







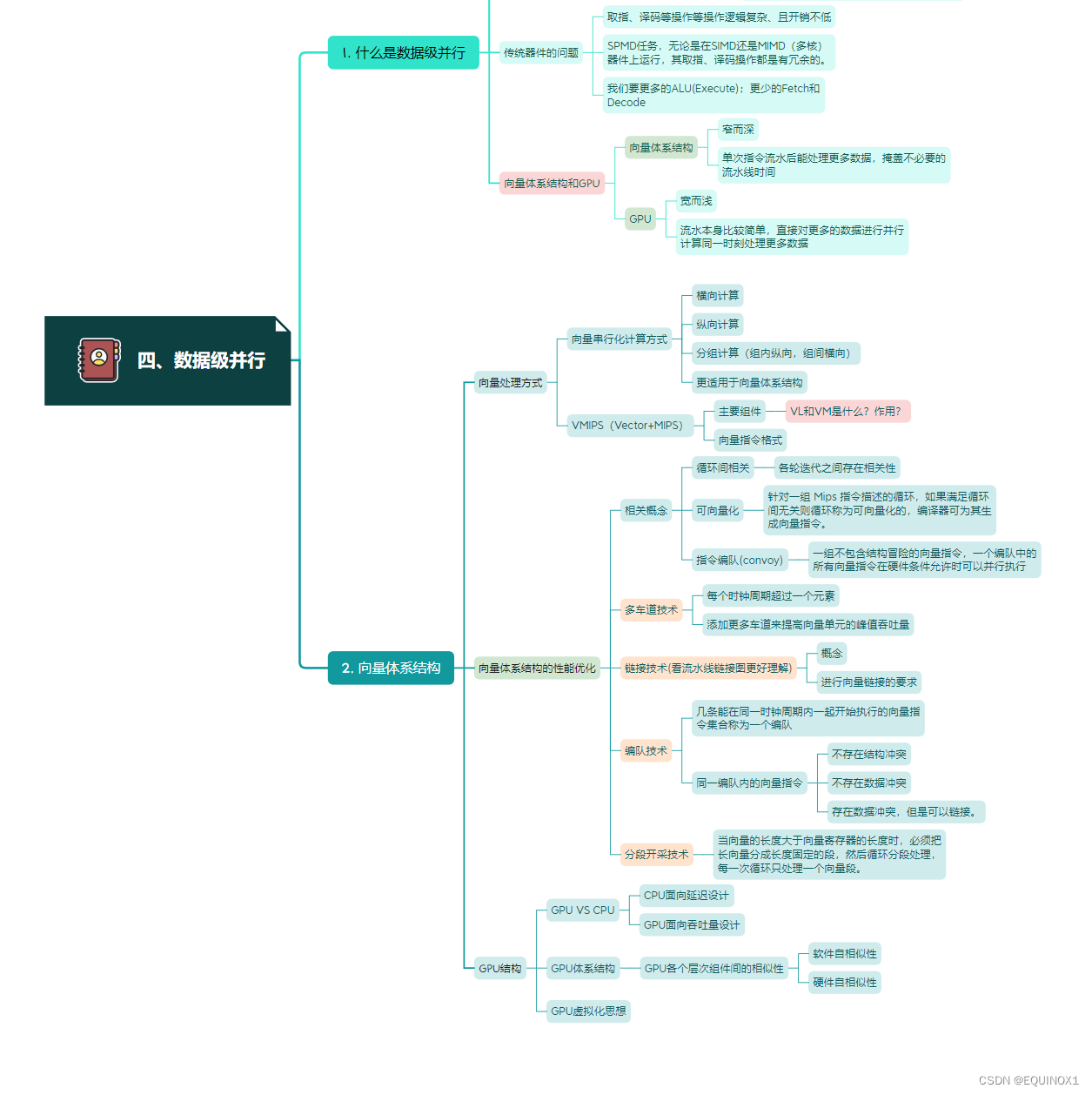
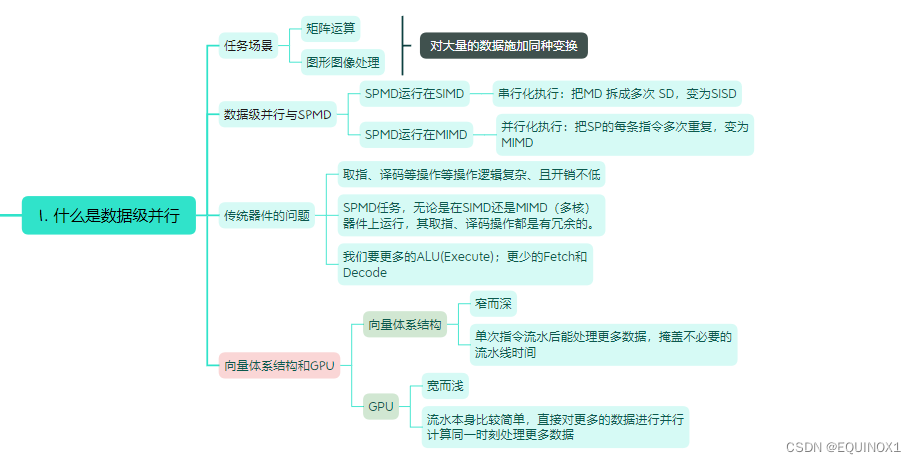
一、什么是数据级并行?
1.1 数据级并行的任务场景
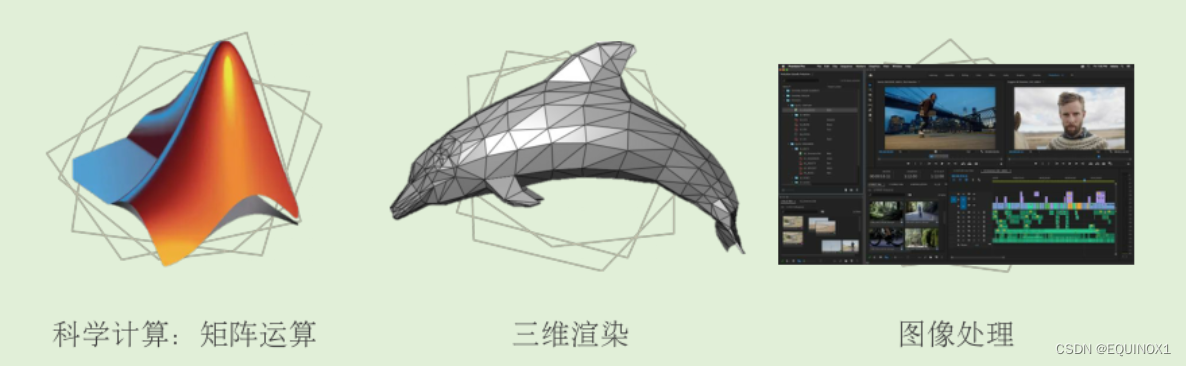
无论是矩阵运算还是图形图像处理,其共性是对大量的数据施加同种变换——数据级并行(DLP)
从软件的角度,在编程模型上,我们期待SPMD(Single Program Multiple Data)
1.2 数据级并行与SPMD
思考:一个SPMD程序如何运行在SIMD(或MIMD)上?
SIMD:
单核、单线程,串行化执行:把MD 拆成多次 SD,变为SISD
缺点很明显,就是耗时

