







一、efficientnet v1
Google2019年发表的文章,在论文中提到,本文提出的EfficientNet-B7在lmagenet top-1上达到了当年最高准确率84.3%,与之前准确率最高的GPipe相比,参数数量仅为其1/8.4,推理速度提升了6.1倍。

1、亮点
- 同时探索输入分辨率,网络的深度、宽度三者共同的影响
2、细节
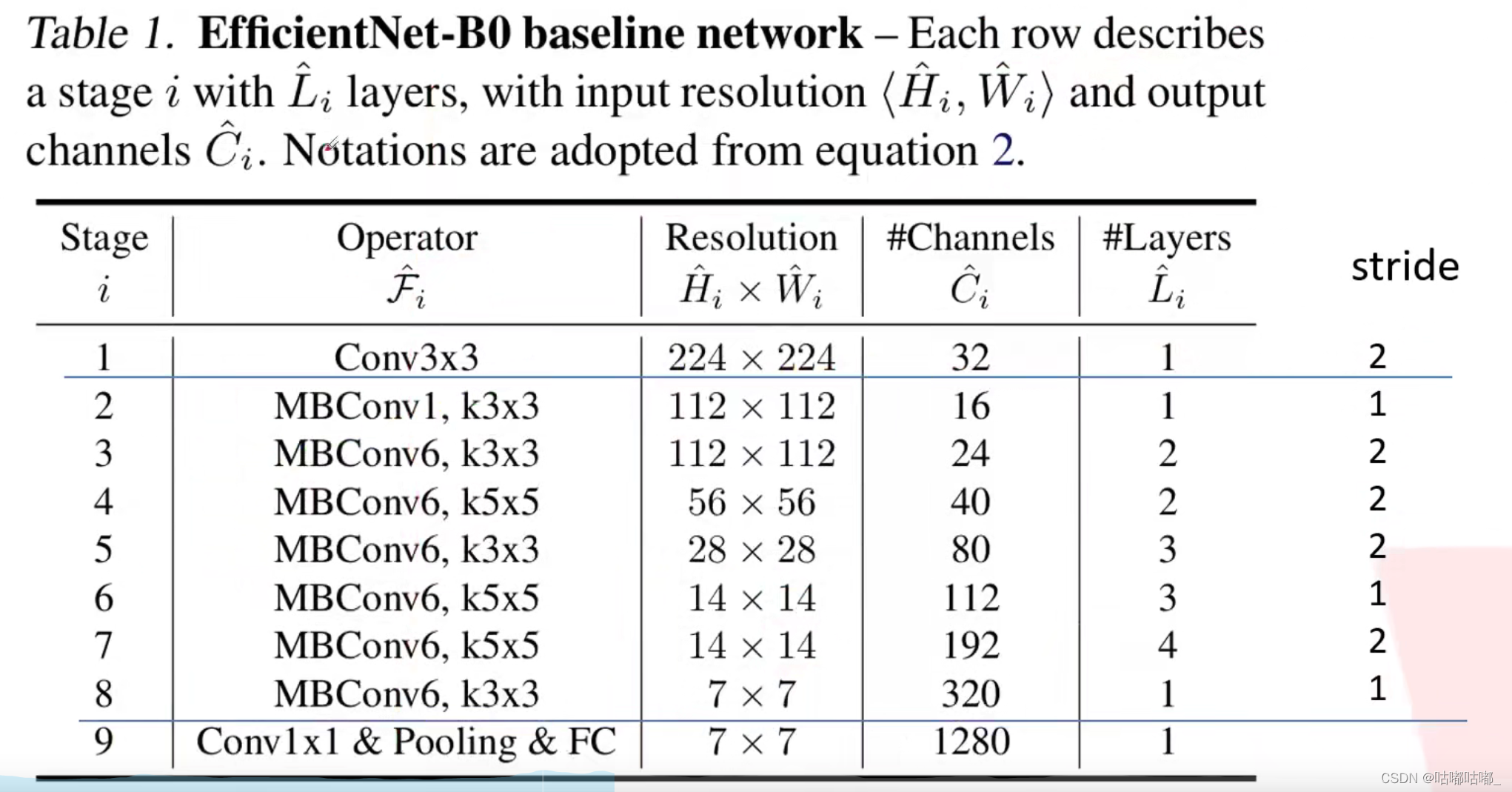

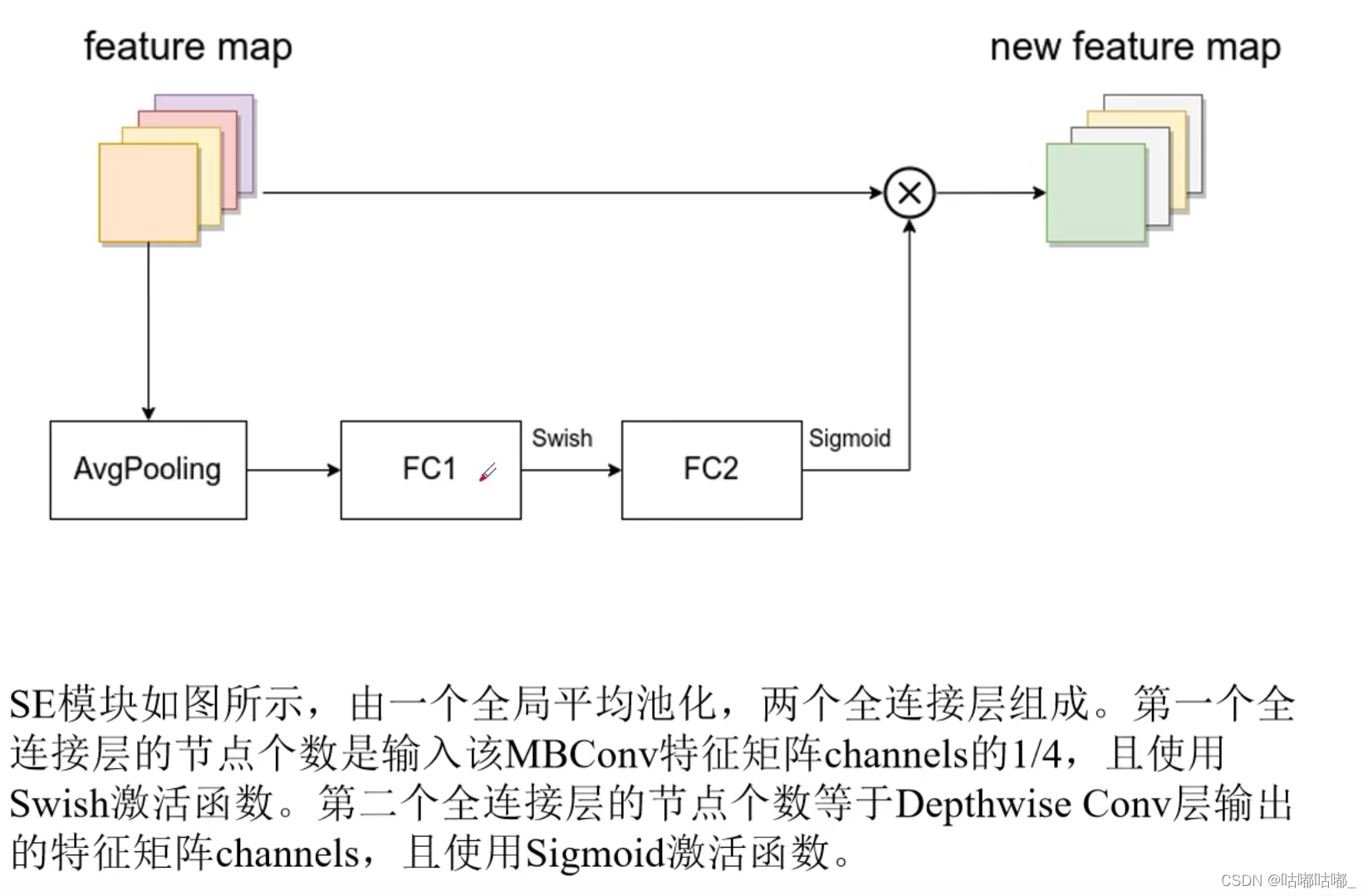
