







Spark
一、Spark介绍
1.1 简介、特点
1) 开发语言:scala,同时兼顾java,有时会用到pathon
2)Spark是一种快速、通用、可扩展的大数据分析引擎
3)特点:
快速高效
简洁易用
可以运行在各种资源调度框架和读写多种数据源
通用性高
多种部署方案
丰富的数据源支持
1.2 面试题MR与spark的最大区别
1.MR只能做离线计算。如果实现复杂计算逻辑,一个MR搞不定,就需要将多个MR按照先后顺序连成一串,一个MR计算完成后会将计算结果写入到HDFS中,下一个MR将上一个MR的输出作为输入,这样就要频繁读写HDFS,网络IO和磁盘IO会成为性能瓶颈。从而导致效率低下。
2.既可以做离线计算,有可以做实时计算,提供了抽象的数据集(RDD、Dataset、DataFrame、DStream)有高度封装的API,算子丰富,并且使用了更先进的DAG有向无环图调度思想,可以对执行计划优化后在执行,并且可以数据可以cache到内存中进行复用。
注意:MR和Spark在Shuffle时数据都落本地磁盘
1.3 部署spark
上传、解压、配置、分发
配置文件:
/conf/spark-env.sh -->配置jdk和master节点
export JAVA_HOME=/usr/local/jdk1.8.0_251/
export SPARK_MASTER_HOST=node-1.51doit.com
export SPARK_WORKER_CORES =4 #指定worker可用的逻辑核数
export SPARK_WORKER_MEMORY=2g #指定worker可用的内存大小
/conf/workers
-->配置worker节点机器
linux01
linux02
也可配置高可用,用zookeeper来管理集群,详情见详细文档
启动:已经配置了环境变量
start-spark-all.sh
stop-spark-all.sh
启动客户端:
spark shell是spark中的交互式命令行客户端,可以在spark shell中使用scala编写spark程序,启动后默认已经创建了SparkContext,别名为sc
在bin目录下启动spark-shell
/bigdata/spark-3.0.0-bin-hadoop3.2/bin/spark-shell --master spark://linux01:7077
--executor-memory 1g --total-executor-cores 3
页面访问端口:linux01:8080
二、 spark架构体系
2.1 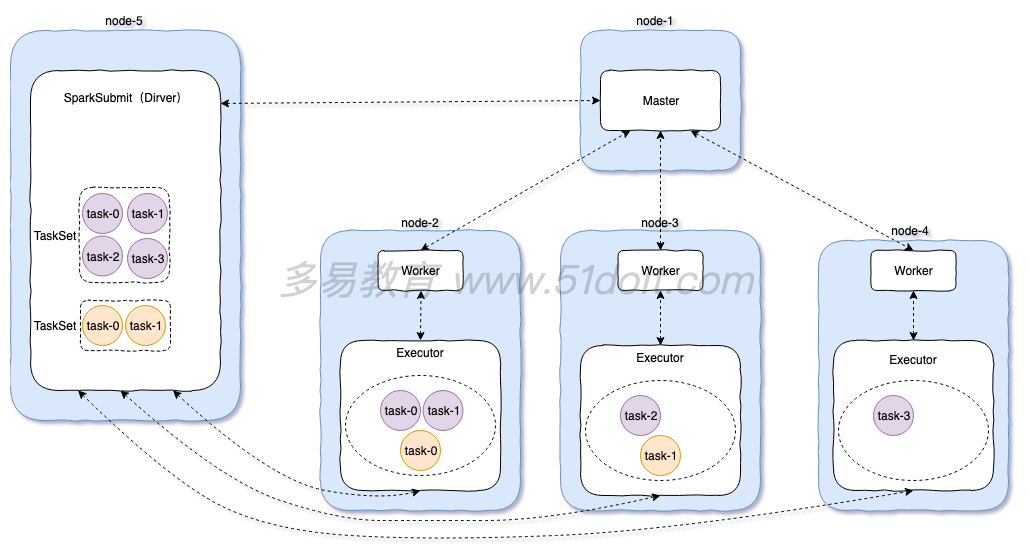
standalone模式流程:
1)先启动Master,再启动Worker,worker启动后向master注册,master定期检查worker(心跳机 制)
2)开启一个线程提交任务:spark-submit,向master提交任务,然后master选择相应的worker进行接收任务。然后worker向Driver端反向注册,拉取任务。然后再worker的executor中执行任务逻辑
3)最后将计算结果发送到Driver端
2.2 standalone cluster 模式
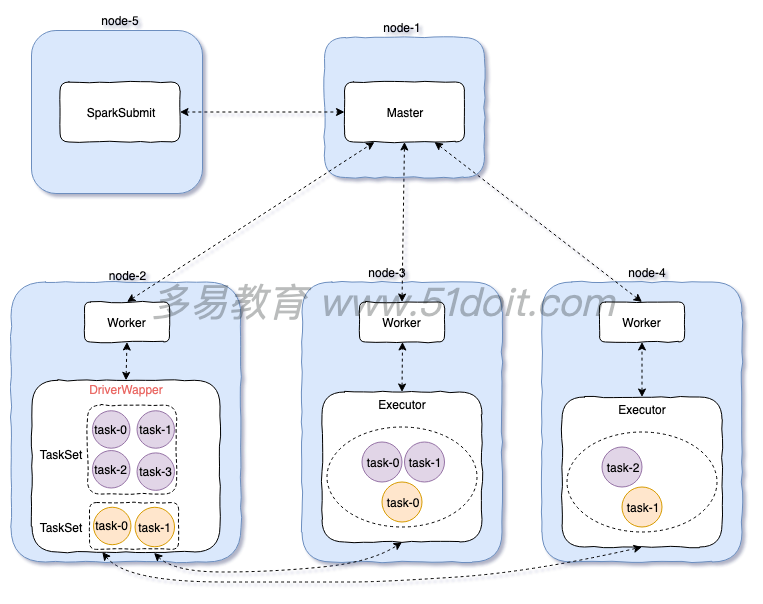
cluster模式:
1)先启动Master,再启动Worker,worker启动后向master注册,master定期检查worker(心跳机 制)
2)开启一个线程sparkSubmit提交任务,向master提交任务
3)master会在worker中开启一个DriverWapper,然后将任务交给DriverWapper。这里DriverWapper就相当于Driver,而client模式Driver是运行在sparkSubmit进程中
4)然后其他的Worker向DriverWapper进行拉取任务,然后在自己的executor中执行
注意:
提交任务的jar包必须在DriverWapper所在的机器上,但是master会随机选择一个worker开启DriverWapper,你也不知道在哪台机器上,所以:
**使用cluster模式,应该将jar包上传到hdfs中
2.3 spark On YARN cluster 模式
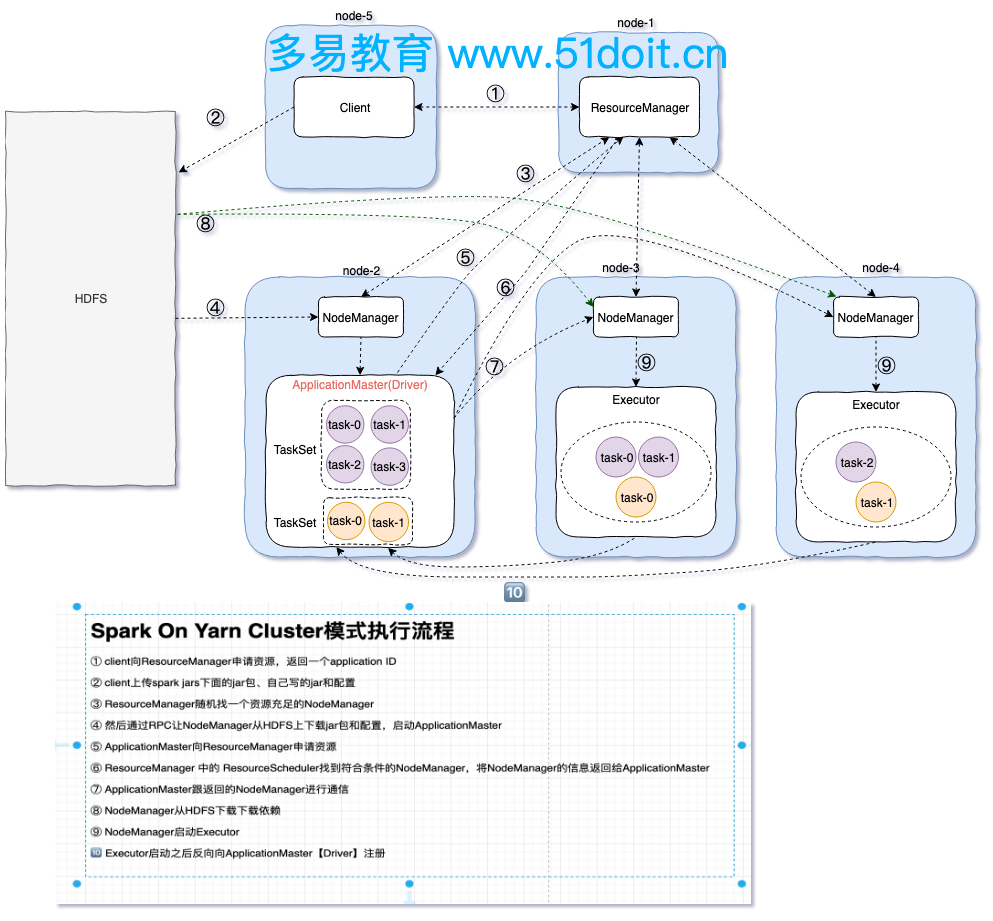
spark On Yarn是生产环境中常使用的一种模式:
1)需要开启hdfs和yarn,(更改hadoop的一些配置,具体的在文档中可见)
不需要开启spark,会将spark的一些配置文件打成jar包
**Linux同步时间命令:(同时发给所有机器:使用send to all sension)
命令:date -s "2021-08-08 09:35:50"
2)以命令的方式运行spark On Yarn
/opt/apps/spark-3.1.2-bin-hadoop3.2/bin/spark-submit
--master yarn
--deploy-mode cluster
--executor-memory 1g
--executor-cores 2 --并行度为2
--num-executors 3 --有三台机器来接收并执行task
--class com.doit.day1.WorkCount
/opt/data/spark_project-1.0-SNAPSHOT-shaded.jar
hdfs://linux01:8020/data/words
hdfs://linux01:8020/out1234
3)spark on yarn cluster 流程
1:client向ResourceManager提交任务,申请资源,ResourceManager返回ApplicationId
2:client向Hdfs上传spark jars下面的jar包,上传自己写的jar包和一些配置文件
3:ResourceManager找一个资源充足的NodeManager向Hdfs下载jar包和配置文件,并启动 ApplicationMaster
(在ApplicationMaster里会启动Driver,而client模式是在客户端的一个进程中启动Driver)
4:Applicationmaster向ResourceManager请求资源,ResourceManager返回可以执行task的节点
5:Applicationmaster与该节点进行交互,该节点从Hdfs上下载jar包和依赖,并启动Executor
6:Executor启动后向ApplicationMaster(Driver)注册
7:ApplicationMaster(Driver)构建DAG切分Satge,将Task序列化发到Executor,然后Executor
执行Task,并将结果返回到Driver端
Yarn-cluster和Yarn-client区别就是:
* Yarn-cluster的driver是在集群节点中随机选取启动ApplicationMaster,然后Driver是运行在 ApplicationMaster中。
* 而Yarn-client中的Driver是运行在提交任务的客户端的一个进程中,节点上启动的是 ExecutorLuacher类似ApplicationMaster,他只具有ApplicationMaster的部分功能,后面的 executor节点也不会向ExecutorLuacher注册,而是向Driver注册,并将结果返回到Drive
2.4 spark On YARN client 模式
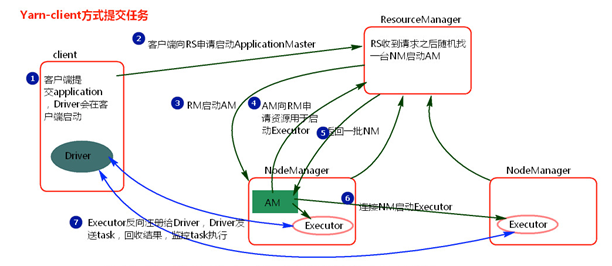
① 客户端提交一个Application,在客户端启动一个Driver进程。
② Driver进程会向ResourceManager发送请求,启动ApplicationMaster的资源。
③ ResourceManager收到请求,随机选择一台NodeManager,然后该NodeManager到HDFS下载jar包和配置,接着启动ApplicationMaster【ExecutorLuacher】。这里的NodeManager相当于Standalone中的Worker节点。
④ ApplicationMaster启动后,会向ResourceManager请求一批container资源,用于启动Executor.
