






大家好,我是煎鱼。
7 月 9 日起,OpenAI 将正式终止对部分地区(包含中国)提供 API 服务,引起业内一片哗然,纷纷开始自检,找新的国内可用的国产化替代方案。
此时我有一个朋友的 Boss,结合各家大模型的表现和价格(性价比),推荐了阿里云的通义千问。
尤其是提起最近新出的开源大模型 Qwen2 系列。非常强!今天特意了解了下,做一个快速的介绍分享。
通义千问 Qwen2
2024 年 6 月 7 日,通义千问正式发布了 Qwen2 系列,其包含 5 个尺寸的预训练和指令微调模型,分别是:
Qwen2-0.5B
Qwen2-1.5B
Qwen2-7B
Qwen2-57B-A14B
Qwen2-72B
其中最特别的是:Qwen2-72B,性能超过美国最强的开源模型 Llama3-70B,也在多个测评中超过文心 4.0、豆包 pro、混元 pro 等众多国内闭源大模型。
体验使用上,所有同学都可以在魔搭社区或 Hugging Face 免费下载通义千问最新开源模型。
Qwen-2开源地址:https://huggingface.co/Qwen/Qwen2-72B-Instruct
快速体验
大家如果想要方便一点的,也可以直接访问通义大模型官网:https://tongyi.aliyun.com/qianwen/ 。对外界面上提供的就是通义千问 2.5,可以直接免费体验。
百闻不如一见。我快速测试了几个 case。
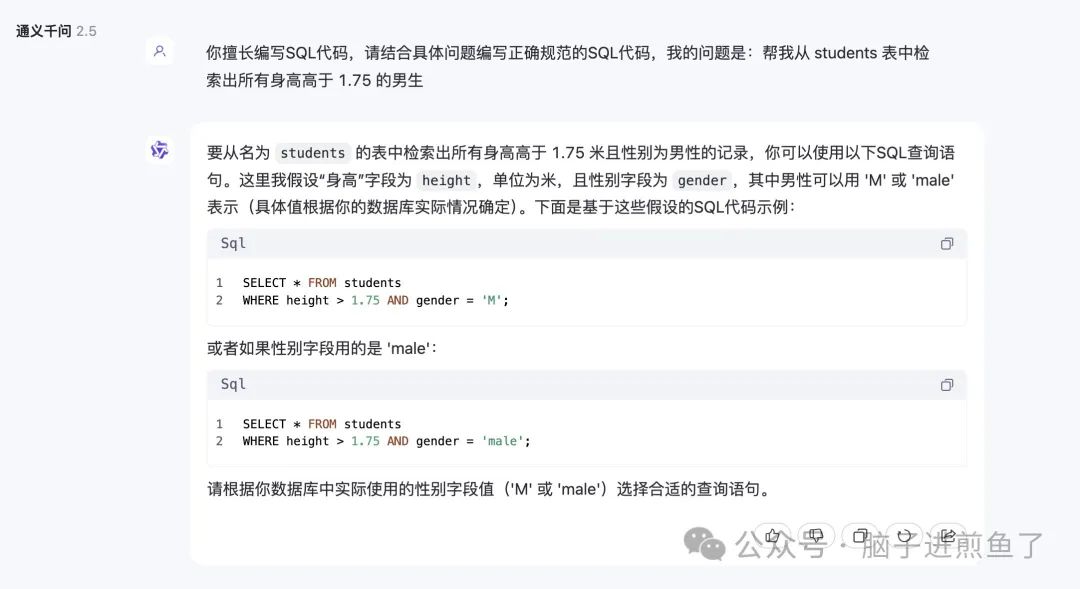
1、写 SQL 语句:
2、写短视频剧本:

3、写工作周报:

整体几轮测试下来,通义千问在每轮的问答上,性能不错,回复速度很快。明显感觉比 GPT 快的多。
内容的有效性上,我个人觉得都挺不错。尤其是认真看了周报部分。通义千问现在已经很强了。这个场景下对于现实职场的适配度高。
大模型评测数据
个人的体验可能还是有限的。这里有一些业内专家对各大模型的评测。
可以参照看看,自行根据业务场景识别。
Qwen2-72B 开源模型第一
6 月 27 日,全球著名开源平台 huggingface 的联合创始人兼首席执行官 Clem 在社交平台宣布,阿里最新开源的 Qwen2-72B 指令微调版本,成为开源模型排行榜第一名。
