








简介
在商业应用中,时间是最重要的因素,能够提升成功率。然而绝大多数公司很难跟上时间的脚步。但是随着技术的发展,出现了很多有效的方法,能够让我们预测未来。不要担心,本文并不会讨论时间机器,讨论的都是很实用的东西。
本文将要讨论关于预测的方法。有一种预测是跟时间相关的,而这种处理与时间相关数据的方法叫做时间序列模型。这个模型能够在与时间相关的数据中,寻到一些隐藏的信息来辅助决策。
当我们处理时序序列数据的时候,时间序列模型是非常有用的模型。大多数公司都是基于时间序列数据来分析第二年的销售量,网站流量,竞争地位和更多的东西。然而很多人并不了解的时间序列分析这个领域。
所以,如果你不了解时间序列模型。这篇文章将会想你介绍时间序列模型的处理步骤以及它的相关技术。
本文包含的内容如下所示:
目录
* 1、时间序列模型介绍
* 2、使用R语言来探索时间序列数据
* 3、介绍ARMA时间序列模型
* 4、ARIMA时间序列模型的框架与应用
让我们开始吧
1、时间序列模型介绍
Let’s begin。本节包括平稳序列,随机游走,Rho系数,Dickey Fuller检验平稳性。如果这些知识你都不知道,不用担心-接下来这些概念本节都会进行详细的介绍,我敢打赌你很喜欢我的介绍的。
平稳序列
判断一个序列是不是平稳序列有三个评判标准:
1. 均值 ,是与时间t 无关的常数。下图(左)满足平稳序列的条件,下图(右)很明显具有时间依赖。

方差 ,是与时间t 无关的常数。这个特性叫做方差齐性。下图显示了什么是方差对齐,什么不是方差对齐。(注意右手边途中的不同分布。)

协方差 ,只与时期间隔k有关,与时间t 无关的常数。如下图(右),可以注意到随着时间的增加,曲线变得越来越近。因此红色序列的协方差并不是恒定的。

我们为什么要关心平稳时间序列呢?
除非你的时间序列是平稳的,否则不能建立一个时间序列模型。在很多案例中时间平稳条件常常是不满足的,所以首先要做的就是让时间序列变得平稳,然后尝试使用随机模型预测这个时间序列。有很多方法来平稳数据,比如消除长期趋势,差分化。
随机游走
这是时间序列最基本的概念。你可能很了解这个概念。但是,很多工业界的人仍然将随机游走看做一个平稳序列。在这一节中,我会使用一些数学工具,帮助理解这个概念。我们先看一个例子
例子:想想一个女孩随机的在想象一个女孩在一个巨型棋盘上面随意移动。这里,下一个位置只取决于上一个位置。

现在想象一下,你在一个封闭的房间里,不能看见这个女孩。但是你想要预测不同时刻这个女孩的位置。怎么才能预测的准一点?当然随着时间的推移你预测的越来越不准。在t=0时刻,你肯定知道这个女孩在哪里。下一个时刻女孩移动到附件8块方格中的一块,这个时候,你预测到的可能性已经降为1/8。继续往下继续预测,现在我们将这个序列公式化:
$X(t) = X(t-1) + Er(t)$
这里的$Er_t$代表这这个时间点随机干扰项。这个就是女孩在每一个时间点带来的随机性。现在我们递归所有x时间点,最后我们将得到下面的等式:
$X(t) = X(0) + Sum(Er(1),Er(2),Er(3).....Er(t))$现在,让我们尝试验证一下随机游走的平稳性假设:
1. 是否均值为常数?
E[X(t)] = E[X(0)] + Sum(E[Er(1)],E[Er(2)],E[Er(3)].....E[Er(t)])我们知道由于随机过程的随机干扰项的期望值为0.到目前为止:E[X(t)] = E[X(0)] = 常数
2. 是否方差为常数?
Var[X(t)] = Var[X(0)] + Sum(Var[Er(1)],Var[Er(2)],Var[Er(3)].....Var[Er(t)])
Var[X(t)] = t * Var(Error) = 时间相关因此,我们推断,随机游走不是一个平稳的过程,因为它有一个时变方差。此外,如果我们检查的协方差,我们看到协方差依赖于时间。
我们看一个更有趣的东西
我们已经知道一个随机游走是一个非平稳的过程。让我们在方程中引入一个新的系数,看看我们是否能制定一个检查平稳性的公式。
Rho系数
X(t) = Rho * X(t-1) + Er(t)现在,我们将改变Rho看看我们可不可以让这个序列变的平稳。这里我们只是看,并不进行平稳性检验。
让我们从一个Rho=0的完全平稳序列开始。这里是时间序列的图:

将Rho的值增加到0.5,我们将会得到如下图:

你可能会注意到,我们的周期变长了,但基本上似乎没有一个严重的违反平稳性假设。现在让我们采取更极端的情况下ρ= 0.9

我们仍然看到,在一定的时间间隔后,从极端值返回到零。这一系列也不违反非平稳性明显。现在,让我们用ρ= 1随机游走看看

这显然是违反固定条件。是什么使rho= 1变得这么特殊的呢?,这种情况并不满足平稳性测试?我们来找找这个数学的原因
公式X(t) = Rho * X(t-1) + Er(t)的期望为:
E[X(t)] = Rho *E[ X(t-1)]这个公式很有意义。下一个X(或者时间点t)被拉到Rho*上一个x的值。
例如,如果x(t–1)= 1,E[X(T)] = 0.5(Rho= 0.5)。现在,如果从零移动到任何方向下一步想要期望为0。唯一可以让期望变得更大的就是错误率。当Rho变成1呢?下一步没有任何可能下降。
Dickey Fuller Test平稳性
这里学习的最后一个知识点是Dickey Fuller检验。。在统计学里,Dickey-Fuller检验是测试一个自回归模型是否存在单位根。这里根据上面Rho系数有一个调整,将公式转换为Dickey-Fuller检验
X(t) = Rho * X(t-1) + Er(t)
=> X(t) - X(t-1) = (Rho - 1) X(t - 1) + Er(t)我们要测试如果Rho–1=0是否差异显著。如果零假设不成立,我们将得到一个平稳时间序列。
平稳性测试和将一个序列转换为平稳性序列是时间序列模型中最重要的部分。因此需要记住本节提到的所有概念方便进入下一节。
接下来就看看时间序列的例子。
2、使用R探索时间序列
本节我们将学习如何使用R处理时间序列。这里我们只是探索时间序列,并不会建立时间序列模型。
本节使用的数据是R中的内置数据:AirPassengers。这个数据集是1949-1960年每个月国际航空的乘客数量的数据。
在入数据集
下面的代码将帮助我们在入数据集并且能够看到一些少量的数据集。
> data(AirPassengers)#在入数据
> class(AirPassengers)
[1] "ts"
#查看AirPassengers数据类型,这里是时间序列数据
> start(AirPassengers)
[1] 1949 1
#这个是Airpassengers数据开始的时间
> end(AirPassengers)
[1] 1960 12
#这个是Airpassengers数据结束的时间
> frequency(AirPassengers)
[1] 12
#时间序列的频率是一年12个月
> summary(AirPassengers)
Min. 1st Qu. Median Mean 3rd Qu. Max.
104.0 180.0 265.5 280.3 360.5 622.0矩阵中详细数据
#The number of passengers are distributed across the spectrum
> plot(AirPassengers)
#绘制出时间序列
>abline(reg=lm(AirPassengers~time(AirPassengers)))
# 拟合一条直线
> cycle(AirPassengers)
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
1949 1 2 3 4 5 6 7 8 9 10 11 12
1950 1 2 3 4 5 6 7 8 9 10 11 12
1951 1 2 3 4 5 6 7 8 9 10 11 12
1952 1 2 3 4 5 6 7 8 9 10 11 12
1953 1 2 3 4 5 6 7 8 9 10 11 12
1954 1 2 3 4 5 6 7 8 9 10 11 12
1955 1 2 3 4 5 6 7 8 9 10 11 12
1956 1 2 3 4 5 6 7 8 9 10 11 12
1957 1 2 3 4 5 6 7 8 9 10 11 12
1958 1 2 3 4 5 6 7 8 9 10 11 12
1959 1 2 3 4 5 6 7 8 9 10 11 12
1960 1 2 3 4 5 6 7 8 9 10 11 12
#打印每年的周期
> plot(aggregate(AirPassengers,FUN=mean))
#绘制
> boxplot(AirPassengers~cycle(AirPassengers))
#绘制盒图

