






目录
摘要
本周主要学习了语义分割的基本概念及其在计算机视觉领域中的应用。了解了语义分割的几种经典网络,如全卷积网络(FCN)、DeepLabV3和LR-ASPP等。深入理解了这些网络的结构和工作原理,特别是FCN网络,它通过替换传统CNN的全连接层为卷积层,实现对图像的像素级分类。此外,还知道了语义分割的常用数据集格式、评价指标以及标注工具,如Labelme和EISeg,并详细讨论了转置卷积的机制和其在神经网络中上采样的应用。最后,学习了FCN网络的结构和原理,理解了其在处理任意尺寸输入图像和保留空间信息方面的优势。
ABSTRACT
This week, we primarily studied the basic concepts of semantic segmentation and its applications in the field of computer vision. We explored several classical networks used in semantic segmentation, such as the Fully Convolutional Network (FCN), DeepLabV3, and LR-ASPP. We gained a deep understanding of the structure and working principles of these networks, particularly the FCN, which accomplishes pixel-level classification of images by replacing the fully connected layers of traditional CNNs with convolutional layers. Additionally, we learned about common data set formats, evaluation metrics, and annotation tools used in semantic segmentation, such as Labelme and EISeg. We also discussed in detail the mechanism of transposed convolution and its application in upsampling within neural networks. Lastly, we studied the structure and principles of the FCN