







Kafka
一、Kafka 基础
1.1 Kafka的特点
1.解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2.冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3.扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4.灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5.可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6.顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性)
7.缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8.异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
1.2 Kafka架构图
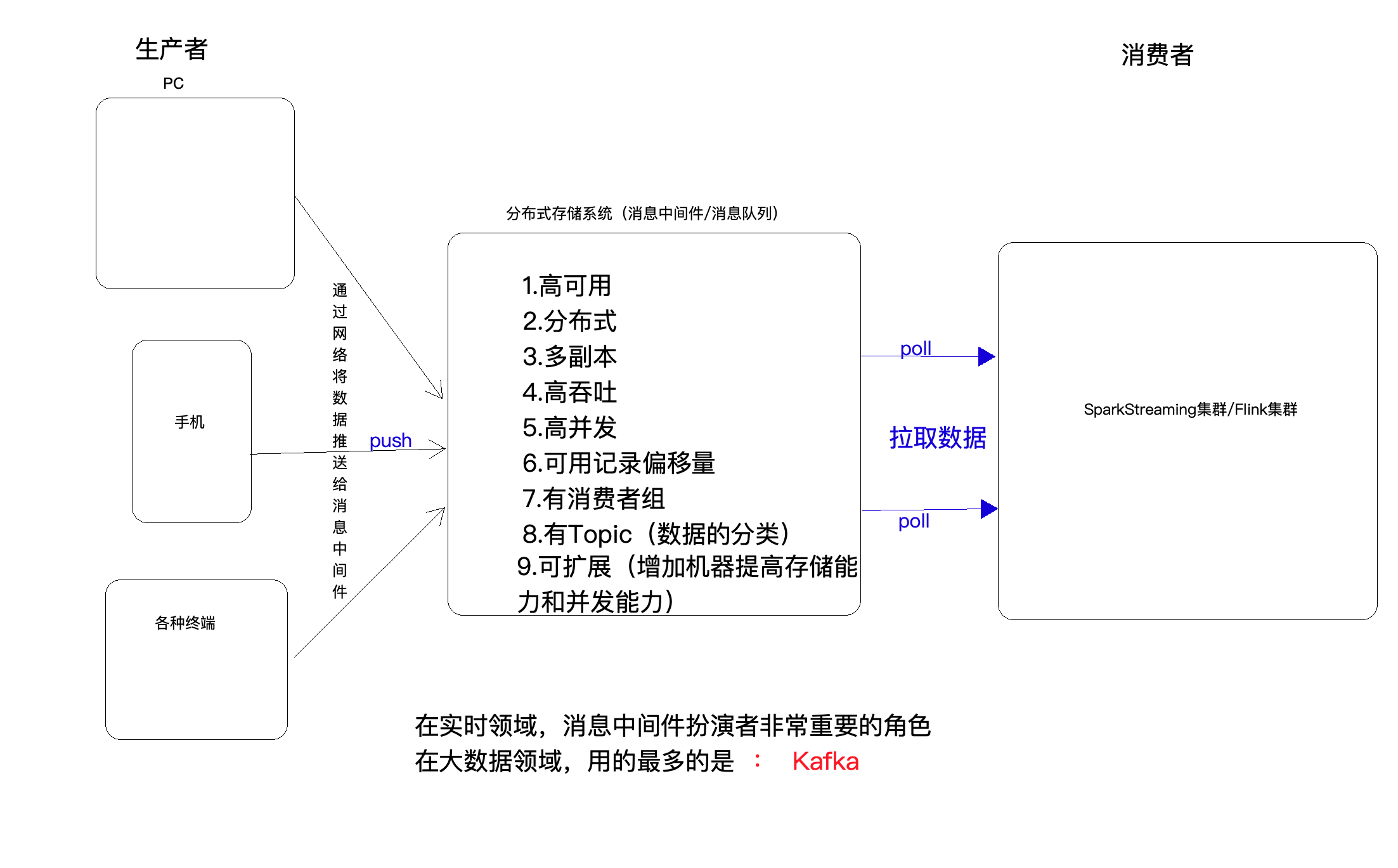
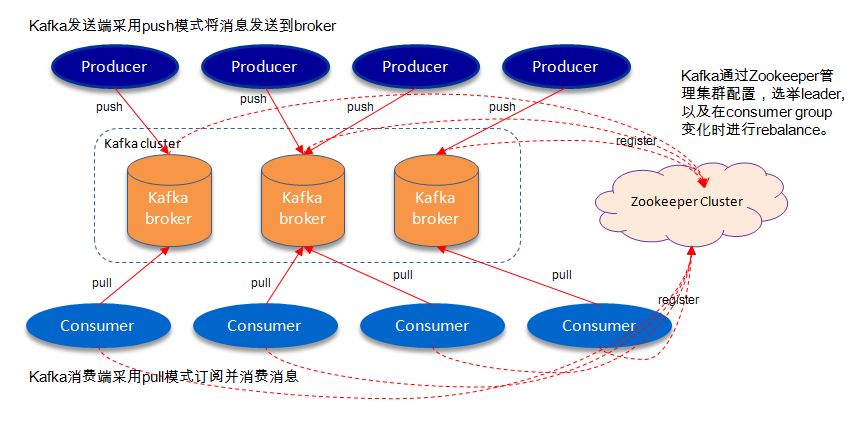
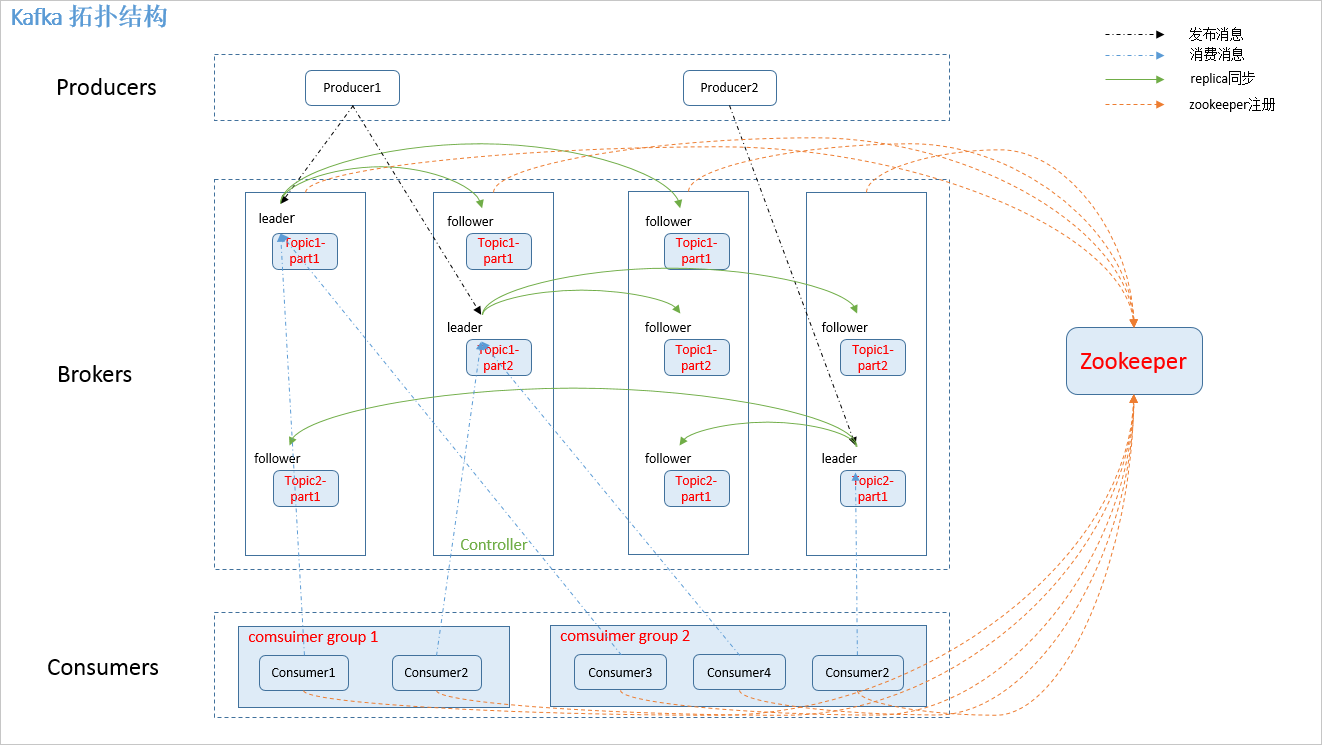
1.3 Kafka相关概念
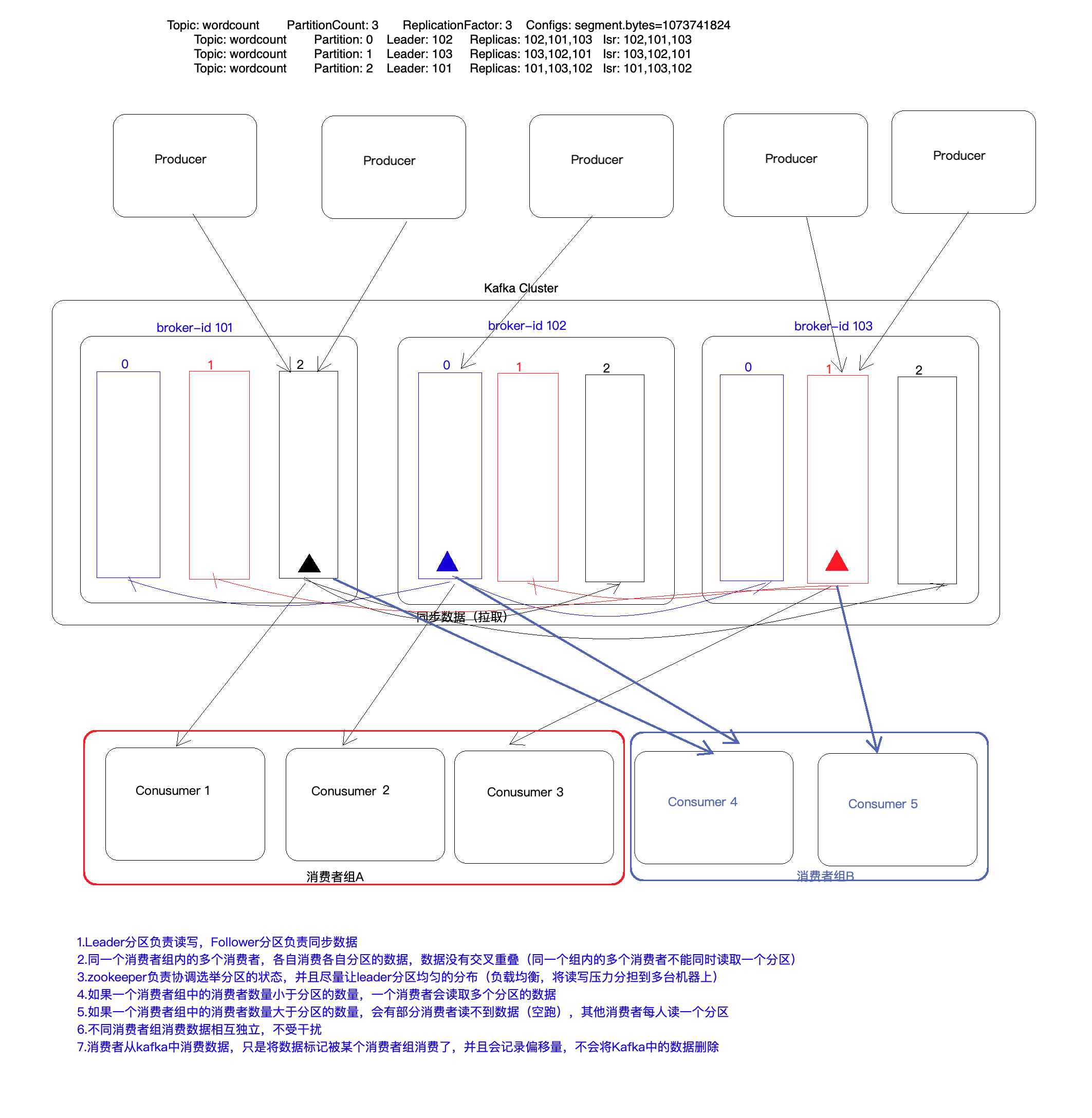
1.producer:
消息生产者,发布消息到 kafka 集群的Borker(下面的Leader分区)。
2.broker:
kafka 集群中安装Kafka的服务器(容器),broker要有唯一的ID。
3.topic:
每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的(相当于数据库中的表)
4.partition:
partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。
5.consumer:
从 kafka 集群中消费消息的终端或服务。
6.Consumer group:
high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
7.replication:
partition 的副本,保障 partition 的高可用。
8.leader:
replication 中的一个角色, producer 和 consumer 只跟 leader 交互(leader分区负责对象)。
9.follower:
replica 中的一个角色,从 leader 中复制数据(follower分区负责同步数据)。
10.zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息
总结:
1.Kafka的生产者直接向Broker的Leader分区写入数据,不需要连接ZK
2.Kafka的消费者(老的API需要先连接ZK,获取Broker信息和topic、分区偏移量信息),新的API不需要连接ZK(直连方式,新的API,底层的API,效率更高)
1.4 安装Kafka集群
一定要开启zookeeper
上传-->解压-->配置-->分发
- 上传Kafka安装包
- 解压
- 修改配置文件
vi servier.properties
properties
#指定broker的id
broker.id=101 -->分发到其他节点的brokerId要不同,101,102,103
#数据存储的目录
log.dirs=/data/kafka
#指定zk地址
zookeeper.connect=Linux01:2181,linux02:2181,linux03:2181
#可以删除topic的数据(生成环境不用配置)
#delete.topic.enable=true -->这个没有配置,所以删除的时候不会立马删除,会过段时间再删除
- 将配置好的kafka拷贝的其他节点
