








总言
主要内容:编程题举例,理解前缀和的思想。
文章目录
1、前缀和
基本说明: 前缀和算法(Prefix Sum Algorithm)是一种用于高效计算数组前缀和的算法。
1、这里前缀指数组中某个位置之前(包括该位置)所有元素的和(表明前缀和适用于求一段连续的区间)。
2、其算法基本思想是通过一次遍历数组,计算每个位置的前缀和,将其存储在一个新的数组中。然后便可通过查询新数组中的元素,快速计算出任意子数组的和,从而无需重新遍历原数组。因此,在处理大型数组或需要频繁计算子序列和的问题时,前缀和算法非常有用。
以下前两题将具体展开说明一维数组的前缀和以及二维数组的前缀和。
2、【模板】一维前缀和(easy)
题源:链接。
2.1、如何理解一维数组前缀和
1)、暴力解法
根据题目,暴力解法即遍历数组(
q
q
q次),求出每次指定的
[
l
,
r
]
[l,r]
[l,r] 此段区间内的元素和:
a
l
+
a
l
+
1
+
…
…
+
a
r
−
1
+
a
r
a_l+a_{l+1}+……+a_{r-1}+a{r}
al+al+1+……+ar−1+ar。
如上述示例,
a
=
{
1
,
2
,
4
}
,
a=\{1,2,4\},
a={1,2,4},
q
=
2
。
q = 2。
q=2。
首次
[
l
,
r
]
[l,r]
[l,r] 为
[
1
,
2
]
,
[1,2],
[1,2], 即求
a
1
+
a
2
=
3
a_1+a_2 = 3
a1+a2=3;
第二次
[
l
,
r
]
[l,r]
[l,r] 为
[
2
,
3
]
,
[2,3],
[2,3], 即求
a
2
+
a
3
=
6
a_2+a_3 = 6
a2+a3=6。
按照这种操作,时间复杂度为
O
(
q
∗
n
)
O(q*n)
O(q∗n),q次循环,每次遍历元素个数为n。
2)、一维数组前缀和
步骤:①预处理出来一个前缀和数组;②使用前缀和数组。
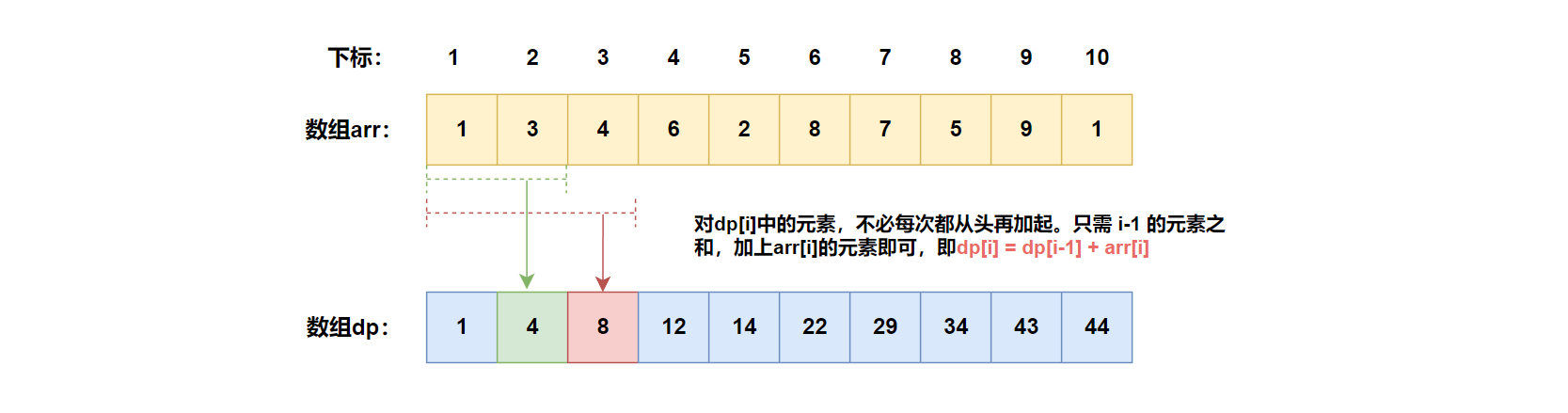
①预处理前缀和数组: 对于一个给定的数组 a r r arr arr ,它的前缀和数组 d p dp dp 中 d p [ i ] dp[i] dp[i] 表示从第 1 1 1 个元素到第 i i i 个元素的总和。计算公式如下:
d p [ i ] = d p [ i − 1 ] + a r r [ i ] dp[i] = dp[i-1] + arr[i] dp[i]=dp[i−1]+arr[i]
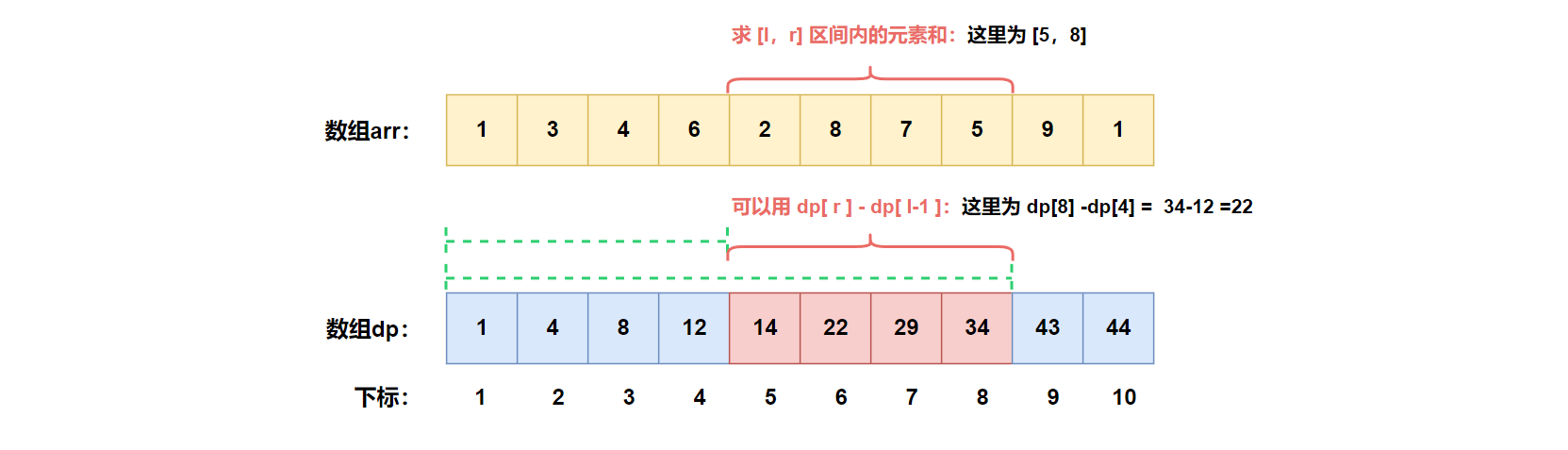
②使用前缀和数组: 前缀和主要用于求任意区间的元素之和。计算
[
l
,
r
]
[l,r]
[l,r] 区间内的元素之和
a
r
r
[
l
]
+
a
r
r
[
l
+
1
]
+
…
…
+
a
r
r
[
r
−
1
]
+
a
r
r
[
r
]
arr[l]+arr[l+1]+……+arr[r-1]+arr[r]
arr[l]+arr[l+1]+……+arr[r−1]+arr[r] ,思路为:
d
p
[
r
]
−
d
p
[
l
−
1
]
dp[r] -dp[l-1]
dp[r]−dp[l−1]
即:
区间和
=
前
r
个元素的和
−
前
l
−
1
个元素的和
区间和 = 前r 个元素的和 - 前 l-1 个元素的和
区间和=前r个元素的和−前l−1个元素的和。
说明1:时间复杂度?
