










自动化部署k8s,自动化部署监控、告警、日志组件以及在k8s上用vLLM部署大模型详细图文教程
阅读原文
建议阅读原文以获得最佳阅读体验:《自动化部署k8s,自动化部署监控、告警、日志组件以及在k8s上用vLLM部署大模型详细图文教程》
引言
本文首先详细介绍了如何利用juju高度自动化部署高可用kubernetes集群,然后再利用juju部署COS(canonical开源的一套监控、告警以及日志套件),如何高效部署ceph集群。
接着介绍了如何利用helm部署NVIDIA GPU operator
最后详细说明了如何在kubernetes集群上运行vLLM,不仅介绍了在单个k8s节点中运行vLLM,还说明了如何进行多节点并行推理。
用juju快速部署charmed kubernetes
规划:主机清单
| 节点名称 | 主机名 | OS | 型号 | ip | 序列号 | 备注(用途) |
|---|---|---|---|---|---|---|
| client | client | ubuntu desktop 24.04 | 虚拟机 | 172.16.0.9 | IT管理员工作站,可以是虚拟机 | |
| maas-system | maas-system | ubuntu server 24.04 | dell precision 5810 tower | 172.16.0.2 | 1W38HP2 | 管理裸金属(也可以管理虚拟机) |
| juju-controller | juju-controller | ubuntu server 24.04 | dell precision 5810 tower | 172.16.0.1 | 1W2CHP2 | juju-controller,建议用虚拟机(本实验使用的是物理PC) |
| etcd00 | etcd00 | ubuntu server 22.04 | 虚拟机 | etcd存储 | ||
| etcd01 | etcd01 | ubuntu server 22.04 | 虚拟机 | etcd存储 | ||
| etcd02 | etcd02 | ubuntu server 22.04 | 虚拟机 | etcd存储 | ||
| kubernetes-control-plane00 | kubernetes-control-plane00 | ubuntu server 22.04 | 虚拟机 | k8s控制平面节点 | ||
| kubernetes-control-plane01 | kubernetes-control-plane01 | ubuntu server 24.04 | 虚拟机 | k8s控制平面节点 | ||
| easyrsa | easyrsa | ubuntu server 22.04 | 虚拟机 | EasyRSA 作为 证书颁发机构(CA),负责生成和管理k8s集群所需的 TLS 证书 | ||
| kubeapi-load-balancer | kubeapi-load-balancer | ubuntu server 22.04 | 虚拟机 | kubernetes api负载均衡节点 | ||
| kubernetes-workernode00 | kubernetes-workernode00 | ubuntu server 22.04 | dell precision 5810 tower | FS8RM63 | worker node(charmed-kubernetes工作节点) | |
| kubernetes-workernode01 | kubernetes-workernode01 | ubuntu server 22.04 | Lenovo system x3650 M5 | 06HDHVL | worker node(charmed-kubernetes工作节点) | |
| kubernetes-workernode02 | kubernetes-workernode02 | ubuntu server 24.04 | dell precision 7920 tower | DYNZK93 | worker node(charmed-kubernetes工作节点) | |
| kubernetes-workernode03 | kubernetes-workernode03 | ubuntu server 22.04 | dell precision 7920 tower | 4VPMJJ3 | worker node(charmed-kubernetes工作节点) | |
| kubernetes-workernode04 | kubernetes-workernode04 | ubuntu server 22.04 | dell precision 5820 tower | 6YBPLR2 | worker node(charmed-kubernetes工作节点) | |
| kubernetes-workernode05 | kubernetes-workernode05 | ubuntu server 22.04 | dell precision 5820 tower | 6Y62NR2 | worker node(charmed-kubernetes工作节点) | |
| kubernetes-workernode06 | kubernetes-workernode06 | ubuntu server 22.04 | dell precision 5820 tower | FS8TM63 | worker node(charmed-kubernetes工作节点) | |
| kubernetes-workernode07 | kubernetes-workernode07 | ubuntu server 22.04 | dell precision 5820 tower | FS8SM63 | worker node(charmed-kubernetes工作节点) | |
| kubernetes-workernode08 | kubernetes-workernode08 | ubuntu server 22.04 | dell precision 5820 tower | FS8VM63 | worker node(charmed-kubernetes工作节点) |
准备client计算机
client计算机主要是用于输入命令的,juju就是在此计算机上执行命令的,然后通过api对maas和juju controller发出指令。
首先配置好代理,然后安装juju
/etc/environment文件内容设置如下:

http_proxy=http://<此处替换为实际的代理服务器地址或域名>:port
https_proxy=http://<此处替换为实际的代理服务器地址或域名>:port
no_proxy="fe80::/10,::1/128,10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/12,.svc,localhost,.dltornado2.com,.security.ubuntu.com,.aliyuncs.com"
安装juju
sudo snap install juju
部署maas
下面的命令是在maas上执行的,为了方便可以直接通过client计算机 ssh过去执行命令
#在执行以下命令之前,建议设置系统级代理,因为大陆访问snap store是不稳定的,而且后续还需要访问maas.io以下载Linux系统镜像,也是很不稳定的,编辑/etc/environment文件配置系统级代理
sudo hostnamectl hostname MAAS-system
sudo snap install maas-test-db
sudo snap install maas
sudo maas init region+rack --maas-url http://172.16.0.2:5240/MAAS --database-uri maas-test-db:///
sudo maas createadmin --username admin --password ubuntu --email tornado@dltornado2.com
sudo maas apikey --username admin > ./admin-api-key
配置maas
主要是第一次进入maas webUI时的初始化,然后是启用dhcp,配置DNS
特别注意:关于dhcp的dns设置
首选dns不能填写maas服务器的ip地址,否则会导致后续步骤部署的k8s集群中的pod无法访问外部网络,因为无法进行域名解析。
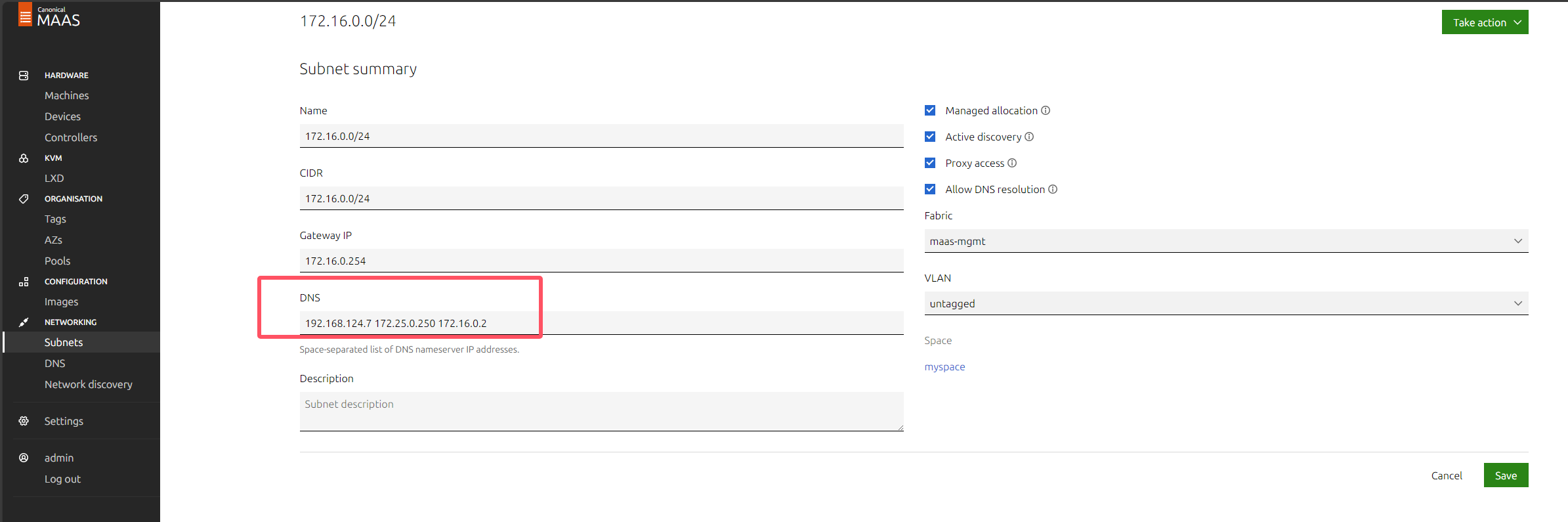
k8s的dns是通过coredns实现的,pod内部如果要访问集群内部的pod或者service,coredns即可完成,但是如果要访问外部网络,如baidu.com,则需要转发给另外一个dns服务器,默认情况下,coredns会将自己无法解析的域名转发给所在节点的设置的dns服务器(/etc/resolv.conf),这是通过configmap实现的,如下图:
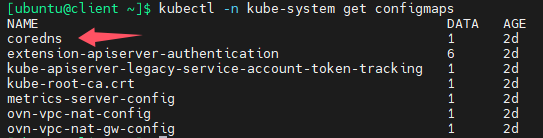
下图其实就是coredns的配置文件,可以看出coredns会将自己无法解析的域名转发给/etc/resolve.conf文件中配置的dns服务器地址,errors指的是日志级别
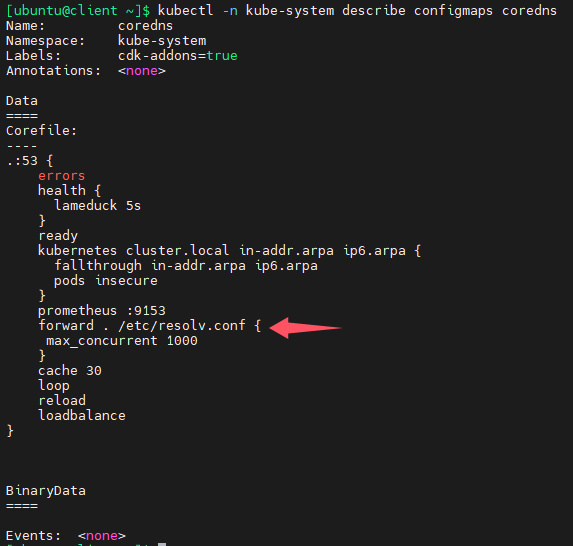
下面是k8s其中一个节点(coredns pod位于此节点)的dns配置,这样的配置是正确的,因为172.16.0.2不是首选dns
准备machines
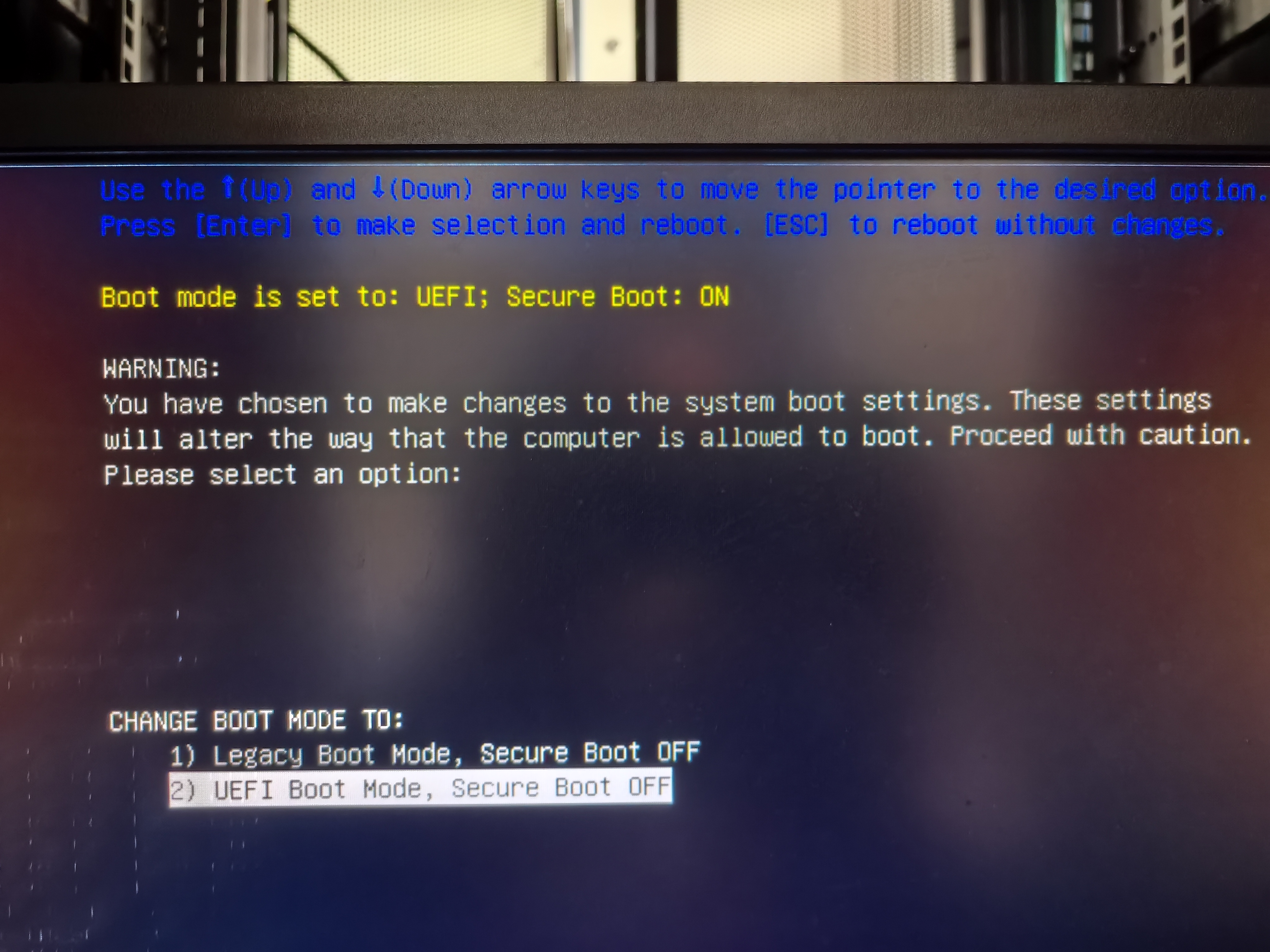
注意:禁用secure boot
如果要在k8s集群上部署NVIDIA GPU operator,则必须在bios上禁用secure boot,否则operator无法正常安装NVIDIA驱动。
通过PXE启动,之后commission,再添加合适的machine标签和storage标签(用于之后部署ceph),详情省略
juju添加maas cloud和其凭据
为了让client计算机上的juju客户端程序可以访问maas,需要先添加一个cloud并授权,如此juju就可以管理maas了
juju add-cloud
juju add-credential maas-one
创建juju controller
下面这段命令用于创建一个juju controller,会在machine上有tag为juju-controller上创建,并配置代理,前面的–config指的是为juju controller配置代理,后面的–model-default指的是为后续的所有models配置默认值,这样就不用每个model都单独设置了,maas-one是cloud的名称,maas-controller是新创建的controller名称,可以随意命名方便识别就行。
–config bootstrap-timeout=3600指的是设置创建controller的超时时间为3600秒(1小时)
juju bootstrap --constraints tags=juju-controller \
--bootstrap-base=ubuntu@24.04 \
--config bootstrap-timeout=3600 \
--config http-proxy=http://<此处替换为实际的代理服务器地址或域名>:port \
--config https-proxy=http://<此处替换为实际的代理服务器地址或域名>:port \
--config no-proxy=10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/16,.svc,dltornado2.com,geekery.cn,daocloud.io,aliyun.com,mywind.com.cn,hf-mirror.com,quay.io,localhost,security.ubuntu.com \
--model-default http-proxy=http://<此处替换为实际的代理服务器地址或域名>:port \
--model-default https-proxy=http://<此处替换为实际的代理服务器地址或域名>:port \
--model-default no-proxy=10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/16,.svc,dltornado2.com,geekery.cn,daocloud.io,aliyun.com,mywind.com.cn,hf-mirror.com,quay.io,localhost,security.ubuntu.com \
--model-default snap-http-proxy=http://<此处替换为实际的代理服务器地址或域名>:port \
--model-default snap-https-proxy=http://<此处替换为实际的代理服务器地址或域名>:port \
maas-one maas-controller
添加一个model
juju add-model charmed-k8s maas-one
部署charmed kubernetes bundle
注意:根据实践,我发现如果用默认的calico作为CNI,则calico pod会反复重启,一直不能就绪,至今没有找出原因,所以此处使用的是kube-ovn,这个cni其实比calico更加强大,吞吐量更大,兼容性更好,很多金融单位都是用这个cni
先准备一个bundle yaml文件,用于对此bundle进行自定义
说明:charmed-k8s-overlay.yaml文件用于覆盖此bundle默认的值,可以在github上查看默认的yaml文件:bundle/releases/1.32/bundle.yaml at main · charmed-kubernetes/bundle
cat <<EOF > charmed-k8s-overlay.yaml
applications:
kubernetes-control-plane:
constraints: tags=k8s-control-plane
options:
allow-privileged: "true"
num_units: 2
kubernetes-worker:
constraints: tags=k8s-workernode
num_units: 9
calico: null
kube-ovn:
charm: kube-ovn
etcd:
constraints: tags=etcd
num_units: 3
easyrsa:
constraints: tags=easyrsa
num_units: 1
kubeapi-load-balancer:
constraints: tags=kubeapi-load-balancer
num_units: 1
relations:
- [kube-ovn:cni, kubernetes-control-plane:cni]
- [kube-ovn:cni, kubernetes-worker:cni]
EOF
开始部署charmed-kubernetes
juju deploy charmed-kubernetes --overlay=charmed-k8s-overlay.yaml
输出如下:
Located bundle "charmed-kubernetes" in charm-hub, revision 1277
Located charm "containerd" in charm-hub, channel latest/stable
Located charm "easyrsa" in charm-hub, channel latest/stable
Located charm "etcd" in charm-hub, channel latest/stable
Located charm "kube-ovn" in charm-hub, channel latest/stable
Located charm "kubeapi-load-balancer" in charm-hub, channel latest/stable
Located charm "kubernetes-control-plane" in charm-hub, channel latest/stable
Located charm "kubernetes-worker" in charm-hub, channel latest/stable
Executing changes:
- upload charm containerd from charm-hub for base ubuntu@22.04/stable from channel stable with architecture=amd64
- deploy application containerd from charm-hub on ubuntu@22.04/stable with stable
added resource containerd
- set annotations for containerd
- upload charm easyrsa from charm-hub for base ubuntu@22.04/stable from channel stable with architecture=amd64
- deploy application easyrsa from charm-hub on ubuntu@22.04/stable with stable
added resource easyrsa
- set annotations for easyrsa
- upload charm etcd from charm-hub for base ubuntu@22.04/stable from channel stable with architecture=amd64
- deploy application etcd from charm-hub on ubuntu@22.04/stable with stable
added resource core
added resource etcd
added resource snapshot
- set annotations for etcd
- upload charm kube-ovn from charm-hub for base ubuntu@22.04/stable with architecture=amd64
- deploy application kube-ovn from charm-hub on ubuntu@22.04/stable
added resource kubectl-ko
- upload charm kubeapi-load-balancer from charm-hub for base ubuntu@22.04/stable from channel stable with architecture=amd64
- deploy application kubeapi-load-balancer from charm-hub on ubuntu@22.04/stable with stable
added resource nginx-prometheus-exporter
- expose all endpoints of kubeapi-load-balancer and allow access from CIDRs 0.0.0.0/0 and ::/0
- set annotations for kubeapi-load-balancer
- upload charm kubernetes-control-plane from charm-hub for base ubuntu@22.04/stable from channel stable with architecture=amd64
- deploy application kubernetes-control-plane from charm-hub on ubuntu@22.04/stable with stable
added resource cni-plugins
- set annotations for kubernetes-control-plane
- upload charm kubernetes-worker from charm-hub for base ubuntu@22.04/stable from channel stable with architecture=amd64
- deploy application kubernetes-worker from charm-hub on ubuntu@22.04/stable with stable
added resource cni-plugins
- expose all endpoints of kubernetes-worker and allow access from CIDRs 0.0.0.0/0 and ::/0
- set annotations for kubernetes-worker
- add relation kubernetes-control-plane:loadbalancer-external - kubeapi-load-balancer:lb-consumers
- add relation kubernetes-control-plane:loadbalancer-internal - kubeapi-load-balancer:lb-consumers
- add relation kubernetes-control-plane:kube-control - kubernetes-worker:kube-control
- add relation kubernetes-control-plane:certificates - easyrsa:client
- add relation etcd:certificates - easyrsa:client
- add relation kubernetes-control-plane:etcd - etcd:db
- add relation kubernetes-worker:certificates - easyrsa:client
- add relation kubeapi-load-balancer:certificates - easyrsa:client
- add relation containerd:containerd - kubernetes-worker:container-runtime
- add relation containerd:containerd - kubernetes-control-plane:container-runtime
- add relation kube-ovn:cni - kubernetes-control-plane:cni
- add relation kube-ovn:cni - kubernetes-worker:cni
- add unit easyrsa/0 to new machine 0
- add unit etcd/0 to new machine 1
- add unit etcd/1 to new machine 2
- add unit etcd/2 to new machine 3
- add unit kubeapi-load-balancer/0 to new machine 4
- add unit kubernetes-control-plane/0 to new machine 5
- add unit kubernetes-control-plane/1 to new machine 6
- add unit kubernetes-worker/0 to new machine 7
- add unit kubernetes-worker/1 to new machine 8
- add unit kubernetes-worker/2 to new machine 9
- add unit kubernetes-worker/3 to new machine 10
- add unit kubernetes-worker/4 to new machine 11
- add unit kubernetes-worker/5 to new machine 12
- add unit kubernetes-worker/6 to new machine 13
- add unit kubernetes-worker/7 to new machine 14
- add unit kubernetes-worker/8 to new machine 15
Deploy of bundle completed.
监控部署
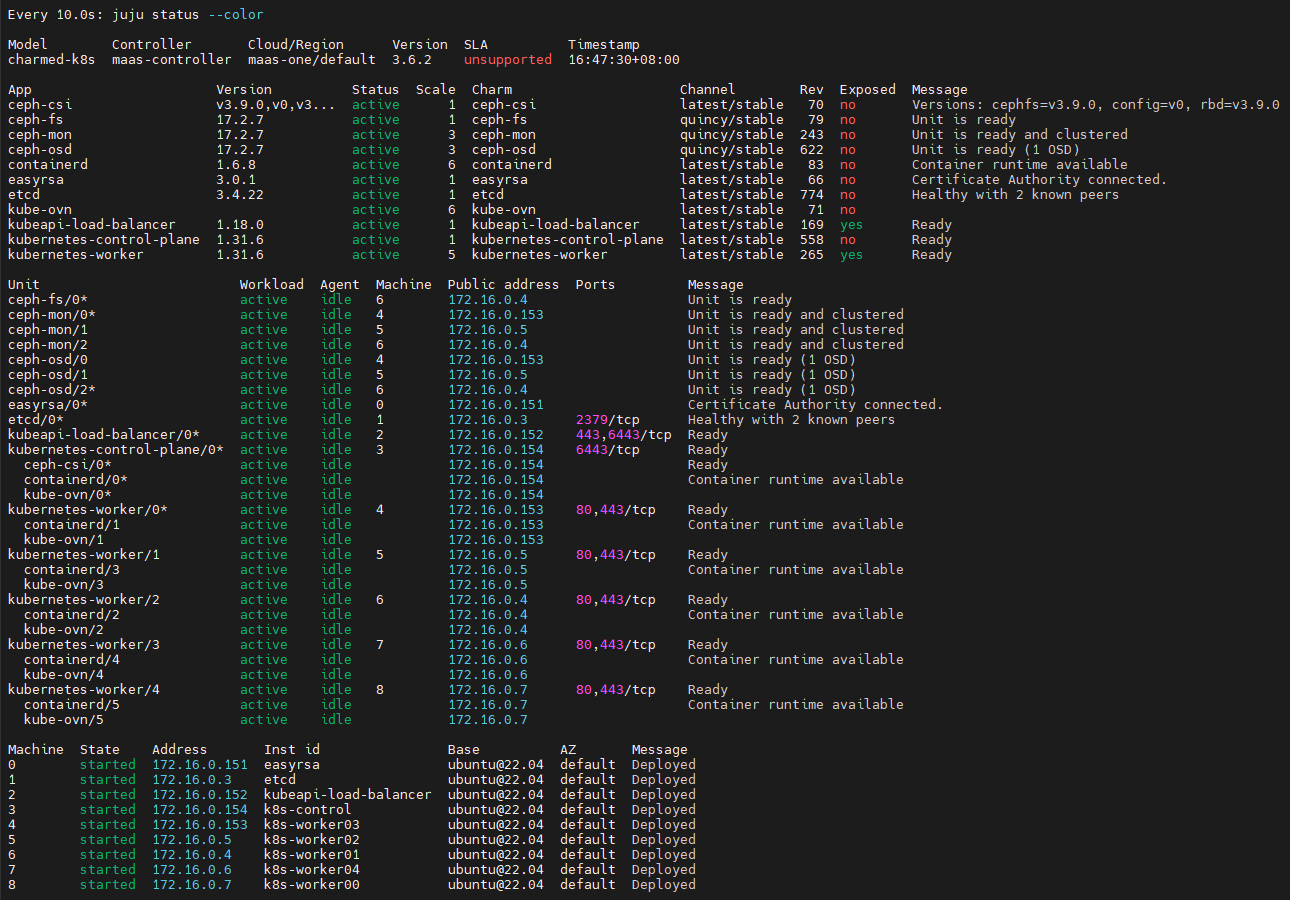
watch -n 10 -c juju status --color
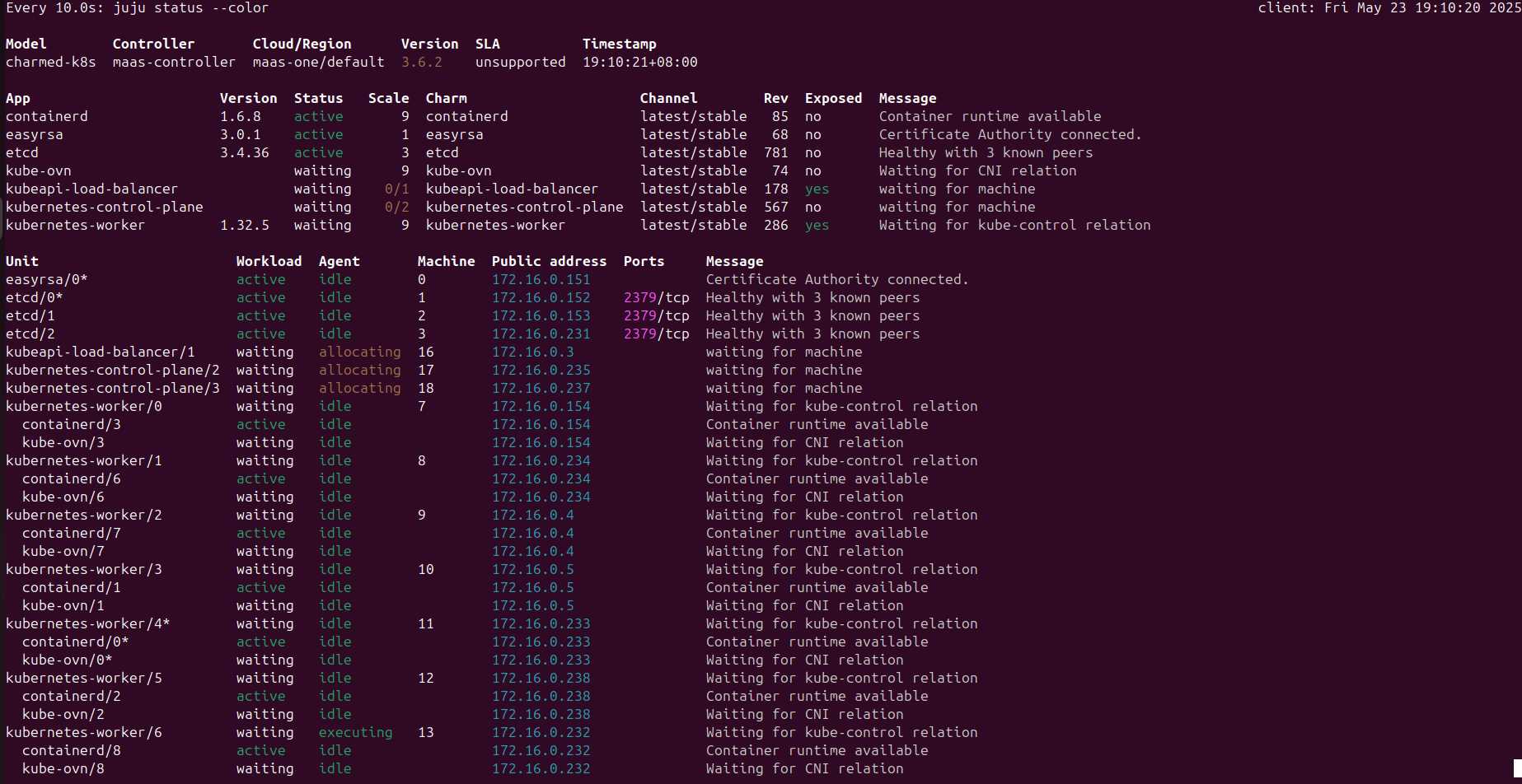
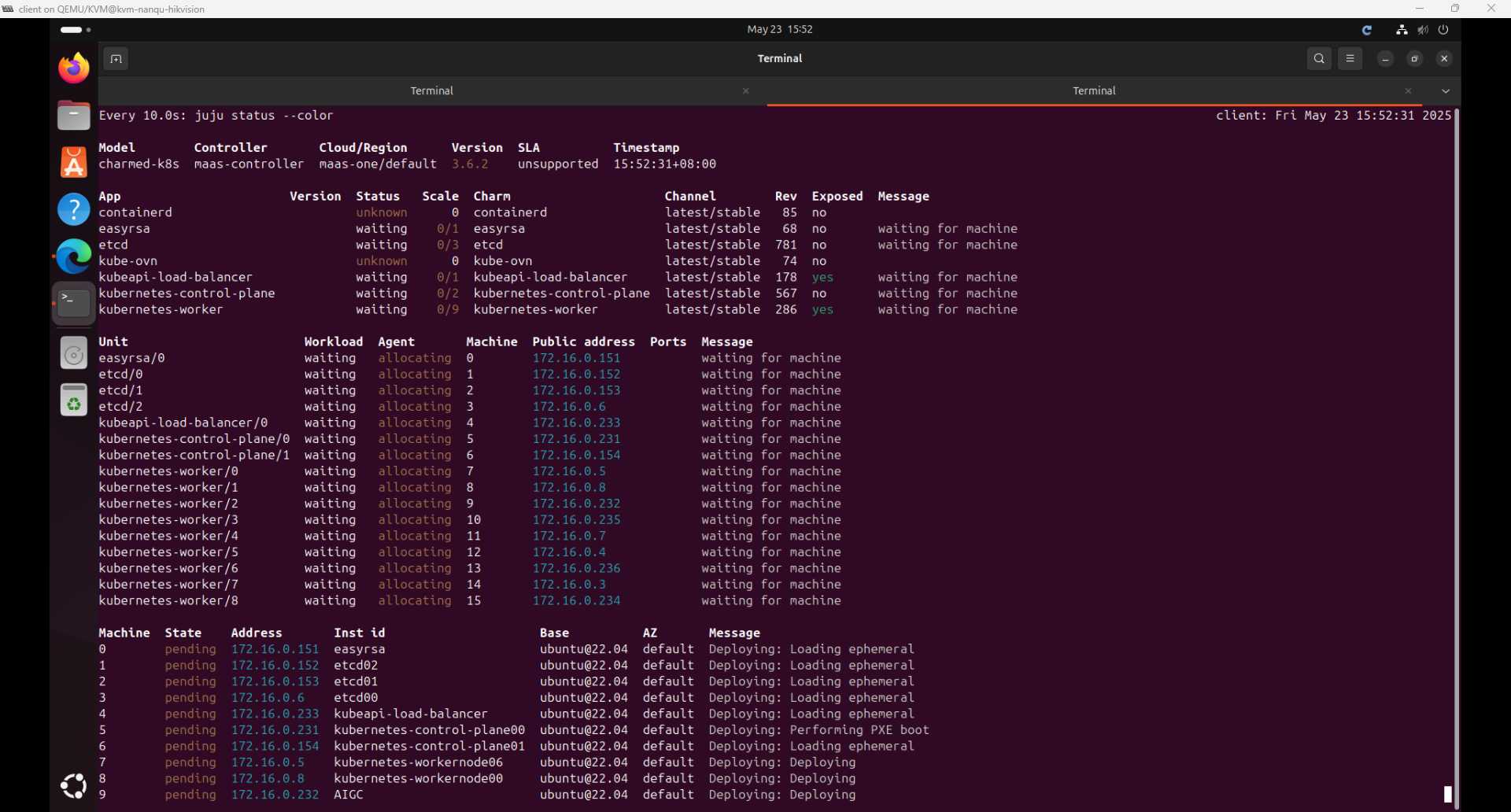
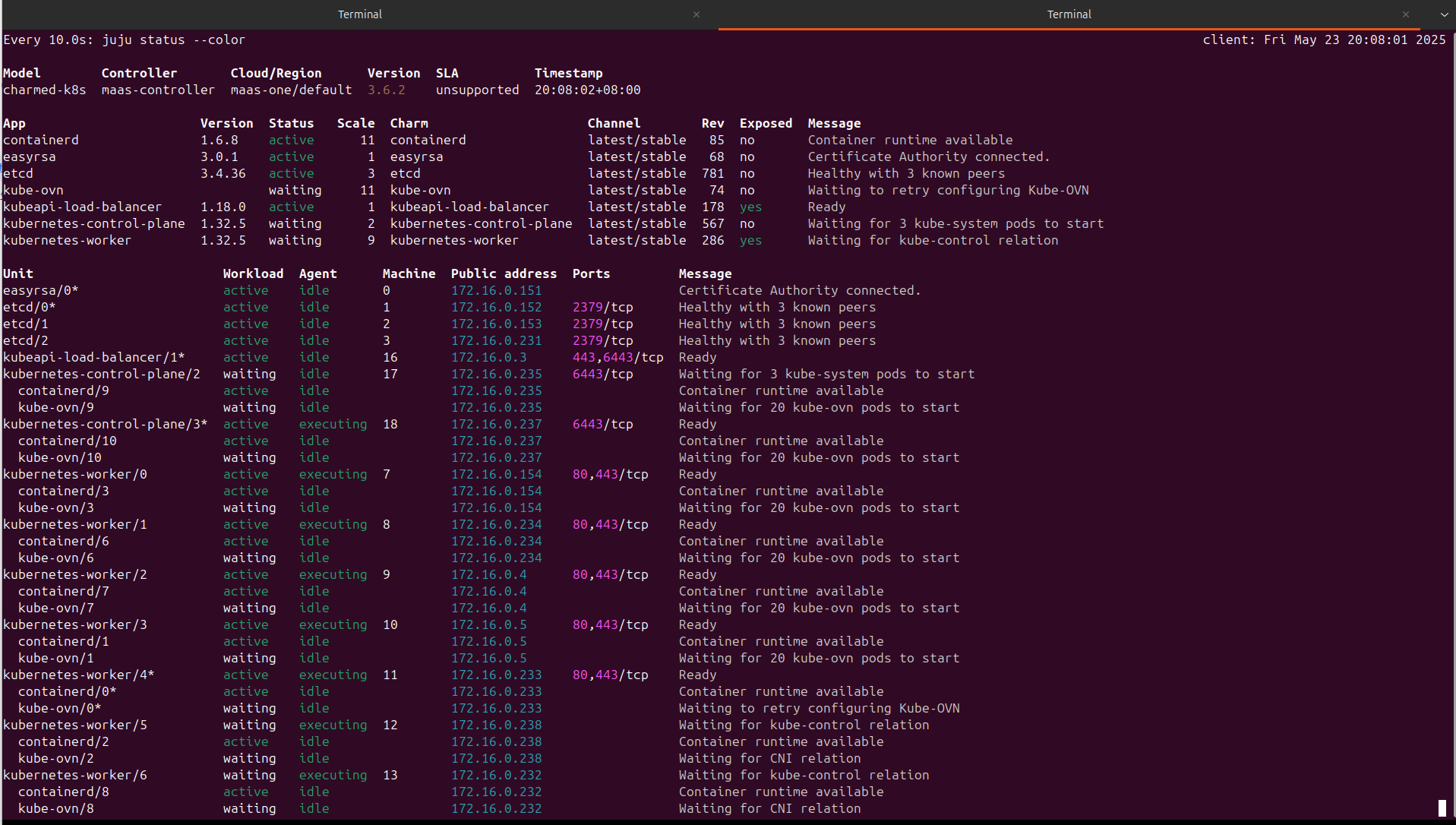
大概3小时后,部署完成
部署失败解决方案
自动化部署ubuntu系统失败
如果遇到自动化部署ubuntu系统失败的问题,一般有两种情况,
第一,超时了,默认情况下,部署系统需要在30分钟内完成,否则就会提示报错;一般超时的原因是因为,部署ubuntu系统时,会自动进行apt update和apt upgrade操作,下载的时间比较长,所以最好是确保网速够快,很大程度上可以避免这个问题。
第二,如下图所示,系统已经部署了,但是一直提示正在重启中,卡住了
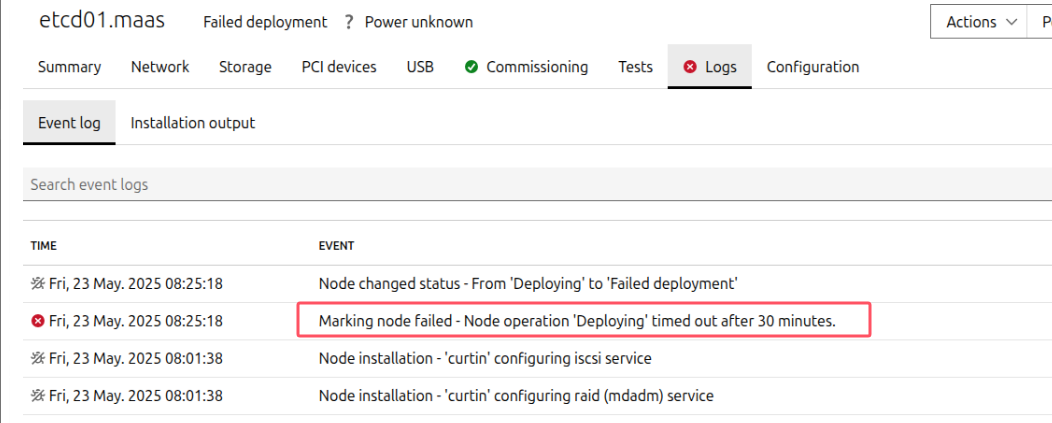
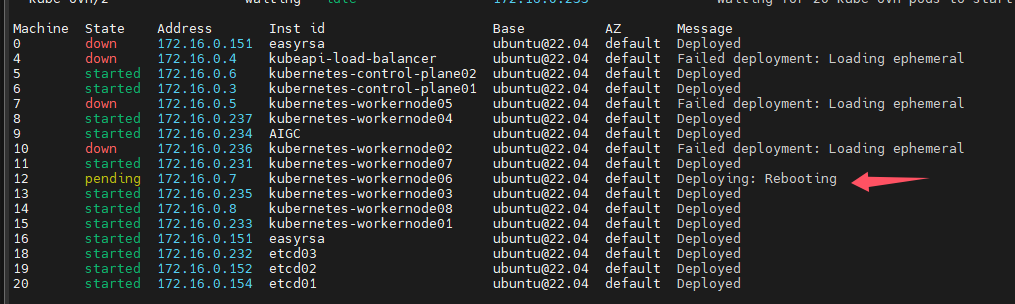
解决方案:
可以先用命令juju retry-provisioning --all让部署失败的machines自动重新开始部署ubuntu系统。
如果上面的方法不奏效的话,那就用终极方法,直接强制移除与失败的machines有关的units,例如(假设3个etcd都部署失败了):
juju remove-unit etcd/0 etcd/1 etcd/2 --force #注意一定要加上参数--force,否则,可能不会自动删除有关的machines
然后重新添加units
juju add-unit etcd -n 3
建议配置registry mirror
国内无法直接访问docker.io,建议配置registry mirror已方便下载容器镜像,可以在一开始就指定,也可以在部署之后再配置
下行命令指的是若是kubelet从docker hub拉取镜像,则将url替换为https://registry.dockermirror.com,如此就能高速下载容器镜像了
juju config containerd custom_registries='[{"host": "docker.io", "url": "https://registry.dockermirror.com"}]'
#上面的registry可能速率比较慢,也可以用下面这个2025年4月4日实测速率非常快,而且几乎所有容器镜像都能拉取
juju config containerd custom_registries='[{"host": "docker.io", "url": "https://docker.1ms.run"}]'
下面这个也行,但是我发现拉取镜像很慢,上面的很快
juju config containerd custom_registries='[{"host": "docker.io", "url": "https://docker.m.daocloud.io"}]'
用juju ssh命令随便远程连接到一个k8s节点中,然后查看config.toml内容,可以看到确实已经更改生效了
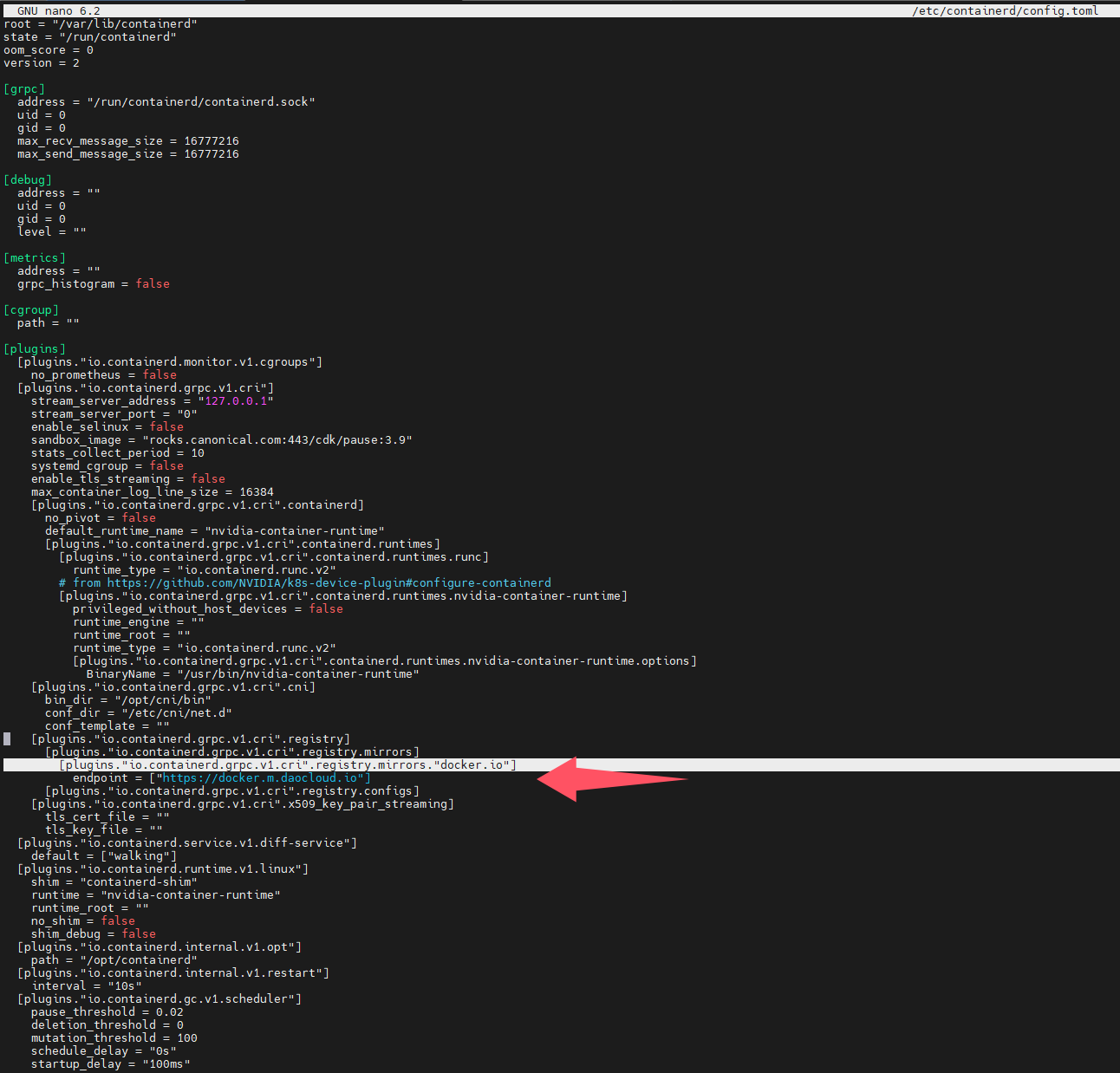
可以用juju config containerd查看当前所有的charm containerd的配置,还有配置的释义
验证已部署的charmed-kubernetes
安装kubectl
sudo snap install kubectl --classic
获取k8s集群的配置文件
mkdir .kube
juju ssh kubernetes-control-plane/leader -- cat config > ~/.kube/config
实现kubectl命令自动补全
参考资料:在 Linux 系统中安装并设置 kubectl | Kubernetes
apt-get install bash-completion -y
source /usr/share/bash-completion/bash_completion
#下面的命令仅对于当前用户生效
echo 'source <(kubectl completion bash)' >>~/.bashrc
查询k8s集群信息
kubectl cluster-info

