







大数据的核心思想是:既然数据是庞大的,而程序要比数据小的多,将数据输入给程序是不划算的。那么就反其道而行,将程序分发到数据所在的地方进行计算,也就是所谓的移动计算比移动数据更划算。
移动计算程序到数据所在的位置进行计算是如何实现的呢?
1.将待处理的大规模数据存储在服务器集群的所有服务器上,主要是用HDFS分布式文件系统,将文件分成很多块(block),以块为单位存储在集群的服务器上。
2.大数据引擎根据集群里不同服务器的计算能力,在每台服务器上启动若干分布式任务执行进程,这些进程会等待给他们分配执行任务。
3.使用大数据计算框架支持的编程模型进行编程,比如Hadoop的MapReduce编程模型,或者spark的RDD模型。应用程序编写好以后,将其打包,MapReduce和spark都是在JVM环境中运行,所以打包出来的是一个jar包。
4.用Hadoop或者spark的启动命令执行这个应用程序的jar包,首先执行引擎会解析程序要处理的数据输入路径,根据输入数据量的大小,将数据分成若干片(Split),每一个数据片都分配给一个任务执行进程去处理。
5.任务执行进程收到分配的任务后,检查自己是否有任务对应的程序包,如果没有就去下载程序包,下载以后通过反射的方式加载程序。走到这里,最重要的一步,也就是移动计算就完成了。
6.加载程序后,任务执行进程根据分配的数据片的文件地址和数据在文件内的偏移量读取数据,并把数据输入给应用程序相应的方法去执行,从而实现在分布式服务器集群中移动计算程序,对大规模数据进行并行处理的计算目标。
如果一个文件大小超过一张磁盘的大小,你该如何存储呢?
单机时代主要解决方案是RAID;分布式时代,主要解决方案是分布式文件系统。
大规模数据储存主要解决以下三个问题:
1.数据存储容量的问题:大数据要解决的是以PB计的数据计算问题
2.数据读写速度的问题:一般磁盘的连续读写速度为几十 MB,以这样的速度,几十 PB 的数据恐怕要读写到天荒地老。
3.数据可靠性的问题:磁盘大约是计算机设备中最容易损坏的设备了,如果磁盘损坏了,数据怎么办?
RAID(独立磁盘冗余阵列)技术是将多块普通磁盘组成一个阵列,共同对外提供服务。主要是为了改善磁盘的存储容量、读写速度,增强磁盘的可读性和容错能力。
常见的RAID技术有以下几种:
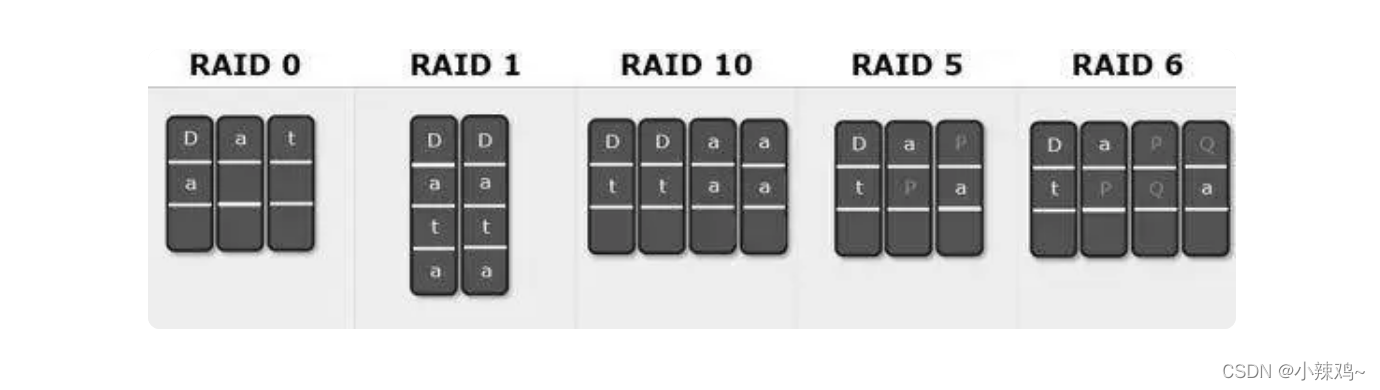
RAID 0是指将数据从内存缓冲区写入到磁盘时,根据磁盘数量将数据分为n份,这些数据同时并行的写入磁盘,使得数据整体写入的速度是一块磁盘的n倍。但是 RAID 0 不做数据备份,N 块磁盘中只要有一块损坏,数据完整性就被破坏,其他磁盘的数据也都无法使用了。
RAID 1是指将一份数据同时保存在两个磁盘上
RAID 10是指将所有的磁盘分成两份,在每一份磁盘里面,利用RAID 0技术并行读写,这样既可以提高可靠性,又可以改善性能。不过磁盘利用率较低。
一般情况下,一台服务器上很少出现同时损坏两块磁盘的情况,在只损坏一块磁盘的情况下,如果能利用其他磁盘的数据恢复损坏磁盘的数据,这样在保证可靠性和性能的同时,磁盘利用率也得到大幅提升。顺着这个思路,RAID 3 可以在数据写入磁盘的时候,将数据分成 N-1 份,并发写入 N-1 块磁盘,并在第 N 块磁盘记录校验数据,这样任何一块磁盘损坏(包括校验数据磁盘),都可以利用其他 N-1 块磁盘的数据修复。
相比 RAID 3,RAID 5 是使用更多的方案。RAID 5 和 RAID 3 很相似,但是校验数据不是写入第 N 块磁盘,而是螺旋式地写入所有磁盘中。这样校验数据的修改也被平均到所有磁盘上,避免 RAID 3 频繁写坏一块磁盘的情况。
如果数据需要很高的可靠性,在出现同时损坏两块磁盘的情况下(或者运维管理水平比较落后,坏了一块磁盘但是迟迟没有更换,导致又坏了一块磁盘),仍然需要修复数据,这时候可以使用 RAID 6。
RAID 6 和 RAID 5 类似,但是数据只写入 N-2 块磁盘,并螺旋式地在两块磁盘中写入校验信息(使用不同算法生成)。
HDFS依然是存储的王者
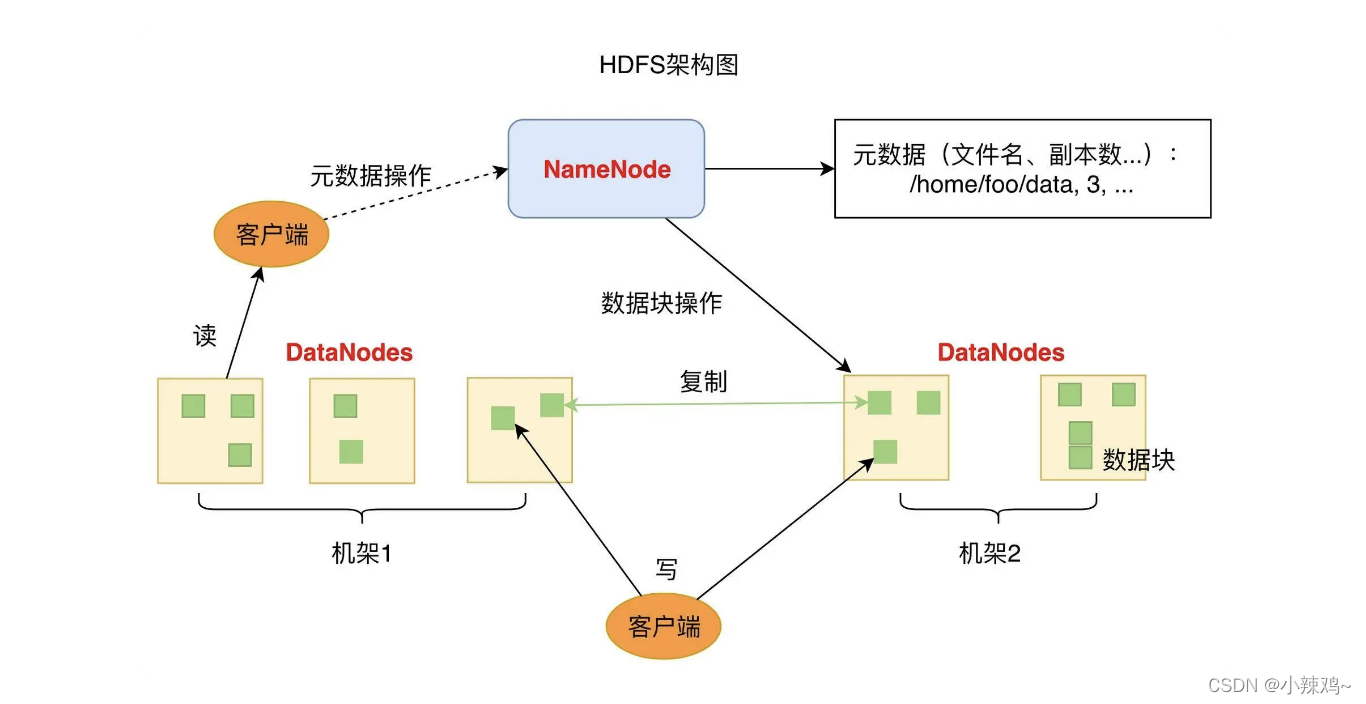
上图是HDFS的架构图,图中DataNode负责数据存储和读写操作,HDFS将数据分成若干数据块(Block),每一个DataNode存储一部分数据块,这样文件就分布存储在哼歌HDFS服务集群中。
NameNode负责整个分布式文件系统的元数据(MetaData)管理,也就是文件路径名,数据块的id以及存储位置等信息,相当于操作系统中文件分配表(FAT)的角色。
为什么说MapReduce既是编程模型又是计算框架?