①获取缀和数组
d
p
dp
dp 需要遍历一遍原数组,此处时间复杂度为
O
(
n
)
O(n)
O(n);
②求区间
[
l
,
r
]
[l,r]
[l,r] 的元素和只用根据公式计算即可,减去了反复多次遍历数组的开销
O
(
1
)
O(1)
O(1) ,共有
q
q
q 次遍历,则为
O
(
1
∗
q
)
O(1*q)
O(1∗q);
故最终,时间复杂度为:
O
(
q
)
+
O
(
n
)
O(q)+O(n)
O(q)+O(n)
说明2:为什么这里下标要从1开始?
1、从1开始计算前缀和可以确保第一个元素的前缀和就是它本身,这符合前缀和的定义。即前缀和数组的第
i
i
i 个元素的值等于原数组中前
i
i
i 个元素的和。 如果下标从0开始,那么处理第一个元素时会引入额外的逻辑,因为不存在“前0个元素”的概念。
2、其次,从 1 1 1开始可以简化计算过程。例如,以下标为 1 1 1 开始,求 [ 1 , 2 ] [1,2] [1,2],则有 d p [ 2 ] − d p [ 0 ] dp[2] - dp[0] dp[2]−dp[0] ,这里只需要设 d p [ 0 ] = 0 dp[0] = 0 dp[0]=0 即可,而这也符合 d p [ 2 ] = a r r [ 1 ] + a r r [ 2 ] dp[2] = arr[1]+arr[2] dp[2]=arr[1]+arr[2] 的特点。
3、此外,从
1
1
1 开始处理下标也便于处理边界情况。 在编程实现中,边界条件往往是最容易出现错误的地方,通过从1开始设置下标,可以避免一些由于下标偏移或越界导致的错误。例如,若下标为
0
0
0 开始,
[
0
,
2
]
[0,2]
[0,2] 则有
d
p
[
2
]
−
d
p
[
−
1
]
dp[2] - dp[-1]
dp[2]−dp[−1],越界,需要额外处理。
2.2、题解
不要死记硬背套用模板,不同题目中可能有微调,因此关键在于理解过程推导。
#include <iostream>
#include <vector>
using namespace std;
int main() {
//1、输入
int n = 0, q = 0;
cin >> n >> q;
vector<int> arr(n+1);
for(int i = 1; i< n+1; ++i)
{
cin >> arr[i];
}
//2、获取一个预处理数组:含当前位置元素在内的0~i元素和
vector<long long> dp(n+1);
for(int i = 1; i< n+1; ++i)
{
dp[i] = dp[i-1] + arr[i];
}
//3、使用该前缀和数组:查询q次,获取[l,r]元素和
int l = 0, r = 0;
for(int i = 0; i< q;++i)
{
cin >> l >> r;
cout << dp[r] -dp[l-1] << endl;
}
return 0;
}
3、【模板】二维前缀和(medium)
题源:链接
3.1、如何理解二维数组前缀和
1)、暴力解法
因给定了左上角和右下角元素下标,暴力解法下,嵌套两层循环可求出
(
x
1
,
y
1
)
−
(
x
2
,
y
2
)
(x_1, y_1) -(x_2,y_2)
(x1,y1)−(x2,y2)所含子区间元素和。遍历
q
q
q 次即可获取所有结果。