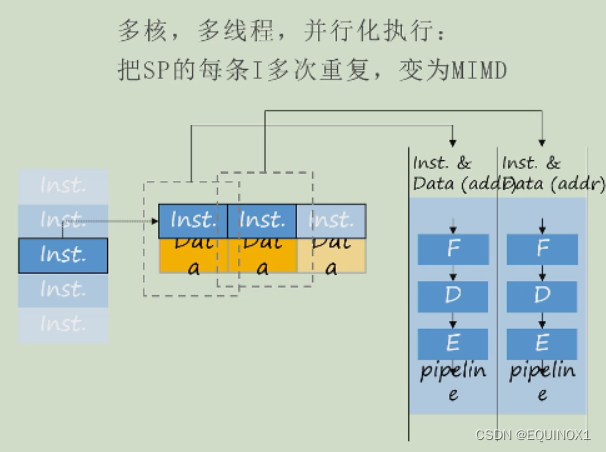
MIMD:
多核,多线程,并行化执行:把SP的每条指令多次重复,变为MIMD
缺点:耗电
下面是ARM A53架构示意图:
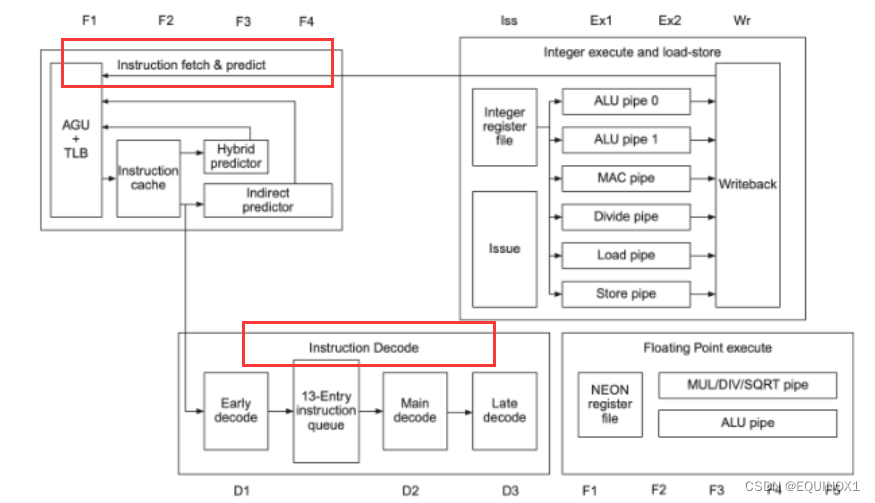
我们可以看到红框中的取指、译码部分。
无论是单核还是多核,都避免不了取指、译码的复杂逻辑。
1.3 传统器件的问题
分析传统的标量CPU流水线可知,取指、译码等操作等操作逻辑复杂、且开销不低。
对于SPMD任务,无论是在SIMD还是MIMD(多核)器件上运行,其取指、译码操作都是有冗余的。
那么对于SPMD场景,如何设计一种新型的器件?
对于SIMD器件,我们要更多的ALU(Execute);更少的Fetch和Decode
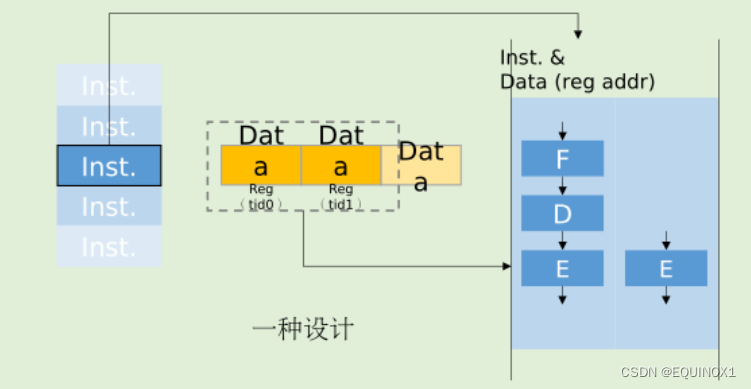
然而更少的Fetch 和 Decode (甚至其他流水部件)意味着什么?
更少的器件,更低的能耗和时间开销。
更多的ALU意味着什么?
一次流水能处理更多数据,速度更快。
我们还可以增加数据存储器的数量来一次存储更多数据,以减少存储器访问延迟。
1.4 向量体系结构和GPU
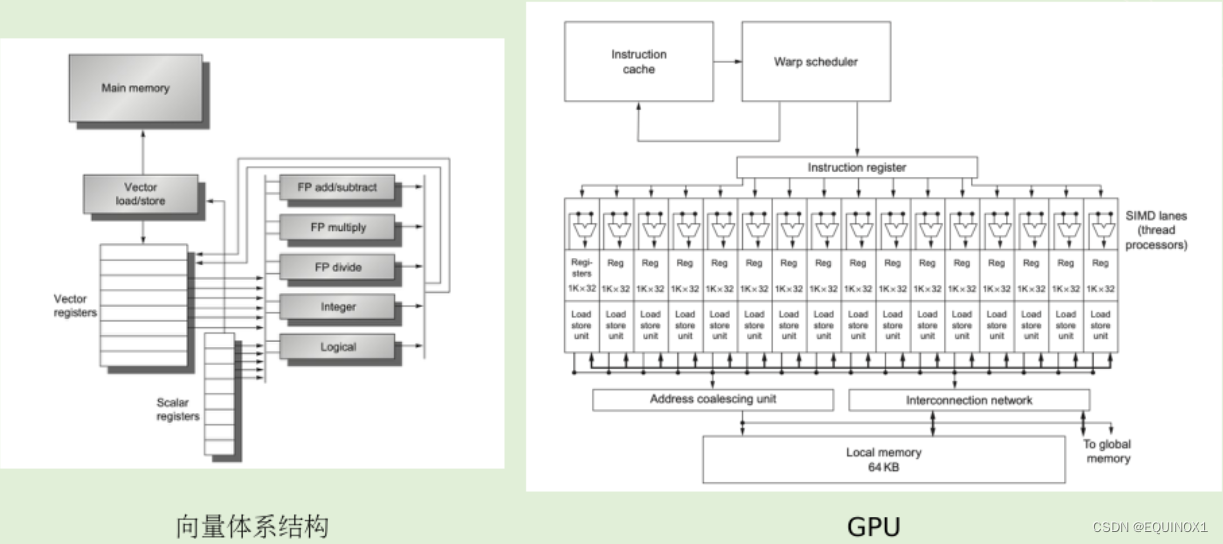
向量体系结构
- “窄而深”
- 指令流水线深, ALU 宽度窄
- 单次指令流水后能处理更多数据,掩盖不必要的流水线时间
GPU
- “宽而浅”
- 指令流水线浅, ALU 宽度宽
- 流水本身比较简单,直接对更多的数据进行并行计算同一时刻处理更多数据
二、向量体系结构
2.1 向量处理方式
2.1.1 向量
**向量(Vector)**由一组有序、具有相同类型和位数的元素组成。
在流水线处理机中,设置向量数据表示和相应的向量指令,称为向量处理机。
不具有向量数据表示和相应的向量指令的流水线处理机,称为标量处理机。
2.1.2 向量运算
以向量x、y为例
x
=
(
1
2
3
)
y
=
(
4
5
6
)
x = \begin{pmatrix} 1 \\ 2 \\ 3 \end{pmatrix}\ \ \ y = \begin{pmatrix} 4 \\ 5 \\ 6 \end{pmatrix}
x=
123
y=
456
向量加法:
x
+
y
=
(
5
7
9
)
x + y = \begin{pmatrix} 5 \\ 7 \\ 9 \end{pmatrix}
x+y=
579
标量乘法:
3
⋅
x
=
(
3
6
9
)
3 · x = \begin{pmatrix} 3 \\ 6 \\ 9 \end{pmatrix}
3⋅x=
369
向量(点)乘法:
x
⋅
y
=
1
∗
4
+
2
∗
5
+
3
∗
6
=
32
x · y = 1 * 4 + 2 * 5 + 3 * 6 = 32
x⋅y=1∗4+2∗5+3∗6=32
向量这种数据结构,以及向量的运算,和我们对 SIMD 的期待不谋而合。
2.1.3 向量的串行化计算方式
下面都以表达式:D = A * (B + C)为例,A、B、C、D都是长度为 N 的向量
2.1.3.1 横向(水平)处理方式
向量计算是按行的方式从左到右横向地进行。
- 先计算:d1 <- a1 * (b1 + c1)
- 再计算:d2 <- a2 * (b2 + c2)
- ……
- 最后计算:dn <- an * (bn + cn)
组成循环程序进行处理。
- qi <- bi + ci
- di <- qi * ai
数据相关:N次 功能切换:2N次
这种计算方式是在标量处理器上对向量的一般计算方式,不适合于向量处理机的并行处理。
2.1.3.2 纵向(垂直)处理方式
向量计算是按列的方式从上到下纵向地进行。
- 先计算:ki = bi + ci
- 再计算:di = ki * ai
表示成向量指令:
K
=
B
+
C
D
=
K
∗
A
K = B + C \\ D = K * A
K=B+CD=K∗A
这样就变成了两条向量指令。
数据相关:1次 功能切换:1次
2.1.3.3 纵横(分组)处理方式
- 对于纵向计算方式已经优化了硬件开销,但是每次计算都需要访问到的向量中的全部元素。
- 考虑到当前计算机体系结构的存储结构往往是层次化的,指令操作数一般都会加载到寄存其中,而寄存器的数量一般不会太多(相比于可以无限增长的向量长度N来说)
缝合结合前面两种计算方式,我们可以使用分组计算方式
纵横(分组)处理:
- 把向量分成若干组,组内按纵向方式处理,组间按横向方式处理
- 对于上述的例子,设:N = S * n + r
- 其中 N 为向量长度,S为组数,n为每组的长度,r为余数
- 余下的r个数成一组,则共有s + 1组
计算流程:
-
先算第一组
- Q1~n <- B1~n + C1~n
- D1~n <- Q1~n * A1~n
-
再算第二组
-
Q(n + 1) ~ 2n <- B(n + 1) ~n + C(n + 1) ~ 2n
-
D(n + 1) ~ 2n <- Q(n + 1) ~ 2n * A(n + 1) ~ 2n
-
-
依次执行下去,直到第s + 1组
-
每组内各用两条向量指令,每组内 数据相关:1次,功能切换:2次
2.1.3.4 串行化向量计算优化方式与向量体系结构
- 根据刚刚探讨的串行化向量计算优化方式,我们得到一种更适用于向量处理的体系结构
- 向量体系结构应当具有很大的顺序寄存器堆(Register File),可加载更多向量元素以支持纵向计算
- 向量体系结构从内存中收集散落的数据,将其放入寄存器堆中,并对寄存器堆中的数据们进行操作,然后将这些结果放回内存(一次传输一组数据,LD/ST流水化)
- 一条指令能够对一个向量的数据进行操作,也就对向量中诸多独立数据元素进行了操作(纵向计算,功能单元流水化)
那么向量体系结构有何优势呢?
- 由于向量的load 和 store 是深度流水线化的,大型寄存器堆充当了Buffer的作用,因此其能够掩盖访存延迟并充分利用内存带宽
- 乱序的超标量处理器往往具有复杂的设计,且乱序程度越高,其复杂性和功耗也会越高,在此方向发展很容易触及 Power Wall
- 将顺序的标量处理器扩展为向量处理器则不会带来复杂性和功耗的大幅度升高,且开发者也能很容易适应和切换到向量指令
2.1.4 VIMPS