network, understanding its advantages in handling input images of arbitrary size and preserving spatial information.
1 语义分割基本概念
语义分割是计算机视觉领域中的一种重要技术,它的目标是将图像分割成多个区域,每个区域表示特定的语义类别。这些类别可以是人、车辆、建筑物等,也可以是更具体的对象,如道路、天空、植被等。语义分割任务是将属于同一类别的像素组合在一起,并为每个像素指定一个类别标签。
语义分割经典网络有全卷积网络(FCN)、DeepLabV3以及LR-ASPP等。全卷积网络(FCN)是语义分割中的一种流行架构,它通过替换CNN中的全连接层为卷积层,使得网络能够输出与输入图像同样大小的特征图,实现像素到像素的分类。DeepLabV3是一个先进的深度学习架构,专门用于图像语义分割任务,由谷歌的研究团队开发。这个模型是DeepLab系列的第三个版本,继承并改进了之前版本的一些核心概念,特别是在处理图像中的多尺度信息和边界细节上具有显著的优势。LR-ASPP通常用在轻量级的卷积神经网络中,如MobileNet或EfficientNet,这些网络本身就是为了减少计算资源的消耗而设计的。在语义分割任务中,输入图像首先通过这种轻量级的基础网络进行特征提取。之后,特征图经过LR-ASPP模块进行进一步处理,模块中包括不同空洞率的空洞卷积和全局平均池化层,以捕获多尺度和全局信息。