n
n
n 行
m
m
m 列
q
q
q 次查询的矩阵,总体时间复杂度为
O
(
n
∗
m
∗
q
)
O(n*m*q)
O(n∗m∗q)
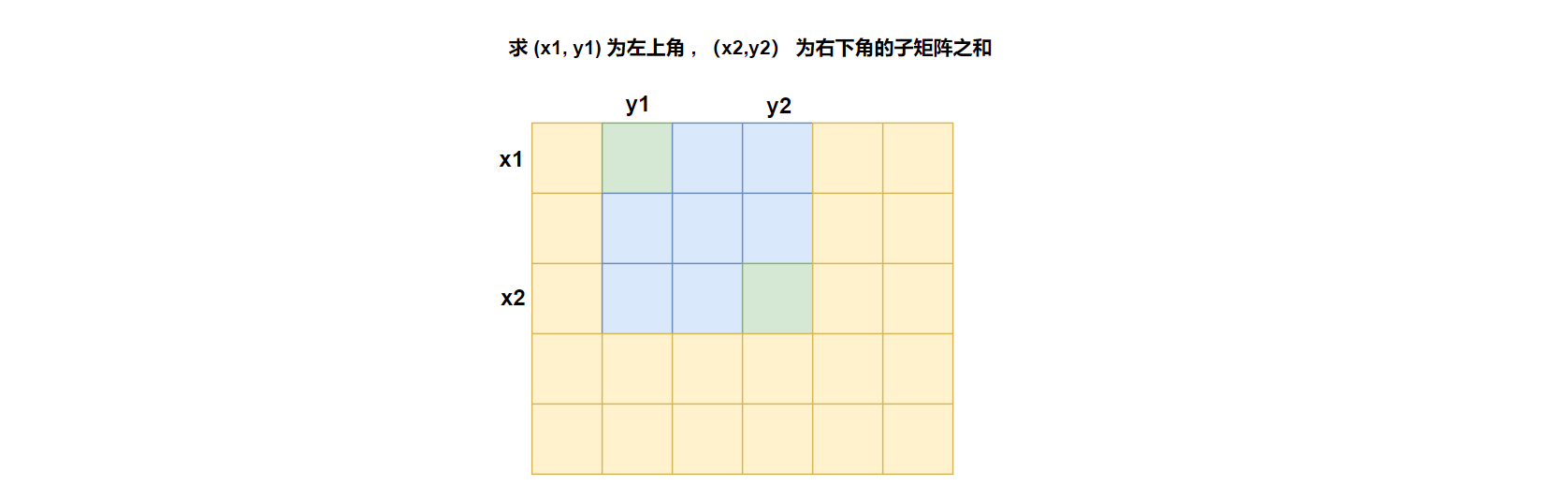
2)、二维数组前缀和
仍旧分为两步骤:①预处理出来一个前缀和数组;②使用前缀和数组。
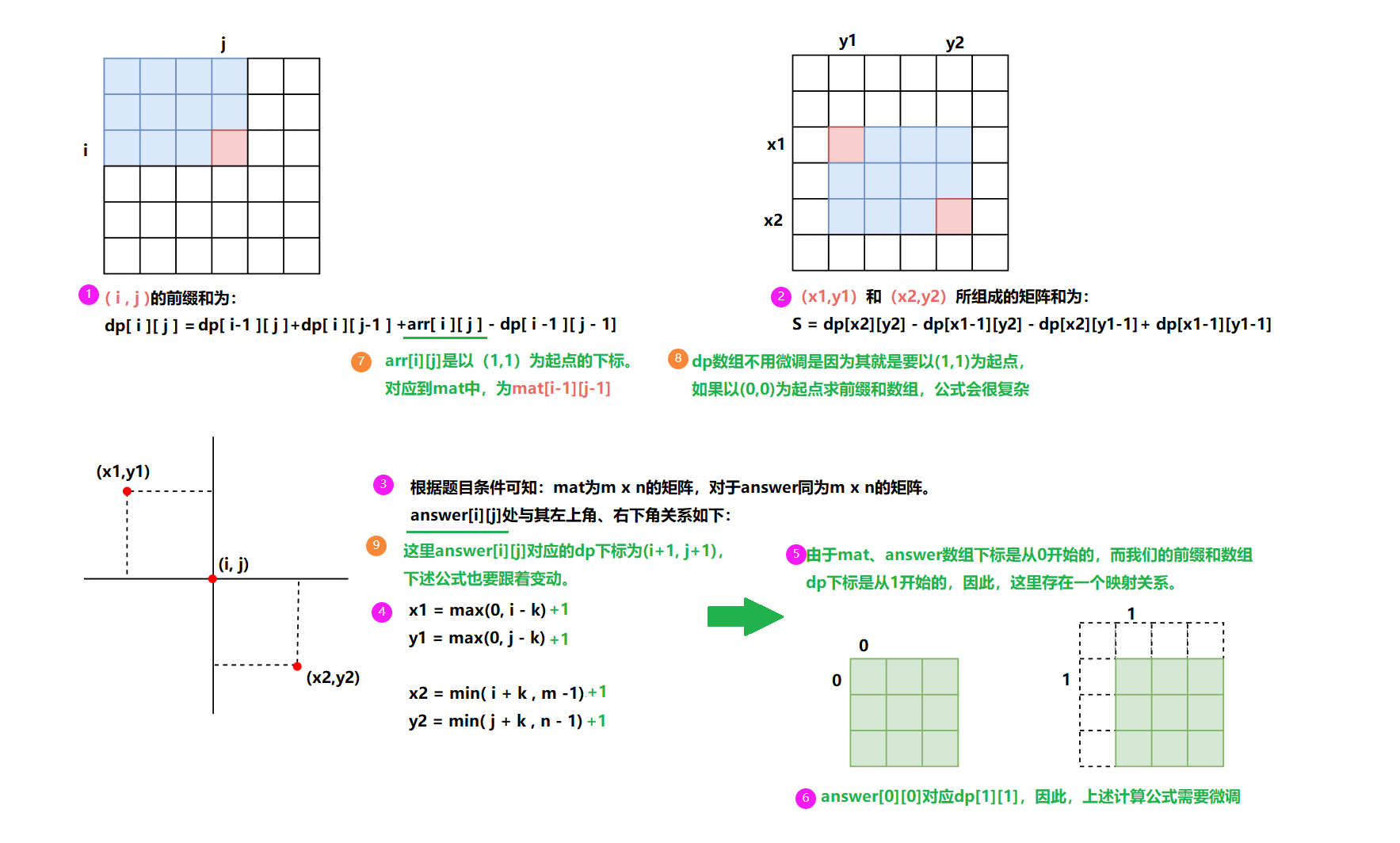
①预处理出来一个前缀和数组: 给定一个二维数组 a r r arr arr ,它的前缀和二维数组 d p dp dp 中, d p [ i ] [ j ] dp[i][j] dp[i][j] 表示以 ( 1 , 1 ) (1,1) (1,1) 为左上角元素,以 ( i , j ) (i,j) (i,j) 为右下角元素的矩形块中所有元素的总和。
要计算每一个 d p [ i ] [ j ] dp[i][j] dp[i][j],不必每次都遍历求和,有如下换算关系:
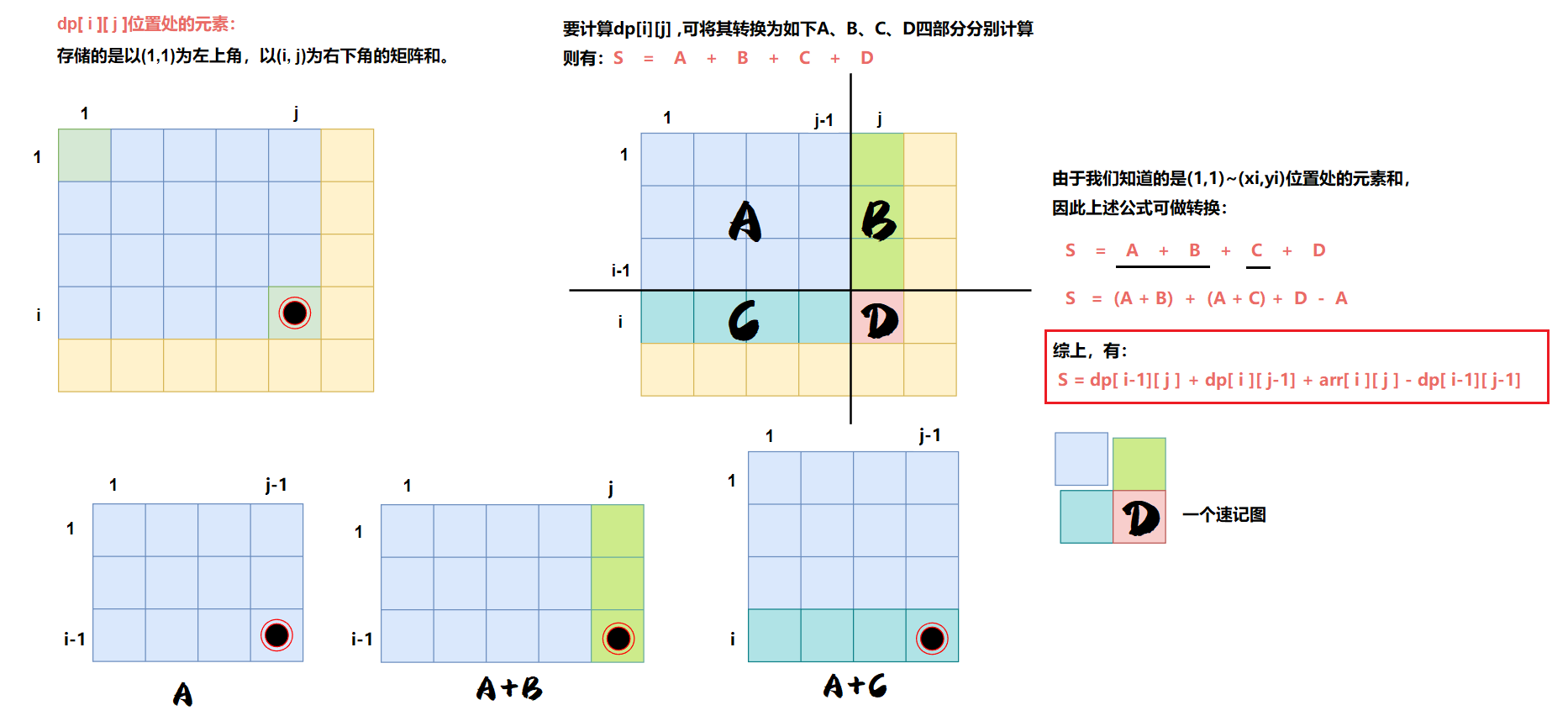
用公式表示为:
d
p
[
i
]
[
j
]
=
d
p
[
i
−
1
]
[
j
]
+
d
p
[
i
]
[
j
−
1
]
+
a
r
r
[
i
]
[
j
]
−
d
p
[
i
−
1
]
[
j
−
1
]
dp[i][j] = dp[i-1][j]+dp[i][j-1]+arr[i][j]-dp[i-1][j-1]
dp[i][j]=dp[i−1][j]+dp[i][j−1]+arr[i][j]−dp[i−1][j−1]
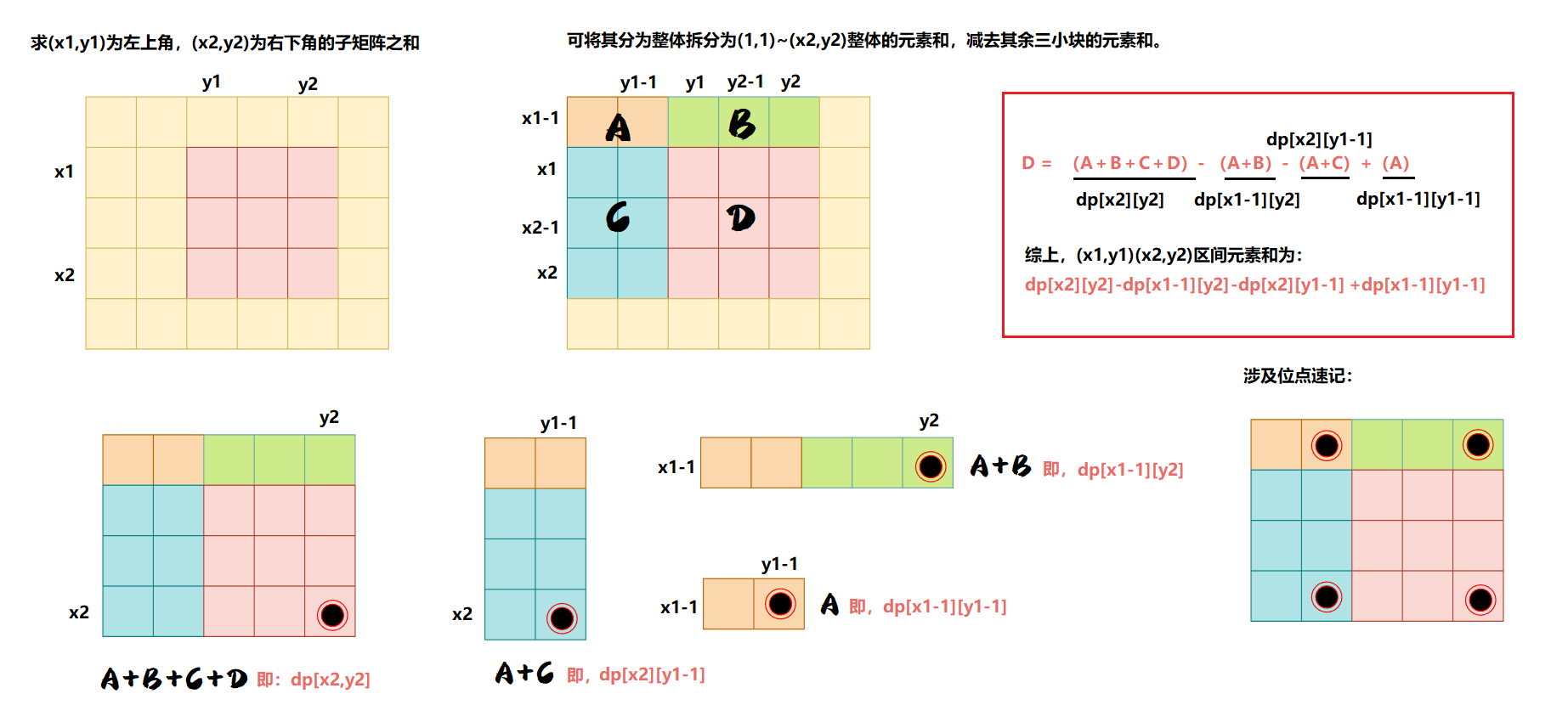
②使用前缀和数组: 二维前缀和的作用也是快速计算区块和。假设我们要计算的区块左上角下标为
(
x
1
,
y
1
)
(x_1,y_1)
(x1,y1),右下角下标为
(
x
2
,
y
2
)
(x_2,y_2)
(x2,y2) 的区块和
S
S
S,计算公式如下:
S
=
d
p
[
x
2
]
[
y
2
]
−
d
p
[
x
1
]
[
y
2
]
−
d
p
[
x
2
]
[
y
1
−
1
]
+
d
p
[
x
1
−
1
]
[
y
1
−
1
]
S=dp[x_2][y_2] -dp[x_1][y_2]-dp[x_2][y_1-1]+dp[x_1-1][y_1-1]
S=dp[x2][y2]−dp[x1][y2]−dp[x2][y1−1]+dp[x1−1][y1−1]
3.2、题解
不要死记硬背套用模板,不同题目中可能有微调,因此关键在于理解过程推导。
#include <iostream>
#include<vector>
using namespace std;
int main() {
//1、输入
int n = 0, m = 0, q = 0;
cin >> n >> m >> q;
vector<vector<int>> arr(n + 1, vector<int>(m + 1));
for (int i = 1; i < n + 1; ++i) {
for (int j = 1; j < m + 1; ++j)
cin >> arr[i][j];
}
//2、预处理一个前缀和数组:存储以(1,1)为左上角,(i,j)为右下角的子矩阵和