我们只要遵循MapReduce编程模型编写业务处理逻辑代码,就可以运行在Hadoop分布式集群上,无需关心分布式计算是如何完成的。也就是说我们只需要关心业务逻辑,无需关系系统调用与运行环境,这和我们主流的开发方式是一致的。
MapReduce既是编程模型又是一个计算框架。也就是说开发人员必须基于MapReduce编程模型进行编程开发,然后将程序通过MapReduce计算框架分发到Hadoop集群中运行。我们先看一下作为编程模型的MapReduce。
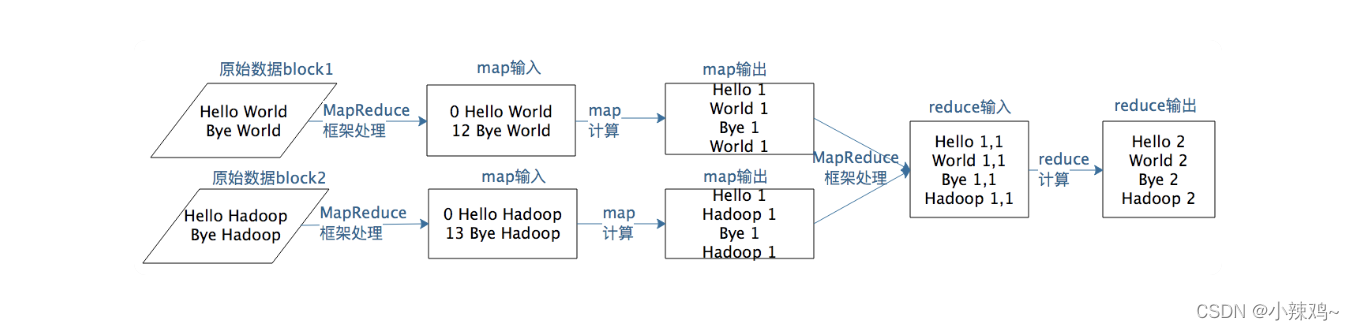
MapReduce编程模型将大数据计算过程分成Map和Reduce两个阶段,map主要输入是一对<key,value>值,经过map计算后输出一对<key,value>值;然后将相同的key合并,形成<key,value集合>,再将这个<key,value集合>输入reduce,经过计算输出0个或者多个<key,value>对。
上述过程存在两个问题需要解决:
1.如何为每个数据块分配一个Map计算任务,也就是代码是如何发送到数据块所在服务器的,发送后是如何启动的,启动后如何知道自己需要计算的数据在文件的什么位置。
2.处于不同服务器的map输出<Key,Value>,如何把相同的Key聚集在一起发送给Reduce任务进行处理的。
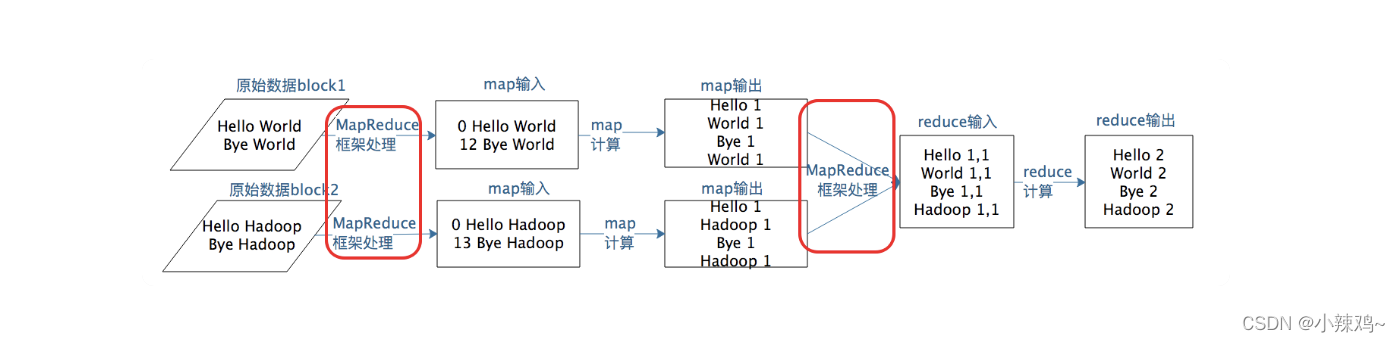
以上问题分别对应上图中红框的部分,它们分别是MapReduce作业启动和运行,以及MapReduce数据合并以及连接
MapReduce作业启动和运行机制
MapReduce运行过程涉及三类关键进程:
1.大数据应用进程:这类进程是启动MapReduce程序的主入口,主要指定Map和Reduce类,输入输出文件路径等,并提交作业给Hadoop集群,也就是下面提到的JobTracker进程。
2.JobTracker进程:这类进程根据要处理的输入数据量,命令下面提到的TaskTracker进程启动响应数量的Map和Reduce进程任务,并管理整个作业生命周期的任务调度和监控。这是Hadoop常驻进程。
3.TaskTracker进程:这个进程负责启动和管理Map进程以及Reduce进程。因为需要每个数据块都有对应的map函数,TaskTracker进程通常和HDFS的DataNode进程启动在同一台服务器上。也就是说,Hadoop集群中绝大多数服务器同时运行DataNode进程和TaskTracker进程。
作业启动和运行机制的整个流程:
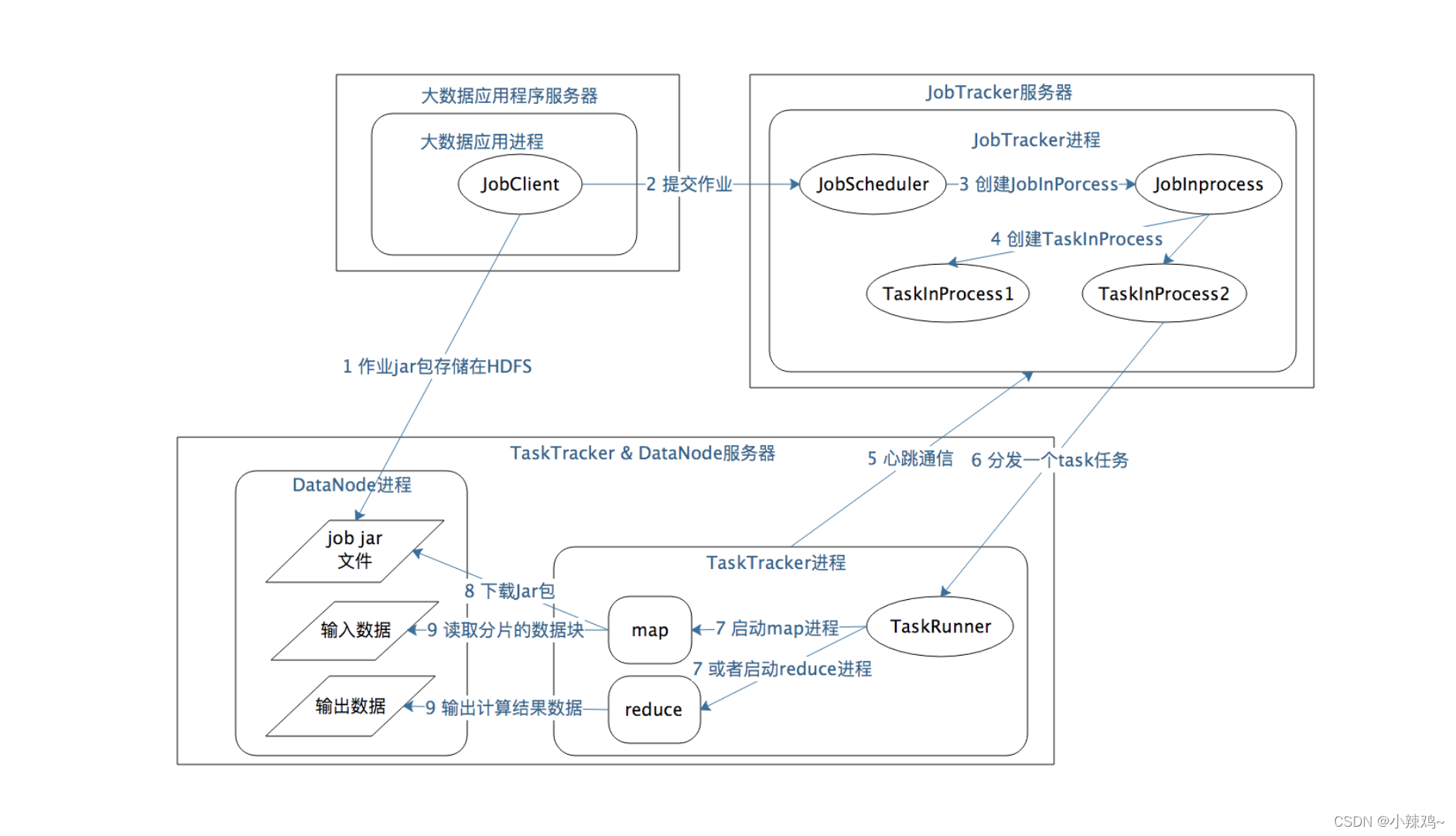
1.应用进程jobClient将用户作业JAR包存储在HDFS中,将来这些JAR包会分发给Hadoop集群中的服务器执行MapReduce计算。
2.应用程序提交job作业给JobTracker。
3.JobTracker根据作业调度策略创建JobInProcess树,每个作业都会有自己的一个JobInProcess树。
4.JobInProcess根据输入数据分片数目(通常情况下就是数据块的数目)和设置的Reduce数目创建相应数量的TaskInProcess。
5.TaskTracker和JobTracker进程进行定时通信。
6.如果TaskTracker有空闲的计算资源(有空闲的cpu核心),JobTracker就会给它分配任务。分配任务的时候会根据TaskTracker的服务器名匹配同一台机器上的数据块计算任务给它,使得启动的计算任务正好处理本机的数据,以实现移动计算比移动数据更划算。
7.TaskTracker收到任务后会根据任务类型(是map还是reduce)和任务参数(作业 JAR 包路径、输入数据文件路径、要处理的数据在文件中的起始位置和偏移量、数据块多个备份的 DataNode 主机名等),启动相应的Map或者reduce进程。
