







 本文深入分析了生成对抗网络(GAN)在训练过程中遇到的两大难题:梯度消失和模式崩溃。梯度消失导致生成器在优化过程中得不到有效的梯度信息,特别是在判别器接近最优时,问题尤为严重。模式崩溃则表现为生成器只能生成有限种类的样本,缺乏多样性。这两个问题限制了GAN的性能,文中通过数学推导揭示了问题的本质,并引用相关研究进行了说明。
本文深入分析了生成对抗网络(GAN)在训练过程中遇到的两大难题:梯度消失和模式崩溃。梯度消失导致生成器在优化过程中得不到有效的梯度信息,特别是在判别器接近最优时,问题尤为严重。模式崩溃则表现为生成器只能生成有限种类的样本,缺乏多样性。这两个问题限制了GAN的性能,文中通过数学推导揭示了问题的本质,并引用相关研究进行了说明。
原始的GAN并不成熟,存在着诸多问题,其中梯度消失和模式崩溃(collapse mode)问题严重限制GAN的发展。只有了解问题发生的本质,才能做出相应的改进,本章主要对GAN在训练中存在梯度消失和模式崩溃的原因进行分析。
梯度消失问题分析
梯度消失即是利用误差反向传播(back propagation,BP)算法对深度神经网络进行训练时,梯度后向传播到浅层网络时基本不能引起数值的扰动,最终导致神经网络收敛很慢甚至不能收敛。GAN存在梯度消失的问题,并且在判别器训练得越好的时候,生成器梯度消失得越严重。最优判别器如下式:
D
G
∗
(
x
)
=
p
d
a
t
a
(
x
)
p
d
a
t
a
(
x
)
+
P
g
(
x
)
D_{G}^{*}(x)=\frac{p_{\mathrm{data}}(x)}{p_{\mathrm{data}}(x)+P_{g}(x)}
DG∗(x)=pdata(x)+Pg(x)pdata(x)
在最极端的情况下,当判别器达到最优时,此时生成器模型如下式。
C
(
G
)
=
max
D
V
(
G
,
D
)
=
E
x
−
p
data
[
l
b
p
data
(
x
)
p
data
(
x
)
+
p
g
(
x
)
]
+
E
x
−
p
g
[
l
b
p
g
(
x
)
p
data
(
x
)
+
p
g
(
x
)
]
\begin{aligned} &C(G)=\max _{D} V(G, D)= \\ &E_{x-p_{\text {data }}}\left[\mathrm{lb} \frac{p_{\text {data }}(x)}{p_{\text {data }}(x)+p_{g}(x)}\right]+E_{x-p_{g}}\left[\mathrm{lb} \frac{p_{g}(x)}{p_{\text {data }}(x)+p_{g}(x)}\right] \end{aligned}
C(G)=DmaxV(G,D)=Ex−pdata [lbpdata (x)+pg(x)pdata (x)]+Ex−pg[lbpdata (x)+pg(x)pg(x)]
原始GAN模型使用KL散度(Kullback-Leibler divergence)和JS散度(Jensen-Shannon)衡量两个分布之间的差异,即是:
C
(
G
)
=
−
l
b
4
+
K
L
(
P
data
∥
p
data
+
p
g
2
)
+
K
L
(
p
g
∥
p
data
+
p
z
2
)
=
−
l
b
4
+
2
J
S
(
p
data
∥
p
g
)
