







前言
提到MySQL的事务,我相信对MySQL有了解的同学都能聊上几句,无论是面试求职,还是日常开发,MySQL的事务都跟我们息息相关。
而事务的ACID(即原子性Atomicity、一致性Consistency、隔离性Isolation、持久性Durability)可以说涵盖了事务的全部知识点,所以,我们不仅要知道ACID是什么,还要了解ACID背后的实现,只有这样,无论在日常开发还是面试求职,都能无往而不利。
为了大家更好的阅读体验,对ACID的深入分析将分为上下两篇。
本篇主要围绕ACID中的I,也就是“隔离性”展开,从基本概念,到隔离性的实现,最后以一个实战案例进行融会贯通。
InnoDB总体结构
首先我们来看官网的一张图(图片来源于MySQL官网):

从上图中可以看出其主要分为两部分结构,一部分为内存中的结构(上图左边),一部分为磁盘中的结构(上图右边)
内存结构
InnoDB内存中的结构主要分为:Buffer Pool,Change Buffer和Log Buffer三部分。
Buffer Pool
Buffer Pool是InnoDB缓存表和索引的一块主内存区域,Buffer Pool允许直接从内存中处理经常使用的数据,从而加快处理速度,带来一定的性能提升。 但是缓存总有放满的时候,当缓存满了新来的数据怎么处理呢?Bufer Pool中采用的是LRU(least recently used,最近最少使用)算法,LRU列表中最前面存的是高频使用页,尾部放的是最少使用的页。当有新数据过来而缓存满了就会覆盖尾部数据。
假如我们有一条查询语句非常大,返回的结果集直接就超过了Buffer Pool的大小,而这种语句使用场景又是极少的,可能查询这一次之后很久不会查询,而这一次就将缓存占满了,将一些热点数据全部覆盖了。为了避免这种情况发生,InnoDB对传统的LRU算法又做了改进,将LRU列表分拆分为2个,如下图(图片来源于MySQL官网):
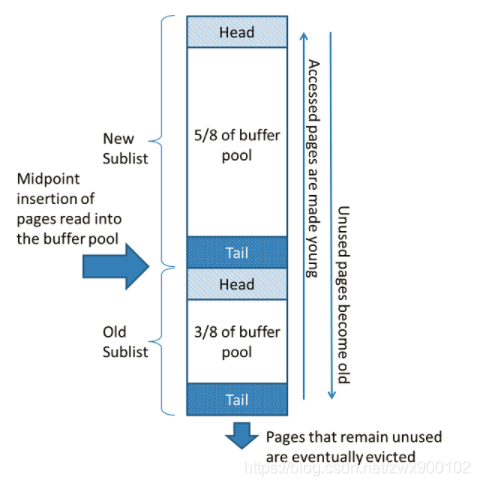
该算法在new子列表中保留大量页面(5/8),old子列表包含较少使用的页面(3/8);old子列表中数据可能会被覆盖,该算法具体操作如下:
-
3/8的Buffer Pool空间用于old子列表
-
列表的中点是new子列表的尾部与old子列表的头部之间的边界
-
当InnoDB将一个页面读入缓冲池时,它首先将它插入到中间点(old子列表的头)。读取的页面是由用户发起的操作(比如SQL查询)或InnoDB自动执行的预读操作
-
访问old子列表中的页面使其“young”,并将其移动到new子列表的头部。如果读取的页是由用户发起的操作,那么就会立即进行第一次访问,并使页面处于young状态;如果读取的页是由预读发起的操作,那么第一次访问不会立即发生,而且可能直到覆盖都不会发生。
-
操作数据时,Buffer Pool中未被访问的页会逐渐移到尾部,最终会被覆盖。
默认情况下,查询读取的页面会立即移动到新的子列表中,这意味着它们在缓冲池中停留的时间更长。
Change Buffer
Change Buffer是一种特殊的缓存结构,用来缓存不在Buffer Pool中的辅助索引页, 支持insert, update,delete(DML)操作的缓存(注意,这个在MySQL5.5之前叫做Insert Buffer,仅支持insert操作的缓存)。当这些数据页被其他查询加载到Buffer Pool后,则会将数据进行merge到索引数据叶中。
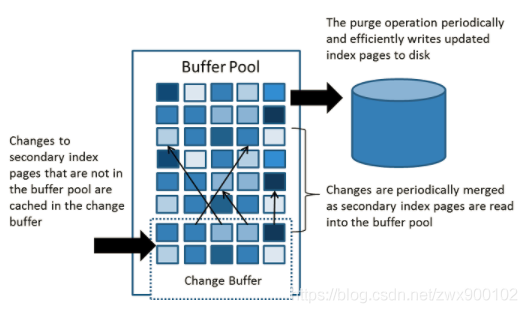
InnoDB在进行DML操作非聚集非唯一索引时,会先判断要操作的数据页是不是在Buffer Pool中,如果不在就会先放到Change Buffer进行操作,然后再以一定的频率将数据和辅助索引数据页进行merge。这时候通常都能将多个操作合并到一次操作,减少了IO操作,尤其是辅助索引的操作大部分都是IO操作,可以大大提高DML性能。
如果Change Buffer中存储了大量的数据,那么可能merge操作会需要消耗大量时间。
为什么Change Buffer只能针对非聚集非唯一索引
因为如果是主键索引或者唯一索引,需要判断数据是否唯一,这时候就需要去索引页中加载数据判断而不能仅仅只操作缓存。
Change Buffer什么时候会merge
总体来说,Change Buffer的merge操作发生在以下三种情况:
-
