







这个课程在狂神中没有教程,所以只能自己学习整理。文章可能会存在个人的误解,恳请大佬指正。
Java自学(九、Java集合框架)
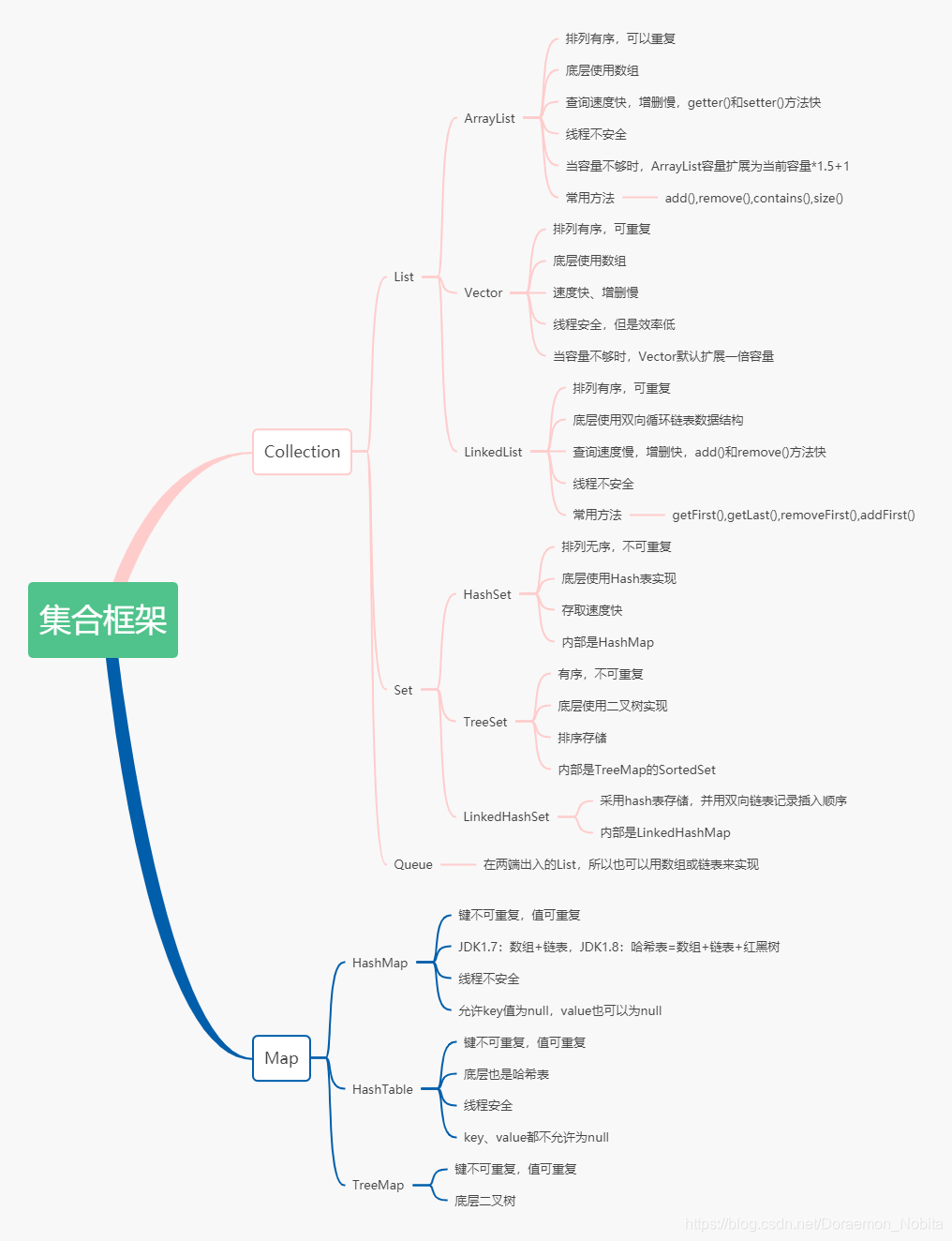
Java集合框架
集合类存放于Java.util包中,主要有三种类型:set(集合)、list(列表,包含Queue)和map(映射)
Collection:collection是集合List、Set、Queue的最基本的接口
Iterator:迭代器,可以通过迭代器遍历集合中的数据
Map:是映射表的基础接口
同步的集合有:Vector(比ArrayList多了个同步)、HashTable(比哈希map多了个线程安全)、ConcurrentHashMap(高效而且线程安全的集合)、Stack(继承于Vector)
Collection
1.List
Java的List是常用的数据类型。List是有序的Collection(Set是无序的),List一共有三个实现类:ArrayList、Vector、LinkedList。
ArrayList(数组)
ArrayList 是最常用的List 实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数
组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要将已经有数
组的数据复制到新的存储空间中。当从ArrayList 的中间位置插入或者删除元素时,需要对数组进
行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
ArrayList扩容是将容量变成1.5倍+1,如果容量不够的时候,遇到添加元素则扩容然后再把元素加进去。
package com.hbq.collectionsuse;
import java.util.ArrayList;
import java.util.Comparator;
public class ArrayListUse {
public static void main(String[] args) {
ArrayList<Integer> al = new ArrayList<>();//数组初始化,注意这里<>里只能是引用数据类型
al.add(11);
al.add(88);
al.add(63);
al.add(-12);
al.add(66);
System.out.println(al);//[11,88,63,-12,66]
System.out.println(al.get(2));//获取下标为2的元素 63
al.set(2, 399);//将下标为2的元素改为399
System.out.println(al);//[11, 88, 399, -12, 66]
al.remove(3);//删除下标为3的元素
System.out.println(al);//[11, 88, 399, 66]
System.out.println(al.size());//看看数组大小 4
al.sort(Comparator.naturalOrder());//按升序排序
System.out.println(al);//[11, 66, 88, 399]
al.sort(Comparator.reverseOrder());//按降序排序
System.out.println(al);//[399, 88, 66, 11]
System.out.println(al.contains(66));//判断-12是否存在于数组中 true
System.out.println(al.contains(999));//判断999是否存在在数组中 false
System.out.println(al.indexOf(66));//返回66元素在数组中的下标 2
System.out.println(al.indexOf(999));//如果数不存在则返回-1
}
}
Vector(用数组实现、线程同步)
Vector 与ArrayList 一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一
个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,
访问它比访问ArrayList 慢。
Vector的使用和ArrayList相似,但是Vector是线程安全的,而且扩容是扩展为当前的两倍容量。所以就简单举几个例子。