vector<vector<long long>> dp(n + 1, vector<long long>(m + 1));
for (int i = 1; i < n + 1; ++i) {
for (int j = 1; j < m + 1; ++j)
dp[i][j] = dp[i][j - 1] + dp[i - 1][j] + arr[i][j] - dp[i - 1][j - 1];
}
//3、使用前缀和数组:循环q次,获取以 (x1, y1) 为左上角 , (x2,y2) 为右下角的子矩阵的和
int x1 = 0, y1 = 0, x2 = 0, y2 = 0;
for (int i = 0; i < q; ++i) {
cin >> x1 >> y1 >> x2 >> y2;
cout << dp[x2][y2] - dp[x2][y1 - 1] - dp[x1 - 1][y2] + dp[x1 - 1][y1 - 1] <<endl;
}
return 0;
}
4、寻找数组的中心下标(easy)
题源:链接

4.1、题解
1)、思路分析
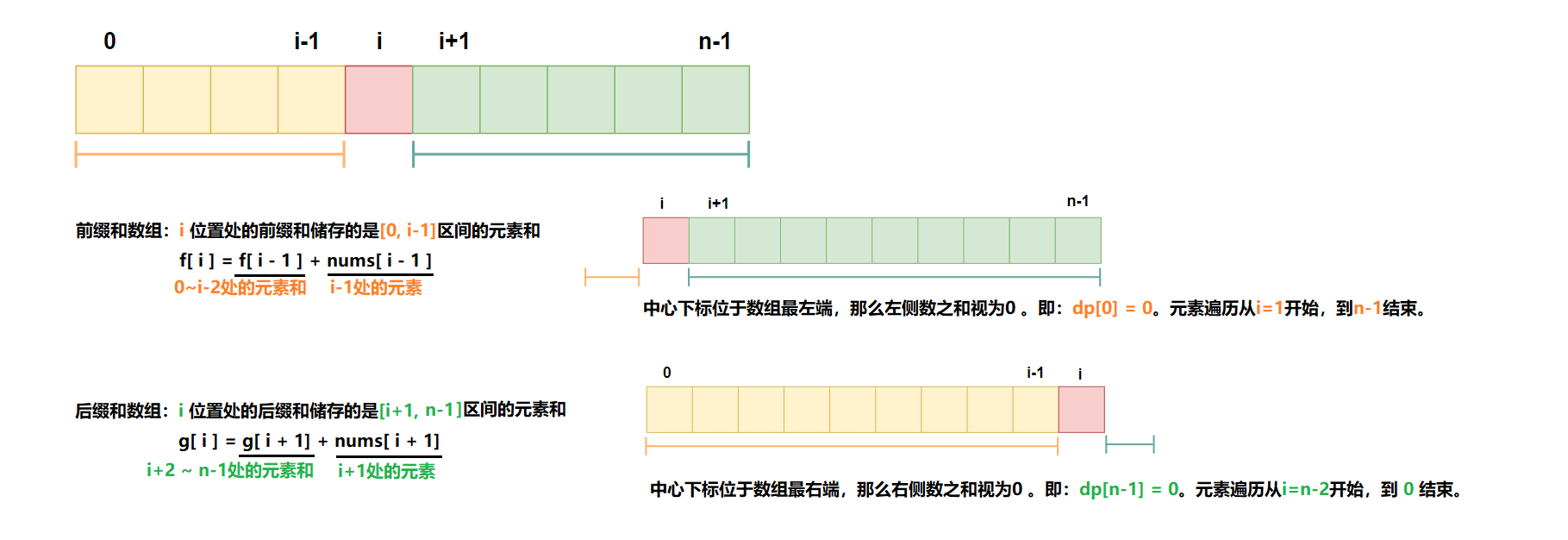
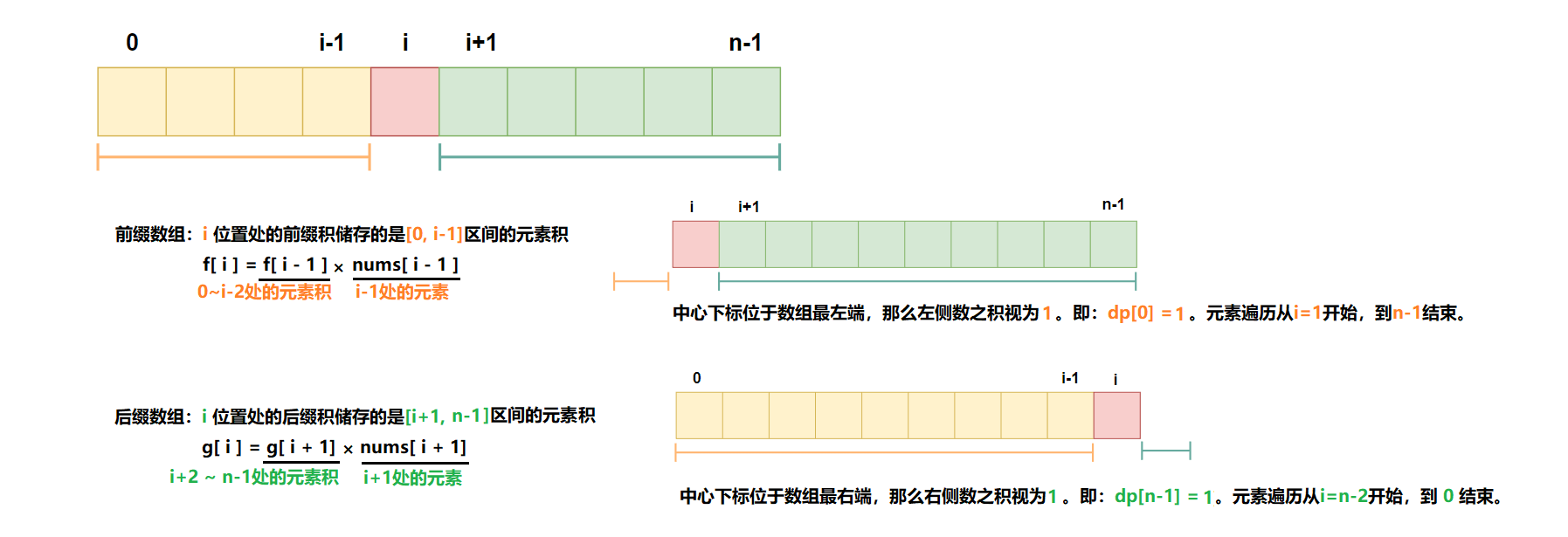
根据题意可知,中心下标左侧所有元素和等于右侧所有元素相加的和。即其左边的「前缀和」等于该元素右边的「后缀和」。
因此,我们可以先预处理出来两个数组,⼀个表示前缀和f[i],另⼀个示后缀和g[i]。
之后,可以⽤⼀个 for 循环枚举可能的中心下标i,判断当前位置的「前缀和」以及「后缀和」是否相等。f[i]==g[i]
2)、题解
class Solution {
public:
int pivotIndex(vector<int>& nums) {
int n = nums.size();//元素总个数。
// 1、获取前缀和数组:f[i] 表⽰:[0, i - 1] 区间所有元素的和
vector<int> f(n);
f[0] = 0; // 处理首个元素(此步也可以不必,vector默认初始化为0)
for (int i = 1; i <= n - 1; ++i)
{
f[i] = f[i - 1] + nums[i - 1];
}
// 2、获取后缀和数组:g[i] 表⽰:[i + 1, n - 1] 区间所有元素的和
vector<int> g(n);
for (int i = n - 2; i >= 0; --i)
{
g[i] = g[i + 1] + nums[i + 1];
}
// 3、比较:有多个中心下标时返回最左边那个,因此从左到右遍历查找最为合适
for (int i = 0; i < n; ++i)
{
if (f[i] == g[i])
return i;
}
return -1; // 找不到
}
};
5、除自身以外数组的乘积(medium)
题源:链接

5.1、题解
1)、思路分析
此题解法与上题相同,只不过这里换成了「前缀积」和「后缀积」。
另外需要注意,如果自身下标nums[ i ]位于数组最左端(最右端),那么左侧(右侧)数之和视为 1 。
2)、题解
class Solution {
public:
vector<int> productExceptSelf(vector<int>& nums) {
int n = nums.size();