如上图为一个向量处理器,这种指令集体系结构我们称为VMIPS(Vector + MIPS)。它的标量部分为MIPS,向量部分是MIPS的逻辑向量扩展。事实上,VMIPS是基于CRAY-1基本结构的,这里不做多解释,只给出其基本结构图

2.1.4.1 VIMS的主要组件
上图中的主要组件说明如下:
-
向量寄存器——每个向量寄存器都是一个固定长度的寄存器组,保存一个向量。
- 8个向量寄存器,每个向量寄存器保存64个单元,每个单元为64位
- 足够多的读写端口——至少16个读取端口和8个写入端口
-
向量功能单元
- 每个单元都完全实现流水化,可以在每个时钟周期开始一个新的操作。
- 需要一个控制单元来检测结构冒险和数据冒险
-
向量载入/存储单元——从存储器中载入向量或者将向量存储到存储器中
- 向量载入和存储操作完全流水化,初始延迟后,每时钟周期一个字
-
标量寄存器集合
- 可以提供数据,作为向量功能单元的输入,也可以为load/store单元提供地址
- 通常是MIPS的32个通用寄存器和32个浮点寄存器,可存地址和数据
有两个上图中无法展示出的两个通用寄存器:向量长度寄存器VL和向量屏蔽寄存器VM
- 向量长度寄存器VL
- 64位,每一位对应于向量寄存器的一个单元
- VL控制所有向量运算的长度,包括ld/st
- 作用:将软件层程序中实际向量长度N与硬件层向量寄存器中的元素数目64相适配
- 向量屏蔽寄存器VM
- 64位,每一位对应于向量寄存器的一个单元
- 作用:用于向量的归并、压缩、还原和测试操作,当向量长度小于 64 时,或者条件语句控制下对向量某些元素的单独运算等
- 即使makscode中有大量的0,使用VM的向量指令速度依然远远快于标量计算模式
2.1.4.2 VMIPS向量指令格式
VMIPS指令 = MIPS指令 + OP1类型 + OP2类型 . 精度
例如:
- mips:add . d
- vmips:addvv.d(V1, V2, V3),addvs.d(V1,V2,F0)
下面是VMIPS 和 MIPS的代码对比示例:
VIMPS:
L.D F0, a //载入a
LV V1, Rx //载入X
MULVS.D V2, V1, FO //a * X
LV V3, Ry //载入Y
ADDVV.D V4, V2, V3 //+Y
SV V4, Ry //存入Y
---
MIPS:
L.D F0, a //载入标量
DADDIU R4, Rx, #512 //载入最后地址
LOOP:L.D F2, 0(Rx) //载入 X[i]
MUL.D F2, F2, FO //a x X[i]
L.D F4, 0(Ry) //载入 Y[i]
ADD.D F4, F4, F2 //载入 ax X[i] + Y[i]
S.D F4, 0(Ry) //存入 Y[i]
DADDIU Rx, Rx, #8 //递増 X
DADDIU Ry, Ry, #8 //递増 Y
DSUBU R20, R4, Rx //计算范围
BNEZ R20, LOOP //检查是否完成
相较于冗长的MIPS,VMIPS简直是太简洁优雅了。然而这背后不仅是代码的减少,还有更少的取指、译码。
2.2 向量体系结构的性能优化
2.2.1 相关概念
- 循环间相关:对一个循环来说,如果各轮迭代之间存在相关性,则称为循环间相关,否则为循环间无关
- 可向量化:针对一组 Mips 指令描述的循环,如果满足循环间无关则循环称为可向量化的,编译器可为其生成向量指令。
- 指令编队(convoy):由一组不包含结构冒险的向量指令组成,一个编队中的所有向量指令在硬件条件允许时可以并行执行。
2.2.2 多车道技术:每个时钟周期超过一个元素
之前讨论的是向量计算在串行化时尽可能进行优化的结果。
VMIPS指令集有一个特性:所有向量算术指令只允许一个向量寄存器的元素 N 与其他向量寄存器的元素 N 进行运算。这一特性极大地简化了一个高度并行向量单元的构造,将其结构设定为多个并行车道。
和高速公路一样,我们可以通过添加更多车道来提高向量单元的峰值吞吐量。如下图,从单车道变为四车道之后,将一次钟鸣的时钟周期数由 64个变为16个。