查询nodes信息
kubectl get nodes -o wide

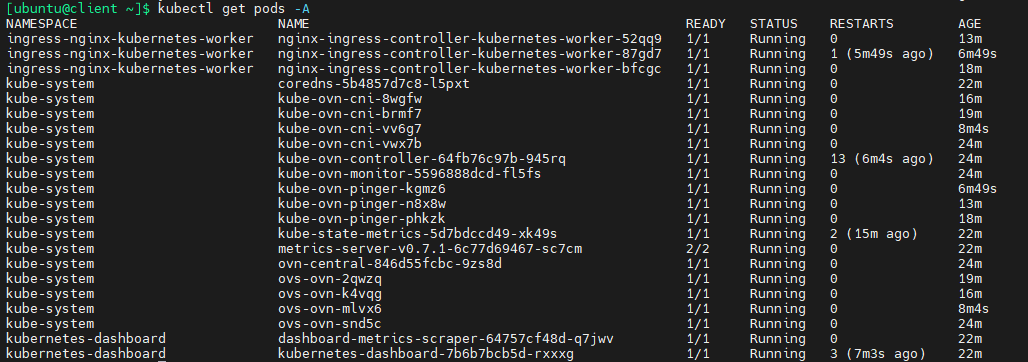
查询所有pods
kubectl get pods -A
k8s集群横向扩容
参考资料:Scaling | Ubuntu
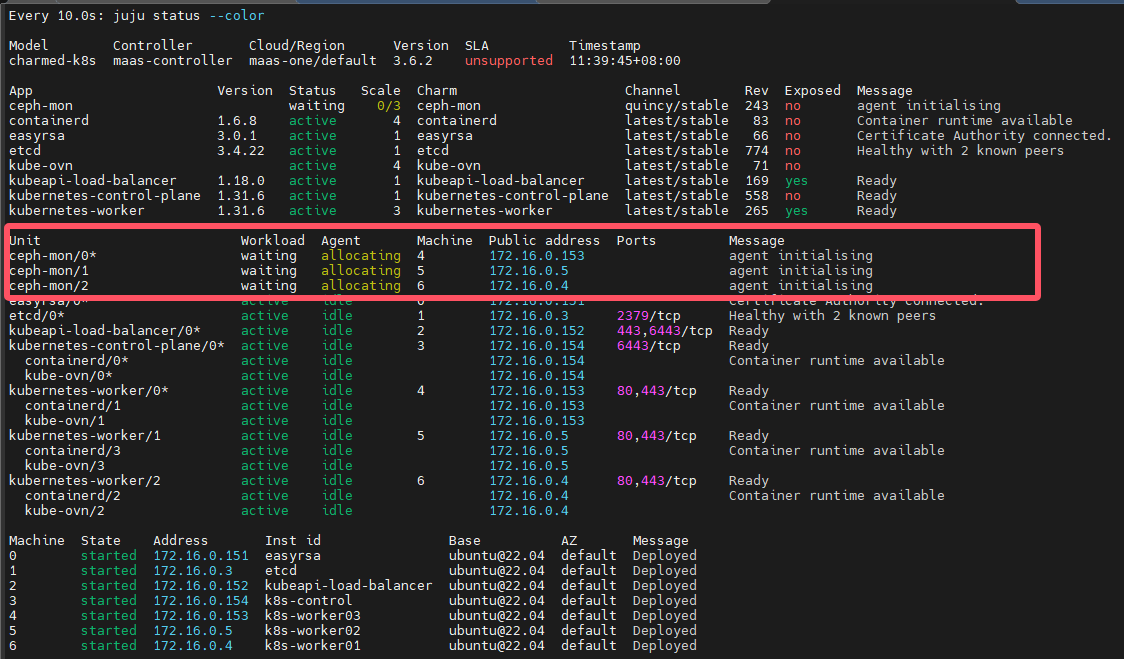
可以轻松利用juju对k8s集群进行横向扩容,控制平面与数据平面是分开扩容的,本节介绍如何进行数据平面横向扩容。
扩容worker node,下行命令表示新增两个k8s worker nodes,这里是无法直接指定contraints的,可以指定–to参数(如果指定了,则忽略contraints)。其实juju在选择新的machines时也是根据之前部署k8s时指定的contraints来定的。如何查看某个app当前的contraints呢?很简单juju constraints kubernetes-worker,所以事先要对两台machines添加相应tag
juju add-unit kubernetes-worker -n 2
查询kubernetes-worker当前的contraints
juju constraints kubernetes-worker

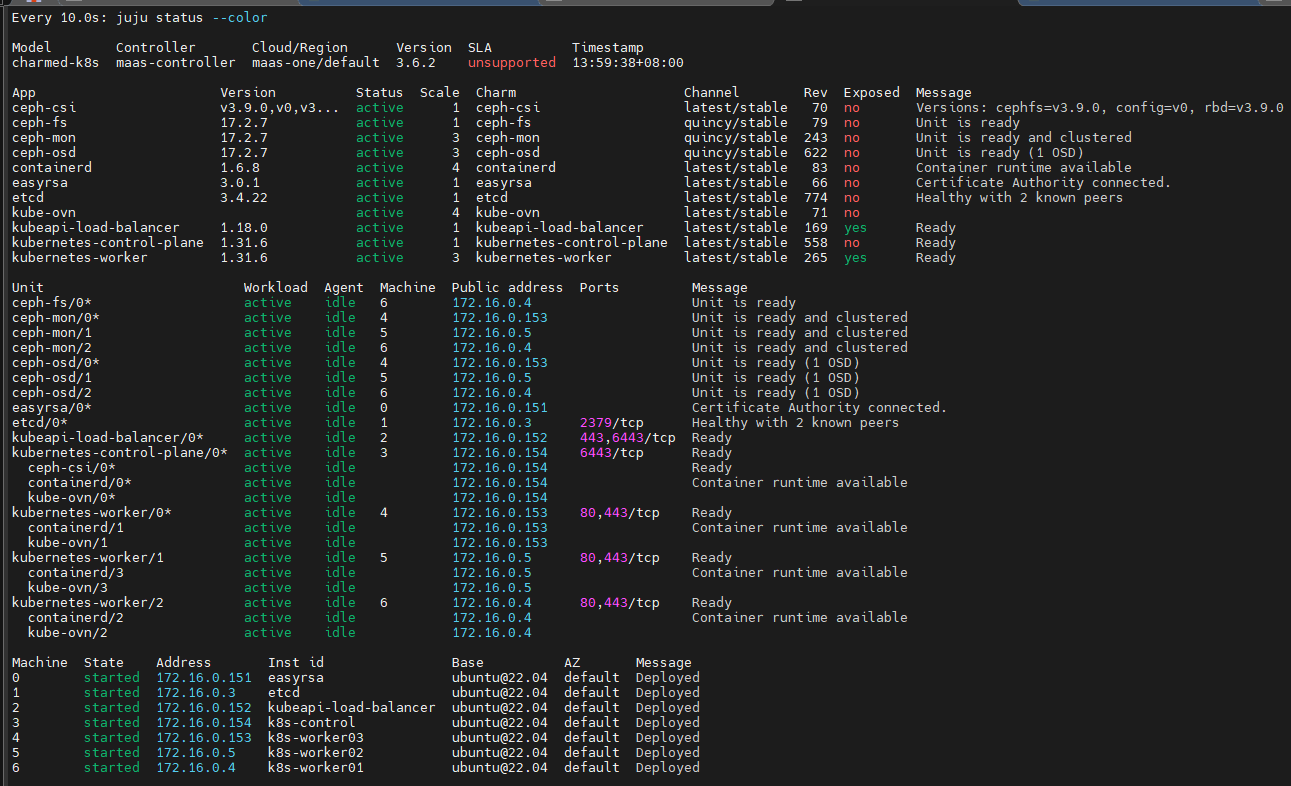
监控状态:
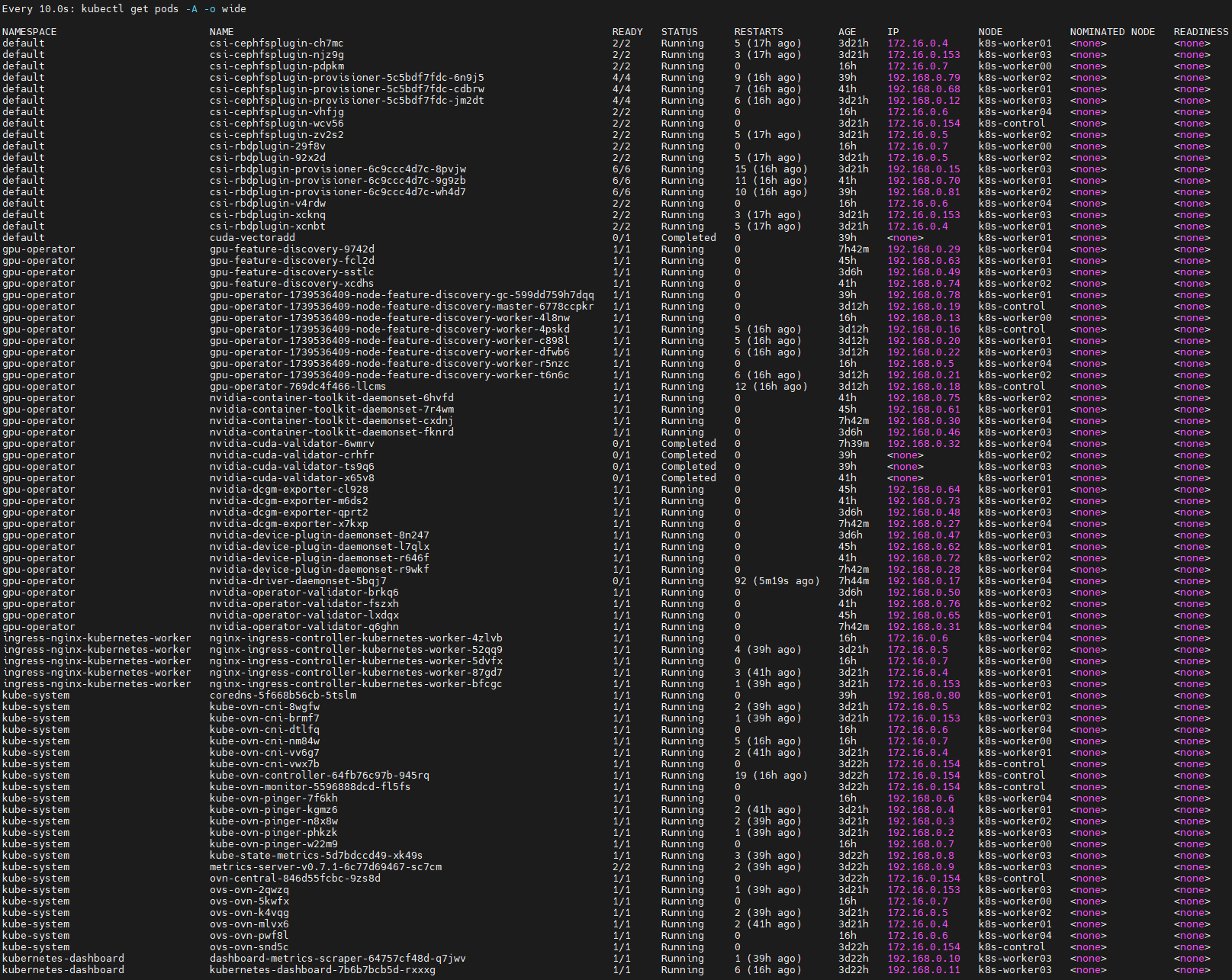
juju会指示maas部署machines,然后自动安装charm、snap等,自动进行配置,自动加入k8s集群,总之是完全自动化的,我发现在这个过程中,kubectl命令无法连接到k8s api endpoint
过一段时间后查看pods状态:
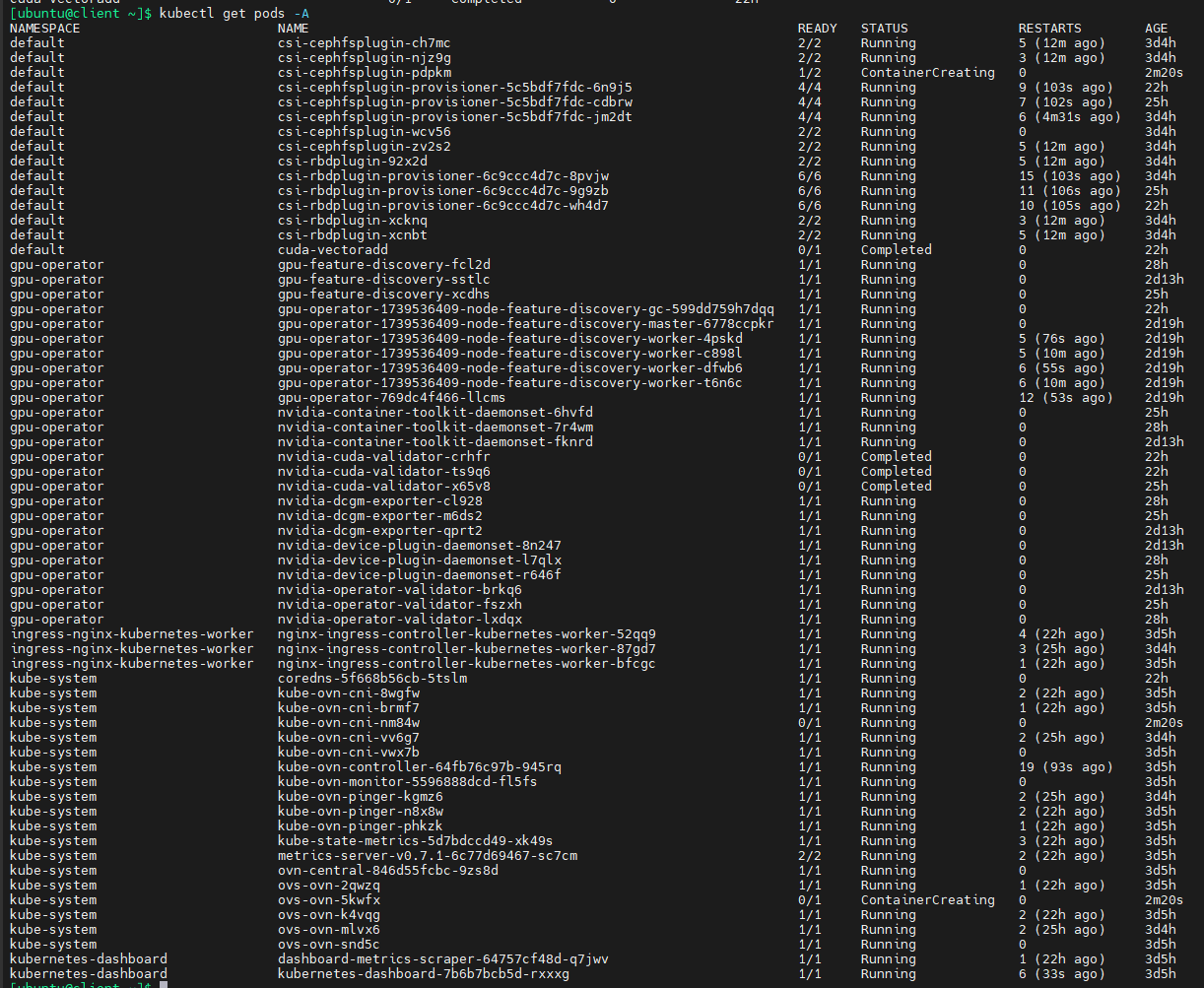
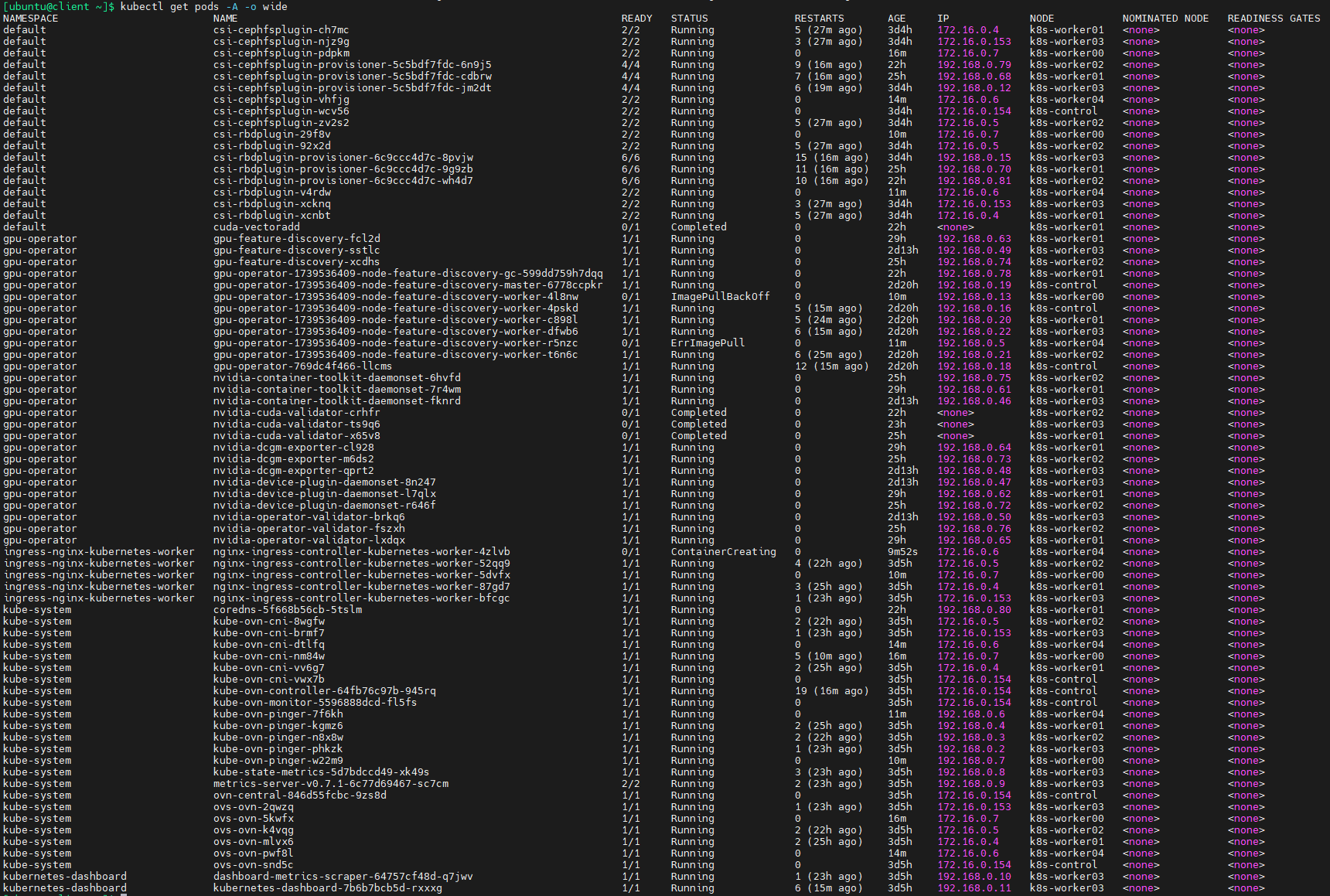
等待比较长的时间之后,所有pods都已经就绪,可以看到,NVIDIA GPU operator会自动对安装了GPU的节点(k8s-worker04)运行有关pods
同样的,如何想对etcd进行扩容,可以用下面的命令
juju add-unit etcd -n 2
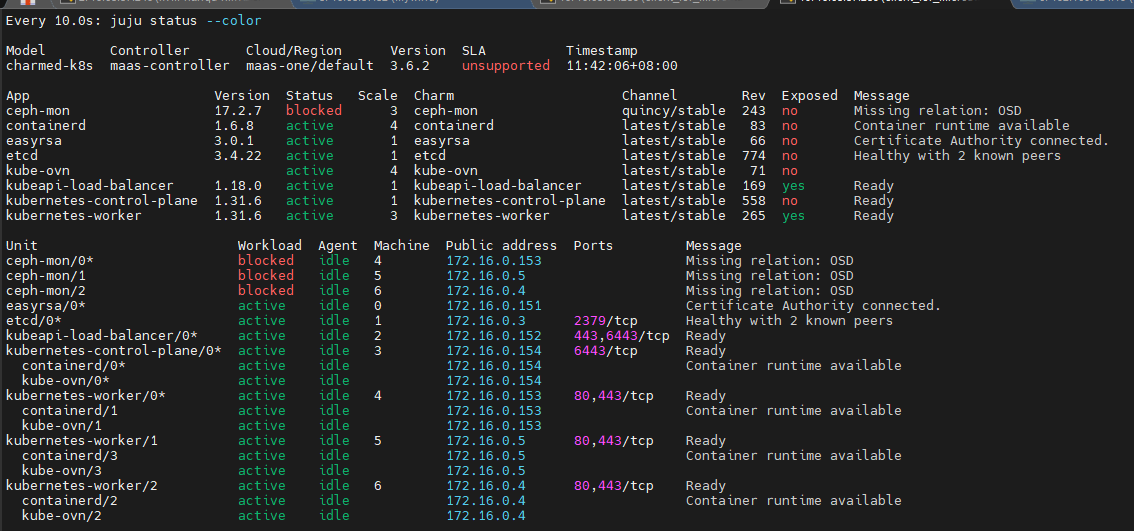
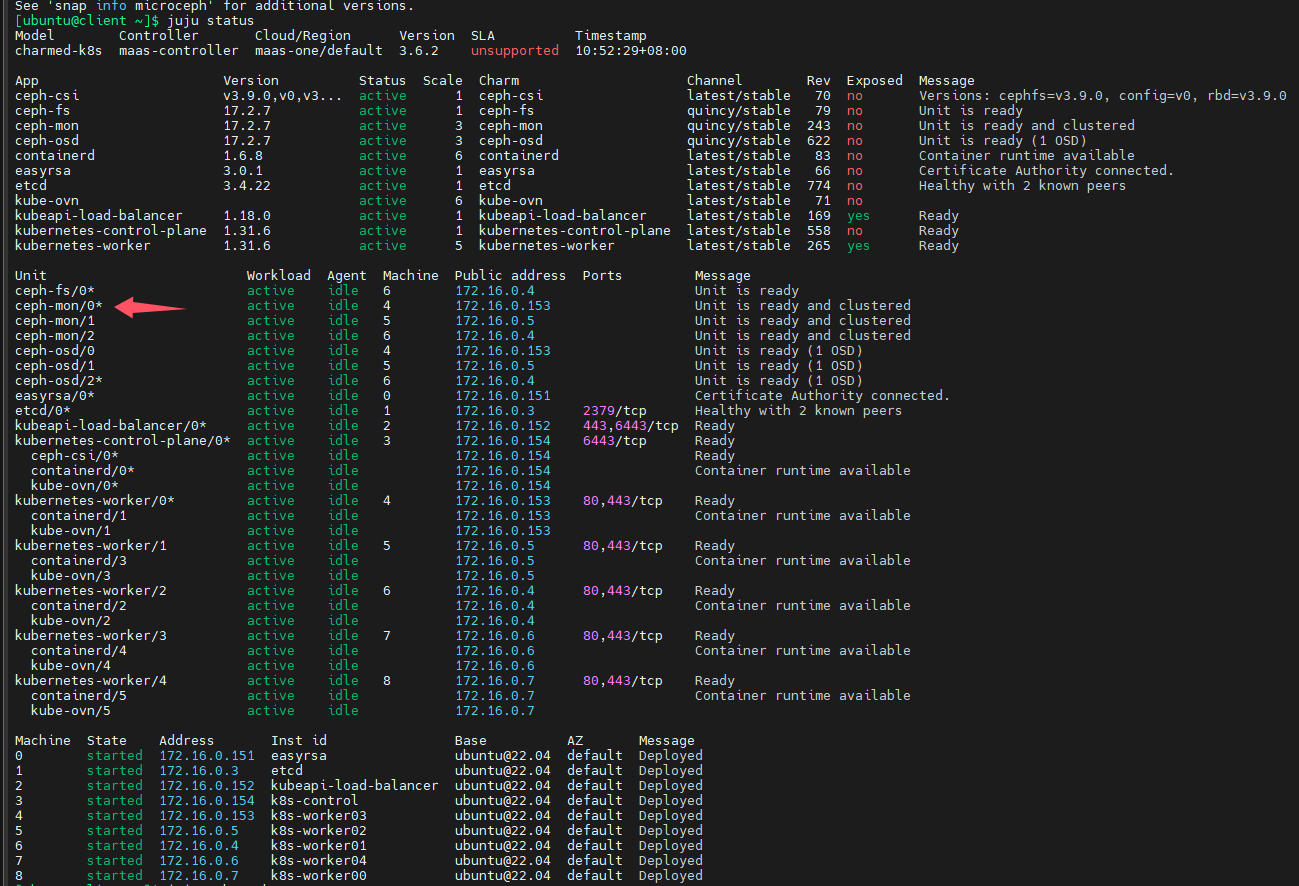
用juju快速部署ceph
可以用juju machines命令查询juju管理的machines信息

