






 本文介绍了一种基于GNN的双通路框架,通过空间和时间编码器有效学习时空表示,用于精确预测极端水温和股票交易时间序列。模型结合Transformer自注意力机制和多种嵌入方法,实验对比了不同架构在预测性能上的优劣。
本文介绍了一种基于GNN的双通路框架,通过空间和时间编码器有效学习时空表示,用于精确预测极端水温和股票交易时间序列。模型结合Transformer自注意力机制和多种嵌入方法,实验对比了不同架构在预测性能上的优劣。
目录
摘要
本周阅读了一篇运用GNN进行时间序列预测的论文。论文主要提出了一种分离空间和时间编码器的双通路框架,用于通过有效的时空表示学习准确预测水温,特别是极端的高水温。框架主要使用Transformer的自注意机制构造空间和时间编码器执行任务,同时采用了各种补丁嵌入方法和空间特征位置嵌入方法的组合。此外,本周还运用GAT模型进行了一个时间序列预测的实验。
ABSTRACT
This week, We read a paper on time series prediction using GNNs. The paper proposes a dual-pathway framework that separates spatial and temporal encoders for accurate prediction of water temperature, particularly extreme high water temperature, through effective spatiotemporal representation learning. The framework primarily utilizes Transformer's self-attention mechanism to construct spatial and temporal encoders for the task, along with various combinations of patch embedding methods and spatial feature positional embedding methods. Additionally, this week, an experiment on time series prediction was conducted using the GAT model.
1 论文信息
1.1 论文标题
Two-pathway spatiotemporal representation learning for extreme water temperature prediction
1.2 论文摘要
准确预测极端水温对于了解海洋环境的变化以及减少全球变暖导致的海洋灾害至关重要。在本研究中,提出了一个分离空间和时间编码器的双通路框架,用于通过有效的时空表示学习准确预测水温,特别是极端高水温。基于Transformer的自注意机制构造空间和时间编码器网络执行任务,预测朝鲜半岛周围16个沿海位置未来连续七天的水温时间序列,同时采用了各种组合的补丁嵌入方法和空间特征的位置嵌入。最后还进行了与传统深度卷积和递归网络的比较实验,通过比较和评估这些结果,所提出的双路径框架能够通过更好地捕获来自开放海洋和区域海域的时空相互关系和长期特征关系,改善对极端沿海水温的可预测性,并进一步确定基于自注意力的空间和时间编码器的最佳架构细节。此外,为了检查所提出的模型的可解释性及其与领域知识的一致性,进行了模型可视化并分析了空间和时间注意力图,展示了与未来预测更相关的时空输入序列的权重。