package com.hbq.collectionsuse;
import java.util.Comparator;
import java.util.Vector;
public class VectorUse {
public static void main(String[] args) {
Vector<Integer> vr = new Vector<>();
vr.add(414);
vr.add(541);
vr.add(-452);
vr.add(54);
System.out.println(vr);//[414,541,-452,54]
System.out.println(vr.contains(54));//true
System.out.println(vr.remove(3));//54
System.out.println(vr);//[414,541,-452]
System.out.println(vr.size());//3
vr.sort(Comparator.naturalOrder());//升序排序
System.out.println(vr);//[-452,414,541]
}
}
LinkedList(链表)
LinkedList 是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较
慢。另外,他还提供了List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆
栈、队列和双向队列使用。
package com.hbq.collectionsuse;
import java.util.LinkedList;
public class LinkedListUse {
public static void main(String[] args) {
LinkedList<Integer> ll = new LinkedList<>();
ll.add(454);
ll.add(855);
ll.add(482);
System.out.println(ll);//[454,855,482] ,可以看到默认是往后加元素的
ll.addFirst(3254);//往头插入元素
System.out.println(ll);//[3254, 454, 855, 482]
ll.addLast(441);//往结尾插入元素
System.out.println(ll);//[3254, 454, 855, 482, 441]
System.out.println(ll.getFirst());//3254
System.out.println(ll.getLast());//441
int i = ll.remove();//删除第一个元素,并返回
System.out.println(i);//3254
System.out.println(ll);//[454,855,482,441]
i = ll.remove(2);//删除下标为2的元素,并返回
System.out.println(i);//482
System.out.println(ll);//[454,855,441]
}
}
2.Set
Set 注重独一无二的性质,该体系集合用于存储无序(存入和取出的顺序不一定相同)元素,值不能重
复。对象的相等性本质是对象hashCode 值(java 是依据对象的内存地址计算出的此序号)判断
的,如果想要让两个不同的对象视为相等的,就必须重写Object 的hashCode 方法和equals 方
法。
HashSet(Hash表)
哈希表存放的是哈希值,哈希表边存放的是哈希值。HashSet 存储元素的顺序并不是按照存入时的顺序(和List 显然不同) 而是按照哈希值来存的所以取数据也是按照哈希值取得。元素的哈希值是通过元素的hashCode 方法来获取的, HashSet 首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals 方法 如果 equls 结果为true ,HashSet 就视为同一个元素。如果equals 为false 就不是同一个元素。
注意:hashcode方法比equals快,但是哈希值是可能会有冲突的,因为哈希值是固定32位长度的,但是我们的变量地址远不止这个数,所以可能会产生冲突,所以我们先判断hashcode是否相等,如果相等了才要再判断equals。
那么根据哈希值和equals的相同或不同就会分成两种情况:
第一种情况如果哈希值不同,则在哈希表中是分离的。
第二种情况如果哈希值相同,但是equals不同,则在哈希表中为一列的。
HashSet通过hashCode值来确定元素在内存中的位置,一个hashCode位置上可以存放多个元素。
package com.hbq.collectionsuse;
import java.util.HashSet;
import java.util.Iterator;
public class HashSetUse {
public static void main(String[] args) {
HashSet<Integer> hs = new HashSet<>();
hs.add(414);
hs.add(478);
hs.add(788);
hs.add(-45);
System.out.println(hs);//[788, -45, 414, 478]
hs.add(414);//重复的元素不会被添加
System.out.println(hs);//[788, -45, 414, 478]
hs.add(null);//可以有null值
System.out.println(hs.contains(788));
boolean flag = hs.remove(-45);
System.out.println(flag);//删除成功返回true
System.out.println(hs);//[null,788,414,478]
flag = hs.remove(-45);
System.out.println(flag);//删除失败返回false
System.out.println(hs.size());//4
for (Iterator iter = hs.iterator(); iter.hasNext(); ) { //可以遍历null的迭代器
System.out.println(iter.next());
}
hs.remove(null);//把null删除掉,不然下面的遍历会出现空指针异常
for (int i : hs) {
System.out.println(i);
}
}
}
TreeSet
TreeSet是使用二叉树的原理对新add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。Integer 和String 对象都可以进行默认的TreeSet 排序,而自定义类的对象是不可以的,自己定义的类必须实现Comparable 接口,并且覆写相应的compareTo()函数,才可以正常使用。在覆写compare()函数时,要返回相应的值才能使TreeSet 按照一定的规则来排序比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
TreeSet是有序的set集合,所以支持add、remove方法。并且add、remove、contains都只有log(n)的时间开销。底层是一颗红黑树。
默认的构造器TreeSet()表示按升序排序,也可以自己指定Comparator.reverseOrder()来降序排序。
package com.hbq.collectionsuse;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetUse {
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<>();
ts.add(44);
ts.add(8978);
ts.add(781);
ts.add(-785);
System.out.println(ts);// [-785, 44, 781, 8978] 有序且排了序
System.out.println(ts.size());// 4
System.out.println(ts.contains(781)); // true
System.out.println(ts.contains(-1)); // false
// 返回set中小于5的最大元素
System.out.println(ts.lower(5)); // -785
// 返回set中小于等于-800的最大元素
System.out.println(ts.lower(-800)); // null
// 返回set中大于等于800的最小元素
System.out.println(ts.ceiling(800)); // 8978