// 1、前缀积数组
vector<int> f(n);
f[0] = 1; // 处理首元素,这里不能为0.
for (int i = 1; i <= n - 1; ++i) {
f[i] = f[i - 1] * nums[i - 1];
}
// 2、后缀积数组
vector<int> g(n);
g[n - 1] = 1;
for (int i = n - 2; i >= 0; --i) {
g[i] = g[i + 1] * nums[i + 1];
}
// 3、相乘
vector<int> ret(n);
for (int i = 0; i < n; ++i) {
ret[i] = f[i] * g[i];
}
return ret;
}
};
6、和为 k 的子数组(medium)
题源:链接

6.1、题解
1)、思路分析
如果按照基础算法的学习顺序来,除了暴力解法,这里相对容易想到的是使用滑动窗口,只是根据提示-1000 <= nums[i] <= 1000,元素有正有负,不满足单调性,滑动窗口相对不便。
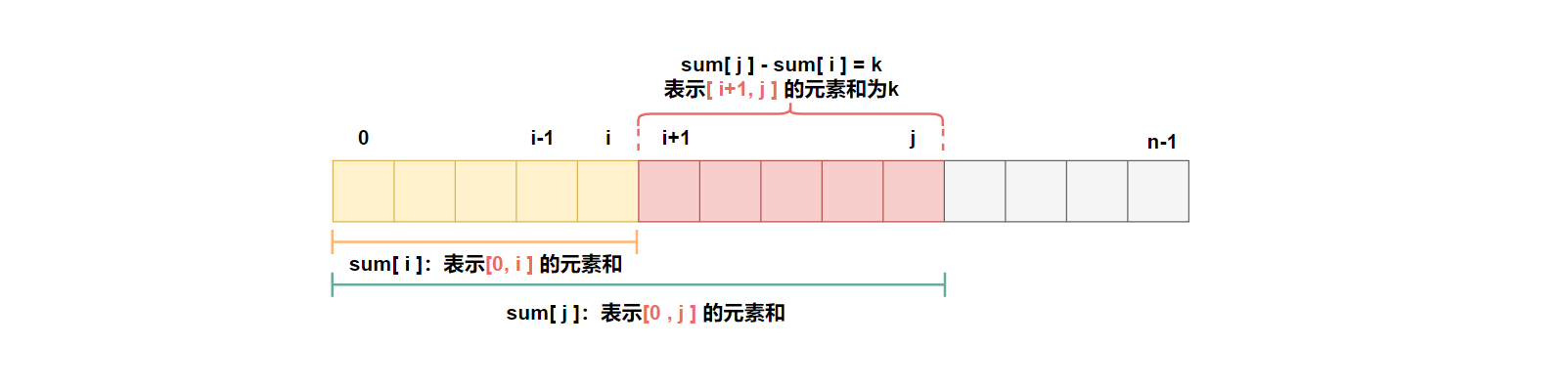
使用前缀和的方法可以解决这个问题,因为我们需要找到和为k的连续子数组的个数。通过计算前缀和,我们可以将问题转化为求解两个前缀和之差等于k的情况:
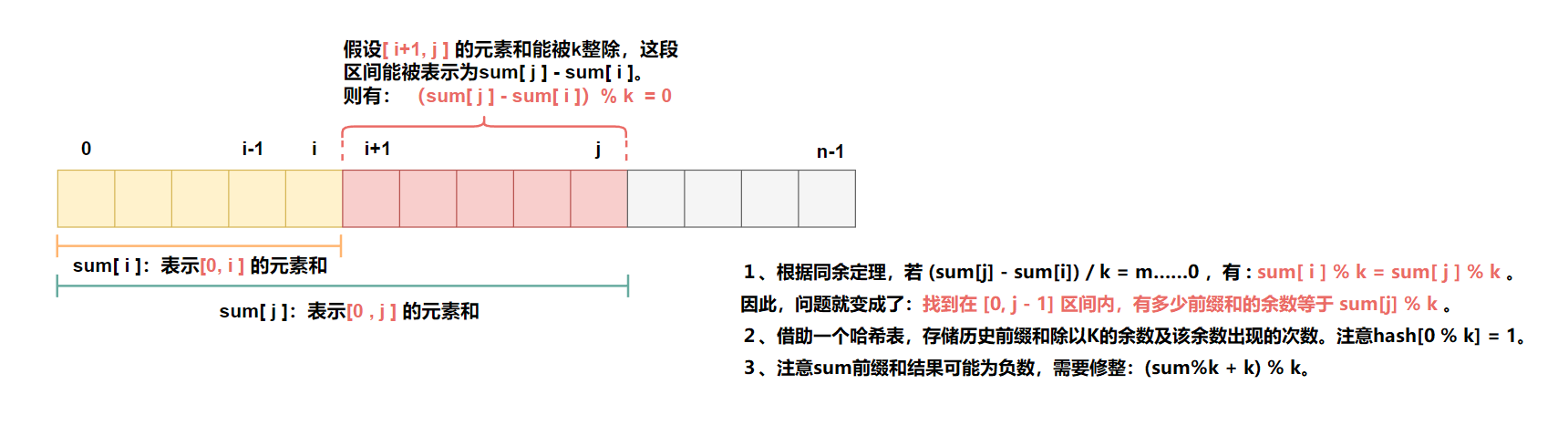
假设数组的前缀和数组为Sum,其中Sum[i]表示从数组起始位置到第i个位置的元素之和。那么对于任意的两个下标i和j(i < j),如果Sum[j] - Sum[i] = k,那么说明从第i+1个位置到第j个位置的连续子数组的和为k。
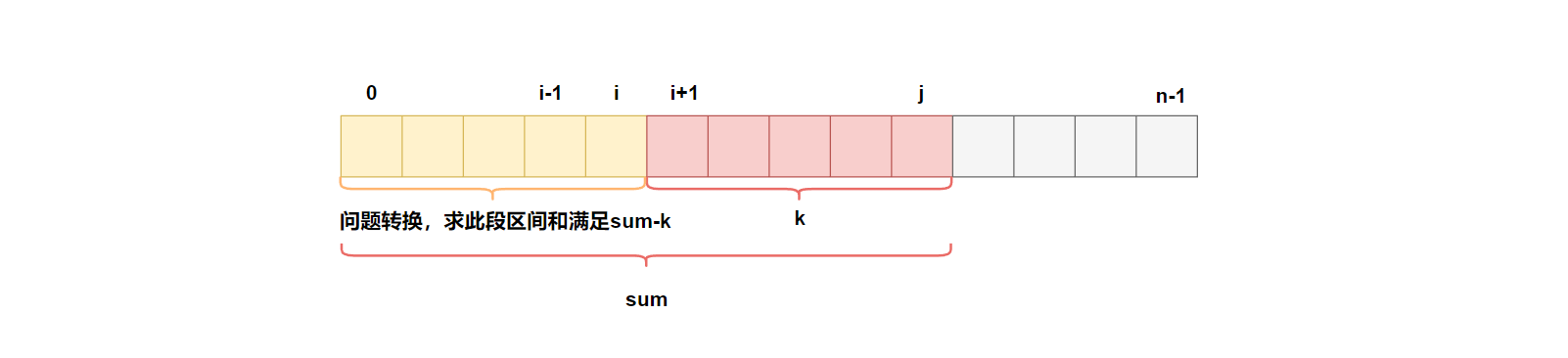
题目为求Sum[j] - Sum[i] = k的区间个数,对问题进行变形,可以转换为求解满足Sum[i] == Sum[j] - k的区间个数,即在[0,j-1]区间中,有多少个前缀和满足 Sum[j] - k。
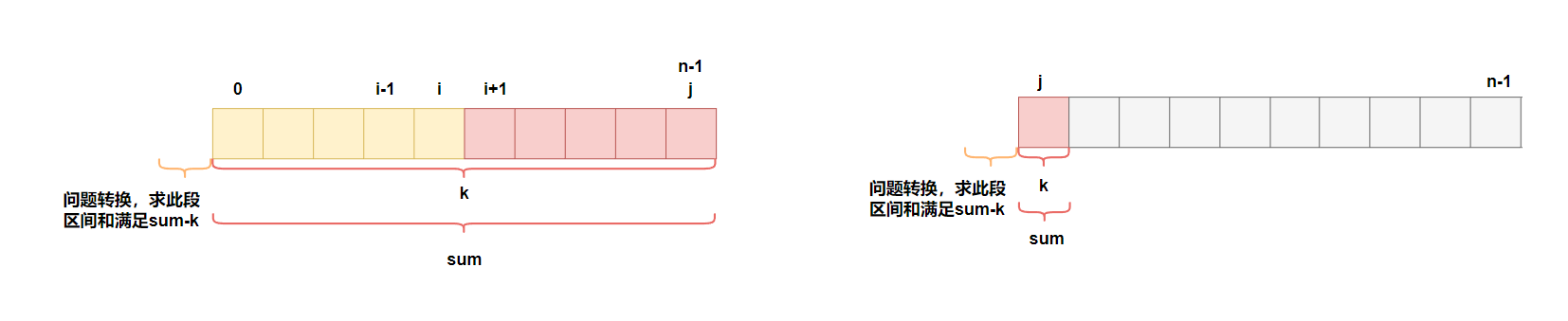
所以我们需要使用一个数据结构,以便在需要时能够快速查找Sum[i]。因此,我们借助哈希表来存储历史前缀和,及其出现的次数。(hash<int,int>,key值为前缀和,value值统计该前缀和出现次数。)
从j = 0开始遍历数组,获取当前位置的的元素和sum[j],检查是否存在Sum[j] - k的前缀和,如果存在,说明[0, j-1]区间内,某个位置到当前位置 j 的连续子数组的和为k,可将对应的次数累加到结果中。
这样,通过遍历一次数组,我们可以统计出和为k的连续子数组的个数,并且时间复杂度为O(n),其中n为数组的长度。
其它细节:
1、创建一个前缀和数组? 实际我们不需要创建一个新的前缀和数组,只需用一个值sum,存储[0,j-1]的元素和,那么遍历到j位置时,只需要sum+=nums[j],即可得到当前j位置处的元素和。
2、前缀和加入哈希表的时机? 由于是j位置处的元素和与[0,j-1]处的历史元素和做差判断Sum- k,因此,比较判断之时,哈希表中只保存[0, j -1]位置的前缀和。判断结束后,才将 j 位置处的前缀和放入哈希表中。
3、为什么初始化hash[0] = 1? 在最开始还没有遍历nums时,可以得到前缀和为0的区间有1个(区间内不包含任何元素)。当然,也可以是数组整个前缀和刚好等于 k的情况。
