







背 景
随着微服务架构的普及,现代企业的IT基础设施已经变得越来越复杂。单一的服务可能有多个下游依赖,而这些依赖又可能有自己的子依赖,和主机资源的依赖。在这样的环境中,当某个服务发生故障,确定具体的原因变得尤为困难。传统的故障排查方法,如手动检查日志或询问开发团队,既耗时又不一定能找到真正的根源。
此外,随着DevOps和持续集成/持续部署(CI/CD)的普及,应用的发布频率大大增加,这使得发布引起的服务中断变得更为常见。同时,资源和基础设施的动态性也为故障诊断带来了挑战。
为了应对这些挑战,优维设计了“Easy分析”服务故障根因分析工具,旨在为技术团队提供一个集成、自动化的解决方案,帮助其迅速、准确地定位服务故障时的原因。
下面,从具体场景出发,详细介绍服务故障根因分析工具。
1
应用发布导致的服务故障
1.1 概述
应用发布可能导致服务运行出现不稳定或其他未预期的影响。当服务发出告警时,本功能将自动分析告警指标,检测服务或其下游服务在最近是否发生过变更。
1.2 核心功能
-
变更检测:当服务告警时,系统会自动检测与告警相关的服务是否近期有变更事件,如启动、关闭、升级或重启等。
-
双态部署事件联动:与双态部署系统紧密集成,获取最新的部署和变更事件信息。
-
告警与变更关联:为告警事件提供直接与变更事件的关联,帮助团队快速确定是否有发布活动导致的故障。
-
消费CMDB数据:根据cmdb的服务相关的模型,自动关联下游服务的变更事件
1.3 场景说明及配置
假设微服务集群中,提供了一个名为flounder_metric的服务。服务的请求一般是从api_gateway接入到集群中,并且基于url路由至具体的应用组件来处理请求。因此,在这个场景中,存在这样一个调用关系:api_gateway -> flounder_metric