- 修改其他节点Kafka的broker.id
二、 启动Kafka
开启zookeeper
zk.sh start
/opt/apps/kafka_2.12-2.6.2/bin/kafka-server-start.sh -daemon /opt/apps/kafka_2.12-2.6.2/config/server.properties
2.1 在所有节点启动Kafka
-daemon是后台启动 每台节点都要开启kafka
/opt/apps/kafka_2.12-2.6.2/bin/kafka-server-start.sh -daemon /opt/apps/kafka_2.12-2.6.2/config/server.properties
2.2 查看Kafka进程信息
jps
进程中会有kafka的进程
2.3 查看Kafka的topic
#老的api
/bigdata/kafka_2.12-2.6.2/bin/kafka-topics.sh --list --zookeeper localhost:2181
#新的
/bigdata/kafka_2.12-2.6.2/bin/kafka-topics.sh --list --bootstrap-server linunx01:9092,linux02:9092,linux03:9092
2.4 创建topic
#老的
/bigdata/kafka_2.12-2.6.2/bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic hellokafka --replication-factor 3 --partitions 3
#x新的--可以指定topic的名称、分区数、副本数
/opt/apps/kafka_2.12-2.6.2/bin/kafka-topics.sh --create --topic access24 --partitions 4 --replication-factor 2 --bootstrap-server linux01:9092,linux02:9092,linux03:9092
2.5 启动命令行开启一个生产者
--可以开启多个生产者
/opt/apps/kafka_2.12-2.6.2/bin/kafka-console-producer.sh --broker-list linux01:9092,linux02:9092,linux03:9092 --topic test1
2.6 启动一个命令行开启一个消费者
--可以开启多个消费者
/opt/apps/kafka_2.12-2.6.2/bin/kafka-console-consumer.sh --bootstrap-server linux01:9092,linux02:9092,linux03:9092 --from-beginning --topic access24
--from-beginning 消费以前产生的所有数据,如果不加,就是消费消费者启动后产生的数据,还有其他的参数如latest
2.7 删除topic
/opt/apps/kafka_2.12-2.4.1/bin/kafka-topics.sh --delete --topic rulesTopic --zookeeper localhost:2181
2.8 查看topic详细信息
/opt/apps/kafka_2.12-2.6.2/bin/kafka-topics.sh --zookeeper linux01:2181 --describe
--topic test1
2.9 查看某个topic的偏移量
/opt/apps/kafka_2.12-2.6.2/bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server linux01:9092,linux02:9092,linux03:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config /opt/apps/kafka_2.12-2.6.2/config/consumer.properties --from-beginning