⑤ ResourceManager会找到一批符合条件NodeManager返回给ApplicationMaster,用于启动Executor。
⑥ ApplicationMaster会向NodeManager发送请求,NodeManager到HDFS下载jar包和配置,然后启动Executor。
⑦ Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端
三、编写spark程序
3.1 案例:work-count
def main(args: Array[String]): Unit = {
//创建sparkContext 用sparkContext来创建RDD
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0))
//调用RDD的Transformation(s)方法
val words = lines.flatMap(_.split("\\s"))
val wordAndOne = words.map((_, 1))
val reducer = wordAndOne.reduceByKey(_ + _)
val sorted = reducer.sortBy(_._2, false)
sorted.saveAsTextFile(args(1))
sc.stop()
}
val conf = new SparkConf()
val sc = new SparkContext(conf)
val res = sc.textFile('hdfs://linux1:8082/opt/words').flatMap(_.split('//s+')).map((_,1)).reduceByKey(_+_).sortByKey(_._2)
res.saveAsTextFile(path)
sc.stop
然后打包上传到linxu中;
在spark的bin目录下,执行命令spark-submit:
--在bin目录下执行spark-submit进行提交任务
./spark-submit --master spark://linux01:7077 --executor-memory 1g --total-executor-cores 4
--class com.doit.demo1.WordCount ---类的路径名
/opt/data/spark15-1.0-SNAPSHOT.jar ---虚拟机中jar包的路径
hdfs://linux01:8020/data/words ---arg(0) 参数,文件的输入路径,在hdfs上
hdfs:// linux01:8020/out111 --- arg(1) 参数,文件的输出路径,在hdfs上
四、RDD
RDD中并不装真正要计算的数据,而装的是描述信息,描述以后从哪里读取数据,调用了用什么方法,传入了什么函数,以及依赖关系等。
RDD是什么?
1.RDD是弹性分布式数据集,分布式的即意味着分区,意味着分布式计算
2.RDD有多个分区,分区是spark计算的最小执行单元
3.在触发对数据的计算之前,spark只存储对数据处理的逻辑,并不会调用数据,而数据与处理
逻辑之家的映射关系便处于RDD中
4.RDD之间存在着依赖,有宽依赖和窄依赖之分,宽依赖会经理shuffle,窄依赖不会
4.1 RDD的特点
有一系列连续的分区
有一个函数作用在每个输入切片上: 每一个分区都会生成一个Task,对该分区的数据进行计算,这个函数就是具体的计算逻辑
RDD和RDD之间存在一些依赖关系:RDD调用Transformation后会生成一个新的RDD,子RDD会记录父RDD的依赖关系,包括宽依赖(有shuffle)和窄依赖(没有shuffle)
(可选的)K-V的RDD在Shuffle会有分区器,默认使用HashPartitioner
(可选的)如果从HDFS中读取数据,会有一个最优位置:spark在调度任务之前会读取NameNode的元数据信息,获取数据的位置,移动计算而不是移动数据,这样可以提高计算效率。
4.2 RDD的算子分类
Transformation:即转换算子,调用转换算子会生成一个新的RDD,Transformation是Lazy的,不会触发job执行。每次使用转换算子都回生成新的RDD,同时新的RDD会记得之前的RDD,即所谓RDD和RDD之间存在一些依赖关系。
Action:行动算子,调用行动算子会触发job执行,本质上是调用了sc.runJob方法,该方法从最后一个RDD,根据其依赖关系,从后往前,划分Stage,生成TaskSet。
4.3 RDD的创建
一定要使用SparkContext才能创建RDD
1)通过并行化方式,将Driver端的集合转成RDD
val rdd1: RDD[Int] = sc.parallelize(Array(1,2,3,4,5,6,7,8))
或者
val rdd1: RDD[Int] = sc.makeRDD(Array(1,2,3,4,5,6,7,8))
2)从HDFS指定的目录据创建RDD
val lines: RDD[String] = sc.textFile("hdfs://node-1.51doit.cn:9000/log")
3)也可以从linux本地读取文件,但是需要每台机器上都有这个文件,不太推荐使用
4.4 分区规则
注意,使用上面两种方式创建RDD都可以指定分区的数量
创建RDD的时候,使用textFile的形式读文件,分区规则:
1)求目录下所有文件的总大小totalSize
2)将总大小除2,也可以传参数除其他数avgSize
3)若某个文件(块)小于avgSize则使用一个分区
4)若某个文件大于avgSize的1.1倍,则将这个文件拆分成两个区,拆分后若余下的数据还是大于avgSize的1.1倍,则再次进行分区
5)当文件很大的时候,平均文件大小超过了128M,则会按照128M作为再次拆分的依据
创建RDD的时候,若使用makeRDD(parallelize)的形式,分区规则:
1)当不指定分区数的时候,默认最大核数就是分区数
2)若指定分区数,则按照分区数来进行分区
五、TransFormation 算子
5.1 不产生shuffle
map filter flatMap mapPartitions mapPartitionsWitnIndex
keys values mapValues flatMapValues union
5.1.0 MapPartitionsRDD
对于TransFormation 算子中不产生shuffle的算子底层使用的都是MapPartitionsRDD,这时一个类
new MapPartitionsRDD[返回值的数据类型,传入的数据类型](rdd,(TaskContext,分区编号,iter迭代器)=>函数)
例如:
new MapPartitionsRDD[Double, Int](rdd1, (_, _, iter) => iter.map(_ * 10.0))
5.1.1 map
map
用法:对集合中的数据逐一操作,常用的用法map((_,1)) 还有对元组数据的map操作
val arr = Array(1,2,3,3,4,5,6,78)
val rdd = sc.makeRDD(arr)
val res = rdd.map(_ * 10)
底层:MapPartitionsRDD
val rdd1 = sc.parallelize(Array(1,2,4,5,6,7,7,89))
val res =
new MapPartitionsRDD[Double, Int](rdd1, (_, _, iter) => iter.map(_ * 10.0))
5.1.2 filter
filter
用法:过滤
val arr = Array(1,2,3,3,4,5,6,78)
val rdd = sc.makeRDD(arr)
val res = rdd.map(e => e%2==1)
底层:MapPartitionsRDD
val rdd1 = sc.parallelize(Array(1,2,4,5,6,7,7,89))
val res =
new MapPartitionsRDD[Double, Int](rdd1, (_, _, iter) => iter.filter(_ %2 ==1))
5.1.3 flatMap
flatMap
用法:先map再压平
val arr = Array("hello java","hello scala","hello sql","hello hdfs","hello hadoop")
val rdd1 = sc.parallelize(arr)
val rdd2 = rdd1.flatMap(_.split(" "))
底层:MapPartitionsRDD
val arr = Array("hello java","hello scala","hello sql","hello hdfs","hello hadoop")
val rdd1 = sc.parallelize(arr)
//若想将函数传进去,必须要变成iterator
val f = (x:String)=>x.split(" ").toIterator
val rdd2 = new MapPartitionsRDD[String, String](rdd1, (_, _, iter) => iter.flatMap(f))
5.1.4 mapPartition
mapPartition
用法:map操作,但是在区内进行map操作,每个分区返回一个迭代器,对迭代器进行操作
mapPartition()可以传参数为true或者false,默认是true,这个布尔值是判断是否保留原来 的分区器
底层:MapPartitionsRDD
map与mapPartition的区别:
mapPartition:作用跟map一样
区别是:
1)mapPartition是分区进行map操作,每个区分配一个迭代器进行map操作,而map是对所有数据进行map操作
2)如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效的多,
mapPartitions是一个区创建一个额外的对象,map是每次处理都创建一个额外的对象
比如:当需要连接mysql的数据库的时候,需要建立连接对象,若用map则每条数据都要创建一个连接对象,
,若用mapPartitions则是一个区用一个连接对象
注意:1)连接对象无法被序列化,所以只能放在算子方法中,不能放到外面。若放到算子方法外面, 则在发送给executor的时候,发现有一个外部引用,而这个外部引用是连接mysql的连接对 象,无法被序列化,所以无法发送,进而无法执行
2)在关闭资源的时候,要进行判断是否为最后一条数据,当所有数据执行结束后在再进行关闭。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
//分类ID,商品的金额
// (1, 3000.0) ------> (1, 手机, 3000.0)
val tpRDD: RDD[(Int, Double)] = sc.makeRDD(List((1, 3000.0), (2, 2000.0), (3, 2000.0), (2, 2000.0)))
val rdd2 = tpRDD.mapPartitions(it => {
//创建一个JDBC连接(在函数内部创建的,即在Executor中调用时才会创建连接对象)
/*
注意:连接对象无法被序列化,所以只能放在算子方法中,不能放到外面。若放到算子方法外面,则 在发送给executor的时候,发现有一个外部引用,而这个外部引用是连接mysql的连接对象,无法 被序列化,所以无法发送,进而无法执行
*/
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=utf-8", "root", "123456")
var name: String = null
it.map(t => {
val preparedStatement = connection.prepareStatement("SELECT name FROM tb_category WHERE id = ?")
preparedStatement.setInt(1, t._1)
val resultSet = preparedStatement.executeQuery()
while (resultSet.next()) {
name = resultSet.getString(1)
}
resultSet.close()
preparedStatement.close()
// 在关闭资源的时候,要进行判断是否为最后一条数据,当所有数据执行结束后在再进行关闭。
if(!it.hasNext) {
connection.close()
}
(t._1, name, t._2)
})
})
//根据分类ID,查询数据库获取分类的名称
//对rdd2进行其他的Transformation
val res = rdd2.collect()
println(res.toBuffer)
}
5.1.5 mapPartitionsWitnIndex
mapPartitionsWitnIndex
用法:分区进行map操作,同时可以拿到分区编号
val rdd1 = sc.parallelize(Array(1,2,4,5,6,7,7,89))
val res = rdd1.mapPartitionsWithIndex((index, iter) => iter.map(e => s"partition:$index element:$e"))
底层:MapPartitionsRDD
val rdd1 = sc.parallelize(Array(1,2,4,5,6,7,7,89))
val res = new MapPartitionRDD[String,Int]((_,index,iter)=>iter.map(e => s"partition:$index element:$e"))
5.1.6 keys values
keys values
用法:针对k-v类型的集合,只获取key集合或者value集合
val tpList = List(("spark", 3), ("hadoop", 5), ("flink", 8), ("hive", 5), ("spark", 7), ("flume", 4))
val rdd1 = sc.parallelize(tpList)
val keys = rdd1.keys
val values = rdd1.values
底层:直接map操作就可以了
val keys = rdd1.map(_._1)
val values = rdd1.map(_._2)
5.1.7 mapValues
mapValues
用法:只针对集合中的value进行map操作,比较常用
val tpList = List(("spark", 3), ("hadoop", 5), ("flink", 8), ("hive", 5), ("spark", 7), ("flume", 4))
val rdd1: RDD[(String, Int)] = sc.parallelize(tpList)
val rdd2: RDD[(String, Int)] = rdd1.mapValues(_ * 10)
底层:MapPartitionsRDD
val tpList = List(("spark", 3), ("hadoop", 5), ("flink", 8), ("hive", 5), ("spark", 7), ("flume", 4))
val rdd1: RDD[(String, Int)] = sc.parallelize(tpList)
