







目录
C++元编程的特点
使用C++元编程也有半个月了,先写一下感想。如果把C比作手枪,C++是步枪,那么C++元编程应该就是机关枪了。C++元编程有很多好处,比如自动的类型推演、编译器错误检查。其核心就是,这是一种编译期的语言。在编译期能对一些流程进行控制,就犹如你让电脑帮你写一些刻板的代码一样。那么它的缺点也很明显,就是这个语言它不够运行态,对于运行期需要动态处理的数据是无法实现的。正因为这个特点,C++元编程适合进行神经网络方面的编程,因为神经网络的结构和处理流程在编译器已经确定了,不会进行更改。
C++元编程的缺点
如果说编译期语言的局限性是设计特点,那么C++模板语言的流程控制过于复杂以及现代编译器弱小缓慢的编译能力则极大的限制了C++元编程的普及。我的卷积层设计成128*128需要编译的时间就是以小时计数的了,这注定这门语言不能用于机器学习算法的试验,只能用于对已经固定算法的加速实现。况且在GPU并行计算的情况下,这种CPU计算的方法注定只能是实验室里的学习用途。
CNN的实现
CNN是卷积神经网络的简称,它是由卷积-池化层(卷积包含了后面的ReLU层)的重复,加上全连接层实现的。卷积-池化层用于压缩数据的特征,全连接层用于对特征的模式进行判断。其中设计的具体算法包括卷积层误差的反向传播、池化层误差的反向传播以及模式判别层的训练方法。
下面开始展示的是我具体的实现。首先还是先展示我的试验代码:
#include "bp.hpp"
#include "cnn.hpp"
template<int input_type>
struct bp_fc_layer
{
/* 因为是模拟结果,而不是判别,所以用的sigmoid,判别时候用softmax。 */
using type = bp<1, nadam, sigmoid, XavierGaussian, input_type, 3>;
};
int main(int argc, char** argv)
{
using cnn_type = cnn<
bp_fc_layer, // 输出层用选用bp,层级是2层,3节点输出
128, 128, // 网络输入是128*128的数据
8, 8, 2, 2, 2, 2, // 第一卷积池化层8*8核2*2步长,池化单位是2*2单元
6, 6, 2, 2, 2, 2, // 第一卷积池化层6*6核2*2步长,池化单位是2*2单元
4, 4, 2, 2, 2, 2, // 卷积池化层,卷积为4*4核2,2步长,池化单位是2*2
2, 2, 1, 1 // 卷积输出,卷积为2*2核2,2步长
>;
cnn_type::print_type(); // 打印网络结构
cnn_type cn;
cnn_type::input_type mt_input;
weight_initilizer<class def>::cal(mt_input, 0, 1);
cnn_type::ret_type mt_expected;
weight_initilizer<def>::cal(mt_expected, 0., 1.);
mt_expected.print();
for (int i = 0; ; ++i)
{
auto out = cn.forward(mt_input);
cn.backward(mt_expected);
if ((i+1) % 1000 == 0)
{
mt_expected.print();
(cn.forward(mt_input)).print();
_getch();
}
}
return 0;
}就是定义一个3个输出节点,输入是8*8矩阵,卷积池化层为卷积核2*2步长2*2、池化模板为2*2最后输出再进行一个2*2核1*1步长的卷积运算,最后用一个bp神经网络作为模式判别全连接层的神经网络。训练数据是随机的0-1间的数值矩阵,输入也是0-1间随机数值的矩阵。最后结果如下:

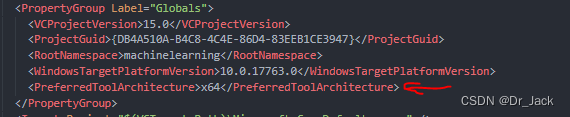
两三千次计算的效果就已经比较好了,到达万次训练结果就是精准匹配了。可见这个网络是具备学习能力的。理论上只要你内存足够大,编译时间足够长,可以编译出各种层数的CNN。但是一定要记得使用VS2017的时候在工程文件vcxproj中加上64位编译器标志(否则默认使用32位编译器会导致编译器内存不够用的问题),如下所示:
CNN算法实现cnn.hpp
#ifndef _CNN_HPP_
#define _CNN_HPP_
#include "convolution_layer.hpp"
#include "pool_layer.hpp"
#include "bp.hpp"
template<int conv_row, int conv_col, int conv_tpl_row, int conv_tpl_col, int conv_step_row, int conv_step_col, int pool_tpl_row, int pool_tpl_col, typename val_t = double>
struct conv_pool_layer
{
using input_type = mat<conv_row, conv_col, val_t >;
using conv_type = conv_layer<conv_row, conv_col, conv_tpl_row, conv_tpl_col, conv_step_row, conv_step_col, nadam, ReLu, HeGaussian, val_t>;
using pool_input_type = typename conv_type::ret_type;
using pool_type = pool_layer<pool_layer_max, pool_input_type::r, pool_input_type::c, pool_tpl_row, pool_tpl_col, val_t>;
using ret_type = typename pool_type::ret_type;
conv_type conv;
pool_type pool;
ret_type forward(const input_type& mt_input)
{
return pool.forward(conv.forward(mt_input));
}
input_type backward(const ret_type& mt_delta)
