







题目
- 一.队列数据结构的封装
- 二.最近请求次数(队列的应用)
- 三.常见 python 面试题目整理
- 1.列举 Python2 和 Python3 的区别?
- 2.简述 Python 的深浅拷贝以及应用场景?
- 3.能否解释一下 *args 和 **kwargs?
- 4.简述 生成器、迭代器、可迭代对象 以及应用场景?
- 5.请说明 yield 关键字的工作机制。
- 6.请简单谈谈装饰器的作用和功能。
- 7.Python 中如何读取大数据的文件内容?
- 8.Python 中的模块和包是什么?
- 9.python 是如何进行内存管理的(python 是如何实现垃圾回收机制的)?
- 10.谈谈你对面向对象的理解?
- 11.Python 面向对象中的继承有什么特点?
- 12.面向对象中 super 的作用?
- 13.面向对象深度优先和广度优先是什么, 并说明应用场景?
- 14.请简述__init__和__len__这两个魔术方法的作用
一.队列数据结构的封装
队列类。队列(queue)是具有先进先出(FIFO)特性的数据结构。一个队
列就像是一行队伍,数据从前端被移除,从后端被加入。这个类必须支持
下面几种方法

并实现下面的功能:

# 队列
class Queue(object):
def __init__(self):
self.__queue = []
def __len__(self):
return len(self.__queue) # 这个魔术方法必须返回一个整数
def enqueue(self, i):
self.__queue.append(i)
return '%s 进队成功!' % i
def dequeue(self):
if not self.isEmpty():
i = self.__queue.pop(0)
return '%s 出队成功!' % i
return 'error'
def first(self):
return self.__queue[0]
def isEmpty(self):
if len(self.__queue):
return False
else:
return True
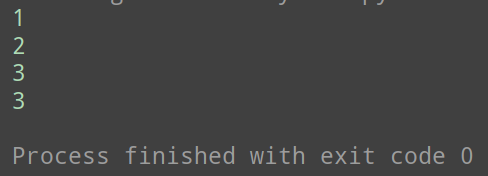
if __name__ == '__main__':
q = Queue()
print(q.enqueue(5))
print(q.enqueue(3))
print(len(q))
print(q.dequeue())
print(q.isEmpty())
print(q.dequeue())
print(q.isEmpty())
print(q.dequeue())
print(q.enqueue(7))
print(q.enqueue(9))
print(q.first())
print(q.enqueue(4))
print(len(q))
print(q.dequeue())

二.最近请求次数(队列的应用)