val res = new MapPartitionsRDD[(String, Double), (String, Int)](rdd1, (_, _, iter) => iter.map {
case (k, v) => (k, v * 10.0)
})
5.1.8 flatMapValues
flatMapValues
用法:对value进行flatMap
/*
运算之后结果为:
("spark","3")
("spark","4")
*/
val tpList = List(("spark", "3,4"), ("hadoop", "5,6"), ("flink", "8,9"), ("hive", "5,7"), ("spark", "7,9"), ("flume", "4"))
val rdd1: RDD[(String, String)] = sc.parallelize(tpList)
val rdd2: RDD[(String, String)] = rdd1.flatMapValues(_.split(","))
底层:MapPartitionsRDD
val tpList = List(("spark", "3,4"), ("hadoop", "5,6"), ("flink", "8,9"), ("hive", "5,7"), ("spark", "7,9"), ("flume", "4"))
val rdd1: RDD[(String, String)] = sc.parallelize(tpList)
val res = new MapPartitionsRDD[(String,Int),(String,String)](rdd1, (_,_,iter)=>iter.flatMap{
case(k,v) => v.split(",").map(_.toInt).map(x=>(k,x))
})
5.1.9 union
union
用法:相当于合并
val rdd1 = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 2)
val rdd2 = sc.makeRDD(Array(10, 11, 12, 14), 3)
val rdd3 = sc.makeRDD(Array(100, 110, 120, 140), 3)
val res = rdd1.union(rdd2).union(rdd3)
sc.union(rdd1, rdd2, rdd3)
注意:
1)相当于合并,前提是rdd的类型一致
2)合并后的分区数是两个rdd的分区数之和
3)union没产生shuffer,他只是在两个rdd上包了一层,数据没有进行打散传输,数据原来在哪 个节点上还是在哪个节点上,产生的新的rdd还是到原来的节点上找数据
val rdd1: RDD[Int] = sc.parallelize(arr,30)
当指定的分区数过于大时,也会有这些分区,只不过有些区内没有数据
4)rdd的uion方法,底层调用的是sparkContext的union方法,可以传入多个RDD
sc.union(rdd1, rdd2, rdd3)
底层:
5.2 产生shuffle
1)shuffle:将具有规律的数据按照指定的分区规则,通过网络传输,将其归到同一个分区中
2)注:
这些shuffle算子都是有可能不产生shuffle的,当数据已经经过相同的分区器进行分区,并且下游的分区器和分区数量一样的时候,便不需要再进行分区。
因为shuffle的底层是用的shuffleRDD,而shuffleRDD中会先进行判断:若下一步的分区器和分区类型和数量跟上一步的分区器类型和分区数量一样,则没必要再进行shufffle,再进行shuffle结果还是跟上一步一样,数据还是在那个分区,还是在那台机器,实在没必要再shuffle一遍,所以此时就不会产生shuffle。
3)比如:
val rdd1 = rdd.rePartitions(new HashPattition(rdd.partitions.length))
val res = rdd1.reduceByKey
此时便只有rePartitions进行了shuffle,而reduceByKey本来是需要shuffle,但上一步进行了shuffle,而且分区器和分区数量和reduceByKey一样,所以reduceByKey便不需要再进行shuffle,直接进行聚合就行了
4)再比如:
val rdd1 = rdd.rePartitions(new HashPattition(rdd.partitions.length))
val rdd2 = rdd1.mapPartition(it=>it , true)
val res = rdd2.reduceByKey
此时会有两个stage,当mapPartition参数为true的时候为保留原来的分区器,所以 reduceByKey的时候,分区器和分区数量跟原来一样,所以不会再shuffle,不会再划分stage
al rdd1 = rdd.rePartitions(new HashPattition(rdd.partitions.length))
val rdd2 = rdd1.mapPartition(it=>it , false)
val res = rdd2.reduceByKey
此时会有三个stage,当mapPartition参数为false的时候为不保留原来的分区器,所以 reduceByKey的时候,分区器和分区数量跟原来不一样,所以会再shuffle,再划分stage
5)底层核心方法:shuffledRDD
combineByKeyWithClassTag
coGroup
combineByKey groupByKey groupBy reduceByKey aggregateByKey foldByKey distinct
5.2.1 combineByKeyWithClassTag:
combineBykey是combineByKeyWithClassTag的简化形式,需要传三个函数:
第一个函数是如何对key第一次出现的时候如何处理
第二个函数是key第二次出现的时候如何处理value
第三个函数是全局聚合的时候如何对相同的key的value处理
combineByKeyWithClassTag:传三个函数,分区器,是否预聚合
val res1=rdd4.combineByKeyWithClassTag(
function1,function2,function3
,new HashPartitioner(rdd4.partitions.length)
,false
)
5.2.2 shuffledRDD
shuffedRDD:
三个重要的参数:
shuffledRDD.setAggregator() ---设置聚合规则
shuffledRDD.setMapSideCombine(true) ---设置是否进行预聚合
shuffledRDD.setKeyOrdering ---设置排序规则
里面的泛型【key,value,value的中间结果的数据类型】
要传参数->原rdd、分区器(分区器内要传原rdd的分区个数)
val shuffledRDD= new ShuffledRDD[String, Int, Int](rdd3, new HashPartitioner(rdd3.partitions.length))
//创建聚合器,传入函数,实现聚合规则
//里面的泛型【k,v,中间结果的v类型】
val aggregator = new Aggregator[String, Int, Int](f1, f2, f3)
shuffledRDD.setAggregator(aggregator)
//设置是否进行预聚合,true为进行预聚合,false为不进行预聚合,直接进行全局聚合
shuffledRDD.setMapSideCombine(true)
mapSideCombine:
--第一个函数是如何对key第一次出现的时候如何处理
--第二个函数是key第二次出现的时候如何处理value
--第三个函数是全局聚合的时候如何对相同的key的value处理
为true:会进行预聚合,第一个和第二个函数在上游执行,进行预聚合,将预聚合的结果写 到磁盘,在下游再执行全局聚合函数,进行全局聚合
为false:则只会执行第一个和第二个函数,第三个函数不会执行,即没有预聚合,上游只是 将数据进行分区然后写到磁盘,下游才会执行聚合函数,将数据聚合
总结:为true的方式好,因为true会进行预聚合,将中间结果写道磁盘的数据会少,若不进 行预聚合,则中间结果的数据会比ture多很多,shuffer写和shuffer读都会多,导致 效率低。
哈希分区器:hashPartitioner=>将key进行分区:
将key取哈希值然后取模
摸是传进来的分区个数mod
若取模后是负数x,则分区编号为mod+x
若取模后是正数y,则分区编号为0+y
5.2.3 reduceByKey
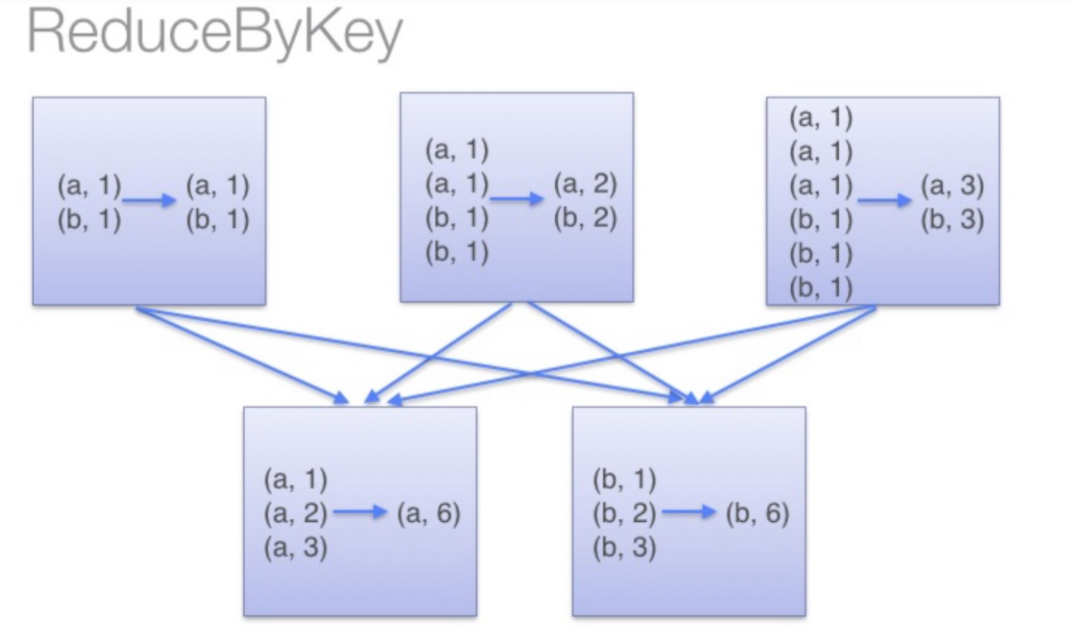
reduceByKey:会根据相同的key进行预聚合,将聚合结果进行shuffle,然后下游从各个分区的聚合结果拉取过来做一个全局的聚合,最终key相同的会跑到同一个分区。
比如:数据经过map((word,1))此时有三个分区,
然后调用reduceByKey算子:key只有a和b;所以最后只会有两个分区的数据,一个key一个
调用reducrByKey算子会进行shuffle:
上游各个分区会对key相同的数据做一个预聚合的操作,然后将预聚合的结果溢写磁盘,下游会从上游拉取数据自己分区的数据,然后做全局的聚合
reduceByKey
用法:
1)将k-v类型的集合按照key进行分组,然后将同一个key下的不同value进行聚合
2)一般会产生shuffle,有时也可能不产生shuffle
当不进行预聚合的时候,会将数据进行分区,然后shuffle到本地磁盘,然后下游从上游拉 取数据,再直接进行全局聚合;当进行预聚合的时候,会将数据进行分区,然后区内局部聚合 再shuffle到磁盘,然后下游从上游拉取数据,再进行全局聚合
底层:
combineByKeyWithClassTag、shuffedRDD
案例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("reduceBYKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Array("spark 1", "sql 2", "word 3","spark 1", "sql 2", "word 3","spark 1", "sql 2", "word 3"))
val rdd2: RDD[Array[String]] = rdd1.map(_.split(" "))
val rdd3= rdd2.map(e => (e(0), e(1).toInt))
//直接使用reduceBuKey方法
val res1 = rdd3.reduceByKey(_ + _)
//println(res1.collect().toBuffer)
//使用combineByKeyWithClassTag
val f1 = (x:Int)=>x
val f2 = (x:Int,y:Int)=>(x+y)
val f3 = (x:Int,y:Int)=>(x+y)
val res = rdd3.combineByKeyWithClassTag(f1, f2, f3, new HashPartitioner(rdd3.partitions.length), true)
println(res.collect().toBuffer)
//使用shuffledRDD
val shuffle = new ShuffledRDD[String, Int, Int](rdd3, new HashPartitioner(rdd3.partitions.length))
val aggregate = new Aggregator[String, Int, Int](f1, f2, f3)
shuffle.setAggregator(aggregate)
shuffle.setMapSideCombine(true)
println(shuffle.collect().toBuffer)
}
5.2.4 groupBuKey
groupBuKey
用法:
1)按照key进行分组,将同一个key的value合并到一个可变集合中
2)会产生shuffle,默认的是mapSideCombine = false,所以默认的是不进行预聚合,将数据 分区shuffle后直接进行全局聚合
3)其底层使用的也是combineByKey,只是处理的逻辑不是将value进行聚合,而是将同一个key的 value取出来合并到一个新的可变集合中
底层:
1)combineByKeyWithClassTag
val res1=rdd3.combineByKeyWithClassTag(f1,f2,f3,new HashPartitioner(rdd3.partitions.length),false)
2)shuffledRDD
案例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("word-group")
val sc = new SparkContext(conf)
val line = sc.textFile("hdfs://linux01:8020/data/words")
val rdd4 = line.flatMap(_.split(" ")).map( (_, 1))
//用groupByKey方法
val res = rdd3.groupByKey()
//用combineByKeyWithClassTag
val f1 = (x: Int) => {
ArrayBuffer[Int](x)
}
val f2 = (buffer: ArrayBuffer[Int], in: Int) => {
buffer += in
}
val f3 = (buffer1: ArrayBuffer[Int], buffer2: ArrayBuffer[Int]) => {
buffer1 ++= buffer2
}
//使用ombineByKeyWithClassTag来实现分组
val res1=rdd4.combineByKeyWithClassTag(f1,f2,f3,new HashPartitioner(rdd4.partitions.length),false)
res1.saveAsTextFile("hdfs://linux01:8020/out2403")
//用shuffledRDD
val shuffled = new ShuffledRDD[String, Int, ArrayBuffer[Int]](rdd4, new HashPartitioner(rdd4.partitions.length))
shuffled.setAggregator(new Aggregator[String, Int, ArrayBuffer[Int]](f1, f2, f3))
shuffled.setMapSideCombine(true)
shuffled.saveAsTextFile("hdfs://linux01:8020/out2406")
}
5.2.5 groupBy
groupBy
用法:
按照指定的字分组
比如:rdd1:(h,1)(h,2)(h,3)--->groupBy(_._1)-->(h,(h,1),(h,2),(h,3))
区别:
1)groupBy会将key也放在value中,会有冗余数据