1.3 论文模型
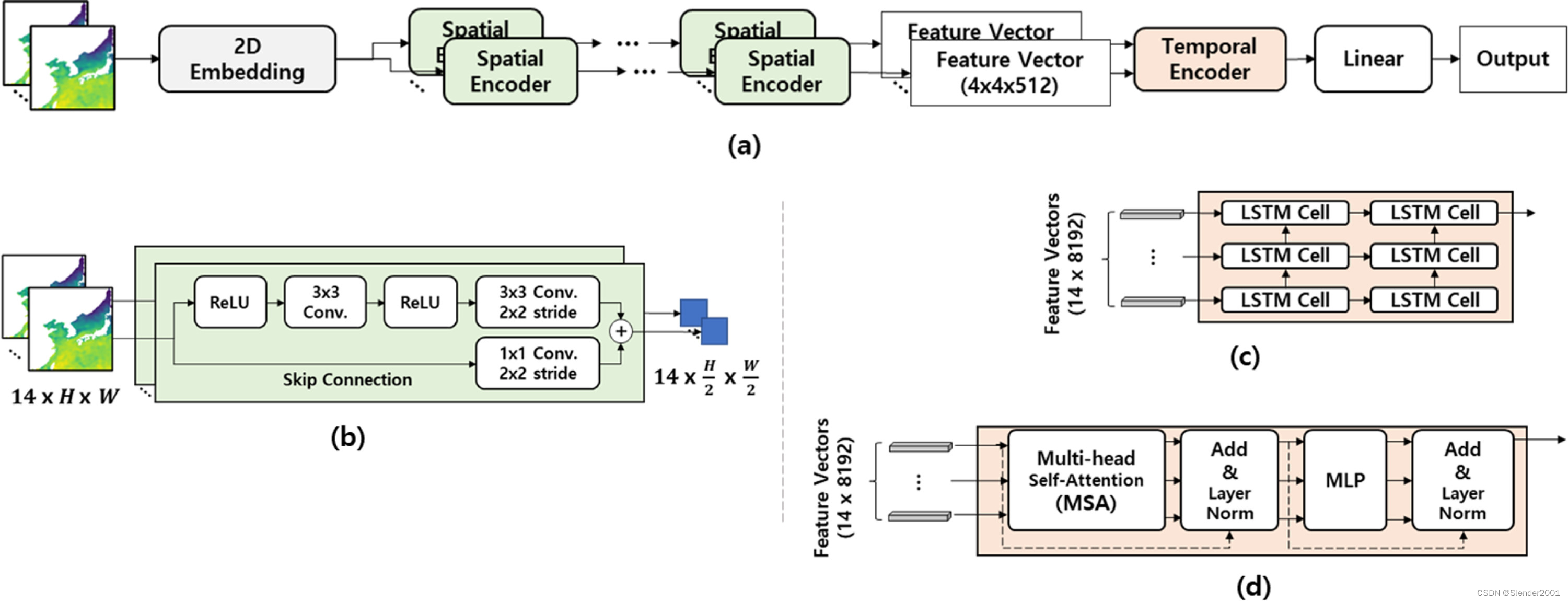
双通路框架主要包括空间编码器(Spatial Encoder)和时间编码器(Temporal Encoder),如Fig.(a)所示。这两个编码器主要用来学习多尺度时空相互关系特征表示,将时空数据的特征表示通过SpatialEncoder和TemporalEncoder分为两个空间组件,维度分别为
和
,以及一个时间组件,维度为
。第一条路径中,SpatialEncoder捕获给定输入数据的一个连续片段的空间依赖关系。第二条路径中,TemporalEncoder捕获从SpatialEncoder中以时间顺序提供的连续序列空间特征向量之间的时间依赖关系,与时间特征融合。Fig.1(a)中的二维嵌入包含一个将输入数据映射到特征空间的操作,然后将其输出结果送到连续的空间编码器中。对于CNN,它通过
卷积核卷积操作执行,而对于基于自注意力的网络,则是将每个数据分成补丁。嵌入特征被馈送到SpatialEncoder,并构建为Feature Vector以学习时空特征表示。Feature Vector的大小是固定的,并且为了比较各种实验模型组合的性能,确定了实现它所需的编码器数量。通过空间编码器压缩的Feature Vector以时间顺序被接收到TemporalEncoder中,以构建集成的时空特征向量。
输入的网格化时空数据序列记作,
。其中,
、
和
分别代表网格化时空数据的高度、宽度和多个连续时间序列。
被映射为来自时间、高度和宽度维度的补丁嵌入的一系列标记
、
。如果使用位置嵌入,
将被重塑为
。
是标记维度,
表示非重叠图像补丁。从每个数据序列中提取
个非重叠图像补丁,然后将具有位置嵌入的总共
个标记传到Transformer的核心共同块SpatialEncoder中的多头自注意力(MSA)。从SpatialEncoder中获得的输出
是从输入的网格化时空数据序列
中获得的新表示,具有
的隐藏特征向量。SpatialEncoder的输出
被馈送到TemporalEncoder的输入中,以学习空间特征的时间依赖性。基于TemporalEncoder的Transformer架构,通过缩放点积注意力计算输入
的单个自注意力,如Eq.(1)所述。缩放点积注意力的输入包括维度为
的queries(
)和keys(
),以及维度为
的值(
)。计算queries与所有keys的点积,每个除以
,并应用softmax函数来获得值的权重。与具有
维keys、queries和值的单个注意力函数相比,通过MSA,将queries、keys和值线性投影
次,分别到
、
和
维度,然后在这些投影版本的queries、keys和值上并行执行注意力函数,产生
维输出值,更利于结果。这些输出被串联并再次投影,得到最终值。多头注意力使模型能够同时关注不同位置的不同表示子空间的信息。使用单个注意力头,平均会抑制这一特性。通过MSA模块,表示具有时间特征的512维向量,这些向量被转换为连续时空序列的16个目标。
(1)
(2)
其中是key向量和query向量的维度,
。