三、概念
3.1 producter写入的策略
数据的写入:会攒一批,然后再写入,而不是来一条写一条
1)若不指定key,不指定分区,则会轮巡写入,先往一个分区写一批,然后再换个分区写一批,轮流着 写。。。
2)若指定分区,则只会往指定的分区写
3)若指定key,则相同的key会跑到同一个分区,但同一个分区会有多个key,原理也是key取哈希值再模 分区数
3.2 偏移量
有三个因素决定:topic,分区,组id
topic不同 或者分区编号不同,或者组id不同,所记录的偏移量是不同的,只有偏移量的记录是分开的,就不会混乱
----偏移量
1)默认是自动提交偏移量,默认提交时间是5秒,这两个参数都可以更改
当把自动提交偏移量的参数改为false的时候,下次再读取的时候,就是从头读,因为没有记录偏移 量
2)--consumer_offsets一个特殊的topic,有50个分区,1个副本。所有自动提交偏移量的消费者都会 将偏移量写道这个topic中.这也预示着创建topic的时候不能用 下划线和点
有个缺点,默认是5秒保存一次偏移量,加入消费者将数据消费了,但是还没来得及提交偏移量就 挂掉了,这样便会造成数据的重复读取,可能会出问题
解决方式应该提交到事物中,偏移量提交成功了就消费,提交不成功就将数据回滚。
---手动提交偏移量:
1)同步提交--阻塞的 -->不提交完程序不往下进行
2)异步提交--异步的 -->开一个线程来提交偏移量,不会阻塞
3)手动指定偏移量提交的内容--同步提交--> 可以将偏移量中的数据取出来,然后手动提交部分 内容,比如不把每个偏移量都提交,而是把每个分区的最大偏移量取出来提交
4)手动指定偏移量提交的内容--异步提交,并且有回调函数-->
5)可能以后会把偏移量提交到mysql中等...
3.3 消费者组
1)同一个消费者组不会消费同样的数据,当消费数据的时候会更新偏移量,如果停掉再打开,即使是从 头开始消费,之前的数据也不会取到
2)同一个消费组内的不同消费者不会消费同一个分区的数据,换句话说,一个分区的数据,不能被同一 个组内的不同消费者消费,但可以被不同组的消费者同时消费,此时若将组id改了,再从头earliest 读数据,则可以读取到,若改为latest,即最近的,则只会读取新产生的数据
假设有4个分区,若一个组内的消费者有3个,则会有一个消费者消费两个分区的数据
若一个组内的消费者有4个,则一个消费者消费一个分区的数据
若一个组内的消费者有5个,则一个消费者消费一个分区的数据,剩下的一个 会一直等待,直到有个消费者挂掉了,便接替那个消费者所消费的分区的数据
四、Kafka 与 Idea
需要在虚拟机中开启zookeeper和Kafka
—生产者
object ProducerDemo {
def main(args: Array[String]): Unit = {
// 1 配置参数
val props = new Properties()
// 连接kafka节点
props.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")
//指定key序列化方式
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
//指定value序列化方式
props.setProperty("value.serializer", classOf[StringSerializer].getName) // 两种写法都行
val topic = "test1" //三个分区{0, 1, 2}
// 2 kafka的生产者
val producer: KafkaProducer[String, String] = new KafkaProducer[String, String](props)
for (i <- 1 to 10) {
// 3 封装的对象
//没有指定分区编号,生成者会将数据轮询写入到Kafka多个分区中(不是写一条就切换)
val record = new ProducerRecord[String, String](topic, "kafka," + i)