重要推论
- 每年的趋势显示旅客的数量每年都在增加
- 七八月的均值和方差比其他月份要高很多
- 每个月的平均值并不相同,但是方差差异很小。因此,可以看出具有很强的周期性。,一个周期为12个月或更少。
查看数据,试探数据是建立时间序列模型最重要的一部-如果没有这一步,你将不知道这个序列是不是平稳序列。就像这个例子一样,我们已经知道了很多关于这个模型的很多细节。
接下来我们会建立一些时间序列模型以及这些模型的特征,也会最一些预测。
3、ARMA时间序列模型
ARMA也叫自回归移动平均混合模型。ARMA模型经常在时间序列中使用。在ARMA模型中,AR代表自回归,MA代表移动平均。如果这些术语听起来很复杂,不用担心-下面将会用几分钟的时间简单介绍这些概念。
我们现在就会领略这些模型的特点。在开始之前,你首先要记住,AR或者MA并不是应用在非平稳序列上的。
在实际应用中可能会得到一个非平稳序列,你首先要做的就是将这个序列变成平稳序列(通过差分化/转换),然后选择可以使用的时间序列模型。
首先,本文将介绍分开介绍两个模型(AR&MA)。接下来我们看一看这些模型的特点。
自回归时间序列模型
让我们从下面的例子理解AR模型:
现状一个国家的GDP(x(t))依赖与去年的GDP(x(t-1)).这个假设一个国家今年的GDP总值依赖与去年的GDP总值和今年的新开的工厂和服务。但是GDP的主要依赖与去年去年的GDP。
那么,GDP的公式为:
x(t) = alpha * x(t – 1) + error (t) (1)这个等式就是AR公式。公式(1)表示下一个点完全依赖与前面一个点。alpha是一个系数,希望能够找到alpha最小化错误率。x(t-1)同样依赖x(t)。
例如,x(t)代表一个城市在某一天的果汁的销售量。在冬天,极少的供应商进果汁。突然有一天,温度上升了,果汁的需求猛增到1000.然而过了几天,气温有下降了。但是众所周知,人们在热天会喝果汁,这些人会有50%在冷天仍然喝果汁。在接下来的几天,这个比例降到了25%(50%的50%),然后几天后逐渐降到一个很小的数。下图解释了AR序列的惯性:

移动平均时间序列模型
接下来另一个关于移动平均的例子。
一个公司生成某种类型的包,这个很容易理解。作为一个竞争的市场,包的销售量从零开始增加的。所以,有一天他做了一个实验,设计并制作了不同的包,这种包并不会被随时购买。因此,假设市场上总需求是1000个这种包。在某一天,这个包的需求特别高,很快库存快要完了。这天结束了还有100个包没卖掉。我们把这个误差成为时间点误差。接下来的几天仍有几个客户购买这种包。下面通过一个简单的公式来描述这个场景:
x(t) = beta * error(t-1) + error (t)尝试把这个图画出来,就是这个样子的:

注意到MA和AR模型的不同了没?在MA模型中,噪声/冲击迅速小时。在AR模型中会受到长时间的影响。
AR模型与MA模型的不同
AR与MA模型的主要不同在于时间序列对象在不同时间点的相关性。
MA模型用过去各个时期的随机干扰或预测误差的线性组合来表达当前预测值。当n>某一个值时,x(t)与x(t-n)的相关性总为0.AM模型仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,步骤模型变量相对独立的假设条件约束,所构成的模型可以消除普通回退预测方法中由于自变量选择、多重共线性等造成的困难。即AM模型中x(t)与x(t-1)的相关性随着时间的推移变得越来越小。这个差别要好好利用起来。
利用ACF和PACF绘图
一旦我们得到一个平稳时间序列。我们必须要回答两个最重要的问题;
Q1:这个是AR或者MA过程?
Q2:我们需要利用的AR或者MA过程的顺序是什么?
解决这两个问题我们要借助两个系数:
时间序列x(t)滞后k阶的样本自相关系数(ACF)和滞后k期的情况下样本偏自相关系数(PACF)。公式省略。
AR模型的ACF和PACF:
通过计算证明可知:
- AR的ACF为拖尾序列,即无论滞后期k取多大,ACF的计算值均与其1到p阶滞后的自相关函数有关。
- AR的PACF为截尾序列,即当滞后期k>p时PACF=0的现象。


上图蓝线显示值与0具有显著的差异。很显然上面PACF图显示截尾于第二个滞后,这意味这是一个AR(2)过程。
MA模型的ACF和PACF:
- MA的ACF为截尾序列,即当滞后期k>p时PACF=0的现象。
- AR的PACF为拖尾序列,即无论滞后期k取多大,ACF的计算值均与其1到p阶滞后的自相关函数有关。

很显然,上面ACF图截尾于第二个滞后,这以为这是一个MA(2)过程。
目前,本文已经介绍了关于使用ACF&PACF图识别平稳序列的类型。现在,我将介绍一个时间序列模型的整体框架。此外,还将讨论时间序列模型的实际应用。
4、ARIMA时间序列模型的框架与应用
到此,本文快速介绍了时间序列模型的基础概念、使用R探索时间序列和ARMA模型。现在我们将这些零散的东西组织起来,做一件很有趣的事情。
框架
下图的框架展示了如何一步一步的“做一个时间序列分析”
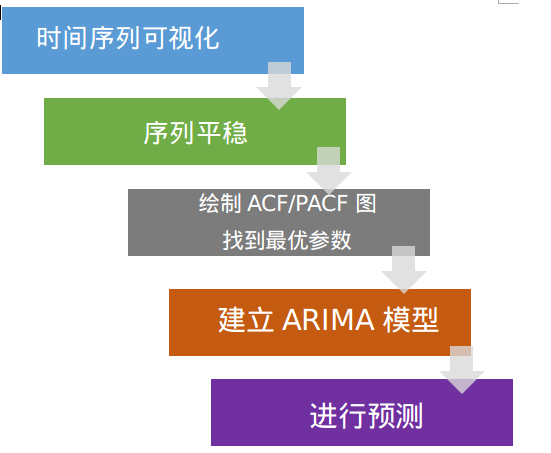
前三步我们在前文意见讨论了。尽管如此,这里还是需要简单说明一下:
第一步:时间序列可视化
在构建任何类型的时间序列模型之前,分析其趋势是至关重要的。我们感兴趣的细节包括序列中的各种趋势、周期\季节性或者随机行为。在本文的第二部分已经介绍了。
第二步:序列平稳
一旦我们知道了模式、趋势、周期。我们就可以检查序列是否平稳。Dicky-Fuller是一种很流行的检验方式。在第一部分意见介绍了这种检验方式。在这里还没有结束!如果发现序列是非平稳序列怎么办?
这里有三种比较常用的技术来让一个时间序列平稳。
1 消除趋势:这里我们简单的删除时间序列中的趋势成分。例如,我的时间序列的方程是:
x(t) = (mean + trend * t) + error这里我简单的删除上述公式中的trend*t部分,建立x(t)=mean+error模型
2 差分:这个技术常常用来消除非平稳性。这里我们是对序列的差分的结果建立模型而不是真正的序列。例如:
x(t) – x(t-1) = ARMA (p , q)这个差分也是ARIMA的部分。现在我们有3个参数了:
p:AR
d:I
q:MA3 季节性:季节性直接被纳入ARIMA模型中。下面的应用部分我们再讨论这个。
第三步:找到最优参数
参数p,q可以使用ACF和PACF图发现。除了这种方法,如果相关系数ACF和偏相关系数PACF逐渐减小,这表明我们需要进行时间序列平稳并引入d参数。
第四步:简历ARIMA模型
找到了这些参数,我们现在就可以尝试简历ARIMA模型了。从上一步找到的值可能只是一个近似估计的值,我们需要探索更多(p,d,q)的组合。最小的BIC和AIC的模型参数才是我们要的。我们也可以尝试一些季节性成分。在这里,在ACF/PACF图中我们会注意到一些季节性的东西。
第五步:预测
到这步,我们就有了ARIMA模型,我们现在就可以做预测了。我们也可以将这种趋势可视化,进行交叉验证。
时间序列模型的应用。
这里我们用前面的例子。使用这个时间序列做预测。我们建议你在进行下一步之前,先观察这个数据。
我们从哪里开始呢?
下图是这些年的乘客数的图。在往下看之前,观察这个图。

