







Spark支持spark-shell、spark-sql、spark-submit多种使用方式,但最终调用的代码都是通过SparkSubmit进行提交,上一篇介绍到spark-submit的示例:
# spark本地模式提交作业
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local
/path/to/examples.jar \
1000下面就来分析下spark-submit提交作业的整个流程。
1. spark-submit脚本分析
spark-submit脚本利用spark-class调用SparkSubmit作为程序主类:
#spark-submit.sh
#!/usr/bin/env bash
#判断是否配置${SPARK_HOME}变量,没有配置则执行find-spark-home脚本进行设置
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
# 调用SparkSubmit类,并携带所有参数
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
spark-submit提交作业之前,先对SPARK_HOME变量进行判断,如果没有设置会调用find-spark-home脚本根据当前spark软件包目录进行配置。
# find-spark-home.sh
#!/usr/bin/env bash
# Attempts to find a proper value for SPARK_HOME. Should be included using "source" directive.
FIND_SPARK_HOME_PYTHON_SCRIPT="$(cd "$(dirname "$0")"; pwd)/find_spark_home.py"
# Short circuit if the user already has this set.
if [ ! -z "${SPARK_HOME}" ]; then
exit 0
elif [ ! -f "$FIND_SPARK_HOME_PYTHON_SCRIPT" ]; then
# If we are not in the same directory as find_spark_home.py we are not pip installed so we don't
# need to search the different Python directories for a Spark installation.
# Note only that, if the user has pip installed PySpark but is directly calling pyspark-shell or
# spark-submit in another directory we want to use that version of PySpark rather than the
# pip installed version of PySpark.
export SPARK_HOME="$(cd "$(dirname "$0")"/..; pwd)"
else
# We are pip installed, use the Python script to resolve a reasonable SPARK_HOME
# Default to standard python interpreter unless told otherwise
if [[ -z "$PYSPARK_DRIVER_PYTHON" ]]; then
PYSPARK_DRIVER_PYTHON="${PYSPARK_PYTHON:-"python"}"
fi
export SPARK_HOME=$($PYSPARK_DRIVER_PYTHON "$FIND_SPARK_HOME_PYTHON_SCRIPT")
fi
然后调用spark-class构造作业提交命令,最终还是以java方式提交:
#!/usr/bin/env bash
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# 使用load-spark-env.sh脚本加载环境变量,设置日志、hadoop配置、JVM、classpath等
. "${SPARK_HOME}"/bin/load-spark-env.sh
# 获取java路径,如果没有配置JAVA_HOME,则通过java命令获取,否则报错
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# 设置SPARK_JARS_DIR,如果PARK_HOME不存在jars目录,则设置为assembly目录.
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
#如果SPARK_JARS_DIR目录不存在并且未设置SPARK_TESTING或SPARK_SQL_TESTING进行报错。存在的话则#设置程序启动LAUNCH_CLASSPATH
