







【开源发布】通义千问 Qwen3 全系开源!8款混合推理模型全面解析
关键词
通义千问 Qwen3 Qwen3开源 MoE模型 Dense模型 混合推理 思考模式 快速响应模式 多语言支持 119种语言 Agent能力 工具调用 MCP协议 预训练36万亿token 长思考链推理 强化学习推理 RLHF 多模态融合 超长上下文32K token HuggingFace部署 ModelScope部署 SGLang部署 vLLM部署 Ollama本地推理 LMStudio llama.cpp ktransformers 动态软切换 Qwen-Agent 智能体系统 AGI ASI
摘要
通义千问Qwen3全系正式开源,覆盖8款混合推理模型,首次引入思考与快速响应双模式,支持119种语言与方言,Agent与工具调用能力大幅增强。旗舰模型Qwen3-235B-A22B在代码、推理、数学等基准测试中表现领先,Qwen3-30B-A3B实现高效推理成本控制。预训练规模达36万亿token,结合强化学习与长思考链训练,推理链条完整度显著提升。支持Hugging Face、ModelScope、SGLang、vLLM等多框架部署,兼容本地轻量推理。Qwen3标志着国内大模型走向智能体系统时代,为开发者、企业提供高性能、易集成的AI底座。
目录
- 通义千问 Qwen3 发布概览
- Qwen3 开源模型全览(MoE+Dense)
- 核心技术亮点解析
3.1 思考模式与快速模式切换
3.2 多语言与多方言支持
3.3 Agent推理与工具调用能力增强 - Qwen3 的预训练与后训练体系
4.1 预训练数据与三阶段流程
4.2 后训练强化学习与模式融合 - 部署与使用指南
5.1 Hugging Face、ModelScope部署
5.2 本地推理与轻量化部署框架
5.3 API服务端点搭建(SGLang/vLLM) - 高级玩法:思考模式动态软切换与Agent集成实践
- 通义千问 Qwen3 的未来演进路线
- 总结与展望
1. 通义千问 Qwen3 发布概览
通义千问团队正式发布了Qwen3模型家族,一口气开源了8款「混合推理」模型,覆盖从小型0.6B到超大型235B全尺寸段,分别包括:
- 2款 MoE(专家混合)模型:在推理性能与成本控制之间取得了优秀平衡。