2.2.3 链接技术
我们来看两条向量指令占用功能流水线和向量寄存器的4种情况:
- 指令不相关
- V0 = V1 + V2
- V6 = V4 * V5
- 二者分别使用各自所需流水线和向量寄存器,可以并行执行
- 功能部件冲突
- V3 = V1 + V2
- V6 = V4 + V5
- 两条指令都需要使用加法流水线,发生了功能部件冲突(但是向量寄存器不冲突)。当第一条指令流出时,占用加法流水线。第二条指令要等加法流水线变成空闲后,才能流出。
- 源寄存器冲突
- V3 = V1 + V2
- V6 = V1 * V4
- 这两条向量指令的源向量之一都取自V1。由于两者的首元素下标可能不同,向量长度也可能不同,所以难以由V1同时提供两条指令所需要的源向量。
- 这两条向量指令不能同时执行。只有等第一条向量指令执行完、释放V1之后,第二条向量指令才能开始执行。
- 结果寄存器冲突
- 两条向量指令使用了相同的结果向量寄存器
- V4 = V1 + V2
- V4 = V3 * V5
- 这两个指令都要访问目的寄存器V4。由于第一条指令在先,所以它先占用V4直到运算完成,然后再流出后一条指令。
讲了这么多,什么是链接技术呢?
**向量流水线链接:**具有先写后读相关的两条指令,在不出现功能部件冲突和源向量冲突的情况下,可以把功能部件链接起来进行流水处理,以达到加快执行的目的。
例如:V3 = V1 + V2,V6 = V3 * V4,这两条指令就可以用链接技术优化
例1:考虑在Cray-1上利用链接技术执行以下4条指令:
V0 <- 存储器 //访存取向量:7拍
V2 <- V0 + V1 //向量加:3拍
V3 <- V2 < A3 //按(A3)左移:4拍
V5 <- V3 & V4 //与操作:2拍
画出链接示意图,并求该链接流水线的通过时间。如果向量长度为64,则需要多少拍才能得到全部结果。
分析:部件冲突:无 寄存器冲突:无 写后读:两两相邻都有
因而可以把访存流水线、向量加流水线、向量移位流水线以及向量逻辑运算流水线链接成一个较长的流水线。

至少需要:a + b + c + d + e + f + g + h + i + j + k + l,各字母含义如下:
a:存储字到“读功能部件”的传送时间
b:存储字经过“读功能部件”的通过时间
c:存储字从“读功能部件”到V0分量的传送时间
d:V0和V1中操作数到整数加功能部件的传送时间
e:整数加功能部件的通过时间
f:和从整数加功能部件到V2分量的传送时间
g:V2中的操作数分量到移位功能部件的传送时间
h:移位功能部件的通过时间
i:结果从移位功能部件到V3分量的传送时间
j:V3和V4中的操作数分量到逻辑部件的传送时间
k:逻辑功能部件的通过时间
l:最后结果到V5分量的传送时间
例2 在CRAY-1上用链接技术进行向量运算D = A * (B + C)
假设向量长度N <= 64,向量元素为浮点数,且向量B、C已存放在V0和V1中。画出链接示意图,并分析非链接执行和链接执行两种情况下的执行时间。
假设功能单元的时间开销为:浮点加减(6 cycle),浮点乘法(7 cycle),浮点存储操作(6 cycle)。为了同步要求,将向量元素送往功能部件,以及把结果存入向量寄存器需要一拍时间,从存储器中把数据送入访存功能部件也需要一拍时间。
翻译成向量指令先:
V3 <- 存储器 //访存取向量A
V2 <- V0 + V1 //向量B和向量C进行浮点加
V4 <- V2 * V3 //浮点乘,结果存入V4

三条指令全部串行,执行时间:
1 + 6 + 1 + N - 1 + 1 + 6 + 1 + N - 1 + 7 + 1 + N - 1 = 3N + 22
前两条指令并行执行,然后再串行执行第3条指令,则执行时间为:
1 + 6 + 1 + N - 1 + 1 + 7 + 1 + N - 1 = 2N + 15
1、2并行并且与第3条链接执行:
1 + 6 + 1 + 1 + 7 + 1 + N - 1 = N + 16
进行向量链接的要求
保证:无向量寄存器使用冲突和无功能部件使用冲突。
- 只有在前一条指令的第一个结果元素送入结果向量寄存器的那一个时钟周期才可以进行链接。
- 当一条向量指令的两个源操作数分别是两条先行指令的结果寄存器时,要求先行的两条指令产生运算结果的时间必须相等,即要求有关功能部件的通过时间相等。
- 要进行链接执行的向量指令的向量长度必须相等,否则无法进行链接。
2.2.4 编队技术
对于一组向量指令而言,其执行时间主要取决于三个因素:
- 向量的长度
- 向量操作之间是否存在流水功能部件的使用冲突
- 数据的相关性
几条能在同一时钟周期内一起开始执行的向量指令集合称为一个编队。
同一个编队中的向量指令之间
- 不存在结构冲突
- 不存在数据冲突
- 存在数据冲突,但是可以链接。
使用编队技术后,向量指令序列的总的执行时间为各编队的执行时间的和。
T
a
l
l
=
∑
i
=
1
m
T
v
p
(
i
)
,
其中
T
v
p
(
i
)
代表第
i
个编队的执行时间,
m
为编队个数
T_{all} = \sum_{i=1}^{m}T_{vp}^{(i)},其中T_{vp}^{(i)}代表第i个编队的执行时间,m为编队个数
Tall=i=1∑mTvp(i),其中Tvp(i)代表第i个编队的执行时间,m为编队个数
当一个编队由若干条指令组成,则其执行时间就该由编队中各指令的执行时间的最大值来确定
T
a
l
l
=
∑
i
=
1
m
T
v
p
(
i
)
=
∑
i
=
1
m
(
T
s
t
a
r
t
(
i
)
+
n
)
T
c
=
(
(
∑
i
=
1
m
T
s
t
a
r
t
(
i
)
)
+
m
n
)
T
c
=
(
T
s
t
a
r
t
+
m
n
)
T
c
T
c
为流水线时钟周期,
T
s
t
a
r
t
=
∑
i
=
1
m
T
s
t
a
r
t
(
i
)
为所有编队流水线启动时钟周期个数之和
\begin{align} T_{all} &= \sum_{i=1}^{m}T_{vp}^{(i)} \\ &= \sum_{i=1}^{m}(T_{start}^{(i)} + n)T_{c} \\ &= ((\sum_{i=1}^{m}T_{start}^{(i)}) + mn)T_{c} \\ &= (T_{start} + mn)T_{c} \\ &Tc为流水线时钟周期,T_{start} = \sum_{i=1}^{m}T_{start}^{(i)}为所有编队流水线启动时钟周期个数之和 \end{align}
Tall=i=1∑mTvp(i)=i=1∑m(Tstart(i)+n)Tc=((i=1∑mTstart(i))+mn)Tc=(Tstart+mn)TcTc为流水线时钟周期,Tstart=i=1∑mTstart(i)为所有编队流水线启动时钟周期个数之和
例:假设每种向量功能部件只有一个,那么下面的一组向量指令,在不使用链接技术和使用链接技术的情况下如何编队?
LV V1,Rx // 取向量x
MULTSV V2,R0,V1 // 向量x和标量(R0)相乘
LV V3,Ry // 取向量y
ADDV V4,V2,V3 // 相加,结果保存到V4中
SV Ry,V4 // 存结果
不使用链接技术:
- 第一编队:LV
- 第二编队:MULTISV LV
- 第三编队:ADDV
- 第四编队:SV
使用链接技术:
- 第一编队:LV MULTISV
- 第二编队:LV ADDV
- 第三编队:SV
2.2.5 分段开采技术
如果向量的长度大于向量寄存器的长度,该如何处理呢?
- 当向量的长度大于向量寄存器的长度时,必须把长向量分成长度固定的段,然后循环分段处理,每一次循环只处理一个向量段。
- 这种技术称为分段开采技术。
- 由系统硬件和软件控制完成,对程序员是透明的
思想还是比较简单的。
2.2.6 向量体系结构的性能影响因素
- 操作数向量的长度
- 向量启动时间
- 操作之间的数据相关,是否采用链接
- 操作之间的结构性相关,发射限制,车道数量,是否采用编队
2.3 GPU结构
2.3.1 GPU概述
-
GPU:Graphics Processing Unit,图形处理器
- 具有极高的计算吞吐率和内存带宽
- 专用图形图像处理器
- 适合纹理图像处理器
-
GPGPU:General-purpose computing on GPUs,通用图形处理器