1.1 数据集格式
语义分割数据集中对应的标注图像(.png)用PIL的 Image.open() 函数读取时,默认为 P 模式,即一个单通道的图像。在背景处的像素值为0,目标边缘处用的像素值为255(训练时一般会忽略像素值为255的区域),目标区域内根据目标的类别索引信息进行填充,例如人对应的目标索引是15,所以目标区域的像素值用15填充。

单通道的图像数据加上调色板之后的结果就可以表示出不同颜色的像素所代表的类别。

1.2 语义分割评价指标
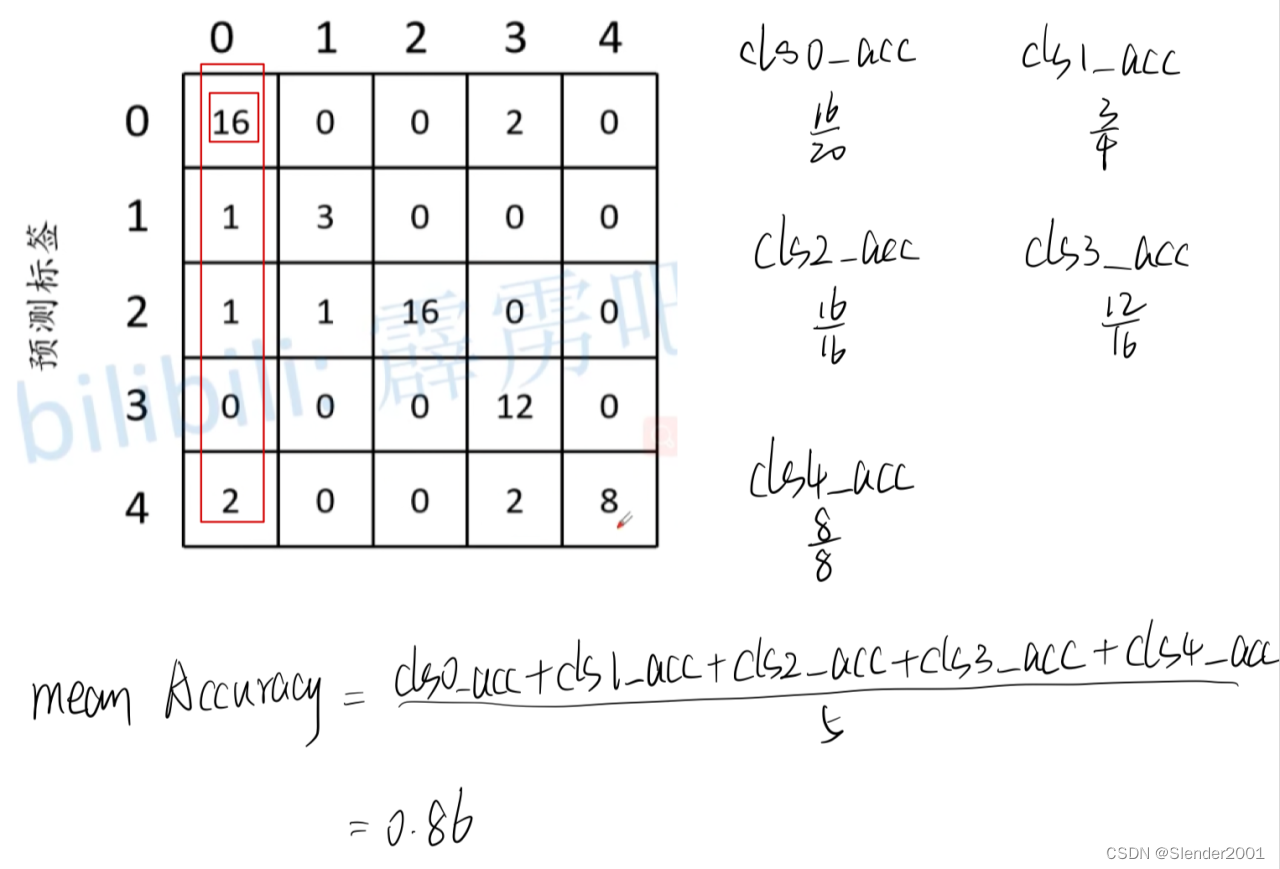
语义分割常用的评价指标有 Pixel Accuracy(Global Acc)、mean Accuracy、mean IoU。

假设已知真实标签和预测标签(忽略边缘):

首先对于真实标签中类别0的部分,将其设置为白色,其余类别设置为灰色。对于预测标签中类别为0的部分,预测正确的设置为绿色,预测错误的设置为红色。最终计算得,当预测标签为0的像素中,真实标签也为0的像素个数为16,真实标签为3的像素个数为2,然后将结果填入表中:
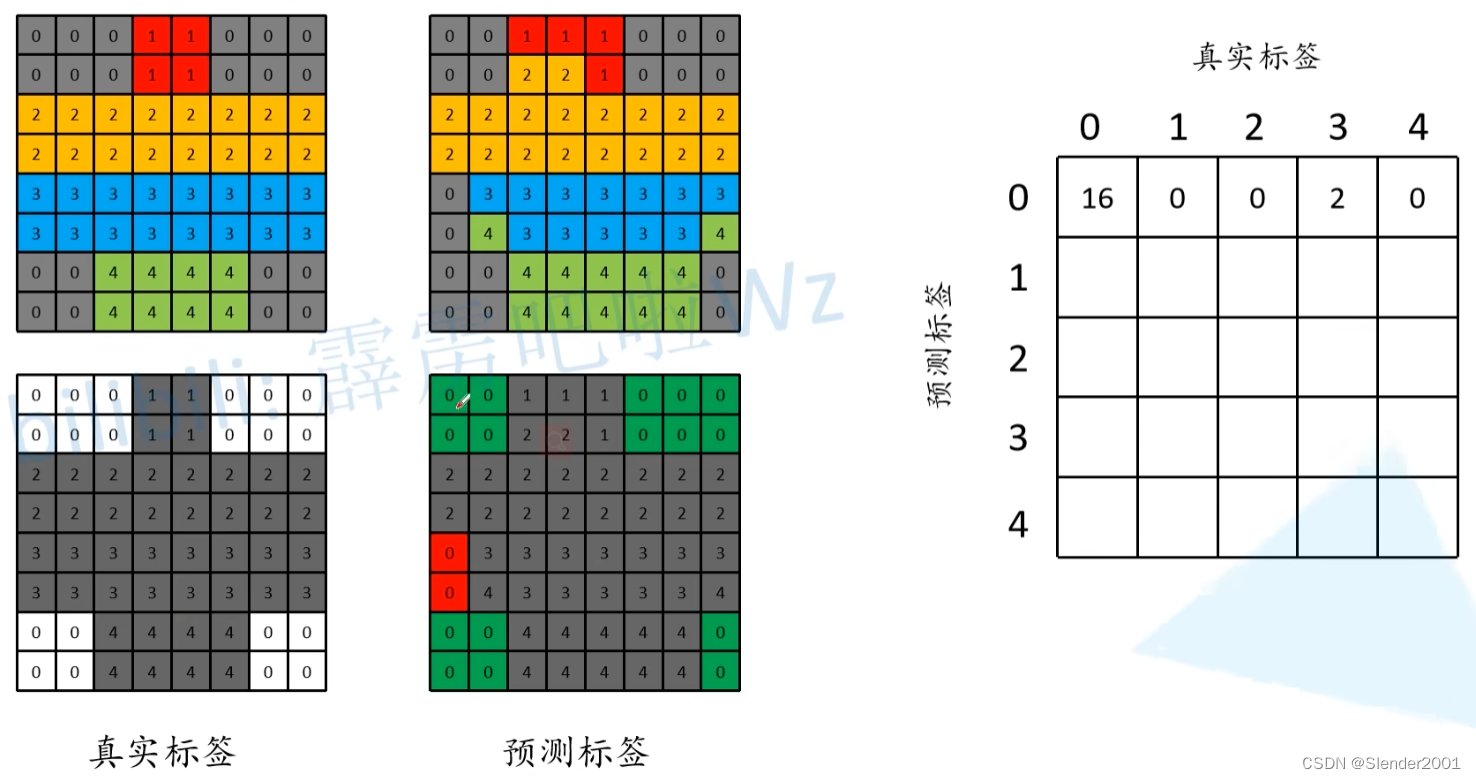
同理,对预测标签中类别1的像素计算可以得到:
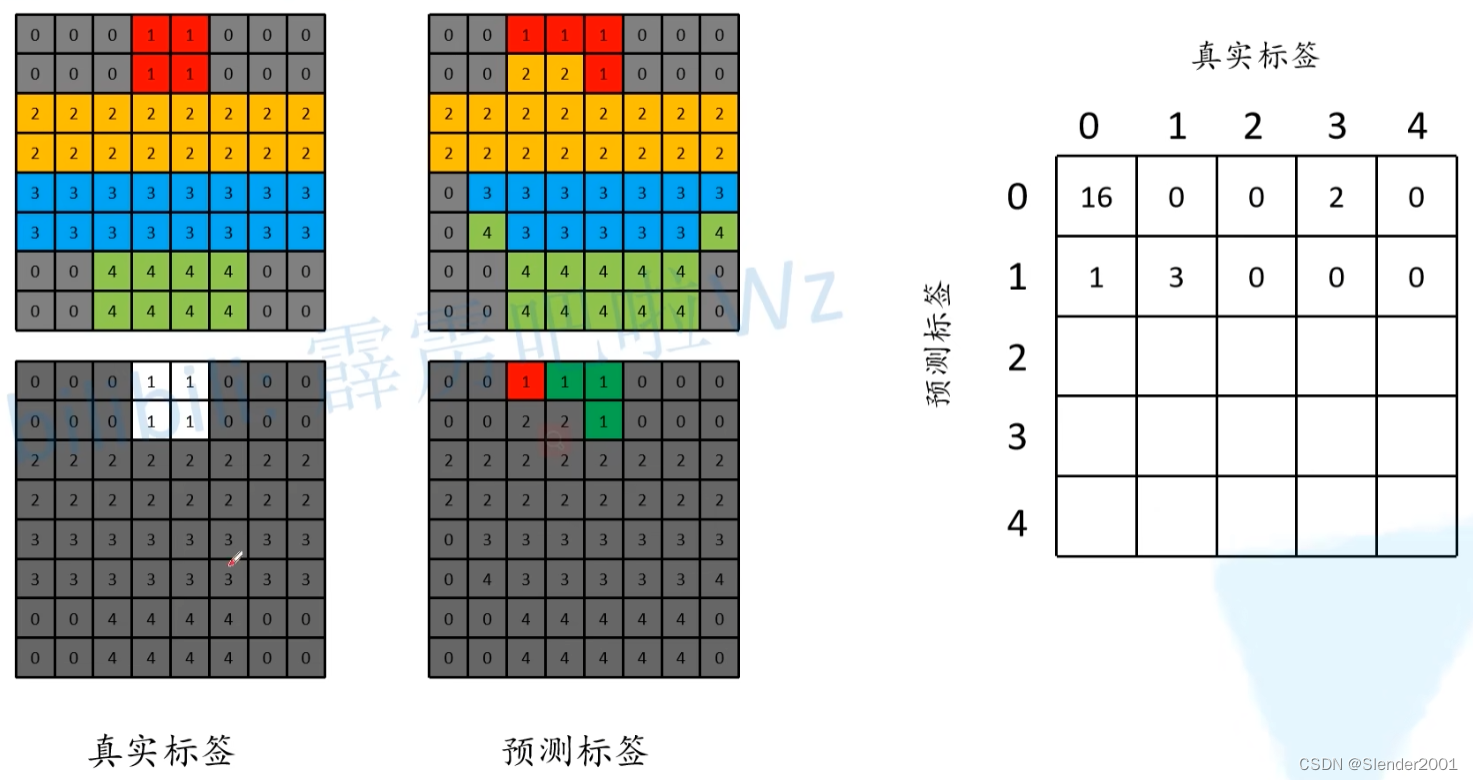
最终得到的表如下:

最终得到的各项评价指标如下:


1.3 语义分割标注工具
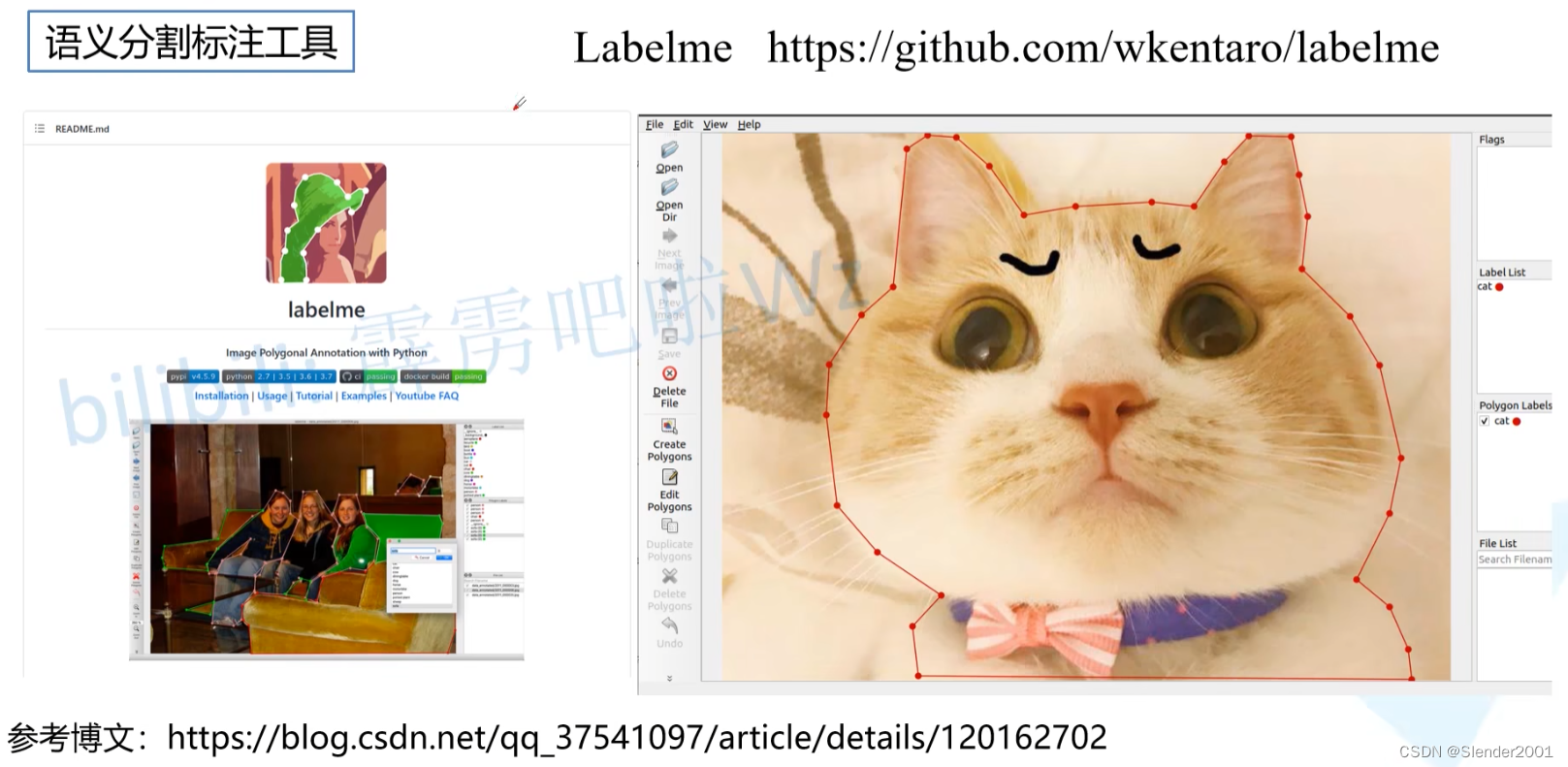
1.Labelme:
使用参考:
Labelme分割标注软件使用_labelme2voc.py-CSDN博客
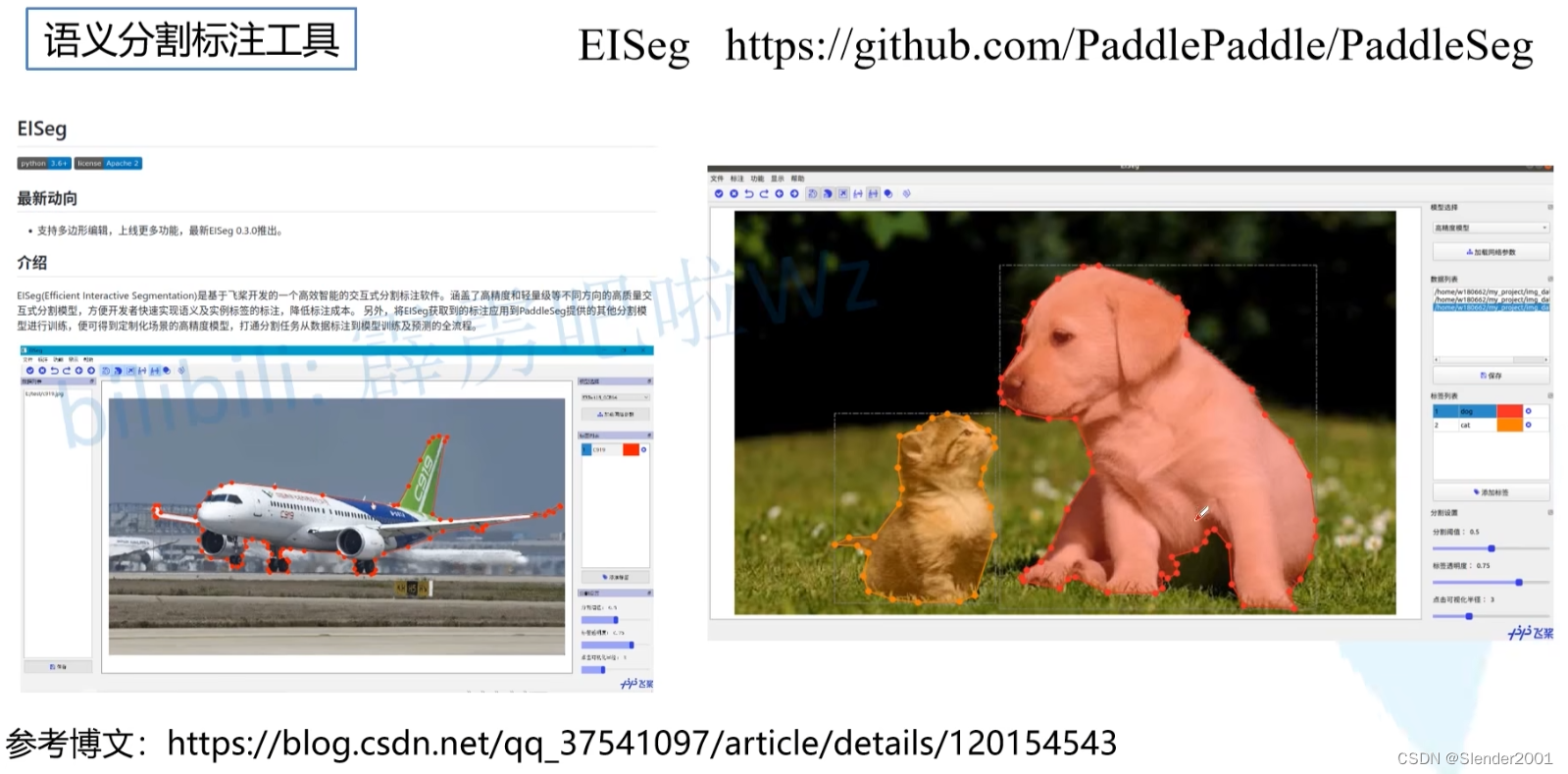
2.EISeg:
下载地址:
使用参考:
2 转置卷积
转置卷积(Transposed Convolution),是一种常用于神经网络中的操作,通常用于上采样过程,即从较小的特征图恢复到较大的特征图尺寸。虽然称为“转置卷积”,但实际上它并不是卷积的真正逆操作,而是一种通过卷积核进行上采样的方法。

转置卷积的运算步骤如下(注意:填充运算的 s 和 p,与卷积运算的 s 和 p 不是一样的):

卷积核上下左右翻转过程与卷积运算过程如下(注意:卷积运算不需要再次填充,故一般 p 设为0,s 设为1):
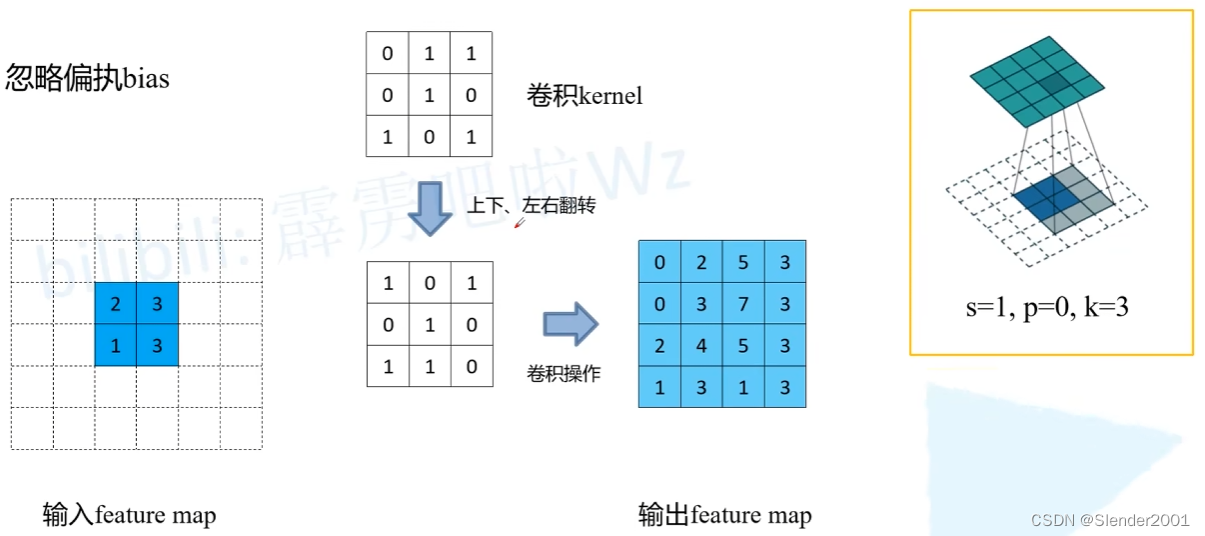