\begin{aligned} &C(G)=-\mathrm{lb} 4+K L\left(P_{\text {data }} \| \frac{p_{\text {data }}+p_{g}}{2}\right)+ \\ &K L\left(p_{g} \| \frac{p_{\text {data }}+p_{z}}{2}\right)=-\mathrm{lb} 4+2 J S\left(p_{\text {data }} \| p_{g}\right) \end{aligned}
C(G)=−lb4+KL(Pdata ∥2pdata +pg)+KL(pg∥2pdata +pz)=−lb4+2JS(pdata ∥pg)
其中:
K
L
(
p
1
∥
p
2
)
=
E
x
−
p
(
lb
p
1
p
2
)
K L\left(p_{1} \| p_{2}\right)=E_{x-p}\left(\operatorname{lb} \frac{p_{1}}{p_{2}}\right)
KL(p1∥p2)=Ex−p(lbp2p1)
J S ( p 1 ∥ p 2 ) = 1 2 K L ( p 1 ∥ p 1 + p 2 2 ) + 1 2 K L ( p 2 ∥ p 1 + p 2 2 ) J S\left(p_{1} \| p_{2}\right)=\frac{1}{2} K L\left(p_{1} \| \frac{p_{1}+p_{2}}{2}\right)+\frac{1}{2} K L\left(p_{2} \| \frac{p_{1}+p_{2}}{2}\right) JS(p1∥p2)=21KL(p1∥2p1+p2)+21KL(p2∥2p1+p2)
训练GAN网络需要极小化 C ( G ) C(G) C(G),即是要求 m i n ( J S ( p d a t a ∣ ∣ p g ) ) min(JS(p_{data}||p_g)) min(JS(pdata∣∣pg)),JS散度的值越小表示两个分布之间越接近,这符合生成器的优化目标,即是要生成以假乱真的样本(两个样本之间的概率分布很接近)。
当两个分布有重叠的时候,优化JS散度是可行的,而在两个分布完全没有重叠部分,或者重叠的部分可以忽略时,JS散度是一个常数,此时梯度为0,即生成器在训练的过程中得不到任何的梯度信息,出现梯度消失的现象。下面从两个分布是否有重叠部分分析梯度消失的原因。
对于两个分布 p d a t a ( x ) p_{data} (x) pdata(x)和 p g ( x ) p_g (x) pg(x),不难得出如下四种情况,如下图所示。
Case 1: p d a t a ( x ) = 0 p_{data} (x) = 0 pdata(x)=0 and p g ( x ) = 0 p_g (x) = 0 pg(x)=0
Case 2 : p d a t a ( x ) ≠ 0 p_{data} (x) ≠ 0 pdata(x)=0 and p g ( x ) ≠ 0 p_g (x) ≠ 0 pg(x)=0
Case 3 : p d a t a ( x ) = 0 p_{data} (x) = 0 pdata(x)=0 and p g ( x ) ≠ 0 p_g (x) ≠ 0 pg(x)=0
Case 4 : p d a t a ( x ) ≠ 0 p_{data} (x) ≠ 0 pdata(x)=0 and p g ( x ) = 0 p_g (x) = 0 pg(x)=0