/*
如果指定了分区编号3,就会写入到指定的分区中
val record = new ProducerRecord[String, String](topic, 3, null, "hello doit " + i)
*/
/*
如果指定了key,则类似HashPartitioner计算分区编号的方式根据key来计算分区
val record = new ProducerRecord[String, String](topic, "abc", "hello doit " + i)
*/
/*
val partition = i % 3; //根据一个变量动态计算出来的,相对均匀
val record = new ProducerRecord[String, String](topic, partition, null, "hello doit " + i)
*/
/*
val key = UUID.randomUUID().toString //生成UUID作为key,相对均匀的写入到各个分区中
val record = new ProducerRecord[String, String](topic, key, "hello doit " + i)
*/
producer.send(record)
}
println("message send success")
//producer.flush()
// 释放资源
producer.close()
}
}
----消费者
object ConsumerDemo {
def main(args: Array[String]): Unit = {
val properties = new Properties();
// 连接kafka节点
properties.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")
//指定key序列化方式
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
//指定value序列化方式
properties.setProperty("value.deserializer", classOf[StringDeserializer].getName) // 两种写法都行
/*
----偏移量(offset)
1)影响偏移量的因素 : topic-partition-groupid = 偏移量
2)enable.auto.commit 默认值就是true【5秒钟更新一次】,消费者定期会更新偏移量
3)auto.commit.interval.ms=10000 10秒钟提交一次偏移量,可以自己设置参数
*/
properties.setProperty("enable.auto.commit", "true") // 可以改为false,不让kafka自动维护偏移量
//设置组号ID
properties.setProperty("group.id", "doit2304")
/*
指定消费的offset从哪里开始:auto.offset.reset
earliest:从头开始
latest:从消费者启动之后开始
*/
properties.setProperty("auto.offset.reset", "earliest") //[latest, earliest, none]
//创建KafkaConsumer 设置topic
val consumer = new KafkaConsumer[String, String](properties)
val topics: util.List[String] = util.Arrays.asList("test1")
// 3 订阅主题(可以订阅一个到多个主题)
consumer.subscribe(topics)
while(true) {
//超时时间为5秒(有数据立即读取,没有数据最多等等5秒)
val consumerRecords: ConsumerRecords[String, String] = consumer.poll(Duration.ofSeconds(5))