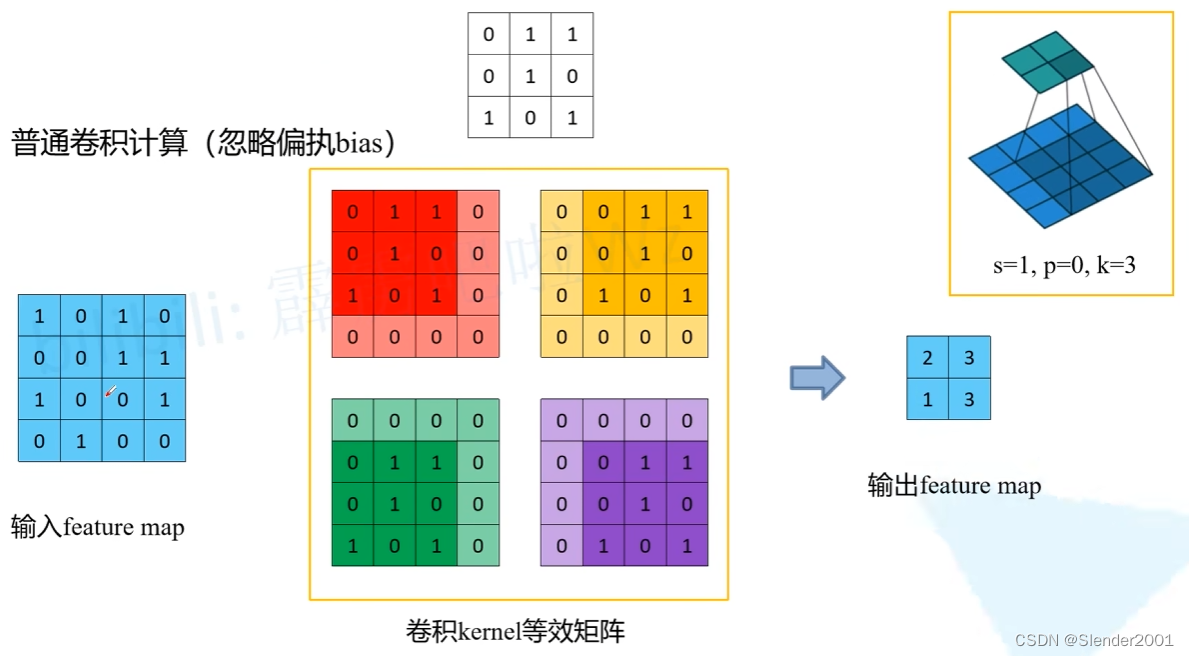
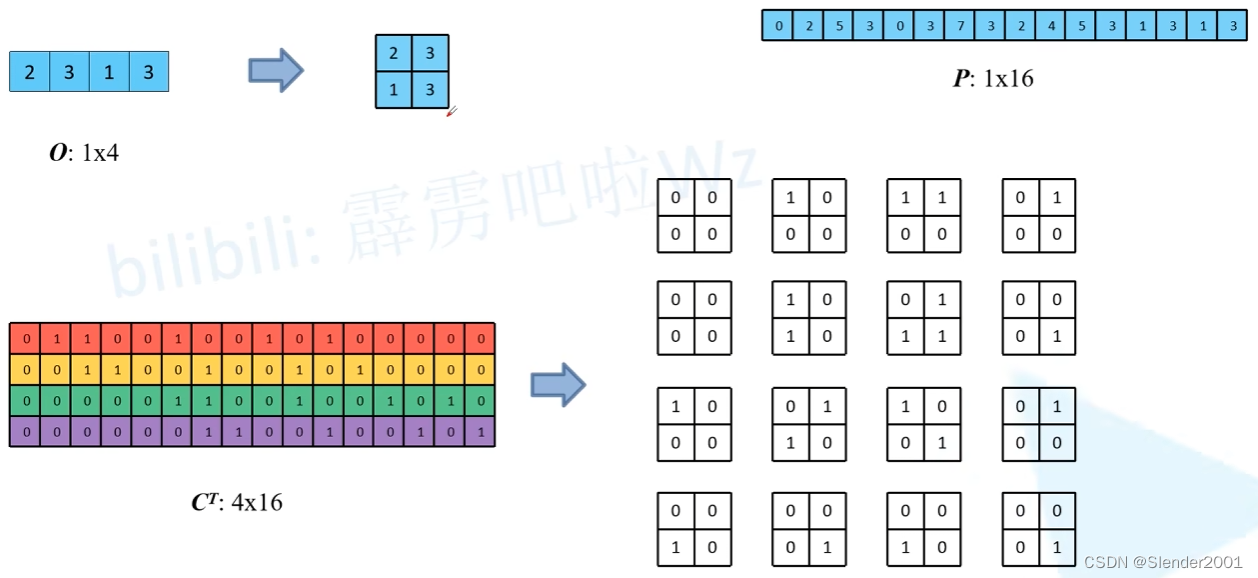
普通卷积过程中,滑动卷积核操作使用 kernel 等效矩阵替代。
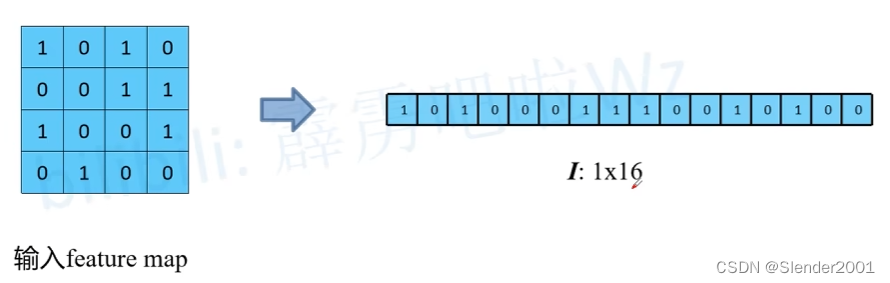
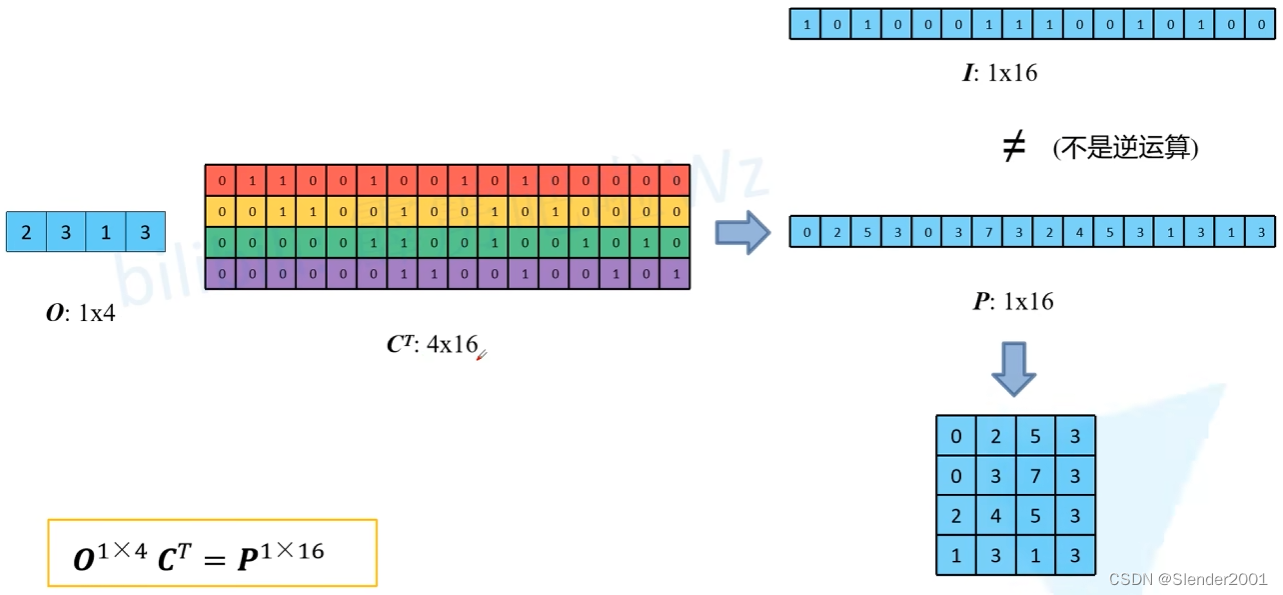
将上图输入 feature map 按行展开,可以得到一个 1 x 16 的矩阵。
将 kernel 等效矩阵也按行展开,可以得到一个 16 x 4 的矩阵。

最终普通卷积计算过程可以用如下矩阵乘法表示:

而转置卷积则是乘上 c 的转置矩阵(注意:此处不是逆运算,不是乘上 c 的逆矩阵):
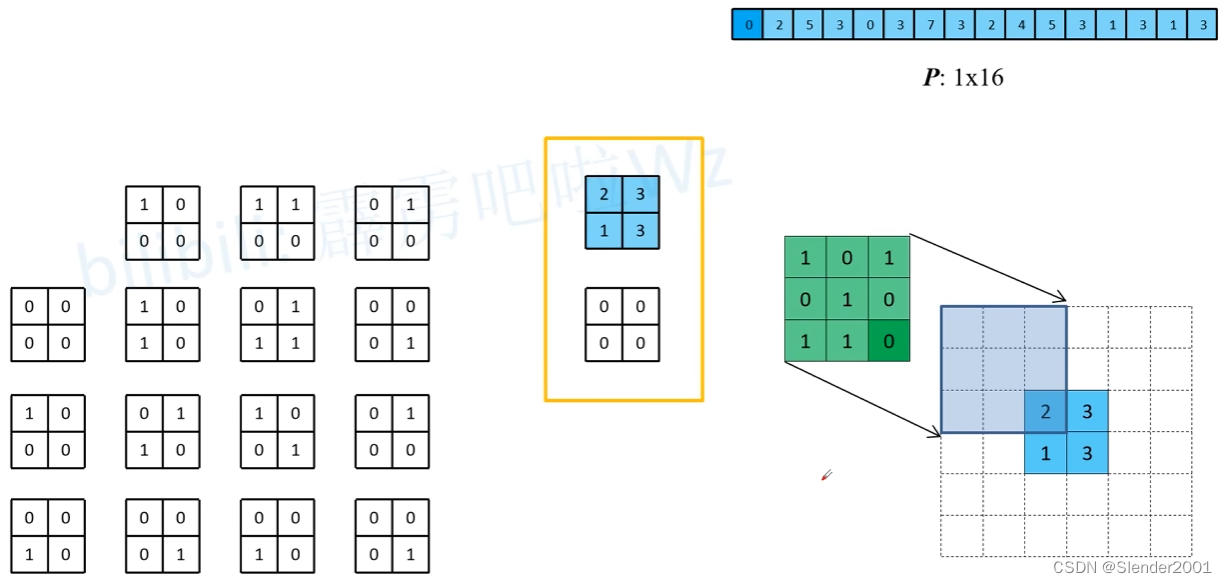
将矩阵反推,就能得到对应的 feature map 和 kernel。
转置卷积反推得到的 feature map 按 s=2,p=0,k=3 进行填充,然后再用之前一个 3 x 3 的 kernel 对其按照 s=1,p=0,k=3 进行卷积,得到的结果和转置卷积的结果一致。
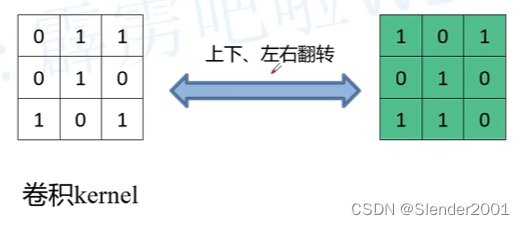