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
# For tests
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi
# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
#
# The exit code of the launcher is appended to the output, so the parent shell removes it from the
# command array and checks the value to see if the launcher succeeded.
# 构造java启动命令,加载LAUNCH_CLASSPATH下jar包,并以org.apache.spark.launcher.Main为主类,携带spark-submit中参数
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
# 关闭posix模式,因为它不允许进程替换
set +o posix
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
# 某些JVM故障会导致将错误打印到stdout(而不是stderr),这会导致解析启动器输出的代码变得混乱。在这些情况下,检查退出代码是否为整数,如果不是,则将其作为特殊错误案例处理。
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fi
if [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fi
CMD=("${CMD[@]:0:$LAST}")
# 最终构造出来的提交命令为:env LD_LIBRARY_PATH=/usr/hdp/current/hadoop-client/lib/native:/usr/hdp/current/hadoop-client/lib/native/Linux-amd64-64 /usr/local/jdk/bin/java -cp /usr/hdp/current/spark2-client/conf/:/usr/hdp/current/spark2-client/jars/*:/usr/hdp/current/spark2-client/jars/../hive/*:/usr/hdp/3.0.1.0-187/hadoop/conf/:/usr/hdp/current/spark2-thriftserver/jars/ranger-spark-plugin-impl/*:/usr/hdp/current/spark2-thriftserver/jars/servlet-api/*:/usr/hdp/3.0.1.0-187/spark2/jars/dragon_jars/* -Xmx1g -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5055 org.apache.spark.deploy.SparkSubmit --master local --conf spark.driver.extraJavaOptions=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5055 --class org.apache.spark.examples.SparkPi spark-examples_2.11-2.4.0-cdh6.2.0.jar
exec "${CMD[@]}"
2. SparkSubmit调用流程
作业提交后最终调用org.apache.spark.deploy.SparkSubmit为主类,通过调试也可以看到Spark程序入口为SparkSubmit的main方法: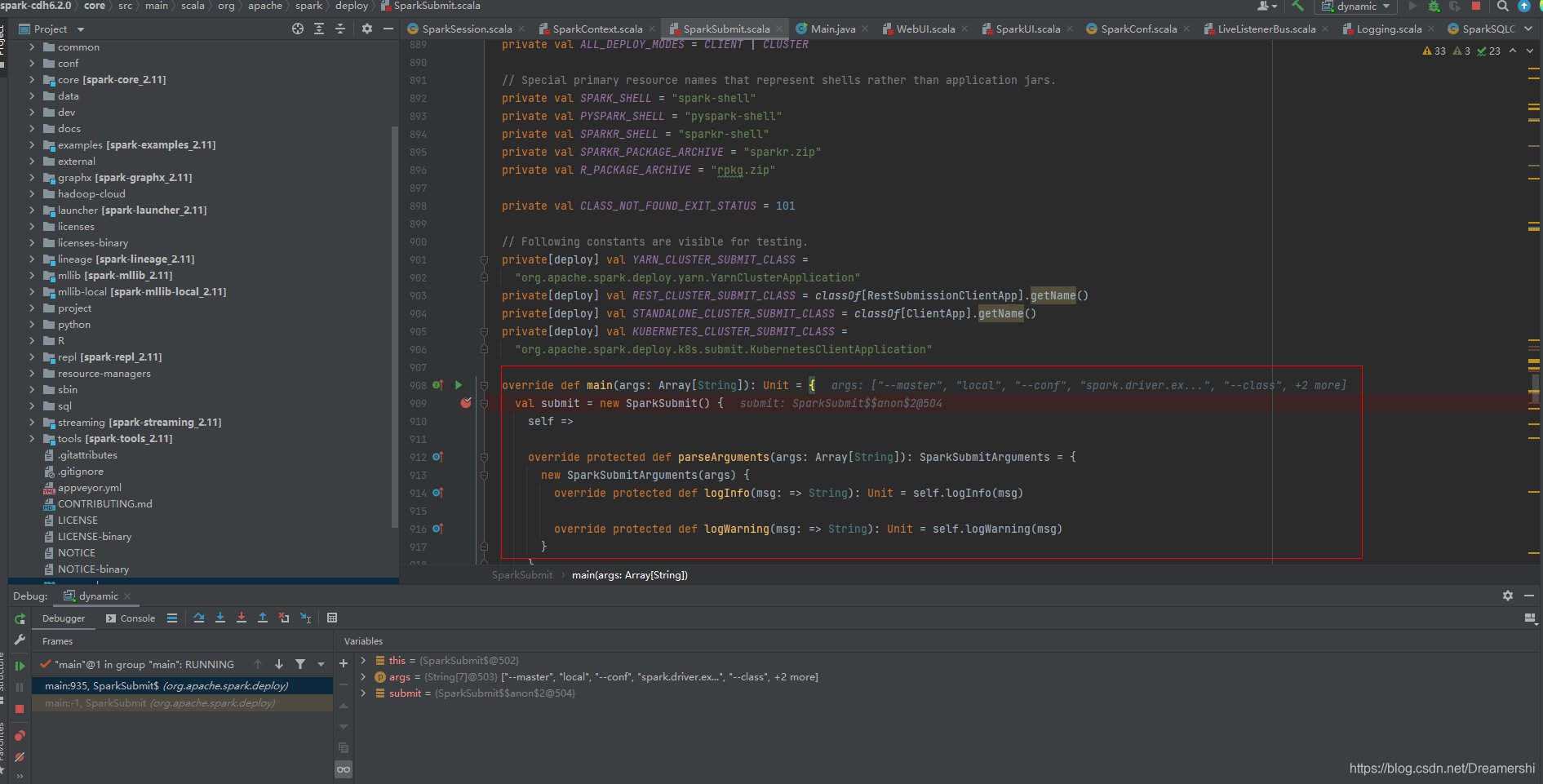
进入main方法后,调用构造SparkSubmit对象,调用doSubmit方法,内部会调用loadEnvironmentArguments把环境变量中参数构造为SparkSubmitArguments对象,携带master、driverMemory、executorMemory等信息:
def doSubmit(args: Array[String]): Unit = {
// 提交之前初始化日志记录并跟踪在应用程序启动之前是否需要重置日志记录,默认使用log4j-defaults.properties文件日志配置。
val uninitLog = initializeLogIfNecessary(true, silent = true)
// 解析参数构造为SparkSubmitArguments对象,内部调用loadEnvironmentArguments,解析出master、driverMemory、executorMemory等运行参数
val appArgs = parseArguments(args)
if (appArgs.verbose) {
logInfo(appArgs.toString)
}
// 根据不同操作类型,执行具体操作。spark-submit支持--kill,--status,--status几种参数类型,其中--kill,--status都是standalone模式下使用,用来杀掉spark作业和查询状态
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
// 加载环境变量参数,这里参数可以是通过sparksumit命令--方式携带,也可以在spark-default.conf配置文件中配置,对应参数名入下代码中所示
private def loadEnvironmentArguments(): Unit = {
master = Option(master)
.orElse(sparkProperties.get("spark.master"))
.orElse(env.get("MASTER"))
.orNull
driverExtraClassPath = Option(driverExtraClassPath)
.orElse(sparkProperties.get("spark.driver.extraClassPath"))
.orNull