2)可以优化:rdd1.map(e=>(e._1,(e._2,e._3))).grouByKey-->(h,CompactBuff(1,2,3))
底层:
combineByKeyWithClassTag、 shuffledRDD
1)其实在groupBy底层使用的就是grouByKey,只是处理的时候是先将数据变为k-v类型,再使用 grouByKey 例如:rdd1.map(e=>(e._1,(e._1,e._2,e._3)))
2)groupByKey:必须针对的是RDD[(K,V)]才能使用groupByKey,并且value中就不保存key的 数据了,更加节省资源
groupBy:使用起来更加灵活,但是value中还有冗余保存key的数据,相对更浪费 源,groupBy底层调用了groupByKey
grouByKey和coGroup的区别:
都是进行分组
区别在于:
1)grouByKey是一个RDD进行分组,而coGroup是多个RDD进行协同分组(最多4个)
2)grouByKey和coGroup在分组的时候,grouByKey是将同一个key的value都放到一个可变集合中
coGroup是将同一个key的value,每一个区的value都返回一个迭代器,而不是将全部的value都放到一个集合中
3)分组后续的处理,grouByKey将key和其所有的value返回即可;
而cogroup可以实现join和左/右连接的时候会对每个迭代器中的value再进行处理
5.2.6 reduceBykey-foldByKey-aggregateByKey 三者的区别:
reduceBykey foldByKey aggregateByKey 三者的区别:
reduceByKey
1)也是一个针对key的聚合
2)不能指定初始值,局部和全局聚合的逻辑一样,但是嘞,可以用combineByKey来实现局部和全 局不同的逻辑
foldByKey
1)也是一个对于value进行聚合的函数
2)跟reducerBeKey的区别在于可以指定初始值
3)foldByKey(0)(_+_)
4)注意:初始值会在每个分区不同的key都执行一次,而全局聚合不使用初始值
比如0号区有(a,10)(b,10) 1号区有(a,10)
f1oldByKey(1000)(_+_)-->(a,2200)(b,1010)
aggregateByKey
1)也是一个聚合函数
2)区别在于即可以传一个初始值,还可以传局部聚合函数和全局聚合的函数
aggregateByKey(0)(Math.max(_,_) , _+_)
5.2.7 distinct
distinct
用法:
1)去重
2)产生shuffle,进行了局部去重和全局去重,比较高效
val rdd = sc.makeRDD(Array(1,1,1,1,3,3,4,4))
val res = rdd.distinct
底层:
实现比较巧妙,
先将数据变为k-v类型 val rdd2 = rdd.map(x=>(x,null))
然后使用reduceByKey val rdd3 = rdd2.reduceByKey((a1,a2)=>a1)
最后只要key val res = rdd3.keys
5.2.8 join连接—coGroup
join leftOuterJoin rightOuterJoin fullOuterJoin
底层使用的都是coGroup
coGroup:
1)协同分组:将多个RDD中的相同的key所对应的value搞到一起
2)条件:多个RDD里面的数据都是对偶元组,并且key是相同数据类型
3)使用同样的分区器,便可以将相同的key搞到一起
4)可以不shuffle,也可以shuffle,当下游的分区数量大于上游的Max(rdd1,rdd2)的时候,必须 shuffle
grouByKey和coGroup的区别:
都是进行分组
区别在于:
1)grouByKey是一个RDD进行分组,而coGroup是多个RDD进行协同分组(最多4个)
2)grouByKey和coGroup在分组的时候,grouByKey是将同一个key的value都放到一个可变集合中
coGroup是将同一个key的value,每一个区的value都单独放到一个集合中,而不是将全部的value都放到一个集合中
3)分组后续的处理,grouByKey将key和其所有的value返回即可;
而cogroup可以实现join和左/右连接的时候会对每个迭代器中的value再进行处理
4)grouByKey必须shuffle;coGroup可以不shuffle,也可以shuffle
val rdd1 = sc.makeRDD(List(("spark", 1),("spark", 10) ,("java", 2), ("sql", 3)))
val rdd2 = sc.makeRDD(List(("spark", 2),("spark", 5), ("java", 2), ("shuke", 3)))
val res = rdd1.cogroup(rdd2,rdd3)
val rdd3: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
返回的是(key,(Iterable[Int], Iterable[Int]))) 同一个kye的每个区的v都放到一个迭代器中
注意:cogroup中有时候会有两个RDD
join:相当于mySql的内连接
leftOuterJoin :左外连接
rightOuterJoin:右外连接
fullOuterJoin:全外连接
案例:
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("join").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(("spark", 1),("spark", 10) ,("java", 2), ("sql", 3)))
val rdd2 = sc.makeRDD(List(("spark", 2),("spark", 5), ("java", 2), ("shuke", 3)))
/*
val res = rdd1.join(rdd2)
val res2 = rdd1.leftOuterJoin(rdd2)
val res3 = rdd1.rightOuterJoin(rdd2)
val res4 = rdd1.fullOuterJoin(rdd2)
*/
//1)使用cogroup来实现join
val rdd3: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
rdd3.flatMapValues{
case (it1,it2) => {
val array = new ArrayBuffer[(Int, Int)]()
for(e1<-it1;e2<-it2){
array += ((e1,e2))
}
array
}
}
//1)使用cogroup来实现join--源码
rdd3.flatMapValues{
t=>for(e1 <- t._1;e2 <- t._2) yield (e1,e2)
}
//2)使用cogroup来实现leftOuterJoin
rdd3.flatMapValues{t=>
if(t._1.nonEmpty && t._2.isEmpty){
t._1.iterator.map((_,None))
}else{
for(e1 <- t._1;e2 <- t._2) yield (e1,e2)
}
/*
可以使用模式匹配,更简洁
case (vs ,Seq()) => vs.map(e=>(Some(e),None))
case (vs,ws) => for(e1 <- vs.iterator;e2<- ws.iterator) yield (e1,e2)
*/
}
//3)使用cogroup来实现rightOuterJoin
rdd3.flatMapValues{t=>
if(t._2.nonEmpty && t._1.isEmpty){
t._2.map((None,_))
}else{
for(e1 <- t._1;e2 <- t._2) yield (e1,e2)
}
/*
可以使用模式匹配,更简洁
case (Seq() ,vs )=> vs.map(e=>(None,Some(e)))
case (vs,ws) => for(e1 <- vs;e2<- ws) yield (e1,e2)
*/
}
//4)使用cogroup来实现fullOuterJoin
rdd3.flatMapValues{
case (vs ,Seq()) => vs.map(e=>(Some(e),None))
case (Seq() ,vs )=> vs.map(e=>(None,Some(e)))
case (vs,ws) => for(e1 <- vs;e2<- ws) yield (e1,e2)
}
}
5.2.9 交集 差集
intersection:
1)求交集,返回交集的结果
2)条件是两个RDD的数据类型一样
subtract:
1)求差集 a.submit(b) 则是求a中剔除a与b的交集的数据的剩下的数据,即求a中不属于b的数 据,即a-a&b
5.2.10 重新分区repartition----coalesce
repartition
1)重新分区,可以改变分区的数量,会进行shuffle
2)底层调用的是coalesce 传两个参数coalesce(分区数量,true) true为是否shuffle,默 认是true
3)当coalesce传false的时候,则不会shuffle,只是将数据进行合并,数据在哪个机器还是在 哪个机器,只是task在读数据的时候去哪个机器读有了改变,数据不会被打散,也不会改变 数据的顺序
当coalesce传true的时候,则会将数据打散,进行均分,进行shuffle
5.2.11 repartitionAndSortWithinRartition
用法:
1)重新分区并且区内排序,下游再进行全局排序
2)会产生shuffle
3)数据必须是k-v类型,因为要根据k进行分区,并且按照key进行排序,或者key的一部分(当key是元组的时候,就可以只用一部分进行排序)
4)参数中要传一个分区器
注:元组有默认的排序规则,按第一个元素排序,若第一个相等则按照第二个再排序
有一个RDD,里面是Tuple3(省,市,金额)
现在想进行分区,区内排序:分区按照省,排序按照金额,而且是降序排序
由于repartitionAndSortWithinRartition必须按照key进行分区排序,所以要把省和金额放到一个元组中作为key
分区:自己写一个分区器,只用省来分区
排序:写一个隐式参数,自定义排序规则,按照元组的默认排序规则,其中金额是int,可以使用-号来实现降序
5.2.12 sortBy/sortByKey
sortBy/sortByKey
1)当有很多的数据额的时候,比如有20个G,而内存不够,如何做到全局排序?
--> 用到一个新的分区器:RangePartitioner--按照范围进行分区(也成为分桶排序)
会先进行抽样,计算大致的数据范围,然后根据数据范围进行分区,同时在区内进行排序, 然后再进行全局排序。此时不同区的的数据会有顺序关系,比如(1,2,3,4) (10,20,30)(45,67,89,100) 这样便可以实现全局排序
2) sortBy本身不是action,而是TransFormation,但是在sortBy底层使用shuffledRDD,并且设置了setKeyOrdering,可以区内排序内部用了RangePartitioner,内部用RangePartitioner分区器,而分桶分区器,需要进行抽样来大致划分数据范围,所以RangePartitioner触发了collect,收集部分数据作为样本来划分数据范围
所以可以说sortBy内部的RangePartitioner分区器,触发了一个collect,而sortBy本身不是action算子
六、 Action算子
6.1 collect
collect
用法:将结果数据收集起来
(1)底层调用了runJob,runJob将每个分区的数据收集到一个Array中 通过网络传输发送到 Driver端
(2)发送到Driver端的时候是按照分区的编号顺序进行发送,因为是收集,所以不会改变数据的 顺序,
而如果是聚合(reduce\aggregate\fold) 则只是聚合,此时是哪个分区的结果先计算 出来,就先发送,不再按照分区编号的顺序
6.2 count
count
用法:
统计RDD里的行数
先在executor端进行区内统计,然后发送到Driver端,在Driver端再进行全局统计
底层:
每个区内用一个迭代器,进行边迭代 边计数,在Driver端再进行全局统计。而不是将所有数据都放内存进行统计
6.3 reduce
reduce
用法:
action的聚合操作,这个聚合是将结果进行聚合再输出,而不是TransFormation的聚合
底层:
将数据先再executor端进行聚合,然后将结果发送到Driver端,每一个区的数据都返回一个集合,将这些集合发送到Drier端,用一个集合将这些集合收集起来,然后在Driver端再进行全局聚合
6.4 fold //aggregate // sum
用法:
fold(初始值)(聚合函数)
aggregate(初始值)(局部聚合函数)(全局聚合函数)
sum()求和
底层:
1)局部聚合函数是在executor端执行的;全局聚合函数是在Driver端执行的
2)sum底层使用的就是fold-->fold(0)(_+_) 便是sum
3)注意:初始值在局部聚合的时候会使用到,在全局聚合的时候也会使用到,这点跟TransFormation的foldBykey和aggregateByKey不同;而且这些聚合函数是局部聚合后哪个worker先聚合完毕,就先发到Driver端,而collect是按照分区编号按顺序发送到Driver端
6.5 foreach // foreachPartition // foreachPartitionAsync
(1)均是在executor端执行,最后一个执行,不返回RDD,直接输出
(2)
foreach一条一条的处理
foreachPartition一个区返回一个迭代器,然后对迭代器进行处理
foreach(e=>println(e))
foreachPartition(iteror => iter.map(x=>println(x)))
foreachPartitionAsync
该方法是个异步方法,Driver端可以继续往后执行,再触发Action,只有集群中
计算资源充足,可以让多个job同时执行,提高计算效率,但最后一个一定是foreachPartition
比如将数据输出到hdfs中。再输出到Hbase中,便可以使用foreachPartitionAsync,不用 串联执行,而是同时进行输出.
6.6 max // min
(1)求结果的最值
(2)比较的时候两两进行比较 这样效率高啊。先在executor端区内两两比较找最大最小,然后在Driver端再找最值。不是放内存中要是全局排序找最值的话多浪费资源
sortBy还要有分区器,还要shuffle还要触发collect,代价太大了
6.7 take
用法:
取前几条数据take(n)
注意:
当第一个分区的数据不够n个的时候,便会再触发一个job,从第二个分区中取数据...所以take可能会触发多个job
take(-1) 返回空数组
take(0) 返回空数组
6.8 top
top
用法:
取top(n)
底层:
也会采取分布式的思想,局部取topN,再全局取TopN