- 6款 Dense(稠密)模型:适配从轻量级推理到高性能推理的不同应用场景。
📈 配图展示:Qwen3模型家族全览
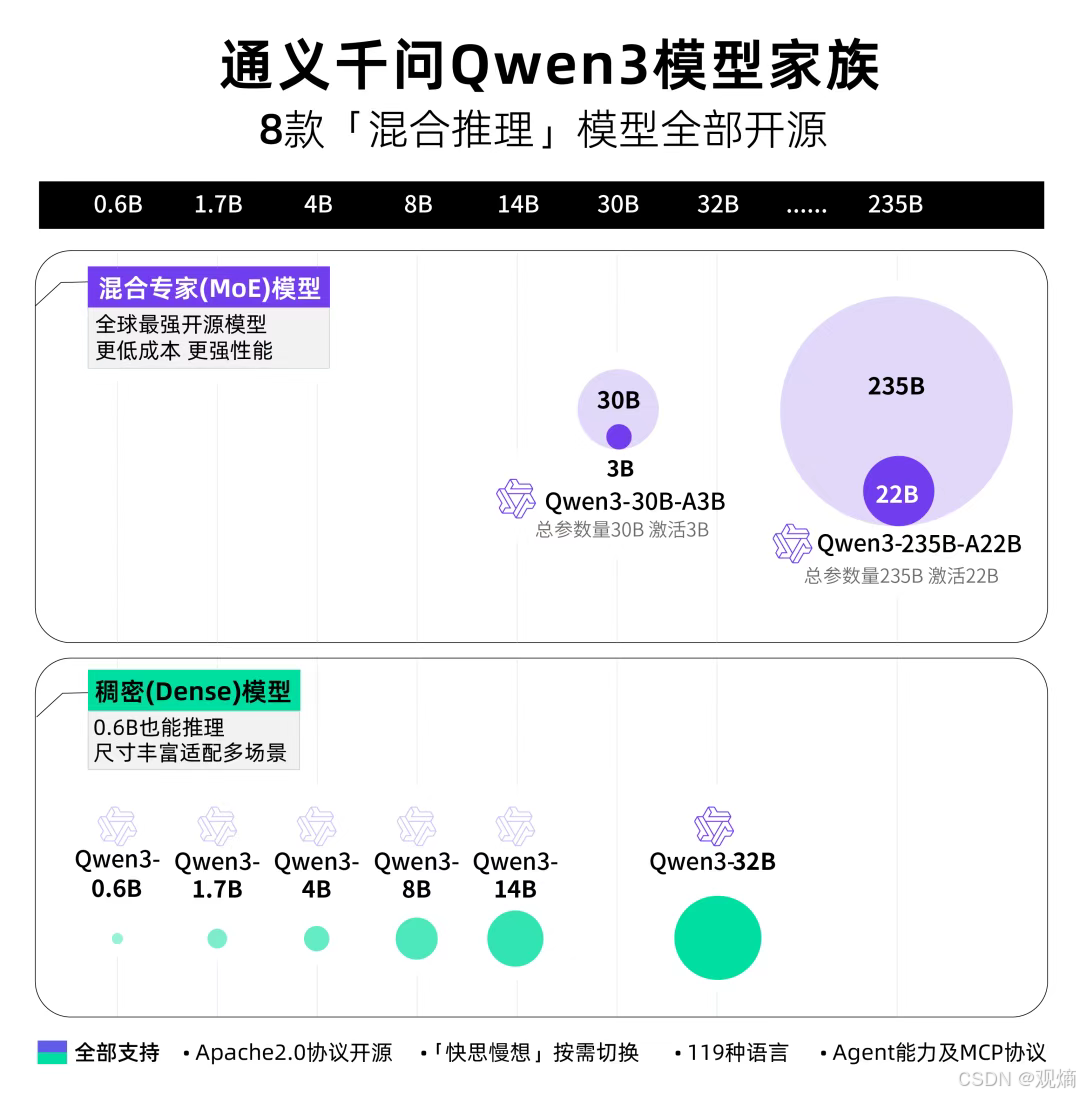
其中,旗舰款 Qwen3-235B-A22B(2350亿总参数,220亿激活参数)表现尤为出色,拥有全球最强开源推理能力。小型MoE模型 Qwen3-30B-A3B 也在30亿激活参数下实现了超越同体积模型的推理效率。
所有模型均支持:
- Apache 2.0协议开源
- 快速/慢速思考模式按需切换
- 119种语言与方言
- Agent工具调用与MCP协议交互
2. Qwen3 开源模型全览(MoE+Dense)
此次开源包括两款MoE模型:Qwen3-235B-A22B(2350多亿总参数、 220多亿激活参),以及Qwen3-30B-A3B(300亿总参数、30亿激活参数);以及六个Dense模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B。
在综合推理、数学、代码等多领域基准测试中,Qwen3系列模型表现极具竞争力,与全球顶尖模型(如OpenAI、DeepSeek、Gemini、Grok等)同场竞技,稳居前列。
📊 配图展示:Qwen3基准测试性能对比
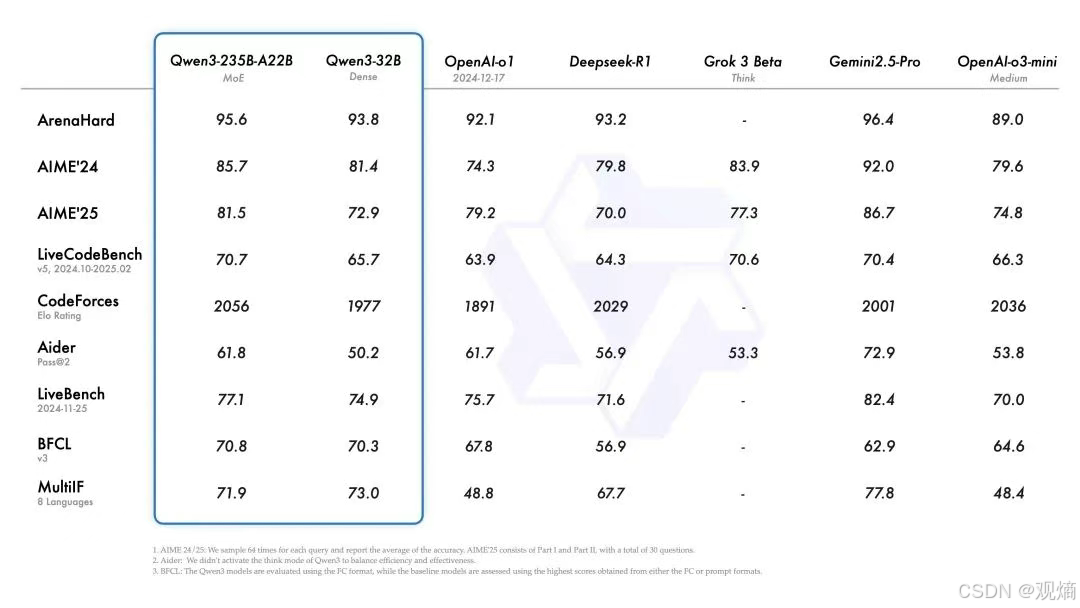
从ArenaHard、AIME’24、Codeforces到LiveBench等多个权威评测数据来看,Qwen3-235B-A22B不仅在绝大多数基准上优于OpenAI-o1、Deepseek-R1等模型,在代码生成、复杂推理、数学推演等细分领域也展现了强大实力。
特别地,Qwen3-32B Dense模型在仅使用稠密结构的情况下,也达到了与部分顶级MoE模型相当的性能表现,进一步验证了底层架构与数据质量的大幅提升。
3. 核心技术亮点解析
Qwen3 在模型推理、跨语言能力和智能体应用扩展方面进行了深度革新,带来了行业领先的多个新特性。以下是三大核心亮点详解:
3.1 思考模式与快速模式切换
Qwen3 系列模型引入了创新性的双推理模式:
- 思考模式(Thinking Mode):支持逐步推理,深度展开逻辑链条,适合复杂推理、数学推演、代码生成等高智力场景。