- 利用GPU能力来执行传统上由中央处理器(CPU)完成的计算任务
- 可编程:例如CUDA,OpenGL
- 适合处理SIMD程序
GPU
-
GPU并行计算,GPU不是独立运行计算平台,需要与CPU协同工作,是CPU的协处理器
-
GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为主机端(host),GPU所在位置称为设备端(device)
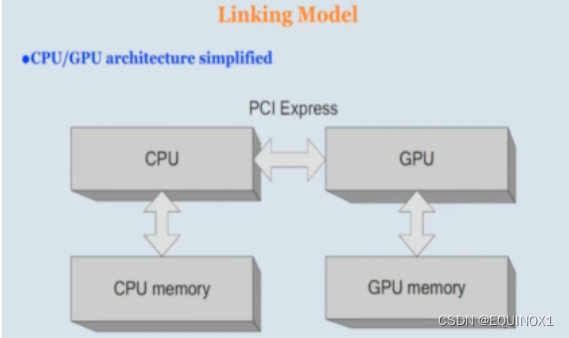
-
数据中心、超算中心的标配。
-
应用:深度学习、大数据、石油化工、传媒娱乐、科学研究等行业
CUDA的历史(CUDA:Compute Unified Device Architecture)
- GPU 比CPU 更强的计算能力,希望GPU应用到通用科学计算上,即GPGPU。
- GPGPU:早期,直接使用图形学的API,将计算任务映射成纹理的染过程
- 使用汇编或者高级着色器语言C9,HLSL等编程
- 通过图形学API执行(Direct3D和OpenGL)
- 开发难度较大,难以优化,对开发人员的要求非常高
- 传统的GPGPU 计算并没有广泛应用。
- 2007年6月,NVIDIA 推出CUDA
- CUDA 不需要借助图形学API,采用类C语言进行开发。
- CUDA 采用统一处理架构,降低了编程的难度使得NVIDIA 相比AMD/ATI后来居上。
- 相比AMD 的GPU,NVIDIA GPU 引入了片内共享存储器,提高了效率
- 早前:图形处理架构,计算资源划分为顶点着色器和像素着色器。CUDA 架构包含一个统一的着色器流水线。新的图形处理器适用通用计算,不仅限于图形计算。
- 现在:用户无需了解 OpenGL或者 DirectX 图形编程结构,无需要将通用计算问题转换成图形计算问题。
- CUDA 优势:
- 给程序员提供了一个类似C语言的编程环境,它以C语言为基础,表达 NVIDIA 的GPU 模型。
- 通过 CUDA,使用C语言方便地写出在 NVIDIA 芯片上执行的程序,无需学习特定的显示芯片的指令或是特殊的结构。
- 随着深度学习的兴起,CUDA 被广大 AI从业者熟知。
CUDA编程

- CUDA编程模型是一个异构模型,需要CPU(host)和GPU(device)协同工作。
- 典型的CUDA程序的执行流程如下
- 分配host内存,并进行数据初始化
- 分配device内存,并从host将数据拷贝到device上
- 调用CUDA的核函数在device上完成指定的运算
- 将device上的运算结果拷贝到host上
- 释放device和host上分配的内存
Transistors Dedication
- Divergent Design Choices
- control logics v.s. arithmetic logics
- 多核 vs 众核:几个核 vs 上千个核,GPU将芯片中更多的晶体管用于计算

CPU VS GPU
绿色的是计算单元。橙红色的是存储单元。橙黄色的是控制单元。
从图看到,CPU和GPU均有自己的存储(橙红色部分,实际的存储体系比图示更为复杂),控制逻辑(橙黄色部分)和运算单元(绿色部分),但区别是CPU的控制逻辑更复杂,而GPU的运算单元虽然较小但是众多,GPU也可以提供更多的寄存器和程序员可控的多级存储资源。
CPU面向延迟设计:
- 强大的ALU,降低运算延迟
- 大量的cache,把长延迟内存访问转换为短延迟cache访问
- 复杂的控制逻辑,分支预测降低分支延迟,数据转发降低数据延迟

GPU面向吞吐量设计:
- 小型CACHE:提高内存吞吐量
- 简单控制:无分支预测,无数据转发
- 节能型ALU:多而长延迟,但具有高吞吐量的大量流水线
- 需要大量线程才能进行容错


-
Cache, local memory:CPU > GPU
-
Threads(线程数):GPU > CPU
-
Registers:GPU > CPU 多寄存器可以支持非常多的Thread,
-
thread需要用到register。thread数目大,register也必须得跟着很大才行。
-
SIMD Unit(单指令多数据流):GPU > CPU
-
使用CPU+GPU架构(异构)
-
为每项任务使用正确的处理器和内存
-
CPU擅长执行几个串行线程
- 快速顺序执行
- 低延迟缓存内存访问
-
GPU擅长执行许多并行线程
- 可伸缩并行执行
- 高带宽并行存储器存取
GPGPU的好处:
- 它使程序员不必熟悉图形API和GPU架构。
- 问题不需要用顶点坐标、纹理和着色器程序来表示,大大降低了程序的复杂性。
- 支持随机读写内存等基本编程功能,极大地发展了编程模型。
- 双精度支持了高性能的GPU上的科学应用。
2.3.2 GPU体系结构



上图展示了GPU架构
-
中间是二级Cache
-
整体划分为四个区,每个区是一个GPC,也就是Graphics processing cluster,图形处理集群
-
一个GPC中包含若干SM,也就是streaming multi-processor,流式多处理器
-
每个GPC的作用:把多个SM集中一起,便于管理。
-
每个GPC公用一个访存控制器
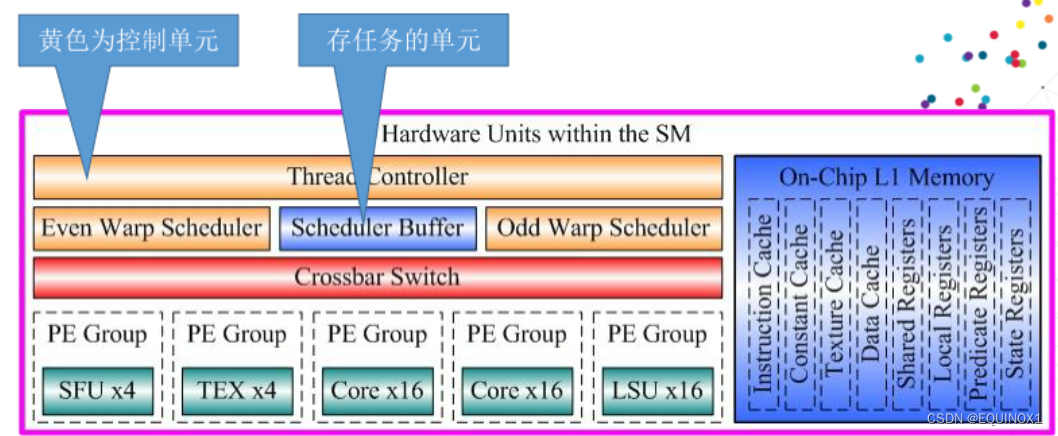
SM架构
- 运行CUDA内核的计算部件。
- 指令cache、数据cache。
- SM包含:
- 32个运算核心(cuda core)
- 16个LD / ST(load / store)模块;
- 4个SFU(Special function units)执行特殊数学运算(sin、cos、log等);
- 128KB寄存器
- 64KB L1缓存
- 全局内存缓存
- Tex纹理读取单元
- Texture Cache纹理缓存
- Poly Morph Engine多边形引擎负责属性装配(attribute Setup)、顶点拉取(VertexFetch)、曲面细分、栅格化(这个模块可以理解专门处理顶点相关的东西)
Warp Schedulers
- 这个模块负责warp(线程束)调度,一个warp由32个线程组成,warp调度器的指令通过Dispatch Units送到Core执行。
- 顺序分发指令给整个warp。
- 某些指令需要更长的时间完成(内存加载),warp调度器会简单地切换到另一个没有内存等待的warp,这是GPU克服内存读取延迟的关键,只是简单地切换活动线程组。为了使这种切换非常快,调度器管理的所有warp在寄存器文件中都有自己的寄存器。
- warp是典型的单指令多线程(SIMT:SIMD单指令多数据的升级)的实现,32个线程同时执行的指令流相同,但是线程数据不一样。
- 好处:一个warp只需要一个套逻辑对指令进行解码和执行,芯片可以做的更小更快。
- 原因:GPU处理的任务天然并行。
- 好处:一个warp只需要一个套逻辑对指令进行解码和执行,芯片可以做的更小更快。