class RecentCounter:
def __init__(self):
self.pings = list()
def ping(self, t):
self.pings.append(t)
while self.pings[0] < t - 3000:
self.pings.pop(0)
return len(self.pings)
if __name__ == '__main__':
r = RecentCounter()
print(r.ping(1))
print(r.ping(100))
print(r.ping(3001))
print(r.ping(3002))
三.常见 python 面试题目整理
1.列举 Python2 和 Python3 的区别?
答:
编码
Py3.X源码文件默认使用utf-8编码,这就使得以下代码是合法的:
>>> 中国 = ‘china’
>>>print(中国)
china
语法
1)关键词加入as 和with,还有True,False,None
2)整型除法返回浮点数,要得到整型结果,使用//
3)去除print语句,加入print()函数实现相同的功能。同样的还有 exec语句,已经改为exec()函数
例如:
2.X: print "The answer is", 2*2
3.X: print("The answer is", 2*2)
2.X: print x, # 使用逗号结尾禁止换行
3.X: print(x, end=" ") # 使用空格代替换行
2.X: print # 输出新行
3.X: print() # 输出新行
2.X: print >>sys.stderr, "fatal error"
3.X: print("fatal error", file=sys.stderr)
2.X: print (x, y) # 输出repr((x, y))
3.X: print((x, y)) # 不同于print(x, y)!
4)改变了顺序操作符的行为,例如x<y,当x和y类型不匹配时抛出TypeError而不是返回随即的 bool值
5)输入函数改变了,删除了raw_input,用input代替:
2.X:guess = int(raw_input('Enter an integer : ')) # 读取键盘输入的方法
3.X:guess = int(input('Enter an integer : '))
6)去除元组参数解包。不能
def(a, (b, c)):
pass
这样定义函数了
7)扩展的可迭代解包。在Py3.X 里,a, b, *rest = seq和 *rest, a = seq都是合法的,只要求两点:- -
- rest是list
- 对象和seq是可迭代的。
8)新的super(),可以不再给super()传参数
>>> class C(object):
def __init__(self, a):
print('C', a)
>>> class D(C):
def __init(self, a):
super().__init__(a) # 无参数调用super()
>>> D(8)
C 8
<__main__.D object at 0x00D7ED90>
9)支持class decorator。用法与函数decorator一样:
>>> def foo(cls_a):
def print_func(self):
print('Hello, world!')
cls_a.print = print_func
return cls_a
>>> @foo
class C(object):
pass
>>> C().print()
Hello, world!
class decorator可以用来玩玩狸猫换太子的大把戏。更多请参阅PEP 3129
数据类型
1)Py3.X去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
2)新增了bytes类型,对应于2.X版本的八位串,定义一个bytes字面量的方法如下:
>>> b = b'china'
>>> type(b)
<type 'bytes'>
str对象和bytes对象可以使用.encode() (str -> bytes) or .decode() (bytes -> str)方法相互转化。
>>> s = b.decode()
>>> s
'china'
>>> b1 = s.encode()
>>> b1
b'china'
3)dict的.keys()、.items 和.values()方法返回迭代器,而之前的iterkeys()等函数都被废弃。同时去掉的还有 dict.has_key(),用 in替代
面向对象
1)引入抽象基类(Abstraact Base Classes,ABCs)。
2)容器类和迭代器类被ABCs化,所以cellections模块里的类型比Py2.5多了很多。
>>> import collections
>>> print('\n'.join(dir(collections)))
Callable
Container
Hashable
ItemsView
Iterable
Iterator
KeysView
Mapping
MappingView
MutableMapping
MutableSequence
MutableSet
NamedTuple
Sequence
Set
Sized
ValuesView
__all__
__builtins__
__doc__
__file__
__name__
_abcoll
_itemgetter
_sys
defaultdict
deque
另外,数值类型也被ABCs化。关于这两点,请参阅 PEP 3119和PEP 3141。
3)迭代器的next()方法改名为__next__(),并增加内置函数next(),用以调用迭代器的__next__()方法
4) 在Python 2及以前的版本中,由任意内置类型派生出的类,都属于“新式类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类,则称之为“经典类”。
在Python 3.x之后的版本,因为所有的类都派生自内置类型object(即使没有显示的继承object类型),即所有的类都是“新式类”
5) 多继承时
- 经典类多继承搜索顺序(深度优先算法):先深入继承树左侧查找,然后再返回,开始查找右侧。
- 新式类多继承搜索顺序(广度优先算法):先在水平方向查找,然后再向上查找。
模块变动
移除了cPickle模块,使用pickle模块代替。
其它
1)xrange() 改名为range(),要想使用range()获得一个list,必须显式调用:
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
2)zip()、map()和filter()都返回迭代器。而apply()、 callable()、coerce()、 execfile()、reduce()和reload()函数都被去除了
3)如果x < y的不能比较,抛出TypeError异常。2.x版本是返回伪随机布尔值的
4)file类被废弃,在Py2.5中:
>>> file
<type 'file'>
在Py3.X中:
>>> file
Traceback (most recent call last):
File "<pyshell#120>", line 1, in <module>
file
NameError: name 'file' is not defined
2.简述 Python 的深浅拷贝以及应用场景?
答:
浅拷贝:
仅仅拷贝数据集合的第一层数据
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n3 = copy.copy(n1)

深拷贝:
拷贝数据集合的所有层
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n4 = copy.deepcopy(n1)