下行命令表示部署ceph-mon到指定machines上,4,5,6对应的就是上图的k8s-worker03,k8s-worker02,k8s-worker01
juju deploy -n 3 ceph-mon --to 4,5,6
查看部署状态:
很快就会看到blocked,这是正常的,因为还没有部署osd,也还没有关联起来,继续执行下面的命令即可
创建一个yaml文件,用于定义osd存储设备
cat <<EOF > ceph-osd.yaml
ceph-osd:
osd-devices: maas:ceph-osd,300G
EOF
juju deploy -n 3 ceph-osd --config ceph-osd.yaml --to 4,5,6
blocked是正常的,因为还没有关联
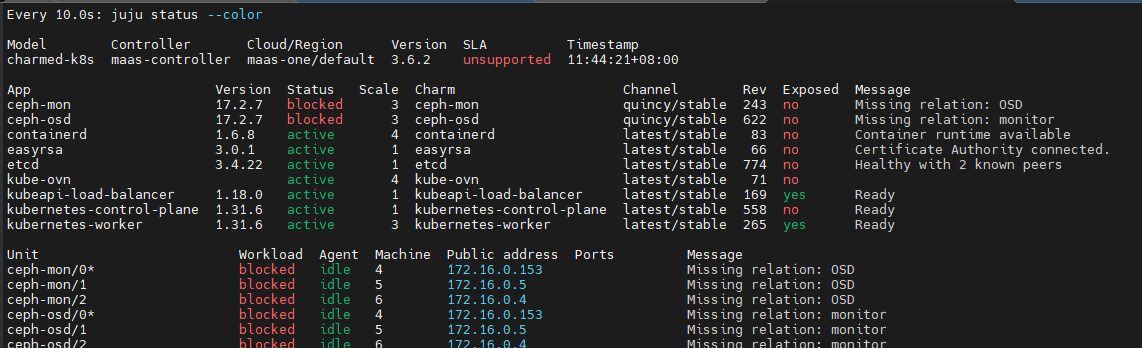
juju integrate ceph-osd ceph-mon
juju deploy ceph-csi
juju deploy ceph-fs --to 6
juju config ceph-csi cephfs-enable=True
一开始ceph-csi显示unknown是正常的,继续执行下面的命令,最终会显示active
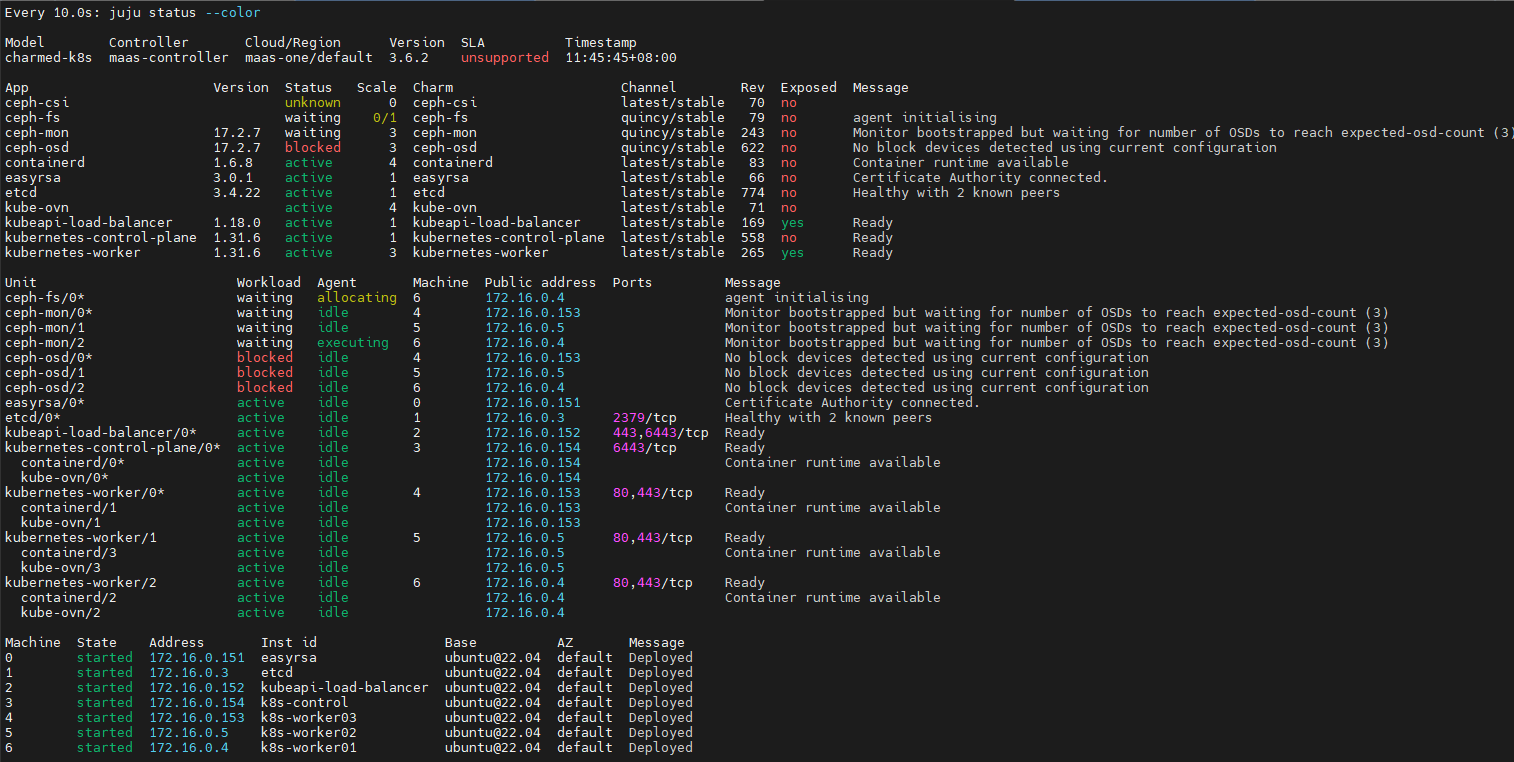
juju integrate ceph-csi:kubernetes kubernetes-control-plane:juju-info
juju integrate ceph-csi:ceph-client ceph-mon:client
juju integrate ceph-fs:ceph-mds ceph-mon:mds
监控部署状态:
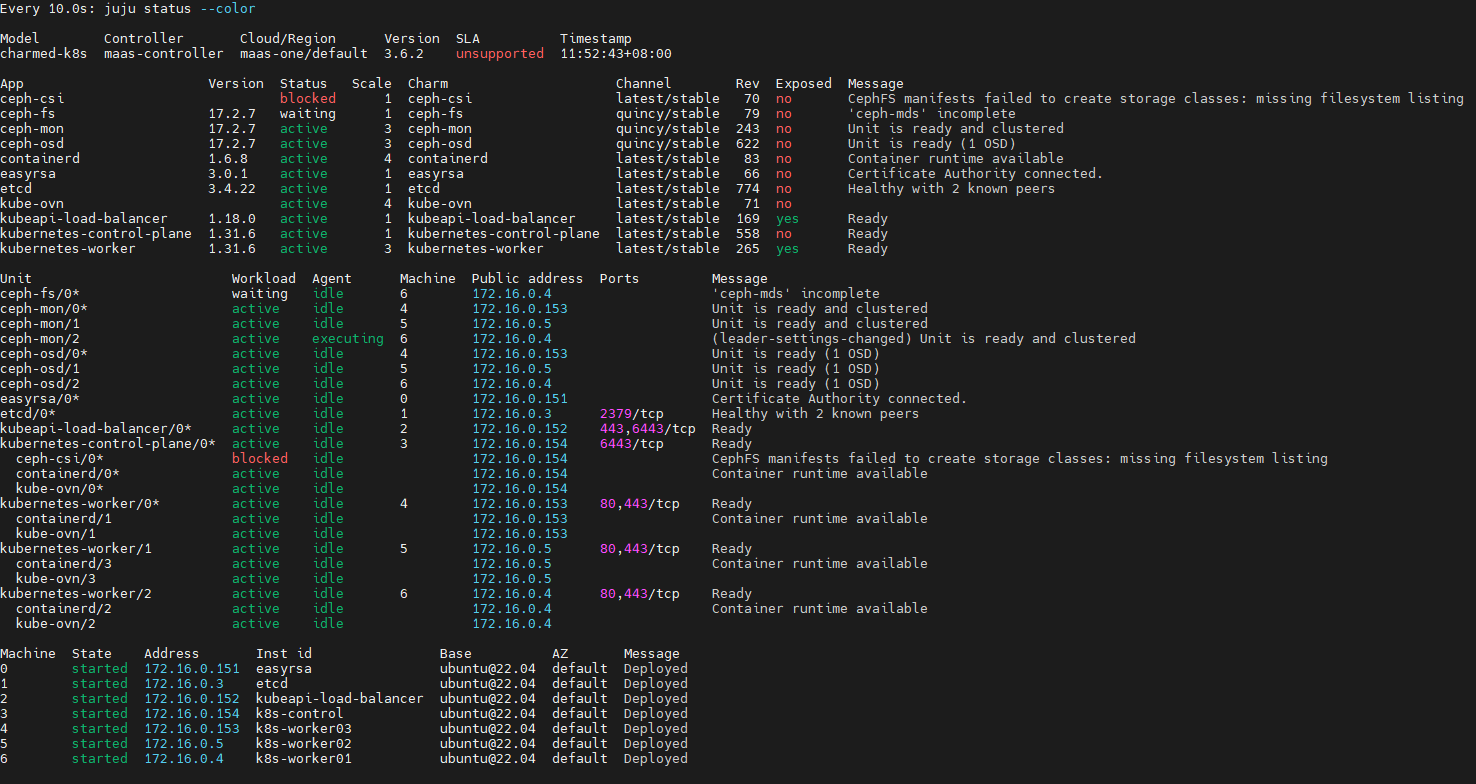
ceph部署完成
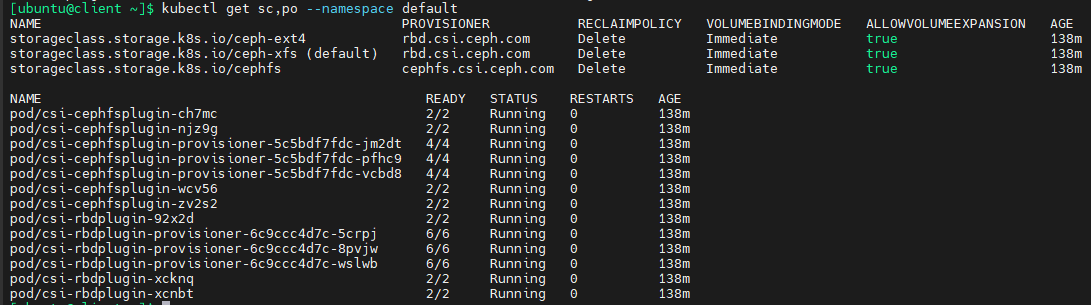
验证已部署的ceph
kubectl get sc,po --namespace default
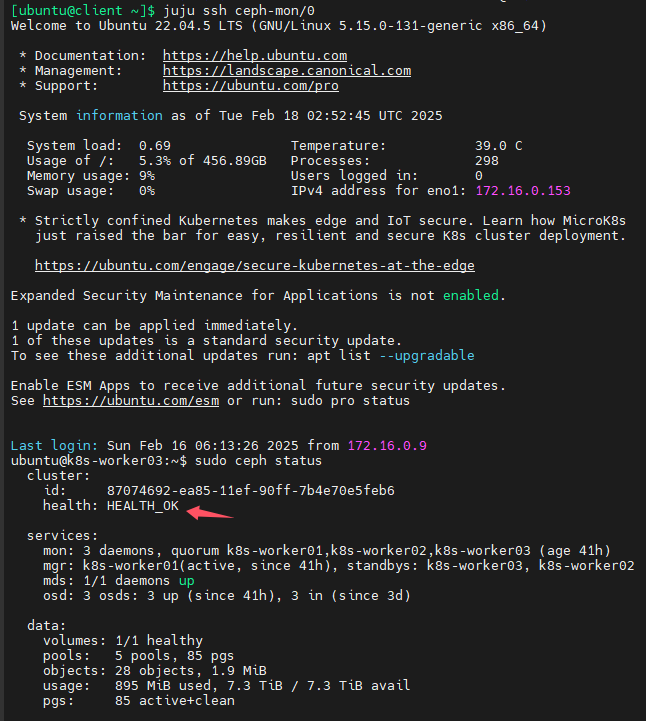
找到带有*号的mon,然后用juju ssh命令连接
juju ssh ceph-mon/0 -- sudo ceph status
部署ceph dashboard
#注意不要指定具体的machine,因为这是附属于ceph之上的,juju会自动决定部署在哪儿
juju deploy --channel quincy/stable ceph-dashboard
juju integrate ceph-dashboard:dashboard ceph-mon:dashboard
juju integrate ceph-dashboard:certificates vault:certificates
报错:可以看出先要部署vault才行
ERROR application “vault” not found (not found)

用juju部署vault
juju deploy vault
可以看到juju自动选择了一台闲置的machine,自动安装操作系统
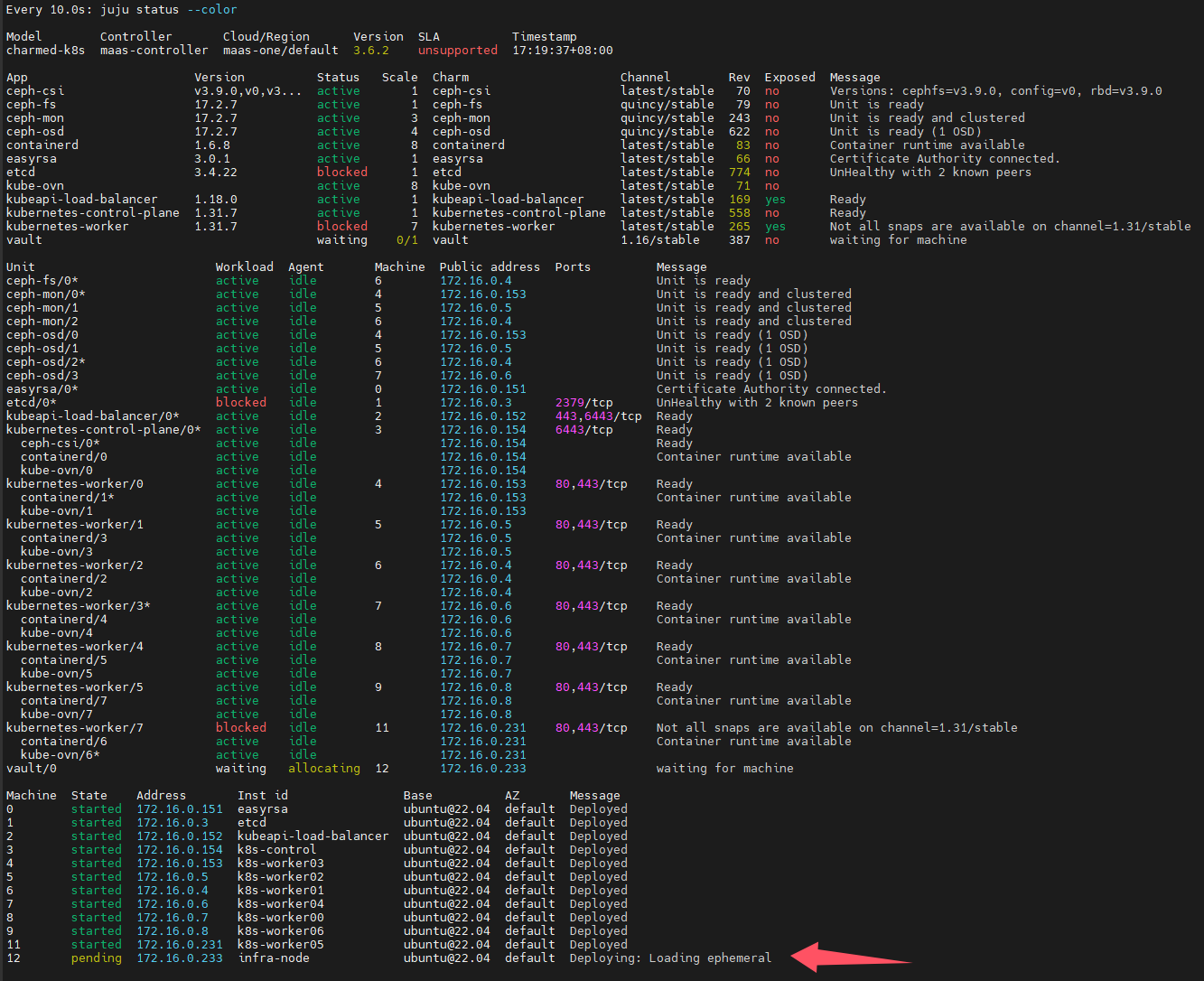
等machine部署完成后,会提示需要对vault进行初始化和解封,具体操作可以参考此文《hashicorp-vault》
完成vault初始化和解封后,还要对charm进行授权
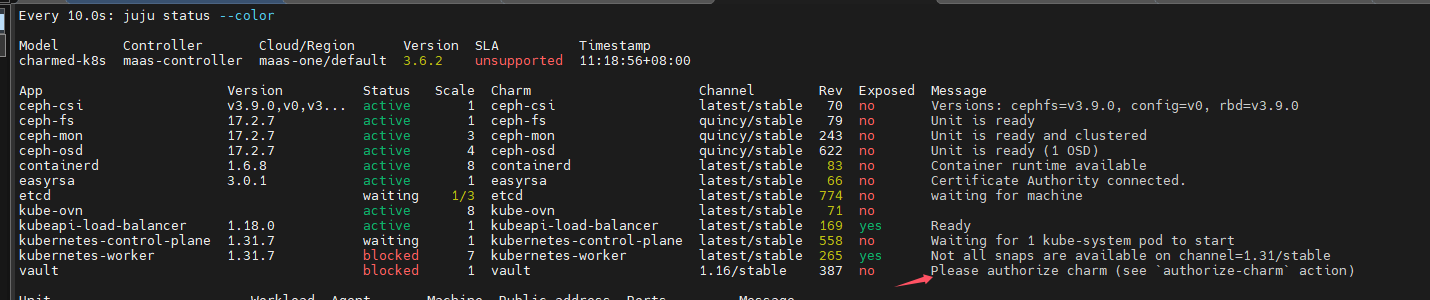
authorize charm
juju run vault/0 authorize-charm secret-id=cvl39ve675ec0r6jvocg
报错了:提示没有权限,仔细查看,日志,还能发现安装snap超时了,这很有可能是网络限制导致无法正常下载snap包
juju run vault/0 authorize-charm secret-id=cvl39ve675ec0r6jvocg
Running operation 1 with 1 task
- task 2 on unit-vault-0
Waiting for task 2...
Action id 2 failed: exit status 1
Uncaught ModelError in charm code: ERROR permission denied
Use `juju debug-log` to see the full traceback.
ERROR the following task failed:
- id "2" with return code 1
use 'juju show-task' to inspect the failure
[ubuntu@client ~]$ juju debug-log --include vault/0
unit-vault-0: 14:21:46 INFO juju.worker.uniter.operation ran "update-status" hook (via hook dispatching script: dispatch)
unit-vault-0: 14:27:14 ERROR unit.vault/0.juju-log Uncaught exception while in charm code:
Traceback (most recent call last):
File "/var/lib/juju/agents/unit-vault-0/charm/./src/charm.py", line 1405, in <module>
main(VaultOperatorCharm)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/main.py", line 553, in main
manager.run()
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/main.py", line 529, in run
self._emit()
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/main.py", line 518, in _emit
_emit_charm_event(self.charm, self.dispatcher.event_name, self._juju_context)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/main.py", line 139, in _emit_charm_event
event_to_emit.emit(*args, **kwargs)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/framework.py", line 347, in emit
framework._emit(event)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/framework.py", line 853, in _emit
self._reemit(event_path)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/framework.py", line 943, in _reemit
custom_handler(event)
File "/var/lib/juju/agents/unit-vault-0/charm/./src/charm.py", line 575, in _configure
self._install_vault_snap()
File "/var/lib/juju/agents/unit-vault-0/charm/./src/charm.py", line 1173, in _install_vault_snap
snap_cache = snap.SnapCache()
File "/var/lib/juju/agents/unit-vault-0/charm/lib/charms/operator_libs_linux/v2/snap.py", line 838, in __init__
self._load_installed_snaps()
File "/var/lib/juju/agents/unit-vault-0/charm/lib/charms/operator_libs_linux/v2/snap.py", line 888, in _load_installed_snaps
installed = self._snap_client.get_installed_snaps()
File "/var/lib/juju/agents/unit-vault-0/charm/lib/charms/operator_libs_linux/v2/snap.py", line 811, in get_installed_snaps
return self._request("GET", "snaps")
File "/var/lib/juju/agents/unit-vault-0/charm/lib/charms/operator_libs_linux/v2/snap.py", line 772, in _request
response = self._request_raw(method, path, query, headers, data)
File "/var/lib/juju/agents/unit-vault-0/charm/lib/charms/operator_libs_linux/v2/snap.py", line 793, in _request_raw
response = self.opener.open(request, timeout=self.timeout)
File "/usr/lib/python3.10/urllib/request.py", line 519, in open
response = self._open(req, data)
File "/usr/lib/python3.10/urllib/request.py", line 536, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "/usr/lib/python3.10/urllib/request.py", line 496, in _call_chain
result = func(*args)
File "/var/lib/juju/agents/unit-vault-0/charm/lib/charms/operator_libs_linux/v2/snap.py", line 709, in http_open
return self.do_open(_UnixSocketConnection, req, socket_path=self.socket_path)
File "/usr/lib/python3.10/urllib/request.py", line 1352, in do_open
r = h.getresponse()
File "/usr/lib/python3.10/http/client.py", line 1375, in getresponse
response.begin()
File "/usr/lib/python3.10/http/client.py", line 318, in begin
version, status, reason = self._read_status()
File "/usr/lib/python3.10/http/client.py", line 279, in _read_status
line = str(self.fp.readline(_MAXLINE + 1), "iso-8859-1")
File "/usr/lib/python3.10/socket.py", line 705, in readinto
return self._sock.recv_into(b)
TimeoutError: timed out
unit-vault-0: 14:27:14 ERROR juju.worker.uniter.operation hook "update-status" (via hook dispatching script: dispatch) failed: exit status 1
unit-vault-0: 14:27:17 ERROR unit.vault/0.juju-log Uncaught exception while in charm code:
Traceback (most recent call last):
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/model.py", line 3213, in _run
result = subprocess.run(args, **kwargs) # type: ignore
File "/usr/lib/python3.10/subprocess.py", line 526, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '('/var/lib/juju/tools/unit-vault-0/secret-get', 'secret:cvl39ve675ec0r6jvocg', '--format=json')' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/var/lib/juju/agents/unit-vault-0/charm/./src/charm.py", line 1405, in <module>
main(VaultOperatorCharm)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/main.py", line 553, in main
manager.run()
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/main.py", line 529, in run
self._emit()
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/main.py", line 518, in _emit
_emit_charm_event(self.charm, self.dispatcher.event_name, self._juju_context)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/main.py", line 139, in _emit_charm_event
event_to_emit.emit(*args, **kwargs)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/framework.py", line 347, in emit
framework._emit(event)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/framework.py", line 853, in _emit
self._reemit(event_path)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/framework.py", line 943, in _reemit
custom_handler(event)
File "/var/lib/juju/agents/unit-vault-0/charm/./src/charm.py", line 438, in _on_authorize_charm_action
token_secret = self.model.get_secret(id=secret_id)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/model.py", line 299, in get_secret
content = self._backend.secret_get(id=id, label=label)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/model.py", line 3579, in secret_get
result = self._run('secret-get', *args, return_output=True, use_json=True)
File "/var/lib/juju/agents/unit-vault-0/charm/venv/ops/model.py", line 3215, in _run
raise ModelError(e.stderr) from e
ops.model.ModelError: ERROR permission denied
unit-vault-0: 14:27:17 WARNING unit.vault/0.authorize-charm Uncaught ModelError in charm code: ERROR permission denied
unit-vault-0: 14:27:17 WARNING unit.vault/0.authorize-charm
unit-vault-0: 14:27:17 WARNING unit.vault/0.authorize-charm Use `juju debug-log` to see the full traceback.
unit-vault-0: 14:27:18 INFO juju.worker.uniter awaiting error resolution for "update-status" hook
unit-vault-0: 14:27:23 INFO juju.worker.uniter awaiting error resolution for "update-status" hook
unit-vault-0: 14:27:27 INFO juju.worker.uniter.operation ran "update-status" hook (via hook dispatching script: dispatch)
安装helm
sudo snap install helm --classic
用helm部署NVIDIA GPU operator
参考资料:Installing the NVIDIA GPU Operator — NVIDIA GPU Operator
部署
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
&& helm repo update
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v24.9.2
我发现即使用了代理,网速还是非常慢
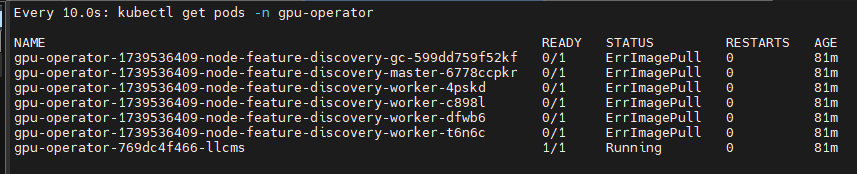