此SE模块与mbnet不同的在于1/4是输入该mbconv的1/4,而不是这个池化前的1/4
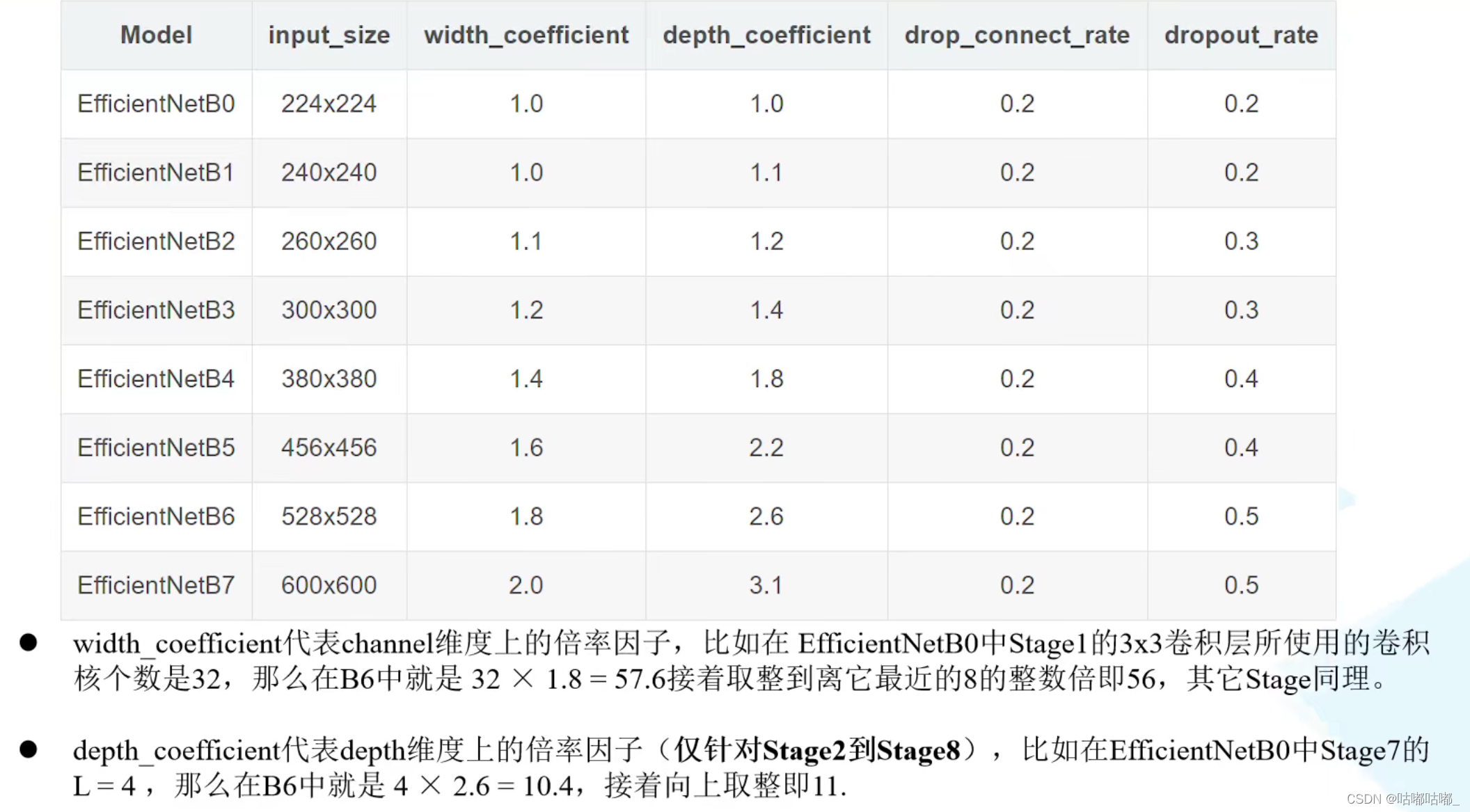
3、原论文实验效果
