







目录
1.GC
1.1 什么是垃圾
在程序开发过程中,有这两个问题是最难解决的
- 野指针
- 并发问题
各种语言都有自己针对内存回收的策略,但是一般而言,运行效率往往和开发效率不成正比。因此,要根据实际情况选择开发语言。
C语言申请内存:malloc free
C++: new delete
c/C++ 手动回收内存
Java: new ?
自动内存回收,编程上简单,系统不容易出错,手动释放内存,容易出两种类型的问题:
- 忘记回收
- 多次回收
没有任何引用指向的一个对象或者多个对象(循环引用)
1.2 如何定位垃圾
- 引用计数(ReferenceCount)
- 根可达算法(RootSearching)
1.3 常见的垃圾回收算法
- 标记清除(mark sweep) - 位置不连续 产生碎片 效率偏低(两遍扫描)
- 拷贝算法 (copying) - 没有碎片,浪费空间
- 标记压缩(mark compact) - 没有碎片,效率偏低(两遍扫描,指针需要调整)
1.4 JVM内存分代模型(用于分代垃圾回收算法)

随着内存的不断变大,使用的算法也在变化。但是一般而言,会将内存堆分为两部分来进行垃圾回收:
- 新生代:根据统计有百分之90的对象在创建后,使用一次就没用了,需要进行回收。在回收几次后,如果这个指针还在被引用,则把它移动到老生代。因此,在新生代片区的对象每使用一次就会进行一次拷贝算法。
2.老生代:这片区的引用不常变化,只有在内存满了以后会进行标记压缩法清除垃圾。这样可以减少算法使用带来的开销。

1.5 常见的垃圾回收器
1.垃圾回收器的发展路线,是随着内存越来越大的过程而演进
从分代算法演化到不分代算法
Serial算法 几十兆
Parallel算法 几个G
CMS 几十个G - 承上启下,开始并发回收 -
.- 三色标记 -
2.JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS
并发垃圾回收是因为无法忍受STW
3.Serial 年轻代 串行回收
4.PS 年轻代 并行回收
5.ParNew 年轻代 配合CMS的并行回收
6.SerialOld
7.ParallelOld
8.ConcurrentMarkSweep 老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms)
CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定
CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收
想象一下:
PS + PO -> 加内存 换垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW)