GPU Level
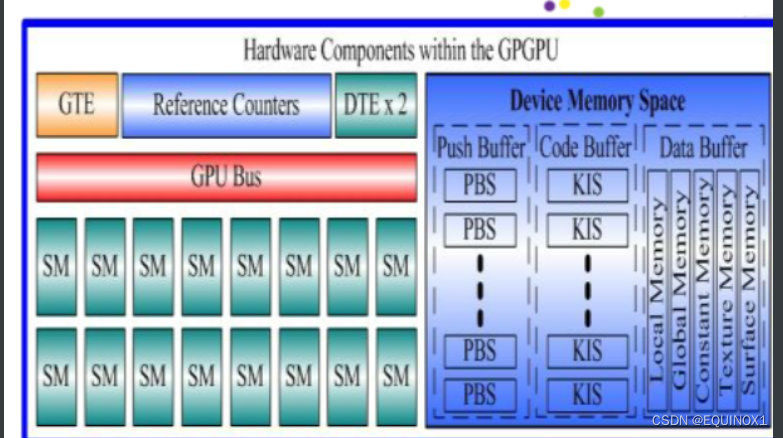
左侧是指令和数据的存储
- GTE. Giga Thread Engine,接受对GPU的调度,并根据内核创建任务实例。它是GPU的Control logic
- Reference counters,是任务的存储
- DTE,Data Transfer Engine,负责数据的传递
- GPU的总线和若干SM
右侧
- PBS,Push Buffer Streams,编译好的push buffer指令,用于驱动GTE和DTE进行GPU计算上下文准备
- KIS,Kernel指令流,编译好的kernel指令,用于驱动GPGPU内部各个运算部件实现计算。
- 数据存储器根据用途分了很多种类。
SM level
Memory Hierachy

GPU存储层次
-
寄存器(register file)
- 每个thread独有
-
共享内存(shared memory)
- 一个block共享,程序员控制
-
一级缓存(L1 Cache)
- 一个SM共享,硬件控制
-
二级缓存(L2 Cache)
- 所有SM共享,硬件控制
-
主存(main memory/DRAM)
- 所有SM共享,硬件控制
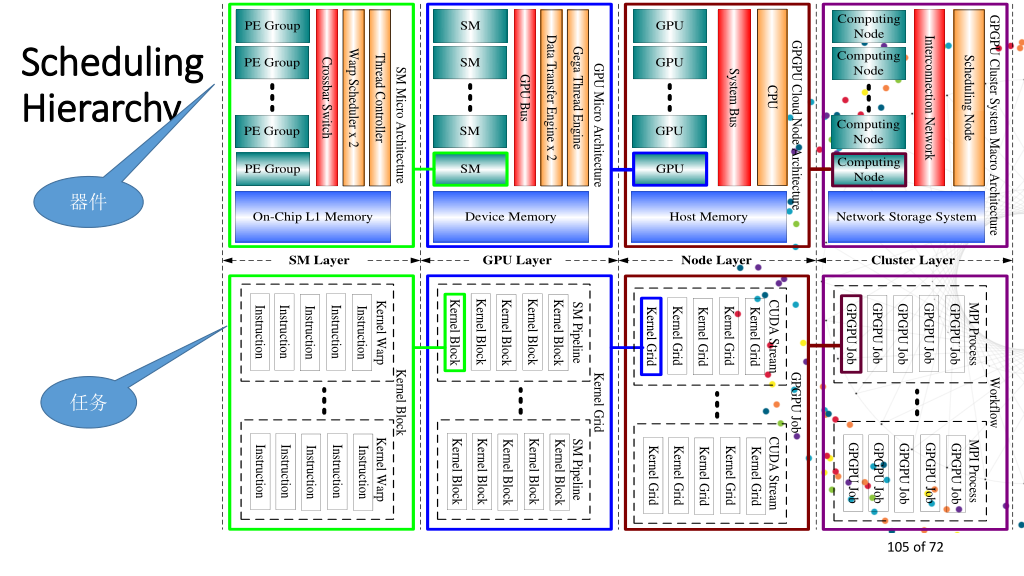
Software Self-similarity,软件自相似性

- 在任务的划分上,存在着自相似性
- 每一个第i级的任务,都可以划分为一组 i - 1 级的任务
- 并且同一级别的任务之间是并行的
Hardware Self-similarity,自相似性

- 在硬件上,同样也体现出了自相似性。
- 逐层的,都是相似的结构,包括调度器、任务的buffer、数据存储和处理单元。
科学计算三元组:
任务调度、数据供给、计算
Code Pattern
Malloc:全称是memoryallocation,中文叫动态内存分配,用于申请一块连续的指定大小的内存块区域
- Host Code Pattern(CPU端、调度、发命令)
- Malloc Host Memory(内存设置一个区域,存数据)
- Malloc Device Memory(显存找一个区域,下发数据)
- CUDA Memory Copy(H2D)(从内存copy到显存)
- Invoke Kernel Function(让GPU计算)
- CUDA Memory Copy(D2H)(从现存copy到内存)
- Device Code Pattern(GPU端)
- Locate Thread Index(缩写为TIDX)
- Compute(TIDX)
- 基于不同的TIDX,实现不同的线程的执行
Compile & Execute

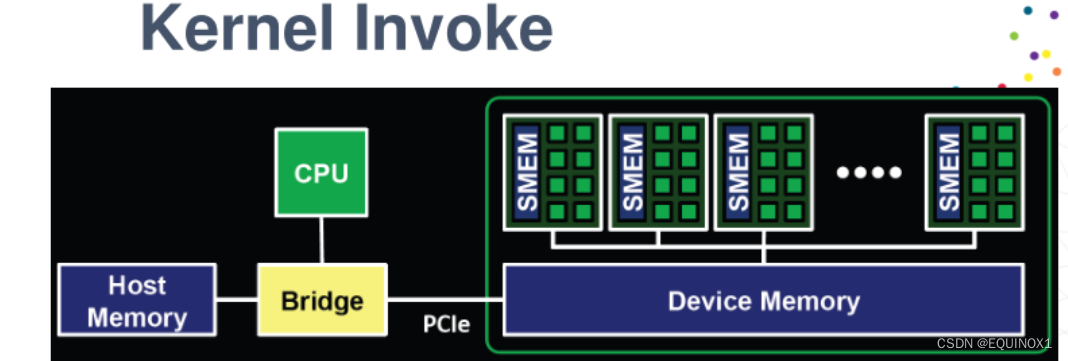
-
Malloc Host Memory Malloc主机内存
-
Malloc Device Memory Malloc设备存储器
-
CUDA Memory Copy(H2D) CUDA Memory Copy(H2D)
-
Invoke Kernel for execution 调用内核执行
-
CUDA Memory Copy(D2H) CUDA Memory Copy(D2H)
Pipeline Kernel lnvoke