driverExtraJavaOptions = Option(driverExtraJavaOptions)
.orElse(sparkProperties.get("spark.driver.extraJavaOptions"))
.orNull
driverExtraLibraryPath = Option(driverExtraLibraryPath)
.orElse(sparkProperties.get("spark.driver.extraLibraryPath"))
.orNull
driverMemory = Option(driverMemory)
.orElse(sparkProperties.get("spark.driver.memory"))
.orElse(env.get("SPARK_DRIVER_MEMORY"))
.orNull
driverCores = Option(driverCores)
.orElse(sparkProperties.get("spark.driver.cores"))
.orNull
executorMemory = Option(executorMemory)
.orElse(sparkProperties.get("spark.executor.memory"))
.orElse(env.get("SPARK_EXECUTOR_MEMORY"))
.orNull
executorCores = Option(executorCores)
.orElse(sparkProperties.get("spark.executor.cores"))
.orElse(env.get("SPARK_EXECUTOR_CORES"))
.orNull
totalExecutorCores = Option(totalExecutorCores)
.orElse(sparkProperties.get("spark.cores.max"))
.orNull
name = Option(name).orElse(sparkProperties.get("spark.app.name")).orNull
jars = Option(jars).orElse(sparkProperties.get("spark.jars")).orNull
files = Option(files).orElse(sparkProperties.get("spark.files")).orNull
pyFiles = Option(pyFiles).orElse(sparkProperties.get("spark.submit.pyFiles")).orNull
ivyRepoPath = sparkProperties.get("spark.jars.ivy").orNull
ivySettingsPath = sparkProperties.get("spark.jars.ivySettings")
packages = Option(packages).orElse(sparkProperties.get("spark.jars.packages")).orNull
packagesExclusions = Option(packagesExclusions)
.orElse(sparkProperties.get("spark.jars.excludes")).orNull
repositories = Option(repositories)
.orElse(sparkProperties.get("spark.jars.repositories")).orNull
deployMode = Option(deployMode)
.orElse(sparkProperties.get("spark.submit.deployMode"))
.orElse(env.get("DEPLOY_MODE"))
.orNull
numExecutors = Option(numExecutors)
.getOrElse(sparkProperties.get("spark.executor.instances").orNull)
queue = Option(queue).orElse(sparkProperties.get("spark.yarn.queue")).orNull
keytab = Option(keytab).orElse(sparkProperties.get("spark.yarn.keytab")).orNull
principal = Option(principal).orElse(sparkProperties.get("spark.yarn.principal")).orNull
dynamicAllocationEnabled =
sparkProperties.get("spark.dynamicAllocation.enabled").exists("true".equalsIgnoreCase)
// Try to set main class from JAR if no --class argument is given
if (mainClass == null && !isPython && !isR && primaryResource != null) {
val uri = new URI(primaryResource)
val uriScheme = uri.getScheme()
uriScheme match {
case "file" =>
try {
Utils.tryWithResource(new JarFile(uri.getPath)) { jar =>
// Note that this might still return null if no main-class is set; we catch that later
mainClass = jar.getManifest.getMainAttributes.getValue("Main-Class")
}
} catch {
case _: Exception =>
error(s"Cannot load main class from JAR $primaryResource")
}
case _ =>
error(
s"Cannot load main class from JAR $primaryResource with URI $uriScheme. " +
"Please specify a class through --class.")
