







第一步、屏蔽系统自带的nouveau
查看命令(没有输出表示屏蔽):
lsmod | grep nouveau
修改dist-blacklist.conf文件:
vim /lib/modprobe.d/dist-blacklist.conf
将nvidiafb注释掉:
#blacklist nvidiafb
然后添加以下语句:
blacklist nouveau
options nouveau modeset=0
第二步、同步内核:
先安装:yum -y install gcc make dkms ,再重启:reboot,最后安装:yum install "kernel-devel-uname-r == $(uname -r)" -y
[root@localhost ~]# uname -r
3.10.0-1160.11.1.el7.x86_64
[root@localhost ~]# rpm -aq | grep kernel-devel
kernel-devel-3.10.0-1160.11.1.el7.x86_64
#下载指定版本 kernel: http://rpm.pbone.net/index.php3?stat=3&limit=1&srodzaj=3&dl=40&search=kernel
#下载指定版本 kernel-devel:http://rpm.pbone.net/index.php3?stat=3&limit=1&srodzaj=3&dl=40&search=kernel-devel
服务器的显卡查看:
yum install pciutils
lspci | grep -i vga
0000:b3:00.0 VGA compatible controller: NVIDIA Corporation TU104GL [Quadro RTX 5000] (rev a1)
使用nvidia GPU查看:
lspci | grep -i nvidia
第三步、下载对应版本的nvidia驱动并安装
[root@localhost ~]# bash NVIDIA-Linux-x86_64-460.32.03.run --kernel-source-path=/usr/src/kernels/3.10.0-1160.11.1.el7.x86_64/


[root@localhost ~]# nvidia-smi 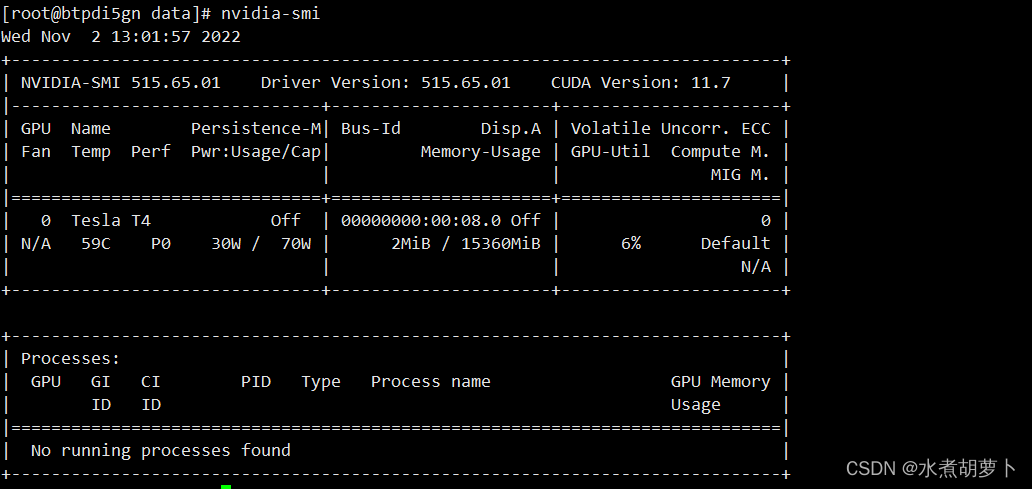


















 5049
5049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