做法是将数据放到一个有界优先队列,有界优先队列需要指定长度,可以传排序规则,他会 自动对数据进行排序,但是只保留固定长度的数据,数据会不断更新,假设取top5,则有界优先队 列中会边放数据,边排序,边更新,最终只保留最大的5个数据(假设排序规则是降序)
先在每个分区使用有界优先队列,然后将每个区的结果的有界优先队列发送到Driver端,(假 设有q1,q2,q3)在Driver端将有界优先队列,再进行合并,q1++=q2 ++=q3
这个时候q1中的数据不断更新,便保留了topN,但是这里面是无序的,所以再 toArray.sorted 大功告成
七、特殊算子
7.1 cache/persist
1) val rdd1 = sc.textFile("hdfs://linux01:7077/words")
rdd1.cache
不会立即cache,需要有action因子触发后才会进行cache标记
rdd1.count -->此时便会进行cache
2) cache 会将结算结果保存在executor所在的机器的内存中,会有cache标记,下次再使用的话直接 从内存中读,所以就会非常快,就不用从原数据进行读取
3) 若application不停掉,则会将数据一直放内存中,可以手动释放:
unpersist(false) false指异步的,一般使用false ,释放内存的时候不会阻塞(当下代码没执行 完,可以继续执行其他程序)
unpersist(true) 同步的,会阻塞
4) cache 即不是action因为不会触发job,但也不是TransFormation,因为并不会生成新的RDD,而 是将一个RDD进行标记
5) 当数据太大的时候,都放到内存便会造成内存溢出,所以他不会将数据都缓存到内存中,他会动态调 节,只缓存部分数据,缓存时按照分区进行缓存(要么一个分区的数据全缓存,要么不缓存),所以当 继续操作的时候,对于已经缓存到内存中的数据,运算自然很快,还有些没缓存的数据,自然就要运 算的慢些
6) cache会将数据读出来以java对象的格式放到内存,可以自定义序列化方式,简化格式
使用kryo的序列化方式,数据更简洁,传输速度更快:
<-- 缓存到磁盘的方式是缓存到executor端的磁盘 -->
val rdd1 = sc.textFile("hdfs://linux02:7077/words") sc.getConf.set("spark.serializer",org.apache.spark.serializer.KryoSerializer) //设置序列化方式为kryo
import org.apache.spark.storage.StorageLevel
rdd1.persist(StorageLevel.MEMORY_AND_DISK_SET)
//设置存储级别为 既缓存到内存,内存不够缓存到磁盘,在StorageLevel中有很多的存储级别,也可 以设置只缓存到内存
cache底层调用的就是persist
总结:
1) 当只需要触发一次action的时候,根本不需要cache,cache了反而要将数据读出来以一定的格式放 到内存(默认使用的是java的序列化格式),反而会慢。
2) 当后续需要再使用的时候,一个rdd会多次触发action,这时候使用cache便会非常快。
3) 当数据处理之后确实很大,海量数据,而且需要进行cache的时候,可以考虑使用设置序列化方式为 kryo的方式,使用persist,建议使用MEMORY_AND_DISK_SET的存储级别
7.2 checkpoint
1) 将一个rdd所对应的数据保存起来,高可用,默认是保存在hdfs中。
-->常用于将有价值的中间结果 保存起来,
而cache/persist是将数据保存到内存中或者磁盘中,当job结束的时候,中间结果的数据会丢失,而checkpoint会保存到hdfs中,安全高可用
sc.setCheckpointDir("hdfs://linux01:8020/data")
val rdd1 = sc.textFile("hdfs://linux02:7077/words")
val rdd2 = rdd1.filter(_.contains("laozhang"))
rdd2.cache
rdd2.checkpoint
rdd2.count
2) checkpoint 即不是action因为不会触发job,但也不是TransFormation,因为并不会生成新的 RDD,而是将一个RDD进行标记未来要做checkpoint即将这个rdd的数据存到hdfs中,会触发两个 job,一个job是将中间结果保存到hdfs中,第二个job是从hdfs中读数据进行下面的运算,当以后触 发action的时候,便会进行checkpoint,将这个rdd的数据存到hdfs中,然后下面的计算逻辑,将 从checkpoint保存的数据中进行读,不再从原文件进行读。
3) 当做了checkpoint的时候,便会切断与其父rdd的依赖关系,因为他把数据安全的保存下来了。
之前若在计算过程中某个worker宕机了,便会依赖rdd之间的关系换台机器重新计算
4) 一般会在checkpoint之前先cache一下,这样当下面继续运算的时候:
*若直接checkpoint,则会将中间结果数据放到hdfs中,然后下游从hdfs中读数据
*若先cache再checkpoint,则会将中间结果做cache,下游运算的时候则直接从cache中读 数据,这样岂不是更快,
*当cache中的数据丢失的时候,便会再从checkpoint保存的hdfs中读数据
*当cache中的数据有丢失,而且checkpoint的数据也有丢失的时候,则报错,不会再从头计算 了,即checkpoint会切断与父RDD之间的依赖关系
5)通过checkpoint保存的数据,不会随 application 的结束而结束吧,要想删除的话需要手动删除。
而persist保存的数据,不管是在内存中的还是磁盘中的,都会随 application 的结束而删除
总结:
1、当中间结果的数据比较重要,需要保存起来,以后可以重复使用,checkpoint便是将中间结果的重要数据安全的保存起来(hdfs集群中)。保存之后就会切断与父RDD的关系。数据比较可靠
2、cache是将计算结果做一个cache标记,然后将计算结果放到内存,下次再次使用这个结果的时候直接从内存中取。job停止,内存中的数据也就消失了。
3、cache和checkpoint都既不属于Action算子也不属于Transformation算子
常用于机器学习和迭代式运算。
7.3 广播变量
将数据搞到Driver端,在Driver端通过网络传输将数据广播到对应的worker的executor端的内存中。减少shuffle,提高速度,executor之间会相互传
比如要将访问日志与ip规则文件进行关联,若规则文件在executor端的内存中,则关联的时候就不用从外面读文件,再shuffle,会提高效率,
所以将数据搞到Driver端,在Driver端通过网络传输将数据广播到对应的worker的executor端的内存中。减少shuffle,提高速度
val rdd1 = sc.textFile("hdfs://linux02:7077/words")
val rdd2 = rdd1.filter(_.contains("laozhang"))
val rdd3 = rdd2.collect
sc.broadcast(rdd3) //将Driver端的数据广播到对应的executor端的内存中
八、Spark中的重要概念
8.0 分区
创建RDD两种方式,对应着两种分区规则
创建RDD的时候,使用textFile的形式读文件,分区规则:
1)求目录下所有文件的总大小totalSize
2)将总大小除2,也可以传参数除其他数avgSize
3)若某个文件(块)小于avgSize则使用一个分区
4)若某个文件大于avgSize的1.1倍,则将这个文件拆分成两个区,拆分后若余下的数据还是大于 avgSize的1.1倍,则再次进行分区
5)当文件很大的时候,平均文件大小超过了128M,则会按照128M作为再次拆分的依据
创建RDD的时候,若使用makeRDD(parallelize)的形式,分区规则:
1)当不指定分区数的时候,默认最大核数就是分区数
2)若指定分区数,则按照分区数来进行分区
3)分区的时候会将数据均分
8.1
Application、DAG 、Job、Stage、Task
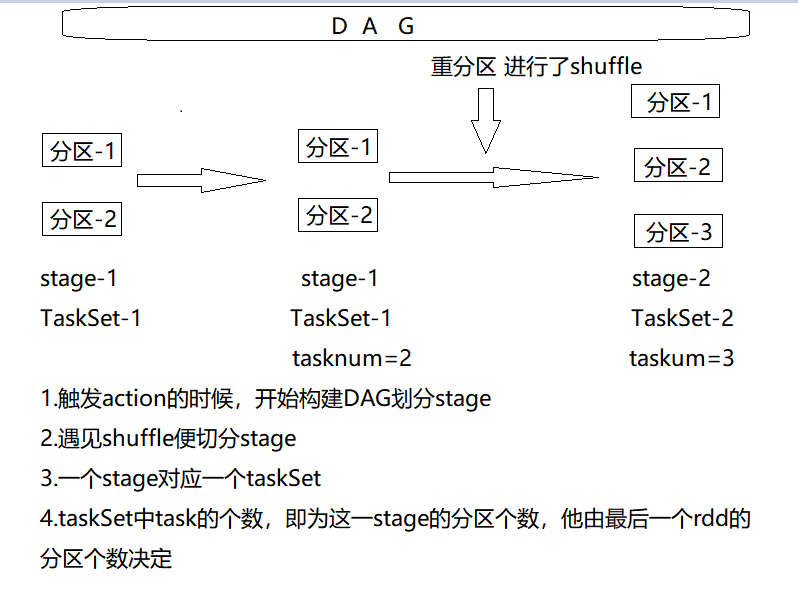
application-->action-->DAG(Job)-->Stage-->TaskSet-->Task
application可以触发多次action,产生多个Job
一个job中可以有多个Stage
一个Stage对应一个TaskSet,一个TaskSet中有多个Task
Task的数量由最后一个RDD所对应的分区个数决定
application:
使用SparkSubmit提交的个计算应用,一个Application中可以触发多次Action,触发一次Acition形成一个完整的DAG,一个DAG对应一个Job,一个Application中可以有一到多个Job.
一个Job中有一到多个Stage,一个stage对应一个taskSet;里面有多个task,而task的个数取决于最后一个RDD有几个分区,有几个分区就有几个task,task会并行执行,
一台机器一个worker,同一个worker可以有多个executor,但这多个executor,不能来自同一个application
8.2 DAG
有向无环图:有方向的无闭环的图
对多个RDD转换过程和依赖关系的描述:RDD串
触发Action就会形成一个完整的DAG,一个DAG就是1个Job
8.3 Stage
任务执行的阶段,shufle的时候会划分阶段
8.4 Task
taskSet:
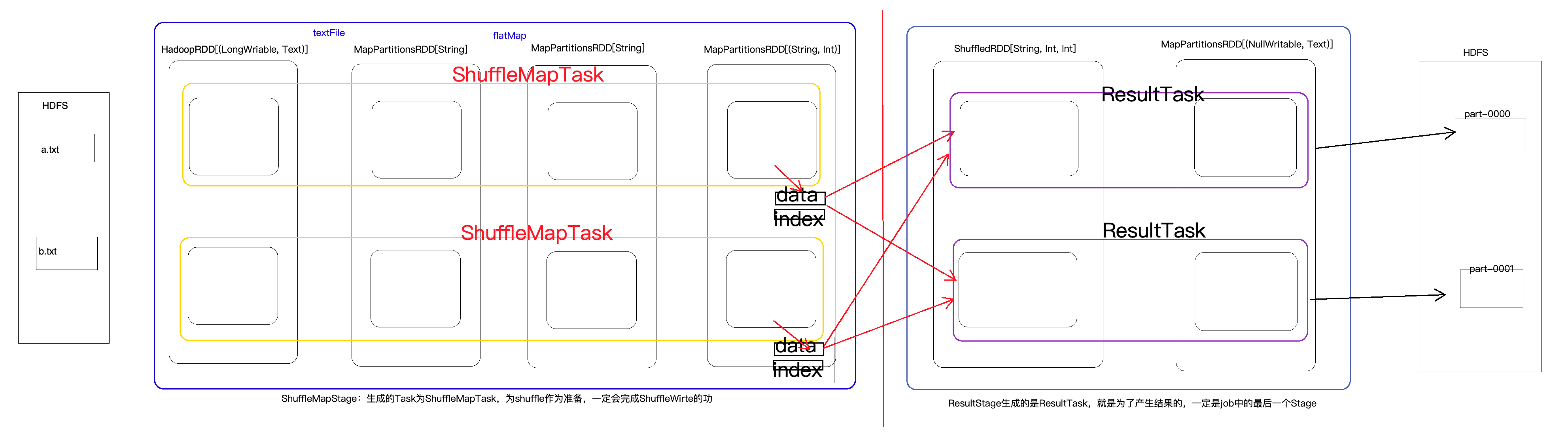
概念:Spark中任务最小的执行单元,Task分类两种,即ShuffleMapTask和ResultTask
Task其实就是类的实例,有属性(从哪里读取数据),有方法(如何计算),Task的数量决定决定并行度,同时也要考虑可用的cores.
一个stage对应一个taskSet;里面有多个task,而task的个数取决于最后一个RDD有几根分区,有几个分区就有几个task,task会并行执行,task中的逻辑都是一样的,但处理的数据不同
task在Driver端生成,发给executor,然后worker再反序列化,在executor端执行,RDD也是再Driver端生成,但最后都是发送到Worker端的executor
task在执行的时候,读数据的时候,会通过迭代器链,边迭代边运算,当需要shuffle的时候,便会应用分区器溢写磁盘,溢写磁盘的时候,会生成一个数据文件,并且还会溢出一个索引文件,用来描述数据文件中的数据的偏移量所对应分区
下游要从上游拉取数据,先读索引文件,获取数据在文件的哪个位置,然后就到对应的文件去拉取数据
8.5 迭代器
迭代器:
相当于一个工具,从集合中拿数据,进行处理,再放到一个集合中。类似于,用手从鸡窝中拿鸡蛋,然后放到篮子里,迭代器的作用就相当于手。
8.6 Spark执行详细流程
stage与task:
1)shuffleMapStage---对应的Task为--->shuffleMapTask:
为shuffl做准备的stage,一定会完成shuffleWrite的功能,溢写磁盘(按照分区编号)
会写出两个文件,一个索引文件,一个数据文件
2)ResuleStage---对应的Task为--->ResuleTask:
结果Stage,一定是最后一个stage,产生结果的stage
3)当没有shuffle的时候,只有一个stage,这个stage为ResultStage
4)当有多个stage的时候(stage0,stage1,stage2,stage3),前面的都是shuffleMapStage,最后一 个(stage3)是ResultStage
*shuffleMapTask:
可以读取原始数据
可以读取上游shuffleWrite的数据
一定会shuffleWrite,溢写磁盘
*ResuleTask:
可以读取原始数据
可以读取上游shuffleWrite的数据
一定会将结果输出

鍜孯esultTask.png)]
Spark执行详细流程:
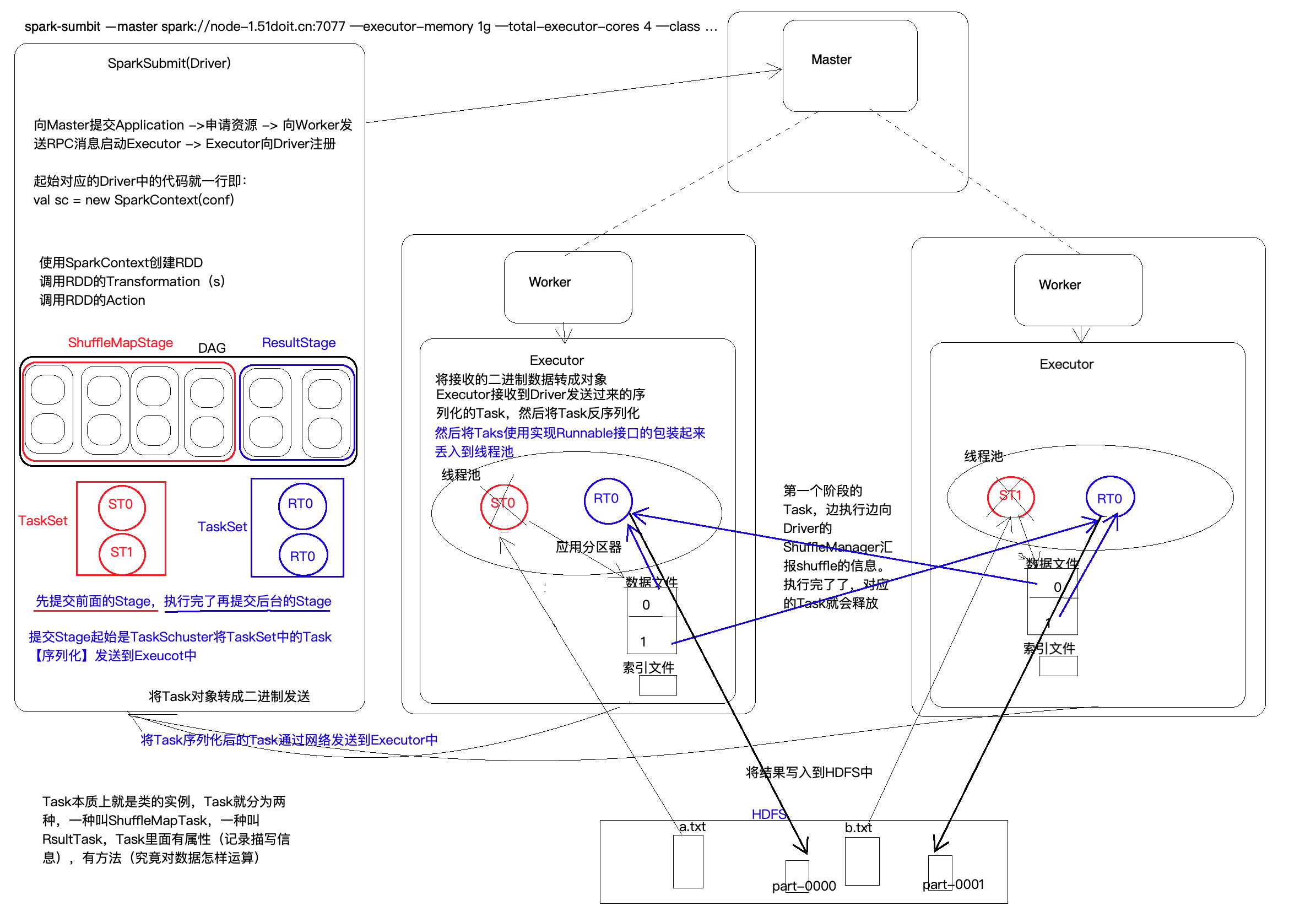
1)向Master提交Application,Master接受任务后通过RPC通信使Worker开启Executor.Executor启 动后向Driver端进行注册。
2)在Driver端使用SparkContext创建RDD,调用RDD的算子。然后在Driver端构建DAG,切分Stage,生成Task,将task序列化发送到Executor端。
shuffle之前的stage称为ShuffleStage,最后一个Stage称为ResultStage。ShuffleStage中的task称为ShuffleMapStage,ResultStage中的task称为ResultTask。一个stage便是一个完整的DAG,Stage中task的数量为本stage最后一个RDD的分区数量,然后会将task放到一个TaskSet中,然后将TaskSet中的task序列化发送到Executor端。task本质就是一个类的实例,里面由属性(一些描述信息),有方法(对数据的运算逻辑)。
提交stage的时候,从ResultStage开始往前推,直到第一个stage,然后从第一个stage开始提交。
3)提交到Executor后,将task反序列化,使用实现了Runnable接口的包装类包装起来,然后丢到线程池中,执行里面的运算逻辑。
当有shuffle的时候,会溢写到本地磁盘,默认是写入到Hdfs中,溢写的时候,会生成一个索引文件,一个数据文件。索引文件描述了数据的起始偏移量;数据文件中会将数据按照分区编号存储在文件的不同位置,方便下游拉取各个分区的数据。shuffle的时候边迭代边运算边shuffle。当task执行结束后,task会被释放。
4)当运算结束后,会将结果发送到Driver端,或者将结果写入到保存的文件中(比如Hdfs中)
8.7 Master、Worker、Executor、Driver、SparkSubmit
Master:
是一个java进程,负责管理worker,与worker之间有心跳机制,负责资源的调度,命令Worker开启Executor
Worker:
是一个java进程,向Master注册并发送心跳,负责开启Executor,并且监控Executor
SparkSubmit:
是一个java进程,负责向Master提交任务
Driver:
在client模式中,Driver是运行在SparkSubmit中的,在cluster模式中,Driver是单独运行在一个进程中的,负责构建DAG,划分stage,生成task,并将task发到executor中执行,并且监控task的执行状态
Executor:
是一个java进程,由Worker开启,负责执行task中的逻辑,将task放到线程中运行
九、实战案例
9.1 统计 TopN
9.1.1 方式1
/*
Author: Tao.W
D a te: 2021/8/2
Description:
分组求topN 求每个科目最受欢迎的前三位老师
map :将数据变为((subject, teacher), 1)
reduceByKey :(_+_)
groupBy : (_._1._1)
mapValues : iter.toList.sortBy(-_._2).take(3)
*/