import scala.collection.JavaConverters._
for(record <- consumerRecords.asScala) {
/*
可以获取消费的数据的各种信息:key,value,topic,partition.offset
val key = record.key()
val value = record.value()
val topic = record.topic()
val partition = record.partition()
val offset = record.offset()
*/
println(record)
}
}
}
}
–消费者手动设置和上传偏移量
object ConsumerCommitOffset {
def main(args: Array[String]): Unit = {
val properties = new Properties();
// 连接kafka节点
properties.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")
//指定key序列化方式
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
//指定value序列化方式
properties.setProperty("value.deserializer", classOf[StringDeserializer].getName) // 两种写法都行
//设置消费者的事务隔离级别 read_committed 只读提交事务的数据
properties.setProperty("isolation.level", "read_committed");
//影响偏移量的因素 : topic-partition-groupid = 偏移量
properties.setProperty("group.id", "doit2306")
properties.setProperty("auto.offset.reset", "earliest") //[latest, earliest, none]
//自动提交偏移量控制不够精准、不灵活 关闭自动提交偏移量
properties.setProperty("enable.auto.commit", "false")
//创建KafkaConsumer
val consumer = new KafkaConsumer[String, String](properties)
val topics: util.List[String] = util.Arrays.asList("test6")
// 3 订阅主题(可以订阅一个到多个主题)
consumer.subscribe(topics)
while(true) {
//超时时间为5秒(有数据立即读取,没有数据最多等等5秒)
val consumerRecords: ConsumerRecords[String, String] = consumer.poll(Duration.ofSeconds(5))
import scala.collection.JavaConverters._
val isEmpty = consumerRecords.isEmpty
val records = consumerRecords.asScala
for(record <- records) {
println(record)
}
//同步提交偏移量,该方法是阻塞的(效率低),偏移量不提交成功,程序不向下运行
//consumer.commitSync()
//异步提交偏移量,方法不是阻塞的(效率高),会开启一个线程来执行提交偏移量任务
//consumer.commitAsync()
//异步提交偏移量,,并且指定提交的偏移量中的数据,比如只提交每次最大的偏移量,提交成功的回调方法
if(!isEmpty) {