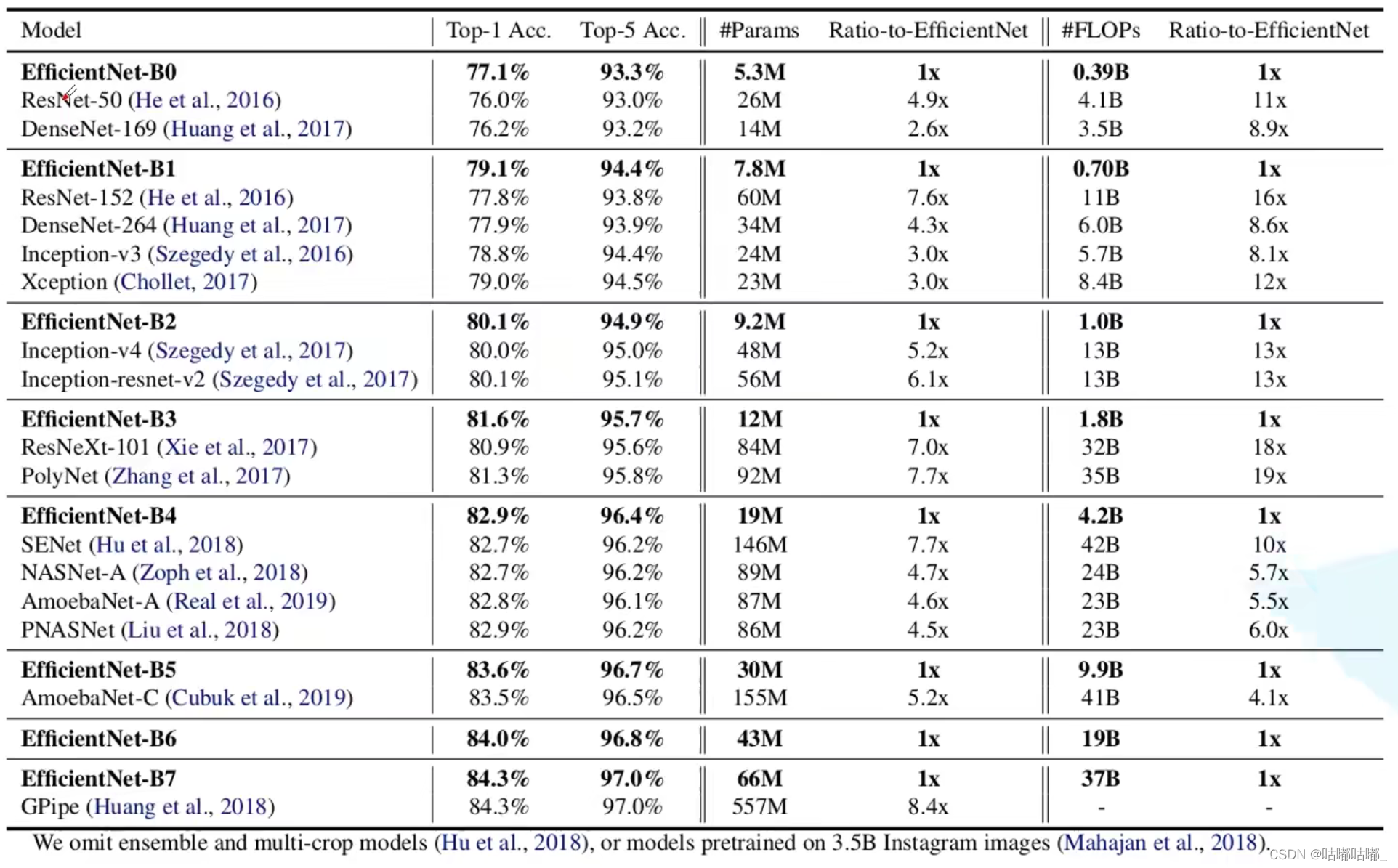
4、缺点
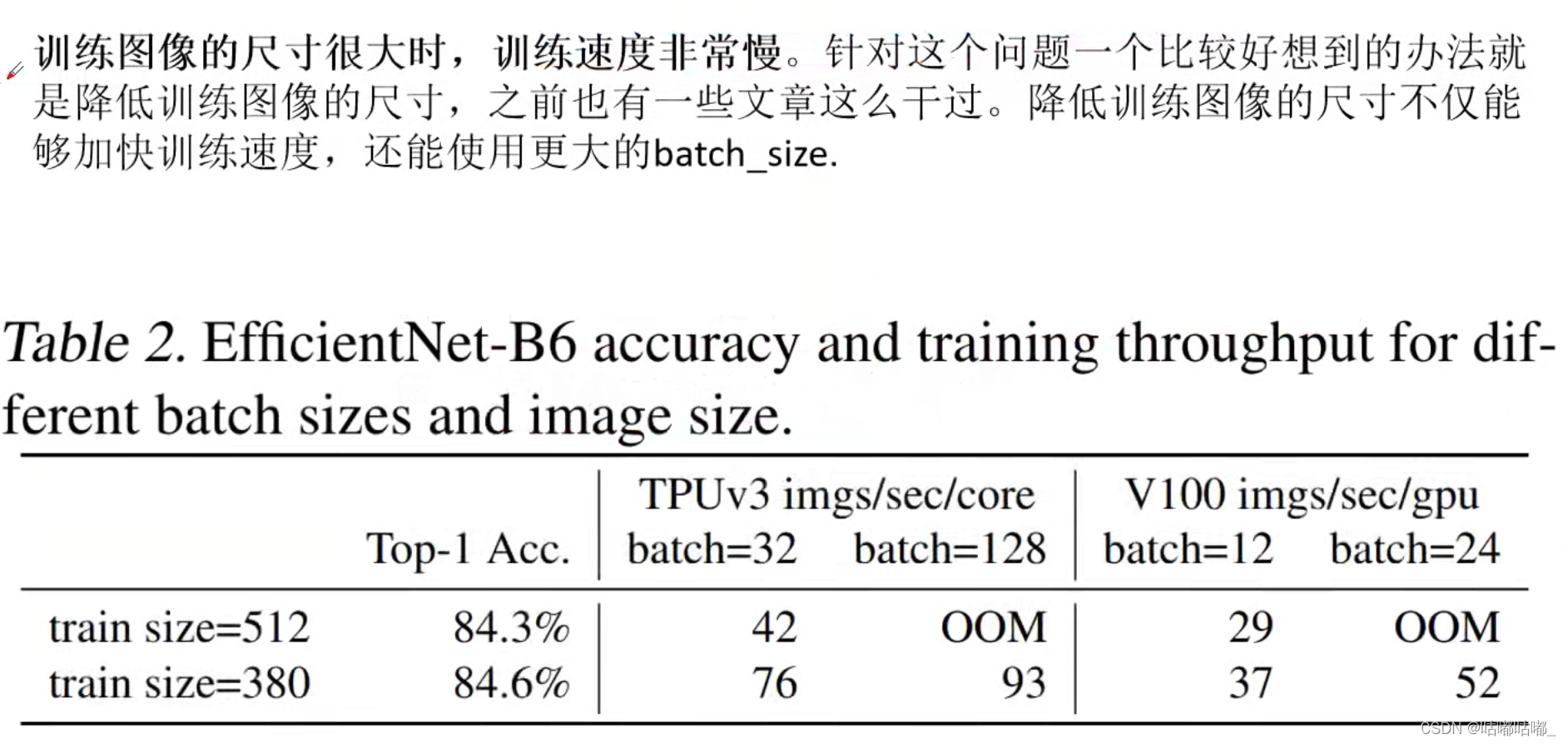
- 虽然推理速度快,但是吃显存 ,因为b6,b7的输入分辨率很大,导致每一层的输入特征图的hw都会增大。