2)、题解
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
unordered_map<int, int> hash; // 哈希表:用于放置历史前缀和及其个数
hash[0] = 1; // 防止sum-k=0的情况;
int sum = 0; // 用于统计j-1次的前缀和,以便在第j次做累加
int ret = 0; // 用于统计和为K的子数组个数
for (auto j : nums) {
sum += j; // j位置处的前缀和
if (hash.count(sum - k)) // 判断sum(i) = sum(j) - k 在历史统计的前缀和中是否存在
ret += hash[sum -k]; // 若存在,说明[0,j]此段区间内,有某一位置i到j的前缀和为K
hash[sum]++; // 把当前j计算得出的前缀和放入哈希表中
}
return ret;
}
};
7、和可被 K 整除的子数组(medium)
题源:链接

7.1、题解
1)、思路分析
此题解法思想和上一题相同,仍可以使用前缀和。这里要先补充两个背景知识:
同余定理
同余定理是数论中的重要概念。给定一个正整数 m m m,如果两个整数 a a a 和 b b b 满足 ( a − b ) (a - b) (a−b) 能被 m m m 整除,那么我们就称整数 a a a 与 b b b 对模 m m m 同余,记作 a ≡ b ( m o d ∣ m ) a ≡ b ( mod | m) a≡b(mod∣m)。
定理1:整数
a
,
b
a, b
a,b对模
m
m
m 同余的充要条件是
a
−
b
a - b
a−b 能被
m
m
m 整除 (即:
m
∣
a
−
b
m|a- b
m∣a−b,
∣
|
∣ 代表的是整除的意思)。
推论:
a
≡
b
(
m
o
d
m
)
a ≡ b(mod m )
a≡b(modm) 的充分条件是
a
=
m
×
t
+
b
a= m × t + b
a=m×t+b ( t为整数)。
更多推论定理相关链接:同余定理
根据同余定理有:
(
x
+
m
o
d
)
%
m
o
d
=
(
x
%
m
o
d
)
+
(
m
o
d
%
m
o
d
)
=
x
%
m
o
d
(x + mod) \% mod = (x \% mod) + (mod \% mod) = x \% mod
(x+mod)%mod=(x%mod)+(mod%mod)=x%mod
若
(
a
−
b
)
÷
m
=
k
…
…
0
(a - b)÷m = k…… 0
(a−b)÷m=k……0,则有,
a
%
m
=
=
b
%
m
a \% m == b \% m
a%m==b%m。证明如下:
(
a
−
b
)
÷
m
=
k
=
>
(
a
−
b
)
=
m
×
k
=
>
a
=
m
×
k
+
b
(a - b)÷m = k => (a - b) = m×k => a = m×k + b
(a−b)÷m=k=>(a−b)=m×k=>a=m×k+b,等式两侧对m取模,得:
a
%
m
=
(
m
×
k
+
b
)
%
m
a \%m =( m×k + b)\%m
a%m=(m×k+b)%m,由
于
m
×
k
%
m
=