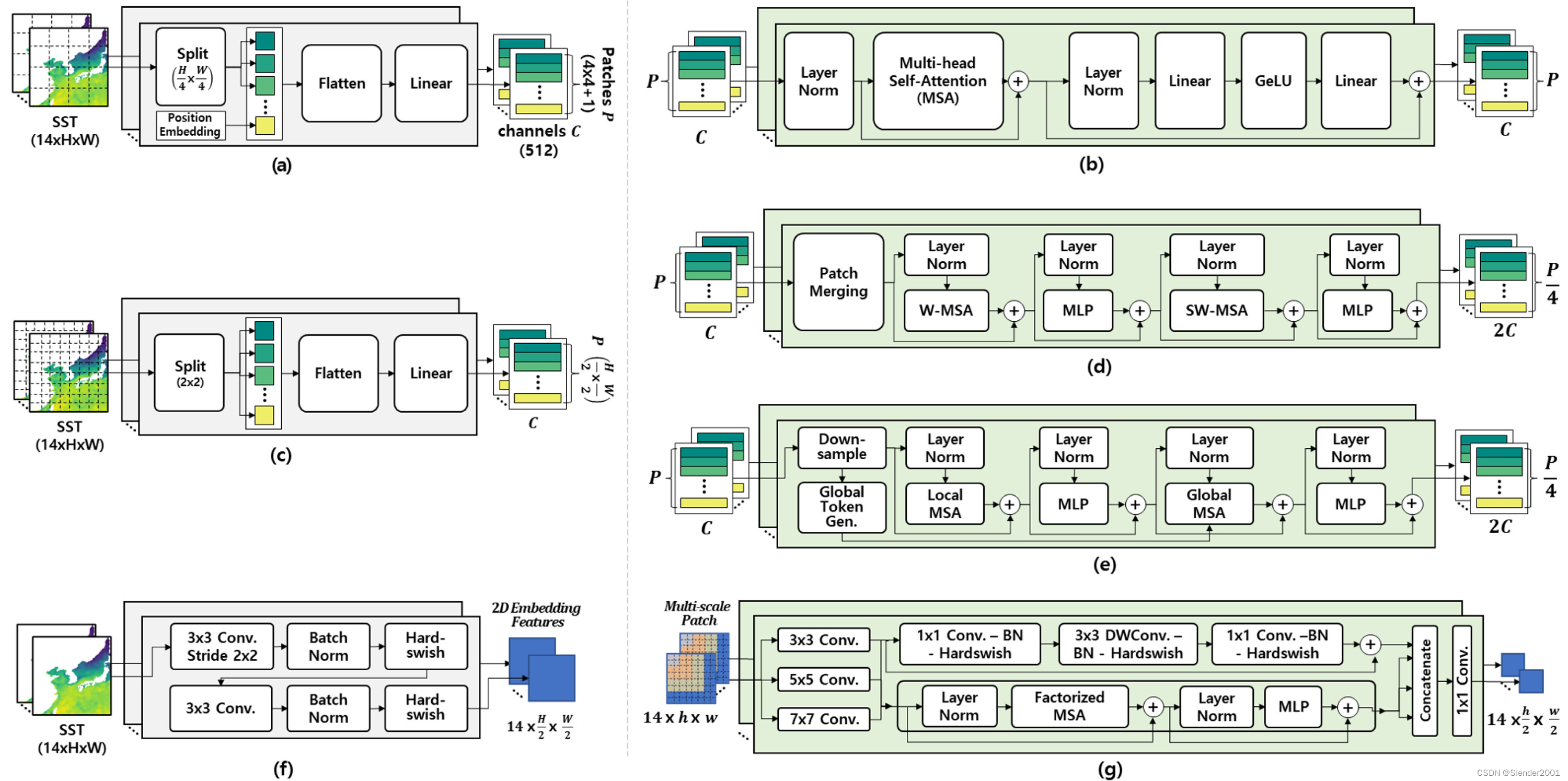
SpatialEncoder应用了ViT(Fig.2(a)和(b))和ViT变体Swin Transformer(SwinT,Fig.2(c)和(d))、全局上下文ViT(GCViT,Fig.2(c)和(e))和多路径ViT(MPViT)(Fig.2(f)和(g)),还包括基本的2D CNN(Fig.1(b))。此外,还将LSTM(Fig.1(c))和基于多头自注意力的 Transformer(MAT,Fig.1(d))作为TemporalEncoder应用,通过不同方式的SpatialEncoder和TemporalEncoder的组合来检验多尺度自注意力时空特征表示的性能,如Table.1所述。同时还研究了10种单独应用SpatialEncoder和TemporalEncoder的实验组合。如Fig.2所示,ViT和ViT 变体SwinT、GCViT 和MPViT具有共同的基于多头自注意力的Transformer架构。然而,位置和补丁嵌入方法存在差异,如Fig2(a)、(c)和(f)所示。此外,可以根据投影注意力的方法以及是否将其视为分层结构进行分类,如Table2所示。


1.3.1 Spatial Encoder(空间编码器)
ViT:一个基于自注意力的空间编码器,通常由两部分组成:补丁构建和Transformer块。如Fig.2(a)所示,对于来自输入的补丁嵌入,2D网格数据的序列被划分为固定大小的补丁,然后进行线性嵌入,并添加一维(1D)位置嵌入以将它们重塑为扁平化的2D补丁序列。1D位置嵌入也按照网格顺序添加到补丁嵌入中。结果的补丁嵌入向量序列被输入到SpatialEncoder中,它具有与标准MAT Transformer相同的结构(Fig.2(b))。它由LayerNorm(LN)、MSA和MLP块组成。在每个MLP块之前和之后分别应用了LN和残差连接。MLP包含用于非线性的高斯误差线性单元(GeLU)。MSA是自注意力的扩展,可以并行执行个自注意力操作并投影它们的串联输出。
SwinT:为了学习更高分辨率的空间特征,SwinT通过逐渐合并深层中相邻的补丁来构建分层特征图,从较小的补丁开始。分层表示是在一种偏移的窗口方案中计算的,它通过将自注意力计算限制在非重叠的局部窗口中来提高效率,同时允许跨窗口连接。对于补丁嵌入(Fig.2(c)),它首先将输入的网格数据划分为非重叠的补丁。然后在这些补丁标记上应用具有修改后自注意力(即SwinT块)的Transformer块,配置如Fig.2(d)所示。SwinT块通过依次连接用于窗口内自注意力操作的Window Multi-head Self-Attention (W-MSA)和用于W-MSA的窗口之间补丁的自注意力操作的Shifted Window Multi-head Self-Attention (SW-MSA),然后在两个MLP层之间插入GeLU来配置。自注意力是在本地窗口内计算的,这些窗口被排列成以非重叠方式均匀划分图像。在每个MSA模块和每个MLP块之前都应用了LN层和残差连接,并在每个模块之后应用了残差连接。Transformer块保持了补丁的数量(),并且与线性嵌入一起被划分为第1个Transformer层。为了创建分层表示,随着网络的加深,补丁合并层会减少补丁(标记)的数量。Transformer层共同创建具有相同分辨率的特征图的分层表示。