所以对于只有一层的数据集合来说深浅拷贝的意义是一样的,比如字符串,数字,还有仅仅一层的字典、列表、元祖等。
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
应用场景:
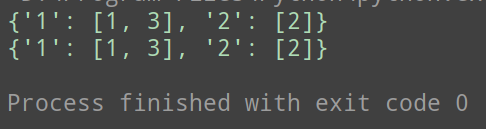
import copy
d = {
'1': [1],
'2': [2]
}
newD = copy.copy(d)
newD['1'].append(3)
print(newD)
print(d)
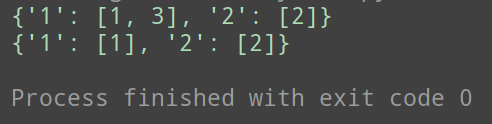
import copy
d = {
'1': [1],
'2': [2]
}
newD = copy.deepcopy(d)
newD['1'].append(3)
print(newD)
print(d)
分析原因:
深拷贝的时候python将字典的所有数据在内存中新建了一份,所以如果你修改新的模版的时候老模版不会变。相反,在浅copy 的时候,python仅仅将最外层的内容在内存中新建了一份出来,字典第二层的列表并没有在内存中新建,所以你修改了新模版,默认模版也被修改了。
3.能否解释一下 *args 和 **kwargs?
答:
可变参数:
*args 作为形参时可给该函数传入多个参数,传入的参数以元组格式保存
关键字参数:
kwargs 作为形参时可给该函数传入多个关键字参数,格式为key=value,传入的参数以字典格式保存
另外:
*args 和 **kwargs也可以用来对元组和字典解包
4.简述 生成器、迭代器、可迭代对象 以及应用场景?
答:
生成器
在Python中,一边循环一边计算的机制,称为生成器
- 列表生成式的改写。 []改成()
- yield关键字
迭代器
可以调用next()方法
可迭代对象
可以使用for循环遍历
5.请说明 yield 关键字的工作机制。
答:
一个函数包含yield关键字,那么这个函数就是一个生成器
使用next()方法会让函数运行到yield的地方停止,下一次调用next()方法,从停止的地方就行执行。
另外还有send()方法可以给yield前传值,但是调用send()方法必须激活生成器,也就是必须先调用一次next()方法或者传入一个None来激活生成器
方法1:
>>> def a():
while True:
b = yield 1
print(b)
>>> x = a()
>>> next(x)
1
>>> next(x)
None
1
>>> x.send(2)
2
1
方法2:
>>> def a():
while True:
b = yield 1
print(b)
>>> x = a()
>>> x.send(None)
1
>>> x.send(2)
2
1
6.请简单谈谈装饰器的作用和功能。
答:
作用
可以让其他函数在不需要修改代码的前提下增加额外的功能
功能
插入日志、性能测试、事务处理、缓存、权限校验等
7.Python 中如何读取大数据的文件内容?
答:
1)指定每次读取的长度
2)逐行读取
8.Python 中的模块和包是什么?
答:
模块是非常简单的Python文件,单个Python文件就是一个模块,两个文件就是两个模块。
包将有联系的模块组织在一起,有效避免模块名称冲突问题,让应用组织结构更加清晰。
9.python 是如何进行内存管理的(python 是如何实现垃圾回收机制的)?
答:
python有对象池:
小整数对象池
1). 整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池,避免为整数频繁申请和销毁内存空间。
2). Python对小整数的定义是[-5,257) 这些整数对象是提前建立好的,不会被垃圾回收。在一个Python的程序中,所有位于这个范围内的整数使用的都是同一个对象.
大整数对象池
每一个大整数,均创建一个新的对象。
intern机制
- 它通过维护一个字符串常量池(string intern pool),从而试图只保存唯一的字符串对象,达到既高效又节省内存地处理字符串的目的。
- 在创建一个新的字符串对象后,Python 先比较常量池中是否有相同的对象(interned),有的话则将指针指向已有对象,并减少新对象的指针,新对象由于没有引用计数,就会被垃圾回收机制回收掉,释放出内存。
- 字符串(含有空格),不可修改,没开启intern机制,不共用对象,引用计数为0,销毁。
回收机制:
引用计数,标记清除,分代收集,可以使用gc模块来管理
10.谈谈你对面向对象的理解?
答:
面向对象是按人们认识客观世界的系统思维方式,采用基于对象(实体)的概念建立模型,模拟客观世界分析、设计、实现软件的办法。通过面向对象的理念使计算机软件系统能与现实世界中的系统一一对应。
特性:抽象 封装 继承 多态
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
缺点:性能比面向过程低
11.Python 面向对象中的继承有什么特点?
答:
子类可以继承父类的属性及方法,也可以通过相同的属性或方法名来重写自己的方法
12.面向对象中 super 的作用?
答:
直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序、重复调用等种种问题。
super().方法名()
13.面向对象深度优先和广度优先是什么, 并说明应用场景?
答:
多继承时
深度优先是,从初始点出发,不断向前走,如果碰到死路了,就往回走一步,尝试另一条路,直到发现了目标
广度优先是,从初始点出发,把所有可能的路径都走一遍,如果里面没有目标位置,则尝试把所有两步能够到的位置都走一遍,看有没有目标位置;如果还不行,则尝试所有三步可以到的位置。
14.请简述__init__和__len__这两个魔术方法的作用
答:
__init__是构造方法,创建实例对象时会默认执行,一般用来传入参数,用传入的参数来初始化该实例
__len__返回个数
例如:
有一个实例对象S
调用len(S)方法时会执行S.__len__()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