8.map和reduce启动后检出是否有要执行任务的jar包,如果没有的话,就去HDFS下载,然后加载Map或者Reduce代码开始执行。
9.如果是map进程从HDFS读取数据,如果是reduce就将结果写入HDFS中。
MapReduce数据合并与数据连接
在map输出和reduce输入之间,MapReduce计算框架处理合并与连接操作,这个操作有个专门的名次叫做shuffle。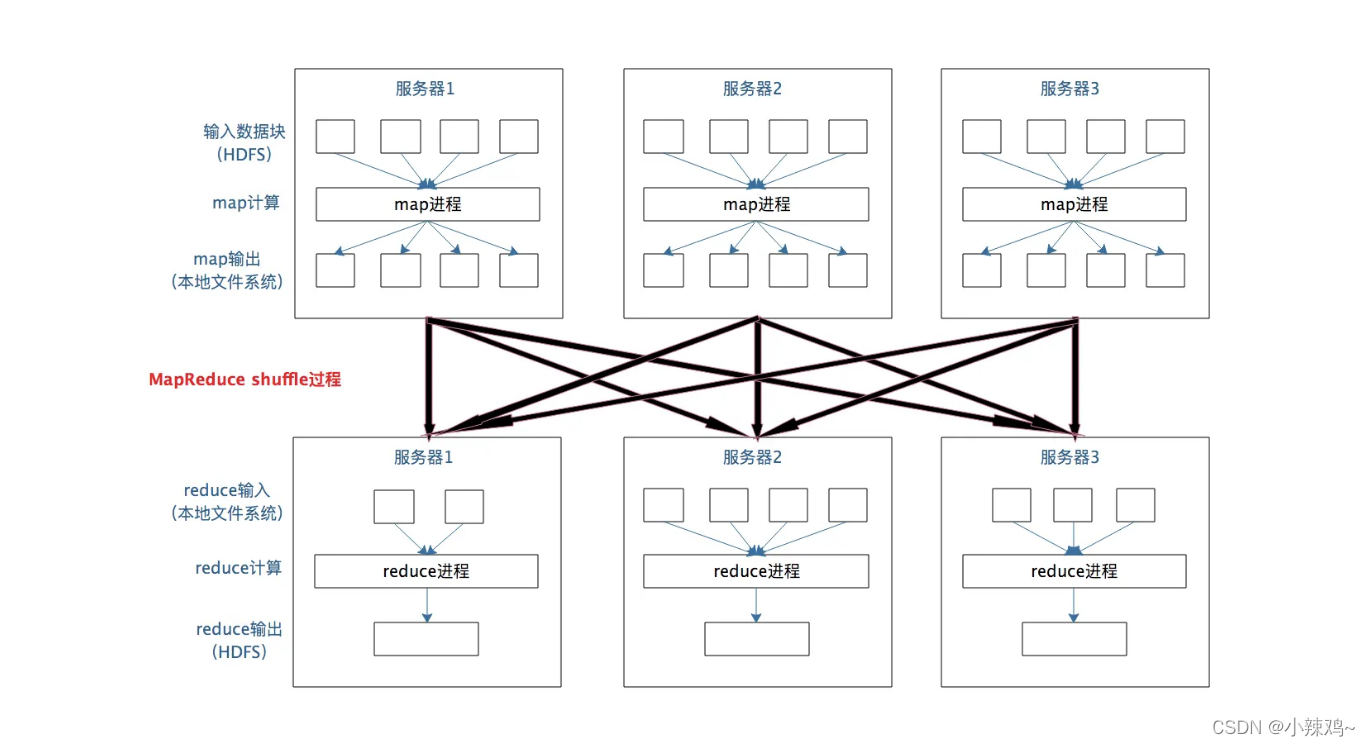
每一个Map任务的计算结果都会写入到本地文件系统。等Map快要计算完成时,MapReduce会启动shuffle过程,在Map任务进程调用一个Partitioner接口,对Map产生的每一个<key,value>进行Reduce分区选择,然后通过Http通信发送给对应的Reduce进程。这样不管Map位于哪个服务器节点,相同的key一定会发送给相同的Reduce进程,Reduce 任务进程对收到的 进行排序和合并,相同的 Key 放在一起,组成一个 传递给 Reduce 执行。
map输出的<Key,value>shuffle到哪个reduce进程是这里的关键,它是由Partitioner来实现的。
分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,就是shuffle。
为什么我们管Yarn叫做资源调度框架?
Hadoop主要由三部分组成,除了前面讲的分布式文件系统HDFS、分布式计算框架MapReduce、还有一个就是分布式集群资源调度框架Yarn。
在MapReduce启动过程中,最重要的就是把MapReduce程序分发到大数据集群的服务器上,在Hadoop 1中,这个过程主要通过TaskTracker和JobTracker完成。
这个方案有什么缺点吗?
这种架构方案的主要缺点是,服务器集群调度管理和MapReduce执行过程耦合在一起,如果想在当前集群中运行其他计算任务,比如spark或者storm,就无法使用集群中的资源
下面是yarm架构:
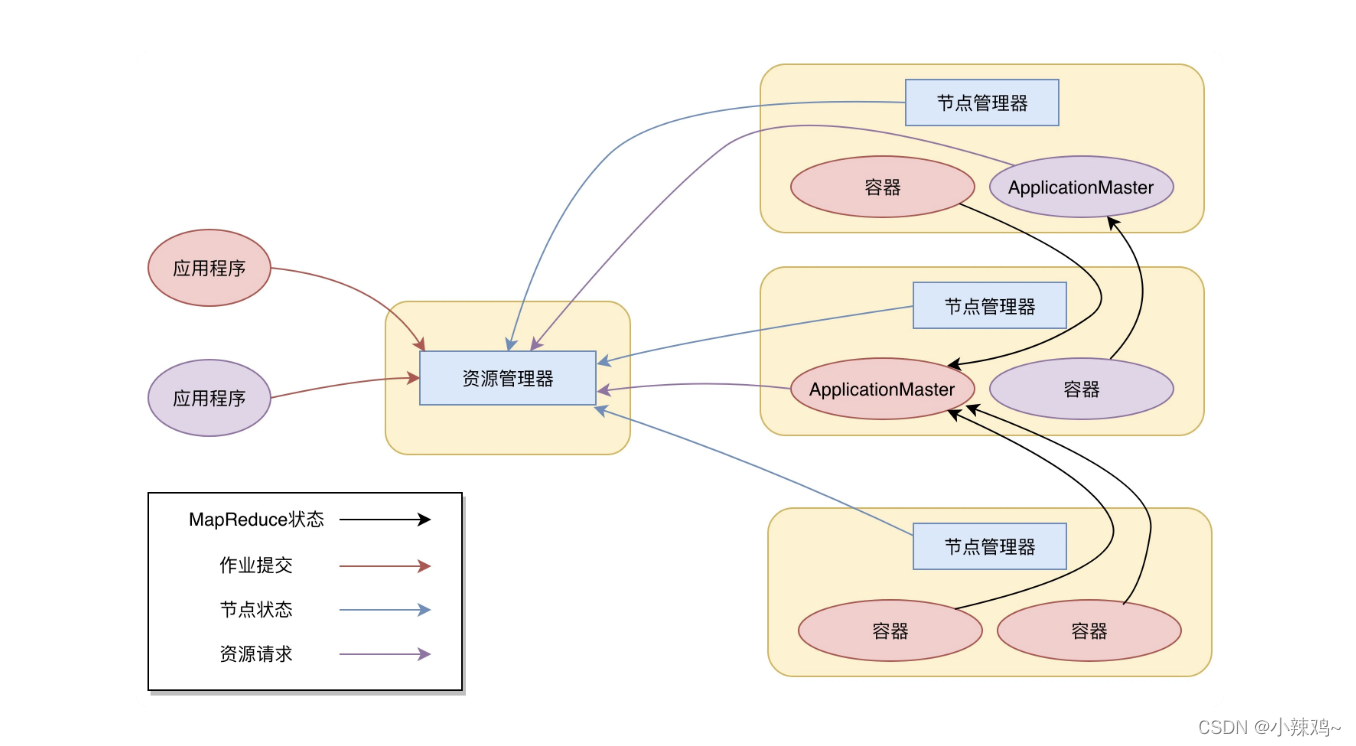
yarm包含两个部分:一个是资源管理器(Resource Manager),一个是节点管理器(Node Manager)。这是yarm的两个主要进程:Resource Manager负责整个集群的资源调度管理。
Node Manager负责具体服务器上的资源和任务管理。
资源管理器包含两个组件:调度器和应用程序管理器。
调度器其实就是一个资源分配算法,根据应用程序(Client)提交的资源申请和当前服务器集群的资源状况进行资源分配。Yarn 内置了几种资源调度算法,包括 Fair Scheduler、Capacity Scheduler 等,你也可以开发自己的资源调度算法供 Yarn 调用。Yarn 进行资源分配的单位是容器(Container),每个容器包含了一定量的内存、CPU 等计算资源,默认配置下,每个容器包含一个 CPU 核心。容器由 NodeManager 进程启动和管理,NodeManger 进程会监控本节点上容器的运行状况并向 ResourceManger 进程汇报。应用程序管理器负责应用程序的提交、监控应用程序运行状态等。应用程序启动后需要在集群中运行一个 ApplicationMaster,ApplicationMaster 也需要运行在容器里面。每个应用程序启动后都会先启动自己的 ApplicationMaster,由 ApplicationMaster 根据应用程序的资源需求进一步向 ResourceManager 进程申请容器资源,得到容器以后就会分发自己的应用程序代码到容器上启动,进而开始分布式计算。我们以一个 MapReduce 程序为例,来看一下 Yarn 的整个工作流程。
