






 本文介绍了书生·浦语大模型实战营的第三课内容,包括使用茴香豆搭建个人RAG智能助手的过程,涉及创建知识问答助手、在InternLMStudio部署、以及进阶作业的两个方向:应用领域知识和优化算法。
本文介绍了书生·浦语大模型实战营的第三课内容,包括使用茴香豆搭建个人RAG智能助手的过程,涉及创建知识问答助手、在InternLMStudio部署、以及进阶作业的两个方向:应用领域知识和优化算法。
书生·浦语大模型实战营——第三课
一、课程相关
-
视频链接
-
视频内容
视频介绍了如何使用茴香豆搭建个人RAG智能助理。首先,介绍了RAG的基础知识和原理架构,然后详细介绍了RAG的工作流程和向量数据库的优化方法。通过实例演示了RAG技术在问答系统中的应用,井解决了大模型处理知识密集任务时的各种桃战。最后,强调了向量数据库的重要性和优化方法,以及不断更新向量数据库以适应新知识的能力。
-
相关文档
二、任务相关
1. 任务一
任务描述
在茴香豆 Web 版中创建自己领域的知识问答助手
操作内容
- 打开茴香豆 Web 版,并创建 茴香豆的技术文档 知识库 及 密码;

-
上传官方技术文档;
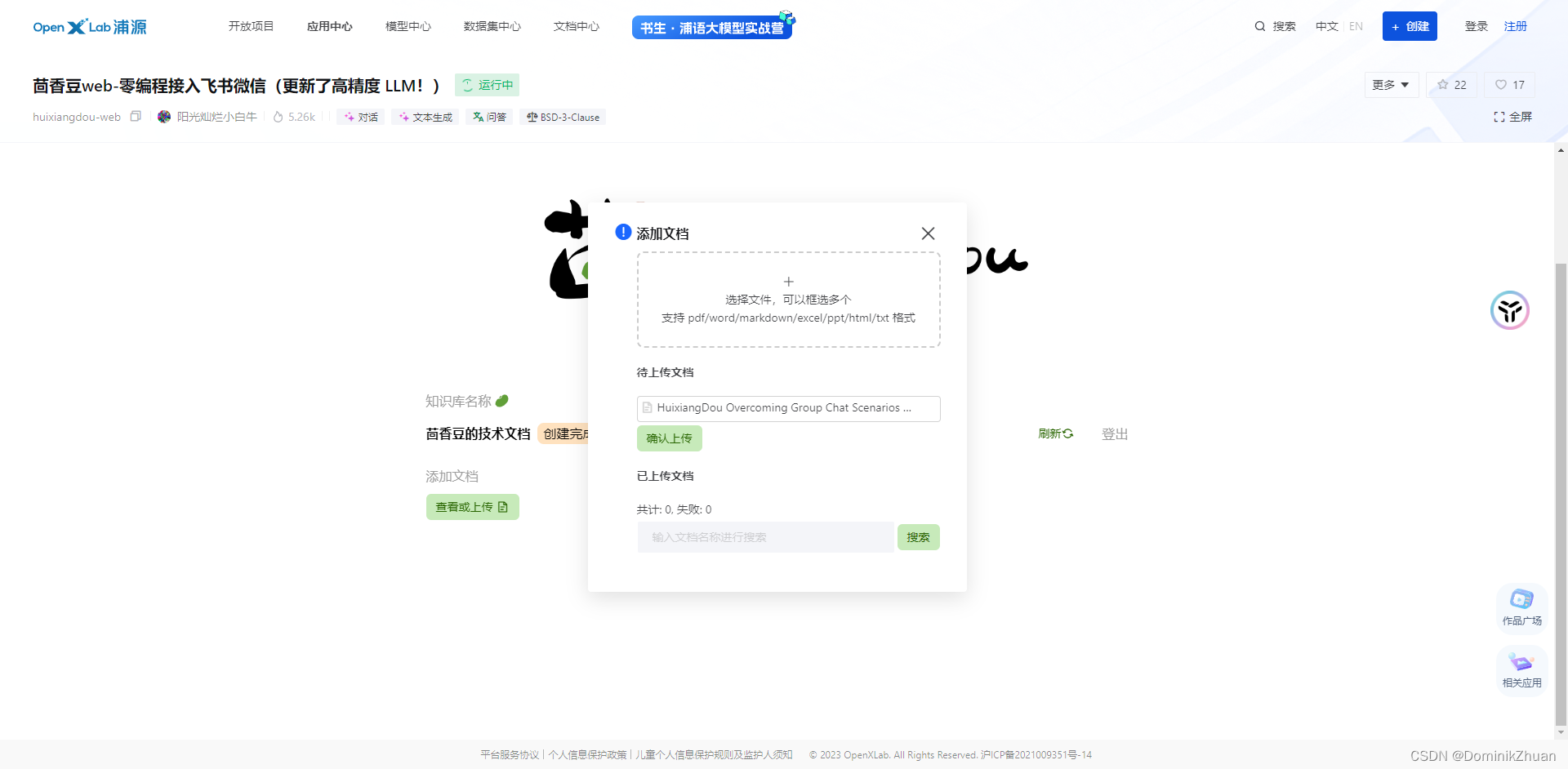
-
刷新并开始对话;
-
直接中文提问,发现并不能得到准确答案:
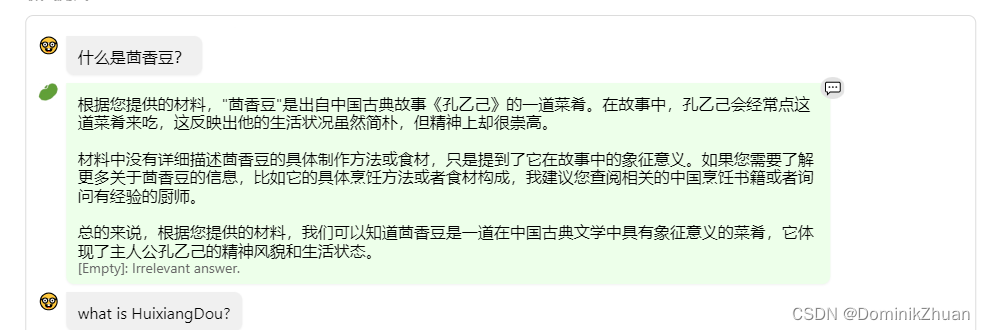
-
英文提问,答案准确,并翻译为中文结果。