}
}
// Global defaults. These should be keep to minimum to avoid confusing behavior.
master = Option(master).getOrElse("local[*]")
// In YARN mode, app name can be set via SPARK_YARN_APP_NAME (see SPARK-5222)
if (master.startsWith("yarn")) {
name = Option(name).orElse(env.get("SPARK_YARN_APP_NAME")).orNull
}
// Set name from main class if not given
name = Option(name).orElse(Option(mainClass)).orNull
if (name == null && primaryResource != null) {
name = new File(primaryResource).getName()
}
// Action should be SUBMIT unless otherwise specified
action = Option(action).getOrElse(SUBMIT)submit方法会对环境变量进行解析,获取到具体执行类的类名、参数和classpath等信息,然后调用runMain方法通过反射机制调起具体的执行类:
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
// 第一步通过设置适当的类路径、系统属性和应用程序参数来准备启动环境,以便基于集群管理器和部署模式运行子主类。
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
// 使用这个启动环境来调用子主类的main方法
def doRunMain(): Unit = {
if (args.proxyUser != null) {
// 作业提交时如果使用--proxy-user设置代理用户,则使用代理用户运行作业
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
error(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
} private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sparkConf: SparkConf,
childMainClass: String,
verbose: Boolean): Unit = {
// verbose模式下打印出详细的类名、参数、classpath、默认配置信息等
if (verbose) {
logInfo(s"Main class:\n$childMainClass")
logInfo(s"Arguments:\n${childArgs.mkString("\n")}")
// sysProps may contain sensitive information, so redact before printing
logInfo(s"Spark config:\n${Utils.redact(sparkConf.getAll.toMap).mkString("\n")}")
logInfo(s"Classpath elements:\n${childClasspath.mkString("\n")}")
logInfo("\n")
}
// 判断参数spark.driver.userClassPathFirst是否设置,默认为false。设置为true时,构造一种可变类加载器ChildFirstURLClassLoader,在加载类和资源时,它优先于父类加载器提供自己的URL。
val loader =
if (sparkConf.get(DRIVER_USER_CLASS_PATH_FIRST)) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
//加载childClasspath下jar包
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
var mainClass: Class[_] = null
try {
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
logWarning(s"Failed to load $childMainClass.", e)
if (childMainClass.contains("thriftserver")) {
logInfo(s"Failed to load main class $childMainClass.")
logInfo("You need to build Spark with -Phive and -Phive-thriftserver.")
}
throw new SparkUserAppException(CLASS_NOT_FOUND_EXIT_STATUS)
case e: NoClassDefFoundError =>
logWarning(s"Failed to load $childMainClass: ${e.getMessage()}")
if (e.getMessage.contains("org/apache/hadoop/hive")) {
logInfo(s"Failed to load hive class.")
logInfo("You need to build Spark with -Phive and -Phive-thriftserver.")