- 我们向 Yarn 提交应用程序,包括 MapReduce ApplicationMaster、我们的 MapReduce 程序,以及 MapReduce Application 启动命令。
2.ResourceManager 进程和 NodeManager 进程通信,根据集群资源,为用户程序分配第一个容器,并将 MapReduce ApplicationMaster 分发到这个容器上面,并在容器里面启动 MapReduce ApplicationMaster。
3.MapReduce ApplicationMaster 启动后立即向 ResourceManager 进程注册,并为自己的应用程序申请容器资源。
4.MapReduce ApplicationMaster 申请到需要的容器后,立即和相应的 NodeManager 进程通信,将用户 MapReduce 程序分发到 NodeManager 进程所在服务器,并在容器中运行,运行的就是 Map 或者 Reduce 任务。
5.Map 或者 Reduce 任务在运行期和 MapReduce ApplicationMaster 通信,汇报自己的运行状态,如果运行结束,MapReduce ApplicationMaster 向 ResourceManager 进程注销并释放所有的容器资源。
MapReduce 如果想在 Yarn 上运行,就需要开发遵循 Yarn 规范的 MapReduce ApplicationMaster,相应地,其他大数据计算框架也可以开发遵循 Yarn 规范的 ApplicationMaster,这样在一个 Yarn 集群中就可以同时并发执行各种不同的大数据计算框架,实现资源的统一调度管理。细心的你可能会发现,我在今天文章开头的时候提到 Hadoop 的三个主要组成部分的时候,管 HDFS 叫分布式文件系统,管 MapReduce 叫分布式计算框架,管 Yarn 叫分布式集群资源调度框架。
为什么 HDFS 是系统,而 MapReduce 和 Yarn 则是框架?框架在架构设计上遵循一个重要的设计原则叫“依赖倒转原则”,依赖倒转原则是高层模块不能依赖低层模块,它们应该共同依赖一个抽象,这个抽象由高层模块定义,由低层模块实现。所谓高层模块和低层模块的划分,简单说来就是在调用链上,处于前面的是高层,后面的是低层。
我们以典型的 Java Web 应用举例,用户请求在到达服务器以后,最先处理用户请求的是 Java Web 容器,比如 Tomcat、Jetty 这些,通过监听 80 端口,把 HTTP 二进制流封装成 Request 对象;然后是 Spring MVC 框架,把 Request 对象里的用户参数提取出来,根据请求的 URL 分发给相应的 Model 对象处理;再然后就是我们的应用程序,负责处理用户请求,具体来看,还会分成服务层、数据持久层等。在这个例子中,Tomcat 相对于 Spring MVC 就是高层模块,Spring MVC 相对于我们的应用程序也算是高层模块。我们看到虽然 Tomcat 会调用 Spring MVC,因为 Tomcat 要把 Request 交给 Spring MVC 处理,但是 Tomcat 并没有依赖 Spring MVC,Tomcat 的代码里不可能有任何一行关于 Spring MVC 的代码。那么,Tomcat 如何做到不依赖 Spring MVC,却可以调用 Spring MVC?
如果你不了解框架的一般设计方法,这里还是会感到有点小小的神奇是不是?
