






文章目录
计算图是TensorFlow中最基本的一个概念,TensorFlow中的所有计算都会被转化为计算图上的节点。
Tensor:即张量,在TensorFlow的范畴里,苦李建议大家将其简单的理解为多维数组
Flow:中文翻译过来是“流”,它形象的表达了张量之间通过计算相互转化的过程
Tensor表明了TensorFlow中的数据结构,而Flow则体现了它的计算模型。
图的直观理解
参考:Calculus on Computational Graphs: Backpropagation
对于公式e=(a+b)∗(b+1).可以分解为:

反向传播:
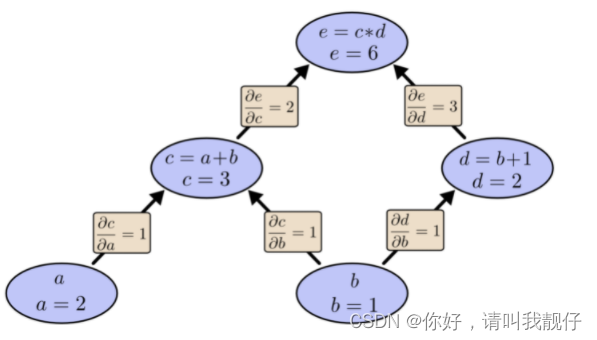
总结而言,计算图模型由节点(nodes)和线(edges)组成,节点表示操作符Operator,或者称之为算子,线表示计算间的依赖,实线表示有数据传递依赖,传递的数据即张量,虚线通常可以表示控制依赖,即执行先后顺序。
三种计算图
TensorFlow中的计算图有三种,分别是静态计算图,动态计算图,以及Autograph
动态计算图
TensorFlow2默认采用的是动态计算图(pytorch默认采用的也是动态计算图):使用一个算子后,该算子会被动态加入到隐含的默认计算图中立即执行得到结果。
动态图的好处在于方便进行调试,可以像调试python代码一样去调试,在图中传播的任何一步都可以停下来看一下中间过程。缺点就是会损失一些性能,因为对于静态图而言,多了很多和C++进程之间的交互(TensorFlow底层API是c++和C API,其他语言的API都是在C API之上封装的)。
静态计算图
静态计算图的运行就需要两步:定义图、运行计算图。先使用TensorFlow的各种算子创建计算图,然后再开启一个会话Session,显式执行计算图。静态计算图构建完成之后几乎全部在TensorFlow内核上使用C++代码执行,效率更高。
动态计算图使用实例
# 第一部分
# 动态计算图在每个算子处都进行构建,构建后立即执行
x = tf.constant("hello")
y = tf.constant("world")
z = tf.strings.join([x,y],separator=" ")
tf.print(z) # hello world
# 第二部分
# 可以将动态计算图代码的输入和输出关系封装成函数
def strjoin(x,y):
z = tf.strings.join([x,y],separator = " ")
tf.print(z) # hello world
return z
result = strjoin(tf.constant("hello"),tf.constant("world"))
print(result) # tf.Tensor(b'hello world', shape=(), dtype=string)
静态计算图使用实例
import tensorflow as tf
# TensorFlow1.0
#定义计算图
g = tf.Graph()
with g.as_default():
#placeholder为占位符,执行会话时候指定填充对象
x = tf.placeholder(name='x', shape=[], dtype=tf.string)
y = tf.placeholder(name='y', shape=[], dtype=tf.string)
z = tf.string_join([x,y],name = 'join',separator=' ')
#执行计算图
with tf.Session(graph = g) as sess:
print(sess.run(fetches = z,feed_dict = {x:"hello",y:"world"}))
计算图的使用
动态计算图内存是执行后自动释放的
以pytorch为例,如果默认只可以反向传播一次,因为图在执行完一次迭代之后就被释放掉了。
net = nn.Linear(3, 4) # 一层的网络,也可以算是一个计算图就构建好了
input = Variable(torch.randn(2, 3), requires_grad=True) # 定义一个图的输入变量
output = net(input) # 最后的输出
loss = torch.sum(output) # 这边加了一个sum() ,因为被backward只能是标量
loss.backward() # 到这计算图已经结束,计算图被释放了
当你想进行两次回传时,就会出错:
net = nn.Linear(3, 4)
input = Variable(torch.randn(2, 3), requires_grad=True)
output = net(input)
loss = torch.sum(output)
loss.backward()
loss.backward()
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed.
如果想要多次回传,需要在反向传播时候添加一个标识,这样表示一次迭代之后不进行删除:
net = nn.Linear(3, 4)
input = Variable(torch.randn(2, 3), requires_grad=True)
output = net(input)
loss = torch.sum(output)
loss.backward(retain_graph=True) # 添加retain_graph=True标识,让计算图不被立即释放
loss.backward()
计算图的反向传播是可以从任意节点开始的
x = Variable(torch.FloatTensor([[1, 2]]), requires_grad=True) # 定义一个输入变量
y = Variable(torch.FloatTensor([[3, 4],
[5, 6]]))
loss = torch.mm(x, y) # 变量之间的运算
loss.backward(torch.FloatTensor([[1, 0]]), retain_graph=True) # 求梯度,保留图
print(x.grad.data) # 求出 y_1 / x
x.grad.data.zero_() # 最后的梯度会累加到叶节点,所以叶节点清零
loss.backward(torch.FloatTensor([[0, 1]])) # 求出 y_2 / x
print(x.grad.data) # 求出 y_2 / x
其实就是想说,loss相当于我们定义的计算图中的最后一个数据节点了。但是实际上从任何一个节点我们都可以作为开始向后反向传播。只要给他一个数就行。
TensorFlow中的张量类型
TensorFlow 程序中,操控和传递的主要目标是 tf.Tensor。tf.Tensor 目标表示一个部分定义的计算,最终会产生一个值。
tf.Tensor 有以下属性:
数据类型(例如 float32,int32 或 string)
形状
主要的张量包括:
tf.Variable 变量张量,一般表示机器学习参数
tf.constant 常量张量,一般用来表示常量,不可改变
tf.placeholder 占位符张量,一般用来表示机器学习中输入的数据 {x,y}
主要区别:
tf.Variable
计算图中的节点,计算过程的中间节点,用于网络的计算传播。
是可以从某一个变量位置开始进行反向传播计算梯度的
tf.placeholder
占位符张量,就是空出来位置,只知道这个位置应该填放的数据长什么样子,但是不知道具体的数据是什么。所以每次训练的时候直接给这里放就好了。Varible的话,就直接指定了这个位置的数据应该放什么值了。
















 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