这里是我的观察:
1. 乘客有着逐年增加的趋势。
2. 这看起来有季节性,每一个周期不超过12个月。
3. 数据的方差逐年增加。
在我们进行平稳性测试之前我们需要解决两个问题。第一,我们需要消除方差不齐。这里我们对这个序列做求对数。第二我们需要解决序列的趋势性。我们通过对时序序列做差分。现在,我们来检验最终序列的平稳性。
adf.test(diff(log(AirPassengers)), alternative="stationary", k=0)
#这里可能会显示没有这个函数,需要安装一下.install.packages("tseries")
#加在这个包,library(tseries
data: diff(log(AirPassengers))
Dickey-Fuller = -9.6003, Lag order = 0,
p-value = 0.01
alternative hypothesis: stationary我们可以看出这个序列是足够平稳做任何时间序列模型。
下一步就是找到ARIMA模型的正确的参数。我们意见知道’d‘是1,因此我们需要做1差分让序列平稳。这里我们绘制出相关图。下面就是这个序列的ACF图。
#ACF图
acf(log(AirPassengers))
从上述表格可以看出什么?
很显然ACF下降的十分的慢,这就意味着乘客的数量并不是平稳的。我们在前面已经讨论了,我们现状准备在序列去对数后的差分上做回归,而不是直接在序列去对数后的数据熵差分。让我们看一下差分后的ACF和PACF曲线吧。
> acf(diff(log(AirPassengers)))
> pacf(diff(log(AirPassengers)))

显然ACF截止与第一个滞后,因此我们知道p的值应该是0.而q的值应该是1或者2.几次迭代以后,我们发现(p,d,q)取(0,1,1)时,AIC和BIC最小。
> fit <- arima(log(AirPassengers), c(0, 1, 1),seasonal = list(order = c(0, 1, 1), period = 12))
> pred <- predict(fit, n.ahead = 10*12)
ts.plot(AirPassengers,2.718^pred$pred, log = "y", lty = c(1,3))
后记
我参加一个时间序列的比赛,对时间序列的了解止步与马尔科夫模型。而且马尔科夫模型并不适合解纯时间序列的问题,所以就上网搜索一下时间序列的相关知识。很偶然的发现了这篇文章,文章的逻辑清晰,表达清楚,文字浅显易懂,值得我学习,所以我就尝试翻译了这篇文章。中间很多东西并不是很了解,如有错误的地方,欢迎指正。
参考资料
A Complete Tutorial on Time Series Modeling in R
时间序列
第八章时间序列分析















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