1.3.2 Temporal Encoder(时间编码器)
TemporalEncoder使用了两种模型:一种是LSTM,它是一种RNN的变种,另一种是基于自注意力的TE,用于通过SpatialEncoder(Fig.2(c)和(d))捕捉压缩的空间特征向量连续序列之间的时间依赖关系。LSTM接收压缩了空间信息的特征向量作为输入,并将其馈送到LSTM单元中以编码时间信息。TemporalEncoder接收压缩了空间信息的特征向量作为输入,并使用自注意力编码时间信息。与此同时,MLP由Linear-GeLU-Linear组成。一系列由先前的SpatialEncoder层压缩的空间特征向量被顺序地馈送到TemporalEncoder。然后通过双通道方法将空间和时间特征分别融合为输出特征图,用于空间-时间特征表示学习。
2 相关代码
实验:PyG搭建图神经网络实现多变量输入多变量输出时间序列预测
参考代码:PyG搭建图神经网络实现多变量输入多变量输出时间序列预测_利用pyg库实现时间序列预测-CSDN博客
step1:首先需要构造图结构,在将多元时间序列数据转化成一个图结构数据之前,需要确定各个节点的空间关系(Node Embedding,一个变量为一个节点)。一个很自然的想法就是计算不同的变量序列间的相关系数,然后使用一个阈值进行判断,如果两个节点(变量)它们的序列间的相关系数大于这个阈值,那么两个变量节点间就存在边。
# num_nodes:节点(变量)数量; data:节点特征数据,data的维度为(x, num_nodes)
def create_graph(num_nodes, data):
# 将data(feature, num_nodes)序列转换成特征矩阵features(num_nodes, feature)
features = torch.transpose(torch.tensor(data), 0, 1)
# 创建一个空的邻接矩阵,用于存储图中的边
edge_index = [[], []]
# 遍历所有节点
for i in range(num_nodes):
# 遍历当前节点之后的所有节点,以避免重复添加边
for j in range(i + 1, num_nodes):
# 从输入的data数据中获取两个节点的特征向量
x, y = data[:, i], data[:, j]
# 计算两个节点之间的相关性
corr = calc_corr(x, y)
# 如果两个节点之间的相关性大于等于0.4,则将它们之间添加一条边
if corr >= 0.4:
edge_index[0].append(i)
edge_index[1].append(j)
# 将邻接矩阵转换为PyTorch的长整型张量
edge_index = torch.LongTensor(edge_index)
# 创建图对象
graph = Data(x=features, edge_index=edge_index)
# 将有向图转换为无向图,以确保每一条有向边都有一个相对应的反向边
graph.edge_index = to_undirected(graph.edge_index, num_nodes=num_nodes)
return graph本次实验的数据集采用伊斯坦布尔股票交易数据集:ISTANBUL STOCK EXCHANGE - UCI Machine Learning Repository