在服务监控中,我们会对flounder_metric的接口进行拨测。配置的步骤如下:
-
建立内网拨测策略,指定监控的应用是「http-logic.api_gateway」,它是api_gateway应用的服务标识;
-
配置关于flounder_metric服务的接口,在变量定义中,通过$.subservices.ip会自动获取到服务下子服务的IP地址。
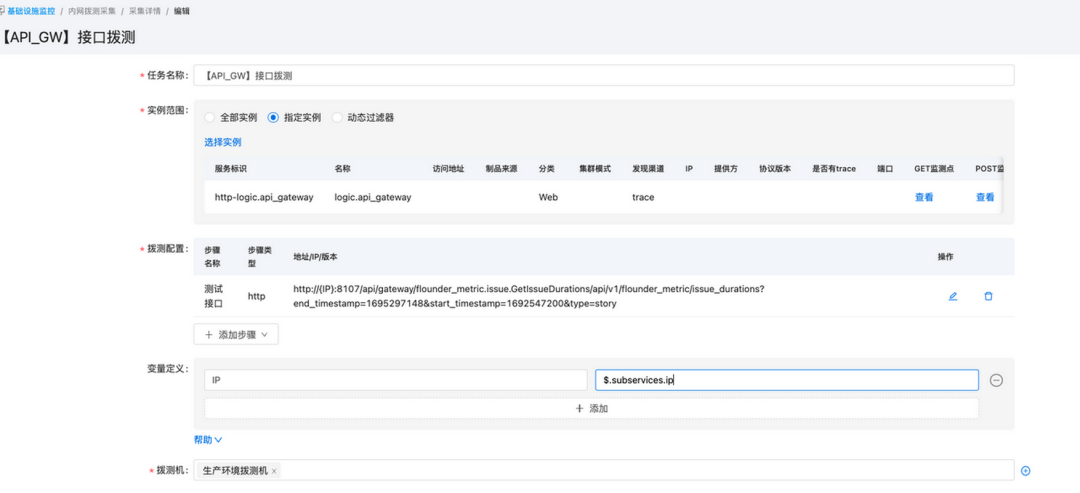
保存后即可。
此时配置基于detect_code的告警规则,即可完成对该接口的监控。
1.4 故障触发和根因分析
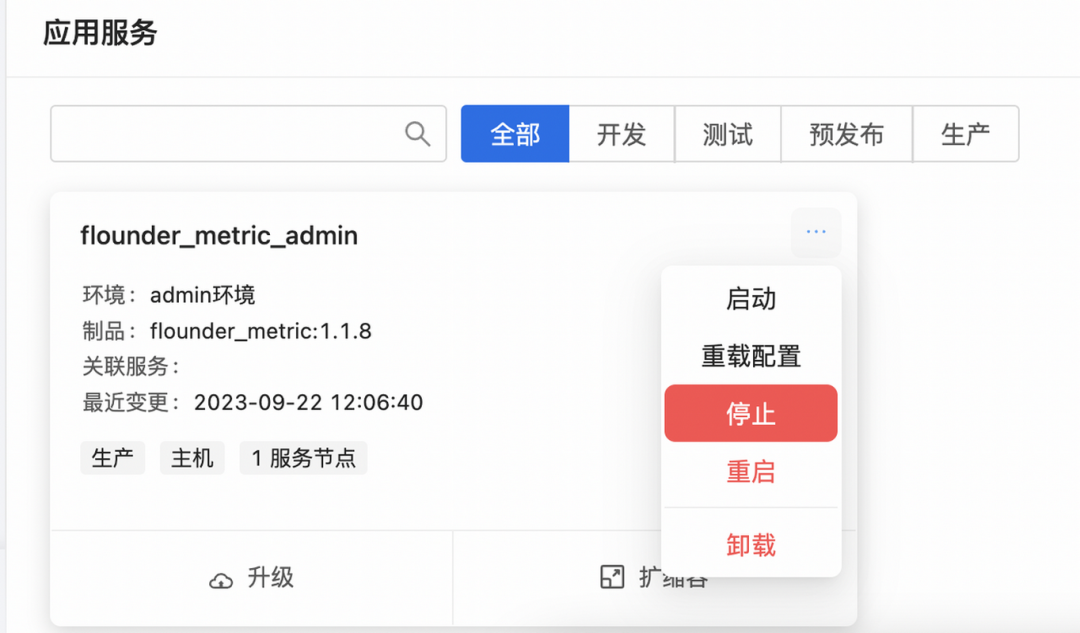
我们人为触发一个服务告警,通过双态部署,关闭flounder_metric服务。
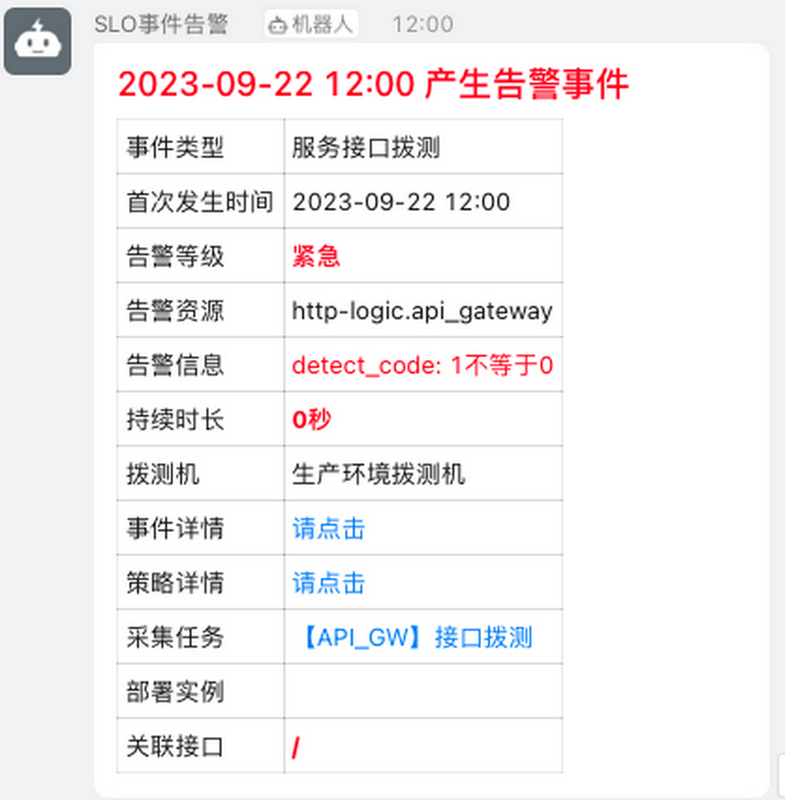
稍后,将触发一个拨测告警:
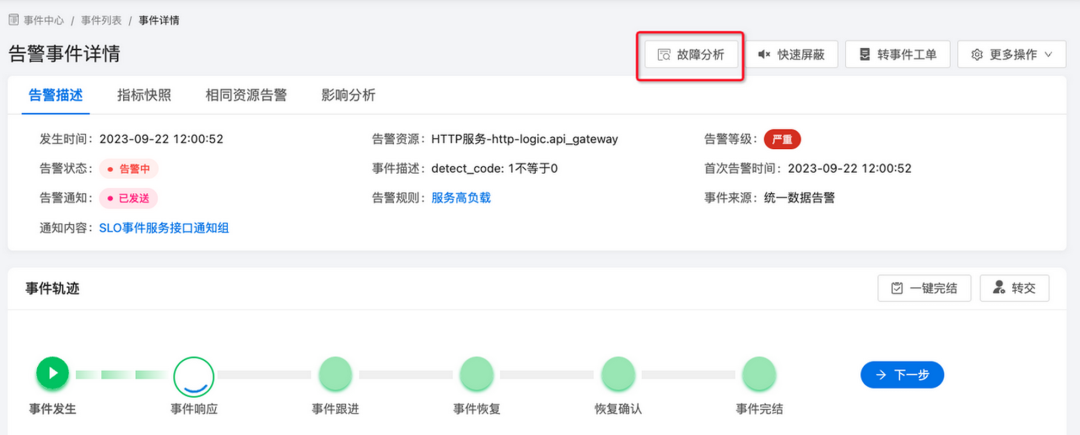
我们通过事件详情,点击故障分析:
此时将看到故障分析页面,让我们来解释一下:
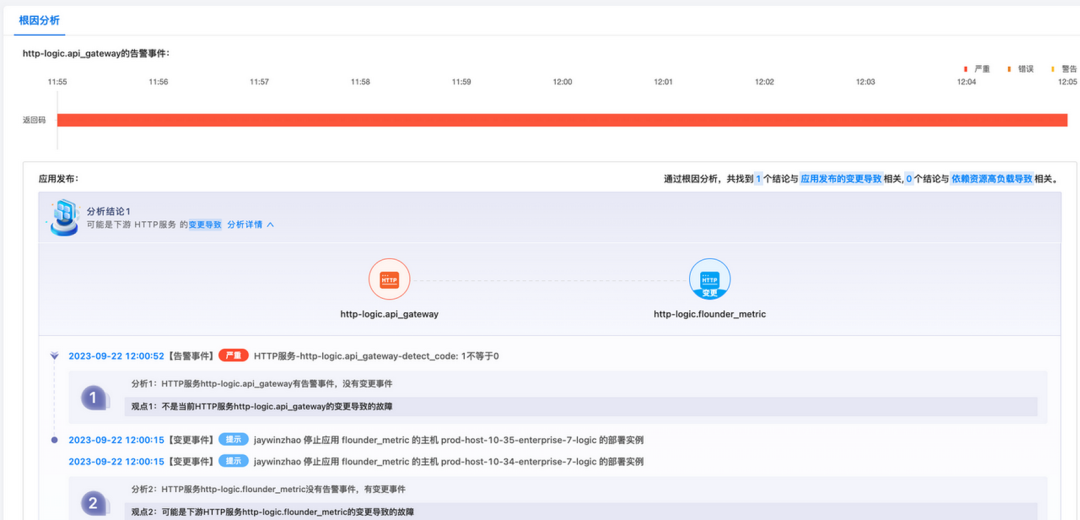
上方是告警事件的告警对象和告警指标持续的时间,可以看到告警持续时间范围是 11:55~12:04。
接下来就是根因分析的结论,一共发现1个结论,和应用发布的变更相关。具体来说,有两个分析:
-