0
于m×k \%m =0
于m×k%m=0,因此有
a
%
m
=
b
%
m
a \%m = b\%m
a%m=b%m。
C99标准中,取模运算规律如下:取模运算结果的正负是由左操作数的正负决定的。 如果%左操作数是正数,那么取模运算的结果是非负数;如果%左操作数是负数,那么取模运算的结果是负数或0。
5 % 2 = 1
5 % -2 = 1
-5 % 2 = -1
-5 % -2 = -1
由于此题解法思想和上题相同,需要借助于哈希表,而-10^4 <= nums[i] <= 10^4,那么数组某一段区间(子数组)累加结果可能为负数,为了统一,这里我们需要将负数的取模的结果修正为整数:
1、要知道一个结论,无论正数还是负数,取模后的绝对值一定是 < mod的,即 | ± x % mod | < mod。
2、而同余定理告诉我们:
(
x
+
m
o
d
)
%
m
o
d
=
(
x
%
m
o
d
)
+
(
m
o
d
%
m
o
d
)
=
x
%
m
o
d
(x + mod) \% mod = (x \% mod) + (mod \% mod) = x \% mod
(x+mod)%mod=(x%mod)+(mod%mod)=x%mod ,设 x= a % mod 因此:
①、
x
%
m
o
d
x \%mod
x%mod 是正数时,
x
%
m
o
d
+
m
o
d
x \%mod +mod
x%mod+mod 还是正数;
②、
x
%
m
o
d
x\%mod
x%mod 为负数时,
x
%
m
o
d
+
m
o
d
x \%mod +mod
x%mod+mod 就能将整个序列都变成正数,但是加一个
m
o
d
mod
mod 后有能数据大于
m
o
d
mod
mod,因此还要再
%
m
o
d
\% mod
%mod ,让最终结果落在
[
0
,
m
o
d
−
1
]
[0,mod-1]
[0,mod−1]内。
一句话总结为: [ ( x % m o d ) + m o d ] % m o d [(x\%mod)+mod] \% mod [(x%mod)+mod]%mod
2)、题解
class Solution {
public:
int subarraysDivByK(vector<int>& nums, int k) {
unordered_map<int,int> hash;//用于记录(0,j-1)的历史前缀和除K后的余数值及其个数
hash[0]=1;//用于处理特别情况:所有元素之和能被K整除时,余数remain=0,此时映射到hash[0]位置。
int sum = 0;//用于记录j位置处的前缀和
int ret = 0;//用于统计符合要求的子数组数目
for(auto j : nums)
{
sum+=j;
int remain=(sum%k+k)%k;//记录当前元素和的余数
if(hash.count(remain)) ret+=hash[remain];
hash[remain]++;
}
return ret;
}
};
8、连续数组(medium)
题源:链接

8.1、题解
1)、思路分析
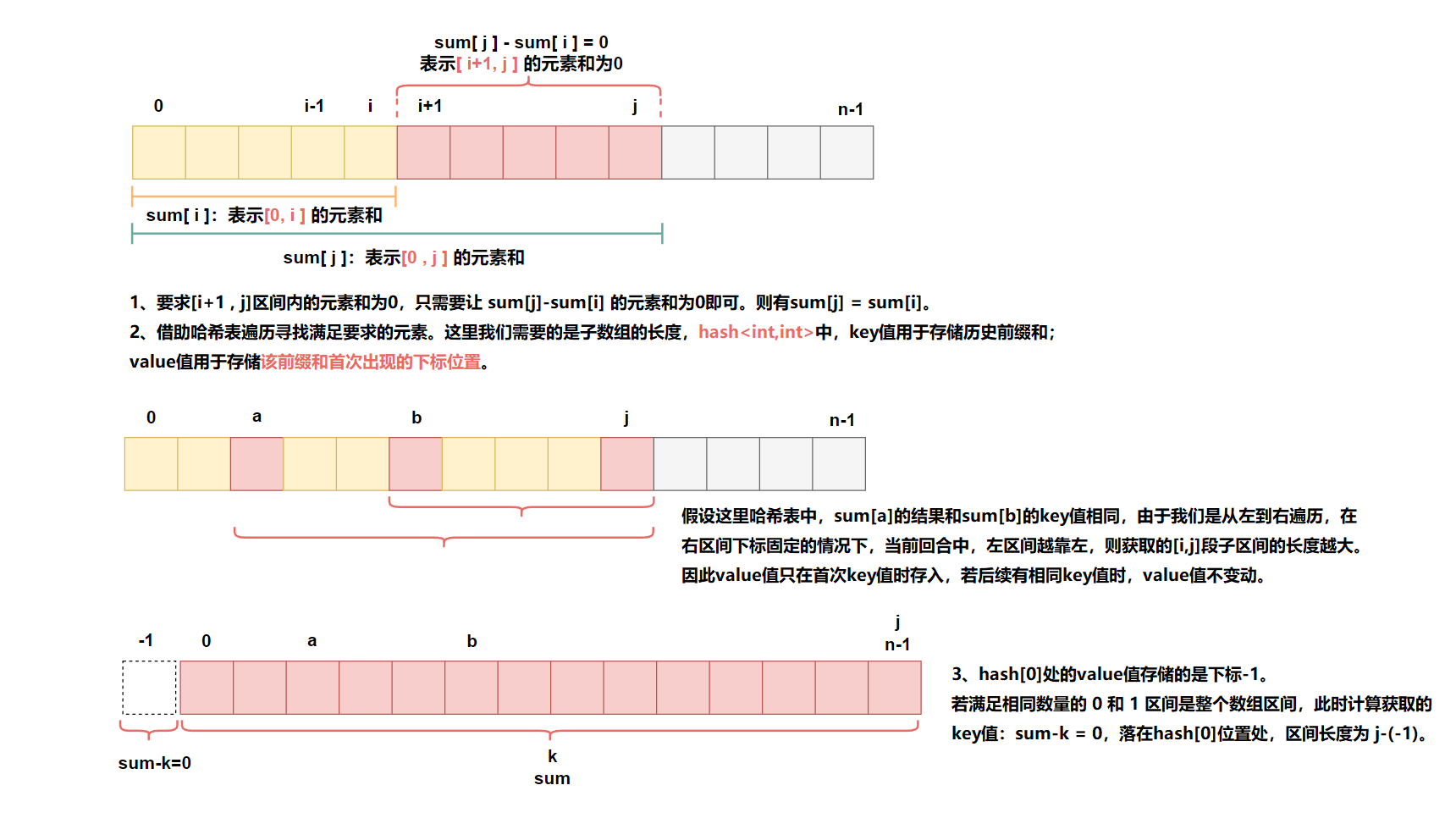
题目要求我们找出⼀段连续的区间,使得 0 和 1 出现的次数相同。让我们稍微做一点转变,若将 0 记为 -1 , 1 记为 1 ,问题就变成了找出⼀段区间,使得这段区间的元素和等于 0 。 思想就与和为K的子数组相同。