最终构建出的图结构为:
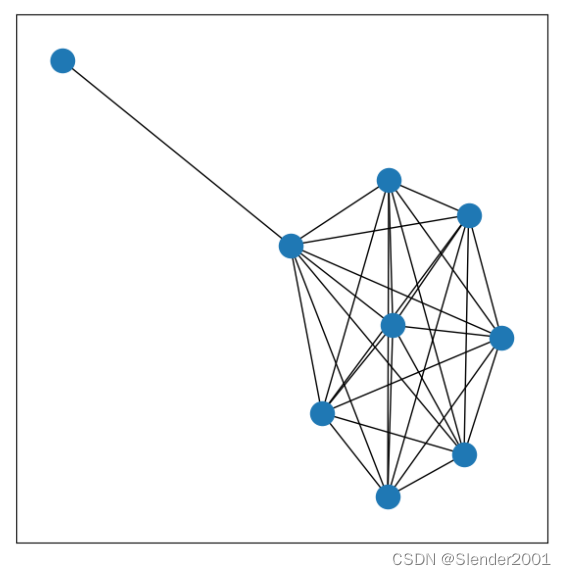
step2:在接下来的训练、验证以及测试过程中保持图的整体结构不变。也就是使用静态图,即图中的关系是通过训练集中的数据确定的。如果想要实现动态图,一个很自然的想法是在构造数据集时,每次都利用一个大小为(num_nodes,seq_len)的矩阵计算出图中的各个参数。这样操作后每一个样本都对应一个图,图中的节点数为num_nodes,节点的初始特征都为长度为seq_len的向量,图中的边通过num_nodes个长度为seq_len的向量间的相关系数来确定。
构造数据集:
def nn_seq(num_nodes, seq_len, B, pred_step_size, data):
# 将数据集划分为训练集(60%)、验证集(20%)和测试集(20%)
train = data[:int(len(data) * 0.6)]
# print(train)
val = data[int(len(data) * 0.6):int(len(data) * 0.8)]
# print(val)
test = data[int(len(data) * 0.8):len(data)]
# print(test)
# 归一化
scaler = MinMaxScaler()
train_normalized = scaler.fit_transform(data[:int(len(data) * 0.8)].values)
# print(train_normalized)
val_normalized = scaler.transform(val.values)
# print(val_normalized)
test_normalized = scaler.transform(test.values)
# print(test_normalized)
# 创建训练集(包含测试集)图
graph = create_graph(num_nodes, data[:int(len(data) * 0.8)].values)
# 数据集处理(生成样本和标签)
# step_size:每一步的步长;shuffle:是否打乱数据
def process(dataset, batch_size, step_size, shuffle):
# 将数据集由DataFrame转化为列表
dataset = dataset.tolist()
# print(len(dataset), len(dataset[0]))
# 创建样本序列
seq = []
# 遍历训练数据集,直到最后一个滑动窗口和预测步长前
for i in tqdm(range(0, len(dataset) - seq_len - pred_step_size, step_size)):
# 创建训练序列
train_seq = []
# 遍历每一个滑动窗口
for j in range(i, i + seq_len):
# 获取一个滑动窗口的样本
x = []
for c in range(len(dataset[0])):
x.append(dataset[j][c])
train_seq.append(x)
# print(x)
# 获取一个滑动窗口的标签
train_labels = []
