







叠甲:仅供学习。。
XMU的小朋友实在不会了可以参考我的思路,但还是建议自己敲一遍哈。
学科实践二还是挺有意思的!
分析豆瓣阅读网站

打开浏览器开发者工具,可以看到如下图所示的内容
获取豆瓣cookie
打开网站https://read.douban.com/provider/all,登录后按F12
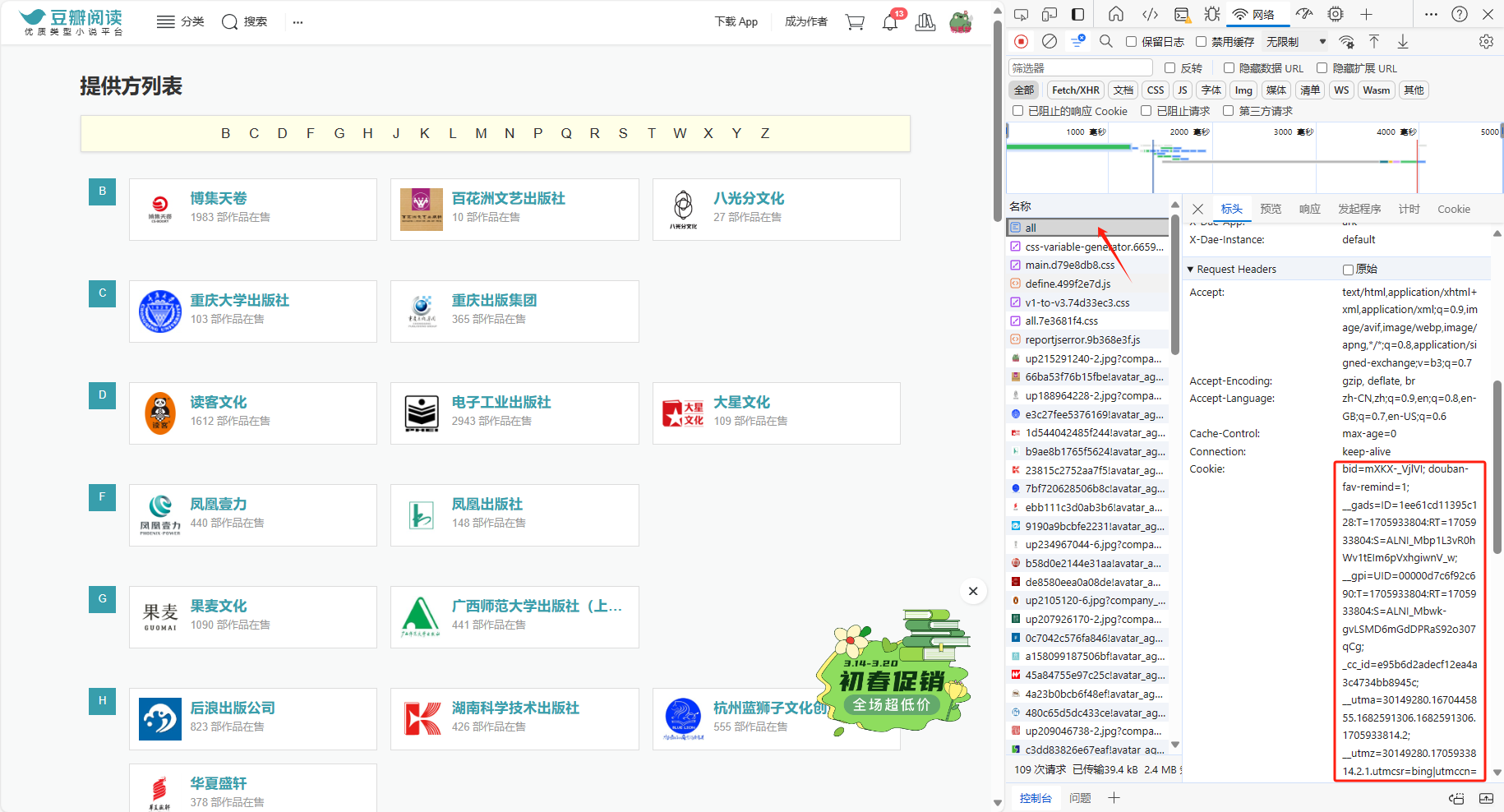
按Ctrl+R、复制Cookie中的所有内容,替换到代码里的对应位置
完整爬虫代码
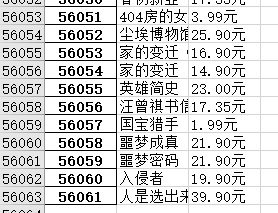
我23年3月的时候,是把豆瓣全部爬取了()一共5w6k条
import sys
import numpy as np
import json
import re
import requests
import pandas as pd
import datetime
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url='https://read.douban.com/provider/all'
# 更换为自己的cookie
cookie={'你的Cookie'}
try:
response = requests.get(url,headers=headers,cookies=cookie)
#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串
soup = BeautifulSoup(response.text,'lxml')
#返回所有的<div>所有标签
publishes = soup.find_all('div',{'class':'provider-group'})
pbs=[]
item_list=[]
#enumerate爬虫中的遍历
#遍历所有出版社
#pb为当前出版社
for index,pb in enumerate(publishes):
#if (index<=1):
if True:
pb_list={}
pb_list['item_name']=pb.find_next('div').text
p=pb.find_next('ul')
li_s=p.find_all('li')#li_s存储了当前出版社的所有数据。
#print(li_s)
book_name=[]
book_value=[]
for li in li_s:
item_li={}
#item_li为进入当前出版社内页书单的链接
item_li['href']='https://read.douban.com'+li.find_next('a').get('href')
url2=item_li['href']
response2=requests.get(url2,headers=headers,cookies=cookie)
soup2 = BeautifulSoup(response2.text,'lxml')
#遍历当前出版社的所有书单页面
while soup2.find('li',class_='next')!=None:
#booklist为当前页面的所有<div class=info>的书籍数据
booklist=soup2.find_all('div',{'class':'info'})
#print(publishes2)
#遍历当前页面的所有书籍
#book为当前的书籍数据
for book in booklist:
if(book.find('h4',class_='title')==None):
continue
title =book.find('h4',class_='title').text
item_li['name']=title
if(book.find('div',class_='sales-price')!=None):
price=book.find('div',class_='sales-price').text
item_li['price']=price
elif(book.find('span',class_='discount-price')!=None):
price=book.find('span',class_='discount-price').text
item_li['price']=price
elif(book.find('span',class_='price-tag')!=None):
price=book.find('span',class_='price-tag').text
item_li['price']=price
else:
continue
#输出查看
print(f"《{title}》:{price}")#1000行截断,保存成xlsx比较好
#item_list用来存储要求得的书名和价格的list型数据结构,一维
item_list.append([title,price])
temp2=soup2.find('li',class_='next')
#若存在后页
if temp2.find('a')!=None:
#跳转到下一页
url3=url2+temp2.find('a').get('href')
response2=requests.get(url3,headers=headers,cookies=cookie)
soup2 = BeautifulSoup(response2.text,'lxml')
else:
break
df=pd.DataFrame(item_list)
df.columns=['书籍名称','价格']
print(df)
#保存到excel文件中
df.to_excel("爬虫数据.xlsx")
except Exception as e:
print(e)















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











