







本文摘要:

实例
对这样一个不规则excel进行数据处理
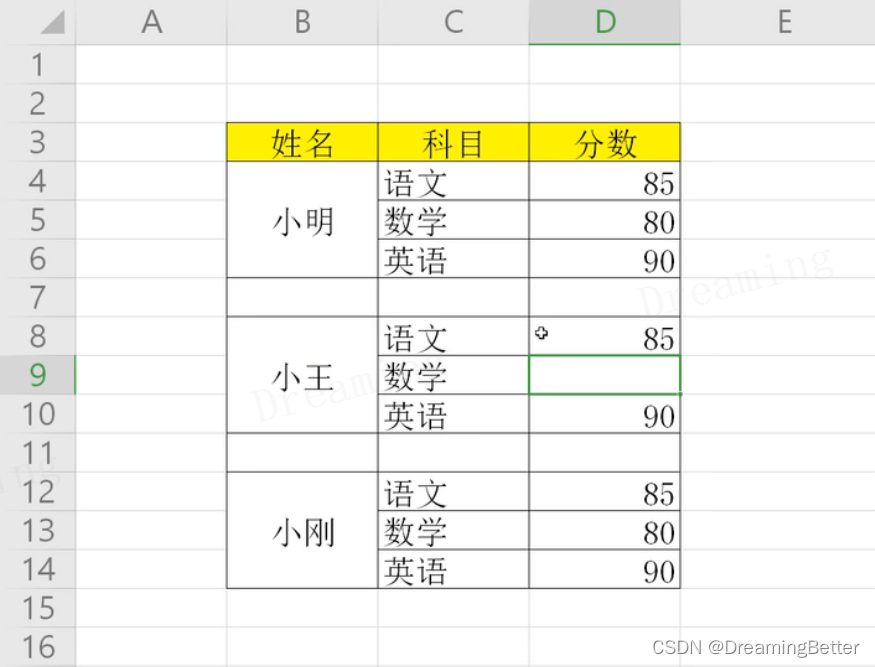
本代码主要演示各个功能的使用和解决思路,并不是完整程序。
import pandas as pd
studf = pd.read_excel('xx.xlsx', skiprows=2) # 读取时跳过前两行
# 检测空值
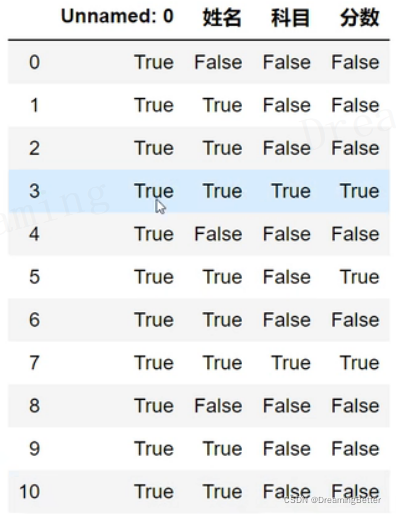
studf.isnull()
检测空值的返回结果
# 单列检测空值
studf['分数'].isnull()
# 与isnull相反,非空为True
studf['分数'].notnull()
# 例如筛选没有空分数的行
studf.loc[studf['分数'].notnull(), :]
# 删除全是空值的列
studf.dropna(axis='columns', how='all', inplace=True)
# 删除全是空值的行
studf.dropna(axis='index', how='all', inplace=True)
# 将分数列为空的值填充为0
studf.fillna({'分数': 0})
# 等同于
studf.loc[:, '分数'] = studf['分数'].fillna(0)
# 将姓名缺失值填充,用前面的有效值填充,ffill:forward fill
studf.loc[:, '姓名'] = studf['姓名'].fillna(method='ffill')
# 保存数据,index=False表示不保留DataFrame自动生成的索引列
studf.to_excel('xxx.xlsx', index=False)
题外话
如何在原dataframe上创建空列
import numpy as np
import pandas as pd
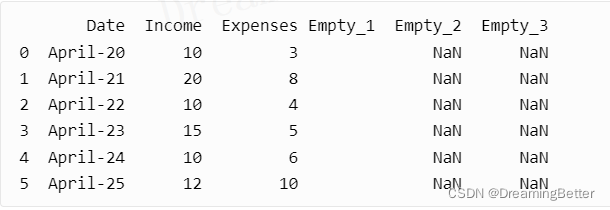
df["Empty_1"] = ""
df["Empty_2"] = np.nan
df['Empty_3'] = pd.Series()
创建结果
*此文仅为个人笔记


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