几十个G的内存,单线程回收 -> G1 + FGC 几十个G -> 上T内存的服务器 ZGC
算法:三色标记 + Incremental Update
9.G1(200ms - 10ms)
算法:三色标记 + SATB
10.ZGC (10ms - 1ms) PK C++
算法:ColoredPointers + LoadBarrier
11.Shenandoah
算法:ColoredPointers + WriteBarrier
12.Eplison
PS 和 PN区别的延伸阅读:
▪https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html#GUID-3D0BB91E-9BFF-4EBB-B523-14493A860E73
14.垃圾收集器跟内存大小的关系
Serial 几十兆
PS 上百兆 - 几个G
CMS - 20G
G1 - 上百G
ZGC - 4T - 16T(JDK13)
1.8默认的垃圾回收:PS + ParallelOld
1.6 CMS
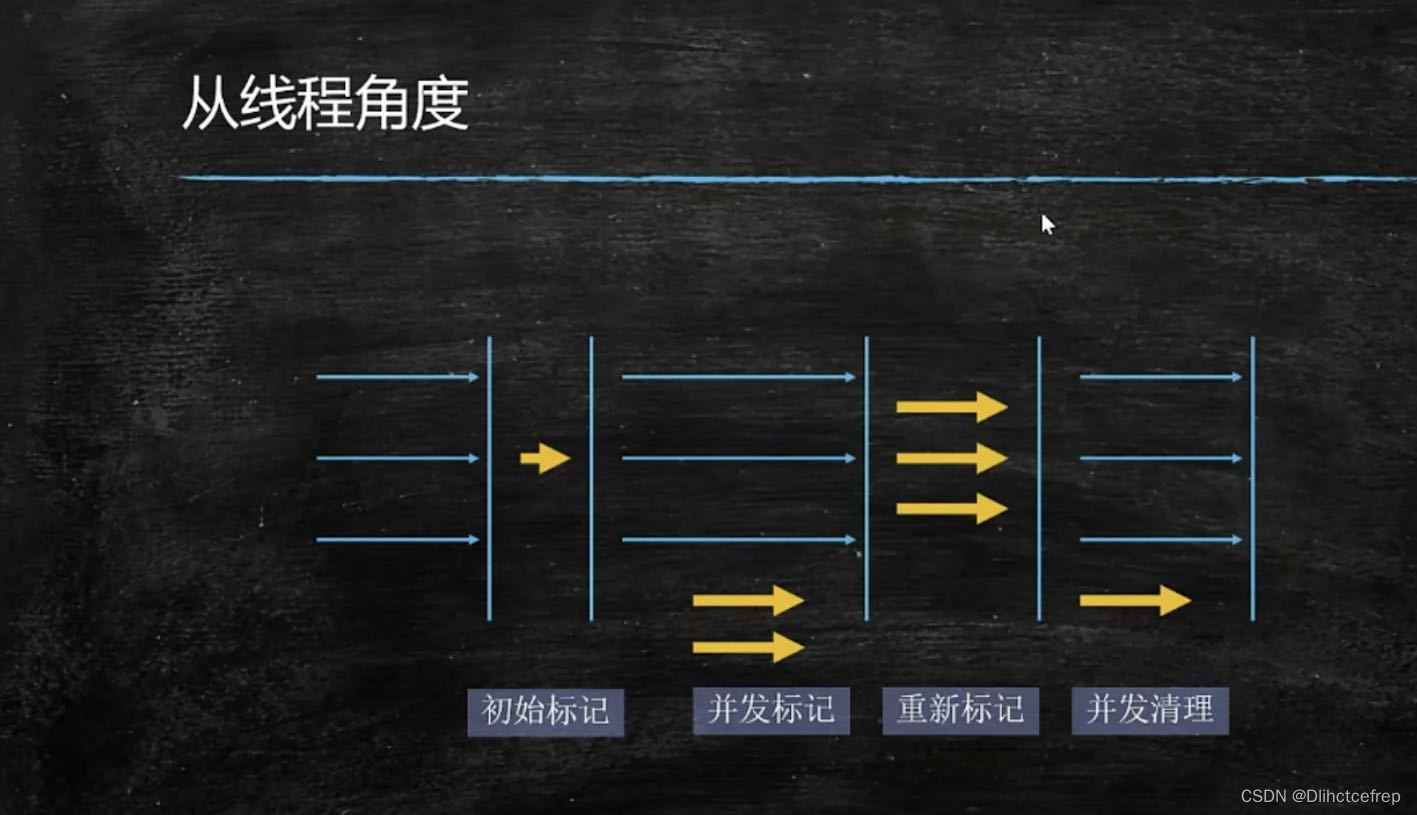
Concurrent GC是针对于大内存的,并且可以和业务线程同时执行。主要讲一下CMS的回收机制:会进行三次标记,一次处理。重新标记是为了解决并发标记错误的地方。初始标记是找到root对象,会重新标记一样需要Stop the word(暂停业务)。
- 并发标记:三色标记算法
对于三色标记算法而言, 对象会根据是否被访问过(也就是是否在可达性分析过程中被检查过)被分为三个颜色:白色、灰色和黑色: - 白色:这个对象还没有被访问过,在初始阶段,所有对象都是白色,所有都枚举完仍是白色的对象将会被当做垃圾对象被清理。
- 灰色:这个对象已经被访问过,但是这个对象所直接引用的对象中,至少还有一个没有被访问到,表示这个对象正在枚举中。
- 黑色:对象和它所直接引用的所有对象都被访问过。这里只要访问过就行,比如A只引用了B,B引用了C、D,那么只要A和B都被访问过,A就是黑色,即使B所引用的C或D还没有被访问到,此时B就是灰色。
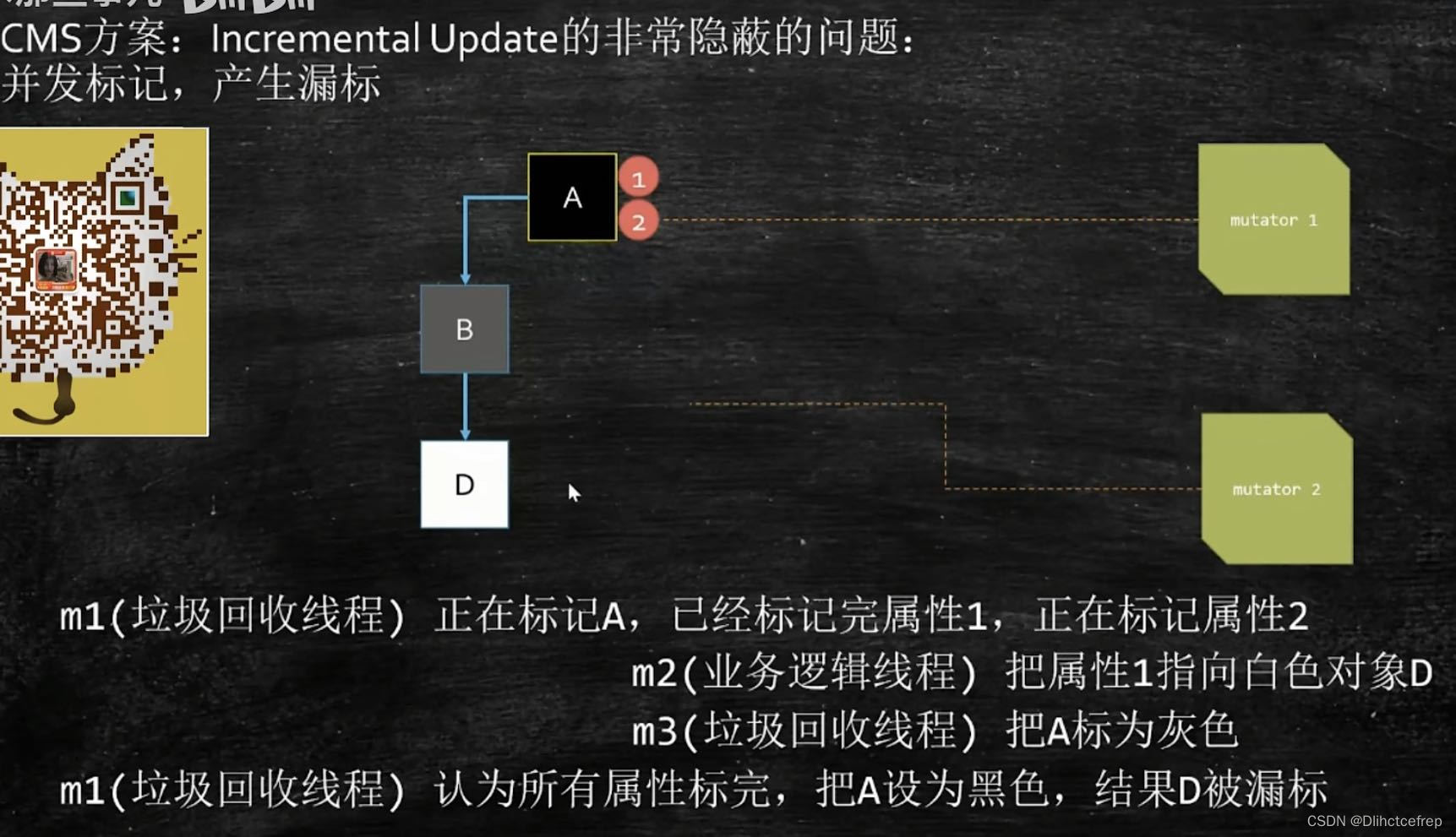
由于CMS会有漏标的bug,因此有了G1
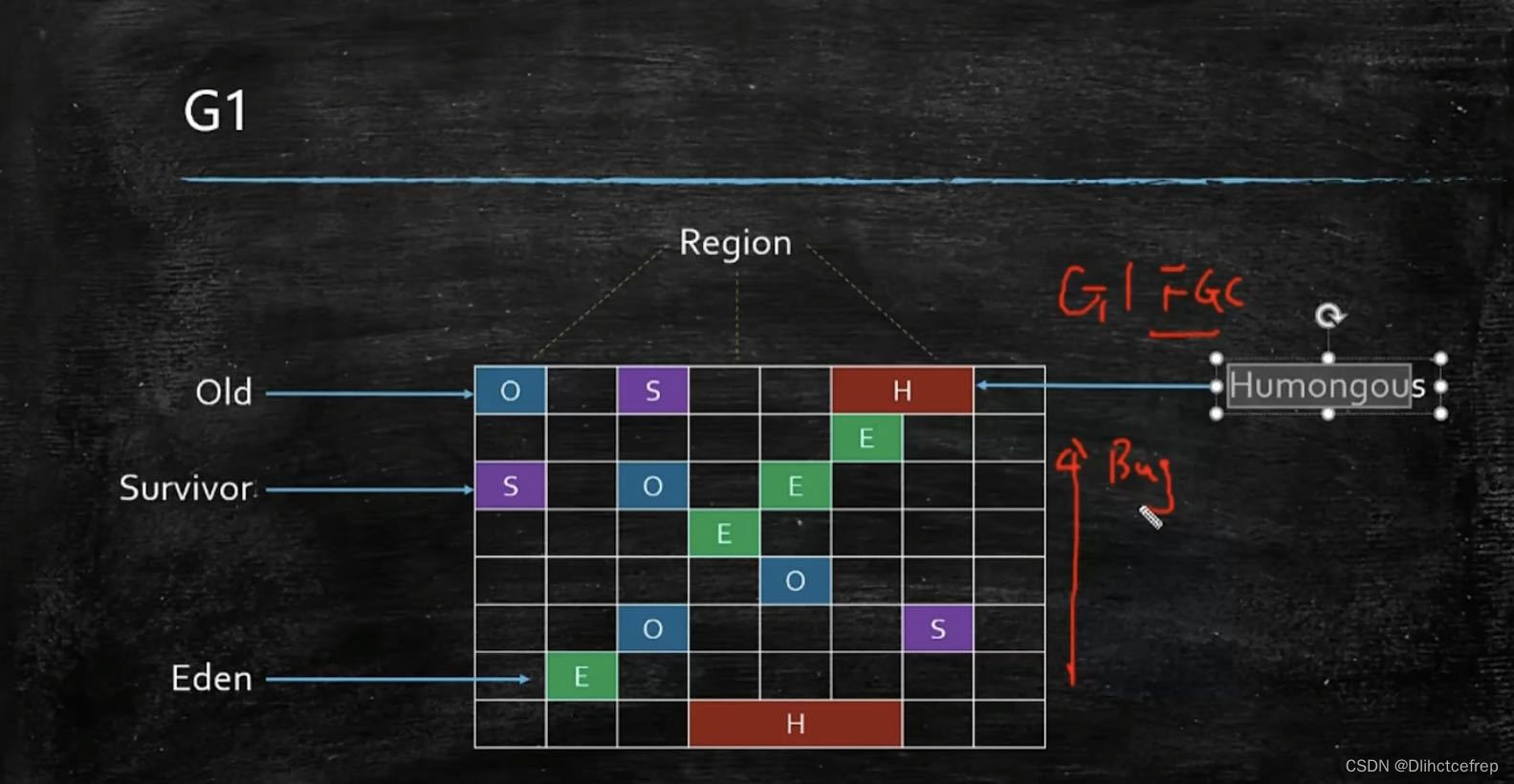
1.7 G1
2. 调优
调优前的基础概念:
吞吐量:用户代码时间 /(用户代码执行时间 + 垃圾回收时间)
响应时间:STW越短,响应时间越好
所谓调优,首先确定,追求啥?吞吐量优先,还是响应时间优先?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量…
问题:
科学计算,吞吐量。数据挖掘,thrput。吞吐量优先的一般:(PS + PO)
响应时间:网站 GUI API (1.8 G1)
什么是调优?