for j in range(len(dataset[0])):
train_label = []
for k in range(i + seq_len, i + seq_len + pred_step_size):
train_label.append(dataset[k][j])
train_labels.append(train_label)
# 得到每一个滑动窗口的训练样本与对应的标签,转化为tensor
train_seq = torch.FloatTensor(train_seq)
train_labels = torch.FloatTensor(train_labels)
# print(train_seq.shape, train_labels.shape)
seq.append((train_seq, train_labels))
seq = MyDataset(seq)
seq = DataLoader(dataset=seq, batch_size=batch_size, shuffle=shuffle, num_workers=0, drop_last=False)
return seq
# 得到每个数据集的DataLoader
Dtr = process(train_normalized, B, step_size=1, shuffle=True)
Val = process(val_normalized, B, step_size=1, shuffle=True)
Dte = process(test_normalized, B, step_size=pred_step_size, shuffle=False)
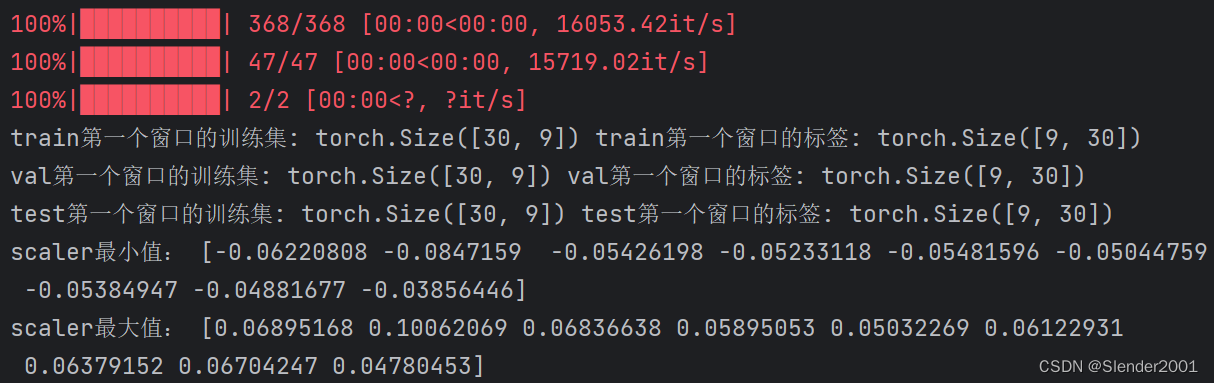
return graph, Dtr, Val, Dte, scaler运行后得到训练集的图结构,并将其数据与邻接矩阵加入后续的模型训练:


函数最后返回训练集,验证集和测试集的DataLoader(Dtr,Val,Dte)以及得到的归一化参数(scaler),加入后续模型的训练(注意:本次实验进行的是多步预测,预测下一个月的股票交易数据):
step3:定义预测模型。这里使用GAT(图注意力网络),也可以换成GCN或GraphSAGE等其他的模型。
class GAT(nn.Module):
def __init__(self, in_features, h_features, out_features):
super(GAT, self).__init__()
self.conv1 = GATConv(in_features, h_features, heads=4, concat=False)
self.conv2 = GATConv(h_features, out_features, heads=4, concat=False)
def forward(self, x, edge_index):
x = F.elu(self.conv1(x, edge_index))
x = self.conv2(x, edge_index)
return x















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









