护,当失败时能自动平衡。
技术优势
-
可伸缩性:Kafka 的两个重要特性造就了它的可伸缩性。
- Kafka 集群在运行期间可以轻松地扩展或收缩(可以添加或删除代理),而不会宕机。
- 可以扩展一个 Kafka 主题来包含更多的分区。由于一个分区无法扩展到多个代理,所以它的容量受到代理磁盘空间的限制。能够增加分区和代理的数量意味着单个主题可以存储的数据量是没有限制的。
-
容错性和可靠性:Kafka 的设计方式使某个代理的故障能够被集群中的其他代理检测到。由于每个主题都可以在多个代理上复制,所以集群可以在不中断服务的情况下从此类故障中恢复并继续运行。
-
吞吐量:代理能够以超快的速度有效地存储和检索数据。
应用场景
-
日志收集:用Kafka可以收集各种服务的Log,通过大数据平台进行处理;
-
消息系统:解耦生产者和消费者、缓存消息等;
-
用户活动跟踪:Kafka经常被用来记录Web用户或者App用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到Kafka的Topic中,然后消费者通过订阅这些Topic来做运营数据的实时的监控分析,也可保存到数据库;
1.2.2、Kafka的应用场景
我们通常将Apache Kafka用在两类程序:
- 建立实时数据管道,以可靠地在系统或应用程序之间获取数据
- 构建实时流应用程序,以转换或响应数据流
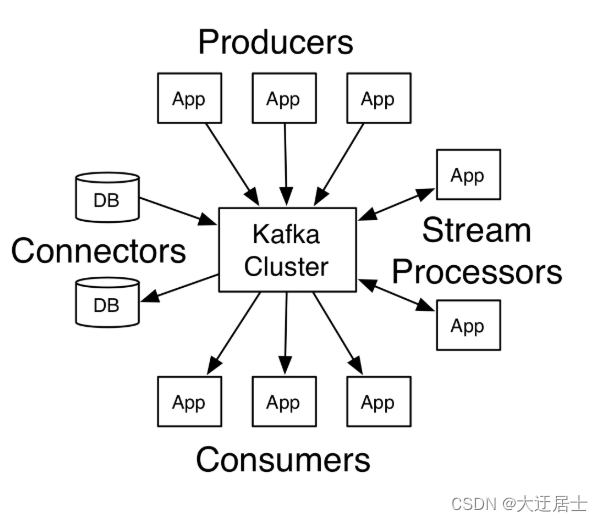
上图,我们可以看到:
- Producers:可以有很多的应用程序,将消息数据放入到Kafka集群中。
- Consumers:可以有很多的应用程序,将消息数据从Kafka集群中拉取出来。
- Connectors:Kafka的连接器可以将数据库中的数据导入到Kafka,也可以将Kafka的数据导出到数据库中。
- Stream Processors:流处理器可以Kafka中拉取数据,也可以将数据写入到Kafka中。
1.2.3、Kafka诞生背景
kafka的诞生,是为了解决linkedin的数据管道问题,起初linkedin采用了ActiveMQ来进行数据交换,大约是在2010年前后,那时的ActiveMQ还远远无法满足linkedin对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,linkedin决定研发自己的消息传递系统,当时linkedin的首席架构师jay kreps便开始组织团队进行消息传递系统的研发。
1.3、Kafka的优势
| ActiveMQ | RabbitMQ | Kafka | RocketMQ | |
|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟 |
| 生产者-消费者模式 | 支持 | 支持 | 支持 | 支持 |
| 发布-订阅 | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 低 | 中 | 高 |
在大数据技术领域,一些重要的组件、框架都支持Apache Kafka,不论成成熟度、社区、性能、可靠性,Kafka都是非常有竞争力的一款产品。
1.4、Kafka生态圈介绍
Apache Kafka这么多年的发展,目前也有一个较庞大的生态圈。
Kafka生态圈官网地址:https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem
1.5、Kafka版本
http://kafka.apache.org/downloads 可以查看到每个版本的发布时间。
二、环境搭配
2.1、 java环境
首先需要安装Java环境,同时配置环境变量,步骤如下:
- 官网下载JDK
- 解压缩,放到指定目录
- 配置环境变量
在/etc/profile文件中配置如下变量
export JAVA_HOME=/java/jdk-12.0.1
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=.:$JAVA_HOME/bin:$JRE_HOME/bin:$KE_HOME/bin:${
MAVEN_HOME}/bin:$PATH
- 测试jdk
java -version
2.2、ZooKeeper的安装
Zookeeper是安装Kafka集群的必要组件,Kafka通过Zookeeper来实施对元数据信息的管理,包括集群、主题、分区等内容。
同样在官网下载安装包到指定目录解压缩,步骤如下:
- ZooKeeper官网:http://zookeeper.apache.org/
- 修改Zookeeper的配置文件,首先进入安装路径conf目录,并将zoo_sample.cfg文件修改为zoo.cfg,并对核心参数进行配置。
文件内容如下:
# The number of milliseconds of each tick
# zk服务器的心跳时间
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# 投票选举新Leader的初始化时间
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 数据目录
dataDir=temp/zookeeper/data
# 日志目录
dataLogDir=temp/zookeeper/log
# the port at which the clients will connect
# Zookeeper对外服务端口,保持默认
clientPort=2181
- 启动Zookeeper命令:bin/zkServer.sh start
angyan@Server-node:/mnt/d/zookeeper-3.4.14$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /mnt/d/zookeeper-3.4.14/bin/../conf/zoo.cfg
//启动成功
Starting zookeeper ... STARTED
angyan@Server-node:/mnt/d/zookeeper-3.4.14$
2.3、搭建Kafka集群
- 将Kafka的安装包上传到虚拟机,并解压
cd /export/software/
tar -xvzf kafka_2.12-2.4.1.tgz -C ../server/
cd /export/server/kafka_2.12-2.4.1/
- 修改 server.properties
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
# 指定broker的id
broker.id=0
# 指定Kafka数据的位置
log.dirs=/export/server/kafka_2.12-2.4.1/data
# 配置zk的三个节点
zookeeper.connect=node1.angyan.cn:2181,node2.angyan.cn:2181,node3.angyan.cn:2181