1.根据需求进行JVM规划和预调优
2.优化运行JVM运行环境(慢,卡顿)
3.解决JVM运行过程中出现的各种问题(OOM)
2.1 小案例
一个案例理解常用工具
测试代码:
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 从数据库中读取信用数据,套用模型,并把结果进行记录和传输
*/
public class T15_FullGC_Problem01 {
private static class CardInfo {
BigDecimal price = new BigDecimal(0.0);
String name = "张三";
int age = 5;
Date birthdate = new Date();
public void m() {}
}
private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50,
new ThreadPoolExecutor.DiscardOldestPolicy());
public static void main(String[] args) throws Exception {
executor.setMaximumPoolSize(50);
for (;;){
modelFit();
Thread.sleep(100);
}
}
private static void modelFit(){
List<CardInfo> taskList = getAllCardInfo();
taskList.forEach(info -> {
// do something
executor.scheduleWithFixedDelay(() -> {
//do sth with info
info.m();
}, 2, 3, TimeUnit.SECONDS);
});
}
private static List<CardInfo> getAllCardInfo(){
List<CardInfo> taskList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
CardInfo ci = new CardInfo();
taskList.add(ci);
}
return taskList;
}
}
如果内存占很多,先top找进程,再top -Hp找到进程里的线程,然后再jstack 线程追踪栈。判断是业务线程还是gc线程,然后根据类型进行处理。
优化环境
1.有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了
为什么原网站慢?
很多用户浏览数据,很多数据load到内存,内存不足,频繁GC,STW长,响应时间变慢
为什么会更卡顿?
内存越大,FGC时间越长
咋办?
PS -> PN + CMS 或者 G1
2.系统CPU经常100%,如何调优?(面试高频)
CPU100%那么一定有线程在占用系统资源,
找出哪个进程cpu高(top)
该进程中的哪个线程cpu高(top -Hp)
导出该线程的堆栈 (jstack)
查找哪个方法(栈帧)消耗时间 (jstack)
工作线程占比高 | 垃圾回收线程占比高
3.系统内存飙高,如何查找问题?(面试高频)
导出堆内存 (jmap),但是会STW
分析 (jhat jvisualvm mat jprofiler … )
如何监控JVM
jstat jvisualvm jprofiler arthas top…
jmap -dump:format=b,file=xxx pid :
线上系统,内存特别大,jmap执行期间会对进程产生很大影响,甚至卡顿(电商不适合)
1:设定了参数HeapDump,OOM的时候会自动产生堆转储文件(不是很专业,因为多有监控,内存增长就会报警)
2:很多服务器备份(高可用),停掉这台服务器对其他服务器不影响
3:在线定位(一般小点儿公司用不到)
4:在测试环境中压测(产生类似内存增长问题,在堆还不是很大的时候进行转储)
- java -Xms20M -Xmx20M -XX:+UseParallelGC -XX:+HeapDumpOnOutOfMemoryError com.mashibing.jvm.gc.T15_FullGC_Problem01
- 使用MAT / jhat /jvisualvm 进行dump文件分析https://www.cnblogs.com/baihuitestsoftware/articles/6406271.html