- 在网络浅层中使用dw卷积速度也会很慢
- 同等的放大每个stage是次优的
二、Efficientnet V2
Google发表在2021年的cvpr

1、亮点
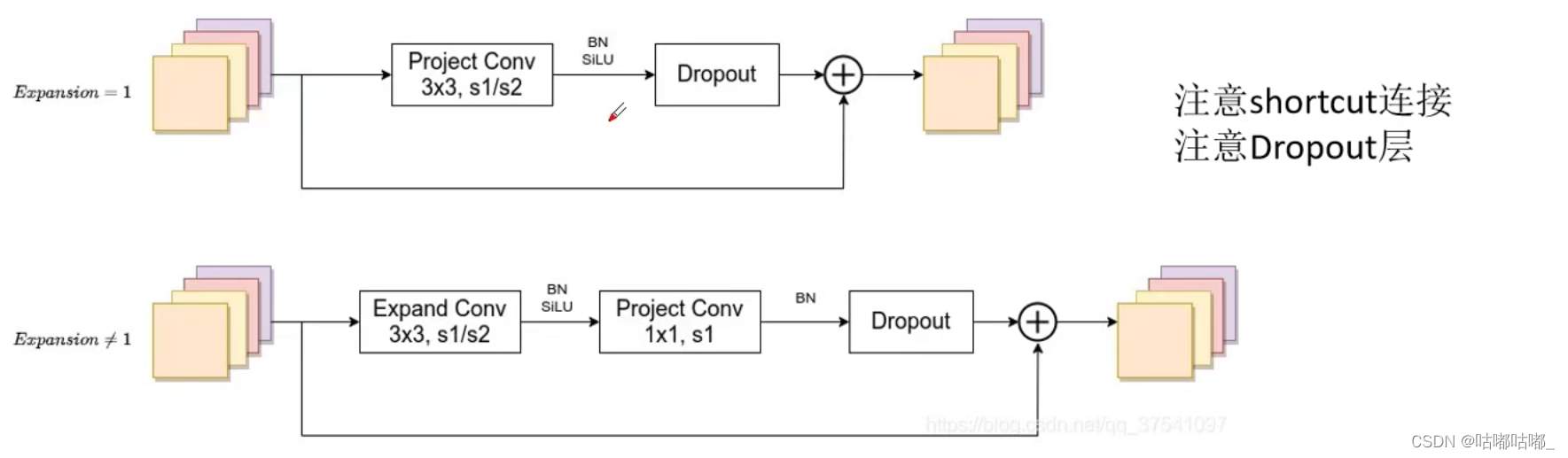