秘诀就是 Tomcat 和 Spring MVC 都依赖 J2EE 规范,Spring MVC 实现了 J2EE 规范的 HttpServlet 抽象类,即 DispatcherServlet,并配置在 web.xml 中。这样,Tomcat 就可以调用 DispatcherServlet 处理用户发来的请求。同样 Spring MVC 也不需要依赖我们写的 Java 代码,而是通过依赖 Spring MVC 的配置文件或者 Annotation 这样的抽象,来调用我们的 Java 代码。所以,Tomcat 或者 Spring MVC 都可以称作是框架,它们都遵循依赖倒转原则。
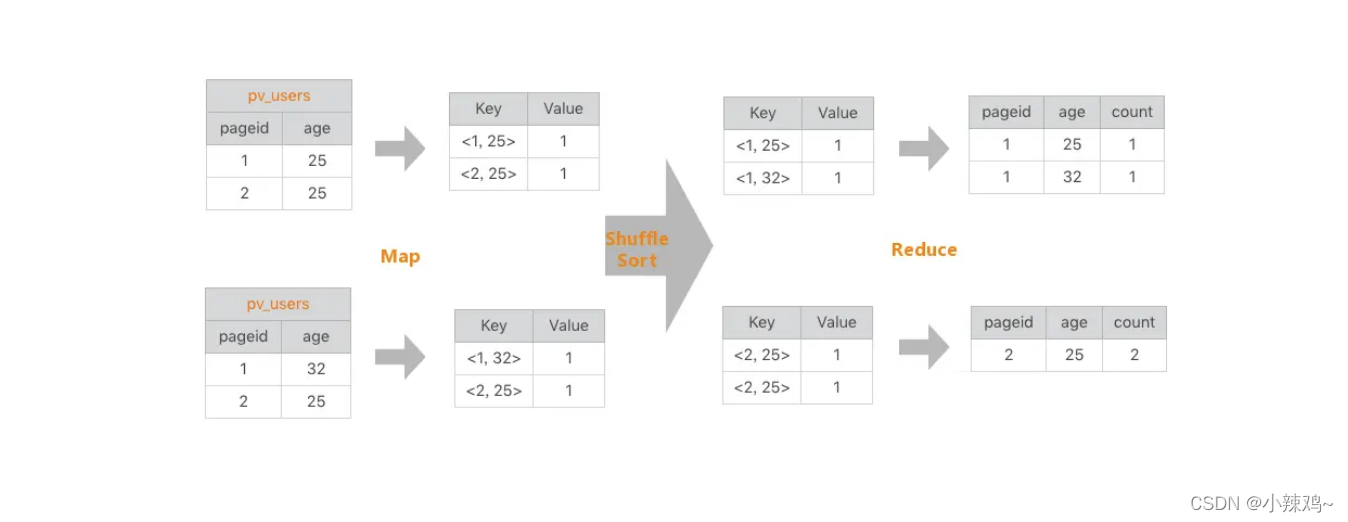
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;

左边是要分析的数据表,右边是分析结果。实际上把左边表相同的行进行累计求和,就得到右边的表了,看起来跟 WordCount 的计算很相似。确实也是这样,我们看下这条 SQL 语句的 MapReduce 的计算过程,按照 MapReduce 编程模型,map 和 reduce 函数的输入输出以及函数处理过程分别是什么。
首先,看下 map 函数的输入 Key 和 Value,我们主要看 Value。Value 就是左边表中每一行的数据,比如 <1, 25> 这样。map 函数的输出就是以输入的 Value 作为 Key,Value 统一设为 1,比如 <<1, 25>, 1> 这样。
map 函数的输出经过 shuffle 以后,相同的 Key 及其对应的 Value 被放在一起组成一个 ,作为输入交给 reduce 函数处理。比如 <<2, 25>, 1> 被 map 函数输出两次,那么到了 reduce 这里,就变成输入 <<2, 25>, <1, 1>>,这里的 Key 是 <2, 25>,Value 集合是 <1, 1>。
在 reduce 函数内部,Value 集合里所有的数字被相加,然后输出。所以 reduce 的输出就是 <<2, 25>, 2>。
Hive 的架构
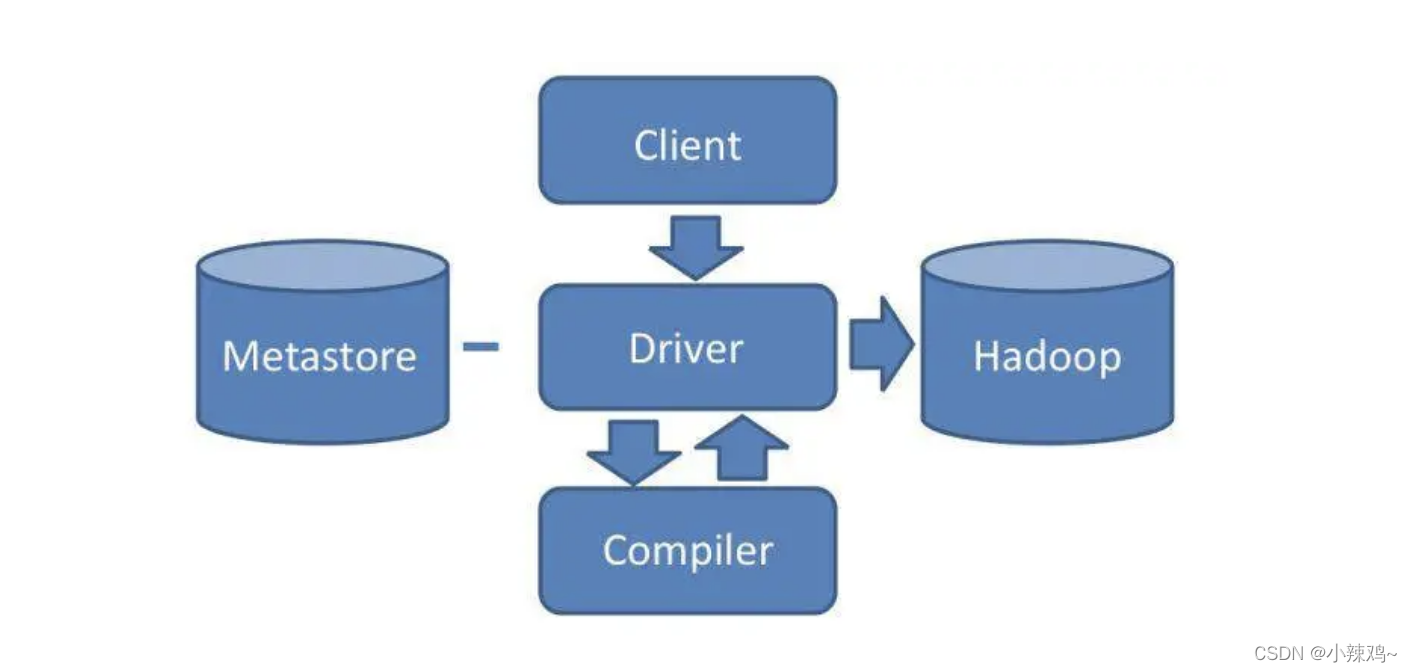
我们通过 Hive 的 Client(Hive 的命令行工具,JDBC 等)向 Hive 提交 SQL 命令。如果是创建数据表的 DDL(数据定义语言),Hive 就会通过执行引擎 Driver 将数据表的信息记录在 Metastore 元数据组件中,这个组件通常用一个关系数据库实现,记录表名、字段名、字段类型、关联 HDFS 文件路径等这些数据库的 Meta 信息(元信息)。
如果我们提交的是查询分析数据的 DQL(数据查询语句),Driver 就会将该语句提交给自己的编译器 Compiler 进行语法分析、语法解析、语法优化等一系列操作,最后生成一个 MapReduce 执行计划。然后根据执行计划生成一个 MapReduce 的作业,提交给 Hadoop MapReduce 计算框架处理。
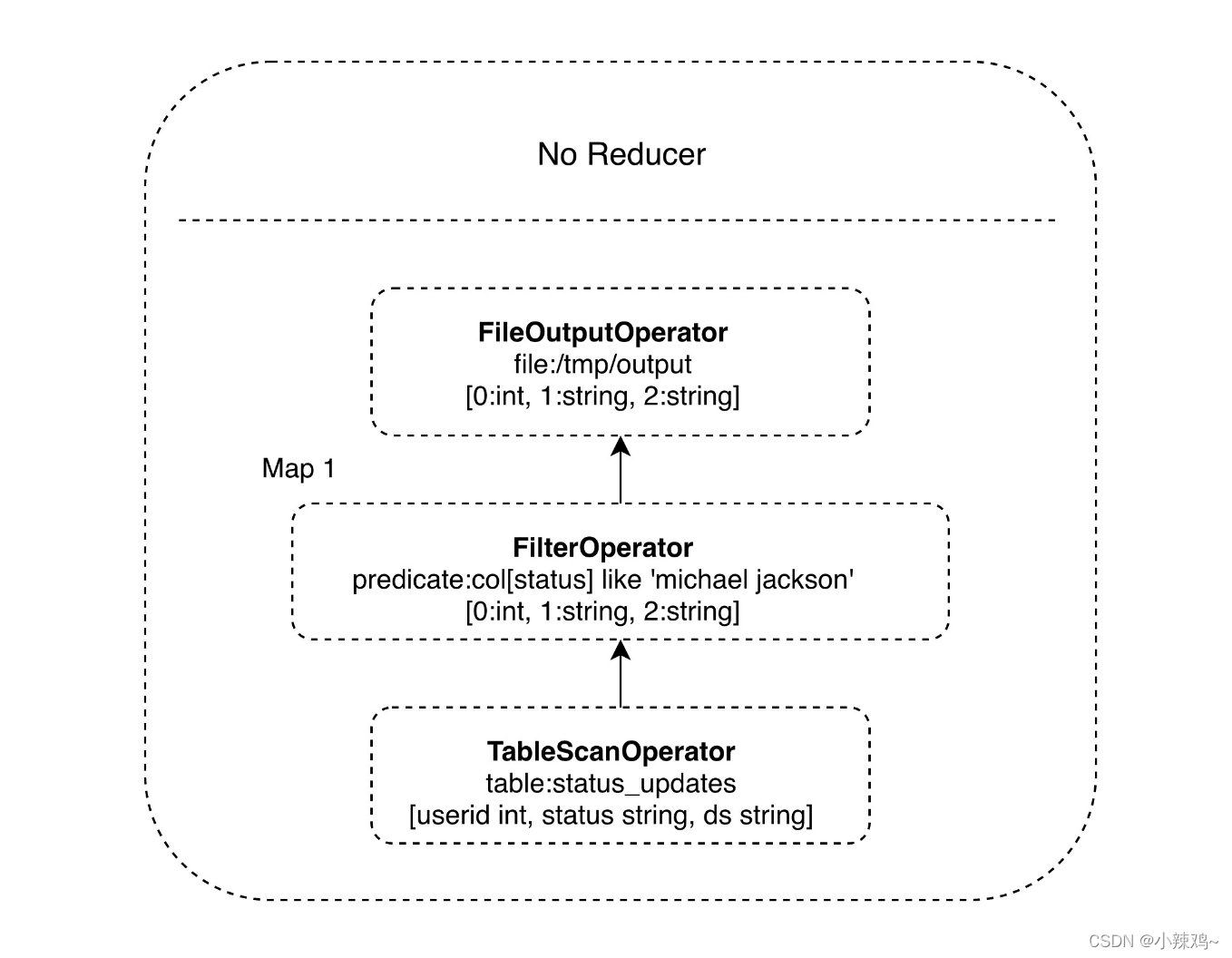
对于一个较简单的 SQL 命令,
比如:SELECT * FROM status_updates WHERE status LIKE ‘michael jackson’;
它对应的 Hive 执行计划如下图。
Hive 如何实现 join 操作
除了上面这些简单的聚合(group by)、过滤(where)操作,Hive 还能执行连接(join on)操作。文章开头的例子中,pv_users 表的数据在实际中是无法直接得到的,因为 pageid 数据来自用户访问日志,每个用户进行一次页面浏览,就会生成一条访问记录,保存在 page_view 表中。而 age 年龄信息则记录在用户表 user 中。
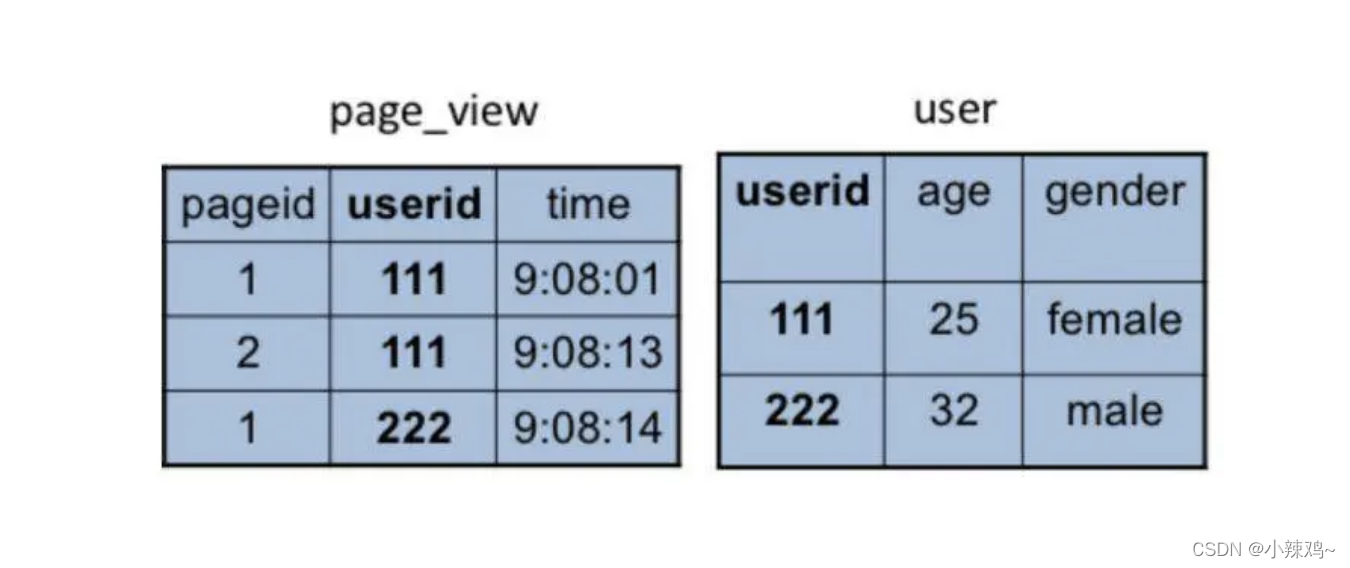
这两张表都有一个相同的字段 userid,根据这个字段可以将两张表连接起来,生成前面例子的 pv_users 表,