}
throw new SparkUserAppException(CLASS_NOT_FOUND_EXIT_STATUS)
}
// 判断程序主类是否是SparkApplication的子类,不是则构造为JavaMainApplication类,JavaMainApplication也是SparkApplication子类,相当于做一层封装,通过SparkApplication的start方法对mainclass进行反射
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
logWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
new JavaMainApplication(mainClass)
}
@tailrec
def findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
try {
//调用SparkApplicationstart方法进行反射调用,下面两行为反射代码
app.start(childArgs.toArray, sparkConf)
//val mainMethod = klass.getMethod("main", new Array[String](0).getClass)
//mainMethod.invoke(null, args)
} catch {
case t: Throwable =>
throw findCause(t)
}
}至此通过spark-submit提交Spark Application程序步骤就完成了,再往下就是进入到具体应用程序代码中,本例中实现SparkPi的计算,首先构造SparkSession(内部进行构建SparkContext),然后通过spark提供的transform和action算子实现具体的算法并提交执行。
object SparkPi {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("Spark Pi")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}3. SparkSession构造
在Spark的早期版本开发Spark程序时,通过SparkContext作为入口。由于RDD是Spark中重要的API,然而它的创建和操作得使用sparkContext提供的API;对于RDD之外的其他东西,我们需要使用其他的Context。比如对于流处理来说,我们得使用StreamingContext;对于SQL得使用SqlContext;而对于hive得使用HiveContext。然而DataSet和Dataframe提供的API逐渐称为新的标准API,我们需要一个切入点来构建它们,因此在 Spark 2.0中引入了一个新的切入点(entry point):SparkSession。
SparkSession实质上是SQLContext和HiveContext以及StreamingContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
SparkSession的设计遵循了工厂设计模式(factory design pattern),Spark程序中首先使用SparkSession.builder对象进行一系列配置,包括appName(设置程序名)、master(运行模式:local、yarn、standalone等)、enableHiveSupport(开启hive元数据,即使用HiveContext)、withExtensions(将自定义扩展注入[[SparkSession]]。这允许用户添加分析器规则、优化器规则、规划策略或自定义解析器),还提供config方法,设置自定义参数等。
getOrCreate方法则初始化具体的SparkCentext(具体介绍在下期)、SparkSession对象等:
def getOrCreate(): SparkSession = synchronized {
assertOnDriver()
// 从当前Session线程中获取Session对象,如果仍active则只需要重新加载下配置即可.
var session = activeThreadSession.get()
if ((session ne null) && !session.sparkContext.isStopped) {
options.foreach { case (k, v) => session.sessionState.conf.setConfString(k, v) }
if (options.nonEmpty) {
logWarning("Using an existing SparkSession; some configuration may not take effect.")
}
return session
}
// 加锁保证defaultsession只设置一次.
SparkSession.synchronized {
// 如果当前线程没有活动会话,从全局会话获取
session = defaultSession.get()
if ((session ne null) && !session.sparkContext.isStopped) {
options.foreach { case (k, v) => session.sessionState.conf.setConfString(k, v) }
if (options.nonEmpty) {
logWarning("Using an existing SparkSession; some configuration may not take effect.")
}
return session
}
// 没有活动或全局默认会话。创建一个新的.这里通过sparkContext进行创建
val sparkContext = userSuppliedContext.getOrElse {
val sparkConf = new SparkConf()
options.foreach { case (k, v) => sparkConf.set(k, v) }
// set a random app name if not given.
if (!sparkConf.contains("spark.app.name")) {
sparkConf.setAppName(java.util.UUID.randomUUID().toString)
}
//创建sparkcontext对象,最终会调用new Context(SparkConf)进行构造
SparkContext.getOrCreate(sparkConf)
// Do not update `SparkConf` for existing `SparkContext`, as it's shared by all sessions.
}
applyExtensions(
sparkContext.getConf.get(StaticSQLConf.SPARK_SESSION_EXTENSIONS).getOrElse(Seq.empty),
extensions)
session = new SparkSession(sparkContext, None, None, extensions)
options.foreach { case (k, v) => session.initialSessionOptions.put(k, v) }
setDefaultSession(session)
setActiveSession(session)
//将成功实例化的上下文注册到singleton。这应该在类定义的末尾,这样只有在实例的构造中没有异常时,才会更新单例。
sparkContext.addSparkListener(new SparkListener {
override def onApplicationEnd(applicationEnd: SparkListenerApplicationEnd): Unit = {
defaultSession.set(null)
}
})
}
return session
}
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









