






LSM Tree
LSM Tree,全称Log Structured Merge Tree
- 其核心思想是利用磁盘顺序写的性能要远高于随机写的特性。
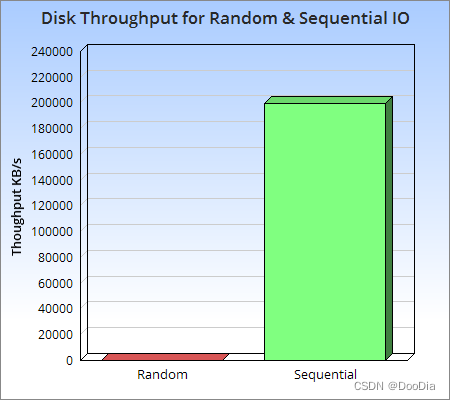
- 牺牲一定读性能,换取高写性能。
- 文件组织方式源自Google的BigTable论文,应用在HBase,LevelDB,RocksDB等强力的 NoSQL 数据库中。
LSM Tree结构
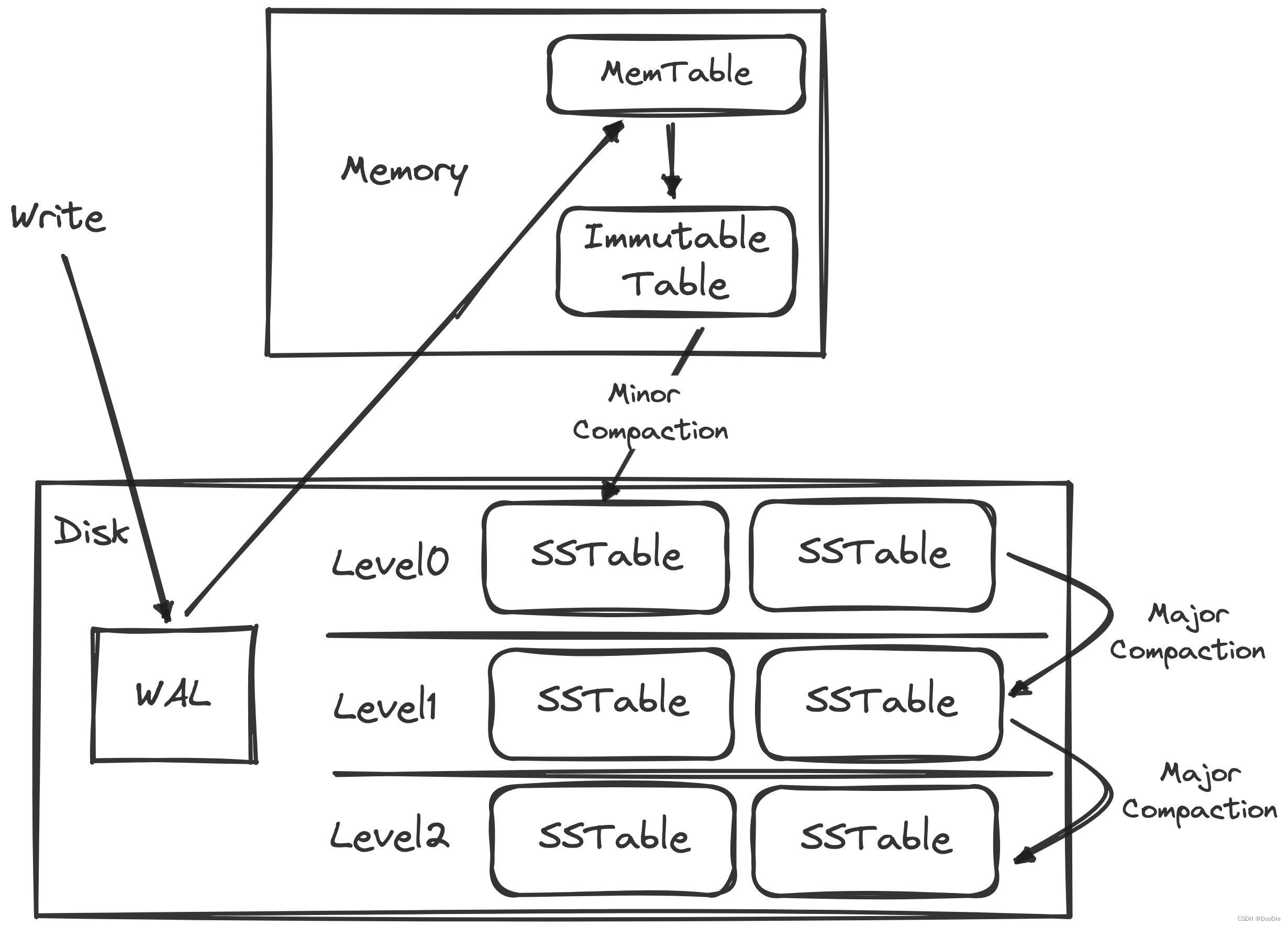
写操作
- 将数据写入
WAL,即Writing Ahead Log, 作为数据备份,实现故障恢复 。 WAL将数据写到内存中的MemTable, 当MemTable达到一定的大小后会冻结为只读状态的Immutable Table,同时为了不堵塞写入,创建一个新的MemTable用于新数据写入。内存中的MemTable和Immutable Table都是红黑树或者跳表实现,从而保证数据有序,同时支持内存中Log(N)的增删改查操作。- 将
Immutable Table持久化到磁盘中的操作叫Minor Compaction,数据在磁盘中的存在形式为SSTable,全称Sorted String Table,来自于BigTable。SSTable中数据根据key的顺序,以键值对的形式连续存储,尾部带有一个索引,同样顺序存储了各key对应在磁盘中的offset。当我们在SSTable中检索时,将索引加载到内存,利用二分搜索可以查找出要访问的key的对应的offset,然后去磁盘中访问。由于Minor Compaction只是将Immutable Table中有序的红黑树或跳表写入SSTable,并不进行合并,所以在Level 0中的不同SSTable可能存在key范围重合或者Key值重复的情况,但后续的层不会。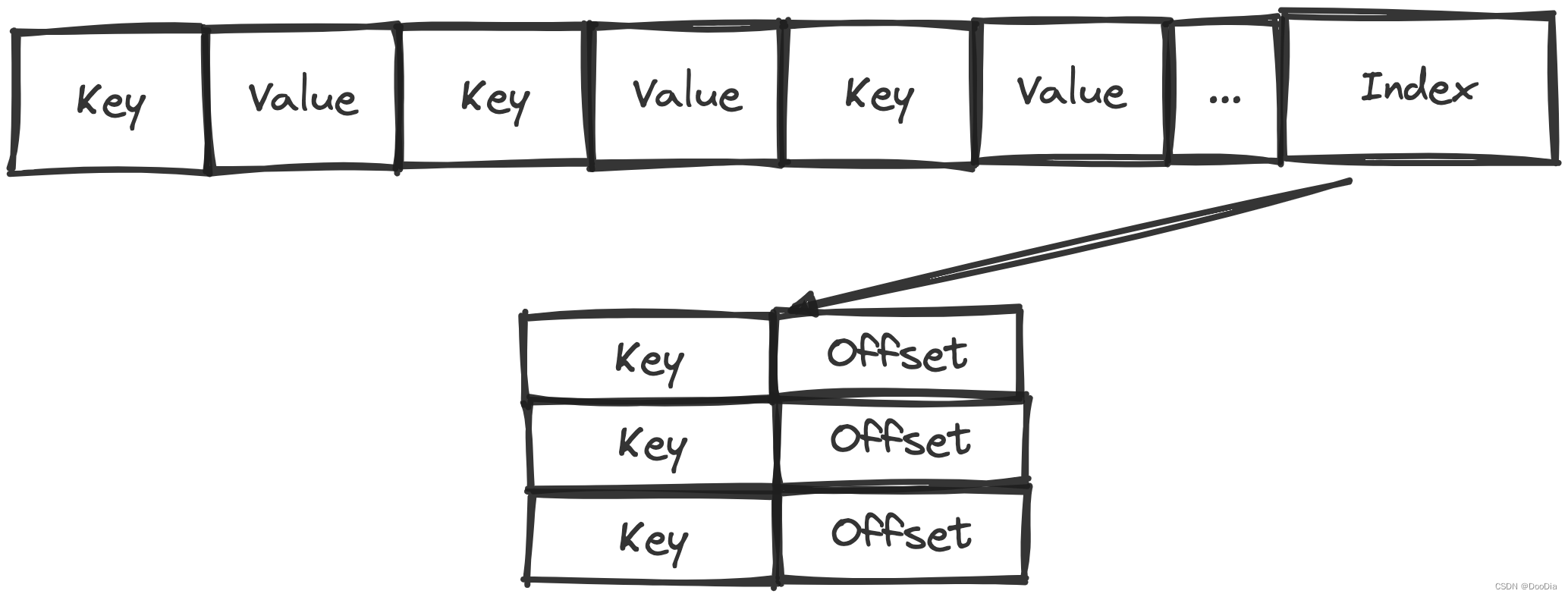
- 当各层的