// 返回set中大于9000的最小元素
System.out.println(ts.higher(9000)); // null
System.out.println(ts.pollFirst());//将set第一个元素弹出
System.out.println(ts.pollLast());//将set最后一个元素弹出
System.out.println(ts);// [44,781]
for (Iterator iter = ts.iterator(); iter.hasNext(); ) {
System.out.println(iter.next());
}
}
}
LinkedHashSet
LinkedHashSet是继承HashSet,并基于LinkedHashMap来实现的,底层使用LinkedHashMap保存所有元素,操作上和HashSet一致,所以其方法都是和HashSet相同的。
package com.hbq.collectionsuse;
import java.util.Iterator;
import java.util.LinkedHashSet;
public class LinkedHashSetUse {
public static void main(String[] args) {
LinkedHashSet<Integer> ll = new LinkedHashSet<>();
ll.add(414);
ll.add(478);
ll.add(788);
ll.add(-45);
System.out.println(ll);//[788, -45, 414, 478]
ll.add(414);//重复的元素不会被添加
System.out.println(ll);//[788, -45, 414, 478]
ll.add(null);//可以有null值
System.out.println(ll.contains(788));
boolean flag = ll.remove(-45);
System.out.println(flag);//删除成功返回true
System.out.println(ll);//[null,788,414,478]
flag = ll.remove(-45);
System.out.println(flag);//删除失败返回false
System.out.println(ll.size());//4
for (Iterator iter = ll.iterator(); iter.hasNext(); ) { //可以遍历null的迭代器
System.out.println(iter.next());
}
ll.remove(null);//把null删除掉,不然下面的遍历会出现空指针异常
for (int i : ll) {
System.out.println(i);
}
}
}
Map
HashMap
1.HashMap
在jdk1.7里,HashMap是数组+链表的形式实现的。jdk1.8后是数组+链表+红黑树实现的。HashMap 根据键的hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,但是允许多条记录的值为null。不支持线程同步。HashMap 的 key 与 value 类型可以相同也可以不同。
HashMap在jdk1.7的实现方式如下:
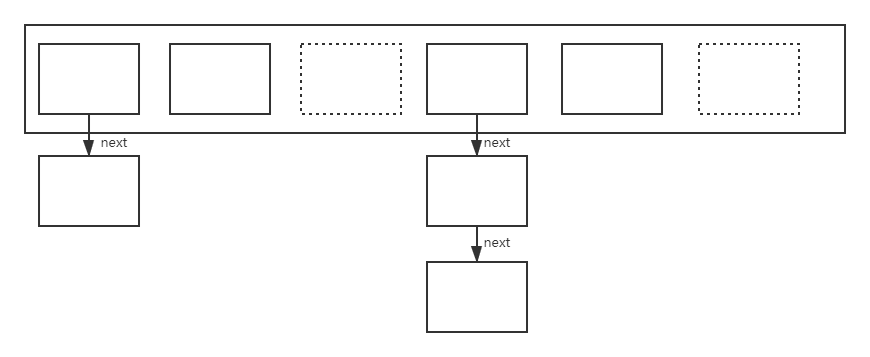
HashMap里面是一个数组,数组中的每一个元素是一个单向的链表。链表里的每个元素又是一个嵌套类Entry的实例,Entry包含四个属性:key、value、hash值和用于单向链表的next。
static class Entry<K,V> implements Map.Entry<K,V>{
final K key;
V value;
Entry<K,V> next;
int hash;
}
但是这样随着链表的长度越来越长,最终查找的效率会降低。可能会有O(n)的时间开销。所以在jdk1.8中,如果链表的元素超过了8个,那么将链表改成红黑树来存储。这样这部分开销可以降低为O(logn)。
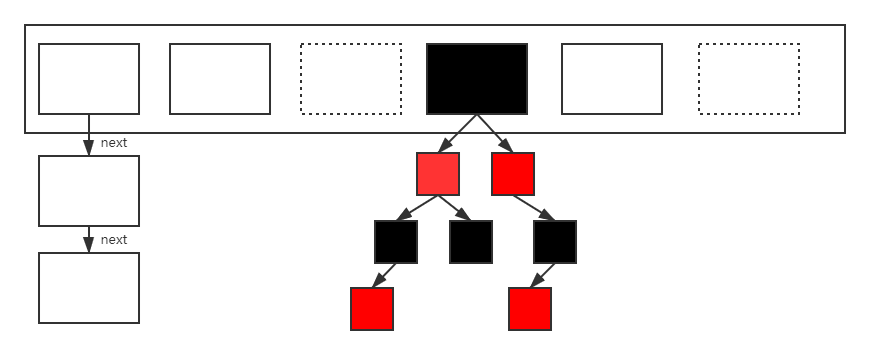
实例
package com.hbq.collectionsuse;
import java.util.HashMap;
public class HashMapUse {