troubleshooting
nvidia-driver pods反复提示CrashLoopBackOff
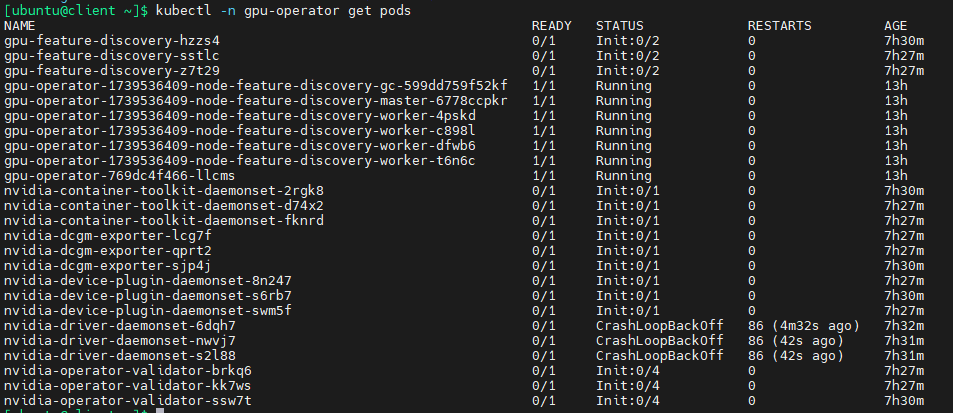
查看pods日志:
kubectl -n gpu-operator logs pods/nvidia-driver-daemonset-6dqh7 --previous
原因是无法解析archive.ubuntu.com
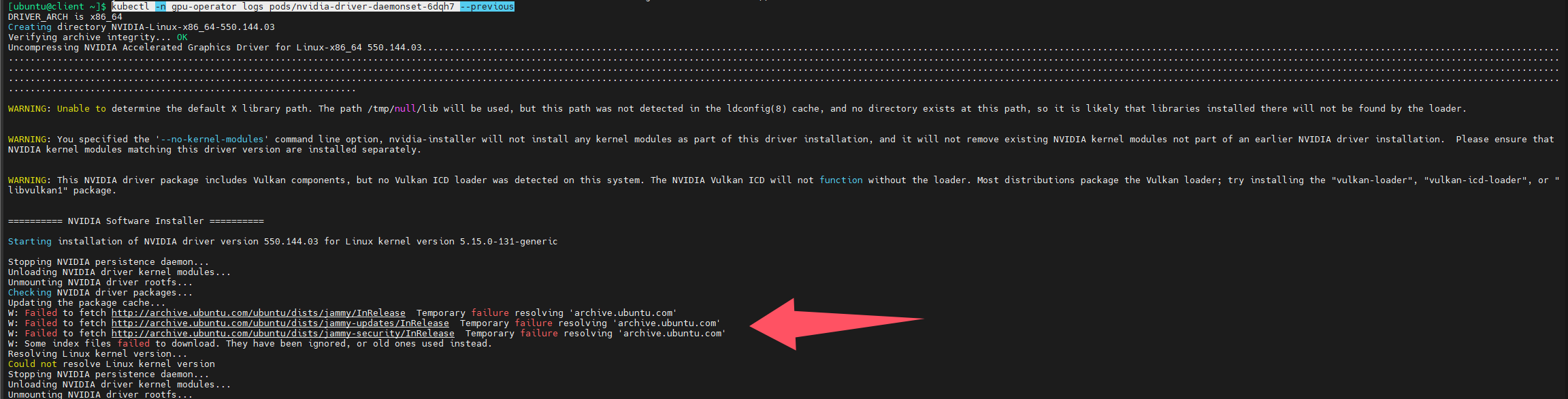
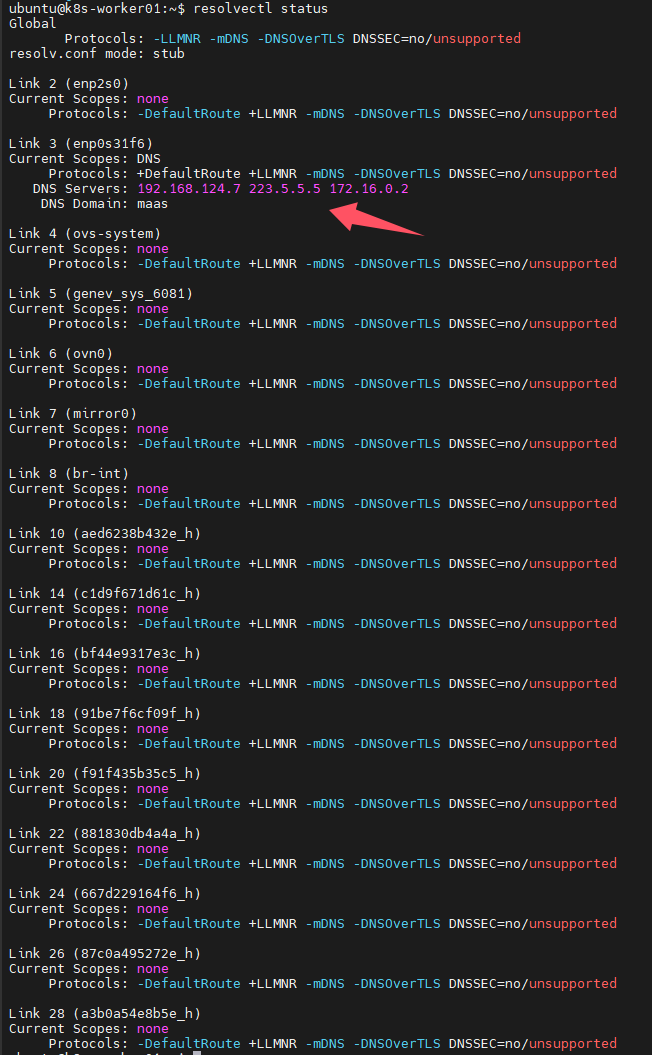
所以要从dns解析上入手,k8s是通过coredns进行域名解析的,而且默认是将自己无法解析的域名转发给所在节点配置的dns服务器,我查看了节点配置的dns,首选dns是172.16.0.2,这是maas服务器的ip地址,所以无法解析域名,解决方法就是修改dns,将192.168.124.7配置为首选dns,修改完成后,我重启了此节点(理论上可以不用重启,立即生效的)
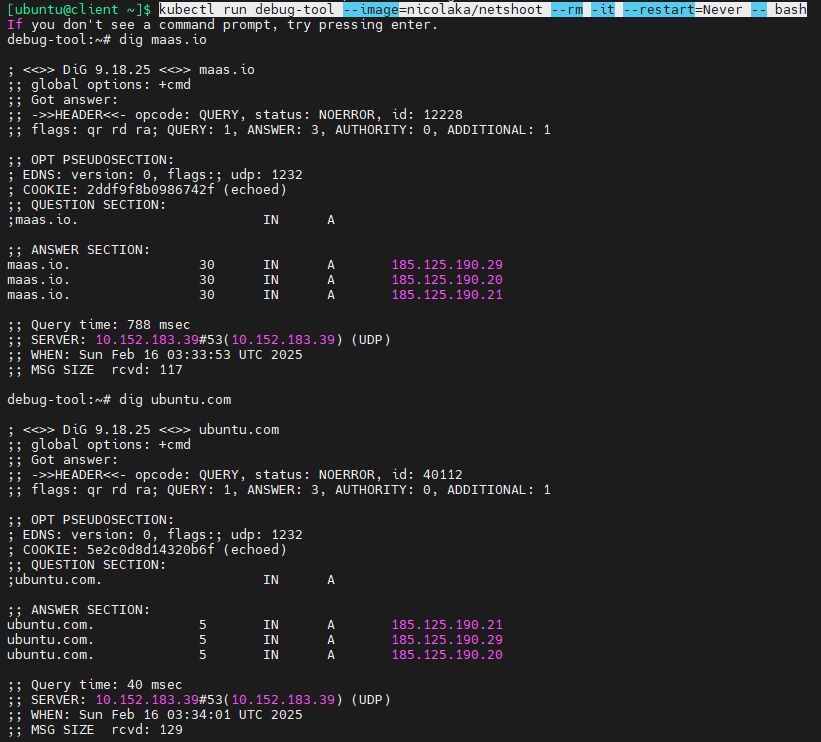
然后再次查看,发现nvidia-driver pod处于running状态了,我们还可以运行一个pod进行网络诊断:
#netshoot是专门用于在k8s进行网络诊断的pod,内置了很多常用网络诊断工具,如dig,nslookup,tcpdump等等
kubectl run debug-tool --image=nicolaka/netshoot --rm -it --restart=Never -- bash
dig ubuntu.com
可以看到可以解析外部域名
另外一种情况:secure boot
kubectl -n gpu-operator logs pods/nvidia-driver-daemonset-nwvj7 --previous
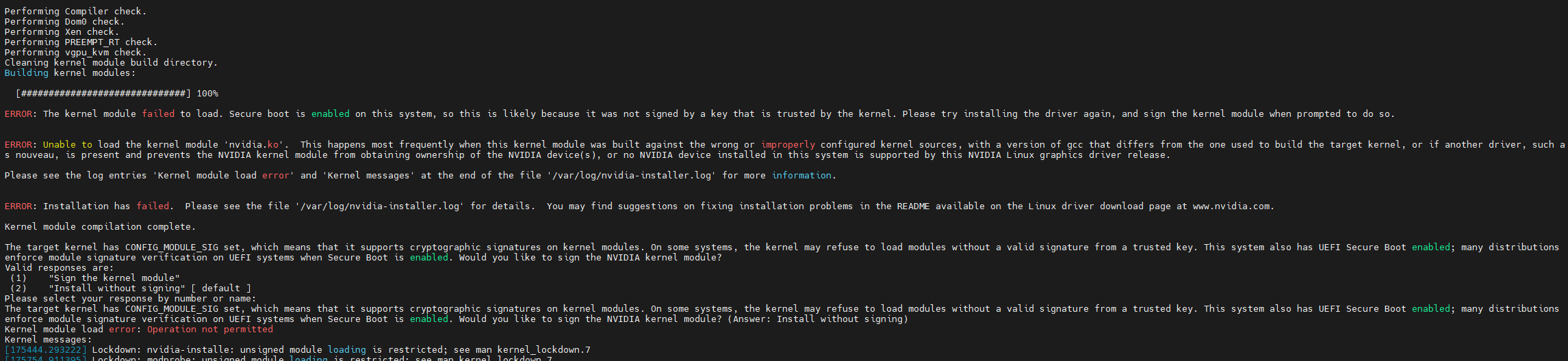
从日志可以看出是因为节点启用了secure boot,导致未签名的NVIDIA驱动无法安装,需要禁用secure boot,在我写作本文时,NVIDIA GPU operator还不支持secure boot,官方文档明确写明了Troubleshooting the NVIDIA GPU Operator — NVIDIA GPU Operator
DRIVER_ARCH is x86_64
Creating directory NVIDIA-Linux-x86_64-550.144.03
Verifying archive integrity... OK
Uncompressing NVIDIA Accelerated Graphics Driver for Linux-x86_64 550.144.03........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
WARNING: Unable to determine the default X library path. The path /tmp/null/lib will be used, but this path was not detected in the ldconfig(8) cache, and no directory exists at this path, so it is likely that libraries installed there will not be found by the loader.
WARNING: You specified the '--no-kernel-modules' command line option, nvidia-installer will not install any kernel modules as part of this driver installation, and it will not remove existing NVIDIA kernel modules not part of an earlier NVIDIA driver installation. Please ensure that NVIDIA kernel modules matching this driver version are installed separately.
WARNING: This NVIDIA driver package includes Vulkan components, but no Vulkan ICD loader was detected on this system. The NVIDIA Vulkan ICD will not function without the loader. Most distributions package the Vulkan loader; try installing the "vulkan-loader", "vulkan-icd-loader", or "libvulkan1" package.
========== NVIDIA Software Installer ==========
Starting installation of NVIDIA driver version 550.144.03 for Linux kernel version 5.15.0-131-generic
Stopping NVIDIA persistence daemon...
Unloading NVIDIA driver kernel modules...
Unmounting NVIDIA driver rootfs...
Checking NVIDIA driver packages...
Updating the package cache...
Resolving Linux kernel version...
Proceeding with Linux kernel version 5.15.0-131-generic
Installing Linux kernel headers...
Installing Linux kernel module files...
Generating Linux kernel version string...
Compiling NVIDIA driver kernel modules...
warning: the compiler differs from the one used to build the kernel
The kernel was built by: gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
You are using: gcc (Ubuntu 12.3.0-1ubuntu1~22.04) 12.3.0
/usr/src/nvidia-550.144.03/kernel/nvidia-drm/nvidia-drm-drv.c: In function 'nv_drm_register_drm_device':
/usr/src/nvidia-550.144.03/kernel/nvidia-drm/nvidia-drm-drv.c:1817:5: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement]
1817 | bool bus_is_pci =
| ^~~~
Skipping BTF generation for /usr/src/nvidia-550.144.03/kernel/nvidia-modeset.ko due to unavailability of vmlinux
Skipping BTF generation for /usr/src/nvidia-550.144.03/kernel/nvidia-peermem.ko due to unavailability of vmlinux
Skipping BTF generation for /usr/src/nvidia-550.144.03/kernel/nvidia-drm.ko due to unavailability of vmlinux
Skipping BTF generation for /usr/src/nvidia-550.144.03/kernel/nvidia-uvm.ko due to unavailability of vmlinux
Skipping BTF generation for /usr/src/nvidia-550.144.03/kernel/nvidia.ko due to unavailability of vmlinux
Relinking NVIDIA driver kernel modules...
Building NVIDIA driver package nvidia-modules-5.15.0-131...
Installing NVIDIA driver kernel modules...
WARNING: The nvidia-drm module will not be installed. As a result, DRM-KMS will not function with this installation of the NVIDIA driver.
ERROR: Unable to open 'kernel/dkms.conf' for copying (No such file or directory)
Welcome to the NVIDIA Software Installer for Unix/Linux
Detected 8 CPUs online; setting concurrency level to 8.
Unable to locate any tools for listing initramfs contents.
Unable to scan initramfs: no tool found
Installing NVIDIA driver version 550.144.03.
Performing CC sanity check with CC="/usr/bin/cc".
Performing CC check.
Kernel source path: '/lib/modules/5.15.0-131-generic/build'
Kernel output path: '/lib/modules/5.15.0-131-generic/build'
Performing Compiler check.
Performing Dom0 check.
Performing Xen check.
Performing PREEMPT_RT check.
Performing vgpu_kvm check.
Cleaning kernel module build directory.
Building kernel modules:
[##############################] 100%
ERROR: The kernel module failed to load. Secure boot is enabled on this system, so this is likely because it was not signed by a key that is trusted by the kernel. Please try installing the driver again, and sign the kernel module when prompted to do so.
ERROR: Unable to load the kernel module 'nvidia.ko'. This happens most frequently when this kernel module was built against the wrong or improperly configured kernel sources, with a version of gcc that differs from the one used to build the target kernel, or if another driver, such as nouveau, is present and prevents the NVIDIA kernel module from obtaining ownership of the NVIDIA device(s), or no NVIDIA device installed in this system is supported by this NVIDIA Linux graphics driver release.
Please see the log entries 'Kernel module load error' and 'Kernel messages' at the end of the file '/var/log/nvidia-installer.log' for more information.
ERROR: Installation has failed. Please see the file '/var/log/nvidia-installer.log' for details. You may find suggestions on fixing installation problems in the README available on the Linux driver download page at www.nvidia.com.
Kernel module compilation complete.
The target kernel has CONFIG_MODULE_SIG set, which means that it supports cryptographic signatures on kernel modules. On some systems, the kernel may refuse to load modules without a valid signature from a trusted key. This system also has UEFI Secure Boot enabled; many distributions enforce module signature verification on UEFI systems when Secure Boot is enabled. Would you like to sign the NVIDIA kernel module?
Valid responses are:
(1) "Sign the kernel module"
(2) "Install without signing" [ default ]
Please select your response by number or name:
The target kernel has CONFIG_MODULE_SIG set, which means that it supports cryptographic signatures on kernel modules. On some systems, the kernel may refuse to load modules without a valid signature from a trusted key. This system also has UEFI Secure Boot enabled; many distributions enforce module signature verification on UEFI systems when Secure Boot is enabled. Would you like to sign the NVIDIA kernel module? (Answer: Install without signing)
Kernel module load error: Operation not permitted
Kernel messages:
[175444.293222] Lockdown: nvidia-installe: unsigned module loading is restricted; see man kernel_lockdown.7
[175754.911395] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175816.021475] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175816.772945] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175826.253934] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175827.512775] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175836.436402] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175837.699633] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175846.558090] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175847.797583] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175856.503291] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175857.772986] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175865.838000] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175866.536829] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175875.865878] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175876.550465] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175886.068335] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175887.193894] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175896.422361] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175897.575308] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175906.200031] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175907.407931] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175916.384652] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175917.574073] Lockdown: modprobe: unsigned module loading is restricted; see man kernel_lockdown.7
[175920.521158] Lockdown: nvidia-installe: unsigned module loading is restricted; see man kernel_lockdown.7
Stopping NVIDIA persistence daemon...
Unloading NVIDIA driver kernel modules...
Unmounting NVIDIA driver rootfs...
我禁用secure boot后问题解决,pod正常运行
nvidia-driver-daemonset pod反复重启,状态信息是CrashLoopBackOff
如下图所示,有两个k8s节点反复重启
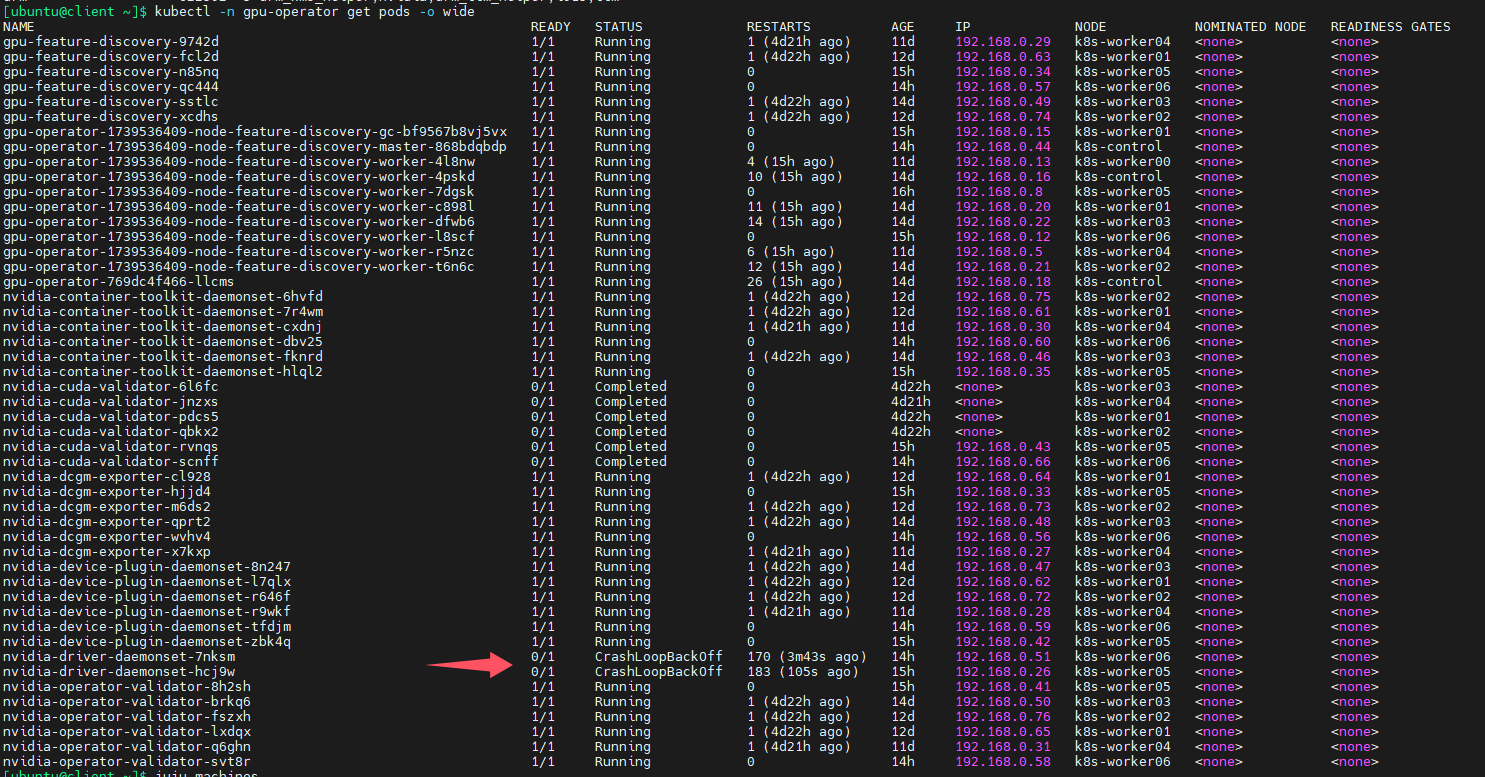
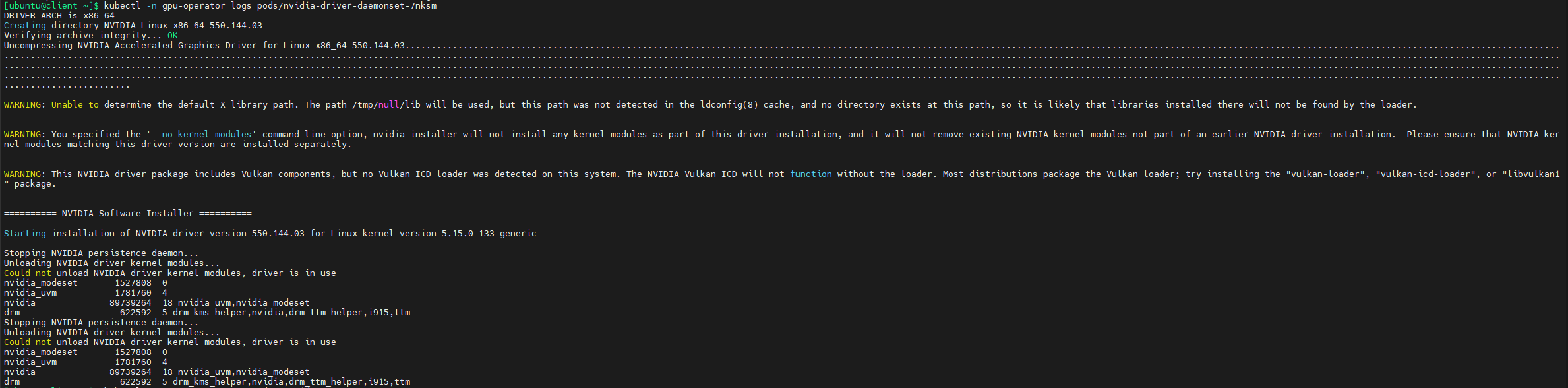
查询pod日志,发现警告信息,如下图,提示无法卸载NVIDIA driver kernel modules,driver is in use
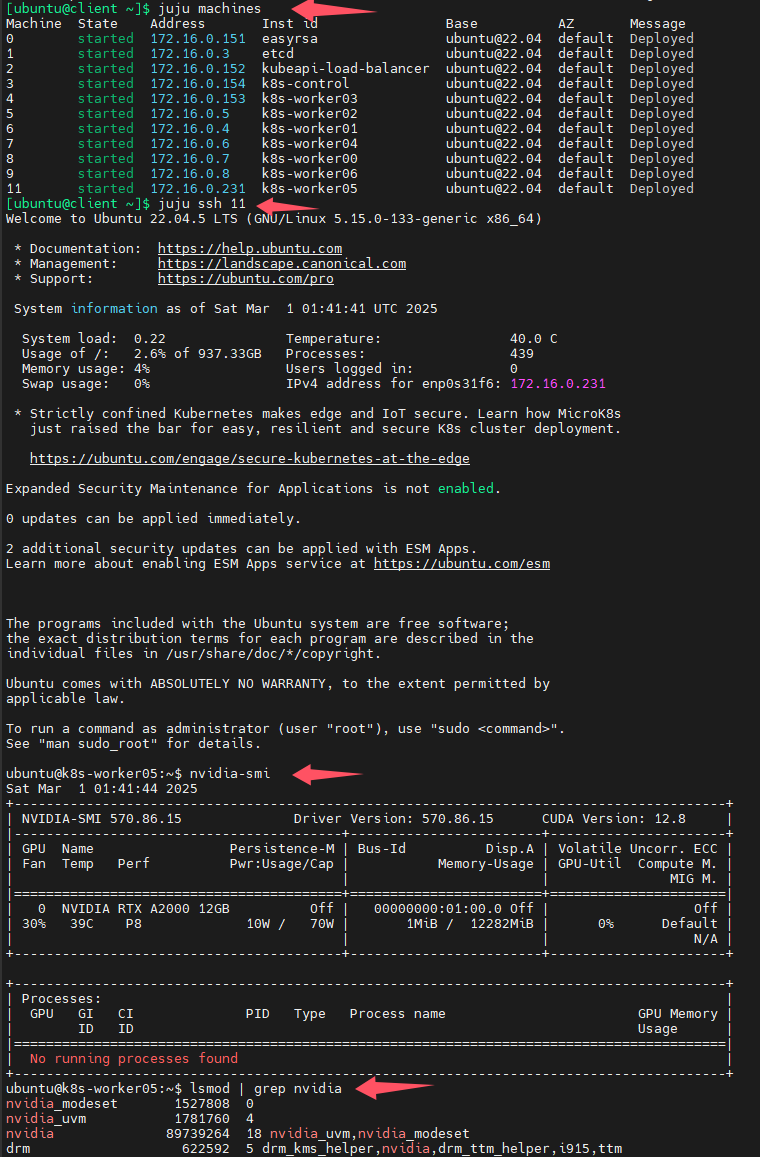
然后我ssh连接到有问题的k8s节点,输入nvidia-smi命令查询此节点是否已经正常安装了NVIDIA驱动,从下图可以看出k8s节点已经正常安装了NVIDIA驱动,于是我重启了有问题的k8s节点,问题解决。
验证
参考资料:Installing the NVIDIA GPU Operator — NVIDIA GPU Operator
创建一个yaml文件
cat <<EOF > cuda-vectoradd.yaml
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1
EOF
运行pod
kubectl apply -f cuda-vectoradd.yaml
查看pod日志
kubectl logs pod/cuda-vectoradd
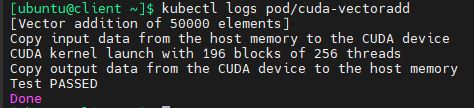
检查安装的驱动程序版本
将COS与charmed kubernetes集成
参考资料:How to integrate with COS Lite
COS(Canonical Observability Stack)可提供日志、监控和告警服务,其利用的是开源的Prometheus、grafana和ELK
添加一个新的model
juju add-model --config logging-config='<root>=DEBUG' cos-cluster
用juju部署k8s
参考资料:Charmhub | Deploy Kubernetes using Charmhub - The Open Operator Collection
juju deploy k8s --constraints="tags=charmed-k8s-node" --base=ubuntu@24.04 --config load-balancer-enabled=true containerd-custom-registries='[{"host": "docker.io", "url": "https://registry.dockermirror.com"}]'
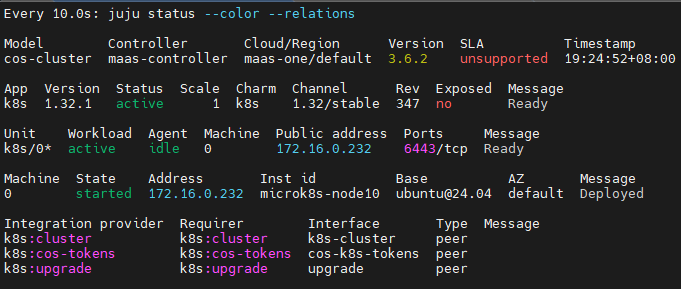
查看部署状态
watch -n 10 -c juju status --color --relations
如果部署k8s时,忘记设置config,部署后还可以再更改,如:
juju config k8s load-balancer-enabled=true containerd-custom-registries='[{"host": "docker.io", "url": "https://registry.dockermirror.com"}]'
等到上图中的k8s app处于ready状态后,再执行下面的命令
sudo apt install yq -y #安装yg
juju run k8s/leader get-kubeconfig | yq eval '.kubeconfig' > k8s-kubeconfig #注意这条命令可能会报错,如果报错可以先
#输入juju run k8s/leader get-kubeconfig 此命令会输出一个yaml文件内容,然后用nano命令手动创建k8s-kubeconfig文件
k8s-kubeconfig文件内容如下所示,这其实是一个yaml格式的文件,所以缩进千万不能错误,否则之后的命令会报错,提示ERROR failed to open kubernetes client: unable to determine legacy status for namespace "cos-lite": Unauthorized
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURIRENDQWdTZ0F3SUJBZ0lSQUlJdTFBWmVsbkdNN1RUYkh1dW1yNnN3RFFZSktvWklodmNOQVFFTEJRQXcKR0RFV01CUUdBMVVFQXhNTmEzVmlaWEp1WlhSbGN5MWpZVEFlRncweU5UQXpNREV4TURVd01ERmFGdzAwTlRBegpNREV4TURVd01ERmFNQmd4RmpBVUJnTlZCQU1URFd0MVltVnlibVYwWlhNdFkyRXdnZ0VpTUEwR0NTcUdTSWIzCkRRRUJBUVVBQTRJQkR3QXdnZ0VLQW9JQkFRQ3lRRlFWaTljUUFTNWJyS3pQYWxCOE5FUHBOVVliRlJ6MkYvTVQKRWJiOU1VNDI2L3VDUXVuZWYwQUNLQUdTZm9vcFJ0eEdSRFNYcFFxeHBYMzB3TkFmdTR1MTVMSWpURlJxNzhCTApRU1BiSktRMzdOZWVCU2xpQm5zVUl1cE5SMlpLQVhZNmh3MFVCdmNEdG9aNkR3YjU2NnFTUFk4akNNUzhUclpRClp1aElSN2g4U3lZMm56Ulc1amFzTTJTM0dsc0ZSbWNnMmFnbHFHRWZ6QjhVWityRTlJbW5YbDBBYllGejU1aU4KVHhpSFpQM2U0a29xSUdNSDFZZUdVemM5RUhPaVBmRFJnTFN0NG53aENzV2RwTnpiNnRaNzdYZVpBbFl1ZXBTSQovU3YvS3RSN2xuWlFucXZ6c0ZXRWRldW5Zdm95MFE4bW1LNlkwWk05ME90OFNKV1BBZ01CQUFHallUQmZNQTRHCkExVWREd0VCL3dRRUF3SUNoREFkQmdOVkhTVUVGakFVQmdnckJnRUZCUWNEQWdZSUt3WUJCUVVIQXdFd0R3WUQKVlIwVEFRSC9CQVV3QXdFQi96QWRCZ05WSFE0RUZnUVVRTjF0dk9LNVpyRXlsMkl4Q0VrMHRBaUI5YjR3RFFZSgpLb1pJaHZjTkFRRUxCUUFEZ2dFQkFEc0d4MG45ZzRPOUd6K3VzWHhoNk5FL2M2aCt4Y1JsV05KakU0UlpDcFBhCndmMUJMNWxnZTJENStOSHdMampEUU5IcDQ0aTBFUHdUOTk4Vko2REh2eHBzYnBMdkhTbDZrbDNNd3N4ajNZUFcKaHV6UDArVW1qMkdYL2J2M0IvTmROUlFNbU5ycEo4SXEvTEs1dFlnUkZrdjgrZDNmQkRSVkhUK3NvZEJhMSt4QwpkeW1mZGM5bFE5K1BPb2xaZzZHRWRMYldkYzlvNEEvaGx4aGtKNXdVL2FXSVNFTndQbDU0NURkSlVDZkEvbGVECnBIYU9XN053eW9mS3NEZjc5SVR5WDFoMWg3V3dhdW1IdnY4cHVlTysrd2VMWkQ0U3dVL0NabGs1S2NmMjY2WlAKejdCUGk4Qzd2U3dmUUUrd1J1d0NPVDMxK3h4NXFVZE9qUWpRZEsrZUloUT0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
server: https://172.16.0.232:6443
name: k8s
contexts:
- context:
cluster: k8s
user: k8s-user
name: k8s
current-context: k8s
kind: Config
preferences: {}
users:
- name: k8s-user
user:
client-certificate-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURQVENDQWlXZ0F3SUJBZ0lRWU9FYU9nazZYcVdHdTNKdE1QMUV2akFOQmdrcWhraUc5dzBCQVFzRkFEQWYKTVIwd0d3WURWUVFERXhScmRXSmxjbTVsZEdWekxXTmhMV05zYVdWdWREQWVGdzB5TlRBek1ERXhNRFV3TURGYQpGdzAwTlRBek1ERXhNRFV3TURGYU1EUXhGekFWQmdOVkJBb1REbk41YzNSbGJUcHRZWE4wWlhKek1Sa3dGd1lEClZRUURFeEJyZFdKbGNtNWxkR1Z6TFdGa2JXbHVNSUlCSWpBTkJna3Foa2lHOXcwQkFRRUZBQU9DQVE4QU1JSUIKQ2dLQ0FRRUFwTzlvV2w2UmVCZHo0T0VBZjFZRXFxcUNlMWFHaHFMdkJ5Z3BmMTJwRG44Yzc4Vm1hcTZYaVhDUApRZ2R4SGZyeTBNSE9NOU56RTNCNCtIbHRUeTcvM1JZdzFvck0ydVlnd1c1Tjd4V2N0TVd5aGttWmszcDNGRlNBCnU0cTNxZHFYZTJWVytrbkx2RFk0aUVZLzBPM3NLdEN5Z1RFODl4UkY2ckpXd3A1c3l0dXFMcHFKZG9kcURDb3cKWmpNcmE3dWw0SjV6L3dPT0RuMmtyb0lpMUZ2azZFZUVkTTIxdXJoY0VPUWhhUFNRSXdVRm1GekdwVktpZDJlbApkdEowdTlZNWhiSE4vV1hCTzhZN3l4VkIySHNnckY1ZUhicEJJeFFIVkdpdEU3aElzRTN5aTV5dm5OTldrTEpICnQ0eStNeU9aY1lsRGFqQTdHWXU0Sjl3eDNIV1gwUUlEQVFBQm8yQXdYakFPQmdOVkhROEJBZjhFQkFNQ0JMQXcKSFFZRFZSMGxCQll3RkFZSUt3WUJCUVVIQXdJR0NDc0dBUVVGQndNQk1Bd0dBMVVkRXdFQi93UUNNQUF3SHdZRApWUjBqQkJnd0ZvQVVOd29sc0hkWHJYTTFkci9LbUczQndxOW5Udzh3RFFZSktvWklodmNOQVFFTEJRQURnZ0VCCkFFbnh6dTRzZlk4aDVZZUt2VkMyWUc0MkZodWJUQTF1MysvSkVpajhXbEMyWkNPMzVTNkh5ZVE1enNHT0VSWU8KMW8vZ1RsLytYY0tJeVJkcWxlKzZncjFUN2wvaXFCVEIrcVVIZjl3b3NkeU1TQkU3ZjdzV0dPU1VhOFZKZ0k4bAp0MHdXTkxvRURFNzNlUHVPbFJHK29yblJ3Y0ViWEpYd3hwZVhHaDZxTkJETlN6QXJpSTN1Tlh6ZG1BVzQ0eTB1Clppd2FNMzZSS0FPZGxpWVRtMzVFNEdidVdYSUJYWGtERUlpT2Qyc2ZqQmxWVDV6NmxKSTNRTGZTUXlrQ05MK2EKSmZiNDlPd1p3K2FZZ0JOTzRGWGNvVEQ5QllMZXVrSkxHRkNWc1RyVWNtVDJkOHpqVHovam83VUZwd0FDT0RSbgp4V2tsTUYramo2ajAxZ0I5V254Q0NoOD0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
client-key-data: LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFb3dJQkFBS0NBUUVBcE85b1dsNlJlQmR6NE9FQWYxWUVxcXFDZTFhR2hxTHZCeWdwZjEycERuOGM3OFZtCmFxNlhpWENQUWdkeEhmcnkwTUhPTTlOekUzQjQrSGx0VHk3LzNSWXcxb3JNMnVZZ3dXNU43eFdjdE1XeWhrbVoKazNwM0ZGU0F1NHEzcWRxWGUyVlcra25MdkRZNGlFWS8wTzNzS3RDeWdURTg5eFJGNnJKV3dwNXN5dHVxTHBxSgpkb2RxRENvd1pqTXJhN3VsNEo1ei93T09EbjJrcm9JaTFGdms2RWVFZE0yMXVyaGNFT1FoYVBTUUl3VUZtRnpHCnBWS2lkMmVsZHRKMHU5WTVoYkhOL1dYQk84WTd5eFZCMkhzZ3JGNWVIYnBCSXhRSFZHaXRFN2hJc0UzeWk1eXYKbk5OV2tMSkh0NHkrTXlPWmNZbERhakE3R1l1NEo5d3gzSFdYMFFJREFRQUJBb0lCQUVMYVYyM3B6d1RpWExIVwpBYUdiZUNERkpFWmg5LzB5cGJnODZ6VVkvYUZHbkxBRFQxUUdtSjI0NWhoWmM5dzNENXpXTVlLSVBxaXVlaG9jCi9kV09zMThsMDMzaW5NNU5ZUkdHYUVoMGRpUS96ZkRvZkR0dTlEMWxVeGl4VFdpbmxhY0ttSXF5eHNYdkpGTDQKUm4ybE1vallOc0p1OXNzZmlJZHM2Z1hRdVVBdnlzeVJDRldHQmZKQ0hYMncyR1dVM1kwWVk5UE81N1pyUG9mSwpxUmRXc3NSN2draFZHSXBoVk5IeUdRWjR5ZVV1UzNaWlRUZ3NVTkZZZjZDbmZ0dHZUaHdJY0RHS0UzZ3pOV24yCjlMVU93NDVUVDl5ckpKS0w3UmdGRnNsVGZhQTBTRjAvbTdiMFNiS1ZoeTkrSktRMVNXWnFLdHVRanhOZlZET1QKTjJzaCtKRUNnWUVBMUVOaG9RRS9lOHhuNi9nRHVhOS9rb1l1ZHVGRVZSQXZ0S1FzeVAvRmdjay81T0l5cVpFeAoyS2JjOXJJVGVGYU9ueXVjZ2dSaFhxNWxmMEU0RFlTeWZDNWNDOExWVVY5U2FzY1RQVEVQamhzdlBMWTR3U3VsCjdwaVpEVmdTNGVyWDhmQjNEMXpYVUFzMGdFcVBPUWZHM0FVOEM0dUNLSWVvdkdzTVY1MnpXTWNDZ1lFQXh1dUkKUlVJUTQzM0lYRUZVdlRDUHhjWmtrY3VtckFKUzB2dnhnSU9Gck9rbjNKaXA2elZYZmZKLzh1M29ydmR4TUpyaQoyYVNEUFBJME50bm5xSzVQZWloYnhTT3U0V2Nmc0RNY1NFNXF3ZEVsbG9PN25uRXBRS3VaZzNRbnlFTmhWYjZtCmUrbWkwWE4vSmxKMHlhV3lRMnVTeVM0LzREQVE3K25yVHdZeDRxY0NnWUJMYzZoQWt6RDkwS3NnTmdrYytFVmcKMEZHejhGOVozV2NYejBRY0xzOEdVNE5pMlFVcFFYTjJqOW43MTFFVWRiQTg1RU85ODlDbzExVTg1dklGM0NXVgovdVM1U1lpS1pGZm5uTnc1NURhalRRWjlqa2llWWVXWjZxUjlHZEdjZk41R0lqUXdRZEJIbzdRRjVuc0N5c0RsCmRQYmpJN1FndEJoRzRjYUJYbzFpQVFLQmdBcHA5RVZqOHd4bDNtSnVEU2ltYlRCMmRYZG9pUDVDVk9HMHpPemsKZGRBYW1McWt4MmlINzErcG5XY3phMVlWb0RoaU0zUWZkN3R1RnF1MGRydE8vTnd4VnJTWWJLUmlTTGRweFpaSApmTEZPNkwvYmY2d0kwcGNQSk1kTUFuVXFpZUw2U3k3N2lVbWIyVkZCU2Rud3NjZHp6MGgzQW1NVFFSKytTRkpuCnlaN0xBb0dCQUxhMU1CUklIWWJCazlPZmVHM0dhSjhSU2VMSzZJL29hU1Q2WnhRSnpqYnZydExIdHM4Q01ycDEKeWFTN3YxTUIrQ3pVaTdEVWVXWXlrYlFaWkdsNm9ySlBWSGdqNEhoaEg1b1BqNXhrTzFSK28zd0FYY0ZqSVNJaQo0TjFOV1Q1S2hrUWZENDlxdlpHM0VpM0JJTXI2YW96WG1JUWhQR1RpejVNY0VwbFF0M0g4Ci0tLS0tRU5EIFJTQSBQUklWQVRFIEtFWS0tLS0tCg==
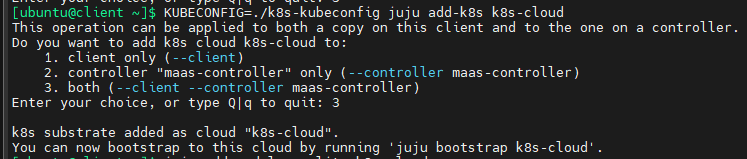
KUBECONFIG=./k8s-kubeconfig juju add-k8s k8s-cloud
会出现交互式提问,选择3
开始部署COS LITE
juju add-model cos-lite k8s-cloud
juju deploy cos-lite --trust
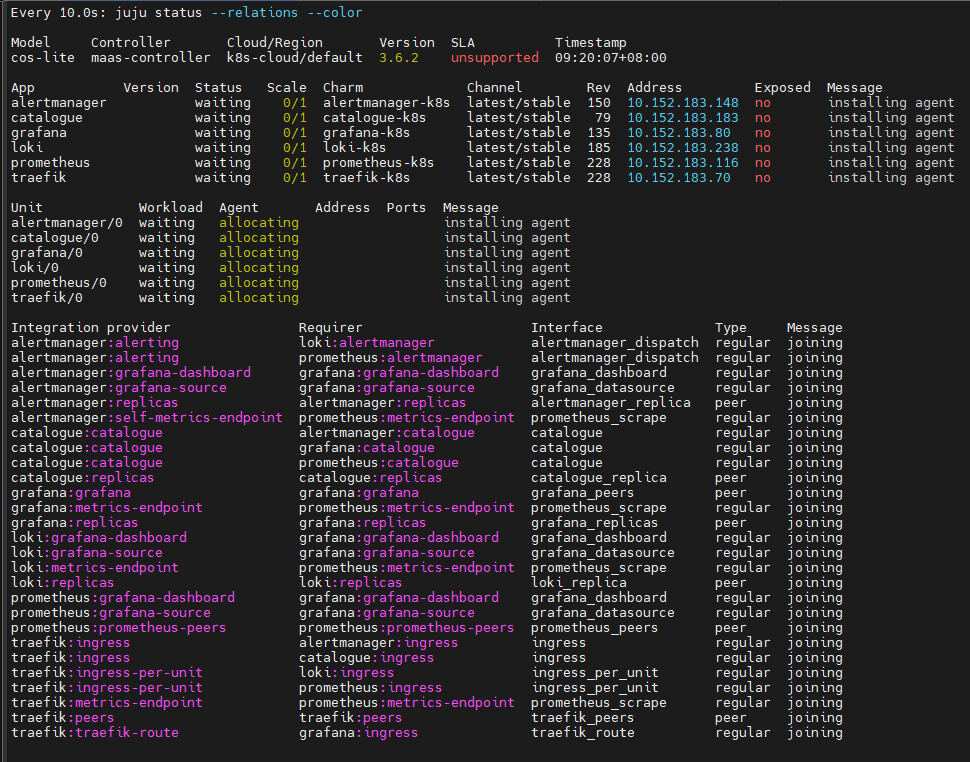
:::
部署cos-lite时,我发现message一直显示“installing agent”,我ssh到k8s节点,发现容器拉取失败了,如下:
juju ssh k8s/0
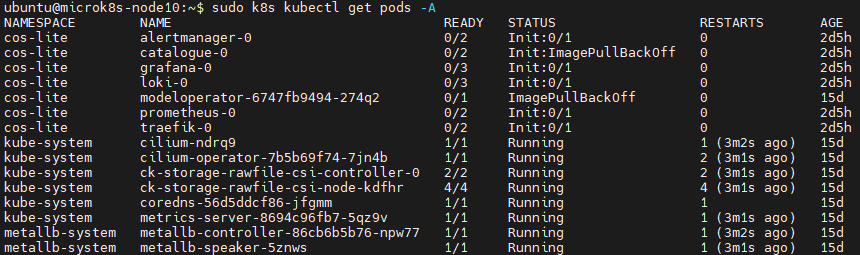
查看events,发现从docker.io拉取镜像,所以没法正常拉取
编辑相应的Deployment,将其改为这个mirror registry,我发现就可以正常拉取镜像了,到那时我发现只有一个Deployment,其它pods没有对应的Deployment,而直接编辑pods的image是无效的,更改Deployment才行。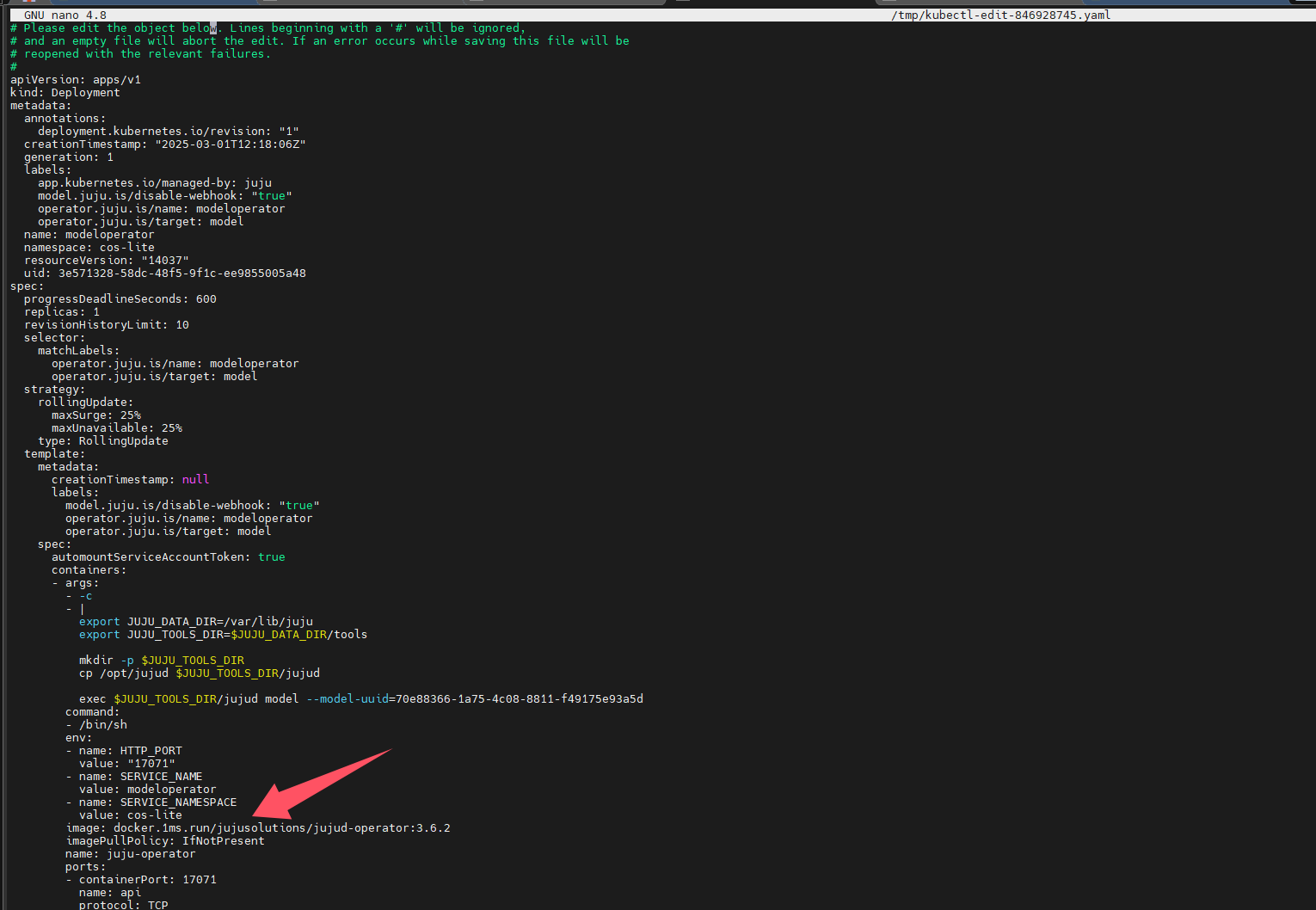
只有modeloperator这个pod正常运行,其它pods都无法正常拉取容器镜像

要解决这个问题,可以更改statefulset,更改后,pods就会使用新的image registry拉取容器镜像了,以下以alertmanager为例:
可以看到,除了modeloperator外,其它pods都是通过statefulset创建的,所以更改statefulset就可以修改pods的image registry
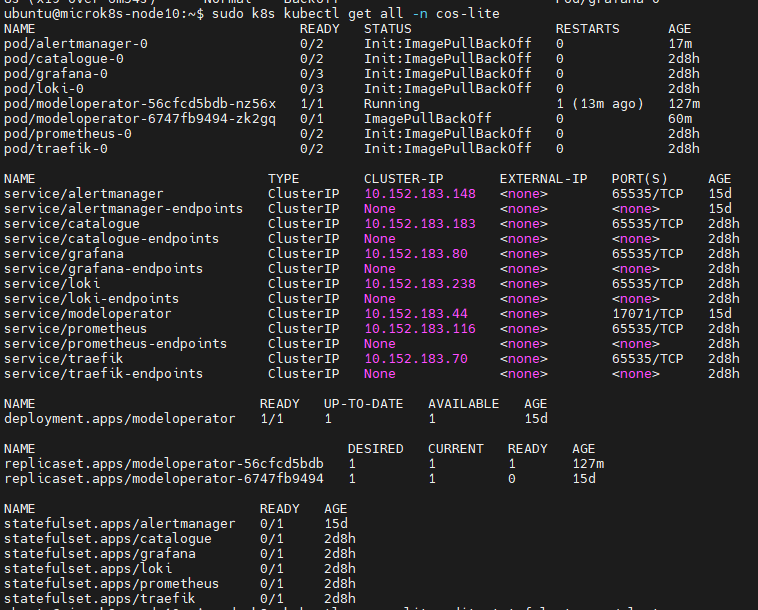
sudo k8s kubectl -n cos-lite edit statefulset.apps/alertmanager
总共有三处需要修改,下图只标识了一处
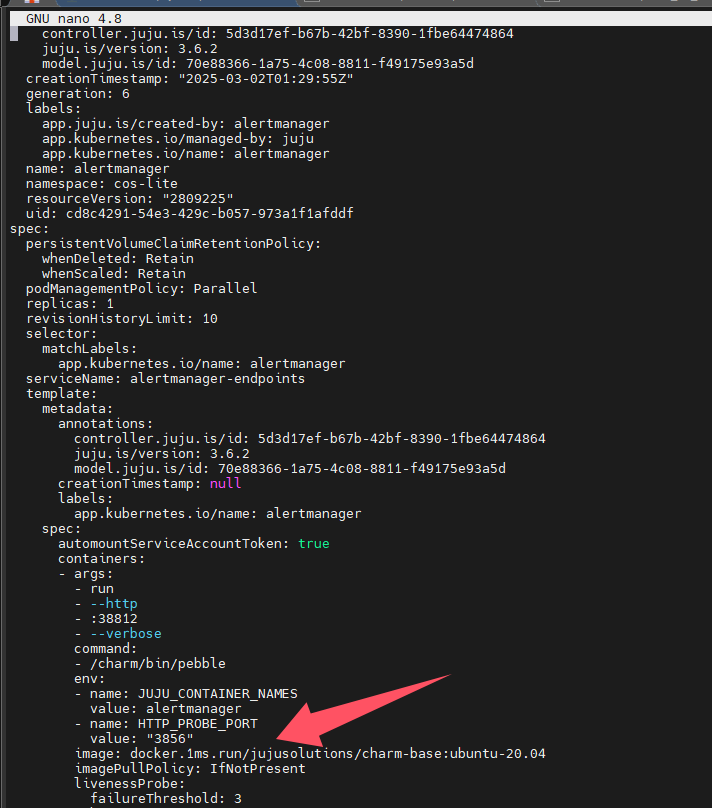
很快,容器镜像就拉取成功了,如下图所示,其它的也是同样的方法
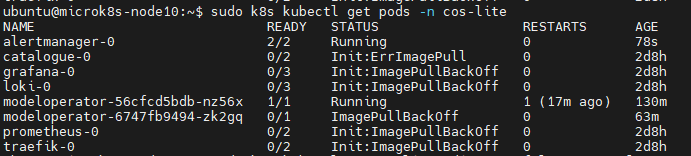
还有一个问题,就是有一个镜像不是从docker.io拉取的,我也没有找到国内可以拉取的仓库镜像

