








 本文深入解析Spark在Yarn上的任务提交流程,从SparkSubmit启动到Executor运行,涉及YarnClusterApplication、ApplicationMaster和YarnCoarseGrainedExecutorBackend等关键角色。了解任务提交的核心步骤,包括客户端创建、AM申请资源、Executor注册等。
本文深入解析Spark在Yarn上的任务提交流程,从SparkSubmit启动到Executor运行,涉及YarnClusterApplication、ApplicationMaster和YarnCoarseGrainedExecutorBackend等关键角色。了解任务提交的核心步骤,包括客户端创建、AM申请资源、Executor注册等。
Spark源码之任务提交流程
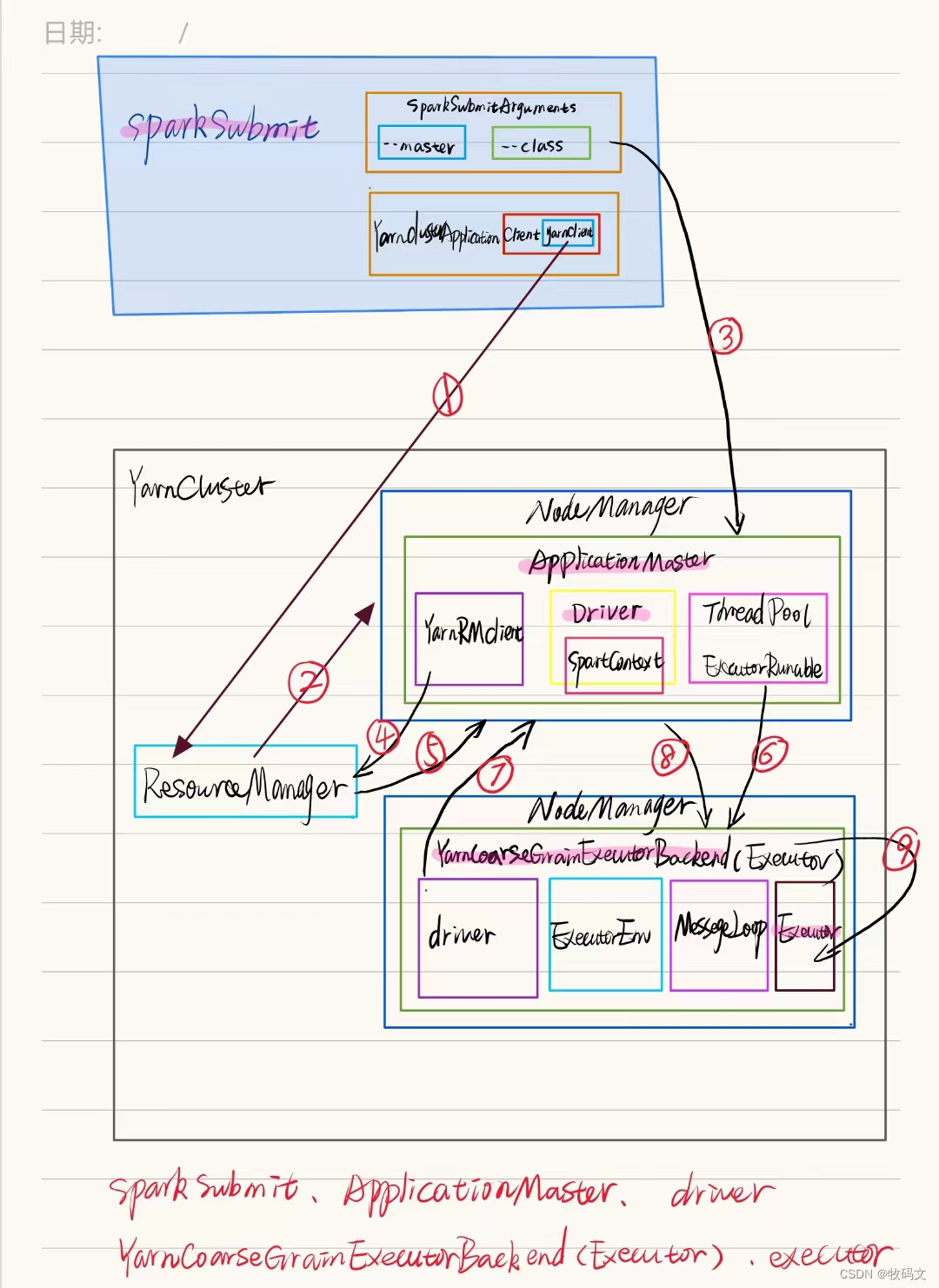
Spark任务的提交大概可以看作是,根据spark提交参数创建一个client,由client创建一个applicationMaster,Master创建一个YarnCoarseGrainedExecutorBackend,driver在applicationMaster中,Executor在YarnCoarseGrainedExecutorBackend中。笼统的看可以是这样,中间还有很多东西。
一、流程
-
执行脚本提交任务,实际是启动一个 SparkSubmit 的 JVM 进程;
-
SparkSubmit 类中的 main 方法反射调用 YarnClusterApplication 的 main 方法;
-
YarnClusterApplication 创建 Yarn 客户端,然后向 Yarn 服务器发送执行指令:bin/java ApplicationMaster;
-
Yarn 框架收到指令后会在指定的 NM 中启动 ApplicationMaster;
-
ApplicationMaster 启动 Driver 线程,执行用户的作业;
-
AM 向 RM 注册,申请资源;
-
获取资源后 AM 向 NM 发送指令:bin/java YarnCoarseGrainedExecutorBackend;
-
CoarseGrainedExecutorBackend 进程会接收消息,跟 Driver 通信,注册已经启动的 Executor;然后启动计算对象 Executor 等待接收任务
-
Driver 线程继续执行完成作业的调度和任务的执行。
-
Driver 分配任务并监控任务的执行
二、流程图
三、任务提交核心
主要涉及到几个核心的类:SparkSubmit、ApplicationMaster 、YarnCoarseGrainedExecutorBackend
SparkSubmit调用 YarnClusterApplication实例化一个Client,由Client创建一个ApplicationMaster ,ApplicationMaster 向RM申请资源之后调用方法创建一个YarnCoarseGrainedExecutorBackend。Driver在ApplicationMaster 中,Executor在YarnCoarseGrainedExecutorBackend中
SparkSubmit、ApplicationMaster 和 YarnCoarseGrainedExecutorBackend是独立的进程;Driver 是独立的线程;Executor 和 YarnClusterApplication 是对象。


















 1578
1578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