public static void main(String[] args) {
HashMap<String, Integer> hm = new HashMap<>();
hm.put("张三", 18);
hm.put("李四", 20);
hm.put("王麻子", 25);
System.out.println(hm);//{李四=20, 张三=18, 王麻子=25}
System.out.println(hm.get("张三"));//通过get方法传入键获得对应的值 18
System.out.println(hm.get("王五"));//get方法要是没有对应的键会得到null
System.out.println(hm.getOrDefault("王五", 0));//如果没有"王五"这个键,就返回0
hm.remove("李四");//remove方法删除传入的键的键值对
System.out.println(hm);//{张三=18, 王麻子=25}
System.out.println(hm.size());//获取HashMap大小 2
System.out.println(hm.containsKey("张三"));//判断是否存在该键 true
System.out.println(hm.containsValue(20));//判断是否存在该值 false
for (String i : hm.keySet()) {
System.out.println("key:" + i + ",value:" + hm.get(i));
}
System.out.println(hm.keySet());//[张三, 王麻子]
System.out.println(hm.values());//[18, 25]
System.out.println(hm.entrySet());//[张三=18, 王麻子=25]
}
}
2.ConcurrentHashMap
HashMap无法实现并发操作,所以设计了一个ConcurrentHashMap使得HashMap可以支持并发操作。ConcurrentHashMap和HashMap的思路差不多。整个ConcurrentHashMap由一个个的Segment段(也称为分段锁)组成。简单来说,ConcurrentHashMap就是一个Segment数组,而Segment数组又是继承ReentrantLock来进行加锁的,每次需要加锁的时候,都会将一个Segment段加锁,这样就能保证一个Segment段是线程安全的,从而保证全局是线程安全的。
在jdk1.7中,ConcurrentHashMap的结构是这样的:

Segment的容量默认是16,这个时候,最多可以支持16个线程并发写,只要它们的操作分别在不同的Segment上。具体的Segment内部其实和HashMap结构上是一样的,只不过要保证线程安全,所以处理起来更麻烦一些。
jdk1.8也只是将上图中链表的部分超出8个以后改成红黑树,这一点与HashMap是一致的。
ConcurrentHashMap方法大多和HashMap一样。在线程章节更详细。
HashTable
HashTable和HashMap类似。就是在多线程进行访问的时候,在HashTable里需要得到锁才能增删查改。
方法和HashMap大体上也是一样的。
TreeMap
按照键进行排序的数据结构。底层是使用红黑树实现的。
用法和HashMap也很类似。
package com.hbq.collectionsuse;
import java.util.Comparator;
import java.util.TreeMap;
public class TreeMapUse {
public static void main(String[] args) {
TreeMap<Integer, String> tm = new TreeMap<>(Comparator.reverseOrder());//初始化的时候默认是升序的,但是可以传入Comparator.reverseOrder()来使其按键降序
tm.put(5,"王五");
tm.put(6,"黄六");
tm.put(3,"张三");
tm.put(-1,"不存在的");
System.out.println(tm);//{6=黄六, 5=王五, 3=张三, -1=不存在的}
}
}














 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