还是科学上网最方便了,就没有这些麻烦了。
:::
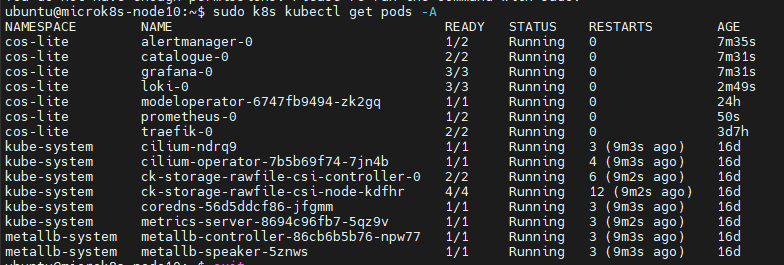
最终部署成功
部署vLLM及运行LLM
参考资料:vLLM 多机多卡推理测试与验证(Kubernetes) | 陈谭军的博客 | tanjunchen Blog
下载模型
提前下载模型文件(本文下载的是经过Q4量化的deepseek R1模型),经过实践,我发现用下行命令经常会出现网络中断的情况,建议换再下面的命令下载模型文件,参考资料:HF-Mirror
注意:强烈建议使用官方的hugggingface-cli命令下载模型文件,因为它会组织好目录结构,而Hfd虽然下载速率非常快,但是只下载模型文件,这会导致vllm不认为已经下载好了模型文件,vllm仍然会重新下载模型文件。另外,不要指定目录,直接用默认的缓存目录即可
#huggingface-cli是官方命令,--token只有在下载一些需要登录的模型时才需要指定,下载deepseek模型也是可以不指定的
pip install -U huggingface_hub
#HF_HUB_DOWNLOAD_TIMEOUT环境变量的作用是设置hugggingface-cli下载文件时的超时时间,默认为10s,如果不延迟超时时间,则经常中断下载。
export HF_HUB_DOWNLOAD_TIMEOUT=18000
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --token <此处替换为你的Huggingface账户的API-KEY> deepseek-ai/DeepSeek-R1
#hfd是Hf-mirror开发的,据说是下载速率快而且稳定,推荐使用
wget https://hf-mirror.com/hfd/hfd.shchmod
a+x hfd.sh
export HF_ENDPOINT=https://hf-mirror.com
#下行命令会自动在当前目录创建新的目录,根据repo命令的,也可直接指定下载到的目录
./hfd.sh deepseek-ai/DeepSeek-R1
./hfd.sh mlx-community/DeepSeek-R1-4bit
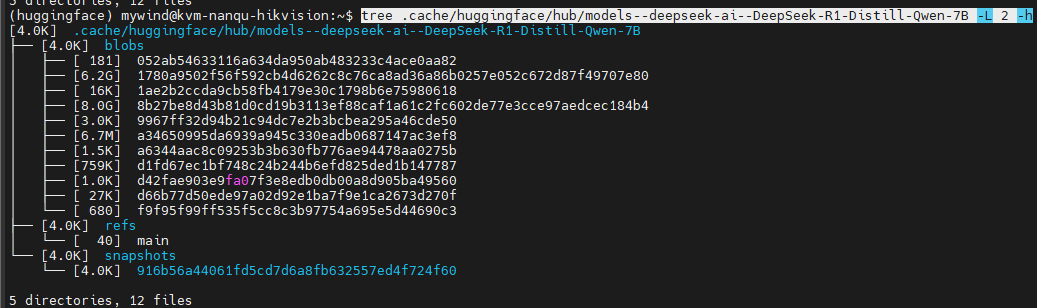
如果用huggingface-cli下载模型文件,默认情况下会将其下载到~/.cache/huggingface/hub目录中,目录结构是这样的:
tree .cache/huggingface/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B -L 2 -h
models–deepseek-ai–DeepSeek-R1-Distill-Qwen-7B这个目录是自动生成的,这与hfd不同,hfd不会生成这个目录,然后snapshots目录里面的文件其实都是符号链接
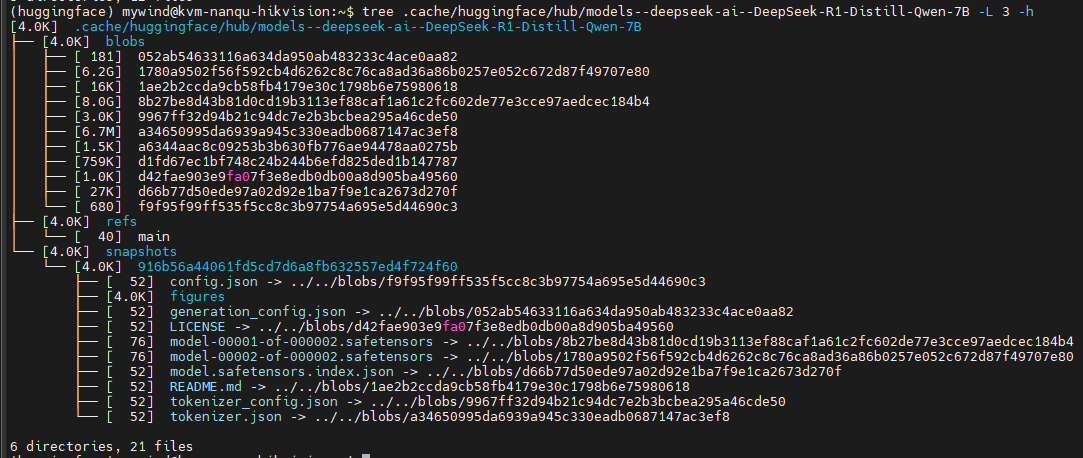
如果是用hfd下载模型文件,那看到的就是跟Huggingfac上显示的文件一样的,而没有上述的目录结构,vllm是不认的。
用hfd下载,网速确实非常快

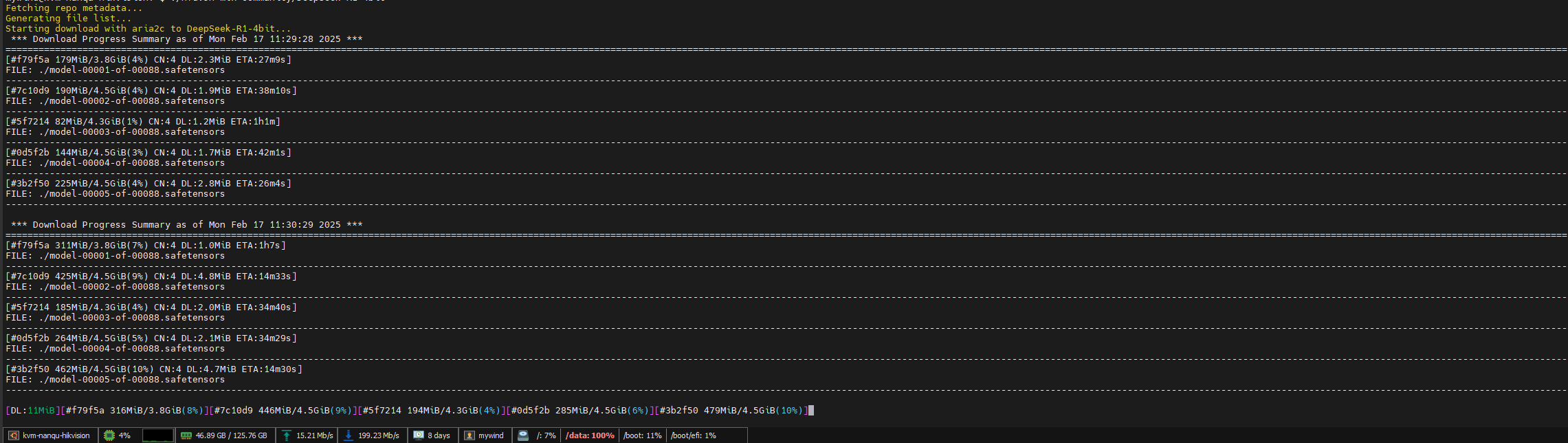
下载完成,日志提示有错误,还说明了可以断点续传,只需要再次执行上面的下载命令即可
总共有391GB
常见下载出错解决方案
huggingface-cli和hfd默认都启用了断点续传
根据实践,我发现如果用Huggingface-cli命令下载模型,如果指定HF_ENDPOINT为https://hf-mirror.com,则下载经常中断,1.5B的模型是可以下载的,再大的就几乎无法完成下载,即使启用了hf_transfer也经常出错。
若使用hfd下载模型文件,并且指定HF_ENDPOINT为https://hf-mirror.com,则下载非常快且稳定,但是这种方式只是下载模型文件,目录结构与用Huggingface-cli命令下载的不同,vllm不认这个。
如果在大陆实现高速稳定下载Huggingfac上的模型文件呢,其实很简单,关键就是要设置两个环境变量,这样虽然也可能出现下载中断的情况,但是频率会低很多。如果出错了,再接着下载即可。
#HF_HUB_DOWNLOAD_TIMEOUT环境变量的作用是设置hugggingface-cli下载文件时的超时时间,默认为10s,如果不延迟超时时间,则经常中断下载。
export HF_HUB_DOWNLOAD_TIMEOUT=18000
export HF_ENDPOINT=https://hf-mirror.com
下行命令,可以查询当与huggingface-cli相关的环境变量设置
huggingface-cli env
另外,默认情况下huggingface-cli会同时下载最多8个文件,如果想同时下载更多文件,可以添加参数–max-workers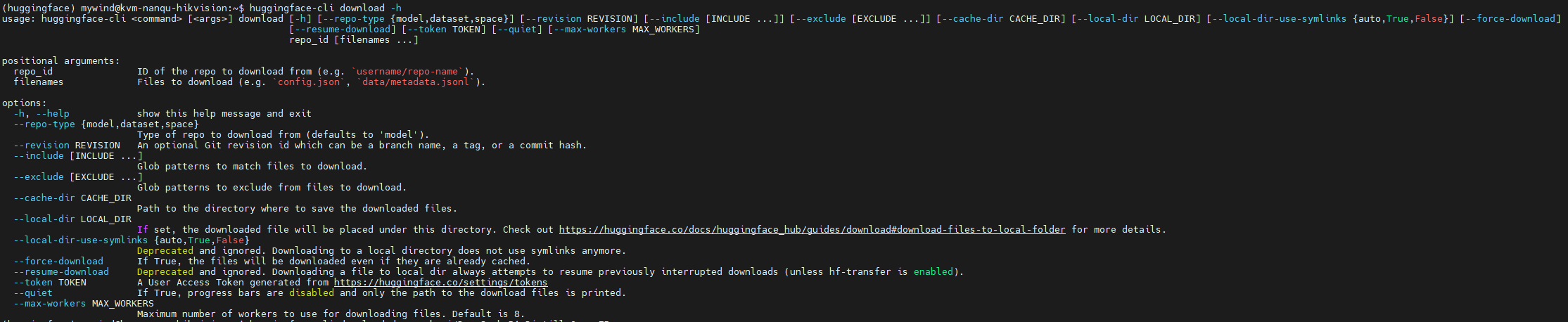
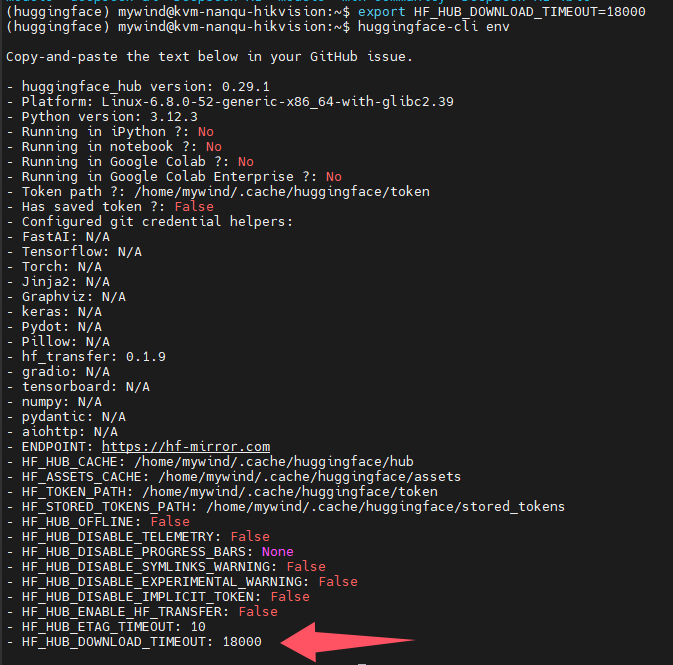
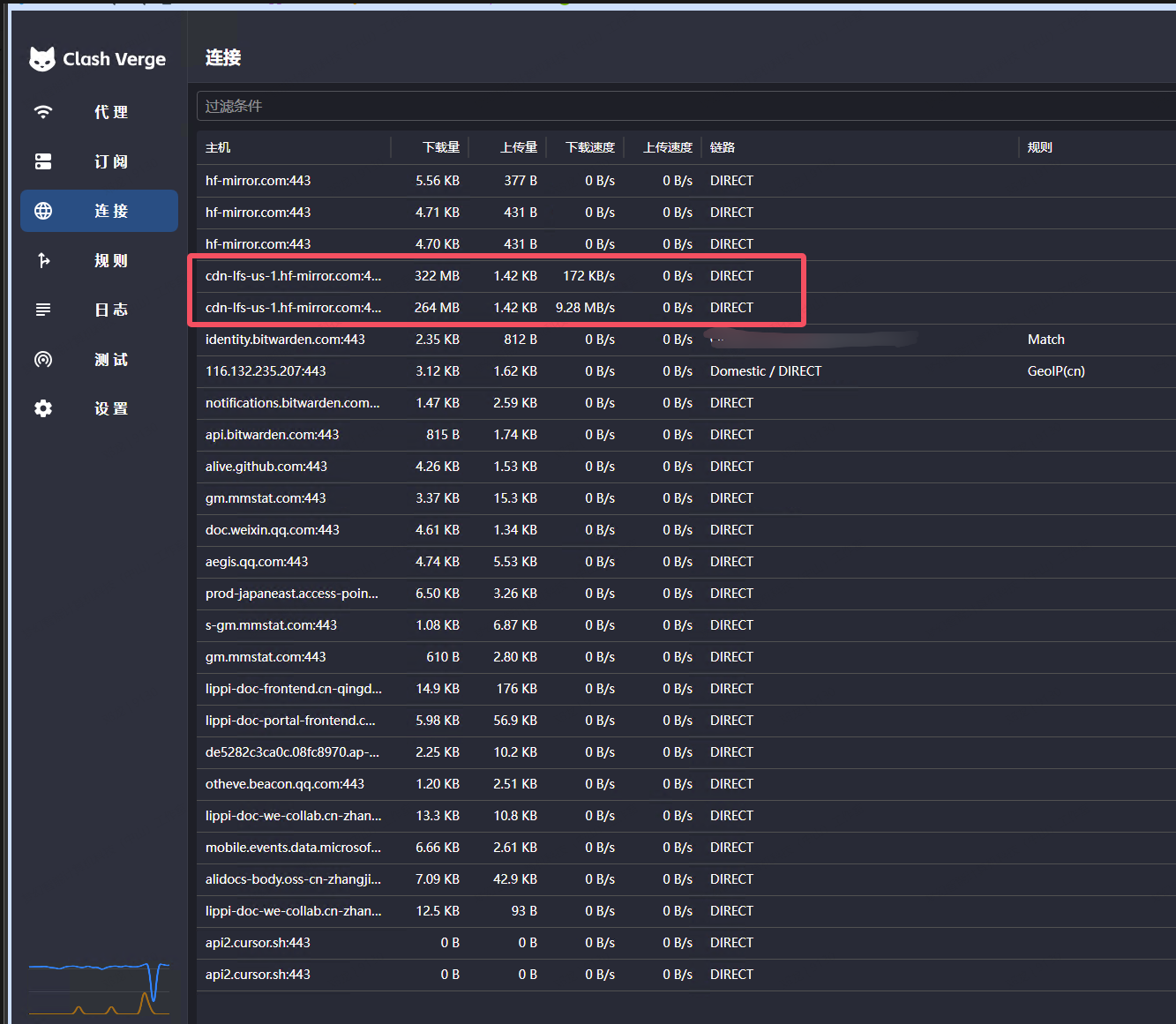
延长超时时间后,没有出现中断下载的情况了

创建PVC–DeepSeek-R1-4bit
注意:name和namespace必须用小写
DeepSeek-R1-4bit-PVC.yaml
cat <<EOF > DeepSeek-R1-4bit-PVC.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: deepseek-r1-4bit
namespace: vllm
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 600Gi
storageClassName: cephfs
volumeMode: Filesystem
EOF
kubectl create ns vllm
kubectl apply -f ./DeepSeek-R1-4bit-PVC.yaml
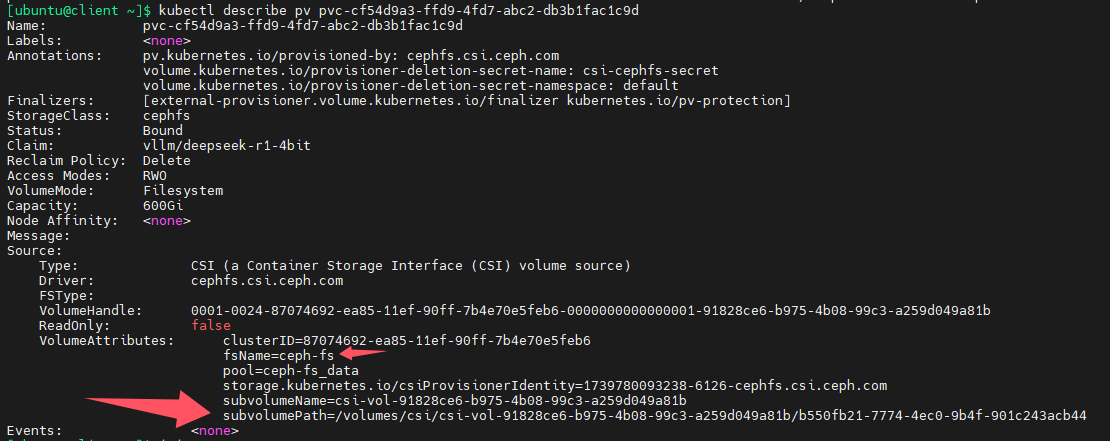
查询pv信息,可以查到subvolume的名称和路径,还有fsname(其实就是ceph的volume name)
将下载好的模型提前上传到ceph的卷中
提前上传好模型文件,好处是省时间,而且vllm默认是直接从huggingface下载模型文件的,国内是无法直接访问的。
由于我将模型文件下载到了另外一台服务器里面,此服务器无法直接访问k8s集群,因此我在client计算机中再添加了一张网卡,然后将模型文件先传到client计算机中,然后再将模型文件上传到ceph集群的fs卷里
sudo rsync -avP --rsh=ssh mywind@10.65.37.240:/home/mywind/DeepSeek-R1-4bit /data/models/
查询subvolume信息
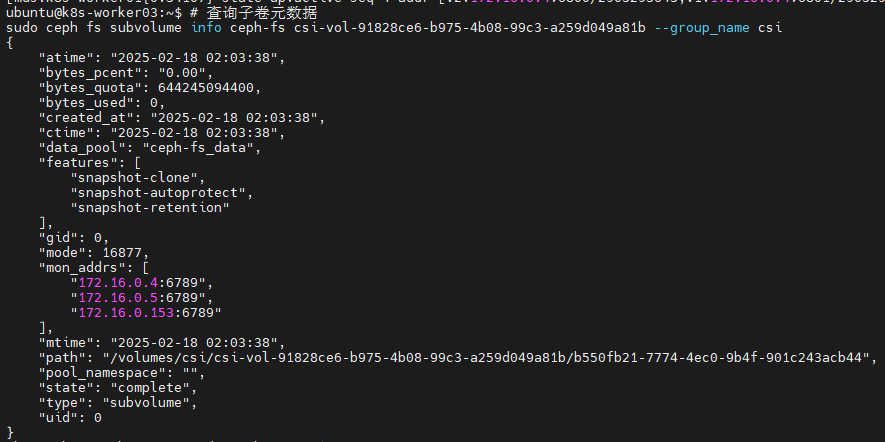
sudo ceph fs subvolume info ceph-fs csi-vol-91828ce6-b975-4b08-99c3-a259d049a81b --group_name csi
查询ceph中fs的容量状况
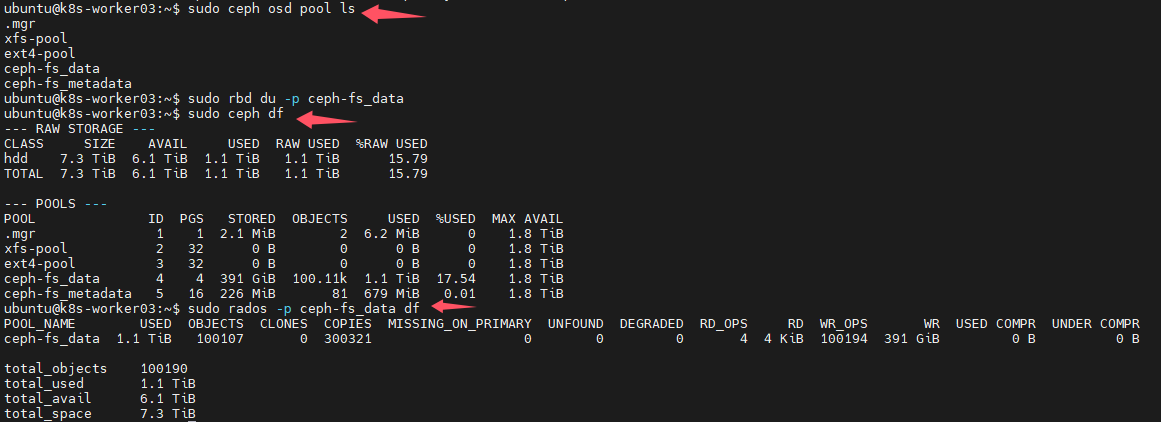

查询ceph的key

将subvolume挂载到本地的目录,如此就可以将本地文件上传到subvolume中了,下行命令的secret的值为上面查询到的key
sudo mkdir /mnt/cephfs
sudo mount -t ceph 172.16.0.4:6789,172.16.0.5:6789,172.16.0.153:6789:/volumes/csi/csi-vol-91828ce6-b975-4b08-99c3-a259d049a81b/b550fb21-7774-4ec0-9b4f-901c243acb44 /mnt/cephfs -o name=admin,secret=AQBju65nJJtaFRAA+n4H+nqwgakZ+YJXl96WVg==
将模型文件复制到ceph集群fs的subvolume中,以供vllm使用
#cp命令不支持显示进度
sudo cp -r /data/models/DeepSeek-R1-4bit /mnt/cephfs/
#建议使用下行的复制命令,支持显示进度,支持断点续传
sudo rsync -ah --progress /data/models/DeepSeek-R1-4bit/ /mnt/cephfs/DeepSeek-R1-4bit
sudo umount /mnt/cephfs
单节点运行BAAI/bge-reranker-v2-m3(成功)
创建PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllmpvc
namespace: vllm
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 800Gi
storageClassName: cephfs
volumeMode: Filesystem
创建Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-bge-reranker-v2-m3
namespace: vllm
labels:
app: vllm-bge-reranker-v2-m3
spec:
replicas: 1
selector:
matchLabels:
app: vllm-bge-reranker-v2-m3
template:
metadata:
labels:
app: vllm-bge-reranker-v2-m3
spec:
nodeSelector: # 添加节点选择器
nvidia.com/gpu.present: "true" # 假设GPU节点的标签是nvidia.com/gpu.present: "true"
volumes:
- name: cache-volume
persistentVolumeClaim:
claimName: vllmpvc
- name: shm
emptyDir:
medium: Memory
containers:
- name: vllm-bge-reranker-v2-m3
image: vllm/vllm-openai:latest
command: ["/bin/sh", "-c"]
args: [
"vllm serve BAAI/bge-reranker-v2-m3 --trust-remote-code"
]
env:
- name: CUDA_DEVICE_ORDER
value: "PCI_BUS_ID"
- name: HF_ENDPOINT
value: "https://hf-mirror.com"
- name: VLLM_LOGGING_LEVEL
value: "DEBUG"
- name: HTTP_PROXY
value: "http://<此处替换为实际的代理服务器地址或域名>:port"
- name: HTTPS_PROXY
value: "http://<此处替换为实际的代理服务器地址或域名>:port"
- name: NO_PROXY
value: "10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/16,.svc,dltornado2.com,geekery.cn,daocloud.io,aliyun.com,mywind.com.cn,hf-mirror.com,quay.io,localhost,security.ubuntu.com"
ports:
- containerPort: 8000
volumeMounts:
- mountPath: /root/.cache/huggingface
name: cache-volume
- name: shm
mountPath: /dev/shm
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60 #建议时间不能设置太长,否则会导致pod一直无法处于ready状态,这会导致service中没有出现正确的endpoints
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60
periodSeconds: 5
创建service
apiVersion: v1
kind: Service
metadata:
name: vllm-bge-reranker-v2-m3
namespace: vllm
spec:
ports:
- name: vllm-bge-reranker-v2-m3
port: 8000
protocol: TCP
targetPort: 8000
# The label selector should match the deployment labels & it is useful for prefix caching feature
selector:
app: vllm-bge-reranker-v2-m3
sessionAffinity: None
type: NodePort
以下是正常运行的vllm日志:
kubectl -n vllm logs pods/vllm-bge-reranker-v2-m3-789d8948c8-9xs85
DEBUG 03-13 01:03:45 main.py:48] Setting VLLM_WORKER_MULTIPROC_METHOD to 'spawn'
DEBUG 03-13 01:03:45 __init__.py:28] No plugins for group vllm.platform_plugins found.
INFO 03-13 01:03:45 __init__.py:207] Automatically detected platform cuda.
DEBUG 03-13 01:03:45 __init__.py:28] No plugins for group vllm.general_plugins found.
INFO 03-13 01:03:45 api_server.py:912] vLLM API server version 0.7.3
INFO 03-13 01:03:45 api_server.py:913] args: Namespace(subparser='serve', model_tag='BAAI/bge-reranker-v2-m3', config='', host=None, port=8000, uvicorn_log_level='info', allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, enable_reasoning=False, reasoning_parser=None, tool_call_parser=None, tool_parser_plugin='', model='BAAI/bge-reranker-v2-m3', task='auto', tokenizer=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=True, allowed_local_media_path=None, download_dir=None, load_format='auto', config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', kv_cache_dtype='auto', max_model_len=None, guided_decoding_backend='xgrammar', logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=1, max_parallel_loading_workers=None, ray_workers_use_nsight=False, block_size=None, enable_prefix_caching=None, disable_sliding_window=False, use_v2_block_manager=True, num_lookahead_slots=0, seed=0, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.9, num_gpu_blocks_override=None, max_num_batched_tokens=None, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, max_num_seqs=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, disable_custom_all_reduce=False, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=False, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, multi_step_stream_outputs=True, scheduler_delay_factor=0.0, enable_chunked_prefill=None, speculative_model=None, speculative_model_quantization=None, num_speculative_tokens=None, speculative_disable_mqa_scorer=False, speculative_draft_tensor_parallel_size=None, speculative_max_model_len=None, speculative_disable_by_batch_size=None, ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None, spec_decoding_acceptance_method='rejection_sampler', typical_acceptance_sampler_posterior_threshold=None, typical_acceptance_sampler_posterior_alpha=None, disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=None, qlora_adapter_name_or_path=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, scheduling_policy='fcfs', scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', generation_config=None, override_generation_config=None, enable_sleep_mode=False, calculate_kv_scales=False, additional_config=None, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, dispatch_function=<function ServeSubcommand.cmd at 0x7fb32d9f1940>)
DEBUG 03-13 01:03:45 api_server.py:190] Multiprocessing frontend to use ipc:///tmp/ba541b02-ca28-4a3f-9e7b-45fa19a5d05f for IPC Path.
INFO 03-13 01:03:45 api_server.py:209] Started engine process with PID 39
DEBUG 03-13 01:03:47 __init__.py:28] No plugins for group vllm.platform_plugins found.
INFO 03-13 01:03:47 __init__.py:207] Automatically detected platform cuda.
DEBUG 03-13 01:03:47 __init__.py:28] No plugins for group vllm.general_plugins found.
INFO 03-13 01:03:49 config.py:2444] Downcasting torch.float32 to torch.float16.
INFO 03-13 01:03:50 config.py:2444] Downcasting torch.float32 to torch.float16.
INFO 03-13 01:03:52 config.py:549] This model supports multiple tasks: {'classify', 'embed', 'score', 'reward'}. Defaulting to 'score'.
INFO 03-13 01:03:52 llm_engine.py:234] Initializing a V0 LLM engine (v0.7.3) with config: model='BAAI/bge-reranker-v2-m3', speculative_config=None, tokenizer='BAAI/bge-reranker-v2-m3', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.float16, max_seq_len=8194, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar'), observability_config=ObservabilityConfig(otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=0, served_model_name=BAAI/bge-reranker-v2-m3, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=False, chunked_prefill_enabled=False, use_async_output_proc=False, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=PoolerConfig(pooling_type=None, normalize=None, softmax=None, step_tag_id=None, returned_token_ids=None), compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":256}, use_cached_outputs=True,
INFO 03-13 01:03:54 config.py:549] This model supports multiple tasks: {'reward', 'score', 'classify', 'embed'}. Defaulting to 'score'.
INFO 03-13 01:03:55 cuda.py:229] Using Flash Attention backend.
DEBUG 03-13 01:03:55 config.py:3461] enabled custom ops: Counter()
DEBUG 03-13 01:03:55 config.py:3463] disabled custom ops: Counter()
DEBUG 03-13 01:03:55 parallel_state.py:810] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://192.168.0.111:35995 backend=nccl
INFO 03-13 01:03:57 model_runner.py:1110] Starting to load model BAAI/bge-reranker-v2-m3...
DEBUG 03-13 01:03:57 decorators.py:109] Inferred dynamic dimensions for forward method of <class 'vllm.model_executor.models.bert.BertEncoder'>: ['hidden_states']
DEBUG 03-13 01:03:57 config.py:3461] enabled custom ops: Counter()
DEBUG 03-13 01:03:57 config.py:3463] disabled custom ops: Counter()
INFO 03-13 01:03:58 weight_utils.py:254] Using model weights format ['*.safetensors']
DEBUG 03-13 01:04:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:04:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:04:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:04:35 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:04:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:04:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:05:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:05:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:05:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:05:35 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:05:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:05:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:06:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:06:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:06:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:06:35 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:06:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:06:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:07:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:07:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:07:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:07:35 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:07:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:07:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:08:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:08:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:08:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:08:35 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:08:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:08:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:09:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:09:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:09:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:09:35 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:09:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:09:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:10:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:10:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:10:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:10:35 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:10:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:10:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:11:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:11:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:11:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:11:35 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:11:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:11:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:12:05 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:12:15 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:12:25 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:12:35 client.py:192] Waiting for output from MQLLMEngine.
INFO 03-13 01:12:39 weight_utils.py:270] Time spent downloading weights for BAAI/bge-reranker-v2-m3: 520.588571 seconds
INFO 03-13 01:12:41 weight_utils.py:304] No model.safetensors.index.json found in remote.
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 2.02it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 2.02it/s]
INFO 03-13 01:12:41 model_runner.py:1115] Loading model weights took 1.0577 GB
DEBUG 03-13 01:12:41 engine.py:135] Starting Startup Loop.
DEBUG 03-13 01:12:41 engine.py:137] Starting Engine Loop.
DEBUG 03-13 01:12:41 api_server.py:282] vLLM to use /tmp/tmpuslz1b6p as PROMETHEUS_MULTIPROC_DIR
INFO 03-13 01:12:41 api_server.py:958] Starting vLLM API server on http://0.0.0.0:8000
INFO 03-13 01:12:41 launcher.py:23] Available routes are:
INFO 03-13 01:12:41 launcher.py:31] Route: /openapi.json, Methods: GET, HEAD
INFO 03-13 01:12:41 launcher.py:31] Route: /docs, Methods: GET, HEAD
INFO 03-13 01:12:41 launcher.py:31] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 03-13 01:12:41 launcher.py:31] Route: /redoc, Methods: GET, HEAD
INFO 03-13 01:12:41 launcher.py:31] Route: /health, Methods: GET
INFO 03-13 01:12:41 launcher.py:31] Route: /ping, Methods: GET, POST
INFO 03-13 01:12:41 launcher.py:31] Route: /tokenize, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /detokenize, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /v1/models, Methods: GET
INFO 03-13 01:12:41 launcher.py:31] Route: /version, Methods: GET
INFO 03-13 01:12:41 launcher.py:31] Route: /v1/chat/completions, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /v1/completions, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /v1/embeddings, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /pooling, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /score, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /v1/score, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /v1/audio/transcriptions, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /rerank, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /v1/rerank, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /v2/rerank, Methods: POST
INFO 03-13 01:12:41 launcher.py:31] Route: /invocations, Methods: POST
INFO: Started server process [7]
INFO: Waiting for application startup.
INFO: Application startup complete.
DEBUG 03-13 01:12:45 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:12:51 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
DEBUG 03-13 01:12:51 client.py:171] Heartbeat successful.
DEBUG 03-13 01:12:51 engine.py:195] Waiting for new requests in engine loop.
DEBUG 03-13 01:12:55 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-13 01:13:01 client.py:171] Heartbeat successful.
DEBUG 03-13 01:13:01 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
DEBUG 03-13 01:13:01 client.py:171] Heartbeat successful.
故障诊断
如果vllm日志一直输出DEBUG 03-13 01:13:05 client.py:192] Waiting for output from MQLLMEngine.
这通常说明模型下载出现了问题,最好事先下载好模型文件。
如果报错提示是:max_num_batched_tokens (1024) is smaller than max_model_len (8194). This effectively limits the maximum sequence length to max_num_batched_tokens and makes vLLM reject longer sequences. Please increase max_num_batched_tokens or decrease max_model_len
则说明是参数max_num_batched_tokens不正确,其实可以不指定此参数,就没有这个报错了
:::
DEBUG 03-12 20:45:13 api_server.py:190] Multiprocessing frontend to use ipc:///tmp/85231bfa-f991-448d-b0e0-680a4a8e5c2a for IPC Path.
INFO 03-12 20:45:13 api_server.py:209] Started engine process with PID 79
INFO 03-12 20:45:14 config.py:2444] Downcasting torch.float32 to torch.float16.
DEBUG 03-12 20:45:17 __init__.py:28] No plugins for group vllm.platform_plugins found.
INFO 03-12 20:45:17 __init__.py:207] Automatically detected platform cuda.
DEBUG 03-12 20:45:17 __init__.py:28] No plugins for group vllm.general_plugins found.
INFO 03-12 20:45:19 config.py:2444] Downcasting torch.float32 to torch.float16.
INFO 03-12 20:45:21 config.py:549] This model supports multiple tasks: {‘classify’, ‘score’, ‘embed’, ‘reward’}. Defaulting to ‘score’.
Traceback (most recent call last):
File “/usr/local/bin/vllm”, line 10, in
sys.exit(main())
^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/cli/main.py”, line 73, in main
args.dispatch_function(args)
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/cli/serve.py”, line 34, in cmd
uvloop.run(run_server(args))
File “/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py”, line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File “/usr/lib/python3.12/asyncio/runners.py”, line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File “/usr/lib/python3.12/asyncio/runners.py”, line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “uvloop/loop.pyx”, line 1518, in uvloop.loop.Loop.run_until_complete
File “/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py”, line 61, in wrapper
return await main
^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py”, line 947, in run_server
async with build_async_engine_client(args) as engine_client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3.12/contextlib.py”, line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py”, line 139, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3.12/contextlib.py”, line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py”, line 220, in build_async_engine_client_from_engine_args
engine_config = engine_args.create_engine_config()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/arg_utils.py”, line 1269, in create_engine_config
scheduler_config = SchedulerConfig(
^^^^^^^^^^^^^^^^
File “”, line 22, in __init__
File “/usr/local/lib/python3.12/dist-packages/vllm/config.py”, line 1572, in __post_init__
self._verify_args()
File “/usr/local/lib/python3.12/dist-packages/vllm/config.py”, line 1577, in _verify_args
raise ValueError(
ValueError: max_num_batched_tokens (1024) is smaller than max_model_len (8194). This effectively limits the maximum sequence length to max_num_batched_tokens and makes vLLM reject longer sequences. Please increase max_num_batched_tokens or decrease max_model_len.
INFO 03-12 20:45:25 config.py:549] This model supports multiple tasks: {‘reward’, ‘score’, ‘classify’, ‘embed’}. Defaulting to ‘score’.
Process SpawnProcess-1:
ERROR 03-12 20:45:25 engine.py:400] max_num_batched_tokens (1024) is smaller than max_model_len (8194). This effectively limits the maximum sequence length to max_num_batched_tokens and makes vLLM reject longer sequences. Please increase max_num_batched_tokens or decrease max_model_len.
ERROR 03-12 20:45:25 engine.py:400] Traceback (most recent call last):
ERROR 03-12 20:45:25 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 391, in run_mp_engine
ERROR 03-12 20:45:25 engine.py:400] engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
ERROR 03-12 20:45:25 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-12 20:45:25 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 119, in from_engine_args
ERROR 03-12 20:45:25 engine.py:400] engine_config = engine_args.create_engine_config(usage_context)
ERROR 03-12 20:45:25 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-12 20:45:25 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/vllm/engine/arg_utils.py”, line 1269, in create_engine_config
ERROR 03-12 20:45:25 engine.py:400] scheduler_config = SchedulerConfig(
ERROR 03-12 20:45:25 engine.py:400] ^^^^^^^^^^^^^^^^
ERROR 03-12 20:45:25 engine.py:400] File “”, line 22, in __init__
ERROR 03-12 20:45:25 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/vllm/config.py”, line 1572, in __post_init__
ERROR 03-12 20:45:25 engine.py:400] self._verify_args()
ERROR 03-12 20:45:25 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/vllm/config.py”, line 1577, in _verify_args
ERROR 03-12 20:45:25 engine.py:400] raise ValueError(
ERROR 03-12 20:45:25 engine.py:400] ValueError: max_num_batched_tokens (1024) is smaller than max_model_len (8194). This effectively limits the maximum sequence length to max_num_batched_tokens and makes vLLM reject longer sequences. Please increase max_num_batched_tokens or decrease max_model_len.
Traceback (most recent call last):
File “/usr/lib/python3.12/multiprocessing/process.py”, line 314, in _bootstrap
self.run()
File “/usr/lib/python3.12/multiprocessing/process.py”, line 108, in run
self._target(*self._args, **self._kwargs)
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 402, in run_mp_engine
raise e
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 391, in run_mp_engine
engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 119, in from_engine_args
engine_config = engine_args.create_engine_config(usage_context)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/arg_utils.py”, line 1269, in create_engine_config
scheduler_config = SchedulerConfig(
^^^^^^^^^^^^^^^^
File “”, line 22, in __init__
File “/usr/local/lib/python3.12/dist-packages/vllm/config.py”, line 1572, in __post_init__
self._verify_args()
File “/usr/local/lib/python3.12/dist-packages/vllm/config.py”, line 1577, in _verify_args
raise ValueError(
ValueError: max_num_batched_tokens (1024) is smaller than max_model_len (8194). This effectively limits the maximum sequence length to max_num_batched_tokens and makes vLLM reject longer sequences. Please increase max_num_batched_tokens or decrease max_model_len.
:::
如果报错提示是:ValueError: Chunked prefill is not supported for pooling models
说明此模型不支持–enable-chunked-prefill这个参数,只要不指定此参数即可
:::
DEBUG 03-12 20:42:01 api_server.py:190] Multiprocessing frontend to use ipc:///tmp/6f7e73e5-0491-4b28-a53e-f4d8b93caaaf for IPC Path.
INFO 03-12 20:42:01 api_server.py:209] Started engine process with PID 39
DEBUG 03-12 20:42:03 __init__.py:28] No plugins for group vllm.platform_plugins found.
INFO 03-12 20:42:03 __init__.py:207] Automatically detected platform cuda.
INFO 03-12 20:42:03 config.py:2444] Downcasting torch.float32 to torch.float16.
DEBUG 03-12 20:42:03 __init__.py:28] No plugins for group vllm.general_plugins found.
INFO 03-12 20:42:04 config.py:2444] Downcasting torch.float32 to torch.float16.
INFO 03-12 20:42:06 config.py:549] This model supports multiple tasks: {‘reward’, ‘embed’, ‘classify’, ‘score’}. Defaulting to ‘score’.
Traceback (most recent call last):
File “/usr/local/bin/vllm”, line 10, in
sys.exit(main())
^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/cli/main.py”, line 73, in main
args.dispatch_function(args)
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/cli/serve.py”, line 34, in cmd
uvloop.run(run_server(args))
File “/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py”, line 109, in run
return __asyncio.run(
^^^^^^^^^^^^^^
File “/usr/lib/python3.12/asyncio/runners.py”, line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File “/usr/lib/python3.12/asyncio/runners.py”, line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “uvloop/loop.pyx”, line 1518, in uvloop.loop.Loop.run_until_complete
File “/usr/local/lib/python3.12/dist-packages/uvloop/__init__.py”, line 61, in wrapper
return await main
^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py”, line 947, in run_server
async with build_async_engine_client(args) as engine_client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3.12/contextlib.py”, line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py”, line 139, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3.12/contextlib.py”, line 210, in __aenter__
return await anext(self.gen)
^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/api_server.py”, line 220, in build_async_engine_client_from_engine_args
engine_config = engine_args.create_engine_config()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/arg_utils.py”, line 1205, in create_engine_config
raise ValueError(msg)
ValueError: Chunked prefill is not supported for pooling models
INFO 03-12 20:42:08 config.py:549] This model supports multiple tasks: {‘classify’, ‘reward’, ‘embed’, ‘score’}. Defaulting to ‘score’.
ERROR 03-12 20:42:08 engine.py:400] Chunked prefill is not supported for pooling models
ERROR 03-12 20:42:08 engine.py:400] Traceback (most recent call last):
ERROR 03-12 20:42:08 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 391, in run_mp_engine
ERROR 03-12 20:42:08 engine.py:400] engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
ERROR 03-12 20:42:08 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-12 20:42:08 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 119, in from_engine_args
ERROR 03-12 20:42:08 engine.py:400] engine_config = engine_args.create_engine_config(usage_context)
ERROR 03-12 20:42:08 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-12 20:42:08 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/vllm/engine/arg_utils.py”, line 1205, in create_engine_config
ERROR 03-12 20:42:08 engine.py:400] raise ValueError(msg)
ERROR 03-12 20:42:08 engine.py:400] ValueError: Chunked prefill is not supported for pooling models
Process SpawnProcess-1:
Traceback (most recent call last):
File “/usr/lib/python3.12/multiprocessing/process.py”, line 314, in _bootstrap
self.run()
File “/usr/lib/python3.12/multiprocessing/process.py”, line 108, in run
self._target(*self._args, **self._kwargs)
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 402, in run_mp_engine
raise e
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 391, in run_mp_engine
engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py”, line 119, in from_engine_args
engine_config = engine_args.create_engine_config(usage_context)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.12/dist-packages/vllm/engine/arg_utils.py”, line 1205, in create_engine_config
raise ValueError(msg)
ValueError: Chunked prefill is not supported for pooling models
:::
如果报错是与下载模型有关的,如下,则建议事先下载好模型文件,然后上传到volume中
:::
INFO 03-12 20:46:26 cuda.py:229] Using Flash Attention backend.
DEBUG 03-12 20:46:26 config.py:3461] enabled custom ops: Counter()
DEBUG 03-12 20:46:26 config.py:3463] disabled custom ops: Counter()
DEBUG 03-12 20:46:26 parallel_state.py:810] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://192.168.0.111:59985 backend=nccl
INFO 03-12 20:46:30 model_runner.py:1110] Starting to load model BAAI/bge-reranker-v2-m3…
DEBUG 03-12 20:46:30 decorators.py:109] Inferred dynamic dimensions for forward method of <class ‘vllm.model_executor.models.bert.BertEncoder’>: [‘hidden_states’]
DEBUG 03-12 20:46:30 config.py:3461] enabled custom ops: Counter()
DEBUG 03-12 20:46:30 config.py:3463] disabled custom ops: Counter()
INFO 03-12 20:46:30 weight_utils.py:254] Using model weights format [‘*.safetensors’]
DEBUG 03-12 20:46:34 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-12 20:46:44 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-12 20:46:54 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-12 20:47:04 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-12 20:47:14 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-12 20:47:24 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-12 20:47:34 client.py:192] Waiting for output from MQLLMEngine.
DEBUG 03-12 20:47:44 client.py:192] Waiting for output from MQLLMEngine.
Process SpawnProcess-1:
ERROR 03-12 20:47:48 engine.py:400] An error occurred while downloading using `hf_transfer`. Consider disabling HF_HUB_ENABLE_HF_TRANSFER for better error handling.
ERROR 03-12 20:47:48 engine.py:400] Traceback (most recent call last):
ERROR 03-12 20:47:48 engine.py:400] File “/usr/local/lib/python3.12/dist-packages/huggingface_hub/file_download.py”, line 428, in http_get
ERROR 03-12 20:47:48 engine.py:400] hf_transfer.download(
ERROR 03-12 20:47:48 engine.py:400] Exception: Failed too many failures in parallel (3): Request: error decoding response body (no permits available)
ERROR 03-12 20:47:48 engine.py:400]
ERROR 03-12 20:47:48 engine.py:400] The above exception was the direct cause of the following exception:
:::
验证