jhat -J-mx512M xxx.dumphttp://192.168.17.11:7000
拉到最后:找到对应链接
可以使用OQL查找特定问题对象
3. JVM基础
3.1 Class文件解读
JVM能运行所有class规范的文件
class文件是二进制字节流
https://blog.csdn.net/weixin_30502157/article/details/97460811
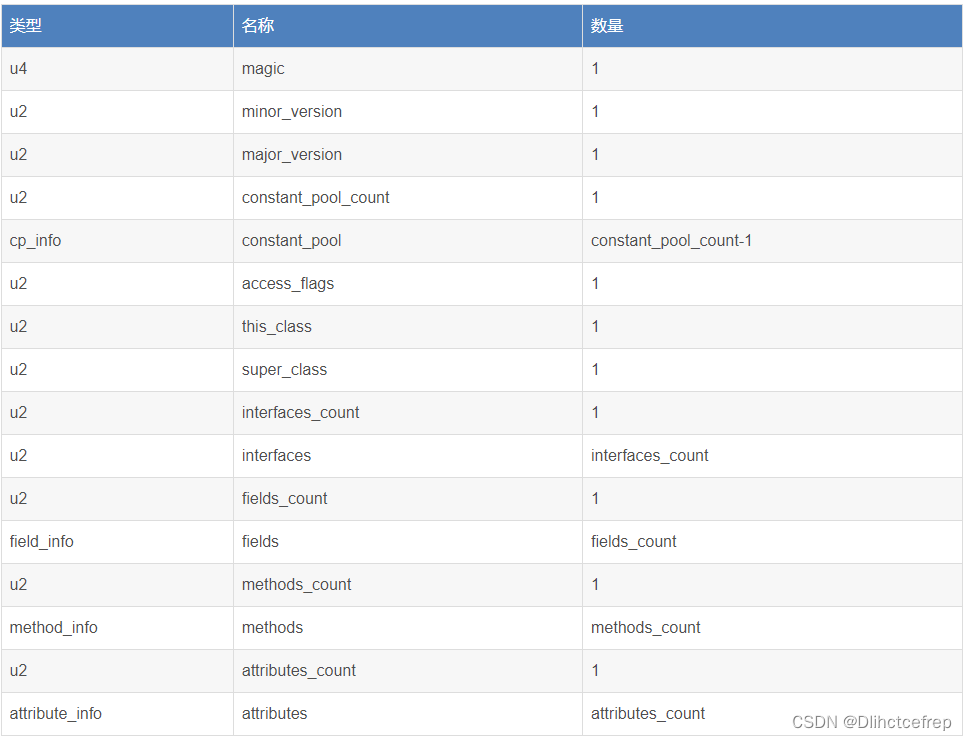
我们可以在IDEA里安装JClassLib插件,来看class文件相关的信息。

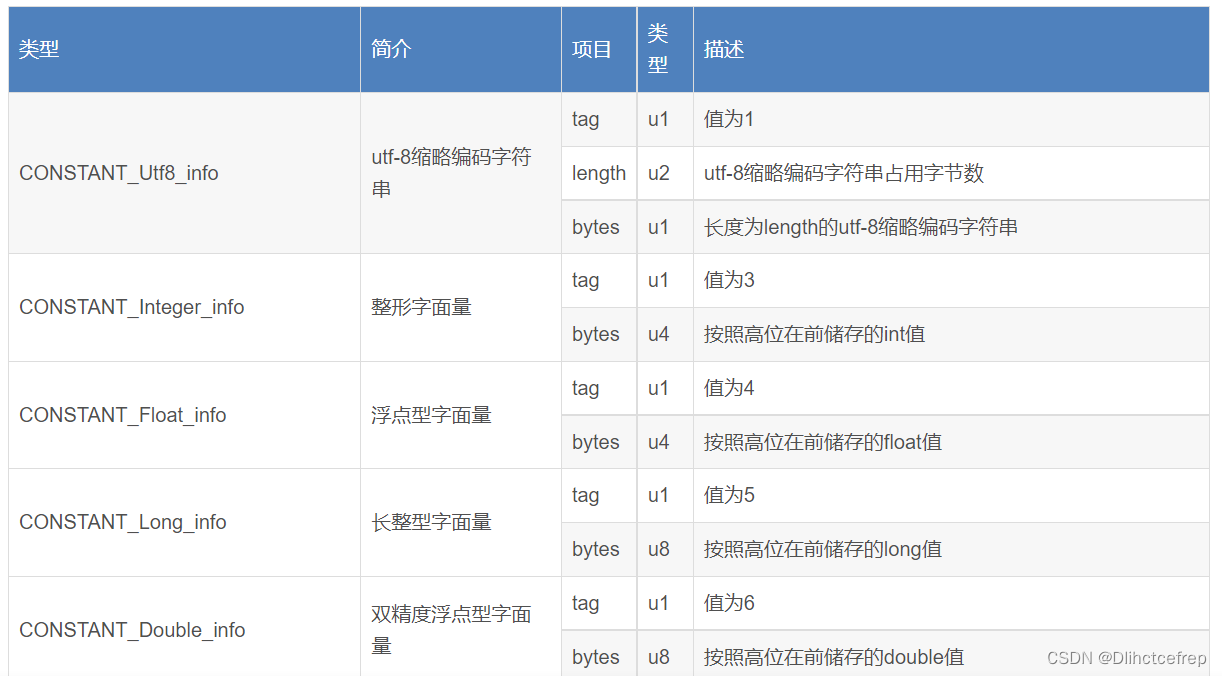
在jdk1.8后,又增加了三个字段
3.2 解读案例
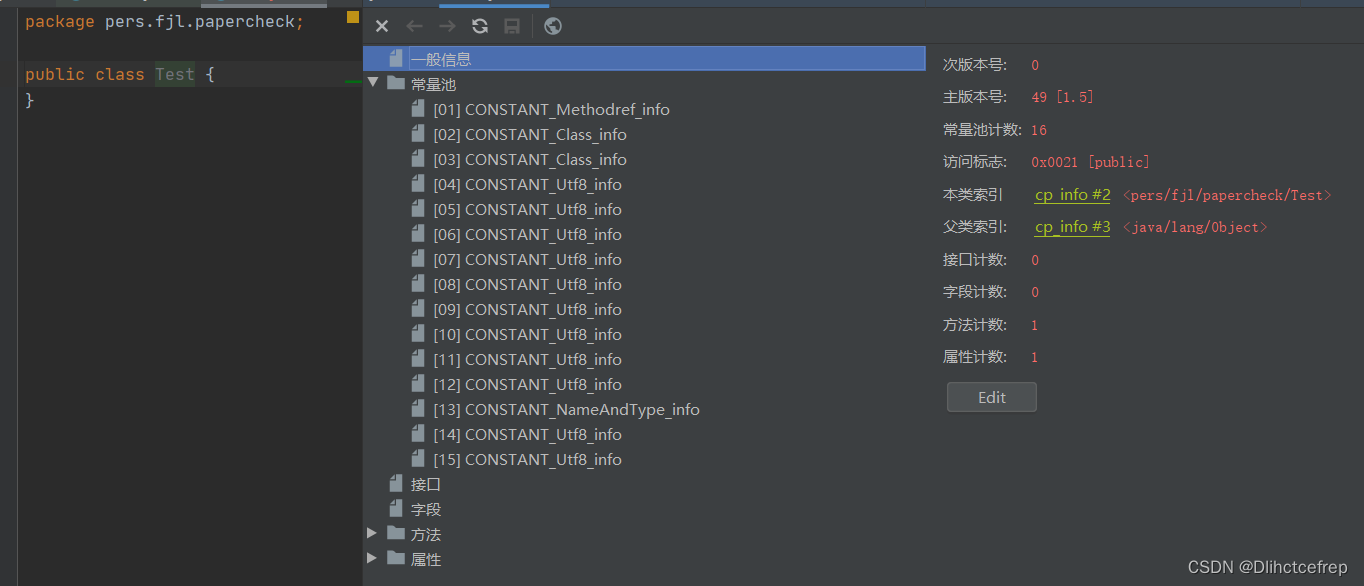
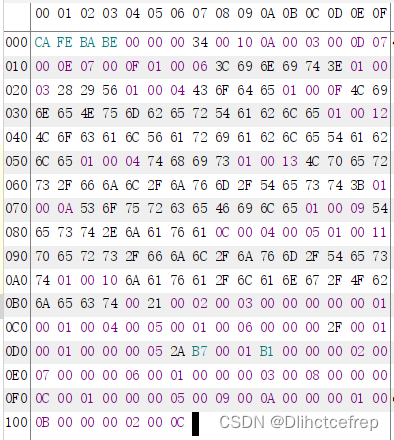

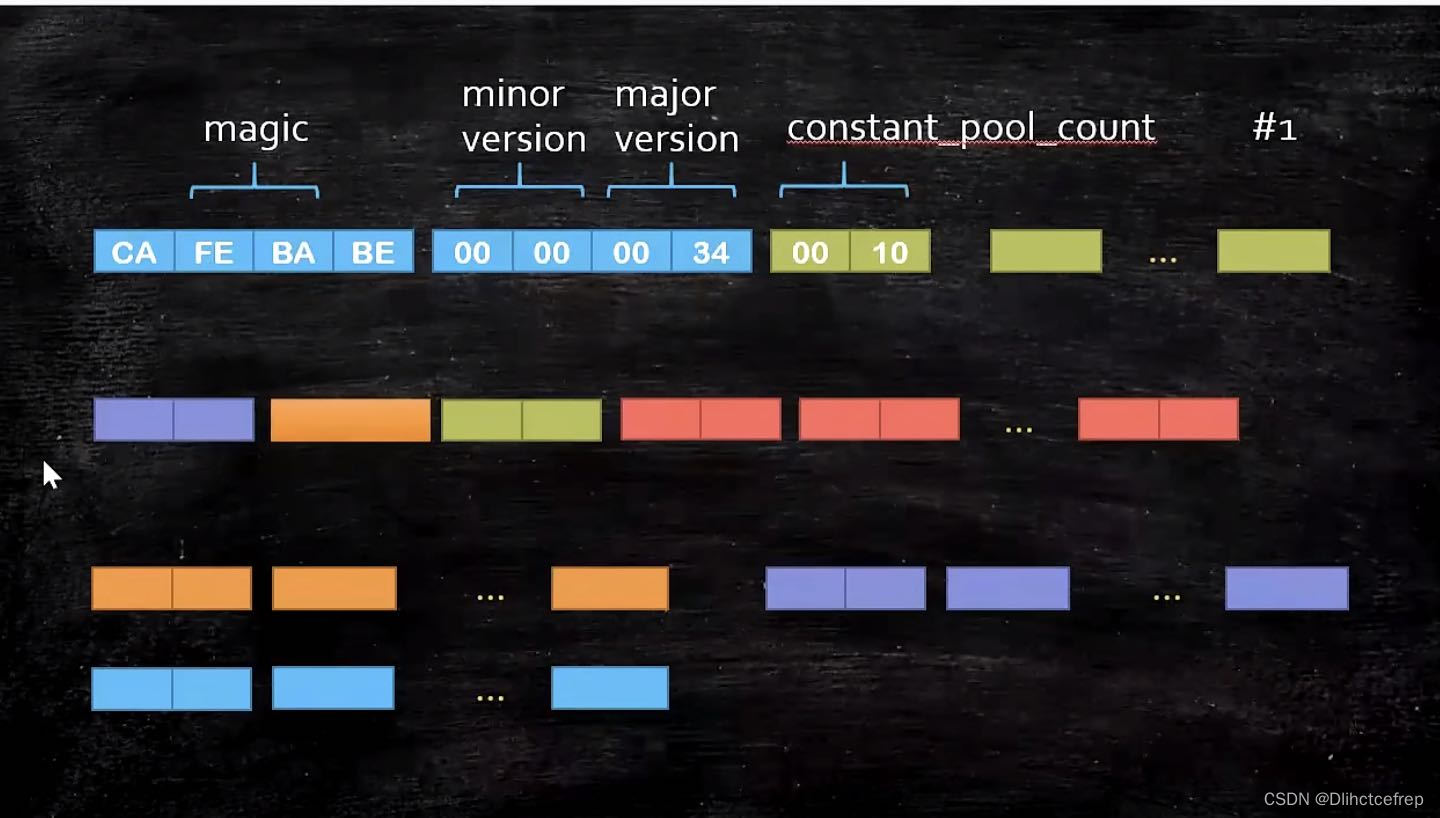
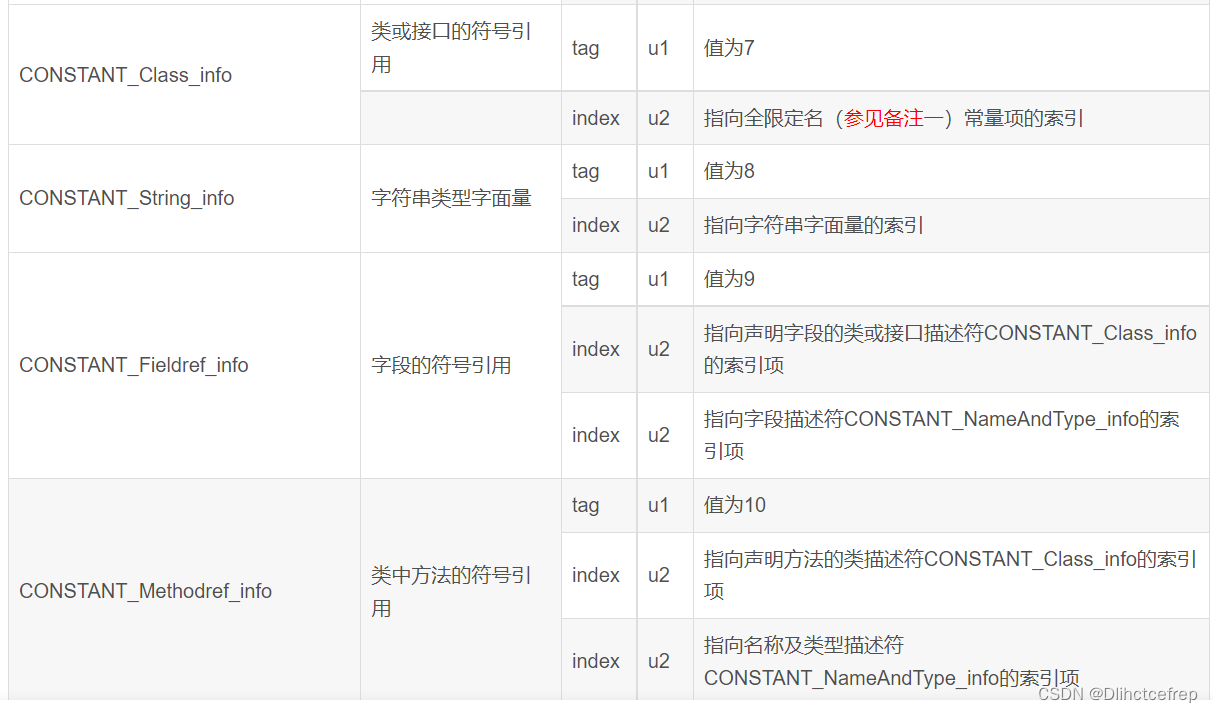
将class文件以16进制的形式观看,可以知道的是常量池数开始的右边第一个字节索引便是常量1:#1。此时,我们要对照表来看,0A代表着10。即tag值为10。
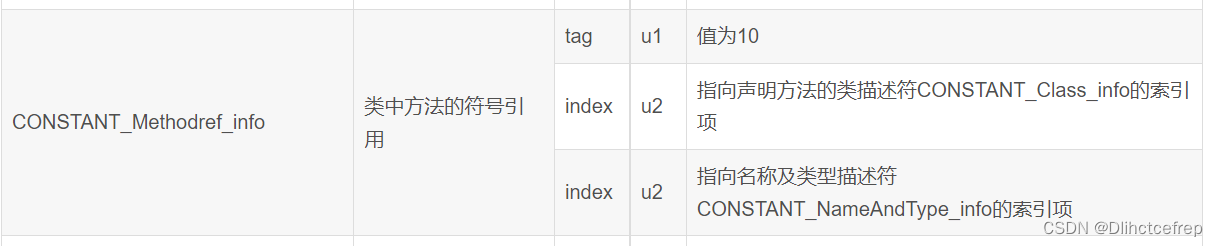
0A后面的两个字节指向声明方法的类描述符,即00 03。
再后面两个字节指向名称及类型描述符,即00 0D。

3.3 类加载器
将class文件从硬盘,加载到内存。
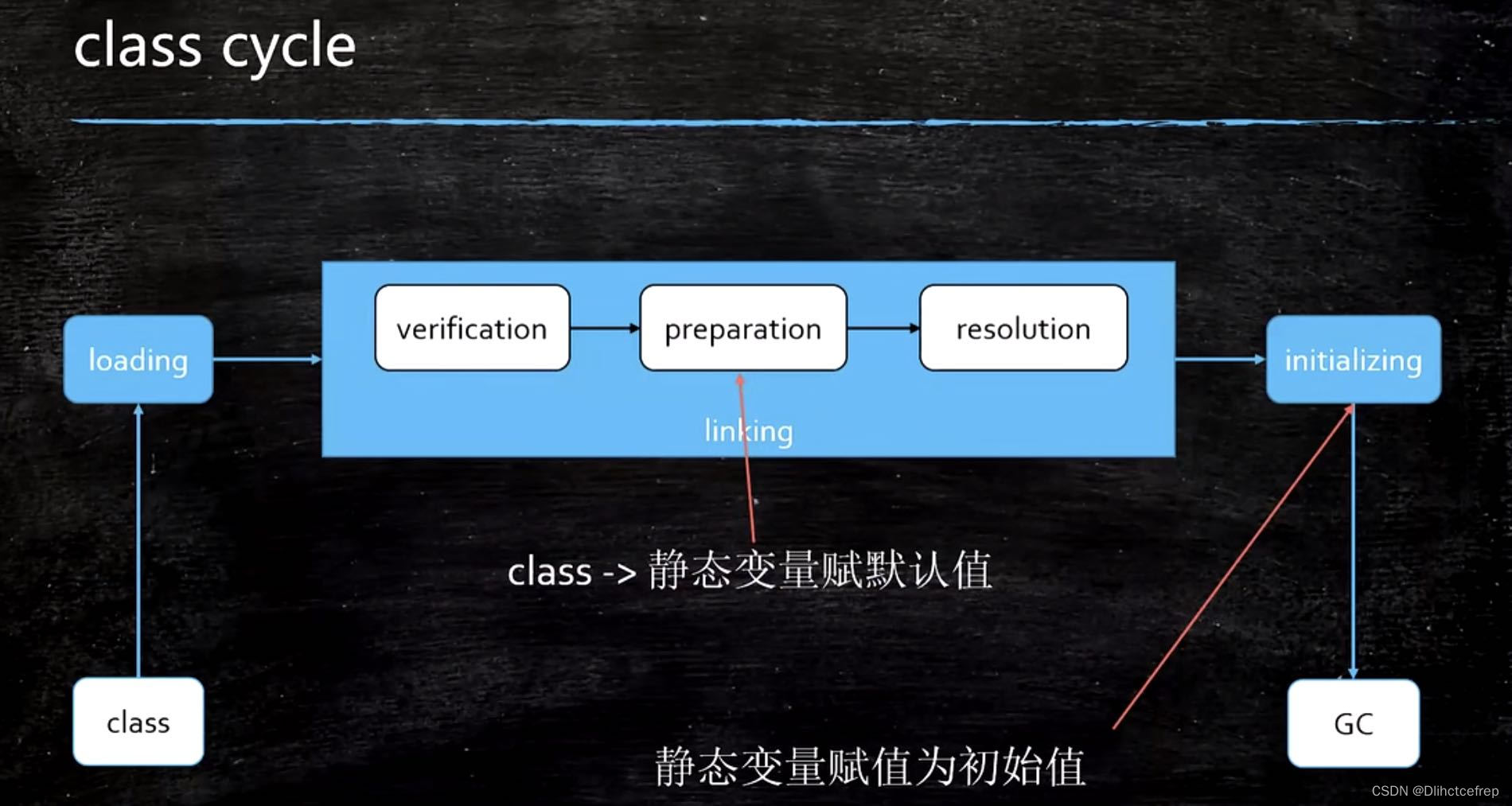
3.3.1 加载过程
- Loading
- Linking
2.1 Verification
2.2 Preparation 静态变量赋予默认值(0)
2.3 Resolution - Initializing 静态变量赋予初始值
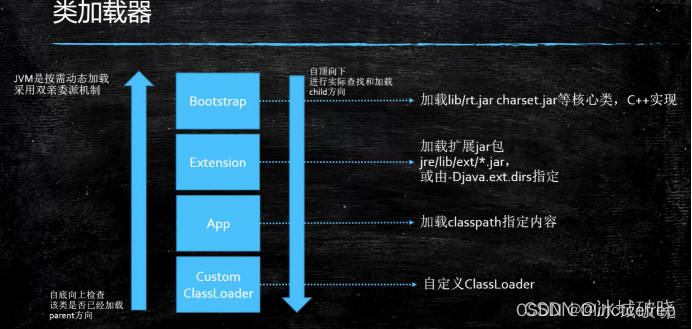
1.最高层级:Bootstrap : 所有jdk的核心类库,比如String,Object… 都由它来加载,内部由C++实现,所以在调用java.lang.String.class.getClassLoader返回的是null。Java并不能正确地找到它。