流水内核调度:
多个Kernel可以实现流水。
CPU准备工作——实现从cpu到gpu的copy——GPU运算——GPU到CPU的copy
Macro Parallelism (kernel 之间的并行)

Computing Hierarchy

Thread Life Cycle
- Grid在GPU上启动
- Thread blocks顺序分配到SM’s
- 一般SM应有 > 1 thread block
- SM把线程组织为warps
- SM调度并执行就绪的warp
- Warps 和 thread blocks 执行结束后释放资源
- GPU继续分发thread blocks
SIMD/SIMT(cuda称为SIMT) Micro Parallelism(微并行:任务内部的并行)

SIMT Implementation(SlMT的硬件实现)
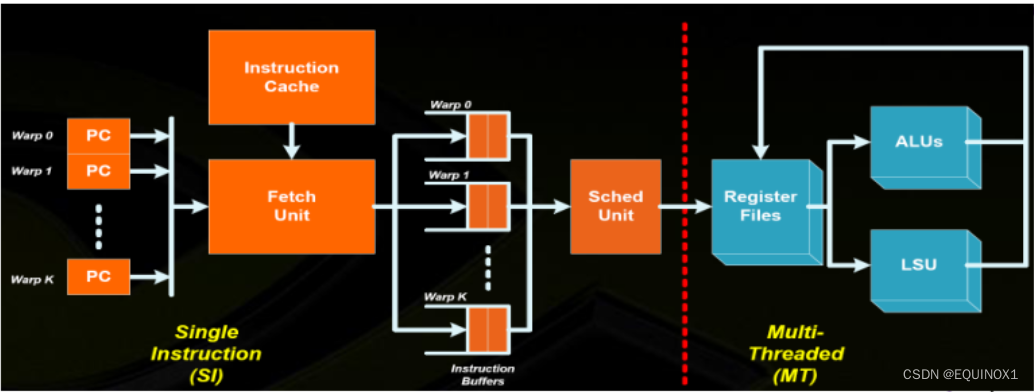
-
每个pc保留自己处理的kernel指令
-
通过pc到fetchunit中取指令
-
然后送进不同的车道(warp0在0车道(运算加法),warp1在1车道(运算load/store……)
-
通过调度单元获取操作数
-
操作数送到寄存器
-
ALU/LSU进行各类运算
Instruction Dispatch
指令队列是多列的
指令流出可以轮询或乱序的

一个warp内的32个线程执行相同指令流,但是操作的数据不同
- Warp(线程束)的划分是固定的:32个线程为一个Warp
- 一个block上定义了128个线程,0 - 31号线程一定会分配到warp1,32 - 63被分配到warp2,以此类推。
- 如果用户声明的线程数量不是32的整数倍,比如:一个block内有100个线程,那么就会有32 - (100 mod 32)个线程处于未激活状态,仍然会被分配到warp上。
- Warp在调度的时候没有太大规律,其调度不是按照顺序的。
- 只要有处于Ready Queue的warps,且当前的运算单元没被占用时,warp调度器就会调用Ready Queue的 warps 去执行指令直到warps都挂起。
- 所以,warp1并不是一定在 warps2 后执行。在编写程序的时候不依赖线程束调度顺序编写程序,使用_syncthreads() 控制线程的同步,不要自行判断线程执行的先后顺序。
GPU有发射概念。
指令和warp是绑定的,warp的执行步骤:
- 首先,warp scheduler会花一个时钟周期从指令缓存中取出下一条指令(load from L1 cache,store into cache buffer)
- warp scheduler作用:管理warp。每次warp切换时,warp scheduler会从位于就绪队列的warp中选择一个发射。会有一个计分板(score boarding)来实现这些功能,决定选择哪个warp。
- 导致warp处于stall 状态的因素很多:
- 最常见的就是Memory Dependency:global memory距离很远,每次取数都要花费很长时间。访问一次global memory大概需要等待200个时钟周期,在这段时间整个warp都必须进入stall状态
- cache miss 导致的延迟等
指令和warp是绑定的,warp的执行要经过如下步骤:
- 指令到达发射站后,根据自身内容选择合适的发射端口(dispatch port)
- 例如:整形数字会正常进入ALU;cos、sin等三角函数,发射到SFU,浮点数则进入FPU,等等
- 指令的发射存在不少瓶颈:
- warp stall
- 发射站:指令在发射站上等待,有的复杂函数指令可能还需要发射多次
- 功能部件阻塞,G80为例,一个SM上只有2块SFU,如果设计大量的三角函数就只能等待。
- warp在片上的切换时间基本可以忽略不计。
- CPU中,进行进程切换需要先保存上下文、处理好寄存器和程序执行信息。
- GPU上切换过程几乎不需要等待。原因是线程的寄存器都是私有的,寄存器只要分配到了某个线程,其生命周期与对应线程相同。所以位于片上的warp移至STALL状态后并不需要做中断和恢复。
Warps/Wavefront

举个例子,一条加法指令,实例化为16个线程(每个线程对应一个threadID,用这个ID关联数据),假如给这16个线程分了四个SP(就是一个SP group),每个SP上执行4个线程。轮询调度
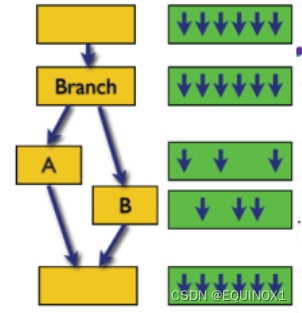
分支指令怎么办?
- 如果是CPU中,是预测一条路走,猜错了回去重新走
- GPU中,控制很简单,遇到分支指令了,AB分支同时走,确定哪个要哪个不要,不要的用屏蔽位过滤掉。
- lf和else都执行一遍,因为GPU计算能力强,ALU多。
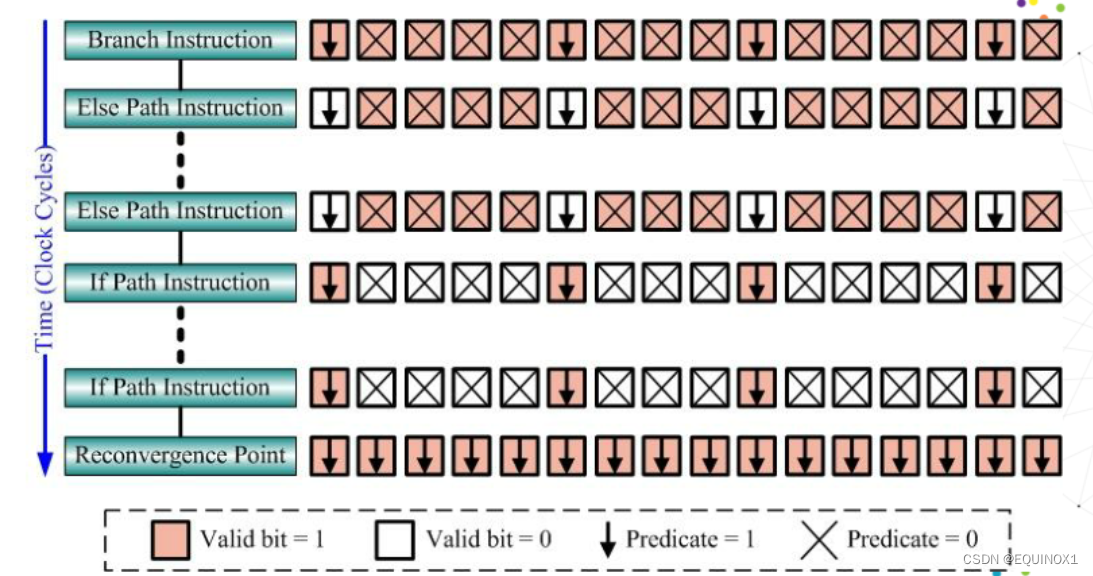
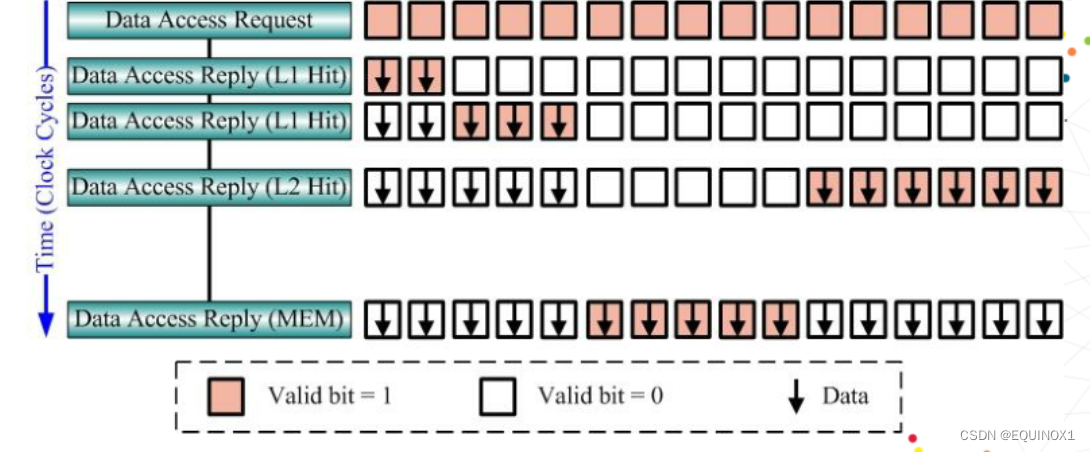
硬件多车道宏并行