- 非思考模式(Non-thinking Mode):快速直接给出响应,适合日常问答、短对话等轻量级场景。
更重要的是,推理预算(Thinking Budget) 可以动态控制 —— 用户可以根据任务复杂度调整推理深度,灵活权衡推理质量与计算开销。
📊 配图展示:思考模式下推理预算提升效果曲线
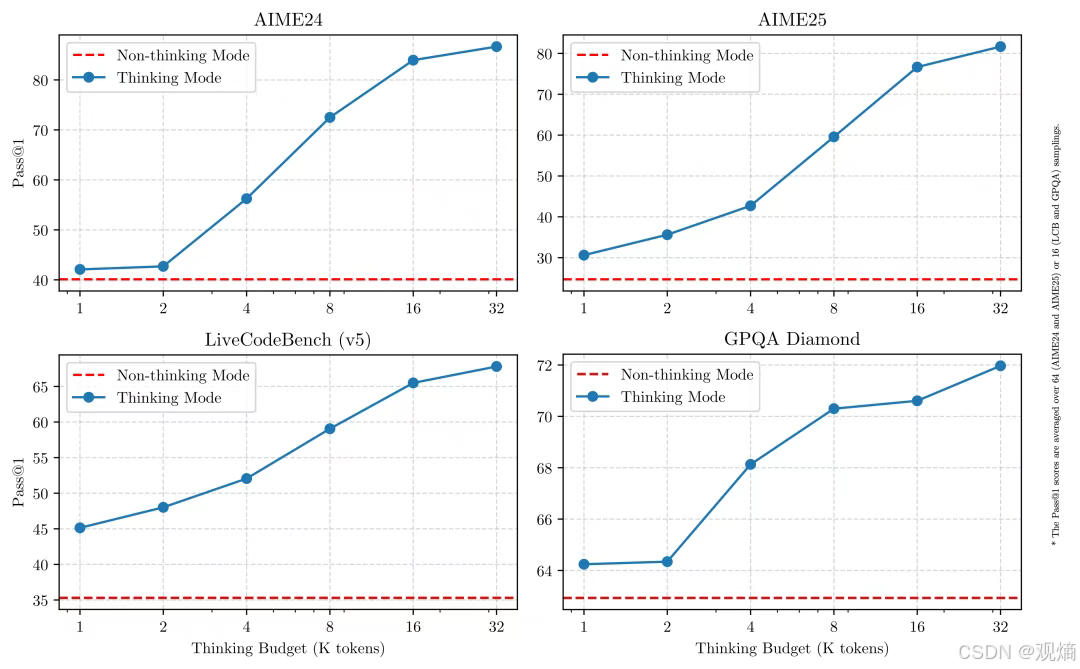
如图所示,在 AIME24、AIME25、LiveCodeBench 和 GPQA 等复杂推理基准中,随着思考预算(Tokens数)的增加,Qwen3的推理正确率(Pass@1)显著提升,而非思考模式则受限于快速响应机制,精度基本固定。这种可控推理机制,为不同业务场景提供了极大的灵活性与成本控制空间。
3.2 多语言与多方言支持
Qwen3 在预训练阶段引入了丰富的多语言、多方言数据,全面支持 119种语言与方言,涵盖英法德俄西中日等主流语种,同时涵盖南岛语系、乌拉尔语系、德拉威语系、藏缅语系等众多小语种,真正做到了全球覆盖。
🌍 配图展示:Qwen3支持的完整语言列表

在跨语言推理、全球化产品集成、国际业务场景中,Qwen3为开发者提供了强有力的支持,极大降低了模型迁移与本地化定制成本。
3.3 Agent推理与工具调用能力增强
为了让大模型真正具备智能体(Agent)级推理与决策能力,Qwen3在训练过程中特别强化了环境交互与**工具调用(Tool-Use)**能力,并基于 MCP协议(Multi-Component Protocol)进行了深度集成。
Qwen3不仅能够理解复杂指令、推理多轮上下文,还能自主调用外部API、执行代码、检索信息等操作,极大地扩展了传统语言模型的应用边界。
例如,用户只需发送简单的指令,Qwen3便可以自动提取网页信息、获取GitHub项目数据并生成图表,实现了“理解—推理—行动”的一体化闭环。这种能力为构建企业级Agent系统、智能助理、自动化工作流等复杂应用场景奠定了坚实基础。
4. Qwen3 的预训练与后训练体系
通义千问Qwen3在数据构建、训练流程、强化学习优化方面进行了全面升级,显著提升了模型在推理、数学、代码、跨语言等多领域的综合性能。
4.1 预训练数据与三阶段流程
Qwen3使用了近36万亿token的超大规模多语种数据集进行预训练,是Qwen2.5时期数据量的约2倍。训练过程分为三个阶段:
- 阶段一(S1):在超30万亿token上进行初步预训练,具备通用语言理解与生成能力(上下文长度4K)。
- 阶段二(S2):引入大量STEM(科学、技术、工程、数学)数据和代码数据,在额外5万亿token上继续训练。
- 阶段三(S3):使用高质量长文本扩展上下文窗口至32K,优化长文档处理能力。
在数据构建过程中,还引入了模型辅助的数据增强技术,如使用Qwen2.5-Math、Qwen2.5-Coder生成高质量数学与代码数据,进一步强化了模型在专业领域的推理与表达能力。
在相同或更少激活参数数量下,Qwen3基础模型性能全面优于同等规模Qwen2.5 Dense模型。
📊 配图展示:Qwen3-235B-A22B预训练基准性能对比
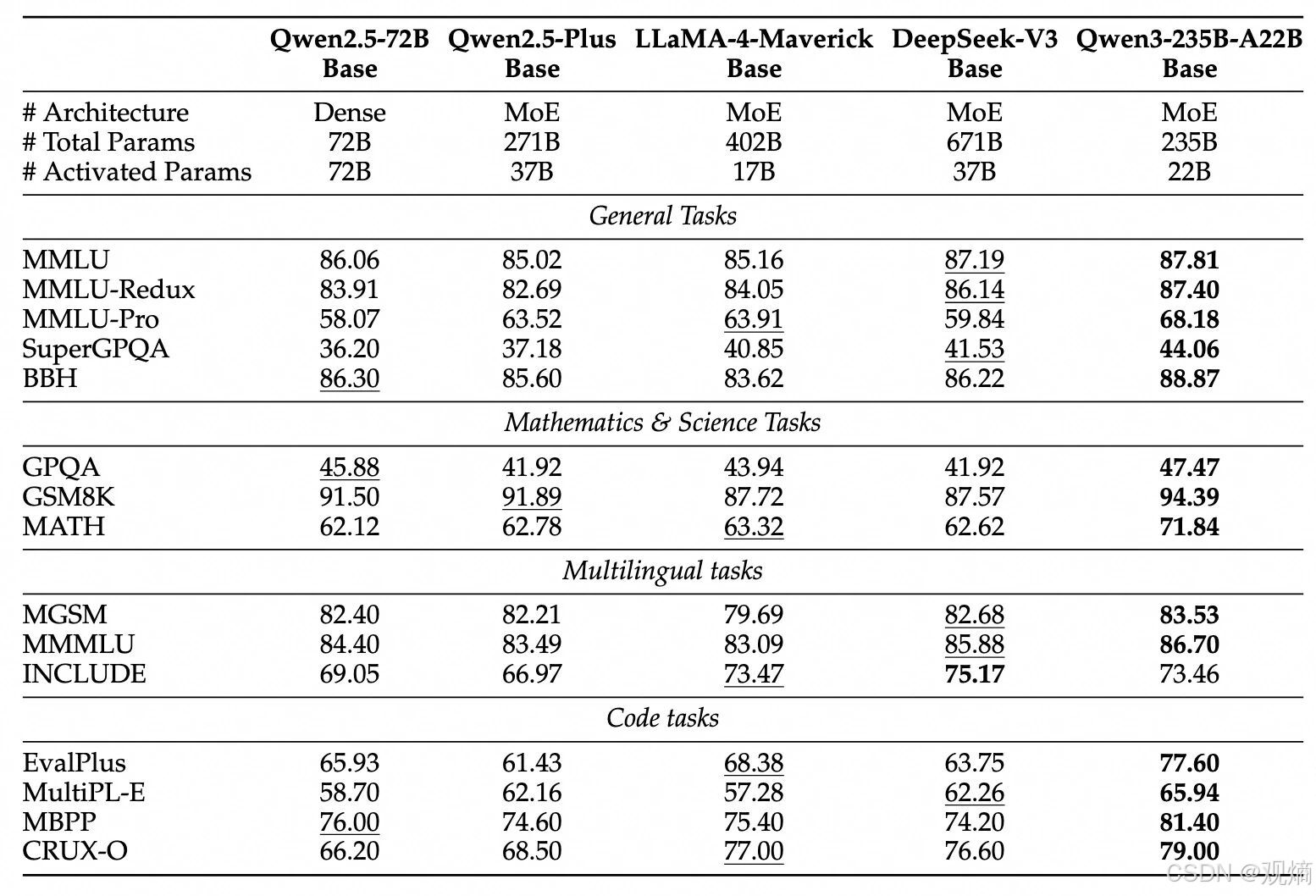
可以看到,Qwen3-235B-A22B在MMLU、GSM8K、MATH、EvalPlus等多个权威基准测试上,全面领先于DeepSeek-V3、LLaMA-4-Maverick等其他顶级开源模型。
4.2 后训练强化学习与模式融合
为了进一步优化推理链条质量与控制思考模式,Qwen3在后训练阶段设计了四阶段强化学习流程:
- Stage 1:长推理链冷启动(Long-CoT Cold Start)
- 微调模型在复杂任务(如数学、代码、逻辑推理)中的长推理链条。
- Stage 2:推理强化学习(Reasoning RL)
- 基于规则奖励机制,强化模型的推理深度与探索能力。
- Stage 3:思考模式融合(Thinking Mode Fusion)
- 融合思考模式与快速模式,打通推理链条与即时响应路径。
- Stage 4:通用强化学习(General RL)
- 在指令跟随、格式遵循、工具调用等领域进一步微调,提升通用任务完成能力。
同时,针对中小尺寸模型,还引入了Strong-to-Weak蒸馏技术,将大型模型的推理能力高效迁移至轻量级模型中,保证小模型也能具备优秀的推理与交互表现。
📈 配图展示:Qwen3后训练流程与蒸馏策略示意图
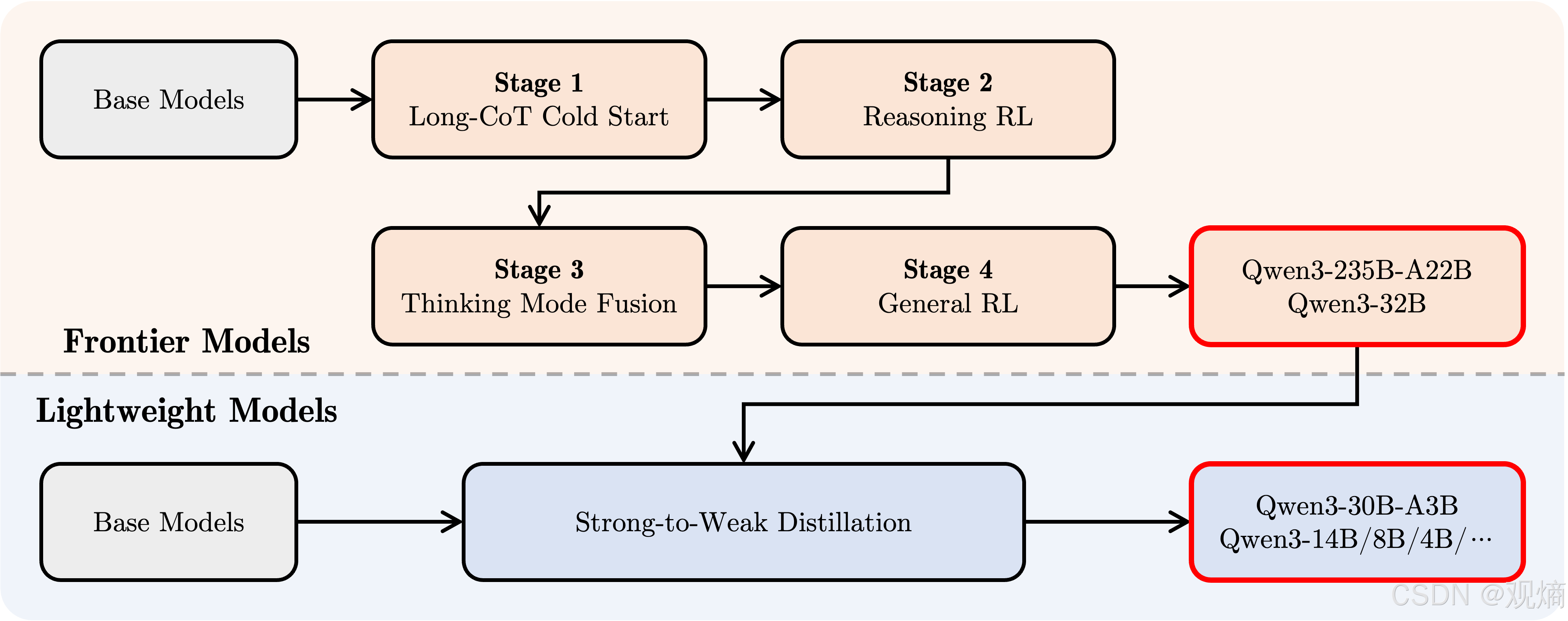
最终,基于这一套系统化后训练体系,Qwen3在推理链条完整性、工具调用准确率、多轮对话稳定性上均实现了显著提升,具备了真正意义上的思考与行动一体化能力。