辅助索引页被读取到Buffer Pool时。 当执行一条select语句时,会去检查当前数据页是否在Change Buffer中,如果在,就会把数据merge到索引页
-
该辅助索引页没有可用空间时。 InnoDB内部会检测辅助索引页是否还有可用空间(至少有1/32页),如果检测到当前操作之后,当前索引页剩余空间不足1/32时,会进行一次强制merge操作
-
后台线程Master Thread定时merge。 Master Thread是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性。
Adaptive Hash Index
Adaptive Hash Index,自适应哈希索引。InnoDB引擎会监控对索引页的查询,如果发现建立哈希索引可以带来性能上的提升,就会建立哈希索引,这种称之为自适应哈希索引,InnoDB引擎不支持手动创建哈希索引。
Log Buffer
日志缓冲区是存储要写入磁盘日志文件的一块数据内存区域,大小由变量innodb_log_buffer_size 控制,默认大小为16MB(5.6版本是8MB):
SHOW VARIABLES LIKE 'innodb_log_buffer_size';-- global级别,无session级别
上文讲述update语句更新流程一文中,我们只提到了Buffer Pool用来代替缓存区,通过本文对内存结构的分析,实际上Buffer Pool中严格来说还有Change Buffer,Log Buffer和Adaptive Hash Index三个部分,DML操作会缓存在Change Buffer区域,而写redo log之前会先写入Log Buffer,所以Log Buffer又可以称之为redo Log Buffer。
Log Buffer什么时候写入redo log
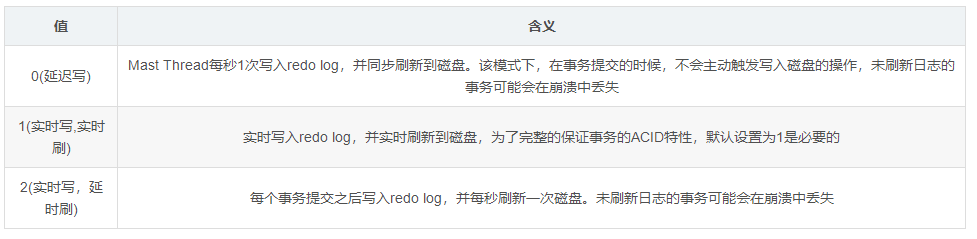
一个大的Log Buffer空间大允许运行大型事务,而无需在事务提交之前将redo log数据写入磁盘。Log Buffer中的数据会定期刷新到磁盘,那么Log Buffer的数据又是如何写入磁盘的呢?Log Buffer数据flush到磁盘有三种方式,通过变量innodb_flush_log_at_trx_commit 控制,默认为1。 |value|描述|
-
当设置为0时,由于数据还在内存,所以崩溃后数据基本会被丢失
-
当设置为2时,由于数据已经实时写到redo log了,如果磁盘文件没有被损坏,还是可以恢复的
另外,Mast Thread默认1s进行一次刷盘操作,这个可以通过变量innodb_flush_log_at_timeout控制,默认1s。
SHOW VARIABLES LIKE 'innodb_flush_log_at_timeout';-- global级别,无session级别
磁盘结构
InnoDB引擎的磁盘结构,从大的方面来说可以分为Tablespace和redo log两部分
Tablespace
Tablespace可以分为4大类,分别是:System Tablespace,File-Per-Table Tablespaces,General Tablespaces,Undo Tablespaces
System Tablespace
系统表空间中包括了 InnoDB data dictionary,doublewrite buffer, change buffer, undo logs 4个部分,默认情况下InnoDB存储引擎有一个共享表空间ibdata1,如果我们创建表没有指定表空间,则表和索引数据也会存储在这个文件当中,可以通过一个变量控制(后面会介绍)。
ibdata1文件默认大小为12MB,可以通过变量innodb_data_file_path来控制,改变其大小的最好方式就是设置为自动扩展。
innodb_data_file_path=ibdata1:12M:autoextend
上面表示默认表空间ibdata1大小为12MB,支持自动扩展大小。
当我们的文件达到一定的大小之后,比如达到了998MB,我们就可以另外开启一个表空间文件:
innodb_data_home_dir=
innodb_data_file_path=/ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
关于上面的设置有3点需要注意:
-
innodb_data_home_dir如果不设置的话,那么就默认所有的表空间文件都在datadir目录下,而我们上面指定了2个不同路径,所以需要把innodb_data_home_dir设为空
-
autoextend这个属性,只能放在最后一个文件
-
指定新的表空间文件名的时候,不能和现有表空间文件名一致,否则启动MySQL时会报错
当然,表空间可以增大,自然也可以减少,但是一般我们都不会去设置减少,而且减少表空间也相对麻烦,在这里就不展开叙述了。
InnoDB Data Dictionary
InnoDB数据字典由内部系统表组成,其中包含用于跟踪对象(如表、索引和表列)的元数据。元数据在物理上位于InnoDB系统表空间中。由于历史原因,数据字典元数据在某种程度上与存储在InnoDB表元数据文件(.frm文件)中的信息重叠。
Doublewrite Buffer
Doublewrite Buffer,双写缓冲区,这个是InnoDB为了实现double write而设置的一块缓冲区,double write和上面的change buffer一个确保了可靠性,一个确保了性能的提升,是InnoDB中非常重要的两大特性。
我们先来看下面一张图:
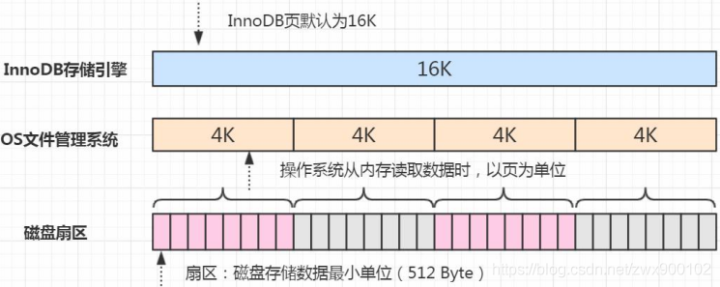
InnoDB默认页的大小是16KB,而操作系统是4KB,如果存储引擎正在写入页的数据到磁盘时发生了宕机,可能出现页只写了一部分的情况,比如只写了 4K,这种情况叫做部分写失效(partial page write),可能会导致数据丢失。
可能有人会说,可以通过redo log来恢复,但是注意,redo log恢复数据有一个前提,那就是页没有损坏,如果页本身已经被损坏了,那么是没办法恢复的,所以为了确保万无一失,我们需要先保存一个页的副本,如果出现了上面的极端情况,可以用页的副本结合redo log来恢复数据,这就是double write技术。
double write也是由两部分组成,一部分是内存中的double write buffer,大小为2MB,另一部分是物理磁盘上的共享表空间中的连续128个页,大小也是2MB,写入流程如下图(图片来源于《MySQL技术内幕 InnoDB存储引擎》):
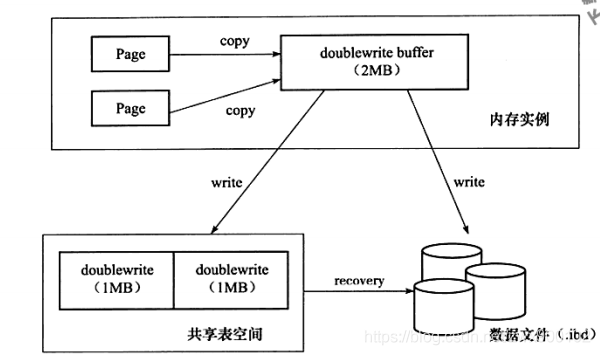
double write机制会使得数据写入两次磁盘,但是其并不需要两倍的I/O开销或两倍的I/O操作。通过对操作系统的单个fsync()调用,数据以一个大的顺序块的形式写入到双写入缓冲区。
在大多数情况下默认启用了doublewrite缓冲区。要禁用doublewrite缓冲区,可通过将变量innodb_doublewrite设置为0即可。
总结
面试难免让人焦虑不安。经历过的人都懂的。但是如果你提前预测面试官要问你的问题并想出得体的回答方式,就会容易很多。
此外,都说“面试造火箭,工作拧螺丝”,那对于准备面试的朋友,你只需懂一个字:刷!
给我刷刷刷刷,使劲儿刷刷刷刷刷!今天既是来谈面试的,那就必须得来整点面试真题,这不花了我整28天,做了份“Java一线大厂高岗面试题解析合集:JAVA基础-中级-高级面试+SSM框架+分布式+性能调优+微服务+并发编程+网络+设计模式+数据结构与算法等”
且除了单纯的刷题,也得需准备一本【JAVA进阶核心知识手册】:JVM、JAVA集合、JAVA多线程并发、JAVA基础、Spring 原理、微服务、Netty与RPC、网络、日志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB、Cassandra、设计模式、负载均衡、数据库、一致性算法、JAVA算法、数据结构、加密算法、分布式缓存、Hadoop、Spark、Storm、YARN、机器学习、云计算,用来查漏补缺最好不过。
ookeeper、Kafka、RabbitMQ、Hbase、MongoDB、Cassandra、设计模式、负载均衡、数据库、一致性算法、JAVA算法、数据结构、加密算法、分布式缓存、Hadoop、Spark、Storm、YARN、机器学习、云计算,用来查漏补缺最好不过。
[外链图片转存中…(img-rjuhdRYH-1651889420041)]














 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









