









分布式计算系统在国外已经有了很多成熟的开源系统,比如比较有名的Hadoop,Spark,Strom等。开源的优势是:大家都在做,各种功能都能找到发布的源码,最最重要的是免费;缺点是:用户体验差,没有规范,功能片面。
对于大多数国内 IT 工程师来说,分布式计算仍是触不可及的领域(缺少实践平台),这是为什么国内大数据核心技术发展缓慢的原因之一。
其实大家熟悉分布式计算最主要还是因为一个名词火了:大数据,但是大数据真的有那么火么?其实是炒起来的,因为巨头在做,所以跟风大家就开始做了,但是想想网民对于分布式需求可能还会滞后很久。
什么是MapReduce?
MapReduce 最早是由 Google 公司研究提出的一种面向大规模数据处理的并行计算模型和方法。Google 公司设计 MapReduce 的初衷主要是为了解决其搜索引擎中大规模网页数据的并行化处理。
发明 MapReduce 以后,Google 公司内部进一步将其广泛应用于很多大规模数据处理问题。到目前为止,Google 公司内有上万个各种不同的算法问题和程序都使用 MapReduce 进行处理。
MapReduce 的灵感来源于函数式语言中的内置函数 Map 和 Reduce 。简单来说,在函数式语言里,Map 表示对一个列表中的每个元素做计算,Reduce 表示对一个列表中的每个元素做迭代计算。它们具体的计算是通过传入的函数来实现的,Map 和 Reduce 提供的是计算的框架。
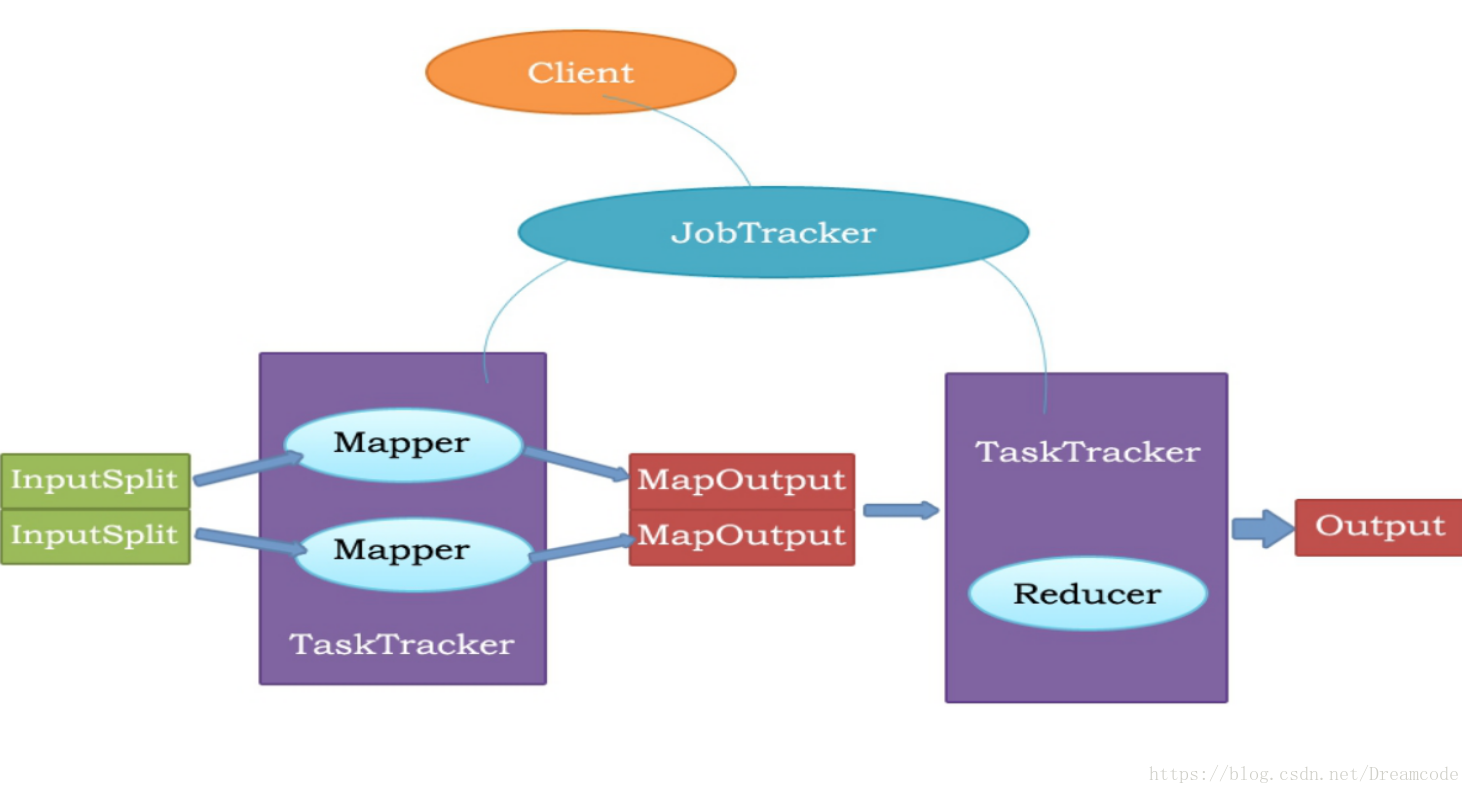
国外 Hadoop 生态链
目前主流的分布式计算系统是Hadoop,Hadoop生态链的好处是用户可以根据自身系统需要,选择性的部署安装部分产品,问题是几乎每一个Hadoop生态链产品都需要根据需求部署为一整套分布式集群,这使得大规模Hadoop数据中心运维非常复杂。
作为一项开源技术,原生的Hadoop并不是一款符合要求的企业级产品,其系统稳定性,兼容性,安全性以及易用性都无法达到企业级客户的标准。而大部分企业级客户自身IT能力相对较弱,基于开源技术进行开发符合自身需求的产品难度很大。
SunlightDB 数据湖
SunlightDB 完全使用 C 语言开发,大数据用户不需要单独部署每个功能模块,一次安装快速拥有一套功能完整,安全高效的企业级大数据平台。SunlightDB 数据湖可以使用简单的脚本语言 Javascript 开发 MR 批处理或流处理作业,进行复杂的数据处理。

SunlightDB 执行代码时,会在节点间进行作业自动分发和并行计算。用户可以将注意力集中在业务逻辑开发上,SunlightDB自动帮助你快速完成,成百上千GB或是TB量级的数据计算。

联系我们
请扫描下方二维码
















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