object TeacherTop {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("teacher1").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\teacher.log")
//将数据变为-->((subject, teacher), 1)-->再按key聚合
val reduced = lines.map(line => {
val arr = line.split("/")
val teacher = arr(3)
val subject = arr(2).split("[.]")(0)
((subject, teacher), 1)
}).reduceByKey(_ + _)
val grouped: RDD[(String, Iterable[((String, String), Int)])] = reduced.groupBy(_._1._1)
val res = grouped.mapValues(iter => {
//组内返回前三
val res1 = iter.toList.sortBy(-_._2).take(3)
res1.map(e=>(e._1._2,e._2))
})
println(res.collect().toBuffer)
}
}
9.1.2 方式2
/*
将迭代器变为list再排序固然可以,但当数据太大的时候,集合边可能放不下,导致内存溢出,
所以进行改进,将数据进行过滤后再输出
*/
object TeacherTop2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("teacher1").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\teacher.log")
//将数据变为-->((subject, teacher), 1)-->再按key聚合
val reduced = lines.map(line => {
val arr = line.split("/")
val teacher = arr(3)
val subject = arr(2).split("[.]")(0)
((subject, teacher), 1)
}).reduceByKey(_ + _)
//过滤出每个科目的数据,然后对每个科目进行取top
val subjects: Array[String] = reduced.map(_._1._1).collect().distinct
for(sb <- subjects){
val filtered: RDD[((String, String), Int)] = reduced.filter(_._1._1.equals(sb))
implicit val ord = Ordering[Int].on[((String, String), Int)](-_._2)
val res = filtered.top(3)(ord)
println(res.toBuffer)
}
}
}
9.1.3 方式3 自定义分区器
/*
进行了改进:在聚合的时候,使用自定义的分区器,按照科目进行分区,同一科目的数据到同一个分区,然后再区内取topN
在聚合的时候使用指定的分区器,这样边少了一次shuffle,效率更高些。因为reduceByKey的时候会进行shuffle,最后
拿到聚合结果,但使用的分区器是HashPartition,之后又使用自定义的分区器重新分区,无疑又进行了一次shuffle,
这两步完全可以合并到一起,在聚合的时候指定分区器
*/
object TeacherTop4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("teacher1").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\teacher.log")
//将数据变为-->((subject, teacher), 1)-->再按key聚合
val subjectAndOne = lines.map(line => {
val arr = line.split("/")
val teacher = arr(3)
val subject = arr(2).split("[.]")(0)
((subject, teacher), 1)
})
val subjects = subjectAndOne.map(_._1._1).distinct().collect()
val subjectPartition = new SubjectPartition2(subjects)
//在聚合的时候使用自定义的分区器,使同一个subject的数据跑到一起,且实现了聚合
val reduced: RDD[((String, String), Int)] = subjectAndOne.reduceByKey(subjectPartition, _ + _)
val res = reduced.mapPartitions(iter => {
iter.toList.sortBy(-_._2).take(3).toIterator
})
println(res.collect().toBuffer)
}
}
class SubjectPartition2 (val subjects:Array[String]) extends Partitioner {
val nameToIndex = new mutable.HashMap[String,Int]()
var index =0
for(subject <- subjects){
nameToIndex(subject) = index
index +=1
}
override def numPartitions: Int = subjects.length
override def getPartition(key: Any): Int = {
val subject = key.asInstanceOf[(String, Int)]._1
nameToIndex(subject)
}
}
9.1.4 方式4 自定义有界优先队列
/*
重要重要重要:
当是取topN的时候,可以使用有界优先队列来代替将数据放到集合进行排序,再取前三,可以有效的防止内存溢出
在排序的时候前面都是放到List中再排序,只是不断的进行分区,减少排序的数据量,以防止内存溢出
**有一个很好的方法,可以不用将数据放到list中进行排序,如果是取topN,则可以使用有界优先队列,边迭代边排序边更新取前三
前面的几个再排序取topN的时候,也可以换为这种方式:有界优先队列,TreeSet
先聚合,然后按科目分组
然后定义一个类似有界优先队列的TreeSet,实现排序取topN
定义有界优先队列
*/
object TeacherTop5 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("teacher1").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\teacher.log")
//将数据变为-->((subject, teacher), 1)-->再按key聚合
val reduced = lines.map(line => {
val arr = line.split("/")
val teacher = arr(3)
val subject = arr(2).split("[.]")(0)
((subject, teacher), 1)
}).reduceByKey(_ + _)
//同一个subject的数据都跑到一个组里面,key是subject,value是((subject, teacher), 1)
val grouped: RDD[(String, Iterable[((String, String), Int)])] = reduced.groupBy(_._1._1)
val res = grouped.mapValues(it => {
/*
implicit val ord = Ordering[Double].on[((String, String), Double)](t => -t._2)
元组有自己的排序方法,Double或者String都可以这样排序
*/
implicit val ord = Ordering[Int].on[((String, String), Int)](t => -t._2)
val treeSet = new mutable.TreeSet[((String, String), Int)]()
val iter = it.toIterator
while (iter.hasNext) {
val tuple = iter.next()
treeSet += tuple
if (treeSet.size > 3) {
treeSet -= treeSet.last
}
}
treeSet
})
println(res.collect().toBuffer)
}
}
9.1.5 使用repartitionAndSortWithinPartition
/*
Author: Tao.W
D a te: 2021/8/4
Description:
使用repartitionAndSortWithinPartition
需要自定义分区器:按照subject进行分区
自定义排序的规则:按照次数进行排序
repartitionAndSortWithinPartition是按照key进行排序,所以key里应该由subject和counts
所以进行map一下,将数据变为reduced.map(t => ((t._2,t._1._1,t._1._2),null))
*/
object TeacherTop6 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("teacher6").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\teacher.log")
//将数据变为-->((subject, teacher), 1)-->再按key聚合
val reduced = lines.map(line => {
val arr = line.split("/")
val teacher = arr(3)
val subject = arr(2).split("[.]")(0)
((subject, teacher), 1)
}).reduceByKey(_ + _)
val subjects = reduced.map(_._1._1).distinct().collect()
//(次数,学科,老师) 因为repartitionAndSortWithinPartitions的排序字段必须是key
val countsAndSubjct = reduced.map(t => ((t._2,t._1._1,t._1._2),null))
val partition = new MyPartition3(subjects) //自定义分区器
implicit val ord = Ordering[Int].on[(Int,String,String)](t => -t._1) //自定义排序规则
//重新分区并且区内排序
val res1 = countsAndSubjct.repartitionAndSortWithinPartitions(partition)
val res = res1.mapPartitions(iter => {
val tuples = iter.take(3)
tuples.map(t=>(t._1._2,t._1._3,t._1._1))
})
println(res.collect().toBuffer)
}
}
class MyPartition3 (val subjects : Array[String]) extends Partitioner {
val numToIndex = new mutable.HashMap[String,Int]()
var index = 0
for(sb <- subjects){
numToIndex(sb) = index
index +=1
}
override def numPartitions: Int = subjects.length
override def getPartition(key: Any): Int = {
val subject = key.asInstanceOf[(Int,String,String)]._2
numToIndex(subject)
}
}
9.2 根据IP计算归属地
/*
Author: Tao.W
D a te: 2021/8/4
Description:
读取ip规则数据
*/
object IpToCity {
def main(args: Array[String]): Unit = {
//读取ip规则数据
val conf = new SparkConf().setAppName("IpToCity").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\ip.txt")
val ipOrd = lines.map(line => {
val arr = line.split("[|]")
val startIp = arr(2).toLong
val endIp = arr(3).toLong
val province = arr(6)
val city = arr(7)
(startIp, endIp, province,city )
})
val ipOrds = ipOrd.collect()
//将规则数据进行广播分发到相应的executor的内存上
val broadCasted = sc.broadcast(ipOrds)
//读访问日志
val lines2 = sc.textFile("E:\\work2\\mrdata\\data\\ipaccess.log")
val provinceAndOne = lines2.map(line => {
val ip1 = line.split("[|]")(1)
val ip: Long = IpUtils.ipToLong(ip1)
//根据ip地址对应的十进制进行查询(查询IP规则数据)
//获取事先已经广播到Executor的数据了
val broadCastedValue: Array[(Long, Long, String, String)] = broadCasted.value
val index = IpUtils.binarySearch(broadCastedValue, ip)
var province = "未知"
if (index >= 0) {
province = broadCastedValue(index)._3
}
(province, 1)
})
val res = provinceAndOne.reduceByKey(_ + _)
println(res.collect().toBuffer)
}
}
package com.doit.workers.work3
import scala.collection.mutable.ArrayBuffer
/*
Author: Tao.W
D a te: 2021/8/4
Description:
上面使用到的工具类
将ip转为十进制的方法
二分查找法
*/
object IpUtils {
//将ip转为十进制的方法
def ipToLong(ip: String): Long = {
val fragments = ip.split("[.]")