-
英语提问,但是结果不准;

-
中文提问,答案为英文,且准确;

-
中文提问,转换为英文,并将回答转换为中文,答案准确;

-
2. 任务二
任务描述
在 InternLM Studio 上部署茴香豆技术助手
操作内容
-
下载conda环境;
studio-conda -o internlm-base -t InternLM2_Huixiangdou -
激活下载的环境,并下载相关依赖与茴香豆项目仓库代码(参照指导手册);
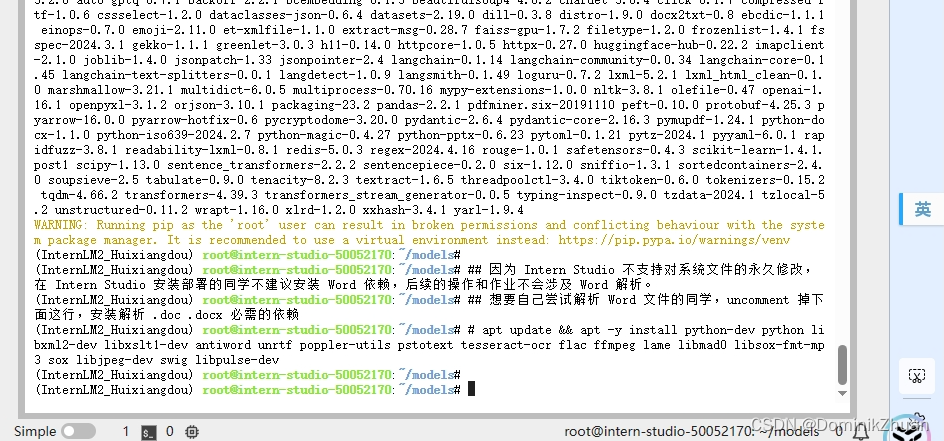
-
修改配置文件中 向量数据库和词嵌入的模型、用于检索的重排序模型和本次选用的大模型 三个模型的路径;
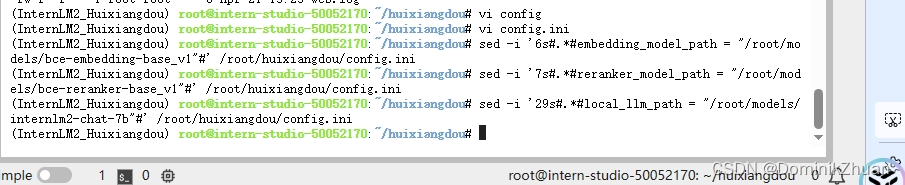
修改好的config.ini文件内容
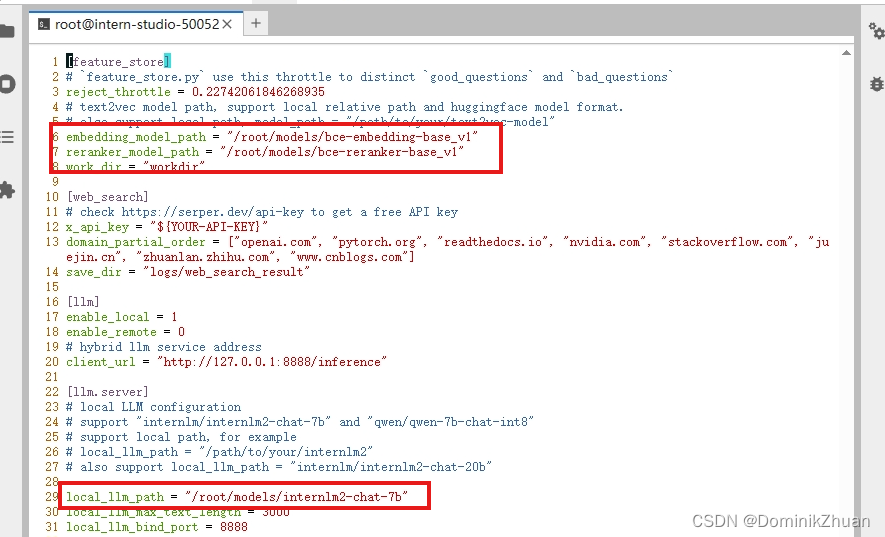
-
创建知识库:下载InternLM的Huixiangdou文档作为知识数据检索的来源,打造一个 Huixiangdou 技术问答助手;
- 注意其中的默认嵌入模型和排序模型使用的是网易的BCE双语模型,可以在config.ini中更改其模型来源;
- 茴香豆有接受和拒答两个向量数据库,用来在检索的过程中更加精确的判断提问的相关性;
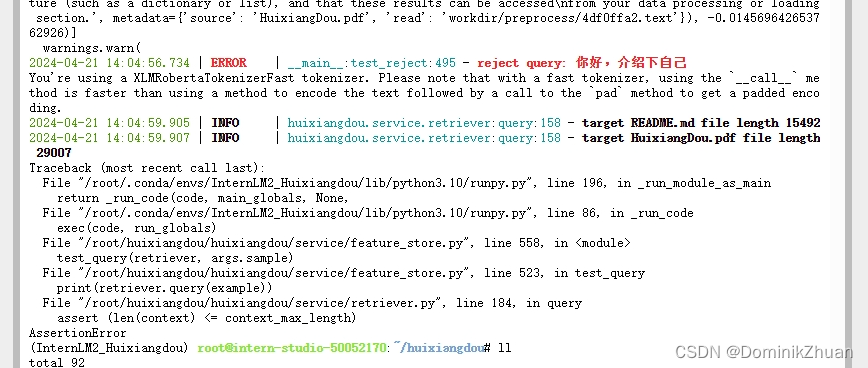
- 构建向量数据库的最后发生了一个ERROR,不知效果是否有影响:
-
运行茴香豆知识助手:
-