2)、题解
class Solution {
public:
int findMaxLength(vector<int>& nums) {
unordered_map<int, int> hash; // 哈希表,一个存sum-k值,一个存下标
hash[0] = -1;//由于获取的是[i,j]长度,因此,这里存储的应该是-1下标位置
int sum = 0;
int maxlen = 0;//maxlen获取当前回合最长的长度
for (int j = 0; j < nums.size(); ++j) {
if (nums[j] == 0) //要对sum内元素做修正:若为1则不变,0则存入-1。
sum += -1;
else
sum += 1;
if (hash.count(sum))
maxlen = max(j - hash[sum], maxlen);//不同回合所获取到的下标长度可能不同,需要比较
else
hash[sum] = j;//首次,则插入
}
return maxlen;
}
};
9、矩阵区域和(medium)
题源:链接

9.1、题解
1)、思路分析
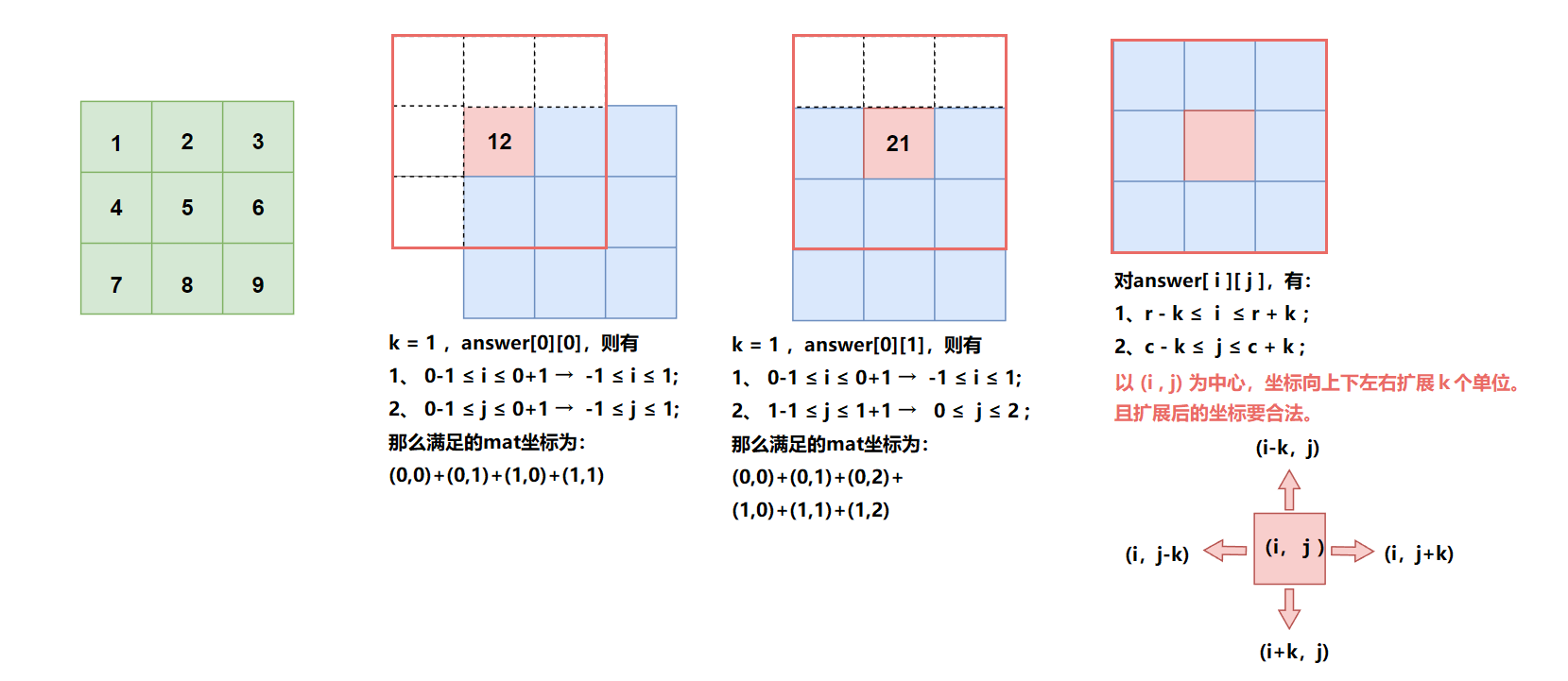
先理解题目意思:
再来看看二维数组前缀和如何应用到本题中:
2)、题解
class Solution {
public:
vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k) {
int m = mat.size(); // 行数
int n = mat[1].size(); // 列数
// 1、获取前缀和数组(以1,1为起始位置,注意修正)
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
//int[][] dp = new int[m + 1][n + 1]; //也可以在堆区开辟
for (int i = 1; i <= m; ++i) {
for (int j = 1; j <= n; ++j)
dp[i][j] = dp[i - 1][j] + dp[i][j - 1] + mat[i - 1][j - 1] -dp[i - 1][j - 1];
}
// 2、获取answer数组
vector<vector<int>> answer(m, vector<int>(n));
//int[][] answer = new int[m][n];
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j)
{
int x1 = max(0,i-k)+1, x2 = min(i+k,m-1)+1;
int y1 = max(0,j-k)+1, y2 = min(j+k,n-1)+1;
answer[i][j] = dp[x2][y2] - dp[x1-1][y2] - dp[x2][y1-1] + dp[x1-1][y1-1];
}
}
return answer;
}
};
Fin、共勉。
















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