观察可以发现,上图中绿色的这个 kernel 其实就是之前普通卷积中的 kernel 进行上下左右翻转之后的结果。
3 FCN网络结构基本原理
在传统的CNN网络中,在最后的卷积层之后会连接上若干个全连接层,将卷积层产生的特征图(feature map)映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率,如ALexNet网络最后输出一个1000维的向量表示输入图像属于每一类的概率。如下图所示:
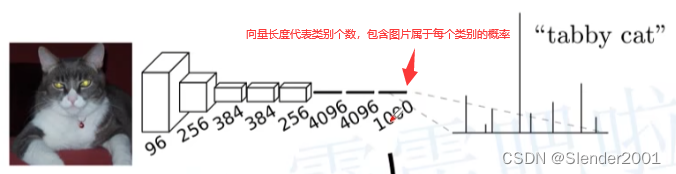
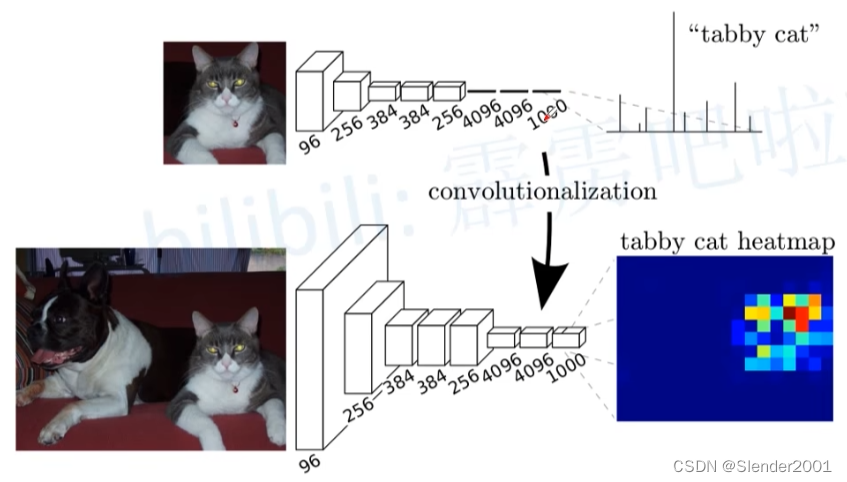
FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题。与上面介绍的经典CNN在卷积层使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图进行像素的分类。简单的说,FCN与CNN的区别在于FCN把CNN最后的全连接层换成卷积层,其输出的是一张已经标记好的图(heat map,不同的颜色代表不同的分类),而不是一个概率值。如下图所示:
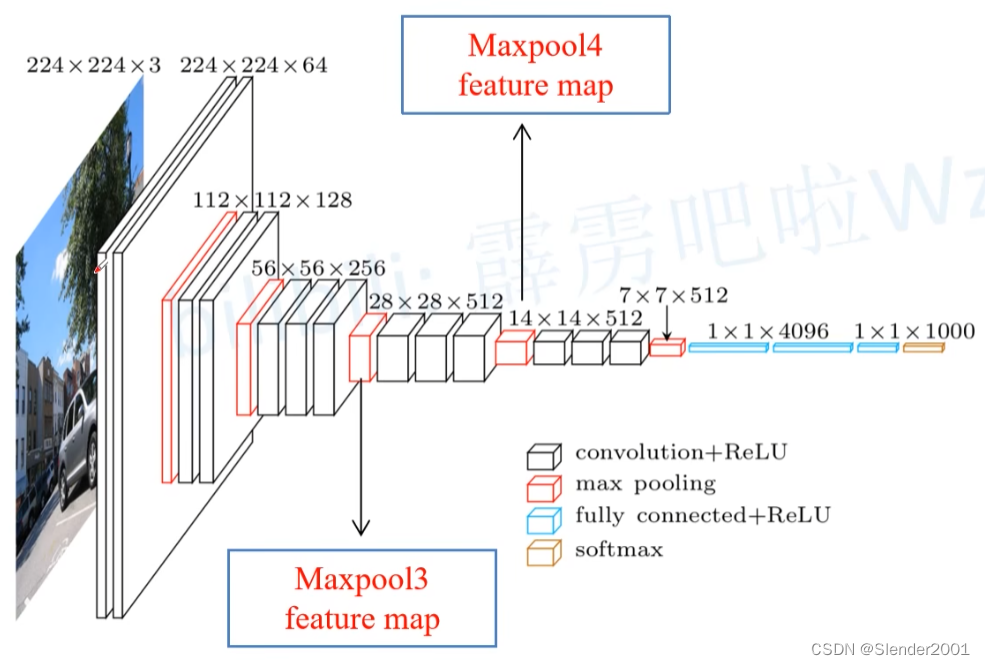