{
return conv.backward(pool.backward(mt_delta));
}
static void print_type()
{
conv_type::print_type();
pool_type::print_type();
}
};
template<int conv_row, int conv_col, typename val_t = double>
struct conv_pool_container
{
template<int conv_tpl_row, int conv_tpl_col, int conv_step_row, int conv_step_col
, int pool_tpl_row, int pool_tpl_col, int... rest>
struct layers
{
using conv_pool_type = conv_pool_layer<conv_row, conv_col, conv_tpl_row, conv_tpl_col, conv_step_row, conv_step_col, pool_tpl_row, pool_tpl_col, val_t>;
using next_type = typename conv_pool_container< conv_pool_type::ret_type::r, conv_pool_type::ret_type::c, val_t>::template layers<rest...>;
using ret_type = typename next_type::ret_type;
using input_type = typename conv_pool_type::input_type;
conv_pool_type layer;
next_type next;
ret_type forward(const input_type& mt_input)
{
return next.forward(layer.forward(mt_input));
}
input_type backward(const ret_type& mt_delta)
{
return layer.backward(next.backward(mt_delta));
}
static void print_type()
{
conv_pool_type::print_type();
next_type::print_type();
}
};
template<int conv_tpl_row, int conv_tpl_col, int conv_step_row, int conv_step_col, int pool_tpl_row, int pool_tpl_col
, int i1, int i2, int i3, int i4>
struct layers<conv_tpl_row, conv_tpl_col, conv_step_row, conv_step_col, pool_tpl_row, pool_tpl_col
, i1, i2, i3, i4>
{
using conv_pool_type = conv_pool_layer<conv_row, conv_col, conv_tpl_row, conv_tpl_col, conv_step_row, conv_step_col, pool_tpl_row, pool_tpl_col, val_t>;
using next_type = conv_layer<conv_pool_type::ret_type::r, conv_pool_type::ret_type::c, i1, i2, i3, i4,
nadam, ReLu, HeGaussian, val_t> ;
using ret_type = typename next_type::ret_type;
using input_type = typename conv_pool_type::input_type;
conv_pool_type layer;
next_type next;
ret_type forward(const input_type& mt_input)
{
return next.forward(layer.forward(mt_input));
}
input_type backward(const ret_type& mt_delta)
{
return layer.backward(next.backward(mt_delta));
}
static void print_type()
{
conv_pool_type::print_type();
next_type::print_type();
}
};
};
/* 输入值必须是1 + 2 + 6*n + 4
第一个是bp判别层的输出个数
,接下来两个是输入的矩阵配置
,接下来是卷积层核(2个),步长(2个),池化层核(2个)
,最后4个是最后一层卷积的,卷积层核(2个),步长(2个)
*/
template<template<int> class fc_tpl, int input_row, int input_col, int...rest>
struct cnn
{
using input_type = mat<input_row, input_col, double>;
using conv_pool_type = typename conv_pool_container<input_row, input_col>::template layers<rest...>;
using fc_type = typename fc_tpl<conv_pool_type::ret_type::r * conv_pool_type::ret_type::c * 2>::type;
using ret_type = typename fc_type::ret_type;
conv_pool_type cp1, cp2;
fc_type b;
ret_type forward(const input_type& mt)
{
auto bp_input = stretch_one_col(cp1.forward(mt), cp2.forwar 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