http-logic.api_gateway有告警事件,没有变更事件,说明不是api_gatewaya变更导致;
-
由于api_gateway的下游是flounder_metric服务,而该服务在12:00分发生了停止操作,进而触发了告警,因此分析为:下游HTTP服务http-logic.flounder_metric的变更导致的故障(这也是此次故障的真正原因)。
1.5 结论
在微服务架构中,服务间的相互依赖和频繁的应用发布行为可能会导致复杂的故障情况。在本场景中,通过"服务故障根因分析"工具,我们成功地自动检测到flounder_metric服务的停止操作是导致api_gateway服务拨测告警的直接原因。该工具能够智能地关联告警事件与近期的应用变更,准确快速地定位到真实的故障原因。
此次案例展示了"服务故障根因分析"工具的核心功能,即自动识别与故障相关的变更,并为技术团队提供明确的、数据驱动的根因分析。此功能大大减少了故障诊断时间,并提高了故障恢复的效率。
2
依赖资源高负载导致的服务故障
2.1 概述
服务的性能和稳定性可能受到其运行环境的影响,特别是当它依赖的资源或子服务处于高负载状态时。本功能提供了与资源负载告警的自动关联能力,帮助识别故障的根本原因。
2.2 核心功能
-
资源负载告警关联:当服务延迟或其他性能指标出现问题时,系统会自动检测与该服务关联的子服务部署实例主机是否有高负载告警。
-
直观的负载影响分析:为用户提供一个清晰的视图,展示服务与其依赖资源之间的关系,以及哪些资源的高负载可能影响了服务的性能。
-
资源性能指标对比:允许用户对比服务性能指标与资源负载指标,例如,当服务延迟增加时,可以立即查看其所在主机的CPU或内存使用情况。