- 接受GPU里的GTE的调度,GTE包含16个车道,称为stream。
- Stream号由程序员给定,不指定都走1号车道。
- 每个grid都会拿到一个编号,对号入座。
- 为了防止grid都走同一个通道,往SM上分配block的时候得串行。
- 每个stream内部有若干block,出来的时候,哪个SM有空,就送到哪个SM上去。
- SM中,每个block都被打散成若干warp,进入warp pool
微并行
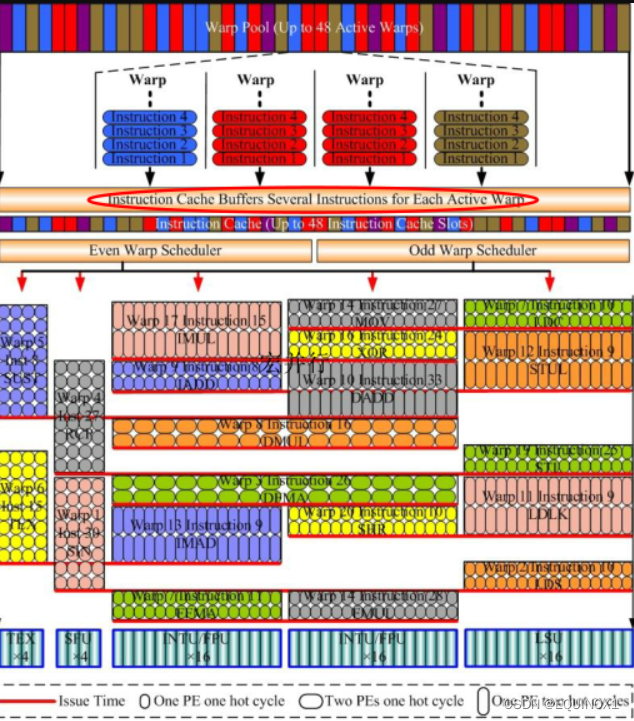
宏并行与微并行小结
- Grid是扔到GPU上的单元
- Grid中有若干block,每个block扔到一个SM上
- Block在扔到SM上的时候,被分成warp。
- 比如Block中是64个thread,这64个thread是一个程序(100条指令)的实例,64个thread分成两组,每组32个放入两个warp。
- 为了节省资源,因为32个thread的代码是相同的,所以在warp中使用的是100条instruction,放在warp的指令队列每个instruction在执行的时候按照32个thread,操纵32个数据,用threadID对应各自的数据
GPGPU Virtualization

企业级做云计算时常常采用虚拟化技术:
- 一个GPU的SM很多,但是对于单用户只能用很少的SM,这样利用率很低
- 硬件上把多个SM进行分割成多个切片
- 软件上为每个用户分配一个SM切片
- 使得每个用户都能满负荷使用SM
- 每个用户感觉自己拥有了一个GPU
三、复习题
1、请简述向量体系结构和GPU体系结构的差异
向量体系结构
- “窄而深”
- 指令流水线深,ALU宽度窄
- 单次指令流水后能处理更多的数据,掩盖不必要的流水线时间。
GPU体系结构
- “宽而浅”
- 指令流水线浅,ALU宽度宽
- 流水线本身比较简单,直接对更多的数据进行并行计算,同一时刻处理更多数据
2、请简述GPU和CPU在设计理念上的差异性
CPU和GPU均有自己的存储、控制逻辑和运算单元,但区别是CPU的控制逻辑更为复杂,而GPU的运算单元虽然较小但是众多,GPU也可以提供更多的寄存器和程序员可控的多级存储资源。
3、请简述GPU各个层次组件间的相似性。
- GPU在任务的划分上,存在着自相似性。
- 每一个第
i级的任务,都可以划分为一组i - 1级的任务,并且同一级别的任务之间是并行的。
- 每一个第
- GPU在硬件上,也体现出了自相似性。
- 逐层的,都是相似的结构,包括调度器、任务的buffer、数据存储和处理单元。
4、请简述GPGPU虚拟化的思想
- 企业级做云计算时常常采用虚拟化技术;
- 一个GPU的SM很多,但是对于单用户来说只能用很少的SM,这样利用率很低。
- 硬件上把多个SM进行分割成多个碎片。
- 软件上为每个用户分配一个SM切片。使得每个用户都能满负荷使用SM,每个用户感觉自己拥有了一个GPU。
5、请简述向量长度寄存器和向量屏蔽寄存器的作用
向量长度寄存器VL:64位,每一位对应于向量寄存器的一个单元。VL控制所有向量运算的长度,包括ld/st。
作用:将软件层程序中实际向量长度N与硬件层向量寄存器中的元素数目64相匹配。
向量屏蔽寄存器VM:当向量长度小于64时,或者条件语句控制下对向量某些元素进行单独运算时使用。
即使掩码(maskcode)中有大量的0,使用VM的向量指令速度依然远远快于标量计算模式。
6、请简述指令编队的思想
由一组不包含结构冒险的向量指令组成,一个编队中的所有向量指令在硬件条件允许的时可以并行执行。
对于同一编队中的指令:
- 不存在结构冲突
- 不存在数据冲突
- 存在数据冲突,但是可以链接
7、请简述链接技术的思想
当两条指令出现“写后读”相关时候,若它们不存在功能部件冲突和向量寄存器(源或目的)冲突,就有可能把它们所用的功能部件头尾相接,形成一个链接(长)流水线,进行流水处理。
8、请简述分段开采技术的思想
当向量的长度大于向量寄存器的长度时,必须把长向量分成长度固定的段,然后循环分段处理,每一次循环只处理一个向量段。
















 2239
2239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











