






目标:本文主要讲解如何自动化通用拟合函数
目录
学习就是参数估计:
在本节中,我们将学习获取数据、选择模型并估计模型的参数,以便它能够对新数据做出良
好的预测。
给定输入数据和相应的期望输出(实际数据),以及权重的初始值,给模型输入数据(正向传播),并通过对输出结果与实际数 据进行比较来评估误差。为了优化模型参数,即它的权重,权重单位变化后的误差变化(误差相对参数的梯度)是使用复合函数的导数的链式法则计算的(反向传播)。然后,在使误差减小的方向上更新权重值。重复该过程,直到根据未知的数据评估的误差降到可接受的水平。
选择线性模型首试:
训练神经网络本质上是使用几个或一些参数将一个模型变换为更加复杂的模型。
权重告诉我们给定的输入对输出的影响有多大。偏置是所有输入为零时的输出。
假设了一个用于
2 组测量数据转换的最简单的模型,2个测量数据集可能是线性相关的—也就是说,将 t_u 乘一个因子,再加一个常数,我们可以得到摄氏温度(忽略一定的误差)。
t
_
c = w * t
_
u + b
减小损失是我们想要的:
损失函数(或代价函数)是一个计算单个数值的函数,学习过程将试图使其值最小化。
从概念上讲,损失函数是一种对训练样本中要修正的错误进行优先处理的方法,因此参数更新会导致对高权重样本的输出进行调整,而不是对损失较小的其他样本的输出进行调整。
值得注意的是,平方差比绝对差对错误结果的惩罚更大。通常,有更多轻微错误的结果比有
少量严重错误的结果要好,并且平方差有助于
根据需要优先处理相关问题。
从问题回到pytorch:
首先收集一些用旧的摄氏温度记录下温度数据,再用新的温度计测量,然后记录下来。几周之后,得到以下数据:
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)创建张量数据,把模型写成python函数:
def model(t_u,w,b):
return w * t_u + b #t_u、w 和 b 分别作为输入张量、权重参数和偏置参数确定损失函数:
def loss_fn(t_p,t_c):
squared_diffs = (t_p - t_c) ** 2
return squared_diffs.mean() #先对其平方元素进行处理,最后通过对得到的张量中的所有元素求平均值得到一个标量损失函数
以初始化参数,调用模型:
w = torch.ones(()) #为什么这么用?
b = torch.zeros(())
print(w,b)
t_p = model(t_u,w,b) #t_u、w 和 b 分别作为输入张量、权重参数和偏置参数
print(t_p) #t_p为预测值,t_c为真实值
print(t_c)
#检查损失的值
loss = loss_fn(t_p,t_c)
print(loss)沿着梯度下降:
根据参数使用梯度下降法来优化损失函数。
其思想是计算各参数的损失变化率,并在减小损 失变化率的方向上修改各参数。
#在 w 和 b 上加上一个小数字来估计变化率,然后看看损失在这附近的变化有多大
delta = 0.1
loss_rate_of_change_w = \
(loss_fn(model(t_u,w + delta,b),t_c) -
loss_fn(model(t_u,w - delta,b),t_c)) / (2.0 * delta)
print(loss_rate_of_change_w)
用一个小的比例因子来衡量变化率。机器学习中称为学习率(learning
_
rate
):
learning_rate = 1e-2 #控制步长 1e-2表示0.01*10的-2次方
w = w - learning_rate * loss_rate_of_change_w
通过重复以上评估步骤(只要我们选择一个足够小的学习率),我们将收敛到在给定数据上使损失最小的参数的最优值。
进行分析:
在一个有
2
个或
2
个以上参数的模型中,我们计算每个参数的损失导数,并将它们放入一个导数向量中,即梯度。
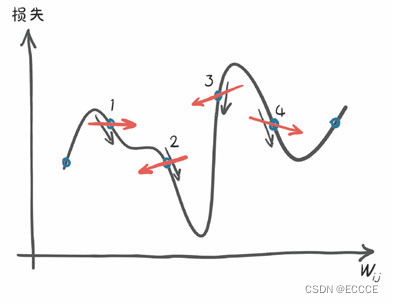
图:当在离散的位置进行评估与对比分析时,估计下降方向的差异
应用链式法则,先计算损失对于其输入(模型的输出)的导数,再乘模型对参数的导数。
def dloss_fn(t_p,t_c): #表示y方向上的梯度 dx2 / dx = 2x得到
dsp_diffs = 2 * (t_p - t_c) / t_p.size(0) #这个除法来自均值的导数
return dsp_diffs
将导数应用到模型中:
def dmodel_dw(t_u,w,b): #模型在w方向上的梯度
return t_u
def dmodel_db(t_u,w,b): #模型在b方向上的梯度
return 1.0
把所有这些放在一起,返回关于
w
和
b
的损失梯度的函数:
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b)
dloss_db = dloss_dtp * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.sum(), dloss_db.sum()]) #用stack将dloss_dw.sum(),dloss_db.sum()连接起来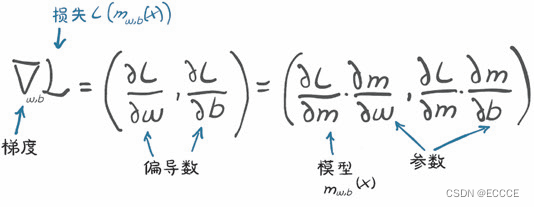
图: 损失函数对权重值的导数
迭代以适应模型 :
训练迭代为一个迭代周期(
epoch
),在这个迭代周期,我们更新所有训练样本的参数。
def training_loop(n_epochs, learning_rate, params, t_u, t_c,
print_params=True):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b) # <1>
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b) # <2>
params = params - learning_rate * grad
if epoch in {1, 2, 3, 10, 11, 99, 100, 4000, 5000}: # <3>
print('Epoch %d, Loss %f' % (epoch, float(loss)))
if print_params:
print(' Params:', params)
print(' Grad: ', grad)
if epoch in {4, 12, 101}:
print('...')