5. 部署与使用指南
Qwen3系列模型开源后,官方提供了丰富的部署与使用方式,支持 Hugging Face、ModelScope、本地推理框架以及 API 端点搭建。以下以 Qwen3-30B-A3B 为例,介绍标准化部署流程。
5.1 Hugging Face transformers 框架使用示例
以下示例演示如何使用 ModelScope 加载并推理 Qwen3-30B-A3B:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备输入
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 默认启用思考模式,可切换
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 进行文本生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容
try:
index = len(output_ids) - output_ids[::-1].index(151668) # 查找 </think> 标签
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
关闭思考模式示例
如果需要禁用思考模式,只需修改 enable_thinking=False:
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # 禁用思考模式
)
5.2 API 服务器部署(SGLang/vLLM)
Qwen3 支持通过 SGLang 或 vLLM 快速搭建 OpenAI兼容API:
- 使用 SGLang 启动服务
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3
- 使用 vLLM 启动服务
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
注意:如果不需要思考模式,可以移除
--reasoning-parser与--enable-reasoning参数。
5.3 本地推理交互体验
如果希望在本地快速体验推理效果,可以直接使用 Ollama 工具运行:
ollama run qwen3:30b-a3b
此外,也可以通过 LMStudio、llama.cpp、ktransformers 等本地推理框架进行集成开发,适合多种系统环境下的轻量化应用。
6. 高级用法:思考模式动态软切换与Agent集成实践
为了进一步提升推理控制能力,Qwen3提供了思考模式的动态软切换机制,同时也优化了Agent框架下的工具调用能力。
6.1 思考模式动态软切换示例
在启用 enable_thinking=True 时,可以通过在用户输入中添加特殊指令 /think 或 /no_think 来逐轮切换思考模式。
以下是基于 transformers 的多轮对话示例代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen3-30B-A3B/Qwen3-30B-A3B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# 更新对话历史
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# 示例使用
if __name__ == "__main__":
chatbot = QwenChatbot()
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
在多轮对话中,模型将自动遵循最近一次出现的 /think 或 /no_think 指令,动态调整推理策略。
6.2 Qwen-Agent 框架下的工具调用示例
为了方便构建智能体系统,Qwen3还提供了集成式 Agent 框架 Qwen-Agent,支持 MCP协议下的多工具调用。
以下是示例代码:
from qwen_agent.agents import Assistant
# 定义 LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B',
# 自定义API服务器
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
}
# 定义可用工具
tools = [
{
'mcpServers': {
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter' # 内置代码解释器工具