val recodesWithMaxOffset: Map[(String, Int), ConsumerRecord[String, String]] = records.groupBy(r => (r.topic(), r.partition())).mapValues(_.toList.maxBy(_.offset()))
val offsets = recodesWithMaxOffset.map(t => {
(new TopicPartition(t._1._1, t._1._2), new OffsetAndMetadata(t._2.offset(), null))
}).asJava
consumer.commitAsync(offsets, new OffsetCommitCallback() {
override def onComplete(offsets: util.Map[TopicPartition, OffsetAndMetadata], exception: Exception): Unit = {
for (of <- offsets.asScala) {
val topicAndPartition = of._1
val topic = topicAndPartition.topic()
val partition = topicAndPartition.partition()
val offset = of._2.offset()
println(s"topic: $topic ,partition: $partition 偏移量: $offset 提交成功")
}
}
})
}
//println("aaaaa")
}
}
}
— 生产者:将数据提交到事物中,提交成功则完成,不成功则将数据回滚
//生产者:将数据提交到事物中,提交成功则完成,不成功则将数据回滚
object TransactionProducerDemo {
def main(args: Array[String]): Unit = {
val properties = new Properties();
// 连接kafka节点
properties.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")
//指定key序列化方式
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
//指定value序列化方式
properties.setProperty("value.serializer", classOf[StringSerializer].getName) // 两种写法都行
//properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transactionId");
//# 或者
properties.put("transactional.id", "transactionId123");
val topic = "test1"
//Kafka的客户端
val producer = new KafkaProducer[String, String](properties)
//初始化事务
producer.initTransactions();
try {
//开启事务
producer.beginTransaction()
val record1 = new ProducerRecord[String, String](topic, "hello doit11111")
val record2 = new ProducerRecord[String, String](topic, "hello doit22222")
val record3 = new ProducerRecord[String, String](topic, "hello doit33333")
producer.send(record1)
producer.send(record2)
val i = 100 / 0
producer.send(record3)
//提交事务
producer.commitTransaction()
} catch {
case e: Exception => {
//回滚事务