if not torch.isfinite(loss).all():
break # <3>
return params但是这个训练过程会导致损失变为无穷,它们的值开始来回波动,每次更新修正过度,就会导致下一次更新更加过度。优化过程是不稳定的:它发散而不是收敛到最小值。
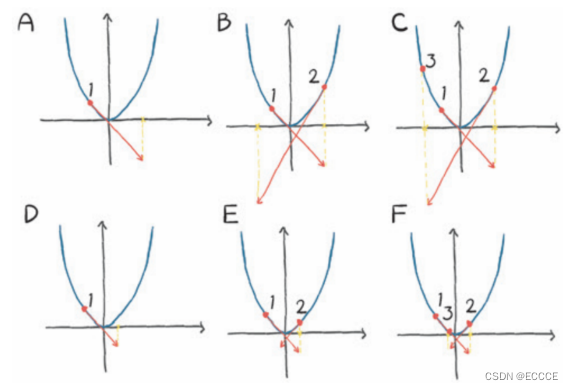
图:顶部:由于大步幅而对凸函数(类抛物线)进行发散优化。底部:用小步幅进行收敛优化
归一化输入:
针对上面的这个问题,我们可以用一种更简单的方法来控制一切:改变输入,这样梯度就不会有太大的不同。
可以通过简单地
将 t
_
u
乘
0.1
得到一个足够接近的结果:
t_un = 0.1 * t_u
对归一化的输入运行训练循环:
#调用循环训练
training_loop(
n_epochs = 100,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c)
out[]
Epoch 1, Loss 80.364342
Params: tensor([1.7761, 0.1064])
Grad: tensor([-77.6140, -10.6400])
Epoch 2, Loss 37.574913
Params: tensor([2.0848, 0.1303])
Grad: tensor([-30.8623, -2.3864])
Epoch 3, Loss 30.871077
Params: tensor([2.2094, 0.1217])
Grad: tensor([-12.4631, 0.8587])
...
Epoch 10, Loss 29.030489
Params: tensor([ 2.3232, -0.0710])
Grad: tensor([-0.5355, 2.9295])
Epoch 11, Loss 28.941877
Params: tensor([ 2.3284, -0.1003])
Grad: tensor([-0.5240, 2.9264])
...
Epoch 99, Loss 22.214186
Params: tensor([ 2.7508, -2.4910])
Grad: tensor([-0.4453, 2.5208])
Epoch 100, Loss 22.148710
Params: tensor([ 2.7553, -2.5162])
Grad: tensor([-0.4446, 2.5165])
把
n
_
epochs改为 5000
:
Epoch 1, Loss 80.364342
Params: tensor([1.7761, 0.1064])
Grad: tensor([-77.6140, -10.6400])
Epoch 2, Loss 37.574913
Params: tensor([2.0848, 0.1303])
Grad: tensor([-30.8623, -2.3864])
Epoch 3, Loss 30.871077
Params: tensor([2.2094, 0.1217])
Grad: tensor([-12.4631, 0.8587])
...
Epoch 10, Loss 29.030489
Params: tensor([ 2.3232, -0.0710])
Grad: tensor([-0.5355, 2.9295])
Epoch 11, Loss 28.941877
Params: tensor([ 2.3284, -0.1003])
Grad: tensor([-0.5240, 2.9264])
...
Epoch 99, Loss 22.214186
Params: tensor([ 2.7508, -2.4910])
Grad: tensor([-0.4453, 2.5208])
Epoch 100, Loss 22.148710
Params: tensor([ 2.7553, -2.5162])
Grad: tensor([-0.4446, 2.5165])
...
Epoch 4000, Loss 2.927680
Params: tensor([ 5.3643, -17.2853])
Grad: tensor([-0.0006, 0.0033])
Epoch 5000, Loss 2.927648
Params: tensor([ 5.3671, -17.3012])
Grad: tensor([-0.0001, 0.0006])
可以清楚的看到沿着梯度下降的方向改变参数时,我们的损失减小了。它不会完全趋近于
0
,这可能 意味着迭代次数不足以使其收敛到 0
,或者数据点不完全在一条线上。















 1099
1099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