SQL 命令是SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.userid = u.userid);
同样,这个 SQL 命令也可以转化为 MapReduce 计算,连接的过程如下图所示。
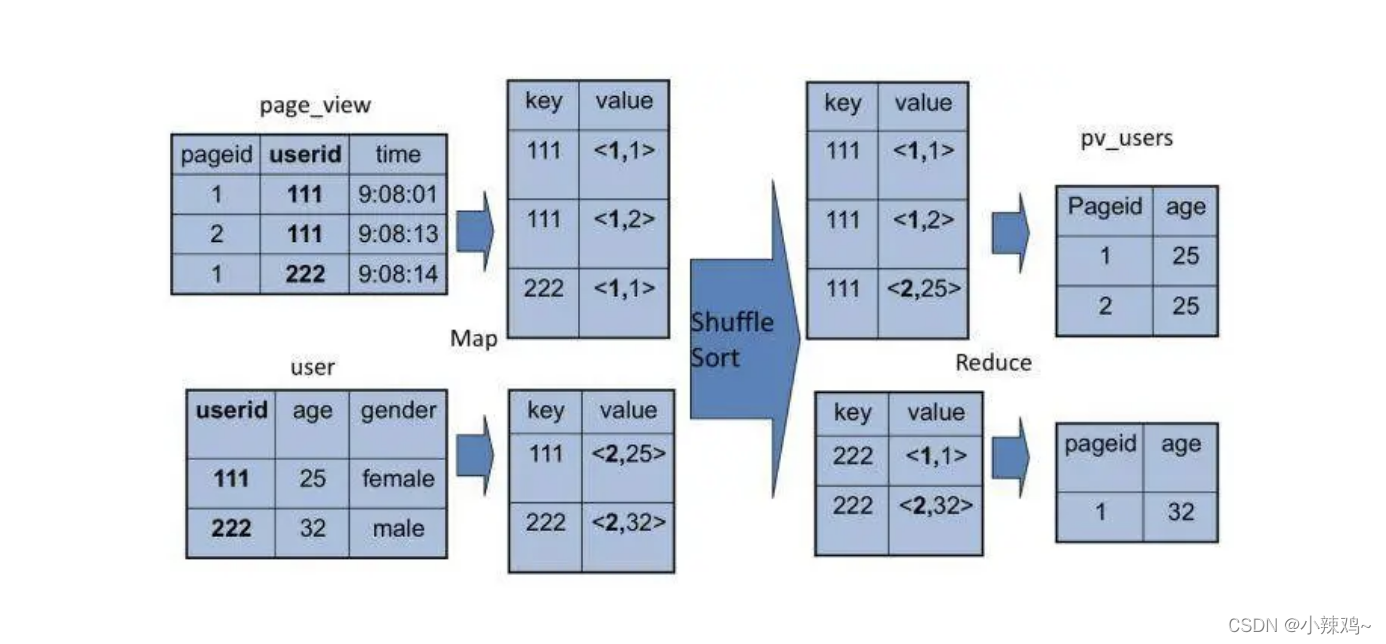
从图上看,join 的 MapReduce 计算过程和前面的 group by 稍有不同,因为 join 涉及两张表,来自两个文件(夹),所以需要在 map 输出的时候进行标记,比如来自第一张表的输出 Value 就记录为 <1, X>,这里的 1 表示数据来自第一张表。这样经过 shuffle 以后,相同的 Key 被输入到同一个 reduce 函数,就可以根据表的标记对 Value 数据求笛卡尔积,用第一张表的每条记录和第二张表的每条记录连接,输出就是 join 的结果。
我们并没有觉得MapReduce速度慢,直到Spark出现
除了速度更快,Spark 和 MapReduce 相比,还有更简单易用的编程模型。使用 Scala 语言在 Spark 上编写 WordCount 程序,主要代码只需要三行。
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
上面代码的含义
第 1 行代码:根据 HDFS 路径生成一个输入数据 RDD。
第 2 行代码:在输入数据 RDD 上执行 3 个操作,得到一个新的 RDD。
1.将输入数据的每一行文本用空格拆分成单词。
2.将每个单词进行转换,word => (word, 1),生成 的结构。
3.相同的key进行统计,统计方式是对Value进行求和,(_ + _)。
第3行代码将这个RDD保存到HDFS中。
RDD是Spark的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写。RDD既是Spark面向开发者的编程模型,又是Spark自身架构的核心元素。
我们都知道,大数据计算是在大规模数据集上进行一系列数据计算处理。
MapReduce针对输入数据,将计算过程分成两个阶段,一个Map阶段,一个Reduce阶段。可以理解为面向过程的大数据计算。我们用MapReduce编程的时候,考虑的是如何将计算逻辑用Map和Reduce两个阶段实现,map和Reduce的输入输出是什么。
而Spark则针对数据进行编程,将大规模数据集合抽象成一个RDD对象。,然后在这个RDD上进行各种计算处理,得到一个新的RDD,继续处理直到得到最后的结果。所以 Spark 可以理解成是面向对象的大数据计算。我们在进行 Spark 编程的时候,思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象,思考的重心和落脚点都在 RDD 上。
RDD的转换操作又分为两类:1.转换操作产生的RDD不会产生新的分片,比如map、filter等。
2.另一种转换操作产生的RDD则会产生新的分片,比如reduceByKey,来自不同的分片Key必须聚合在一起进行操作,这样就会产生新的RDD分片。
Spark计算阶段
首先和MapReduce一个应用只运行一个map和一个reduce不同,Spark可以根据应用的复杂程度,分割成更多的计算阶段。这些阶段形成一个有向无环图DAG,Spark 任务调度器可以根据 DAG 的依赖关系执行计算阶段。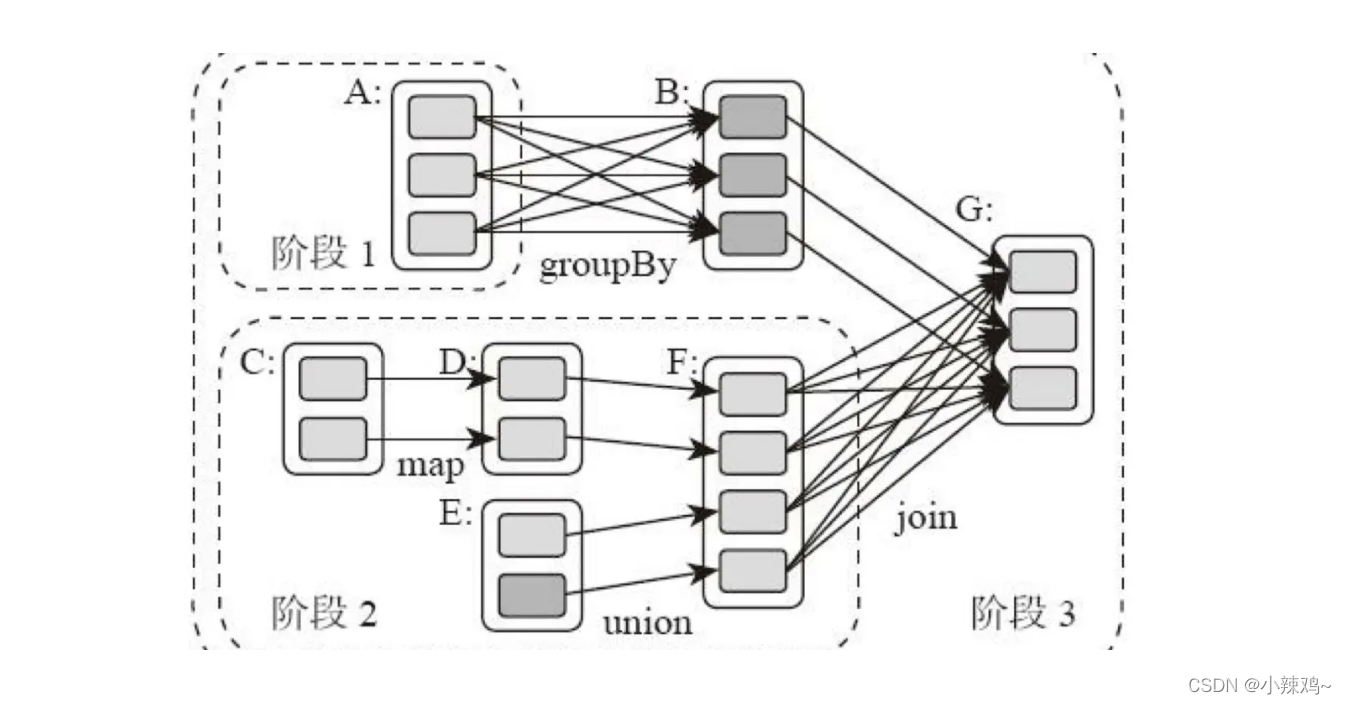
Spark作业调度的核心是DAG,有了DAG整个整个应用就被切成哪些阶段,每个阶段的依赖关系也就清楚了。之后再根据每个阶段的数据量生成相应的任务集合(TaskSet), 每个任务都分配一个任务进程去处理。
同样是经过shuffle,为什么spark可以更高效?