SSTable达到一定大小,会进行合并操作,这一步骤叫做Major Compaction,将当前层的SSTable与下一层具有相同key的SSTable进行合并,清除被标记删除的数据,合并多版本数据。由于SSTable都是有序的,所以归并排序的时间成本不会太高,但仍然非常消耗CPU和磁盘IO的,如果在业务高峰期,如果发生了Major Compaction,会降低整个系统的吞吐量,因此许多NoSql数据库比如Hbase里面常常会禁用Major Compaction,在凌晨业务低峰期进行。
Compaction的策略包括Leveled (一层一个 SSTable), Tiered (一层一N格 SSTable), Tiered & Leveled。在RocksDB和OceanBase中采用的是1-leveling 的策略,即 L0 层为Tiered策略,其余层级为 Leveled 策略。可以参考官方文档。
读操作
- 在内存中查询,如果查询到就返回。
- 若不在内存中,则在磁盘中自上而下遍历各层扫描。
优化读操作
如果SSTable的分层较多,在最坏的情况下要遍历所有的层,针对这种情况我们需要进行优化。
- 压缩:根据locality将数据分组,每个组分别压缩,当读取数据的时候,我们不需要解压缩整个文件而是解压缩部分 Group 就可以读取。
- 缓存:因为磁盘中的
SSTable除了Compaction时是不会变化的,可以将一次扫描结果进行缓存,供后续查询。 - 布隆过滤器:为
SSTable增加一个Bloom Filter,确定某个Key一定不存在从而实现过滤。
对比B+Tree
-
LSM Tree的优点是支持高吞吐的写操作,复杂度为O(1),而读操作的复杂度是O(N),在使用索引或者缓存优化后的也可以达到O(logN),适用于写多读少的场景。但是为了实现高吞吐的写操作,需要进行频繁的Compaction,消耗CPU和磁盘IO,需要禁用并定期执行Compaction的操作来规避。阿里采用的优化是引入了异构硬件设备FPGA来代替CPU完成Compaction操作。
-
B+tree的优点是支持高效稳定的读操作,O(logN),写操作的效率同样为O(LogN),适用于写少读多或写读平衡。但随着数据不断插入,为了维护B+树结构,节点会不断的分裂和合并。操作磁盘的随机读写概率会变大,故导致性能降低。















 1615
1615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