2.Extension(ExtClassLoader):jre/lib/ext文件夹下的所有类由它来加载。
3.App(Application,AppClassLoader):所有CLASSPATH下的类由它来加载
4.CustomerClassLoader:用户自定义类加载器,用来加载用户指定的类。
实际上类加载器在Java内部也是一个类。所有的类加载器都是由顶层的Bootstrap来load到内存当中的,之后,它们再去load其他类。
值得一提的是,类加载器的层次并不是它们的父子关系,也就是说Extension的父类并不是Bootstrap,App的父类并不是Extension。所有ClassLoader的顶级父类是ClassLoader类。类加载的子父类关系如下所示:
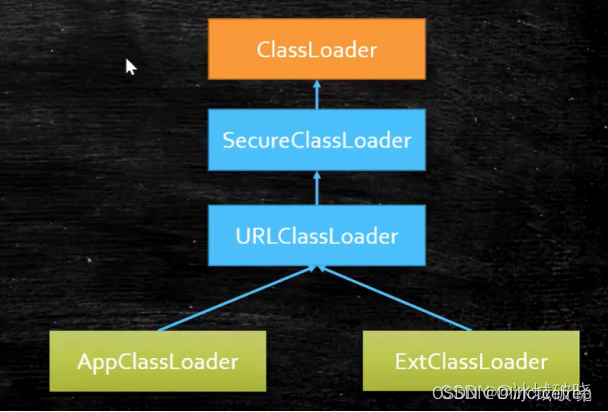
通过类名.class.getClassLoader()获得到的类加载器格式如下:
正常的类显示应为:类名+HashCode码。其中$的意思是:ExtClassLoader是sun.misc.Launcher类中的一个内部类。中间用$标注。
3.3.2 双亲委派
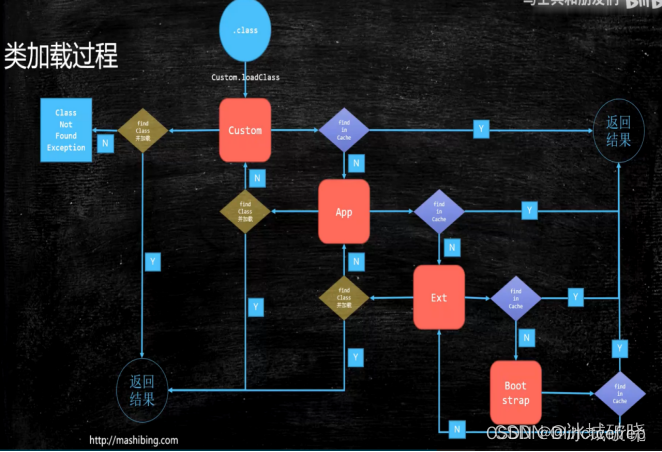
一个类被load到内存的过程采用了双亲委派机制。整个ClassLoader的层次会被遍历两遍

加入当一个类:S 需要load到内存时,首先会从CustomClassLoader开始询问,当前加载器是否已经加载了S类,类加载器会在自己内部的容器中寻找是否有S,如果有,则返回。如果没有则向上一层询问App是否加载了这个类。以此类推到Bootstrap,**如果依旧没有返回,则Bootstrap开始尝试加载这个类,**如果不归自己加载,则指派下一层的Ext去加载这个类,如果依旧不归Ext管,则再由Ext指派App。以此类推到CustomClassLoader,如果都不能load这个类,则抛出ClassNotFoundException。
以上过程就是双亲委派。先由底向上询问是否已经初始化,如果没有则从高向下指派加载器去加载类。
为什么使用双亲委派机制?