- 引入Fused-MBConv模块
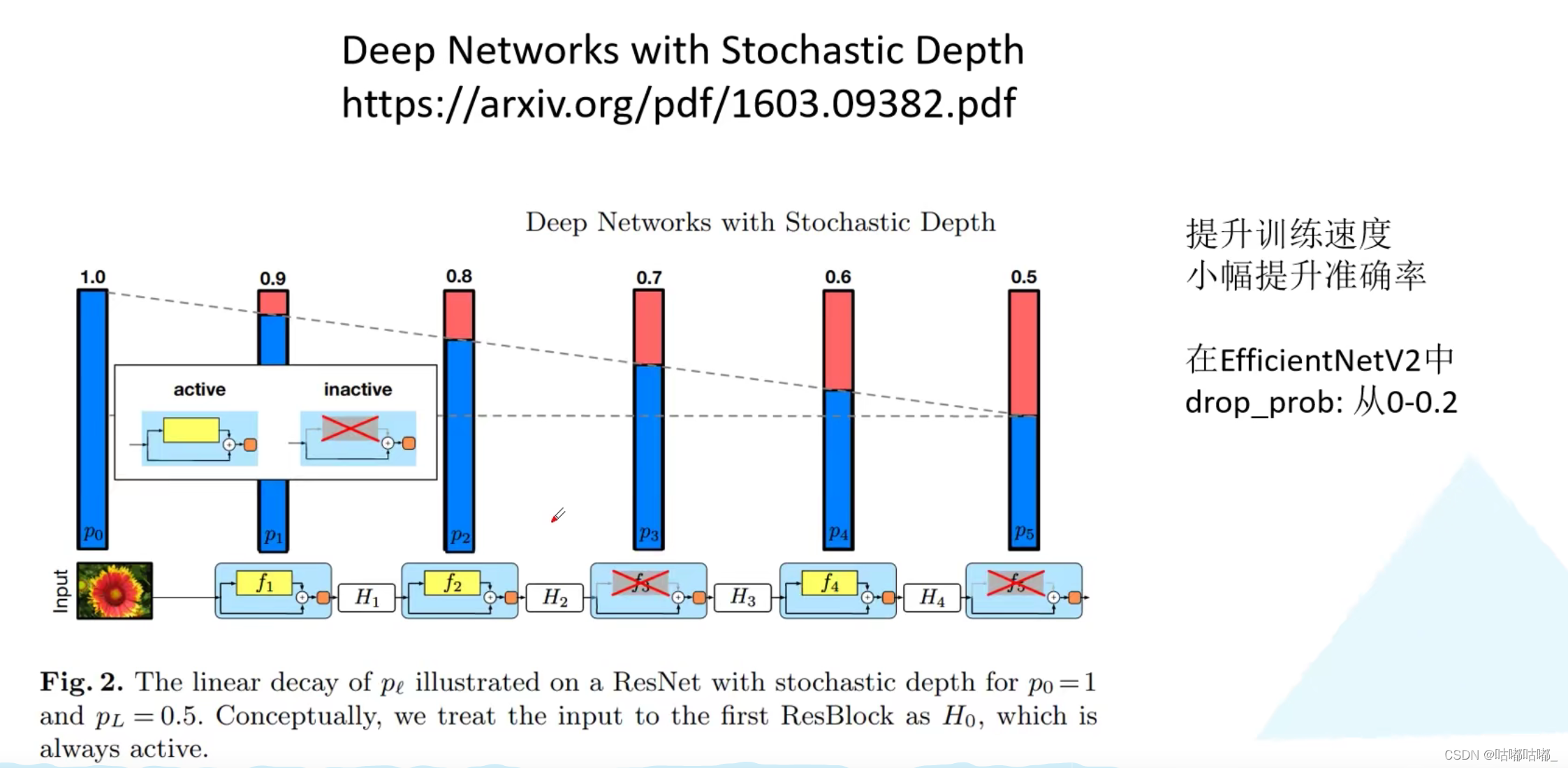
- 引入渐进式学习策略(训练更快)
2、细节
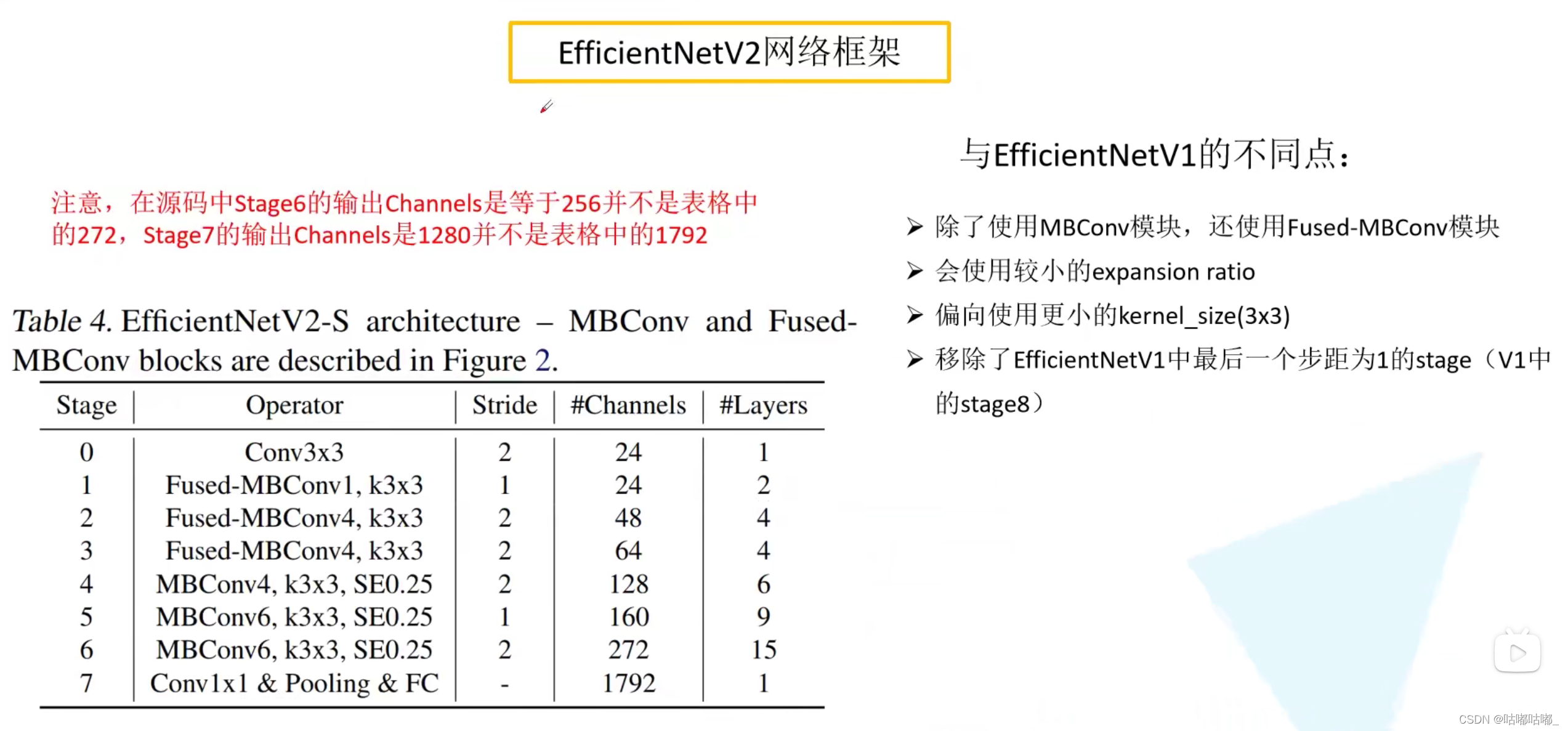