]
# 定义 Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# 流式生成示例
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
通过以上方式,开发者可以快速集成多种工具能力,如:获取当前时间、爬取网页内容、解释执行代码等,实现高度自主化的智能交互。
7. Qwen3 的未来演进方向
Qwen3 的发布代表了通义千问团队在追求更高智能体系道路上的一次重要飞跃。展望未来,Qwen项目将继续围绕以下几个关键方向持续优化与升级:
-
模型规模扩展
在当前最大235B参数规模基础上,进一步扩展模型深度与广度,探索更大规模推理网络。 -
预训练数据质量提升
持续丰富多样性数据源,特别是STEM领域、代码、推理链条相关高质量数据集,提升模型专业领域认知。 -
超长上下文处理能力
将支持上下文长度从当前32K扩展至更长区间,提升长文档理解与处理能力,为复杂任务推理提供更大空间。 -
多模态融合
推进语言、视觉、音频、代码等多模态能力统一,打造面向真实环境交互的泛智能体模型。 -
环境反馈强化学习(RLHF扩展)
通过引入真实世界交互反馈,进一步优化智能体的长期推理与决策质量。 -
智能体系统(Agent Systems)中心化
从单一模型训练,转向以自主智能体系统(多模型协作+外部工具调用)为核心的能力建设,真正走向以「Agent训练」为中心的新纪元。
通义千问团队将致力于持续推动开源开放,助力全球开发者与研究人员共同探索通用人工智能(AGI)和超级人工智能(ASI)的无限可能。
8. 总结与展望
通义千问 Qwen3 系列以创新的思考模式控制、多语言广泛支持、超大规模预训练数据、深度强化学习优化和强大的Agent能力,为开源大模型领域树立了新的技术标杆。
无论是超大模型(如 Qwen3-235B-A22B),还是轻量级高效模型(如 Qwen3-30B-A3B、Qwen3-4B),都展现了极具竞争力的性能表现,适配从科研探索到生产应用的各类需求场景。
未来,随着更多训练方法革新、环境交互强化、多模态融合推进,Qwen项目将持续引领智能体技术演进潮流,为构建更加智能、开放、可控的未来AI生态奠定坚实基础。
🌟 如果本文对你有帮助,欢迎三连支持!