//producer.abortTransaction()
println("出现异常了")
}
} finally {
producer.close()
}
}
}
6.SparkStreaming和Kafka进行整合
6.1 KafkaUtils.createDirectStream
但是存在问题,目前没法保证Exactly-Once(处理且处理一次)
因为偏移量是消费者(SparkStreaming以后生成的很多Task)自动定期更新到Kafka中的一个特殊的topic(__consumer_offsets),并且累加的数据是存在checkpoint中,不是存在同一个支持事物的数据库中
解决方法:将累加的数据和偏移量新的保存到一个支持事物的数据库中(MySQL集群、Redis集群、MongoDB集群),并且者两个对数据库的操作要放到一个事物中
如果使用MySQL,必须使用MySQL的InoDB引擎,支持事物的
默认是执行完一条SQL后自动提交事务,如果我们想让多条SQL在一个事物中,那么就要将自动提交事物设置为false
package cn._51doit.spark.streamng.day2
import java.sql.{Connection, DriverManager, PreparedStatement, SQLException}
object MySQLTransactionTest {
def main(args: Array[String]): Unit = {
var conn: Connection = null
var ps1: PreparedStatement = null
var ps2: PreparedStatement = null
try {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=utf-8", "root", "123456")
//开启事物
conn.setAutoCommit(false)
ps1 = conn.prepareStatement("INSERT INTO t_wordcount (word, counts) VALUES (?, ?)")
ps1.setString(1, "jerry")
ps1.setLong(2, 222)
ps1.executeUpdate()
val i = 1 / 0
ps2 = conn.prepareStatement("INSERT INTO t_kafka_offset (app_gid, topic_partition, offset) VALUES (?, ?, ?)")
ps2.setString(1, "test1_g001")
ps2.setString(2, "wc_0")
ps2.setLong(3, 30)
ps2.executeUpdate()
println("2 sql execute")
//提交事物
conn.commit()
} catch {
case e: Exception => {
println("a error happen")
conn.rollback()
}
} finally {
if(ps1 != null) {
ps1.close()
}
if(ps2 != null) {
ps2.close()
}
if(conn != null) {
conn.close()
}
println("finally")
}
}
}
6.1 Kafka直连方式将计算的结果或偏移量都保存在MySQL数据库中
哪个Topic,哪个分区、哪个组
- 如何获取当前的批次RDD的偏移量?
- 直连方式一个kafka的分区对应一个RDD的分区
- 如何获取当前的批次RDD的分区呢?
使用DStream中的一个方法叫forEachRDD:获取当前DStream中的RDD
https://www.cnblogs.com/xifenglou/p/7251112.htmlpng)















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