论文使用nas搜索出把stage1——3替换为fused-mbconv是最优的,且fused-conv源码中并没有使用se模块



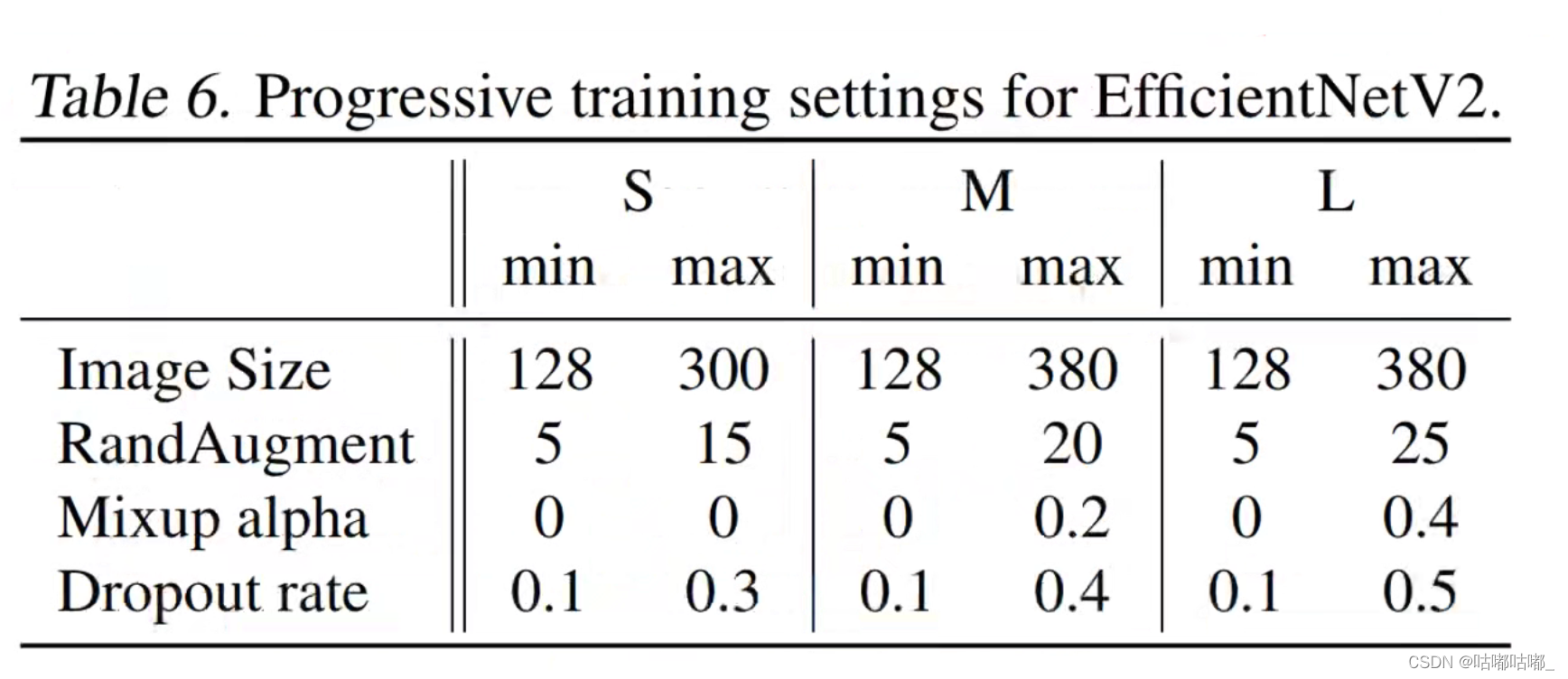
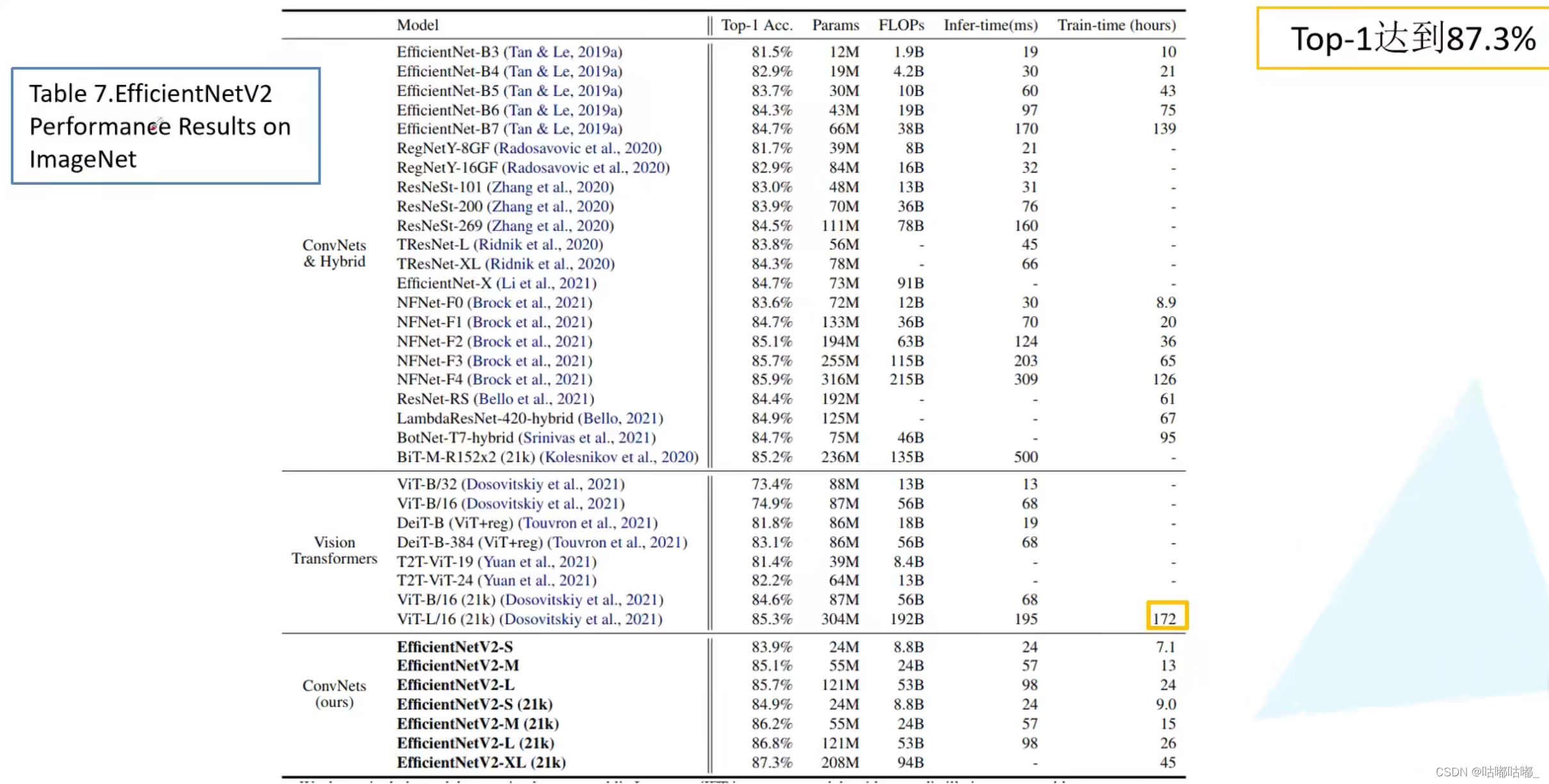
3、原论文实验效果
【参考】
b站:霹雳吧啦Wz



















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