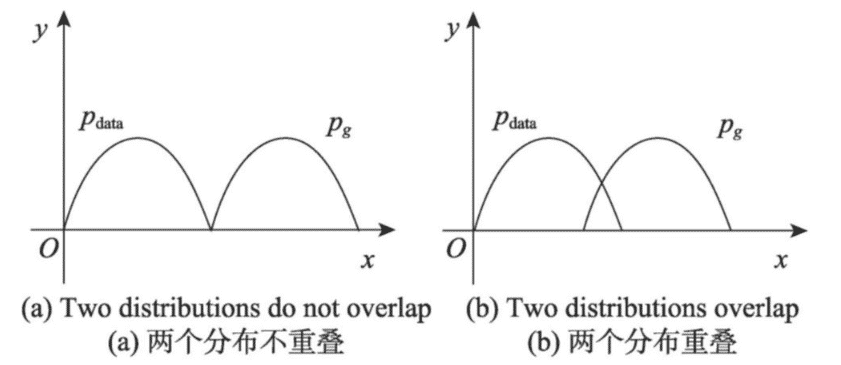
(1)两个分布没有重叠部分。对于情况1,由于 p d a t a p_data pdata和 p g p_g pg的取值都在函数的支撑集(support)之外,因此情况1对JS散度无贡献。
情况2由于两个分布的支撑集没有交集,因此对最后的JS散度也无贡献。
对于情况3,将
p
d
a
t
a
(
x
)
=
0
p_{data}(x)=0
pdata(x)=0且
p
g
(
x
)
≠
0
p_g(x)≠0
pg(x)=0带入式(4),得到式(5)。
J
S
(
p
d
a
t
a
∥
p
g
)
=
1
2
K
L
(
0
∥
0
+
p
g
2
)
+
1
2
K
L
(
p
g
∥
0
+
p
g
2
)
=
0
+
∑
x
∼
X
p
g
(
x
)
×
l
b
2
\begin{aligned} &J S\left(p_{\mathrm{data}} \| p_{\mathrm{g}}\right)=\frac{1}{2} K L\left(0 \| \frac{0+p_{\mathrm{g}}}{2}\right)+ \\ &\frac{1}{2} K L\left(p_{\mathrm{g}} \| \frac{0+p_{\mathrm{g}}}{2}\right)=0+\sum_{x \sim X} p_{\mathrm{g}}(x) \times \mathrm{lb} 2 \end{aligned}
JS(pdata∥pg)=21KL(0∥20+pg)+21KL(pg∥20+pg)=0+x∼X∑pg(x)×lb2
由于
∑
x
∼
X
p
g
(
x
)
=
1
\sum_{x \sim X} p_{\mathrm{g}}(x) = 1
∑x∼Xpg(x)=1 , 我们有
J
S
(
p
d
a
t
a
∣
∣
p
g
)
=
l
b
2
JS(p_{data}||p_g ) = lb 2
JS(pdata∣∣pg)=lb2 . 同理,对于情况4,我们有
J
S
(
p
d
a
t
a
∣
∣
p
g
)
=
l
b
2
JS(p_{data}||p_g ) = lb 2
JS(pdata∣∣pg)=lb2. 说明此时生成器没有得到任何梯度信息,梯度消失。
(2)两个分布有重叠部分。文献18指出,两个分布在高维空间是很难相交的,即使相交,其相交部分其实是高维空间中的一个低维流形,其测度为0,这说明两个分布相交部分可以忽略不计,此时JS散度的值和(1)讨论的一致,换言之,
p
d
a
t
a
p_{data}
pdata和
p
g
p_g
pg两个分布只要它们没有重叠部分或者重叠部分可以忽略,那么JS散度就固定是常数
l
b
2
lb 2
lb2,这对于梯度下降法而言意味着梯度为0。文献19证明了若存在一个判别器D无限接近于最优解时,即
∣
∣
D
∼
D
∗
∣
∣
<
ε
||D \sim D∗ || < ε
∣∣D∼D∗∣∣<ε,有如下关系:
∥
∇
θ
E
z
∼
p
(
z
)
[
lb
(
1
−
D
(
g
θ
(
z
)
)
)
∥
2
<
M
ε
1
−
ε
\| \nabla_{\theta} E_{z \sim p(z)}\left[\operatorname{lb}\left(1-D\left(g_{\theta}(z)\right)\right) \|_{2}<M \frac{\varepsilon}{1-\varepsilon}\right.