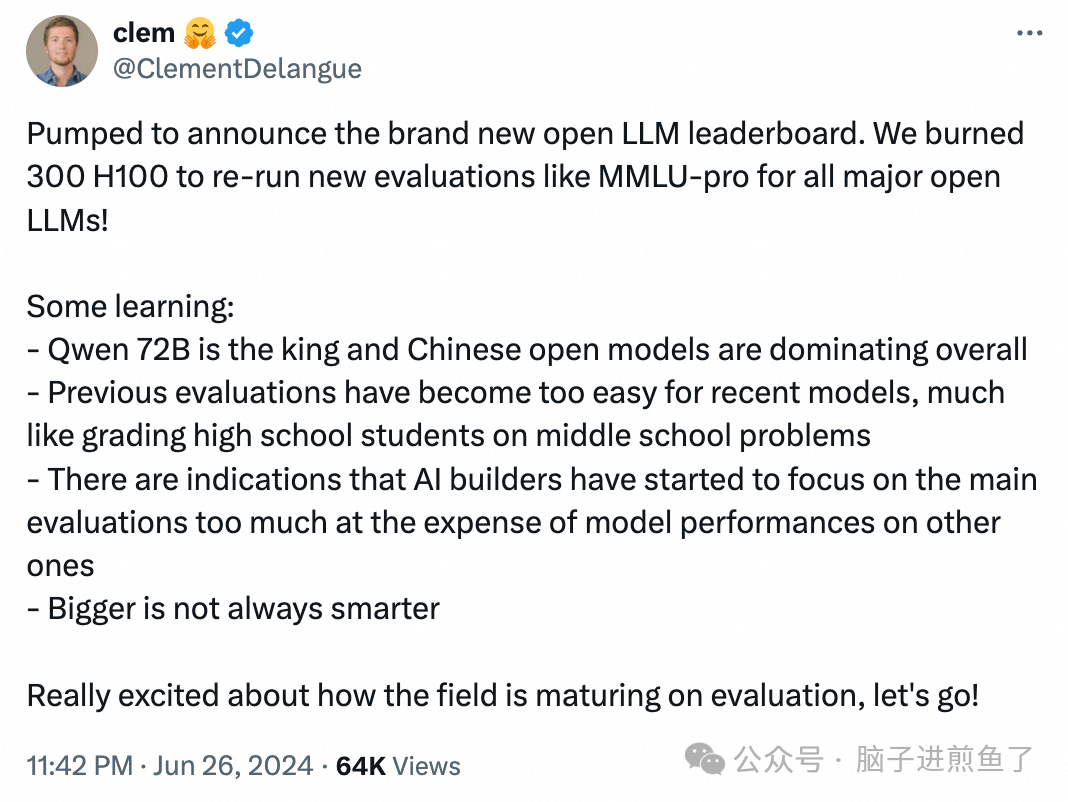
他表示,为了提供全新的开源大模型排行榜,使用了 300 块 H100 对目前全球 100 多个主流开源大模型,例如,Qwen2、Llama-3、mixtral、Phi-3 等,在 BBH、MUSR、MMLU-PRO、GPQA 等基准测试集上进行了全新评估。
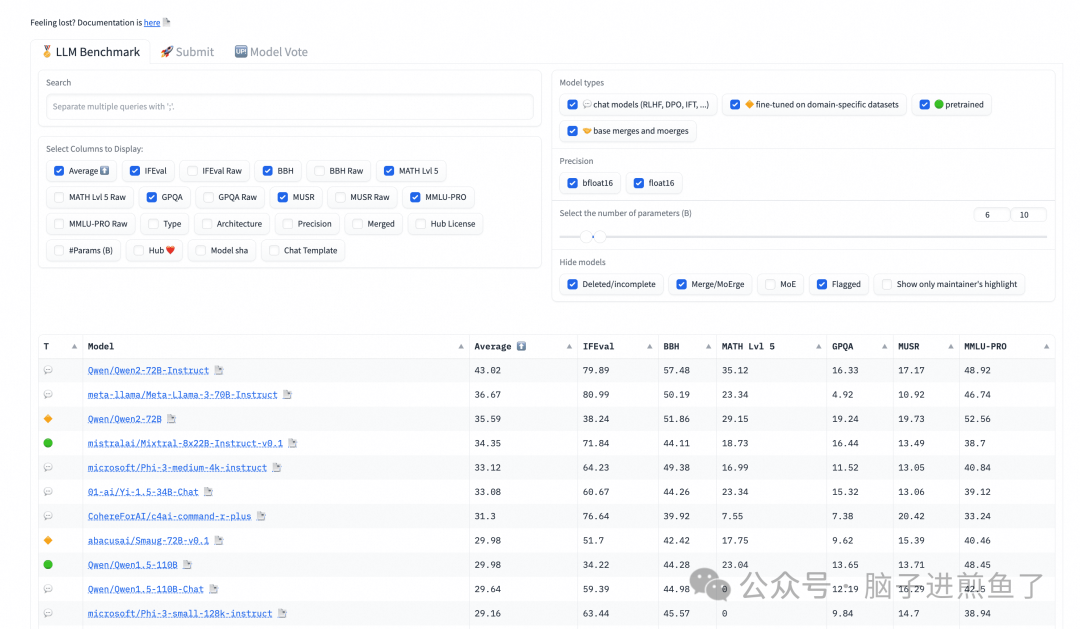
结果显示,阿里开源的 Qwen-2 72B 力压科技、社交巨头 Meta 的 Llama-3、法国著名大模型平台 Mistralai 的 Mixtral 成为新的王者,中国在全球开源大模型领域处于领导地位。
Qwen2 测评榜单国内第一
上海人工智能实验室大模型测评榜单 Compass Arena,最近公布了最新结果:
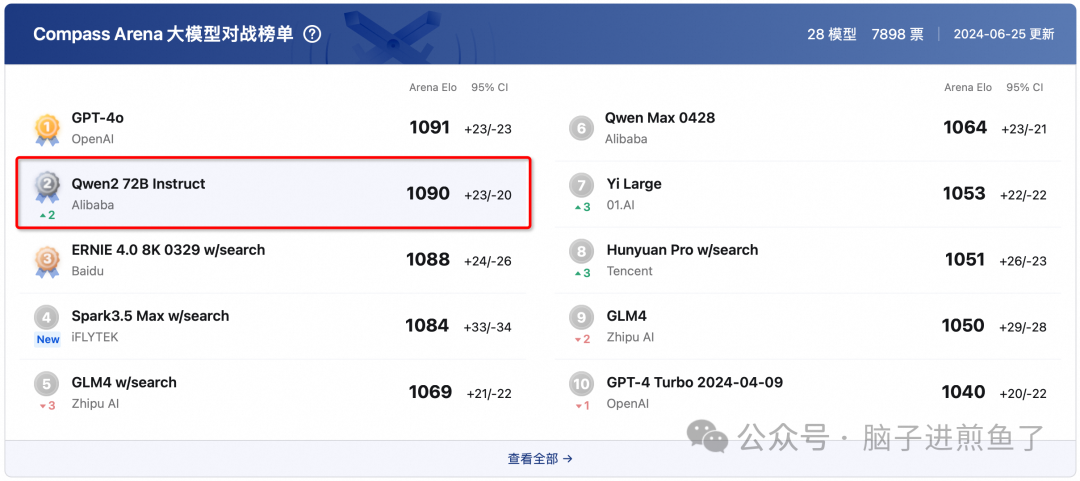