var ipNum = 0L
for (i <- 0 until fragments.length) {
ipNum = fragments(i).toLong | ipNum << 8L
}
ipNum
}
/**
* 二分法查找
根据ip的十进制,来查找ip所在的范围
*/
def binarySearch(lines : Array[(Long,Long,String,String)] , orderIp : Long): Int ={
var start = 0
var end = lines.length - 1
while(start <= end){
var middle = (start+end) / 2
if(orderIp >= lines(middle)._1 && orderIp <= lines(middle)._2) {
return middle
} else if(orderIp <= lines(middle)._1){
end = middle-1
}else if(orderIp >= lines(middle)._2){
start = middle+1
}
}
-1
}
}
9.3 自定义排序规则
/*
Author: Tao.W
D a te: 2021/8/4
Description:
自定义排序规则
*/
object MySort2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("IpToCity").setMaster("local[*]")
val sc = new SparkContext(conf)
//创建
val lst = List("老段,38,99.99", "念行,30,99.99", "老赵,36,9999.99")
val linesRDD = sc.parallelize(lst)
val teachers = linesRDD.map(line => {
val fields = line.split(",")
val name = fields(0)
val age = fields(1).toInt
val fv = fields(2).toDouble
Teacher(name, age, fv)
})
//使用自定义的排序规则
import com.doit.workers.work4.MyOrder.OrdingTeache
val res = teachers.sortBy(t => t)
println(res.collect().toBuffer)
}
}
case class Teacher (name:String,age:Int,face:Double)
//
/*
Author: Tao.W
D a te: 2021/8/4
Description:
*/
object MyOrder {
implicit object OrdingTeache extends Ordering[Teacher] {
override def compare(x: Teacher, y: Teacher): Int = {
if(x.face == y.face){
x.age - y.age
}else{
y.face.compare(x.face)
}
}
}
}
/*
对于自定义的数据类型,可以使用自定义的排序规则
再使用orderBy的时候可以传一个隐式参数,通过自己写隐式参数来实现自定义的排序规则
对于元组的数据类型,则直接使用元组的排序规则,则是十分的方便
*/
object MySort {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("IpToCity").setMaster("local[*]")
val sc = new SparkContext(conf)
//创建
val lst = List("老段,38,99.99", "念行,30,99.99", "老赵,36,9999.99")
val linesRDD = sc.parallelize(lst)
val tuple3 = linesRDD.map(line => {
val fields = line.split(",")
val name = fields(0)
val age = fields(1).toInt
val fv = fields(2).toDouble
(name, age, fv)
})
val sorted = tuple3.sortBy(t => (-t._3, t._2, t._1))
println(sorted.collect().toBuffer)
}
}
9.4 统计用户的连续登录天数
object ContinuedLogin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ContinuedLogin").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\login.log")
//(1) 将uid和日期放到元组里
val uidAndDate = lines.map(line => {
val arr = line.split(",")
val uid = arr(0)
val date = arr(1)
(uid, date)
}).distinct()
//(2) 按照uid进行分组 ,key是uid而组内数据是uid的每次登录时间
val grouped: RDD[(String, Iterable[String])] = uidAndDate.groupByKey()
//(3) 对value进行操作, 将字符串转为日期,然后进行排序、与标记数进行相减得到时间间隔diff
// 最后返回(String, (String, String)) -->(uid,(date,diff))
val uidAndDiff: RDD[(String, (String, String))] = grouped.flatMapValues(iter => {
val sorted = iter.toList.sorted
var index =1
val dateFormat = new SimpleDateFormat("yyyy-MM-dd")
val calendar = Calendar.getInstance()
sorted.map(dt =>{
//将字符串解析成日期
val date = dateFormat.parse(dt)
calendar.setTime(date)
//使用日期的相减函数,将日期减一
calendar.add(Calendar.DATE,-index)
index +=1
//将日期和日期相减后的数据再进行格式化成日期,放到元组中
(dt,dateFormat.format(calendar.getTime))
})
})
//(4) 将上面的数据进行聚合 、过滤、得到连续登录大于3天的用户的uid和起始时间和连续登录天数
// 这里的聚合函数不仅是做了相加的操作 还有其他操作 比较优秀
val result = uidAndDiff.map {
case (uid, (dt, diff)) => ((uid, diff), (dt, dt, 1))
}
.reduceByKey((a, b) => {
val start = Ordering[String].min(a._1, b._1)
val end = Ordering[String].max(a._1, b._1)
val total = a._3 + b._3
(start, end, total)
})
.map {
case ((uid, diff), (start, end, total)) => (uid, total, start, end)
}
.filter(_._2 >= 3)
//输出结果
println(result.collect().toBuffer)
}
}
第二种方式来实现:与第一种方式各有利弊
object ContinuedLogin2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ContinuedLogin2").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\login.log")
//(1) 将uid和日期放到元组里
val uidAndDate = lines.map(line => {
val arr = line.split(",")
val uid = arr(0)
val date = arr(1)
(uid, date)
}).distinct()
/*
(2) 按照uid进行分组 ,key是uid而组内数据是uid的每次登录时间
使用分组,然后在组内排序,如果一个组内的数据过多,可能会内存溢出
val grouped: RDD[(String, Iterable[String])] = uidAndDate.groupByKey()
这里采用自定义分区器,按照uid进行分区,按照日期进行排序
repartitionAndSortWithinPartitions
*/
val uids: Array[String] = uidAndDate.keys.distinct().collect()
val uidDateAndNull = uidAndDate.map {
case (uid, date) => ((uid, date), null)
}
val partition = new UidPartition(uids)
val sorted: RDD[((String, String), Null)] = uidDateAndNull.repartitionAndSortWithinPartitions(partition)
//(3) 对value进行操作, 将字符串转为日期,然后进行排序、与标记数进行相减得到时间间隔diff
val uidAndDateAndDiff: RDD[(String, String, String)] = sorted.mapPartitions(it => {
var index =1
val dateFormat = new SimpleDateFormat("yyyy-MM-dd")
val calendar = Calendar.getInstance()
it.map(dt =>{
//将字符串解析成日期
val date = dateFormat.parse(dt._1._2)
calendar.setTime(date)
//使用日期的相减函数,将日期减一
calendar.add(Calendar.DATE,-index)
index +=1
//(uid,date,diff)
(dt._1._1,dt._1._2,dateFormat.format(calendar.getTime))
})
})
//(4) 将上面的数据进行聚合 、过滤、得到连续登录大于3天的用户的uid和起始时间和连续登录天数
// 这里的聚合函数不仅是做了相加的操作 还有其他操作 比较优秀
val result = uidAndDateAndDiff.map {
case (uid, dt, diff) => ((uid, diff), (dt, dt, 1))
}
.reduceByKey((a, b) => {
val start = Ordering[String].min(a._1, b._1)
val end = Ordering[String].max(a._1, b._1)
val total = a._3 + b._3
(start, end, total)
})
.map {
case ((uid, diff), (start, end, total)) => (uid, total, start, end)
}
.filter(_._2 >= 3)
println(result.collect().toBuffer)
}
}
//自定义的分区器 按照uid进行分区 :缺陷是用户太多的时候,明显分区数量太多了
class UidPartition (val uids : Array[String])extends Partitioner {
val uidToIndex = new mutable.HashMap[String,Int]()
var index = 0
for(uid <- uids){
uidToIndex(uid) = index
index +=1
}
override def numPartitions: Int = uids.length
override def getPartition(key: Any): Int = {
val uid = key.asInstanceOf[(String, String)]._1
uidToIndex(uid)
}
}