从本质上看,Spark算是一种MapReduce计算模型的不同实现。Hadoop MapReduce简单粗暴的根据shuffle将大数据计算分成Map和Reduce两个阶段,然后就完事了。而Spark更细腻一点,将前一个Reduce和后一个Map连接起来,当做一个阶段持续计算,形成更优雅更高效的计算模型,其本质上依旧是Map和Reduce。但是这种多个计算阶段依赖执行的方案可以有效的减少对HDFS的访问,减少作业的调度执行次数,因此执行速度也更快。
并且Hadoop MapReduce主要使用磁盘存储shuffle过程中的数据不同,Spark优先使用内存进行数据存储,包括RDD数据,除非是内存不够了,否则尽可能使用内存。
Spark的作业管理
Spark里的RDD有两种,一种是转换函数,调用以后得到的还是一个RDD。
另一种是action函数,调用以后不再返回RDD。比如 count() 函数,返回 RDD 中数据的元素个数;
Spark的DAGScheduler在遇到shuffle的时候,会生成一个计算阶段,在遇到action的时候会生成一个job(作业)
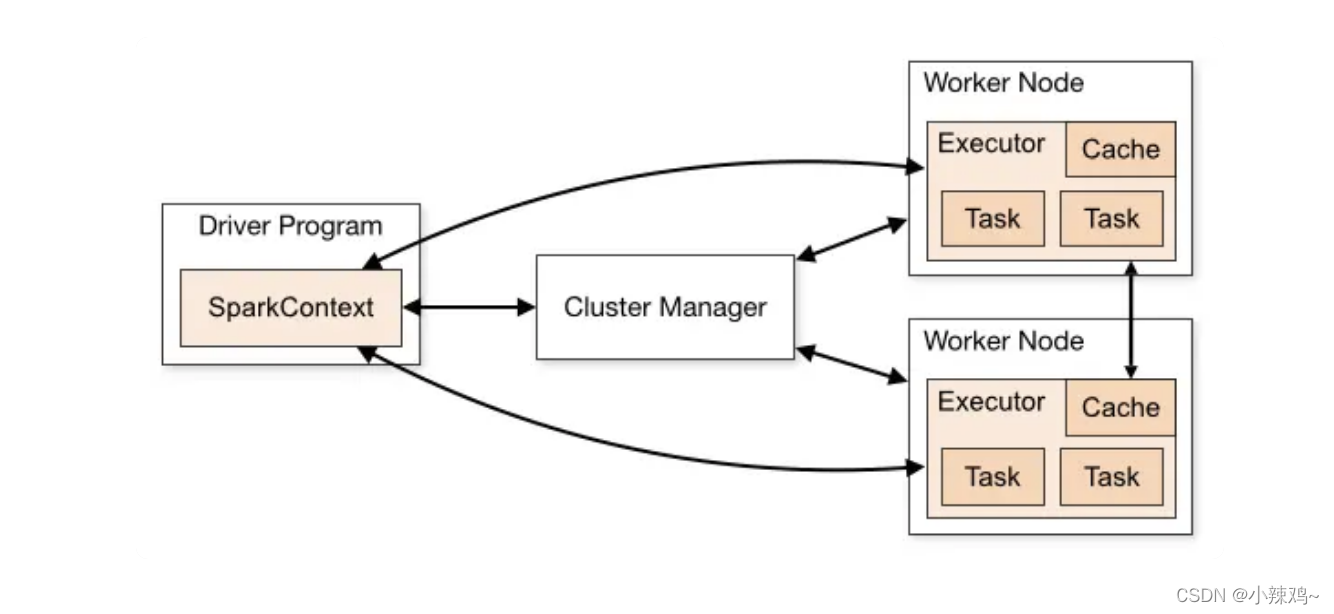
Spark的执行过程
首先Spark应用进程启动在自己的JVM进程里,即Driver进程,启动后调用SparkContext初始化执行配置和输入数据。SparkContext启动DAGScheduler构造执行的DAG图,切分成最小的执行单位也就是计算任务。
然后Driver向Cluster Manager请求计算资源,用于DAG的分布式计算。Cluster Manager收到请求后会将Driver的主机地址等信息通知给集群的所有计算节点Worker。
Worker收到信息后会根据Driver的主机地址,根Driver进行通信并注册,然后根据自己空闲的资源向Driver通报自己可以领取的任务数。Driver根据DAG图向注册的Worker分配任务。
Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行。
BigTable的开源实现:Hbase
BigTable对应的NoSQL系统HBase,看看它是如何处理大规模海量数据的?
Hbase可伸缩架构
Hbase为可伸缩海量存储而设计的,实现面向在线业务的实时数据访问延迟。HBase的伸缩性主要依赖其可分裂的HRegion及可伸缩的分布式文件系统HDFS实现的。
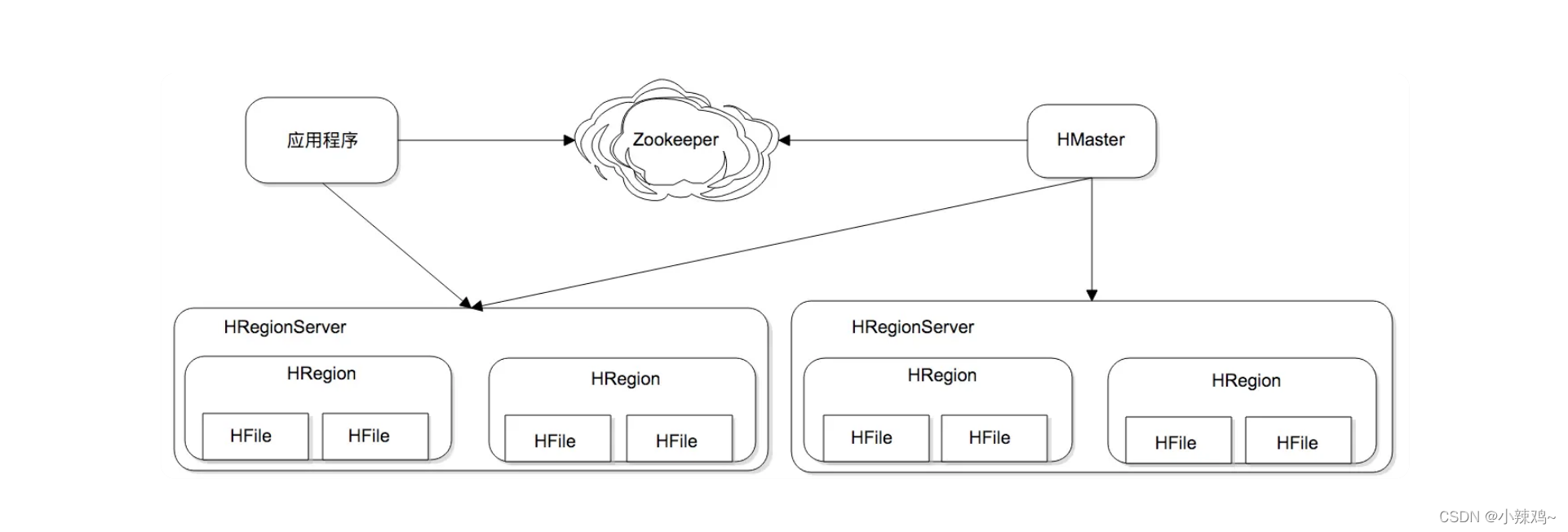
HRegion是HBase负责数据存储的主要进程,应用程序对数据的读写操作都是通过和HRegion通信完成的。