- 将安装好的kafka复制到另外两台服务器
cd /export/server
scp -r kafka_2.12-2.4.1/ node2.angyan.cn:$PWD
scp -r kafka_2.12-2.4.1/ node3.angyan.cn:$PWD
修改另外两个节点的broker.id分别为1和2
---------node2.angyan.cn--------------
cd /export/server/kafka_2.12-2.4.1/config
vim erver.properties
broker.id=1
--------node3.angyan.cn--------------
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
broker.id=2
- 配置KAFKA_HOME环境变量
vim /etc/profile
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:${
KAFKA_HOME}
分发到各个节点
scp /etc/profile node2.angyan.cn:$PWD
scp /etc/profile node3.angyan.cn:$PWD
每个节点加载环境变量
source /etc/profile
- 启动服务器
# 启动ZooKeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
# 启动Kafka
cd /export/server/kafka_2.12-2.4.1
nohup bin/kafka-server-start.sh config/server.properties &
# 测试Kafka集群是否启动成功
bin/kafka-topics.sh --bootstrap-server node1.angyan.cn:9092 --list
注意:
- 每一个Kafka的节点都需要修改broker.id(每个节点的标识,不能重复)
- log.dir数据存储目录需要配置
2.4、目录结构分析
| 目录名称 | 说明 |
|---|---|
| bin | Kafka的所有执行脚本都在这里。例如:启动Kafka服务器、创建Topic、生产者、消费者程序等等 |
| config | Kafka的所有配置文件 |
| libs | 运行Kafka所需要的所有JAR包 |
| logs | Kafka的所有日志文件,如果Kafka出现一些问题,需要到该目录中去查看异常信息 |
| site-docs | Kafka的网站帮助文件 |
2.5、Kafka一键启动/关闭脚本
为了方便将来进行一键启动、关闭Kafka,我们可以编写一个shell脚本来操作。将来只要执行一次该脚本就可以快速启动/关闭Kafka。
- 在节点1中创建 /export/onekey 目录
cd /export/onekey
- 准备slave配置文件,用于保存要启动哪几个节点上的kafka
node1.angyan.cn
node2.angyan.cn
node3.angyan.cn
- 编写start-kafka.sh脚本
vim start-kafka.sh
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & "
}&
wait
done
- 编写stop-kafka.sh脚本
vim stop-kafka.sh
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9"
}&
wait
done
- 给start-kafka.sh、stop-kafka.sh配置执行权限
chmod u+x start-kafka.sh
chmod u+x stop-kafka.sh
- 执行一键启动、一键关闭
./start-kafka.sh
./stop-kafka.sh
2.6、Kafka测试消息生产与消费
- 首先创建一个主题
命令如下:
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic angyan --partitions 2 --replication-factor 1
–zookeeper:指定了Kafka所连接的Zookeeper服务地址。多个zookeeper用 ‘,’分开。
–topic:指定了所要创建主题的名称
–partitions:指定了分区个数
–replication-factor:指定了副本因子。每个副本分布在不通节点,不能超过总节点数。如你只有一个节点,但是创建时指定副本数为2,就会报错。
–create:创建主题的动作指令
angyan@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic angyan --partitions 2 --replication-factor 1
//主题创建成功
Created topic angyan.
angyan@Server-node:/mnt/d/kafka_2.12-2.2.1$
- 展示所有主题
命令:
bin/kafka-topics.sh --zookeeper localhost:2181 --list
angyan@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper localhost:2181 --list
angyan
angyan@Server-node:/mnt/d/kafka_2.12-2.2.1$
- 查看主题详情
命令:
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic angyan
–describe 查看详情动作指令
angyan@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic angyan
Topic: angyan PartitionCount:2 ReplicationFactor:1 Configs:
Topic: angyan Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: angyan Partition: 1 Leader: 0 Replicas: 0 Isr: 0
angyan@Server-node:/mnt/d/kafka_2.12-2.2.1$
命令:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic angyan
–bootstrap-server 指定了连接Kafka集群的地址
–topic 指定了消费端订阅的主题
angyan@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic angyan
Hello,Kafka!