在dify中添加,如图所示:
特别注意:API endpoint URL不要填错了,这个跟openai还是有一些格式区别的,openai的url中间是有个api的,但是vllm是没有的
单节点运行model–DeepSeek-R1-Distill-Qwen-1.5B(成功)
本小节介绍如何用vllm在一个k8s节点中运行大模型(即不进行分布式推理)
模型文件已经事先上传到cephfs的subvolume中了
Deployment-DeepSeek-R1-Distill-Qwen-1.5B.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-r1-distill-qwen-15b
namespace: vllm
labels:
app: DeepSeek-R1-Distill-Qwen-1.5B
spec:
replicas: 2
selector:
matchLabels:
app: DeepSeek-R1-Distill-Qwen-1.5B
template:
metadata:
labels:
app: DeepSeek-R1-Distill-Qwen-1.5B
spec:
nodeSelector: # 添加节点选择器
nvidia.com/gpu.present: "true" # 假设GPU节点的标签是nvidia.com/gpu.present: "true"
volumes:
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-distill-qwen-1.5b
- name: shm
emptyDir:
medium: Memory
containers:
- name: deepseek-r1-distill-qwen-15b
image: vllm/vllm-openai:latest
command: ["/bin/sh", "-c"]
args: [
"vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --trust-remote-code --enable-chunked-prefill --max_num_batched_tokens 1024 --dtype half"
]
env:
- name: CUDA_DEVICE_ORDER
value: "PCI_BUS_ID"
- name: HF_ENDPOINT
value: "https://hf-mirror.com"
- name: VLLM_LOGGING_LEVEL
value: "DEBUG"
- name: HTTP_PROXY
value: "http://<此处替换为实际的代理服务器地址或域名>:port"
- name: HTTPS_PROXY
value: "http://<此处替换为实际的代理服务器地址或域名>:port"
- name: NO_PROXY
value: "10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/16,.svc,dltornado2.com,geekery.cn,daocloud.io,aliyun.com,mywind.com.cn,hf-mirror.com,quay.io,localhost,security.ubuntu.com"
ports:
- containerPort: 8000
volumeMounts:
- mountPath: /root/.cache/huggingface
name: cache-volume
- name: shm
mountPath: /dev/shm
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60
periodSeconds: 5
service-DeepSeek-R1-Distill-Qwen-1.5B.yaml
apiVersion: v1
kind: Service
metadata:
name: deepseek-r1-distill-qwen-15b
namespace: vllm
spec:
ports:
- name: deepseek-r1-distill-qwen-15b
port: 80
protocol: TCP
targetPort: 8000
# The label selector should match the deployment labels & it is useful for prefix caching feature
selector:
app: DeepSeek-R1-Distill-Qwen-1.5B
sessionAffinity: None
type: ClusterIP
ingress-deepseek-r1-distill-qwen-15b.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: deepseek-r1-ingress
namespace: vllm
annotations:
# 以下为Nginx Ingress的示例注解,其他控制器可能需要不同配置
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: "deepseek.dltornado2.com" # 替换为您的实际域名
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: deepseek-r1-distill-qwen-15b # 必须与Service名称完全匹配
port:
number: 8000 # 必须与Service暴露的端口匹配
验证
注意:我没有设置API,所以知道url就可以直接调用大模型的能力了,您需要先将电脑的dns改为192.168.124.7或者你也可以直接更改hosts文件(Windows系统hosts文件路径是C:\Windows\System32\drivers\etc\hosts),添加一行:
10.65.37.239 deepseek.dltornado2.com
用Powershell命令如下:
$result = Invoke-RestMethod -Uri "http://deepseek.dltornado2.com/v1/chat/completions" `
-Method Post `
-ContentType "application/json" `
-Body '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "一加一等于几?"}
]
}'
$result.choices.message.content
如果是Linux系统中的curl,则可以这样验证大模型是否可以被调用
curl http://deepseek.dltornado2.com:80/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁"}
]
}'

如何让curl的输出更易读
可以用yq命令,例如:
curl --request POST \
-H "Content-Type: application/json" \
--header 'Authorization: Bearer token-iamtornado888' \
--url http://172.16.0.5:31990/v1/chat/completions \
--data '{"messages":[{"role":"user","content":"简要介绍ragflow"}],"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"}' | jq .
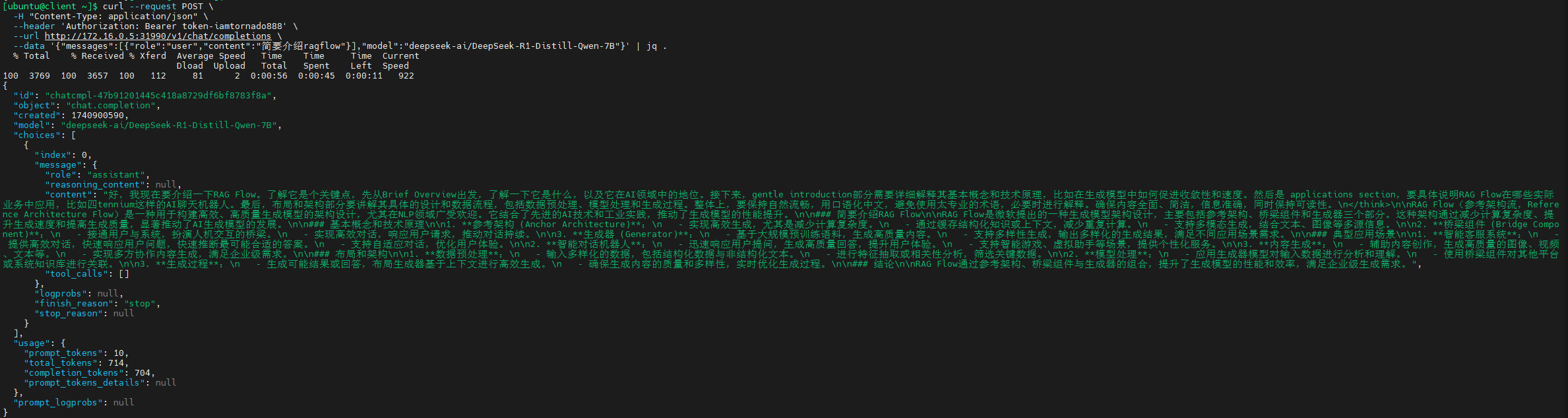
多节点运行DeepSeek-R1-Distill-Qwen-7B(成功)
yaml文件内容
先创建一个yaml文件,内容如下,其中包含了configmap、service和Deployment,没有写pvc,pvc的yaml跟之前的方法是一样的,我之前用了之前创建的pvc
本节的实验环境是两台dell precision 3660工作站,每台工作站安装了一块NVIDIA gtx A2000 12GB的GPU
cat << 'EOF' > Deployment-DeepSeek-R1-Distill-Qwen-7B.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: vllm-config
namespace: vllm
data:
IP_OF_HEAD_NODE: "vllm-head-service.vllm.svc.cluster.local" # 主机网络模式可填 ray head node 的 IP 地址
CUDA_DEVICE_ORDER: "PCI_BUS_ID"
NCCL_DEBUG: "TRACE" # 调试信息级别,可根据需要调整
NCCL_IB_DISABLE: "1" # 禁用 InfiniBand,根据实际情况调整
VLLM_TRACE_FUNCTION: "1" #用于调试
HF_ENDPOINT: "https://hf-mirror.com"
HTTP_PROXY: "http://<此处替换为实际的代理服务器地址或域名>:port"
HTTPS_PROXY: "http://<此处替换为实际的代理服务器地址或域名>:port"
NO_PROXY: "10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/16,.svc,dltornado2.com,dltornado.com,geekery.cn,daocloud.io,aliyun.com,mywind.com.cn,quay.io,localhost,security.ubuntu.com"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-head-service
namespace: vllm
spec:
selector:
app: vllm-head
ports:
- name: ray-port
protocol: TCP
port: 6379
targetPort: 6379
- name: object-manager-port
protocol: TCP
port: 8625
targetPort: 8625
- name: deepseek-r1-distill-qwen-7b
port: 8000
protocol: TCP
targetPort: 8000
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-head
namespace: vllm
spec:
replicas: 1
selector:
matchLabels:
app: vllm-head
template:
metadata:
labels:
app: vllm-head
spec:
nodeSelector:
nvidia.com/gpu.machine: "Precision-3660" # 假设GPU节点的标签是nvidia.com/gpu.machine: "Precision-3660"
vllm-role: "vllm-head"
# hostNetwork: true # 主机网络模式,根据实际情况调整
containers:
- name: vllm-head
image: vllm/vllm-openai:latest
command:
- "/bin/bash"
args:
- "-c"
- |
ray start --head --port=6379 --dashboard-host=0.0.0.0 --object-manager-port=8625 --block
securityContext:
privileged: true
volumeMounts:
- name: shm
mountPath: /dev/shm
- name: cache-volume
mountPath: /root/.cache/huggingface
envFrom:
- configMapRef:
name: vllm-config
volumes:
- name: shm
emptyDir:
medium: Memory
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-worker
namespace: vllm
spec:
replicas: 1
selector:
matchLabels:
app: vllm-worker
template:
metadata:
labels:
app: vllm-worker
spec:
nodeSelector:
nvidia.com/gpu.machine: "Precision-3660" # 假设GPU节点的标签是nvidia.com/gpu.machine: "Precision-3660"
vllm-role: "vllm-worker"
# hostNetwork: true # 主机网络模式,根据实际情况调整
containers:
- name: vllm-worker
image: vllm/vllm-openai:latest
command:
- "/bin/bash"
args:
- "-c"
- |
ray start --address=${IP_OF_HEAD_NODE}:6379 --block
securityContext:
privileged: true
volumeMounts:
- name: cache-volume
mountPath: /root/.cache/huggingface
- name: shm
mountPath: /dev/shm
envFrom:
- configMapRef:
name: vllm-config
volumes:
- name: shm
emptyDir:
medium: Memory
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
EOF
查看ray集群状态,可以看到总共有两个GPU,两个节点
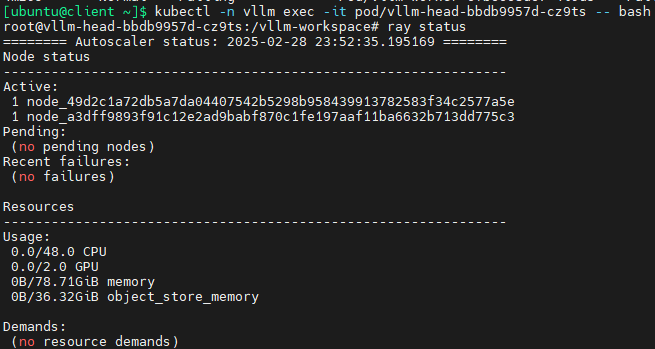
运行vllm
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--tensor-parallel-size 1 \
--pipeline-parallel-size 2 \
--max_num_batched_tokens 1024 \
--max_model_len 65536 \
--trust-remote-code \
--gpu-memory-utilization 0.95 \
--enable-chunked-prefill \
--port 8000 > vllm_serve.log 2>&1 &
查看vllm日志,可以看到vllm正常运行,此时可以尝试与大模型聊天了
tail vllm_serve.log -f
INFO 03-01 00:06:04 __init__.py:207] Automatically detected platform cuda.
INFO 03-01 00:06:04 api_server.py:912] vLLM API server version 0.7.3
INFO 03-01 00:06:04 api_server.py:913] args: Namespace(subparser='serve', model_tag='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', config='', host=None, port=8000, uvicorn_log_level='info', allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, enable_reasoning=False, reasoning_parser=None, tool_call_parser=None, tool_parser_plugin='', model='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', task='auto', tokenizer=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=True, allowed_local_media_path=None, download_dir=None, load_format='auto', config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', kv_cache_dtype='auto', max_model_len=65536, guided_decoding_backend='xgrammar', logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=2, tensor_parallel_size=1, max_parallel_loading_workers=None, ray_workers_use_nsight=False, block_size=None, enable_prefix_caching=None, disable_sliding_window=False, use_v2_block_manager=True, num_lookahead_slots=0, seed=0, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.95, num_gpu_blocks_override=None, max_num_batched_tokens=1024, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, max_num_seqs=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, disable_custom_all_reduce=False, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=False, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, multi_step_stream_outputs=True, scheduler_delay_factor=0.0, enable_chunked_prefill=True, speculative_model=None, speculative_model_quantization=None, num_speculative_tokens=None, speculative_disable_mqa_scorer=False, speculative_draft_tensor_parallel_size=None, speculative_max_model_len=None, speculative_disable_by_batch_size=None, ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None, spec_decoding_acceptance_method='rejection_sampler', typical_acceptance_sampler_posterior_threshold=None, typical_acceptance_sampler_posterior_alpha=None, disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=None, qlora_adapter_name_or_path=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, scheduling_policy='fcfs', scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', generation_config=None, override_generation_config=None, enable_sleep_mode=False, calculate_kv_scales=False, additional_config=None, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, dispatch_function=<function ServeSubcommand.cmd at 0x7f409cad7600>)
INFO 03-01 00:06:09 config.py:549] This model supports multiple tasks: {'score', 'generate', 'embed', 'reward', 'classify'}. Defaulting to 'generate'.
INFO 03-01 00:06:09 config.py:1382] Defaulting to use ray for distributed inference
INFO 03-01 00:06:09 config.py:1555] Chunked prefill is enabled with max_num_batched_tokens=1024.
WARNING 03-01 00:06:09 config.py:676] Async output processing can not be enabled with pipeline parallel
INFO 03-01 00:06:09 llm_engine.py:234] Initializing a V0 LLM engine (v0.7.3) with config: model='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', speculative_config=None, tokenizer='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.bfloat16, max_seq_len=65536, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=2, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar'), observability_config=ObservabilityConfig(otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=0, served_model_name=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=False, chunked_prefill_enabled=True, use_async_output_proc=False, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":256}, use_cached_outputs=False,
2025-03-01 00:06:10,796 INFO worker.py:1636 -- Connecting to existing Ray cluster at address: 192.168.0.69:6379...
2025-03-01 00:06:10,808 INFO worker.py:1821 -- Connected to Ray cluster.
INFO 03-01 00:06:10 ray_distributed_executor.py:153] use_ray_spmd_worker: False
(RayWorkerWrapper pid=457) INFO 03-01 00:06:12 __init__.py:207] Automatically detected platform cuda.
WARNING 03-01 00:06:12 logger.py:202] VLLM_TRACE_FUNCTION is enabled. It will record every function executed by Python. This will slow down the code. It is suggested to be used for debugging hang or crashes only.
INFO 03-01 00:06:12 logger.py:206] Trace frame log is saved to /tmp/root/vllm/vllm-instance-00838/VLLM_TRACE_FUNCTION_for_process_1827_thread_139920160649216_at_2025-03-01_00:06:12.902734.log
(RayWorkerWrapper pid=279, ip=192.168.0.70) WARNING 03-01 00:06:12 logger.py:202] VLLM_TRACE_FUNCTION is enabled. It will record every function executed by Python. This will slow down the code. It is suggested to be used for debugging hang or crashes only.
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:12 logger.py:206] Trace frame log is saved to /tmp/root/vllm/vllm-instance-00838/VLLM_TRACE_FUNCTION_for_process_279_thread_140199717167104_at_2025-03-01_00:06:12.903365.log
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:20 cuda.py:229] Using Flash Attention backend.
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:12 __init__.py:207] Automatically detected platform cuda.
INFO 03-01 00:06:20 cuda.py:229] Using Flash Attention backend.
INFO 03-01 00:06:21 utils.py:916] Found nccl from library libnccl.so.2
INFO 03-01 00:06:21 pynccl.py:69] vLLM is using nccl==2.21.5
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Bootstrap : Using eth0:192.168.0.69<0>
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO NET/Plugin: No plugin found (libnccl-net.so)
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO NET/Plugin: Plugin load returned 2 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-net.so
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO NET/Plugin: Using internal network plugin.
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO cudaDriverVersion 12080
NCCL version 2.21.5+cuda12.4
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:21 utils.py:916] Found nccl from library libnccl.so.2
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:21 pynccl.py:69] vLLM is using nccl==2.21.5
INFO 03-01 00:06:21 model_runner.py:1110] Starting to load model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B...
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:21 model_runner.py:1110] Starting to load model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B...
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:22 weight_utils.py:254] Using model weights format ['*.safetensors']
INFO 03-01 00:06:23 weight_utils.py:254] Using model weights format ['*.safetensors']
INFO 03-01 00:06:23 weight_utils.py:270] Time spent downloading weights for deepseek-ai/DeepSeek-R1-Distill-Qwen-7B: 0.655547 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.32it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.32it/s]
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:25 model_runner.py:1115] Loading model weights took 7.1512 GB
INFO 03-01 00:06:26 model_runner.py:1115] Loading model weights took 7.1512 GB
INFO 03-01 00:06:27 worker.py:267] Memory profiling takes 0.85 seconds
INFO 03-01 00:06:27 worker.py:267] the current vLLM instance can use total_gpu_memory (11.63GiB) x gpu_memory_utilization (0.95) = 11.05GiB
INFO 03-01 00:06:27 worker.py:267] model weights take 7.15GiB; non_torch_memory takes 0.09GiB; PyTorch activation peak memory takes 0.15GiB; the rest of the memory reserved for KV Cache is 3.66GiB.
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:27 worker.py:267] Memory profiling takes 0.94 seconds
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:27 worker.py:267] the current vLLM instance can use total_gpu_memory (11.63GiB) x gpu_memory_utilization (0.95) = 11.05GiB
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:27 worker.py:267] model weights take 7.15GiB; non_torch_memory takes 0.09GiB; PyTorch activation peak memory takes 1.41GiB; the rest of the memory reserved for KV Cache is 2.39GiB.
INFO 03-01 00:06:27 executor_base.py:111] # cuda blocks: 5596, # CPU blocks: 9362
INFO 03-01 00:06:27 executor_base.py:116] Maximum concurrency for 65536 tokens per request: 1.37x
INFO 03-01 00:06:28 model_runner.py:1434] Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
Capturing CUDA graph shapes: 0%| | 0/35 [00:00<?, ?it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 3%|▎ | 1/35 [00:00<00:11, 2.92it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 6%|▌ | 2/35 [00:00<00:10, 3.01it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 9%|▊ | 3/35 [00:00<00:10, 3.11it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 11%|█▏ | 4/35 [00:01<00:09, 3.17it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 14%|█▍ | 5/35 [00:01<00:09, 3.22it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 17%|█▋ | 6/35 [00:01<00:08, 3.23it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 20%|██ | 7/35 [00:02<00:08, 3.27it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 23%|██▎ | 8/35 [00:02<00:08, 3.29it/s]
Capturing CUDA graph shapes: 26%|██▌ | 9/35 [00:02<00:07, 3.31it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 29%|██▊ | 10/35 [00:03<00:07, 3.32it/s]RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 31%|███▏ | 11/35 [00:03<00:07, 3.34it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 34%|███▍ | 12/35 [00:03<00:06, 3.34it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 37%|███▋ | 13/35 [00:03<00:06, 3.36it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 40%|████ | 14/35 [00:04<00:06, 3.38it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 43%|████▎ | 15/35 [00:04<00:05, 3.38it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 46%|████▌ | 16/35 [00:04<00:05, 3.38it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 49%|████▊ | 17/35 [00:05<00:05, 3.51it/s]
Capturing CUDA graph shapes: 51%|█████▏ | 18/35 [00:05<00:04, 3.58it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 54%|█████▍ | 19/35 [00:05<00:04, 3.67it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 57%|█████▋ | 20/35 [00:05<00:04, 3.72it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 60%|██████ | 21/35 [00:06<00:03, 3.74it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 63%|██████▎ | 22/35 [00:06<00:03, 3.79it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 66%|██████▌ | 23/35 [00:06<00:03, 3.82it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 69%|██████▊ | 24/35 [00:06<00:02, 3.85it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 71%|███████▏ | 25/35 [00:07<00:02, 3.83it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 74%|███████▍ | 26/35 [00:07<00:02, 3.88it/s]
Capturing CUDA graph shapes: 77%|███████▋ | 27/35 [00:07<00:02, 3.87it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 80%|████████ | 28/35 [00:07<00:01, 3.91it/s]
Capturing CUDA graph shapes: 83%|████████▎ | 29/35 [00:08<00:01, 3.94it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 86%|████████▌ | 30/35 [00:08<00:01, 3.94it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 89%|████████▊ | 31/35 [00:08<00:01, 3.91it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 91%|█████████▏| 32/35 [00:08<00:00, 3.94it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 94%|█████████▍| 33/35 [00:09<00:00, 3.98it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 97%|█████████▋| 34/35 [00:09<00:00, 3.94it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 100%|██████████| 35/35 [00:09<00:00, 3.59it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 0%| | 0/35 [00:00<?, ?it/s]
Capturing CUDA graph shapes: 3%|▎ | 1/35 [00:00<00:11, 2.93it/s]](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 100%|██████████| 35/35 [00:10<00:00, 3.30it/s]
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:28 model_runner.py:1434] Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
Capturing CUDA graph shapes: 6%|▌ | 2/35 [00:00<00:10, 3.01it/s]erWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 9%|▊ | 3/35 [00:00<00:10, 3.05it/s]
Capturing CUDA graph shapes: 11%|█▏ | 4/35 [00:01<00:10, 3.06it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 14%|█▍ | 5/35 [00:01<00:09, 3.08it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 17%|█▋ | 6/35 [00:01<00:09, 3.10it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 20%|██ | 7/35 [00:02<00:09, 3.10it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 23%|██▎ | 8/35 [00:02<00:08, 3.11it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 26%|██▌ | 9/35 [00:02<00:08, 3.13it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 29%|██▊ | 10/35 [00:03<00:07, 3.15it/s]RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 31%|███▏ | 11/35 [00:03<00:07, 3.20it/s]RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 34%|███▍ | 12/35 [00:03<00:07, 3.26it/s]RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 37%|███▋ | 13/35 [00:04<00:06, 3.30it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 40%|████ | 14/35 [00:04<00:06, 3.33it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 43%|████▎ | 15/35 [00:04<00:06, 3.32it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 46%|████▌ | 16/35 [00:05<00:05, 3.31it/s]
Capturing CUDA graph shapes: 49%|████▊ | 17/35 [00:05<00:05, 3.44it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 51%|█████▏ | 18/35 [00:05<00:04, 3.55it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 54%|█████▍ | 19/35 [00:05<00:04, 3.63it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 57%|█████▋ | 20/35 [00:06<00:04, 3.68it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 60%|██████ | 21/35 [00:06<00:03, 3.73it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 63%|██████▎ | 22/35 [00:06<00:03, 3.78it/s]
Capturing CUDA graph shapes: 66%|██████▌ | 23/35 [00:06<00:03, 3.82it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 69%|██████▊ | 24/35 [00:07<00:02, 3.85it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 71%|███████▏ | 25/35 [00:07<00:02, 3.90it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 74%|███████▍ | 26/35 [00:07<00:02, 3.93it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 77%|███████▋ | 27/35 [00:07<00:02, 3.96it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 80%|████████ | 28/35 [00:08<00:01, 3.97it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 83%|████████▎ | 29/35 [00:08<00:01, 3.97it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 86%|████████▌ | 30/35 [00:08<00:01, 4.00it/s]
Capturing CUDA graph shapes: 89%|████████▊ | 31/35 [00:08<00:00, 4.03it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 91%|█████████▏| 32/35 [00:09<00:00, 4.07it/s]
Capturing CUDA graph shapes: 94%|█████████▍| 33/35 [00:09<00:00, 4.03it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 97%|█████████▋| 34/35 [00:09<00:00, 4.00it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 100%|██████████| 35/35 [00:09<00:00, 3.56it/s](RayWorkerWrapper pid=279, ip=192.168.0.70)
Capturing CUDA graph shapes: 100%|██████████| 35/35 [00:10<00:00, 3.31it/s]
(RayWorkerWrapper pid=279, ip=192.168.0.70) INFO 03-01 00:06:48 model_runner.py:1562] Graph capturing finished in 20 secs, took 0.19 GiB
INFO 03-01 00:06:49 model_runner.py:1562] Graph capturing finished in 21 secs, took 0.19 GiB
INFO 03-01 00:06:49 llm_engine.py:436] init engine (profile, create kv cache, warmup model) took 23.68 seconds
INFO 03-01 00:06:52 api_server.py:958] Starting vLLM API server on http://0.0.0.0:8000
INFO 03-01 00:06:52 launcher.py:23] Available routes are:
INFO 03-01 00:06:52 launcher.py:31] Route: /openapi.json, Methods: HEAD, GET
INFO 03-01 00:06:52 launcher.py:31] Route: /docs, Methods: HEAD, GET
INFO 03-01 00:06:52 launcher.py:31] Route: /docs/oauth2-redirect, Methods: HEAD, GET
INFO 03-01 00:06:52 launcher.py:31] Route: /redoc, Methods: HEAD, GET
INFO 03-01 00:06:52 launcher.py:31] Route: /health, Methods: GET
INFO 03-01 00:06:52 launcher.py:31] Route: /ping, Methods: GET, POST
INFO 03-01 00:06:52 launcher.py:31] Route: /tokenize, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /detokenize, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /v1/models, Methods: GET
INFO 03-01 00:06:52 launcher.py:31] Route: /version, Methods: GET
INFO 03-01 00:06:52 launcher.py:31] Route: /v1/chat/completions, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /v1/completions, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /v1/embeddings, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /pooling, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /score, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /v1/score, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /v1/audio/transcriptions, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /rerank, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /v1/rerank, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /v2/rerank, Methods: POST
INFO 03-01 00:06:52 launcher.py:31] Route: /invocations, Methods: POST
INFO: Started server process [1827]
INFO: Waiting for application startup.
INFO: Application startup complete.
因为上述的yaml文件中,service是cluster类型的,而且也没有创建ingress,所以无法从外部网络调用API,为了方便验证,可以直接进入vllm-head pod中的容器执行curl命令
kubectl -n vllm exec -it pod/vllm-head-bbdb9957d-cz9ts -- bash
curl --request POST \
-H "Content-Type: application/json" \
--url http://$IP_OF_HEAD_NODE:8000/v1/chat/completions \
--data '{"messages":[{"role":"user","content":"给我推荐中国适合旅游的方"}],"stream":false,"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"}'
输出如下:

再次查看vllm的日志,可以发现vllm确实检测到了post请求,详细的日志解读往下看
INFO 03-01 00:19:40 chat_utils.py:332] Detected the chat template content format to be 'string'. You can set `--chat-template-content-format` to override this.
INFO 03-01 00:19:40 logger.py:39] Received request chatcmpl-1d06d3cea5f34edd9e51b9f48a92284f: prompt: '<|begin▁of▁sentence|><|User|>给我推荐中国适合旅游的方<|Assistant|><think>\n', params: SamplingParams(n=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.0, temperature=1.0, top_p=1.0, top_k=-1, min_p=0.0, seed=None, stop=[], stop_token_ids=[], bad_words=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=65524, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True, truncate_prompt_tokens=None, guided_decoding=None), prompt_token_ids: None, lora_request: None, prompt_adapter_request: None.
INFO 03-01 00:19:40 async_llm_engine.py:211] Added request chatcmpl-1d06d3cea5f34edd9e51b9f48a92284f.
/usr/local/lib/python3.12/dist-packages/vllm/distributed/parallel_state.py:408: UserWarning: The given buffer is not writable, and PyTorch does not support non-writable tensors. This means you can write to the underlying (supposedly non-writable) buffer using the tensor. You may want to copy the buffer to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:1560.)
object_tensor = torch.frombuffer(pickle.dumps(obj), dtype=torch.uint8)
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO NCCL_IB_DISABLE set by environment to 1.
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO NET/Socket : Using [0]eth0:192.168.0.69<0>
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Using non-device net plugin version 0
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Using network Socket
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO ncclCommInitRank comm 0x451d03d0 rank 0 nranks 2 cudaDev 0 nvmlDev 0 busId 1000 commId 0x1d4c79f95611512d - Init START
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO NCCL_CUMEM_ENABLE set by environment to 0.
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO comm 0x451d03d0 rank 0 nRanks 2 nNodes 2 localRanks 1 localRank 0 MNNVL 0
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Channel 00/02 : 0 1
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Channel 01/02 : 0 1
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Trees [0] 1/-1/-1->0->-1 [1] -1/-1/-1->0->1
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO P2P Chunksize set to 131072
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Channel 00/0 : 1[0] -> 0[0] [receive] via NET/Socket/0
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Channel 01/0 : 1[0] -> 0[0] [receive] via NET/Socket/0
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Channel 00/0 : 0[0] -> 1[0] [send] via NET/Socket/0
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Channel 01/0 : 0[0] -> 1[0] [send] via NET/Socket/0
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Connected all rings
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO Connected all trees
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 512 | 512
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO 2 coll channels, 2 collnet channels, 0 nvls channels, 2 p2p channels, 2 p2p channels per peer
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO TUNER/Plugin: Plugin load returned 2 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-tuner.so
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO TUNER/Plugin: Using internal tuner plugin.
vllm-head-bbdb9957d-cz9ts:1827:1827 [0] NCCL INFO ncclCommInitRank comm 0x451d03d0 rank 0 nranks 2 cudaDev 0 nvmlDev 0 busId 1000 commId 0x1d4c79f95611512d - Init COMPLETE
[rank0]:[W301 00:19:40.895581544 ProcessGroupNCCL.cpp:3057] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS=1 has no effect for point-to-point collectives. (function operator())
(RayWorkerWrapper pid=279, ip=192.168.0.70) [rank1]:[W301 00:19:40.895424301 ProcessGroupNCCL.cpp:3057] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS=1 has no effect for point-to-point collectives. (function operator())
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO cudaDriverVersion 12080
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Bootstrap : Using eth0:192.168.0.70<0>
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO NET/Plugin: No plugin found (libnccl-net.so)
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO NET/Plugin: Plugin load returned 2 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-net.so
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO NET/Plugin: Using internal network plugin.
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO NCCL_IB_DISABLE set by environment to 1.
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO NET/Socket : Using [0]eth0:192.168.0.70<0>
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Using non-device net plugin version 0
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Using network Socket
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO ncclCommInitRank comm 0x420a5990 rank 1 nranks 2 cudaDev 0 nvmlDev 0 busId 1000 commId 0x1d4c79f95611512d - Init START
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO NCCL_CUMEM_ENABLE set by environment to 0.
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO comm 0x420a5990 rank 1 nRanks 2 nNodes 2 localRanks 1 localRank 0 MNNVL 0
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Trees [0] -1/-1/-1->1->0 [1] 0/-1/-1->1->-1
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO P2P Chunksize set to 131072
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Channel 00/0 : 0[0] -> 1[0] [receive] via NET/Socket/0
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Channel 01/0 : 0[0] -> 1[0] [receive] via NET/Socket/0
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Channel 00/0 : 1[0] -> 0[0] [send] via NET/Socket/0
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Channel 01/0 : 1[0] -> 0[0] [send] via NET/Socket/0
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Connected all rings
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO Connected all trees
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 512 | 512
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO 2 coll channels, 2 collnet channels, 0 nvls channels, 2 p2p channels, 2 p2p channels per peer
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO TUNER/Plugin: Plugin load returned 2 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-tuner.so
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO TUNER/Plugin: Using internal tuner plugin.
(RayWorkerWrapper pid=279, ip=192.168.0.70) vllm-worker-6fb6668d67-4l9d5:279:279 [0] NCCL INFO ncclCommInitRank comm 0x420a5990 rank 1 nranks 2 cudaDev 0 nvmlDev 0 busId 1000 commId 0x1d4c79f95611512d - Init COMPLETE
INFO 03-01 00:19:45 metrics.py:455] Avg prompt throughput: 2.4 tokens/s, Avg generation throughput: 15.6 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.1%, CPU KV cache usage: 0.0%.
INFO 03-01 00:19:50 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 16.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.2%, CPU KV cache usage: 0.0%.
INFO 03-01 00:19:55 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 16.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.3%, CPU KV cache usage: 0.0%.
INFO 03-01 00:20:00 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 16.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.4%, CPU KV cache usage: 0.0%.
INFO 03-01 00:20:05 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 16.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.5%, CPU KV cache usage: 0.0%.
INFO 03-01 00:20:10 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 16.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.6%, CPU KV cache usage: 0.0%.
INFO 03-01 00:20:15 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 16.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.7%, CPU KV cache usage: 0.0%.
INFO 03-01 00:20:20 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 16.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.8%, CPU KV cache usage: 0.0%.
INFO 03-01 00:20:24 async_llm_engine.py:179] Finished request chatcmpl-1d06d3cea5f34edd9e51b9f48a92284f.
INFO: 10.152.183.168:49464 - "POST /v1/chat/completions HTTP/1.1" 200 OK
INFO 03-01 00:20:33 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 5.8 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
INFO 03-01 00:20:43 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
上述日志解读:
以下是vLLM日志的简化解释(关键信息分层说明):
---
### **1. 请求处理流程**
- **请求接收**(00:19:40):
用户请求ID `chatcmpl-1d06d3cea5f34edd9e51b9f48a92284f` 被加入队列,请求内容是推荐中国旅游地。引擎参数为默认(`temperature=1.0`,无重复惩罚等)。
- **分布式初始化**(00:19:40-00:19:45):
vLLM通过Ray框架启动分布式推理,使用两个GPU节点(IP `192.168.0.69` 和 `192.168.0.70`),通过NCCL(NVIDIA集合通信库)建立通信通道。日志中显示网络使用`eth0`接口,并初始化张量并行(`tensor-parallel-size=2`)。
---
### **2. 分布式通信细节**
- **NCCL配置**:
- 使用`Socket`网络协议,禁用InfiniBand(`NCCL_IB_DISABLE=1`)。
- 通信通道分配:两个节点间通过`Channel 00/02`和`Channel 01/02`交换数据,块大小(`Chunksize`)设为`131072`。
- **警告信息**:
- `TORCH_NCCL_AVOID_RECORD_STREAMS=1`对点对点通信无效,属于PyTorch框架的兼容性提示,不影响运行。
---
### **3. 性能指标**
- **吞吐量**:
- 输入处理(Prompt)速度:初始`2.4 tokens/s`,后续稳定为`0 tokens/s`(表示输入已完全加载)。
- 生成(Generation)速度:稳定在`15.6-16.2 tokens/s`,显示模型推理效率较高。
- **资源占用**:
- GPU KV缓存使用率从`0.1%`逐步升至`0.8%`,CPU缓存未使用(`0.0%`),表明显存管理高效。
---
### **4. 请求完成**
- **结束时间**(00:20:24):
请求成功处理完毕,返回HTTP状态码`200 OK`,总耗时约44秒(含初始化)。
- **空闲状态**(00:20:33后):
系统进入空闲,吞吐量归零,无排队或挂起请求。
---
### **关键结论**
- **分布式优势**:vLLM通过Ray和NCCL实现多GPU协同,适合大模型推理。
- **性能优化**:KV缓存显存占用极低(<1%),生成速度稳定,体现PagedAttention技术的高效性。
- **日志警告无害**:NCCL和PyTorch的警告多为环境配置提示,不影响服务正常运行。
如需更具体的某段日志分析,可提供对应行内容。
外部网络访问vllm
如果想要在外部网络访问vllm,可以将service改为nodeport或者添加ingress,下面是将service改为nodeport的示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: vllm-config
namespace: vllm
data:
IP_OF_HEAD_NODE: "vllm-head-service.vllm.svc.cluster.local" # 主机网络模式可填 ray head node 的 IP 地址
CUDA_DEVICE_ORDER: "PCI_BUS_ID"
NCCL_DEBUG: "TRACE" # 调试信息级别,可根据需要调整
NCCL_IB_DISABLE: "1" # 禁用 InfiniBand,根据实际情况调整
VLLM_TRACE_FUNCTION: "1"
HF_ENDPOINT: "https://hf-mirror.com"
HTTP_PROXY: "http://<此处替换为实际的代理服务器地址或域名>:port"
HTTPS_PROXY: "http://<此处替换为实际的代理服务器地址或域名>:port"
NO_PROXY: "10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/16,.svc,dltornado2.com,dltornado.com,geekery.cn,daocloud.io,aliyun.com,mywind.com.cn,quay.io,localhost,security.ubuntu.com"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-head-service
namespace: vllm
spec:
type: NodePort
selector:
app: vllm-head
ports:
- name: ray-port
protocol: TCP
port: 6379
targetPort: 6379
- name: object-manager-port
protocol: TCP
port: 8625
targetPort: 8625
- name: deepseek-r1-distill-qwen-7b
port: 8000
protocol: TCP
targetPort: 8000
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-head
namespace: vllm
spec:
replicas: 1
selector:
matchLabels:
app: vllm-head
template:
metadata:
labels:
app: vllm-head
spec:
nodeSelector:
nvidia.com/gpu.machine: "Precision-3660" # 假设GPU节点的标签是nvidia.com/gpu.machine: "Precision-3660"
vllm-role: "vllm-head"
# hostNetwork: true # 主机网络模式,根据实际情况调整
containers:
- name: vllm-head
image: vllm/vllm-openai:latest
command:
- "/bin/bash"
args:
- "-c"
- |
ray start --head --port=6379 --dashboard-host=0.0.0.0 --object-manager-port=8625 --block
securityContext:
privileged: true
volumeMounts:
- name: shm
mountPath: /dev/shm
- name: cache-volume
mountPath: /root/.cache/huggingface
envFrom:
- configMapRef:
name: vllm-config
volumes:
- name: shm
emptyDir:
medium: Memory
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-worker
namespace: vllm
spec:
replicas: 1
selector:
matchLabels:
app: vllm-worker
template:
metadata:
labels:
app: vllm-worker
spec:
nodeSelector:
nvidia.com/gpu.machine: "Precision-3660" # 假设GPU节点的标签是nvidia.com/gpu.machine: "Precision-3660"
vllm-role: "vllm-worker"
# hostNetwork: true # 主机网络模式,根据实际情况调整
containers:
- name: vllm-worker
image: vllm/vllm-openai:latest
command:
- "/bin/bash"
args:
- "-c"
- |
ray start --address=${IP_OF_HEAD_NODE}:6379 --block
securityContext:
privileged: true
volumeMounts:
- name: cache-volume
mountPath: /root/.cache/huggingface
- name: shm
mountPath: /dev/shm
envFrom:
- configMapRef:
name: vllm-config
volumes:
- name: shm
emptyDir:
medium: Memory
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
验证,在外部网络下(k8s集群之外)调用api
curl --request POST \
-H "Content-Type: application/json" \
--url http://172.16.0.5:31990/v1/chat/completions \
--data '{"messages":[{"role":"user","content":"简要介绍ragflow"}],"stream":false,"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"}'

添加api key
默认情况下vllm是不需要api key就可以访问的,如果想添加api key,非常简单,只需要在vllm serve命令中添加一个参数即可,如下,关键是--api-key这个参数
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--tensor-parallel-size 1 \
--pipeline-parallel-size 2 \
--max_num_batched_tokens 1024 \
--max_model_len 65536 \
--api-key token-iamtornado888 \
--trust-remote-code \
--gpu-memory-utilization 0.95 \
--enable-chunked-prefill \
--port 8000 > vllm_serve.log 2>&1 &
验证
curl命令必须要再添加一个header,如下第三行所示,特别注意,一定要在apikey之前加上Bearer,否则会提示"error": "Unauthorized"
curl --request POST \
-H "Content-Type: application/json" \
--header 'Authorization: Bearer token-iamtornado888' \
--url http://172.16.0.5:31990/v1/chat/completions \
--data '{"messages":[{"role":"user","content":"简要介绍ragflow"}],"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"}' | jq .
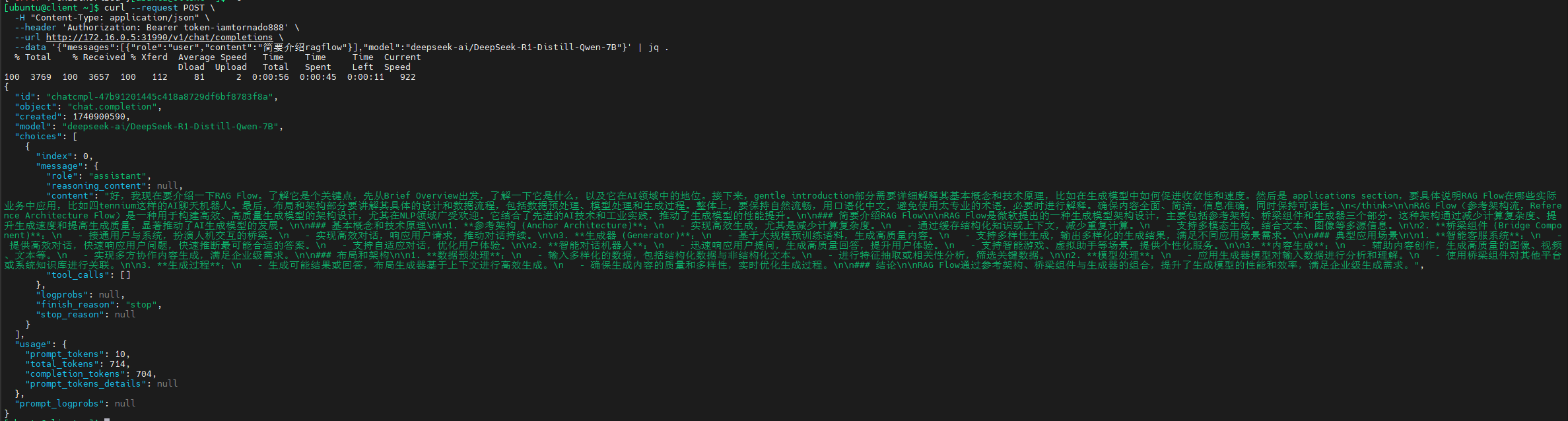
如果不添加api key,或者提供的api key不对,则会报错:

运行model–DeepSeek-R1-4bit
Deployment-DeepSeek-R1-4bit.yaml
cat <<EOF > Deployment-DeepSeek-R1-4bit.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-r1-4bit
namespace: vllm
labels:
app: deepseek-r1-4bit
spec:
replicas: 4
selector:
matchLabels:
app: deepseek-r1-4bit
template:
metadata:
labels:
app: deepseek-r1-4bit
spec:
volumes:
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
# vLLM needs to access the host's shared memory for tensor parallel inference.
- name: shm
emptyDir:
medium: Memory
containers:
- name: deepseek-r1-4bit
image: vllm/vllm-openai:latest
command: ["/bin/sh", "-c"]
args: [
"vllm serve mlx-community/DeepSeek-R1-4bit --trust-remote-code --enable-chunked-prefill --max_num_batched_tokens 1024"
]
env:
- name: CUDA_DEVICE_ORDER
value: "PCI_BUS_ID" # 关键配置
ports:
- containerPort: 8000
volumeMounts:
- mountPath: /root/.cache/huggingface
name: cache-volume
- name: shm
mountPath: /dev/shm
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60
periodSeconds: 5
EOF
kubectl apply -f Deployment-DeepSeek-R1-4bit.yaml

容器比较大,下载时间会比较长
容器镜像高达8.3GB
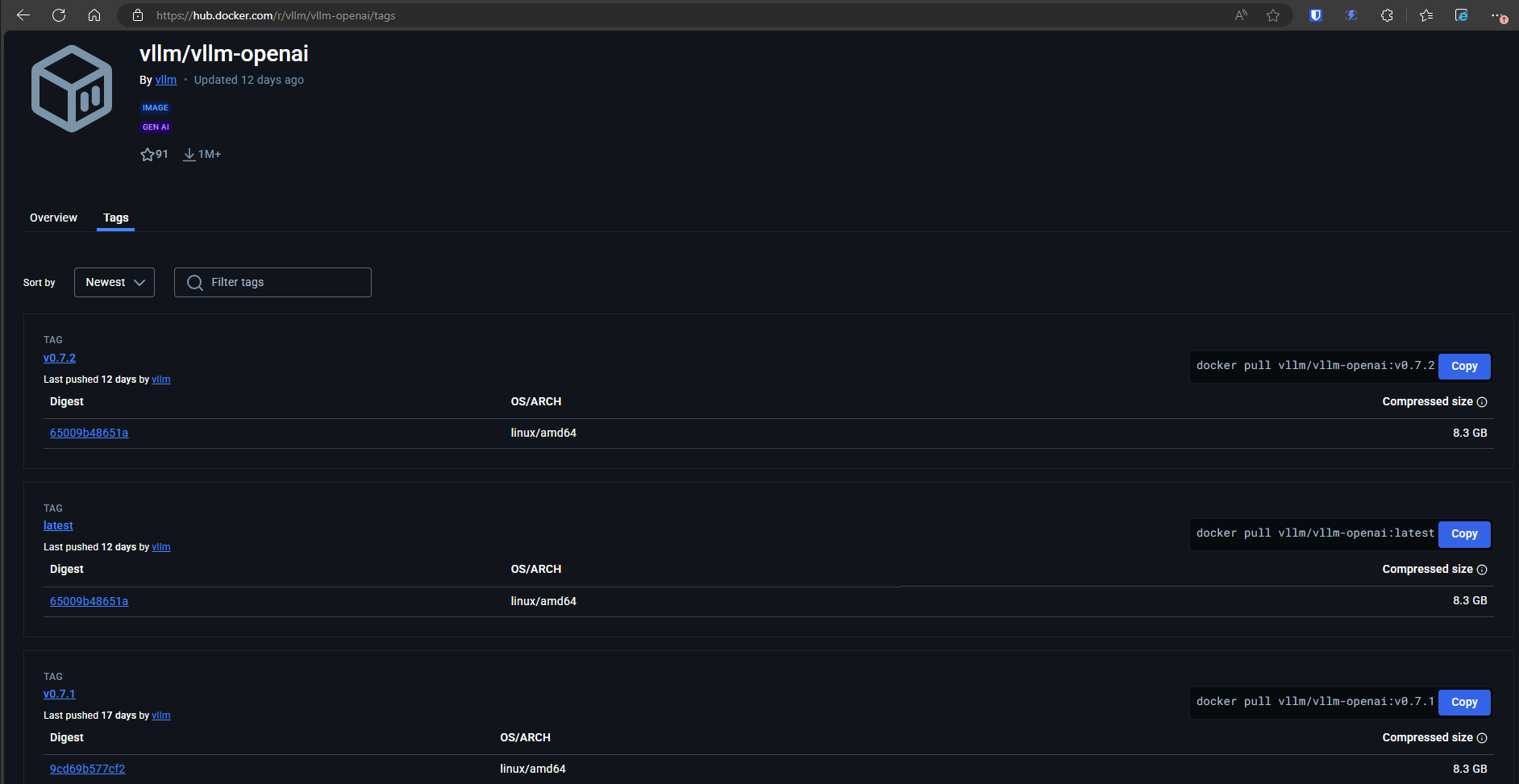
创建一个service
apiVersion: v1
kind: Service
metadata:
name: deepseek-r1-distill-qwen-15b
namespace: vllm
spec:
ports:
- name: deepseek-r1-distill-qwen-15b
port: 80
protocol: TCP
targetPort: 8000
# The label selector should match the deployment labels & it is useful for prefix caching feature
selector:
app: DeepSeek-R1-Distill-Qwen-1.5B
sessionAffinity: None
type: ClusterIP
ingress yaml
GNU nano 7.2 ingress-deepseek-r1-distill-qwen-15b.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: deepseek-r1-ingress
namespace: vllm
annotations:
# 以下为Nginx Ingress的示例注解,其他控制器可能需要不同配置
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: "deepseek.dltornado2.com" # 替换为您的实际域名
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: deepseek-r1-distill-qwen-15b # 必须与Service名称完全匹配
port:
number: 8000 # 必须与Service暴露的端口匹配
多节点运行model–DeepSeek-R1-Distill-Qwen-7B
用Huggingfac-cli下载模型文件
#huggingface-cli是官方命令,--token只有在下载一些需要登录的模型时才需要指定,下载deepseek模型也是可以不指定的
pip install -U huggingface_hub
#HF_HUB_DOWNLOAD_TIMEOUT环境变量的作用是设置hugggingface-cli下载文件时的超时时间,默认为10s,如果不延迟超时时间,则经常中断下载。
export HF_HUB_DOWNLOAD_TIMEOUT=18000
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
下载完成后,是这样的:
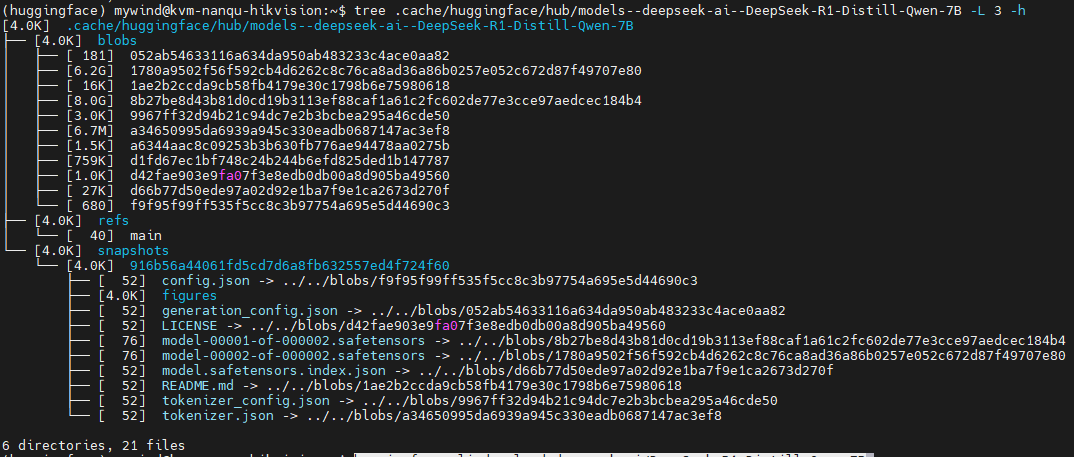
将下载好的模型文件预先上传到cephfs的subvolume中
sudo rsync -avP --rsh=ssh mywind@10.65.37.240:/home/mywind/.cache/huggingface/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B /mnt/cephfs/hub/

Deployment-DeepSeek-R1-Distill-Qwen-7B.yaml文件包含了所有需要的资源,如configmap、service、Deployment
先用这个yaml文件搭建ray集群,然后再进入容器内执行vllm命令运行model
cat << 'EOF' > Deployment-DeepSeek-R1-Distill-Qwen-7B.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: vllm-config
namespace: vllm
data:
IP_OF_HEAD_NODE: "vllm-head-service.vllm.svc.cluster.local" # 主机网络模式可填 ray head node 的 IP 地址
CUDA_DEVICE_ORDER: "PCI_BUS_ID"
NCCL_DEBUG: "TRACE" # 调试信息级别,可根据需要调整
NCCL_IB_DISABLE: "1" # 禁用 InfiniBand,根据实际情况调整
VLLM_TRACE_FUNCTION: "1"
HF_ENDPOINT: "https://hf-mirror.com"
HTTP_PROXY: "http://<此处替换为实际的代理服务器地址或域名>:port"
HTTPS_PROXY: "http://<此处替换为实际的代理服务器地址或域名>:port"
NO_PROXY: "10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/16,.svc,dltornado2.com,dltornado.com,geekery.cn,daocloud.io,aliyun.com,mywind.com.cn,quay.io,localhost,security.ubuntu.com"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-head-service
namespace: vllm
annotations:
nvidia.com/gpu.devicemappings: '{"device-0": "GPU-4ded26bd-139a-16f9-c37d-40603b832cf8","device-2": "GPU-c077873b-946e-d2d7-0a1c-6f98991ec941","device-3": "GPU-01fe0b8c-f486-b9a2-1b42-beeb3ee5ca55","device-4": "GPU-9496efc9-150a-bdee-0990-40c1c1c5e4fc"}' # 指定物理GPU ID
spec:
selector:
app: vllm-head
ports:
- name: ray-port
protocol: TCP
port: 6379
targetPort: 6379
- name: object-manager-port
protocol: TCP
port: 8625
targetPort: 8625
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-head
namespace: vllm
spec:
replicas: 1
selector:
matchLabels:
app: vllm-head
template:
metadata:
labels:
app: vllm-head
spec:
nodeSelector:
nvidia.com/gpu.machine: "Precision-7920-Tower" # 假设GPU节点的标签是nvidia.com/gpu.machine: "Precision-7920-Tower"
vllm-role: "vllm-head"
# hostNetwork: true # 主机网络模式,根据实际情况调整
containers:
- name: vllm-head
image: vllm/vllm-openai:latest
command:
- "/bin/bash"
args:
- "-c"
- |
ray start --head --port=6379 --dashboard-host=0.0.0.0 --object-manager-port=8625 --block
securityContext:
privileged: true
volumeMounts:
- name: shm
mountPath: /dev/shm
- name: cache-volume
mountPath: /root/.cache/huggingface
envFrom:
- configMapRef:
name: vllm-config
env:
- name: CUDA_VISIBLE_DEVICES
value: "0,2,3,4" # 对应k8s分配的GPU逻辑编号
volumes:
- name: shm
emptyDir:
medium: Memory
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-worker
namespace: vllm
annotations:
nvidia.com/gpu.devicemappings: '{"device-1": "GPU-d255c36c-a9e6-af3b-a9ee-5a6e0d7ba7d4","device-2": "GPU-4617a5b9-ceba-75c4-b56f-ed595ccbbf18}' # 指定物理GPU ID
spec:
replicas: 1
selector:
matchLabels:
app: vllm-worker
template:
metadata:
labels:
app: vllm-worker
spec:
nodeSelector:
nvidia.com/gpu.machine: "Precision-7920-Tower" # 假设GPU节点的标签是nvidia.com/gpu.machine: "Precision-7920-Tower"
vllm-role: "vllm-worker"
# hostNetwork: true # 主机网络模式,根据实际情况调整
containers:
- name: vllm-worker
image: vllm/vllm-openai:latest
command:
- "/bin/bash"
args:
- "-c"
- |
ray start --address=${IP_OF_HEAD_NODE}:6379 --block
securityContext:
privileged: true
volumeMounts:
- name: cache-volume
mountPath: /root/.cache/huggingface
- name: shm
mountPath: /dev/shm
envFrom:
- configMapRef:
name: vllm-config
env:
- name: CUDA_VISIBLE_DEVICES
value: "1,2" # 对应k8s分配的GPU逻辑编号
volumes:
- name: shm
emptyDir:
medium: Memory
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
EOF
检查 ray 集群状态,随机找ray集群中的节点就行,运行下行命令
kubectl -n vllm exec -it pod/vllm-head-76545d88b5-9srjk -- bash
ray status
可以看到,ray集群有两个节点,还能看到资源信息
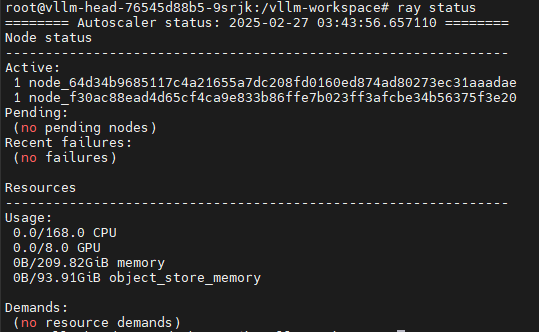
资源使用情况(Resources)含义解读:
查看vllm-head pod的日志
kubectl -n vllm logs pod/vllm-head-76545d88b5-9srjk --follow
可以看到,没有报错,ray正常运行,而且正在监听6379端口
kubectl -n vllm logs pod/vllm-head-76545d88b5-9srjk --follow
[2025-02-27 03:38:02,096 W 1 1] global_state_accessor.cc:463: Retrying to get node with node ID 64d34b9685117c4a21655a7dc208fd0160ed874ad80273ec31aaadae
2025-02-27 03:38:00,325 INFO usage_lib.py:467 -- Usage stats collection is enabled by default without user confirmation because this terminal is detected to be non-interactive. To disable this, add `--disable-usage-stats` to the command that starts the cluster, or run the following command: `ray disable-usage-stats` before starting the cluster. See https://docs.ray.io/en/master/cluster/usage-stats.html for more details.
2025-02-27 03:38:00,325 INFO scripts.py:823 -- Local node IP: 192.168.0.146
2025-02-27 03:38:03,120 SUCC scripts.py:860 -- --------------------
2025-02-27 03:38:03,120 SUCC scripts.py:861 -- Ray runtime started.
2025-02-27 03:38:03,120 SUCC scripts.py:862 -- --------------------
2025-02-27 03:38:03,121 INFO scripts.py:864 -- Next steps
2025-02-27 03:38:03,121 INFO scripts.py:867 -- To add another node to this Ray cluster, run
2025-02-27 03:38:03,121 INFO scripts.py:870 -- ray start --address='192.168.0.146:6379'
2025-02-27 03:38:03,121 INFO scripts.py:879 -- To connect to this Ray cluster:
2025-02-27 03:38:03,121 INFO scripts.py:881 -- import ray
2025-02-27 03:38:03,121 INFO scripts.py:882 -- ray.init()
2025-02-27 03:38:03,121 INFO scripts.py:913 -- To terminate the Ray runtime, run
2025-02-27 03:38:03,121 INFO scripts.py:914 -- ray stop
2025-02-27 03:38:03,121 INFO scripts.py:917 -- To view the status of the cluster, use
2025-02-27 03:38:03,121 INFO scripts.py:918 -- ray status
2025-02-27 03:38:03,122 INFO scripts.py:1031 -- --block
2025-02-27 03:38:03,122 INFO scripts.py:1032 -- This command will now block forever until terminated by a signal.
2025-02-27 03:38:03,122 INFO scripts.py:1035 -- Running subprocesses are monitored and a message will be printed if any of them terminate unexpectedly. Subprocesses exit with SIGTERM will be treated as graceful, thus NOT reported.
查看vllm-worker pod的日志
kubectl -n vllm logs pod/vllm-worker-86fbc9c96-554js --follow
可以看到,ray已启动,没有报错信息
kubectl -n vllm logs pod/vllm-worker-86fbc9c96-554js --follow
2025-02-27 03:38:01,829 INFO scripts.py:1005 -- Local node IP: 192.168.0.147
2025-02-27 03:38:02,169 SUCC scripts.py:1018 -- --------------------
2025-02-27 03:38:02,169 SUCC scripts.py:1019 -- Ray runtime started.
2025-02-27 03:38:02,169 SUCC scripts.py:1020 -- --------------------
2025-02-27 03:38:02,170 INFO scripts.py:1022 -- To terminate the Ray runtime, run
2025-02-27 03:38:02,170 INFO scripts.py:1023 -- ray stop
2025-02-27 03:38:02,170 INFO scripts.py:1031 -- --block
2025-02-27 03:38:02,170 INFO scripts.py:1032 -- This command will now block forever until terminated by a signal.
2025-02-27 03:38:02,170 INFO scripts.py:1035 -- Running subprocesses are monitored and a message will be printed if any of them terminate unexpectedly. Subprocesses exit with SIGTERM will be treated as graceful, thus NOT reported.
开始运行vllm
nohup vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--tensor-parallel-size 4 \
--pipeline-parallel-size 1 \
--max_num_batched_tokens 1024 \
--dtype half \
--enforce_eager \
--trust-remote-code \
--disable_custom_all_reduce \
--enable-chunked-prefill > vllm_serve.log 2>&1 &
查看日志:
troubleshooting
vllm worker节点没有正常连接到head节点
kubectl -n vllm describe pod/vllm-worker-5cd4c9d457-sjv4l 查询pod详细信息发现bash命令不对,没有ip地址,这说明环境变量有问题
kubectl -n vllm describe pod/vllm-worker-5cd4c9d457-sjv4l
Name: vllm-worker-5cd4c9d457-sjv4l
Namespace: vllm
Priority: 0
Service Account: default
Node: k8s-worker02/172.16.0.5
Start Time: Thu, 27 Feb 2025 17:59:43 +0800
Labels: app=vllm-worker
pod-template-hash=5cd4c9d457
Annotations: ovn.kubernetes.io/allocated: true
ovn.kubernetes.io/cidr: 192.168.0.0/16
ovn.kubernetes.io/gateway: 192.168.0.1
ovn.kubernetes.io/ip_address: 192.168.0.140
ovn.kubernetes.io/logical_router: ovn-cluster
ovn.kubernetes.io/logical_switch: ovn-default
ovn.kubernetes.io/mac_address: 00:00:00:81:FC:03
ovn.kubernetes.io/pod_nic_type: veth-pair
ovn.kubernetes.io/routed: true
Status: Running
IP: 192.168.0.140
IPs:
IP: 192.168.0.140
Controlled By: ReplicaSet/vllm-worker-5cd4c9d457
Containers:
vllm-worker:
Container ID: containerd://505e0104bd60bae42906498b3e91eca3b9472206b505b8788f12b49f83642c35
Image: vllm/vllm-openai:latest
Image ID: docker.io/vllm/vllm-openai@sha256:4f4037303e8c7b69439db1077bb849a0823517c0f785b894dc8e96d58ef3a0c2
Port: <none>
Host Port: <none>
Command:
/bin/bash
Args:
-c
ray start --address=:6379 --block
State: Running
Started: Thu, 27 Feb 2025 19:00:09 +0800
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Thu, 27 Feb 2025 18:48:01 +0800
Finished: Thu, 27 Feb 2025 19:00:03 +0800
Ready: True
Restart Count: 5
Environment Variables from:
vllm-config ConfigMap Optional: false
Environment: <none>
Mounts:
/dev/shm from shm (rw)
/root/.cache/huggingface from cache-volume (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-66q5l (ro)
于是我进入相应的容器中验证环境变量是否有误,如下,环境变量没有问题
kubectl -n vllm exec -it pod/vllm-worker-5cd4c9d457-sjv4l -- bash
root@vllm-worker-5cd4c9d457-sjv4l:/vllm-workspace# env | grep IP_OF_HEAD_NODE
IP_OF_HEAD_NODE=vllm-head-service.vllm.svc.cluster.local
然后我打开yaml文件,发现里面有好多空格,这不符合yaml文件的规范,要删除这些空格,然后再次应用yaml文件,然而问题依然存在,其实出错的原因很简单,就是因为我是用cat命令创建的yaml文件,其会将$符号解释为特殊的字符,所以yaml文件本身就没有环境变量了,看下面第二张图
ValueError: Total number of attention heads (28) must be divisible by tensor parallel size (8).
原先的命令是这个,可以看到参数–tensor-parallel-size的值为8,报错信息已经说了,这个值必须要能被 attention heads (28)整除,也就是说只能是1、2、4、7、12、14和28这几个值,8无法被28整除,不允许如此设置。
为何attention heads的值是28呢?这是模型文件中的config.json决定的,看下图
nohup vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --tensor-parallel-size 2 --pipeline-parallel-size 2 --max_num_batched_tokens 1024 --dtype half --gpu-memory-utilization 0.8 --disable-custom-kernels --trust-remote-code --enforce-eager --enable-chunked-prefill > vllm_serve.log 2>&1 &
RuntimeError: Found Quadro P2000 which is too old to be supported by the triton GPU compiler, which is used as the backend. Triton only supports devices of CUDA Capability >= 7.0, but your device is of CUDA capability 6.1
参考资料,官方的兼容性矩阵:Compatibility Matrix — vLLM
表明 GPU计算能力不足。具体来说:
-
Quadro P2000的CUDA计算能力为6.1,而vLLM依赖的Triton编译器要求最低CUDA计算能力7.0(如Volta、Turing、Ampere架构的GPU)
-
此问题在分布式推理中尤为突出,因为vLLM的跨节点通信(NCCL)和内核优化(如FlashAttention)需要较新GPU架构支持。
解决方案:
我尝试过添加这两个参数 --disable_custom_all_reduce和–force_eager问题依然存在
要想彻底解决,显卡的CUDA capability至少要是7.0 NVIDIA GTX 1660S的CUDA capability是7.5,是支持的,P2000不支持(CUDA capability是6.1)
我尝试过,如果只在一个节点上进行多GPU推理,还是会报错,显卡的CUDA capability至少要是7.0,也就是GPU架构至少是volta架构的
如何指定具体的GPU给pod使用
查询GPU的型号,UUID和编号
nvidia-smi --query-gpu=gpu_name,uuid,index --format=csv