∥∇θEz∼p(z)[lb(1−D(gθ(z)))∥2<M1−εε
这说明了当判别器训练得越好,无限接近于最优判别器
D
G
∗
D_G^∗
DG∗ 时,生成器的梯度消失越严重,即是
lim ∥ D − D ∗ ∥ → 0 ∇ θ E z ∼ p ( z ) [ lb ( 1 − D ( g θ ( z ) ) ) ] = 0 \lim _{\left\|D-D^{*}\right\| \rightarrow 0} \nabla_{\theta} E_{z \sim p(z)}\left[\operatorname{lb}\left(1-D\left(g_{\theta}(z)\right)\right)\right]=0 ∥D−D∗∥→0lim∇θEz∼p(z)[lb(1−D(gθ(z)))]=0
模式崩溃问题分析
GAN模式崩溃(mode collapse)是指GAN生成不了多样性的样本,而是生成了与真实样本相同的样本,该缺陷在数据增强领域中是致命的。为解决GAN梯度消失问题,Goodfellow等人重新定义了损失函数,如下式。
min
G
max
D
V
(
D
,
G
)
=
E
x
∼
p
dut
(
x
)
[
⌊
l
b
D
(
x
)
]
+
E
z
∼
p
z
(
z
)
[
−
lb
(
D
(
x
)
)
]
\begin{aligned} &\min _{G} \max _{D} V(D, G)= \\ &E_{x \sim p_{\text {dut }}(x)}\left[\lfloor\mathrm{lb} D(x)]+E_{z \sim p_{z}(z)}[-\operatorname{lb}(D(x))]\right. \end{aligned}
GminDmaxV(D,G)=Ex∼pdut (x)[⌊lbD(x)]+Ez∼pz(z)[−lb(D(x))]
在最优判别器
D
G
∗
(
x
)
D_G^*(x)
DG∗(x)下,优化生成器的目标函数如下式
min
(
C
(
G
)
)
=
K
L
(
p
g
∥
p
data
)
−
2
J
S
(
p
data
∥
p
g
)
\min (C(G))=K L\left(p_{g} \| p_{\text {data }}\right)-2 J S\left(p_{\text {data }} \| p_{g}\right)
min(C(G))=KL(pg∥pdata )−2JS(pdata ∥pg)
要优化该目标函数,则要求同时满足下面俩式。
min
(
K
L
(
p
g
∥
p
data
)
)
\begin{aligned} &\min \left(K L\left(p_{g} \| p_{\text {data }}\right)\right) \end{aligned}
min(KL(pg∥pdata ))
max ( 2 J S ( p data ∥ p g ) ) \begin{aligned} &\max \left(2 J S\left(p_{\text {data }} \| p_{g}\right)\right) \end{aligned} max(2JS(pdata ∥pg))
上面第一个式子要求 p g p_g pg和 p d a t a p_{data} pdata的概率分布一样,而上面第二个式子则要求 p g p_g pg和 p d a t a p_{data} pdata的概率分布不一样,这样会产生矛盾,使得生成器无法稳定训练。放宽约束,只要求满足上面第一个式子同样不可行。如下:
(1)当 p g ( x ) → 0 p_g (x) → 0 pg(x)→0 且 p d a t a ( x ) → 1 p_{data} (x) → 1 pdata(x)→1, p g ( x ) lb p g ( x ) p data ( x ) → 0 p_{g}(x) \operatorname{lb} \frac{p_{g}(x)}{p_{\text {data }}(x)} \rightarrow0 pg(x)lbpdata (x)pg(x)→0 ,此时 K L ( p g ∣ ∣ p d a t a ) KL(p_g ||p_{data} ) KL(pg∣∣pdata)趋近于0. 该情况说明了生成器生成了与真实样本相似的样本。
(2) 当 p g ( x ) → 1 p_g (x) → 1 pg(x)→1 且 p d a t a ( x ) → 0 p_{data} (x) → 0 pdata(x)→0, p g ( x ) lb p g ( x ) p data ( x ) → ∞ p_{g}(x) \operatorname{lb} \frac{p_{g}(x)}{p_{\text {data }}(x)} \rightarrow \infty pg(x)lbpdata (x)pg(x)→∞ . 此时 K L ( p g ∣ ∣ p d a t a ) KL(p_g ||p_{data} ) KL(pg∣∣pdata) 趋近于正无穷。该情况说明生成器生成了不真实的样本。
情况(1)生成的样本缺乏多样性,惩罚较小,生成器宁可生成一些重复但很安全的样本,也不愿意生成多样性的样本,该现象就是模式崩溃。
情况(2)是生成器生成了不真实的样本,样本缺乏准确性,惩罚较大。
来源
梁俊杰,韦舰晶,蒋正锋.生成对抗网络GAN综述[J].计算机科学与探索,2020,14(01):1-17.

















 3316
3316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