对于任一个卷积层,都存在一个能实现和它一样的前向传播函数的全连接层,任何全连接层都可以被转化为卷积层。例如VGG16中,经过一次卷积、四次池化操作后,特征图的尺寸转换为了 7x7x512,然后通过4096个节点和1000个节点的全连接层将特征转化为输出。
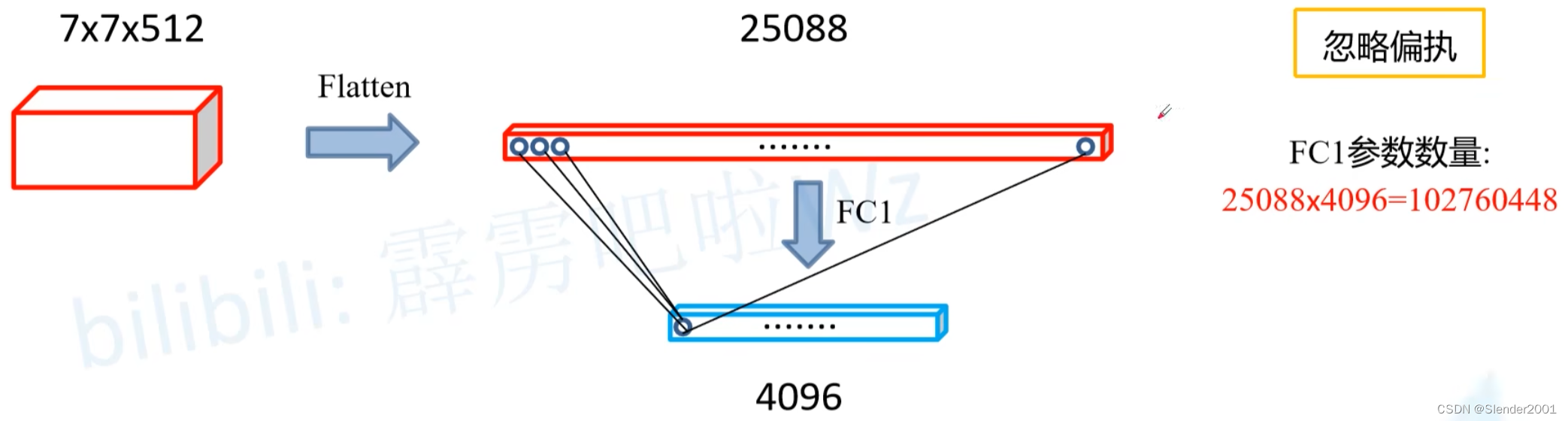
输入FC1的特征是将7x7x512的特征展平为长度为25088的向量,FC1中的每一个节点包含25088个权重参数,通过将权重参数和向量进行加权求和,得到每一个节点的特征。因此FC1的参数个数就是25088x4096=102760448个。
将FC1转化成卷积层的方法如下。通过一个大小与特征大小相同的卷积核(shape:7x7x512),卷积核的个数与全连接层的节点个数一致,同时 P=0,S=1。由此得到的结果也是可以看作长度为25088的向量,而一个卷积核的参数和一个节点的参数是一样的,因此卷积层的参数与全连接层的参数个数也是一致的。

同理,FC2也可以转化为一个卷积层,这样VGG16的所有全连接层就都转化为了卷积层。以上就是FCN网络的基本原理。














 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