也可以用这个命令:nvidia-smi -L

Deployment-DeepSeek-R1-Distill-Qwen-7B.yaml文件也要做相应调整,主要是用到了环境变量CUDA_VISIBLE_DEVICES,还有在Deployment中的annotation指定了GPU的UUID
实践表面,不需要特地指定resources,按照下面的yaml文件是满足要求的
cat << 'EOF' > Deployment-DeepSeek-R1-Distill-Qwen-7B.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: vllm-config
namespace: vllm
data:
IP_OF_HEAD_NODE: "vllm-head-service.vllm.svc.cluster.local" # 主机网络模式可填 ray head node 的 IP 地址
CUDA_DEVICE_ORDER: "PCI_BUS_ID"
NCCL_DEBUG: "TRACE" # 调试信息级别,可根据需要调整
NCCL_IB_DISABLE: "1" # 禁用 InfiniBand,根据实际情况调整
VLLM_TRACE_FUNCTION: "1"
HF_ENDPOINT: "https://hf-mirror.com"
HTTP_PROXY: "http://<此处替换为实际的代理服务器地址或域名>:port"
HTTPS_PROXY: "http://<此处替换为实际的代理服务器地址或域名>:port"
NO_PROXY: "10.0.0.0/8,192.168.0.0/16,127.0.0.1,172.16.0.0/16,.svc,dltornado2.com,dltornado.com,geekery.cn,daocloud.io,aliyun.com,mywind.com.cn,quay.io,localhost,security.ubuntu.com"
---
apiVersion: v1
kind: Service
metadata:
name: vllm-head-service
namespace: vllm
spec:
selector:
app: vllm-head
ports:
- name: ray-port
protocol: TCP
port: 6379
targetPort: 6379
- name: object-manager-port
protocol: TCP
port: 8625
targetPort: 8625
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-head
namespace: vllm
annotations:
nvidia.com/gpu.devicemappings: |
{
"device-0": "GPU-4ded26bd-139a-16f9-c37d-40603b832cf8",
"device-1": "GPU-c077873b-946e-d2d7-0a1c-6f98991ec941",
"device-2": "GPU-01fe0b8c-f486-b9a2-1b42-beeb3ee5ca55",
"device-3": "GPU-9496efc9-150a-bdee-0990-40c1c1c5e4fc"
}
spec:
replicas: 1
selector:
matchLabels:
app: vllm-head
template:
metadata:
labels:
app: vllm-head
spec:
nodeSelector:
nvidia.com/gpu.machine: "Precision-7920-Tower" # 假设GPU节点的标签是nvidia.com/gpu.machine: "Precision-7920-Tower"
vllm-role: "vllm-head"
# hostNetwork: true # 主机网络模式,根据实际情况调整
containers:
- name: vllm-head
image: vllm/vllm-openai:latest
command:
- "/bin/bash"
args:
- "-c"
- |
ray start --head --port=6379 --dashboard-host=0.0.0.0 --object-manager-port=8625 --block
securityContext:
privileged: true
volumeMounts:
- name: shm
mountPath: /dev/shm
- name: cache-volume
mountPath: /root/.cache/huggingface
envFrom:
- configMapRef:
name: vllm-config
env:
- name: CUDA_VISIBLE_DEVICES
value: "0,2,3,4" # 对应k8s分配的GPU逻辑编号
volumes:
- name: shm
emptyDir:
medium: Memory
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-worker
namespace: vllm
annotations:
nvidia.com/gpu.devicemappings: |
{
"device-1": "GPU-d255c36c-a9e6-af3b-a9ee-5a6e0d7ba7d4",
"device-2": "GPU-4617a5b9-ceba-75c4-b56f-ed595ccbbf18"
}
spec:
replicas: 1
selector:
matchLabels:
app: vllm-worker
template:
metadata:
labels:
app: vllm-worker
spec:
nodeSelector:
nvidia.com/gpu.machine: "Precision-7920-Tower" # 假设GPU节点的标签是nvidia.com/gpu.machine: "Precision-7920-Tower"
vllm-role: "vllm-worker"
# hostNetwork: true # 主机网络模式,根据实际情况调整
containers:
- name: vllm-worker
image: vllm/vllm-openai:latest
command:
- "/bin/bash"
args:
- "-c"
- |
ray start --address=${IP_OF_HEAD_NODE}:6379 --block
securityContext:
privileged: true
volumeMounts:
- name: cache-volume
mountPath: /root/.cache/huggingface
- name: shm
mountPath: /dev/shm
envFrom:
- configMapRef:
name: vllm-config
env:
- name: CUDA_VISIBLE_DEVICES
value: "1,2" # 对应k8s分配的GPU逻辑编号
volumes:
- name: shm
emptyDir:
medium: Memory
- name: cache-volume
persistentVolumeClaim:
claimName: deepseek-r1-4bit
EOF
查看ray集群状态,发现集群只有6个GPU,这说明之前的配置生效了,因为这两个k8s节点GPU总数是8
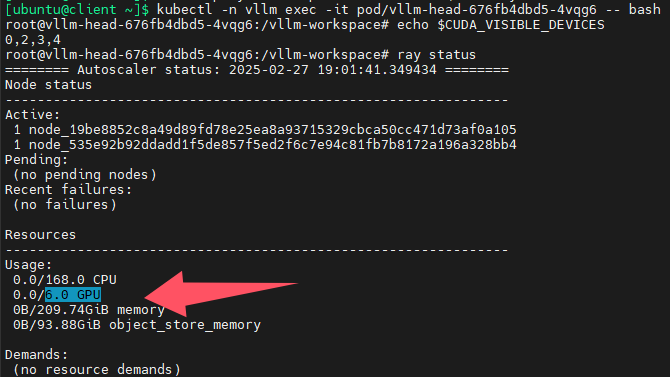
启动vllm
nohup vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--tensor-parallel-size 6 \
--max_num_batched_tokens 1024 \
--dtype half \
--trust-remote-code \
--enable-chunked-prefill > vllm_serve.log 2>&1 &
上述命令报错了,这是因为vllm 0.7.3版本是不支持CUDA capability低于7的GPU的,而集群中有好几张NVIDIA quadro P2000甚至P1000的卡,所以没法进行推理。
验证
$result = Invoke-RestMethod -Uri "http://deepseek.dltornado2.com/v1/chat/completions" `
-Method Post `
-ContentType "application/json" `
-Body '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "一加一等于几?"}
]
}'
$result.choices.message.content
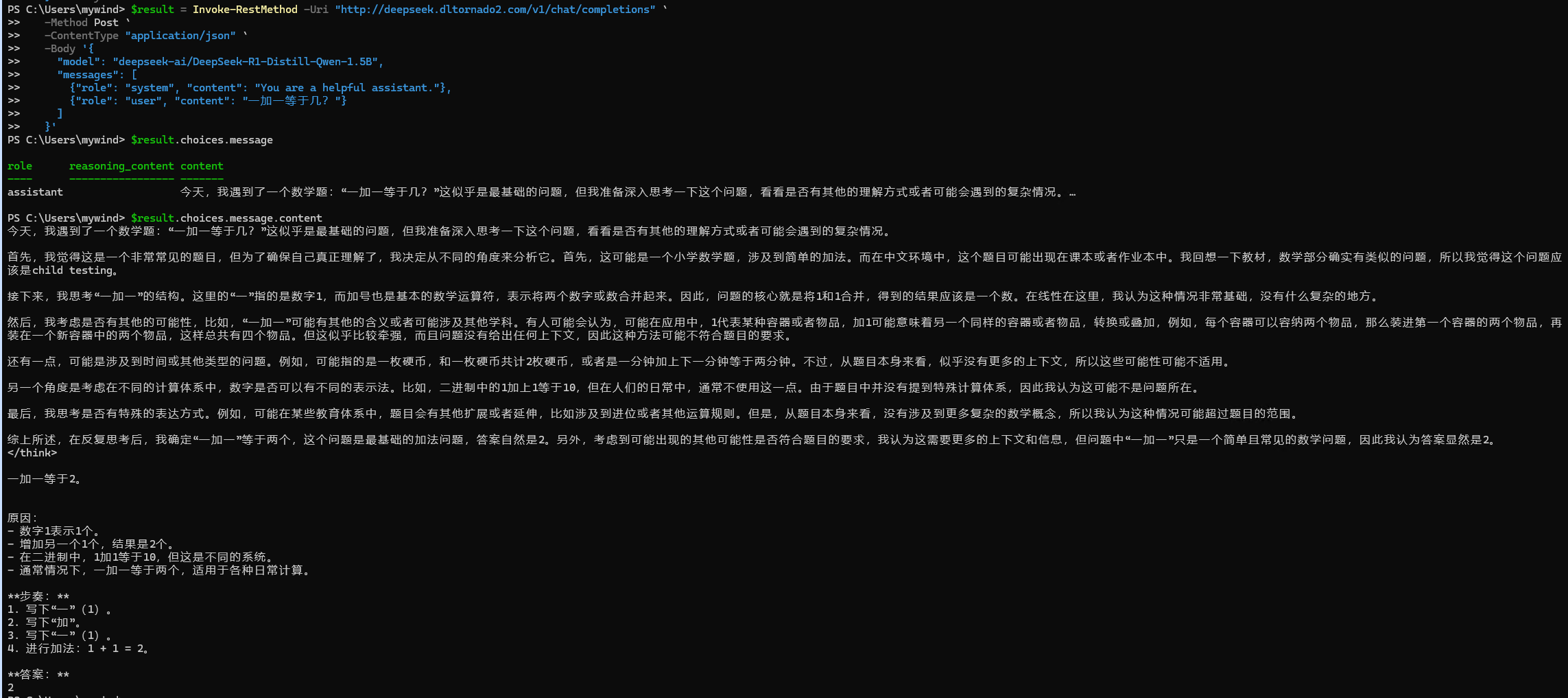
$result = Invoke-RestMethod -Uri "http://deepseek.dltornado2.com/v1/chat/completions" `
-Method Post `
-ContentType "application/json" `
-Body '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "一加一等于几?"}
]
}'
$result.choices.message.content

troubleshooting
配置了ingress,然而有些网段可以访问,有些不能访问
我发现10.65.37.0/24和10.65.0.0/16网段可以访问,但是192.168.124.0/24网段不能访问。这是因为pods的ip地址是192.168.0.11,CIDR包含了192.168.124.0/24这个网段,导致数据包无法返回来。
下载模型报错
pod运行后,很快就会自动从huggingface下载模型文件(如果没有本地缓存),而且默认情况下是启用了hf_transfer以加速下载,然而查看pod日志,发现报错了:An error occurred while downloading using hf_transfer. Consider disabling HF_HUB_ENABLE_HF_TRANSFER for better error handling
kubectl -n vllm logs pods/deepseek-r1-4bit-bcdc4bb4c-9lhwh --follow
具体报错信息如下,其原因是启用了HF_HUB_ENABLE_HF_TRANSFER,虽然启用此选项后会大大加速下载,但是这个工具没有很好的错误处理,非常容易导致下载失败(根据,实践,就算不启用此功能,下载也经常中断)。
注意,我是将HF_ENDPOINT环境变量设置为了https://hf-mirror.com 如果用默认的huggingface.co再用梯子,应该不会出现此问题。
注意:我发现vllm下载出错时,会导致pod重启,重启后,会完全重新开始下载模型文件,之前下载的文件会被删除,这就很有可能导致模型文件永远都无法完成下载,所以最好还是实现手工下载好模型文件。
kubectl -n vllm logs pods/deepseek-r1-4bit-bcdc4bb4c-9lhwh --follow
INFO 02-26 00:48:43 __init__.py:207] Automatically detected platform cuda.
INFO 02-26 00:48:44 api_server.py:912] vLLM API server version 0.7.3
INFO 02-26 00:48:44 api_server.py:913] args: Namespace(subparser='serve', model_tag='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', config='', host=None, port=8000, uvicorn_log_level='info', allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, enable_reasoning=False, reasoning_parser=None, tool_call_parser=None, tool_parser_plugin='', model='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', task='auto', tokenizer=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=True, allowed_local_media_path=None, download_dir=None, load_format='auto', config_format=<ConfigFormat.AUTO: 'auto'>, dtype='half', kv_cache_dtype='auto', max_model_len=None, guided_decoding_backend='xgrammar', logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=4, max_parallel_loading_workers=None, ray_workers_use_nsight=False, block_size=None, enable_prefix_caching=None, disable_sliding_window=False, use_v2_block_manager=True, num_lookahead_slots=0, seed=0, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.9, num_gpu_blocks_override=None, max_num_batched_tokens=1024, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, max_num_seqs=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, disable_custom_all_reduce=False, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=False, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, multi_step_stream_outputs=True, scheduler_delay_factor=0.0, enable_chunked_prefill=True, speculative_model=None, speculative_model_quantization=None, num_speculative_tokens=None, speculative_disable_mqa_scorer=False, speculative_draft_tensor_parallel_size=None, speculative_max_model_len=None, speculative_disable_by_batch_size=None, ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None, spec_decoding_acceptance_method='rejection_sampler', typical_acceptance_sampler_posterior_threshold=None, typical_acceptance_sampler_posterior_alpha=None, disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=None, qlora_adapter_name_or_path=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, scheduling_policy='fcfs', scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', generation_config=None, override_generation_config=None, enable_sleep_mode=False, calculate_kv_scales=False, additional_config=None, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, dispatch_function=<function ServeSubcommand.cmd at 0x7ff86d23b060>)
INFO 02-26 00:48:44 api_server.py:209] Started engine process with PID 79
WARNING 02-26 00:48:45 config.py:2448] Casting torch.bfloat16 to torch.float16.
INFO 02-26 00:48:48 __init__.py:207] Automatically detected platform cuda.
WARNING 02-26 00:48:50 config.py:2448] Casting torch.bfloat16 to torch.float16.
INFO 02-26 00:48:52 config.py:549] This model supports multiple tasks: {'classify', 'reward', 'generate', 'embed', 'score'}. Defaulting to 'generate'.
INFO 02-26 00:48:52 config.py:1382] Defaulting to use mp for distributed inference
INFO 02-26 00:48:52 config.py:1555] Chunked prefill is enabled with max_num_batched_tokens=1024.
INFO 02-26 00:48:56 config.py:549] This model supports multiple tasks: {'classify', 'embed', 'score', 'generate', 'reward'}. Defaulting to 'generate'.
INFO 02-26 00:48:56 config.py:1382] Defaulting to use mp for distributed inference
INFO 02-26 00:48:56 config.py:1555] Chunked prefill is enabled with max_num_batched_tokens=1024.
INFO 02-26 00:48:56 llm_engine.py:234] Initializing a V0 LLM engine (v0.7.3) with config: model='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', speculative_config=None, tokenizer='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.float16, max_seq_len=131072, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=4, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar'), observability_config=ObservabilityConfig(otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=0, served_model_name=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=False, chunked_prefill_enabled=True, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":256}, use_cached_outputs=True,
WARNING 02-26 00:48:57 multiproc_worker_utils.py:300] Reducing Torch parallelism from 52 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed.
INFO 02-26 00:48:57 custom_cache_manager.py:19] Setting Triton cache manager to: vllm.triton_utils.custom_cache_manager:CustomCacheManager
WARNING 02-26 00:48:57 logger.py:202] VLLM_TRACE_FUNCTION is enabled. It will record every function executed by Python. This will slow down the code. It is suggested to be used for debugging hang or crashes only.
INFO 02-26 00:48:57 logger.py:206] Trace frame log is saved to /tmp/root/vllm/vllm-instance-1c515/VLLM_TRACE_FUNCTION_for_process_79_thread_140203373663360_at_2025-02-26_00:48:57.595152.log
INFO 02-26 00:49:01 __init__.py:207] Automatically detected platform cuda.
INFO 02-26 00:49:01 __init__.py:207] Automatically detected platform cuda.
INFO 02-26 00:49:01 __init__.py:207] Automatically detected platform cuda.
(VllmWorkerProcess pid=356) INFO 02-26 00:49:01 multiproc_worker_utils.py:229] Worker ready; awaiting tasks
(VllmWorkerProcess pid=356) WARNING 02-26 00:49:01 logger.py:202] VLLM_TRACE_FUNCTION is enabled. It will record every function executed by Python. This will slow down the code. It is suggested to be used for debugging hang or crashes only.
(VllmWorkerProcess pid=356) INFO 02-26 00:49:01 logger.py:206] Trace frame log is saved to /tmp/root/vllm/vllm-instance-1c515/VLLM_TRACE_FUNCTION_for_process_356_thread_139966580180096_at_2025-02-26_00:49:01.745096.log
(VllmWorkerProcess pid=355) INFO 02-26 00:49:01 multiproc_worker_utils.py:229] Worker ready; awaiting tasks
(VllmWorkerProcess pid=355) WARNING 02-26 00:49:01 logger.py:202] VLLM_TRACE_FUNCTION is enabled. It will record every function executed by Python. This will slow down the code. It is suggested to be used for debugging hang or crashes only.
(VllmWorkerProcess pid=355) INFO 02-26 00:49:01 logger.py:206] Trace frame log is saved to /tmp/root/vllm/vllm-instance-1c515/VLLM_TRACE_FUNCTION_for_process_355_thread_140674893083776_at_2025-02-26_00:49:01.762847.log
(VllmWorkerProcess pid=354) INFO 02-26 00:49:01 multiproc_worker_utils.py:229] Worker ready; awaiting tasks
(VllmWorkerProcess pid=354) WARNING 02-26 00:49:01 logger.py:202] VLLM_TRACE_FUNCTION is enabled. It will record every function executed by Python. This will slow down the code. It is suggested to be used for debugging hang or crashes only.
(VllmWorkerProcess pid=354) INFO 02-26 00:49:01 logger.py:206] Trace frame log is saved to /tmp/root/vllm/vllm-instance-1c515/VLLM_TRACE_FUNCTION_for_process_354_thread_139807281853568_at_2025-02-26_00:49:01.789725.log
INFO 02-26 00:49:21 cuda.py:178] Cannot use FlashAttention-2 backend for Volta and Turing GPUs.
INFO 02-26 00:49:21 cuda.py:226] Using XFormers backend.
(VllmWorkerProcess pid=355) INFO 02-26 00:49:25 cuda.py:178] Cannot use FlashAttention-2 backend for Volta and Turing GPUs.
(VllmWorkerProcess pid=355) INFO 02-26 00:49:25 cuda.py:226] Using XFormers backend.
(VllmWorkerProcess pid=354) INFO 02-26 00:49:25 cuda.py:178] Cannot use FlashAttention-2 backend for Volta and Turing GPUs.
(VllmWorkerProcess pid=354) INFO 02-26 00:49:25 cuda.py:226] Using XFormers backend.
(VllmWorkerProcess pid=356) INFO 02-26 00:49:26 cuda.py:178] Cannot use FlashAttention-2 backend for Volta and Turing GPUs.
(VllmWorkerProcess pid=356) INFO 02-26 00:49:26 cuda.py:226] Using XFormers backend.
(VllmWorkerProcess pid=354) INFO 02-26 00:49:27 utils.py:916] Found nccl from library libnccl.so.2
(VllmWorkerProcess pid=354) INFO 02-26 00:49:27 pynccl.py:69] vLLM is using nccl==2.21.5
(VllmWorkerProcess pid=355) INFO 02-26 00:49:27 utils.py:916] Found nccl from library libnccl.so.2
(VllmWorkerProcess pid=355) INFO 02-26 00:49:27 pynccl.py:69] vLLM is using nccl==2.21.5
(VllmWorkerProcess pid=356) INFO 02-26 00:49:27 utils.py:916] Found nccl from library libnccl.so.2
INFO 02-26 00:49:27 utils.py:916] Found nccl from library libnccl.so.2
(VllmWorkerProcess pid=356) INFO 02-26 00:49:27 pynccl.py:69] vLLM is using nccl==2.21.5
INFO 02-26 00:49:27 pynccl.py:69] vLLM is using nccl==2.21.5
deepseek-r1-4bit-bcdc4bb4c-9lhwh:79:79 [0] NCCL INFO Bootstrap : Using eth0:192.168.0.134<0>
deepseek-r1-4bit-bcdc4bb4c-9lhwh:79:79 [0] NCCL INFO NET/Plugin: No plugin found (libnccl-net.so)
deepseek-r1-4bit-bcdc4bb4c-9lhwh:79:79 [0] NCCL INFO NET/Plugin: Plugin load returned 2 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-net.so
deepseek-r1-4bit-bcdc4bb4c-9lhwh:79:79 [0] NCCL INFO NET/Plugin: Using internal network plugin.
deepseek-r1-4bit-bcdc4bb4c-9lhwh:79:79 [0] NCCL INFO cudaDriverVersion 12080
NCCL version 2.21.5+cuda12.4
(VllmWorkerProcess pid=354) WARNING 02-26 00:49:27 custom_all_reduce.py:136] Custom allreduce is disabled because it's not supported on more than two PCIe-only GPUs. To silence this warning, specify disable_custom_all_reduce=True explicitly.
WARNING 02-26 00:49:27 custom_all_reduce.py:136] Custom allreduce is disabled because it's not supported on more than two PCIe-only GPUs. To silence this warning, specify disable_custom_all_reduce=True explicitly.
(VllmWorkerProcess pid=355) WARNING 02-26 00:49:27 custom_all_reduce.py:136] Custom allreduce is disabled because it's not supported on more than two PCIe-only GPUs. To silence this warning, specify disable_custom_all_reduce=True explicitly.
(VllmWorkerProcess pid=356) WARNING 02-26 00:49:27 custom_all_reduce.py:136] Custom allreduce is disabled because it's not supported on more than two PCIe-only GPUs. To silence this warning, specify disable_custom_all_reduce=True explicitly.
INFO 02-26 00:49:27 shm_broadcast.py:258] vLLM message queue communication handle: Handle(connect_ip='127.0.0.1', local_reader_ranks=[1, 2, 3], buffer_handle=(3, 4194304, 6, 'psm_2c61b69f'), local_subscribe_port=34141, remote_subscribe_port=None)
(VllmWorkerProcess pid=355) INFO 02-26 00:49:27 model_runner.py:1110] Starting to load model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B...
INFO 02-26 00:49:27 model_runner.py:1110] Starting to load model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B...
(VllmWorkerProcess pid=356) INFO 02-26 00:49:27 model_runner.py:1110] Starting to load model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B...
(VllmWorkerProcess pid=354) INFO 02-26 00:49:27 model_runner.py:1110] Starting to load model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B...
INFO 02-26 00:49:29 weight_utils.py:254] Using model weights format ['*.safetensors']
(VllmWorkerProcess pid=354) INFO 02-26 00:49:30 weight_utils.py:254] Using model weights format ['*.safetensors']
(VllmWorkerProcess pid=356) INFO 02-26 00:49:30 weight_utils.py:254] Using model weights format ['*.safetensors']
(VllmWorkerProcess pid=355) INFO 02-26 00:49:31 weight_utils.py:254] Using model weights format ['*.safetensors']
ERROR 02-26 00:51:13 engine.py:400] An error occurred while downloading using `hf_transfer`. Consider disabling HF_HUB_ENABLE_HF_TRANSFER for better error handling.
ERROR 02-26 00:51:13 engine.py:400] Traceback (most recent call last):
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/file_download.py", line 428, in http_get
ERROR 02-26 00:51:13 engine.py:400] hf_transfer.download(
ERROR 02-26 00:51:13 engine.py:400] Exception: Failed too many failures in parallel (3): Request: error decoding response body (no permits available)
ERROR 02-26 00:51:13 engine.py:400]
ERROR 02-26 00:51:13 engine.py:400] The above exception was the direct cause of the following exception:
ERROR 02-26 00:51:13 engine.py:400]
ERROR 02-26 00:51:13 engine.py:400] Traceback (most recent call last):
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 391, in run_mp_engine
ERROR 02-26 00:51:13 engine.py:400] engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 124, in from_engine_args
ERROR 02-26 00:51:13 engine.py:400] return cls(ipc_path=ipc_path,
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/multiprocessing/engine.py", line 76, in __init__
ERROR 02-26 00:51:13 engine.py:400] self.engine = LLMEngine(*args, **kwargs)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/engine/llm_engine.py", line 273, in __init__
ERROR 02-26 00:51:13 engine.py:400] self.model_executor = executor_class(vllm_config=vllm_config, )
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/executor/executor_base.py", line 271, in __init__
ERROR 02-26 00:51:13 engine.py:400] super().__init__(*args, **kwargs)
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/executor/executor_base.py", line 52, in __init__
ERROR 02-26 00:51:13 engine.py:400] self._init_executor()
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/executor/mp_distributed_executor.py", line 125, in _init_executor
ERROR 02-26 00:51:13 engine.py:400] self._run_workers("load_model",
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/executor/mp_distributed_executor.py", line 185, in _run_workers
ERROR 02-26 00:51:13 engine.py:400] driver_worker_output = run_method(self.driver_worker, sent_method,
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/utils.py", line 2196, in run_method
ERROR 02-26 00:51:13 engine.py:400] return func(*args, **kwargs)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/worker/worker.py", line 183, in load_model
ERROR 02-26 00:51:13 engine.py:400] self.model_runner.load_model()
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/worker/model_runner.py", line 1112, in load_model
ERROR 02-26 00:51:13 engine.py:400] self.model = get_model(vllm_config=self.vllm_config)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/model_loader/__init__.py", line 14, in get_model
ERROR 02-26 00:51:13 engine.py:400] return loader.load_model(vllm_config=vllm_config)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/model_loader/loader.py", line 409, in load_model
ERROR 02-26 00:51:13 engine.py:400] loaded_weights = model.load_weights(
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen2.py", line 515, in load_weights
ERROR 02-26 00:51:13 engine.py:400] return loader.load_weights(weights)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/utils.py", line 235, in load_weights
ERROR 02-26 00:51:13 engine.py:400] autoloaded_weights = set(self._load_module("", self.module, weights))
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/utils.py", line 187, in _load_module
ERROR 02-26 00:51:13 engine.py:400] for child_prefix, child_weights in self._groupby_prefix(weights):
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/utils.py", line 101, in _groupby_prefix
ERROR 02-26 00:51:13 engine.py:400] for prefix, group in itertools.groupby(weights_by_parts,
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/utils.py", line 99, in <genexpr>
ERROR 02-26 00:51:13 engine.py:400] for weight_name, weight_data in weights)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/model_loader/loader.py", line 385, in _get_all_weights
ERROR 02-26 00:51:13 engine.py:400] yield from self._get_weights_iterator(primary_weights)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/model_loader/loader.py", line 338, in _get_weights_iterator
ERROR 02-26 00:51:13 engine.py:400] hf_folder, hf_weights_files, use_safetensors = self._prepare_weights(
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/model_loader/loader.py", line 291, in _prepare_weights
ERROR 02-26 00:51:13 engine.py:400] hf_folder = download_weights_from_hf(
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/vllm/model_executor/model_loader/weight_utils.py", line 259, in download_weights_from_hf
ERROR 02-26 00:51:13 engine.py:400] hf_folder = snapshot_download(
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
ERROR 02-26 00:51:13 engine.py:400] return fn(*args, **kwargs)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/_snapshot_download.py", line 294, in snapshot_download
ERROR 02-26 00:51:13 engine.py:400] _inner_hf_hub_download(file)
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/_snapshot_download.py", line 270, in _inner_hf_hub_download
ERROR 02-26 00:51:13 engine.py:400] return hf_hub_download(
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
ERROR 02-26 00:51:13 engine.py:400] return fn(*args, **kwargs)
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/file_download.py", line 862, in hf_hub_download
ERROR 02-26 00:51:13 engine.py:400] return _hf_hub_download_to_cache_dir(
ERROR 02-26 00:51:13 engine.py:400] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/file_download.py", line 1011, in _hf_hub_download_to_cache_dir
ERROR 02-26 00:51:13 engine.py:400] _download_to_tmp_and_move(
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/file_download.py", line 1547, in _download_to_tmp_and_move
ERROR 02-26 00:51:13 engine.py:400] http_get(
ERROR 02-26 00:51:13 engine.py:400] File "/usr/local/lib/python3.12/dist-packages/huggingface_hub/file_download.py", line 439, in http_get
ERROR 02-26 00:51:13 engine.py:400] raise RuntimeError(
ERROR 02-26 00:51:13 engine.py:400] RuntimeError: An error occurred while downloading using `hf_transfer`. Consider disabling HF_HUB_ENABLE_HF_TRANSFER for better error handling.
ERROR 02-26 00:51:13 multiproc_worker_utils.py:124] Worker VllmWorkerProcess pid 356 died, exit code: -15
INFO 02-26 00:51:13 multiproc_worker_utils.py:128] Killing local vLLM worker processes
pod重启后,完全重新开始下载,而不是断点续传
根据实践,我发现,如果vllm发现没有本地缓存,则会自动从环境变量HF_ENDPOINT设置的网址下载模型文件(实验环境中,我使用的是pv,删除Deployment后,pv仍然存在,所以并不是k8s将卷删除的,而是pod删除的),如果下载过程中出错,会导致pod自动重启,此时,之前下载的文件会被清空,完全重新开始下载,这就导致模型文件永远都无法下载完成。当然了因为我是将HF_ENDPOINT环境变量设置为了https://hf-mirror.com 如果用默认的huggingface.co再用梯子,应该不会出现此问题。
无法正常拉取pod
可以将openai容器镜像改为这个:
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/vllm/vllm-openai:latest
卸载
如果是因为部署的应用或者基础设施(操作系统)出现了故障,无法修复了,再或者仅仅是想要destroy这个环境,可以遵循本节的说明依次移除已经部署的应用,还能卸载操作系统,使得整个环境还原到初始状态以便于我们再次部署应用。
先查询当前有哪些models、clouds、controllers


移除model cos-lite
#下行命令将会彻底移除所有的与cos-lite这个model相关的machines、apps、storage,时间比较久请耐心等待
juju destroy-model cos-lite --force --destroy-storage
移除model cos-cluster
juju destroy-model cos-cluster --force --destroy-storage
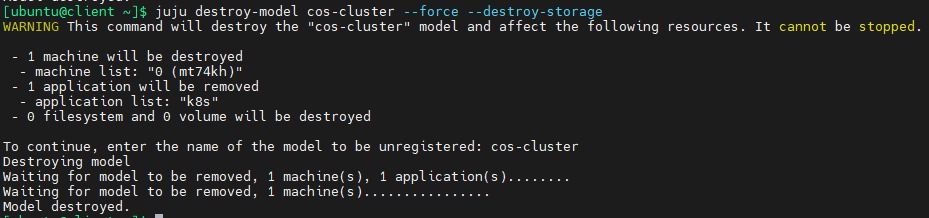
移除model charmed-k8s
juju destroy-model charmed-k8s --force --destroy-storage
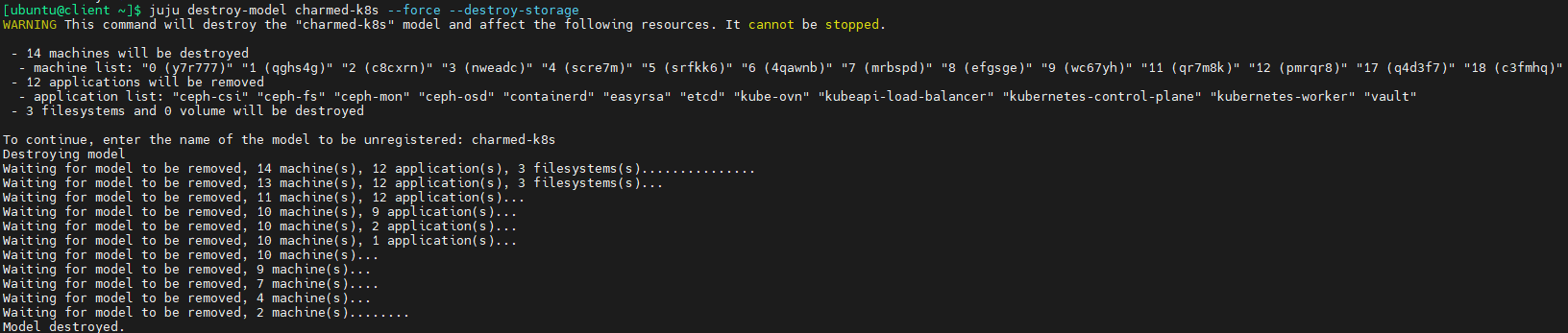
移除model charmed-k8s后,Maas上的已经部署的machines(除了controller)也会自动变为ready状态。
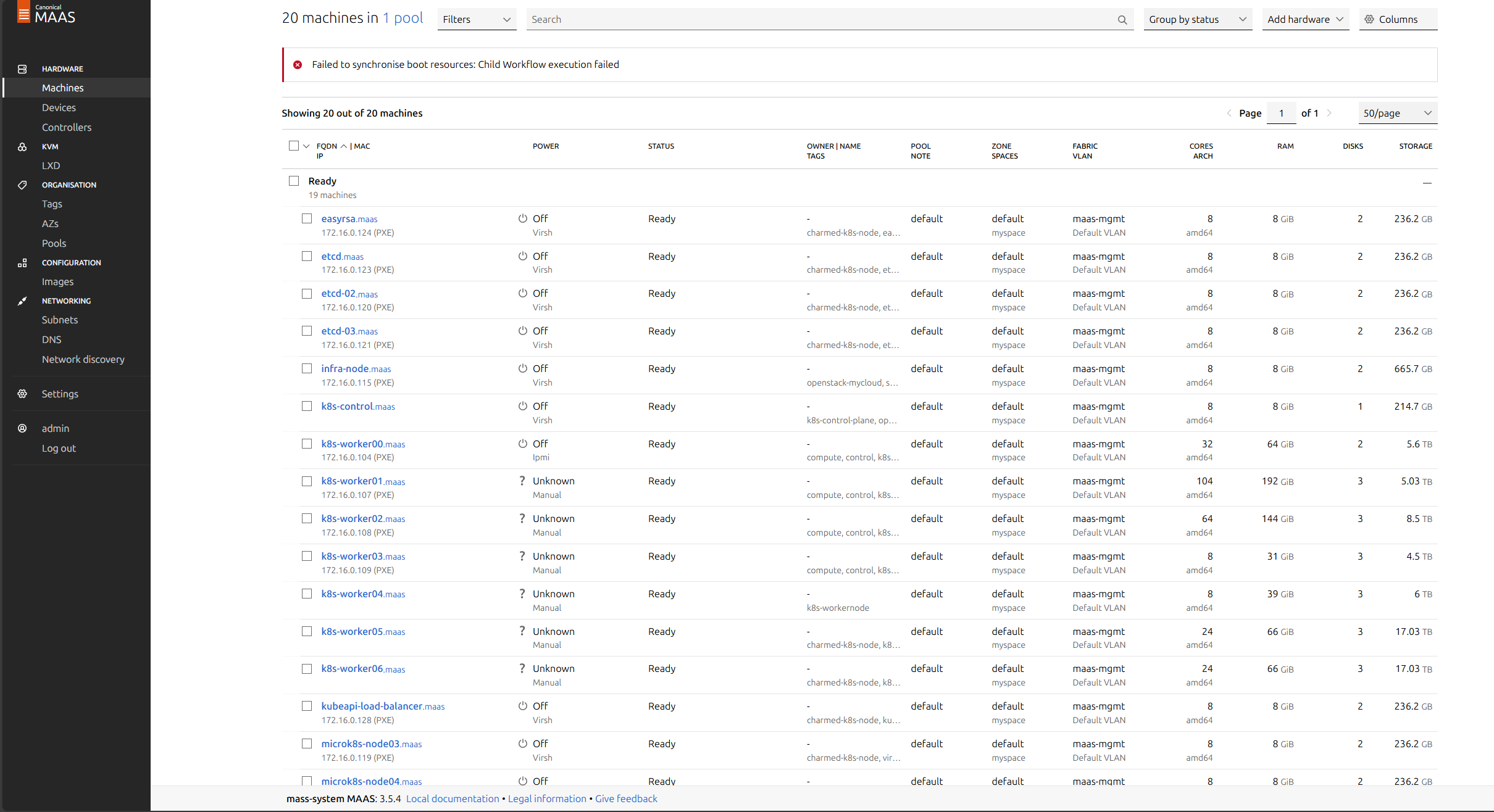
移除cloud k8s-cloud
juju remove-cloud k8s-cloud

关注微信公众号“AI发烧友”,获取更多IT开发运维实用工具与技巧,还有很多AI技术文档!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