9.5 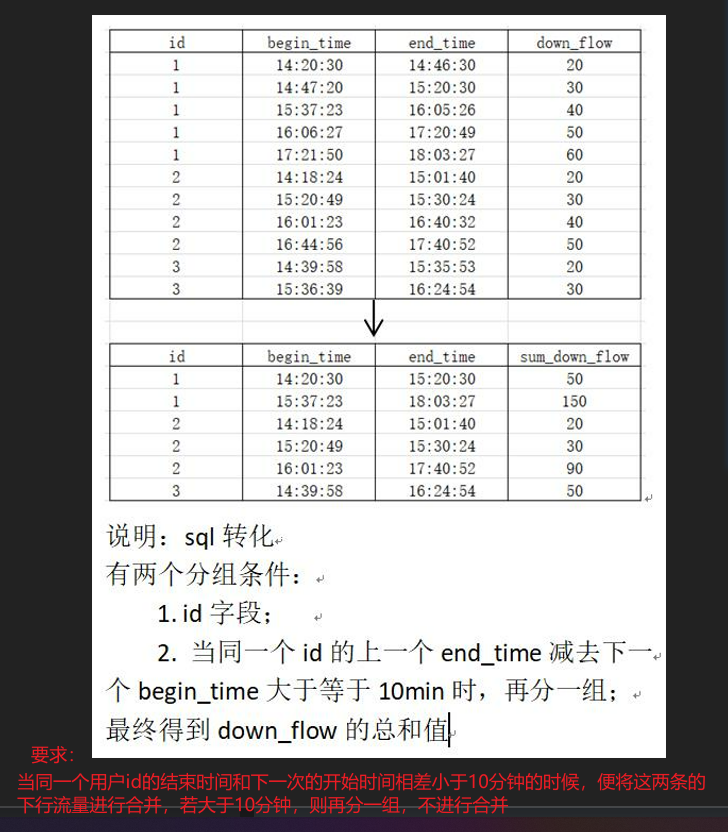
(重要)
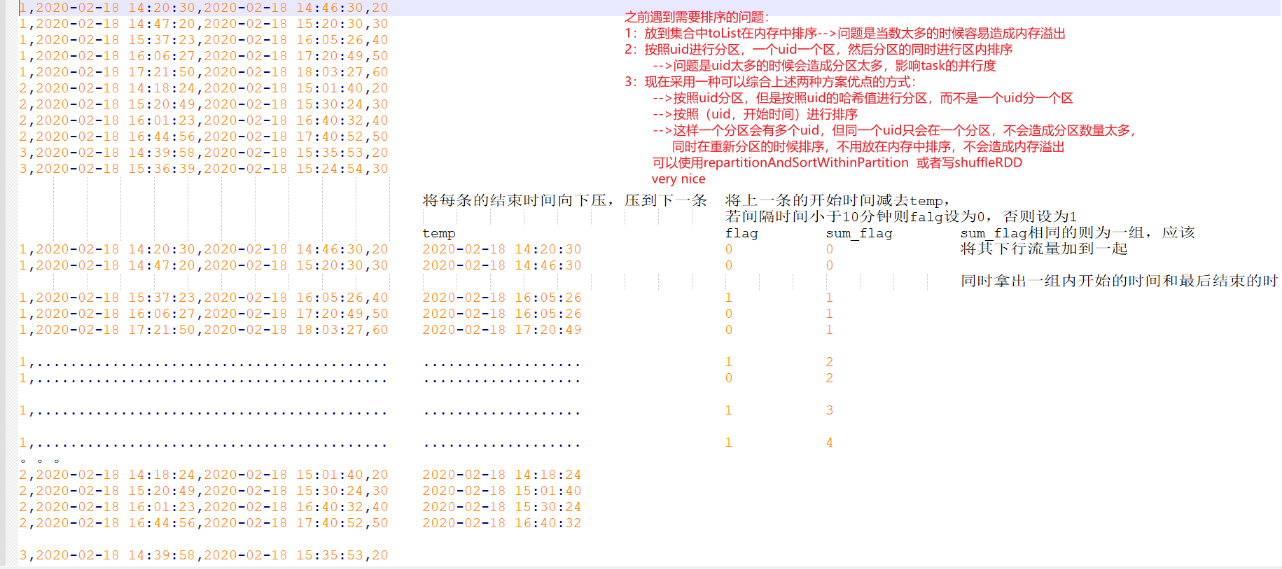
object FlowCount3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("FlowCount2").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\work2\\mrdata\\data\\data.csv")
//希望分区且排序
val uidStartAndEndFlow: RDD[((String, String), (String, Int))] = lines.mapPartitions(it => {
//val dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
it.map(e => {
val fields = e.split(",")
val uid = fields(0)
val start = fields(1)
val end = fields(2)
val flow = fields(3).toInt
//val startTime = dateFormat.parse(start).getTime
//val endTime = dateFormat.parse(end).getTime
((uid, start), (end, flow))
})
})
//val partitioner = new HashPartitioner(uidStartAndEndFlow.partitions.length)
val partitioner = new MyHashPartitioner(uidStartAndEndFlow.partitions.length)
val shuffled = new ShuffledRDD[(String, String), (String, Int), (String, Int)](uidStartAndEndFlow, partitioner)
val ord = Ordering[(String, String)]
shuffled.setKeyOrdering(ord)
val result: RDD[((String, Int), (String, String, Int))] = shuffled.mapPartitions(it => {
val dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
var temp = 0L
var flag = 0
var sum_flag = 0
var tempUid: String = null
it.map {
case ((uid, start), (end, flow)) => {
val startTime = dateFormat.parse(start).getTime
val endTime = dateFormat.parse(end).getTime
//用户ID不为空,并且当前用户的ID跟上一条的ID相同
if (tempUid != null && !uid.equals(tempUid)) {
temp = 0L
flag = 0
sum_flag = 0
}
if (temp == 0) {
temp = startTime
}
if (startTime - temp > 600000) {
flag = 1
} else {
flag = 0
}
temp = endTime
tempUid = uid
sum_flag += flag
((uid, sum_flag), (start, end, flow))
}
}
}).reduceByKey((a, b) => {
val start = Ordering[String].min(a._1, b._1)
val end = Ordering[String].max(a._2, b._2)
val sum = a._3 + b._3
(start, end, sum)
})
println(result.collect().toBuffer)
}
}
class MyHashPartitioner(val num: Int) extends Partitioner {
override def numPartitions: Int = num
override def getPartition(key: Any): Int = {
val uid = key.asInstanceOf[(String, String)]._1
nonNegativeMod(uid.hashCode, numPartitions)
}
def nonNegativeMod(x: Int, mod: Int): Int = {
val rawMod = x % mod
rawMod + (if (rawMod < 0) mod else 0)
}
}
十、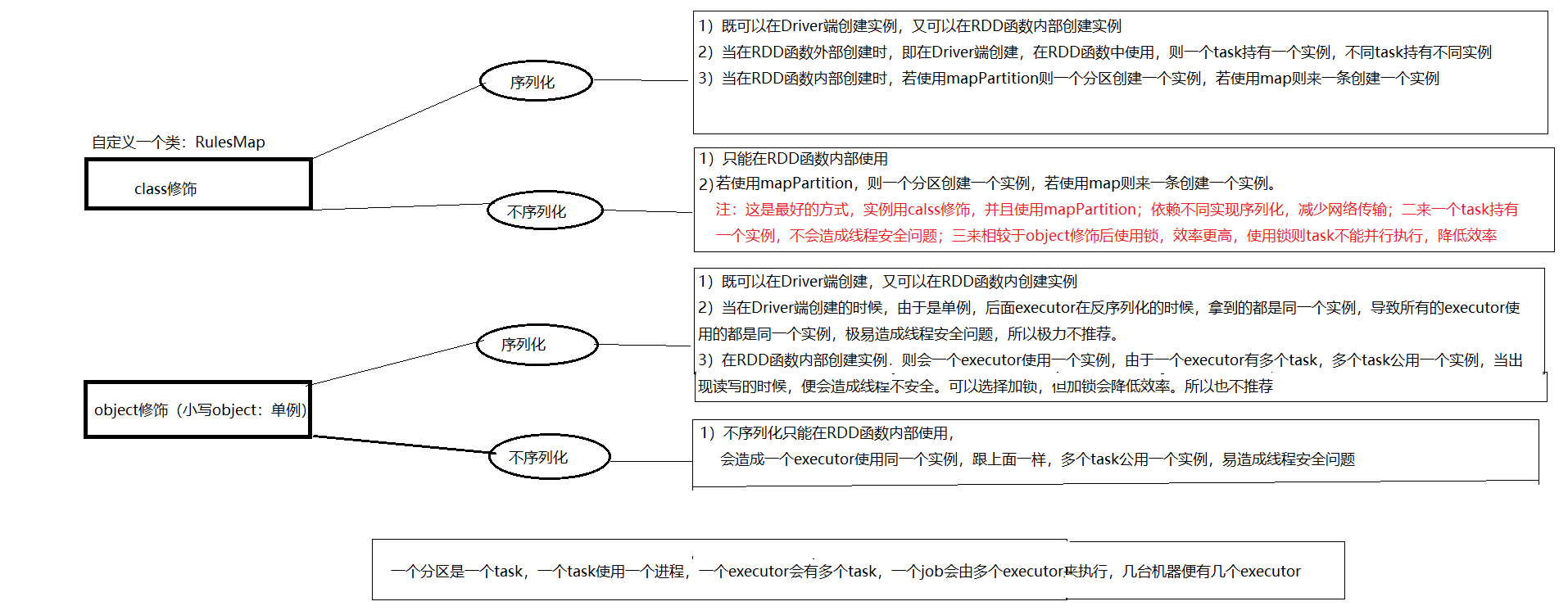
一个对象在Driver端创建,在RDD中持有了这个对象的引用,即持有外部引用。若这个外部引用不能被序列化,则会报序列化异常的错误,
在task生成之前,RDD算子会检测引用是否可以序列化,若不能则会直接报错,此时task根本无法生成。
1)一个分区使用一个task,一个task使用的是同一个外部引用对象,使用同一个实例,使用一个进程 在一个机器的executor上运行,同一个task不会在多个executor上运行
2)不同分区使用不同task,不同task使用的是不同的外部引用对象,使用不同的实例,使用不同的进程
3) 在scala中使用小写的object 来修饰类,则这个类是单例,后续在一个executor中即使有多 个task,持有的也都是同一个实例,不同executor会持有不同的实例
因为单例只能由一个,所以在executor端反序列化的时候,只能创建一个,所以在一个 executor中即使有多个task,持有的也都是同一个实例。不同executor会独自进行序列化,故 不同executor会持有不同的实例
4)若在RDD内部创建实例,则不需要序列化
5) 比较nice的方式:在RDD内部创建实例,则不需要序列化,若这个实例是object修饰的,即单例, 则一个executor使用同一个实例,还不需要实现序列化
*但这种也会有个问题,一个executor有多个task,全都使用同一个实例,便容易引起线程安全的 问题
*解决:这种方式极力推荐
1)使用mapPartitions,一个分区使用一个迭代器,在这里面使用class修饰的实例,
这样一来,既不用实现序列化进行网络传输,又是同一个task使用同一个实例,避免了 线程不安全问题
2)给实例加锁。但加锁会导致效率变慢,导致task不能并行执行,不推荐
6)在RDD内部创建实例,则不需要序列化,若这个实例不是object修饰的,即不是单例,则会由很多的实 例,具体看代码。会创建很多的实例,打死也不会用
结果:
这种方式极力推荐:
类不实现序列化,使用calss修饰,在RDD的mapPartition中创建实例
这样一来,既不用实现序列化进行网络传输,又是同一个task使用同一个实例,避免了 线程不安全问题
累加器:Accumulator
**累加器:accumulator
1)在做计算的时候,可以顺带做一些统计相关的计算(用于计数(比如数据中的偶数))
要使用spark提供的累加器,他能够在每个task进行累加,并且在Driver进行全局统计
2)累加器是每个task都持有自己的累加器,而不是一个executor公用一个累加器,因为累加器会进行加 减等读写操作,共用一个会造成线程安全问题
3)该累加器是calss修饰的实例,然后在RDD算子中使用,所以需要实现序列化
4)job结束后task便被释放,但是累加器却没有释放,此时再计算一次,累加器便会从之前的累加器的 结果上进行累加
解决方式:
1)在第一遍计算结束后进行catch。这样之前的计算逻辑便不会再计算一遍,自然累加器也 不会改变还是第一次计算结果的值
rdd2.cache()
2)在下一次重新计算之前,重置累加器(清空累加器)
accumulator.reset()
5)累加器可以用来做多种计算,比如处理数据的时候将脏数据收集起来
-->有一个collectionAccumulator集合,可以将脏数据收集到集合中,但如果脏数据太多,则明显不能使用,因为会占用大量内存,而且网络传输到Driver也会耗资源
val accumulator: CollectionAccumulator[String] = sc.collectionAccumulator[String]("err_data_collector")
//使用累加器
val beanRDD: RDD[Teacher] = lines.map(line => {
var bean: Teacher = null
try {
bean = JSON.parseObject(line, classOf[Teacher])
} catch {
case e: JSONException => {
//添加到集合累加器
accumulator.add(line) //不适合存放大量的数据,因为会占用Executor的内存,返回到Driver是也会占用网络IO
}
}
bean
})
**注:
1)RDD不能嵌套使用,即不能在RDD的算子中再调用RDD。
比如:rdd1.map(e=>{(e,rdd2.collect)}) 这样就是RDD嵌套,不可以使用
会因为SparkContext不存在而报错。因为SparkContext是在Driver端创建,如果在RDD内部调用了RDD,则RDD的逻辑是在executor端执行,所以会缺少SparkContext
2)reduceByKey要求value的返回结果跟原来的value类型要一致
十一、Shuffle过程详解(面试重要)
11.1 Hash Shuffle (已淘汰)
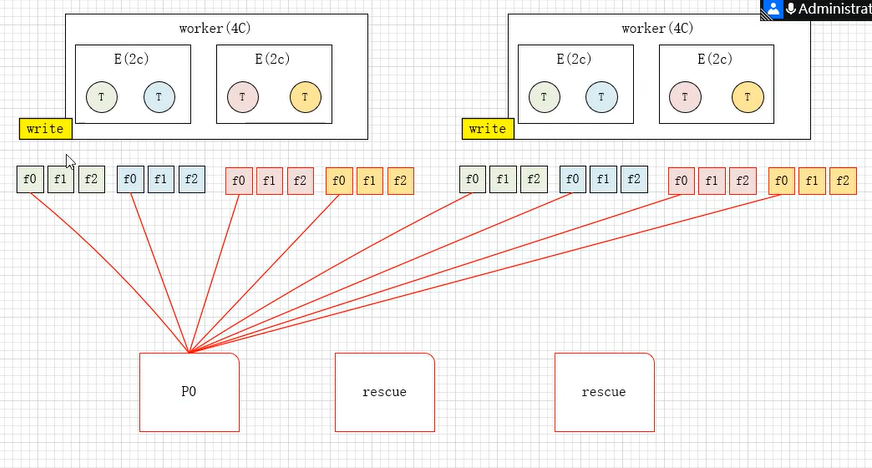
假设现在有两个worker,每个worker4个核,里面有两个Executor,每个E两个核,每个executor执行两个task,下游有三个分区:
在shuffle的时候,每个task都会溢写出三个文件,分别对应三个分区,然后下游在拉取数据的时候,要从上游的8个文件中去拉取,要频繁打开io。
这种方式产生的shuffle文件数量极多,是task数量*下游分区数 =8*3=24
11.2 HashShuffle改进
由于开始的hashShuffle会产生大量的小文件,所以进行了改进,将一个task生成的文件合并到一个文件中。在文件中打上分区的起始标签,方便下游拉取数据。
但是这样还时会产生大量小文件,如果task太多的话,也会产生很多的文件
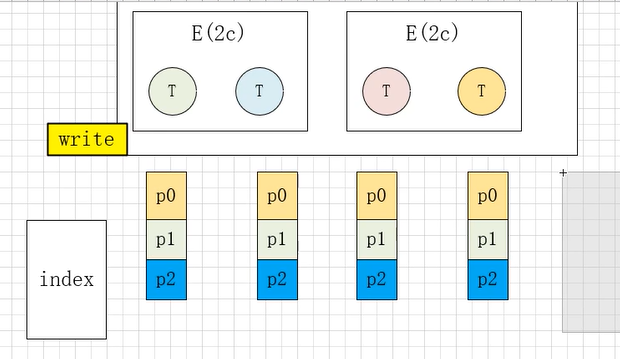
11.3 SortShuffleManager
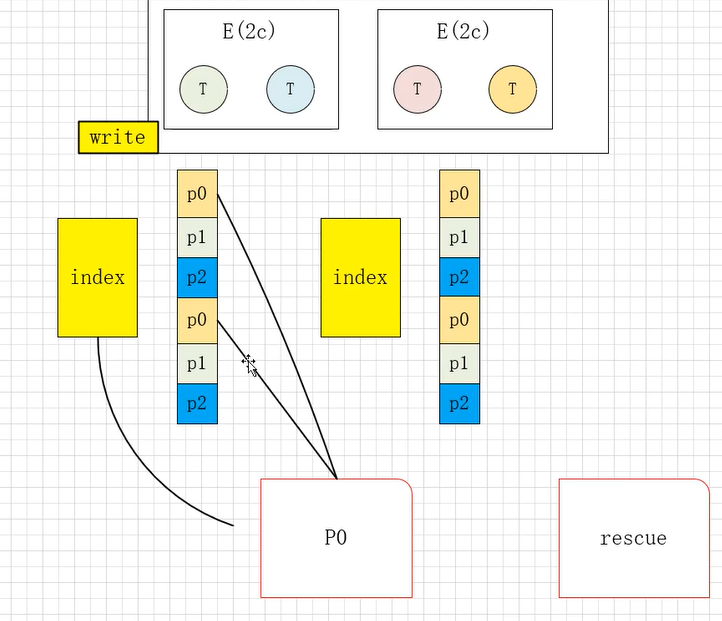
在之前的基础上进一步改进,将同一个executor中的所有task所shuffle的文件合并到一起,最终一个executor产生一个数据文件和一个索引文件,数据文件中按照task和分区进行排序,索引文件记录数据的起始位置。这样一来,一个executor产生一个文件,肯定不会生成大量小文件,而且进行了排序,方便下游拉取数据。
十二、Spark中的join场景
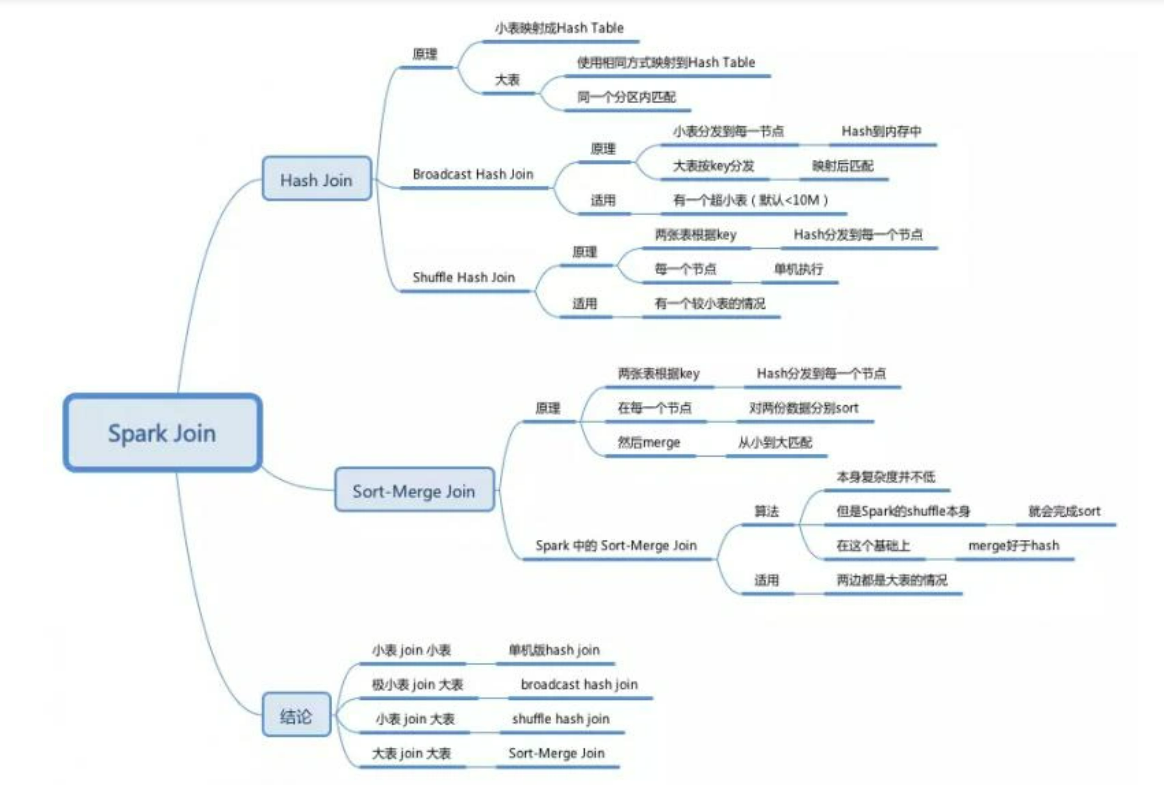
三种方式的Join:
①两个小表:hash join
②极小表(<10M)与大表:broadcast hash join
将小表数据放到广播中,作为广播变量,由Driver广播到每一个executor中
③小表与大表:shuffle hash join
将两个表的数据按照join的字段进行keyBy,从而key相同的进到同一个分区中,然后在各个区内进行join(每个区内使用的仍然是hash join,还是会将数据少的部分放到内存中进行join)
④两个大表:sort merge join
将两个表的数据按照join的字段进行keyBy,然后区内进行排序,然后两个表的数据会各自对应一个迭代器,然后两个迭代器同时进行迭代,边迭代边join,不再需要进行hash join
Hash join
普通的join就是hash join
会将其中一个较小表中的key进行hash 然后将hash值与对应的数据放到内存中(类似hashMap)
然后另外一张表对key进行同样的hash,然后就可以根据hash相同来join到对应的数据















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