# 填入问题 sed -i '74s/.*/ queries = ["huixiangdou 是什么?", "茴香豆怎么部署到微信群", "今天天气怎么样?"]/' /root/huixiangdou/huixiangdou/main.py # 运行茴香豆 cd /root/huixiangdou/ python3 -m huixiangdou.main --standalone -
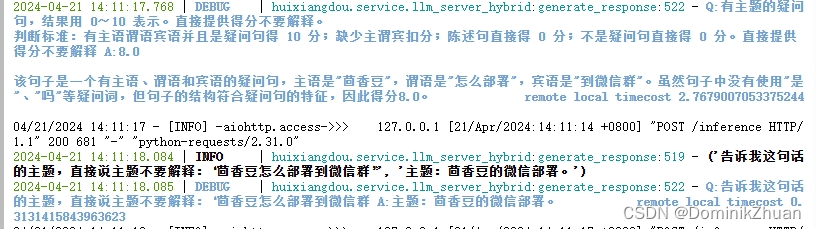
运行之后会更新 langchain-community 依赖,并开始将 queries 中的问题逐一进行请求回复,在请求回复的过程中可以看到,茴香豆的分析流程:
-
首先对该问题打分,并提取其主题;
-
针对明确的主题,去检索相似度高的 材料chunk,并整理成回复;


-
-
3. 进阶作业(后续补充)
A.【应用方向】 结合自己擅长的领域知识(游戏、法律、电子等)、专业背景,搭建个人工作助手或者垂直领域问答助手,参考茴香豆官方文档,部署到下列任一平台。
- 飞书、微信
- 可以使用 茴香豆 Web 版 或 InternLM Studio 云端服务器部署
- 涵盖部署全过程的作业报告和个人助手问答截图
B.【算法方向】尝试修改 good_questions.json、调试 prompt 或应用其他 NLP 技术,如其他 chunk 方法,提高个人工作助手的表现。
- 完成不少于 400 字的笔记 ,记录自己的尝试和调试思路,涵盖全过程和改进效果截图















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