- 生产端发送消息
命令:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic angyan
–broker-list 指定了连接的Kafka集群的地址
–topic 指定了发送消息时的主题
angyan@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic angyan
>Hello,Kafka!
>
三、基础操作
3.1、创建topic
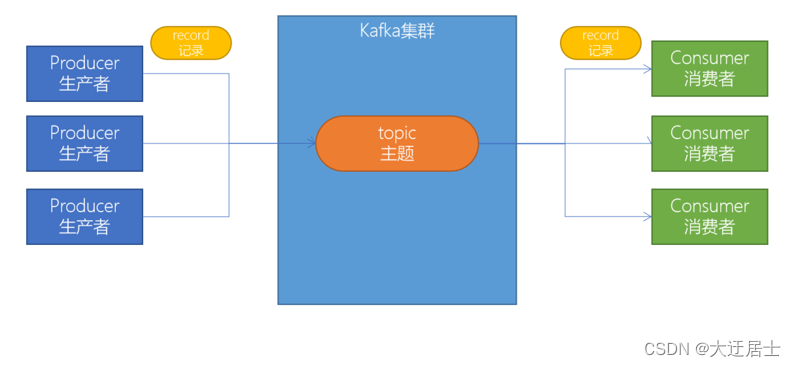
创建一个topic(主题)。Kafka中所有的消息都是保存在主题中,要生产消息到Kafka,首先必须要有一个确定的主题。
# 创建名为test的主题
bin/kafka-topics.sh --create --bootstrap-server node1.angyan.cn:9092 --topic test
# 查看目前Kafka中的主题
bin/kafka-topics.sh --list --bootstrap-server node1.angyan.cn:9092
3.2、生产消息到Kafka
使用Kafka内置的测试程序,生产一些消息到Kafka的test主题中。
bin/kafka-console-producer.sh --broker-list node1.angyan.cn:9092 --topic test
3.3、从Kafka消费消息
使用下面的命令来消费 test 主题中的消息。
bin/kafka-console-consumer.sh --bootstrap-server node1.angyan.cn:9092 --topic test --from-beginning
3.4、使用Kafka Tools操作Kafka
- 安装Kafka集群,可以测试以下
- 创建一个topic主题(消息都是存放在topic中,类似mysql建表的过程)
- 基于kafka的内置测试生产者脚本来读取标准输入(键盘输入)的数据,并放入到topic中
- 基于kafka的内置测试消费者脚本来消费topic中的数据
- 推荐大家开发的使用Kafka Tool
- 浏览Kafka集群节点、多少个topic、多少个分区
- 创建topic/删除topic
- 浏览ZooKeeper中的数据
四、Kafka基准测试
4.1、基准测试
基准测试(benchmark testing)是一种测量和评估软件性能指标的活动。我们可以通过基准测试,了解到软件、硬件的性能水平。主要测试负载的执行时间、传输速度、吞吐量、资源占用率等。
4.1.1、基于1个分区1个副本的基准测试
测试步骤:
- 启动Kafka集群
- 创建一个1个分区1个副本的topic: benchmark
- 同时运行生产者、消费者基准测试程序
- 观察结果
4.1.1.1、创建topic
bin/kafka-topics.sh --zookeeper node1.angyan.cn:2181 --create --topic benchmark --partitions 1 --replication-factor 1
4.1.1.2、生产消息基准测试
在生产环境中,推荐使用生产5000W消息,这样会性能数据会更准确些。为了方便测试,课程上演示测试500W的消息作为基准测试。
bin/kafka-producer-perf-test.sh --topic benchmark --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=node1.angyan.cn:9092,node2.angyan.cn:9092,node3.angyan.cn:9092 acks=1
bin/kafka-producer-perf-test.sh
--topic topic的名字
--num-records 总共指定生产数据量(默认5000W)
--throughput 指定吞吐量——限流(-1不指定)
--record-size record数据大小(字节)
--producer-props bootstrap.servers=192.168.1.20:9092,192.168.1.21:9092,192.168.1.22:9092 acks=1 指定Kafka集群地址,ACK模式
4.1.1.3、消费消息基准测试
bin/kafka-consumer-perf-test.sh --broker-list node1.angyan.cn:9092,node2.angyan.cn:9092,node3.angyan.cn:9092 --topic benchmark --fetch-size 1048576 --messages 5000000
bin/kafka-consumer-perf-test.sh
--broker-list 指定kafka集群地址
--topic 指定topic的名称
--fetch-size 每次拉取的数据大小
--messages 总共要消费的消息个数
五、Java编程操作Kafka
5.1、同步生产消息到Kafka中
5.1.1、需求
接下来,我们将编写Java程序,将1-100的数字消息写入到Kafka中。
5.1.2、准备工作
5.1.2.1、导入Maven Kafka POM依赖
<repositories><!-- 代码库 -->
<repository>
<id>central</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- kafka客户端工具 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2793
2793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