- 安全
这是最关键的点。在load类的过程中,如果我们自己定义了一个java.lang.String,想去覆盖JDK核心类库中的String并在其中添加具有攻击性的代码,如果我们规定一个自定义加载器去加载,那么就会产生严重的问题。所有使用了这个类的用户都会被影响。所以自定义加载器会先向上询问是否已经加载,到Bootstrap时,它会返回已经存在的真正JDK核心类库中的java.lang.String,防止出现安全问题。双亲委派过程是写死的,即使自定义了类加载器可以加载,也会先经过双亲委派机制。- 防止资源浪费
对于一个类load到内存应该是单例的,即每个类只应该拥有一个自己的Class类。所以每次先询问的过程就可以防止一个类被多次load到内存中,浪费资源。
3.3.3 自定义类加载器
loadClass(),在硬盘查找class文件,load进内存,并创建这个class对象。
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
阅读源码的loadClass方法可知,加载的过程首先判断当前类加载器有无缓存的class,如果没有。则向上找父加载器,重复此操作。
Class<?> c = findLoadedClass(name);
if (c == null) { //没有缓存,代表没加载过
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else { //找到顶部Bootstrap
c = findBootstrapClassOrNull(name);
}
}
自己的父类加载器没有加载此class,只能往下递归然后自己创建该class对象
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
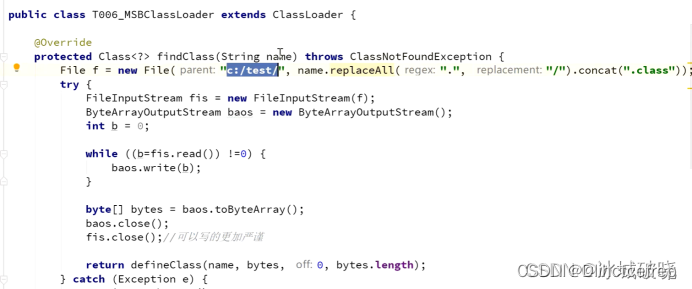
总的来说就几步,在继承了ClassLoader类后,我们只需要重写findClass方法。首先将文件读取到内存,并拿着二进制的文件和文件名去创建class。
- 可以自定义类加载器实现加密功能:编写seed进行异或操作(任何东西异或两次就是他本身),解密只需要再异或一次
- 编译器是混合模式:解释和编译都有,短时间内调用频率多的就会进行编译。
- 懒加载:在需要这个类时,才会按需加载
3.4 初始化操作
- verificaition:验证cafe baby
- preparation:静态成员变量赋予默认值
- resolution:将类、方法、属性等符号引用解析为直接引用。常量池中的各种符号引用解析为指针、偏移量等内存地址的直接引用。(常量池的引用,A指向了B,B指向了LObject,A对B的就是符号引用,要直接解析为地址引用即指向LObject)
- Initializing:给静态变量赋初始值
先看个小程序,可以先猜一下会打印几。

答案是3,那如果把第十行和第十一行两行代码倒换顺序如下,答案是多少呢?:
public static T t = new T();
public static int count = 2;
没错,是2。
在调用代码时,首先loading将T001_ClassLoadingProcedure这个类加载进内存。然后验证,然后将静态变量赋默认值。下面这行代码的默认值是null,
public static T t = new T();
下面这行count默认值是0.
public static int count = 2;
然后,进行初始化,按照顺序 public static T t = new T();,但是count的值此时为0,count++就变为1。