Qwen2-72B 得分仅次于 GPT-4o,以 1 分之差排名第二,成为排名最高的开源大模型,总成绩超过文心 4.0、讯飞星火 3.5 等国内闭源大模型。
用户口碑
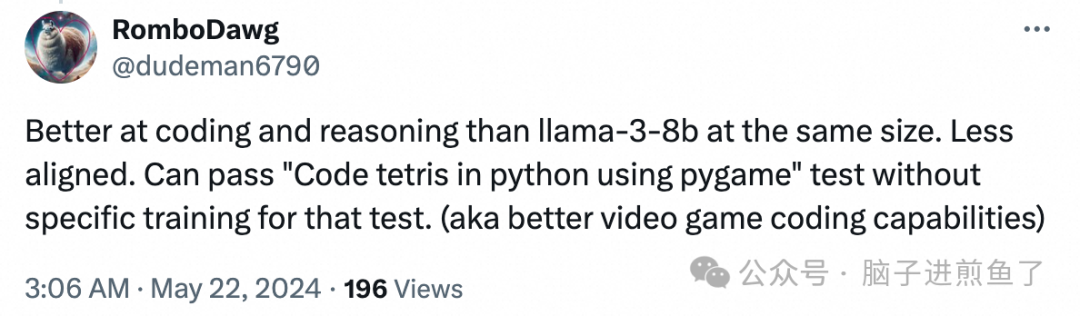
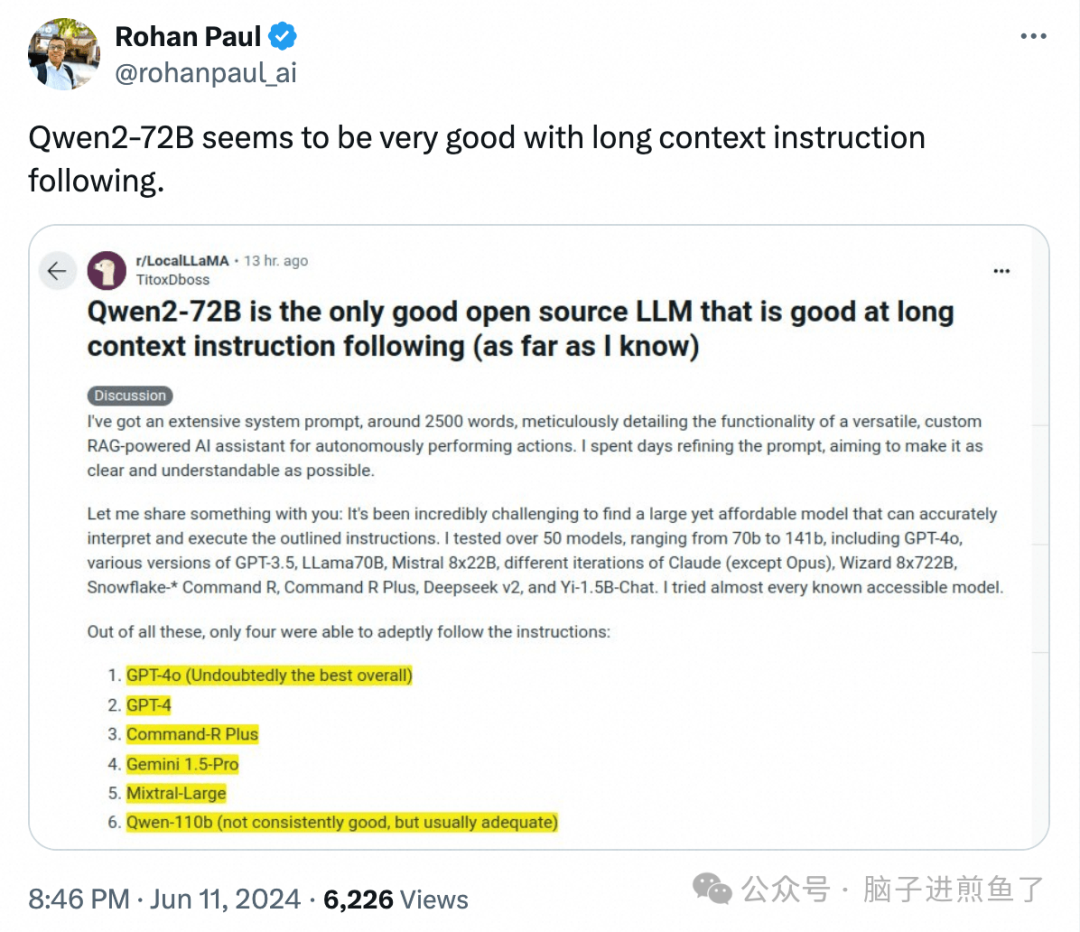
Qwen2的编码和推理能力比同等规模的 llama-3-8b 更好,无需专门训练即可编写俄罗斯方块游戏:
总结
讲了很多内容,可以看的出来通义千问在不断地持续进化,直至现在 Qwen2 系列已经到了 “遥遥领先” 国内各大模型的地步了。
还有一个关键点,通义有自己阿里云基于自研的异构芯片互联体系,在基础设施层,阿里云灵骏智算集群具备高达十万卡 GPU 的扩展性。这是其他国内厂商都所难以在短时间内匹敌的。
推荐大家可以尝试接入使用看看!

















 2392
2392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