👍 点个赞,给我一些反馈动力
⭐ 收藏起来,方便之后复习查阅
🔔 关注我,后续还有更多实战内容持续更新
写系统,也写秩序;写代码,也写世界。
观熵出品,皆为实战沉淀。
个人简介
作者简介:全栈研发,具备端到端系统落地能力,专注大模型的压缩部署、多模态理解与 Agent 架构设计。 热爱“结构”与“秩序”,相信复杂系统背后总有简洁可控的可能。
我叫观熵。不是在控熵,就是在观测熵的流动
个人主页:观熵
个人邮箱:privatexxxx@163.com
座右铭:愿科技之光,不止照亮智能,也照亮人心!

专栏导航
观熵系列专栏导航:
AI前沿探索:从大模型进化、多模态交互、AIGC内容生成,到AI在行业中的落地应用,我们将深入剖析最前沿的AI技术,分享实用的开发经验,并探讨AI未来的发展趋势
AI开源框架实战:面向 AI 工程师的大模型框架实战指南,覆盖训练、推理、部署与评估的全链路最佳实践
计算机视觉:聚焦计算机视觉前沿技术,涵盖图像识别、目标检测、自动驾驶、医疗影像等领域的最新进展和应用案例
国产大模型部署实战:持续更新的国产开源大模型部署实战教程,覆盖从 模型选型 → 环境配置 → 本地推理 → API封装 → 高性能部署 → 多模型管理 的完整全流程
TensorFlow 全栈实战:从建模到部署:覆盖模型构建、训练优化、跨平台部署与工程交付,帮助开发者掌握从原型到上线的完整 AI 开发流程
PyTorch 全栈实战专栏: PyTorch 框架的全栈实战应用,涵盖从模型训练、优化、部署到维护的完整流程
深入理解 TensorRT:深入解析 TensorRT 的核心机制与部署实践,助力构建高性能 AI 推理系统
Megatron-LM 实战笔记:聚焦于 Megatron-LM 框架的实战应用,涵盖从预训练、微调到部署的全流程
AI Agent:系统学习并亲手构建一个完整的 AI Agent 系统,从基础理论、算法实战、框架应用,到私有部署、多端集成
DeepSeek 实战与解析:聚焦 DeepSeek 系列模型原理解析与实战应用,涵盖部署、推理、微调与多场景集成,助你高效上手国产大模型
端侧大模型:聚焦大模型在移动设备上的部署与优化,探索端侧智能的实现路径
行业大模型 · 数据全流程指南:大模型预训练数据的设计、采集、清洗与合规治理,聚焦行业场景,从需求定义到数据闭环,帮助您构建专属的智能数据基座
机器人研发全栈进阶指南:从ROS到AI智能控制:机器人系统架构、感知建图、路径规划、控制系统、AI智能决策、系统集成等核心能力模块
人工智能下的网络安全:通过实战案例和系统化方法,帮助开发者和安全工程师识别风险、构建防御机制,确保 AI 系统的稳定与安全
智能 DevOps 工厂:AI 驱动的持续交付实践:构建以 AI 为核心的智能 DevOps 平台,涵盖从 CI/CD 流水线、AIOps、MLOps 到 DevSecOps 的全流程实践。
C++学习笔记?:聚焦于现代 C++ 编程的核心概念与实践,涵盖 STL 源码剖析、内存管理、模板元编程等关键技术
AI × Quant 系统化落地实战:从数据、策略到实盘,打造全栈智能量化交易系统
大模型运营专家的Prompt修炼之路:本专栏聚焦开发 / 测试人员的实际转型路径,基于 OpenAI、DeepSeek、抖音等真实资料,拆解 从入门到专业落地的关键主题,涵盖 Prompt 编写范式、结构输出控制、模型行为评估、系统接入与 DevOps 管理。每一篇都不讲概念空话,只做实战经验沉淀,让你一步步成为真正的模型运营专家。


















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