然后是public static int count = 2; 因此,count就为2。
类的加载和初始化的过程。大概顺序如下:
父类静态变量/静态块(顺序执行)->子类静态变量/静态块(顺序执行)->父类实例变量/构造块(顺序执行)->父类构造器->子类实例变量/构造块(顺序执行)->子类构造器
也可以看看单例模式 双重锁解析这篇文章
https://www.cnblogs.com/liaowenhui/p/12772744.html
https://www.runoob.com/design-pattern/singleton-pattern.html
3.5 Java Memory Model

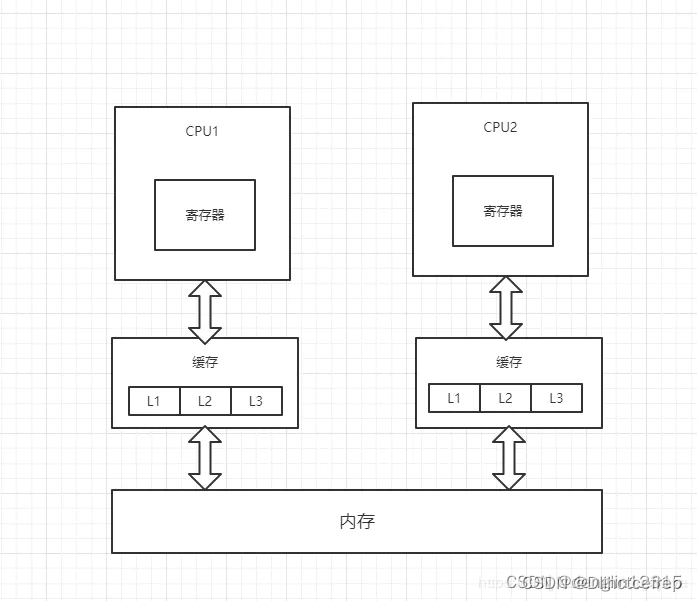

两个线程访问两个CPU,该怎么保证数据的一致性呢?
老的CPU是加总线锁,线程一读取X时,就加锁。(效率太低)
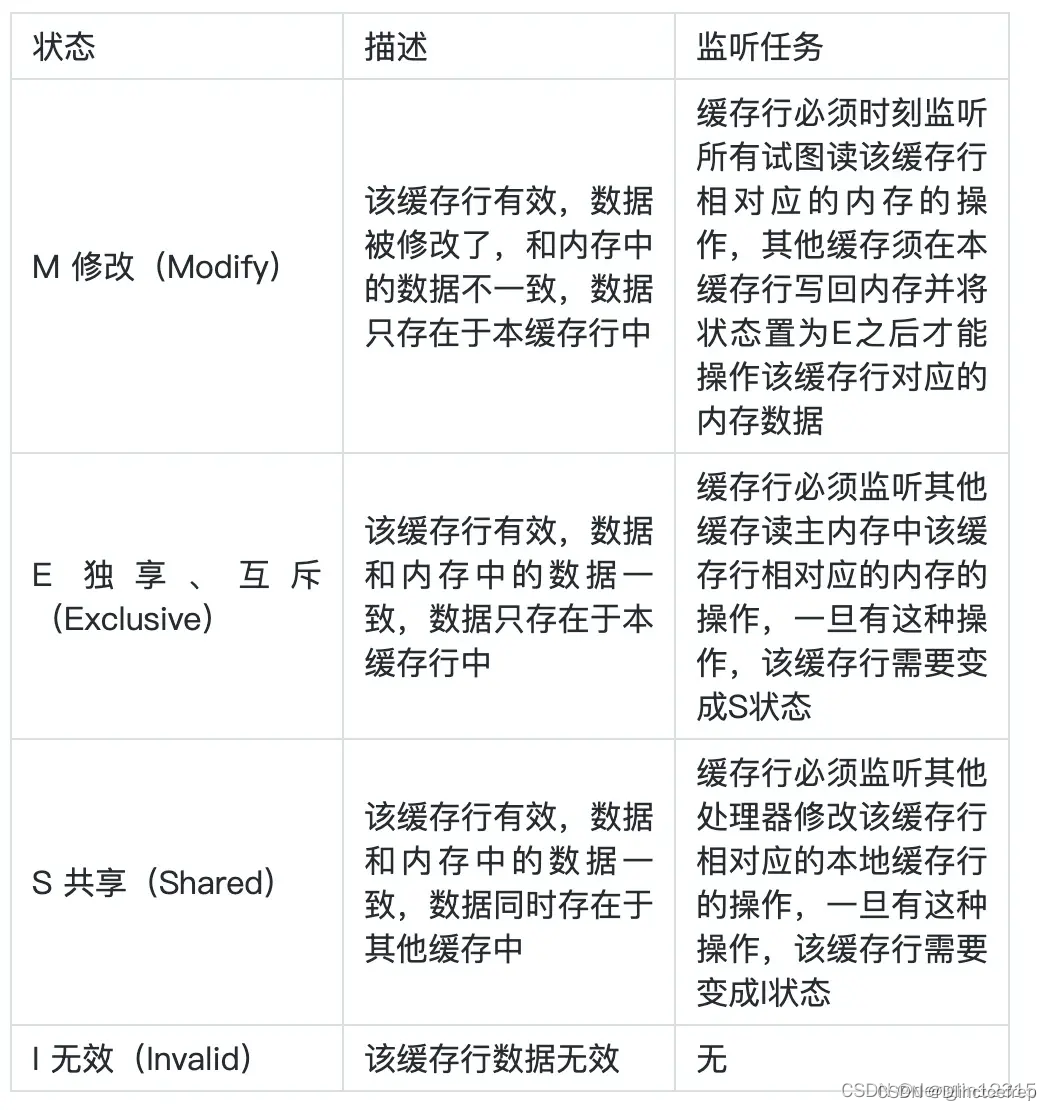
3.5.1 MESI Cache一致性协议
-
- 伪共享
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
设想如果我们有个long类型的变量a,它不是数组的一部分,而是一个单独的变量,并且还有另外一个long类型的变量b紧挨着它,那么当加载a的时候将免费加载b。
看起来似乎没有什么问题,但是如果一个cpu核心的线程在对a进行修改,另一个cpu核心的线程却在对b进行读取。当前者修改a时,会把a和b同时加载到前者核心的缓存行中,更新完a后其它所有包含a的缓存行都将失效,因为其它缓存中的a不是最新值了。而当后者读取b时,发现这个缓存行已经失效了,需要从主内存中重新加载。
请记着,我们的缓存都是以缓存行作为一个单位来处理的,所以失效a的缓存的同时,也会把b失效,反之亦然。

这样就出现了一个问题,b和a完全不相干,每次却要因为a的更新需要从主内存重新读取,它被缓存未命中给拖慢了。这就是传说中的伪共享。
为了提高效率,可以将缓存行对齐。即可以凑齐64字节
class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
}
3.5.2 乱序问题
CPU的执行速度要比内存高很多倍。
当CPU读取了内存的五条指令时,如果他们按序执行,会浪费很多时间(执行第一条指令时,还得去内存获取数据,很浪费时间)
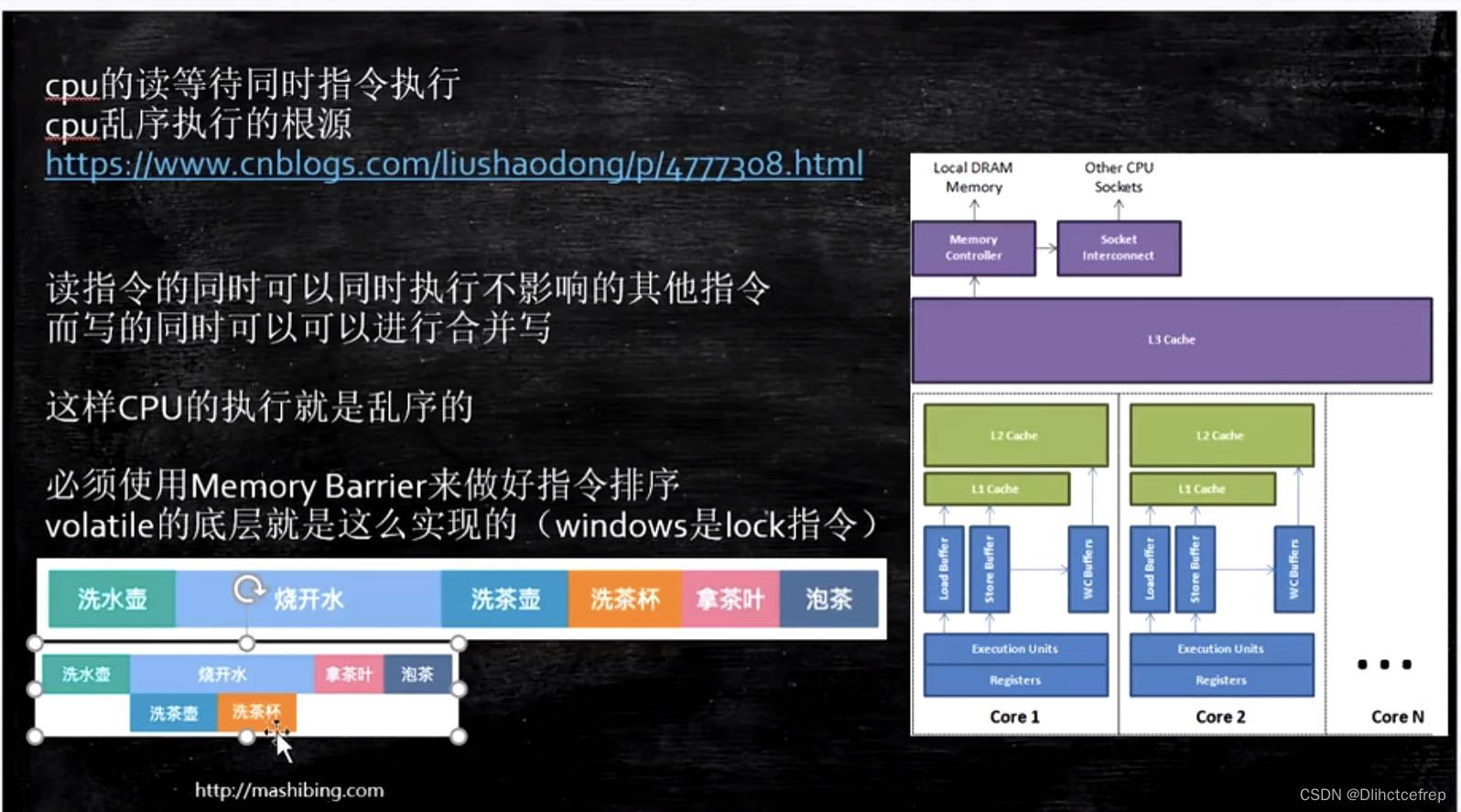
所以CPU为了提高执行效率,不等你第一条执行完,就同时执行第二条(前提是两条指令没有依赖关系)
为了保证指令不重排,只能加内存屏障,例如加volatile

3.6 Volatile
- 字节码层面:ACC_VOLATILE(加了个flag)
- JVM层面:

- OS和硬件层面:hsdis工具查看汇编,windows是lock指令实现
3.7 synchronized
- 字节码层面:方法时ACC_SYNCHRONIZED,语句块是开始moniterenter 结束monitorexit
- JVM层面:C和C++调用了操作系统提供的同步机制,
- OS和硬件层面:windows x86是lock指令实现
https://blog.csdn.net/21aspnet/article/details/88571740















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