HRegionServer是物理服务器,每个HRegionServer上可以启动多个HRegion实例。当一个HRegion的写入数据太多达到配置的阀值的时候,一个HRegion会分裂成两个HRegion,并将整个HRegion在集群中进行迁移,以使HRegionServer达到负载均衡。
HBase的高性能存储
传统机械磁盘的访问特点:连续读写很快,随机读写很慢。
为了提高读写速度,HBase使用一种叫做LSM树的数据结构进行数据存储。
LSM树相比于B+树提高写性能的原因:无论是磁盘还是SSD,都有随机读写慢,顺序读写快的问题。
LSM参看:
https://blog.csdn.net/wsdc0521/article/details/107826869
http://www.codebaoku.com/eth/eth-lsm.html
流式计算
实时处理跟HDFS最大的不同就是实时传输过来的。或者形象的来说是流过来的。所以针对这类大数据的实时处理系统也叫做大数据流计算系统。
目前业内知名的大数据计算框架有Storm、Spark Streaming、Flink。
接下来我们一起看看它们的架构原理和使用方法:
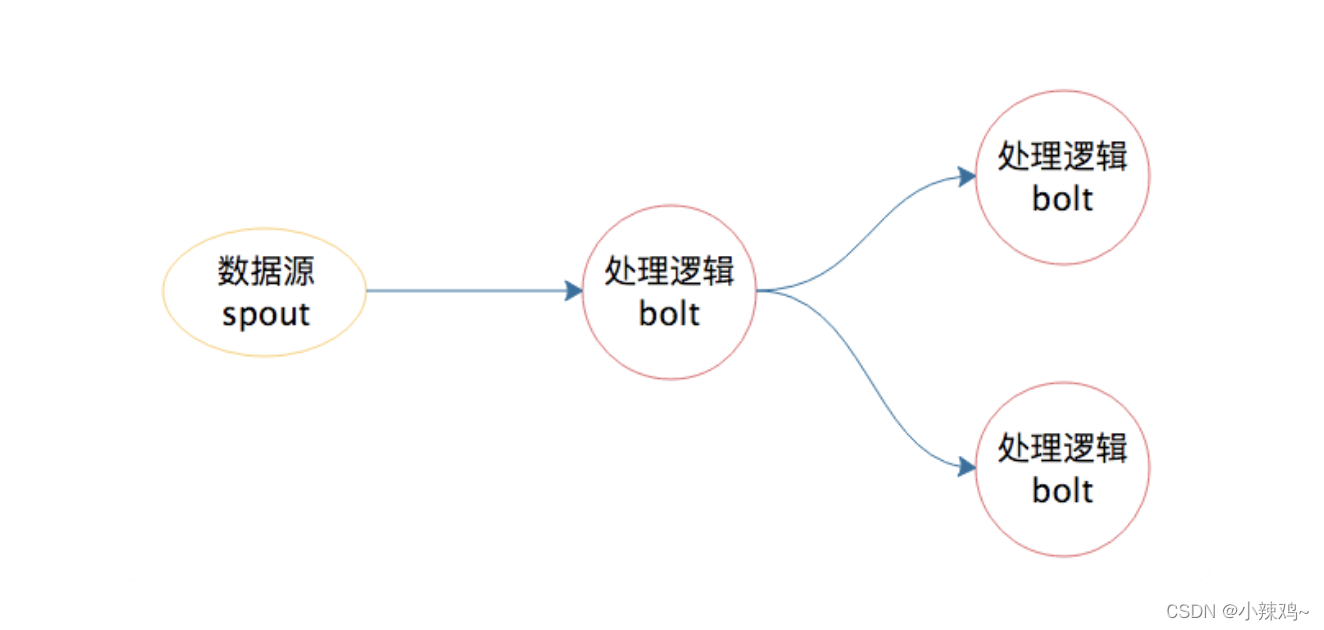
有了Storm之后,开发者无需再关心数据的流转、消息的处理和消费,只需要编写好数据处理的逻辑bolt和数据源的逻辑spout,以及它们之间的拓扑关系toplogy,提交到storm上运行就可以了。
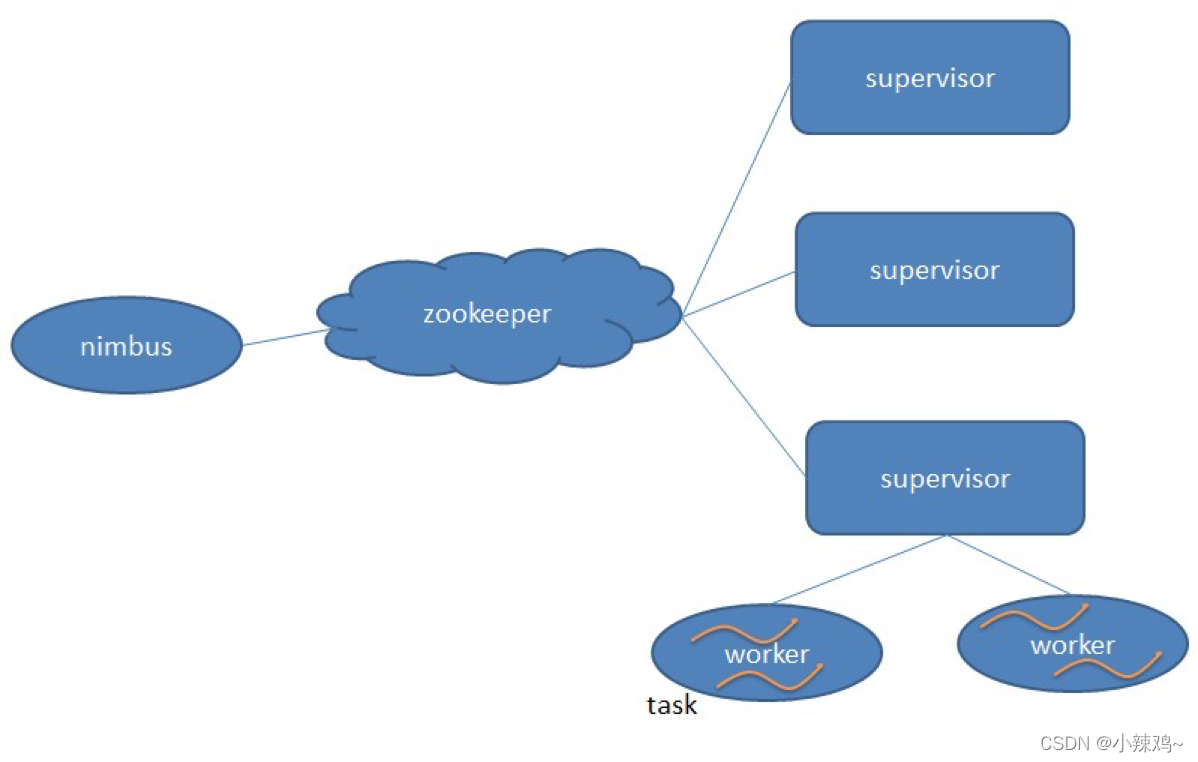
nimbus是集群的Master,负责集群的管理、任务分配等。superivor是真正完成计算的地方,每个supervivor启动多个worker进程,每个worker上运行多个task,而task就是spout 或者 bolt。supervisor 和 nimbus 通过 ZooKeeper 完成任务分配、心跳检测等操作。
Spark Streaming
spark是批处理大数据计算引擎,主要针对大批量历史数据进行计算。前面我在介绍Spark架构原理时介绍过,spark是一个快速计算的大数据引擎,它将原始数据分片后装载到集群中进行计算,对于数据量不是很大、过程不是很复杂的计算可以在秒级或者毫秒级完成。
Spark Streaming巧妙利用了spark的分片和快速计算的特点,将实时传输进来的数据按照时间进行分段,把一段时间传输进来的数据合并到一起,当作一批数据,再交给spark去处理。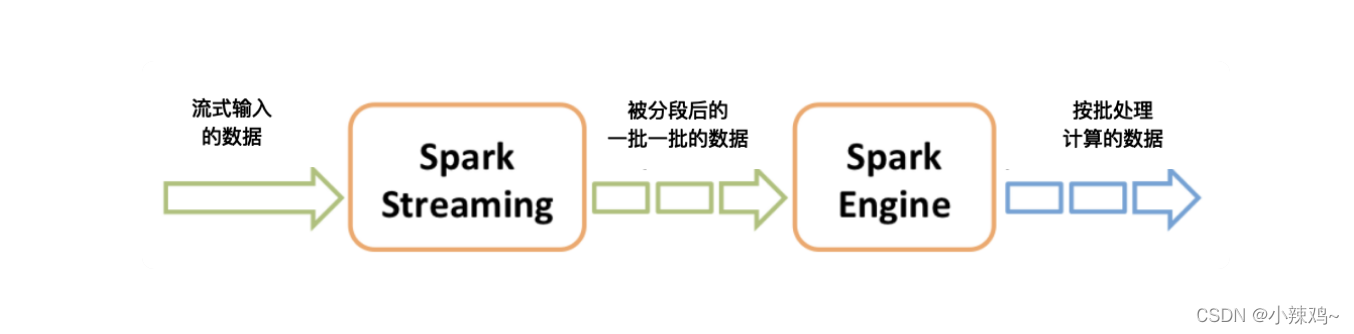














 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