2.3 场景说明及配置
假设微服务集群中,提供了一个名为cmdb_service的服务,并且对它的延迟做监控。我们设定SLO是10ms,并且手动触发系统高负载,来审视根因分析的准确性。
为了实现这个场景,我们人为设定当「磁盘IO的使用率」过高并触发告警后,再触发延迟告警。
当告警发生后,我们点击故障分析,进入分析页:
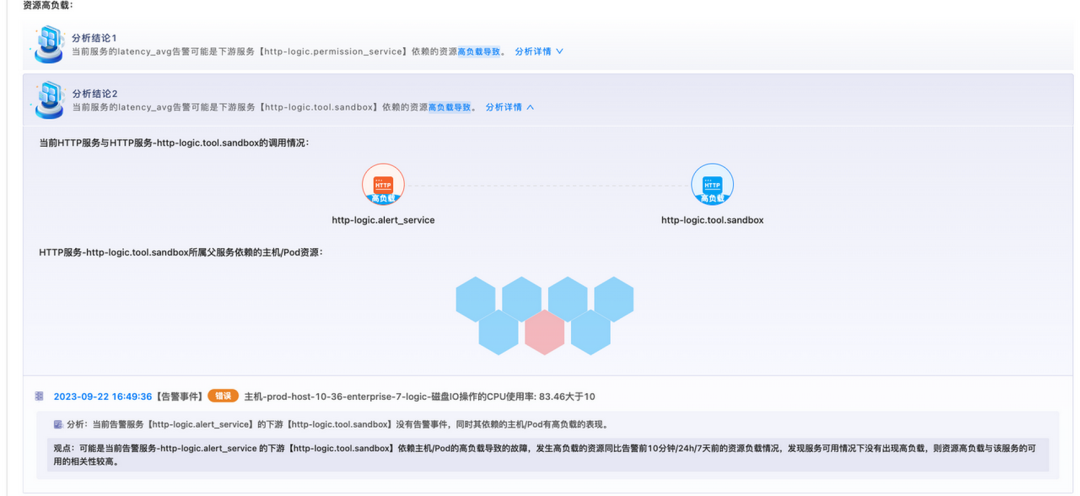
分析页面如上所示,让我们解释一下。
-
由于alert_service的下游是tool.sandbox,并且这两个服务都在主机:prod-host-10-36-enterprise-7-logic,并且该主机发生磁盘IO操作的CPU使用率过高的告警。因此根因分析就会把这些关系和告警联系起来,并告知给用户。
除了「磁盘IO操作的CPU使用率」,还有「5分钟单核负载」,「网络流量」等指标均可触发高负载场景的分析。
2.4 结论
在微服务架构中,单一服务的性能往往与其所依赖的其他服务和资源紧密相关。我们在这次的模拟场景中成功地展示了如何通过“服务故障根因分析”工具来识别和关联服务延迟增加与其所在主机的资源高负载之间的因果关系。
这种自动化的、综合的分析方法大大简化了故障诊断过程,确保了更快速、更准确的问题定位和解决,进一步提高了服务的稳定性和可用性。
3
支持按拓扑形式分析故障演变情况
故障根因分析的分析视图改版,支持按拓扑形式分析故障演变情况。在旧版本中,尽管可以关联并分析出所有可能导致故障的原因,但是分析视图所携带的信息过于繁琐和冗余,不利于高效分析的目的。在新版故障分析视图中,支持以故障拓扑的形式去智能分析故障演化路径。如下所示:
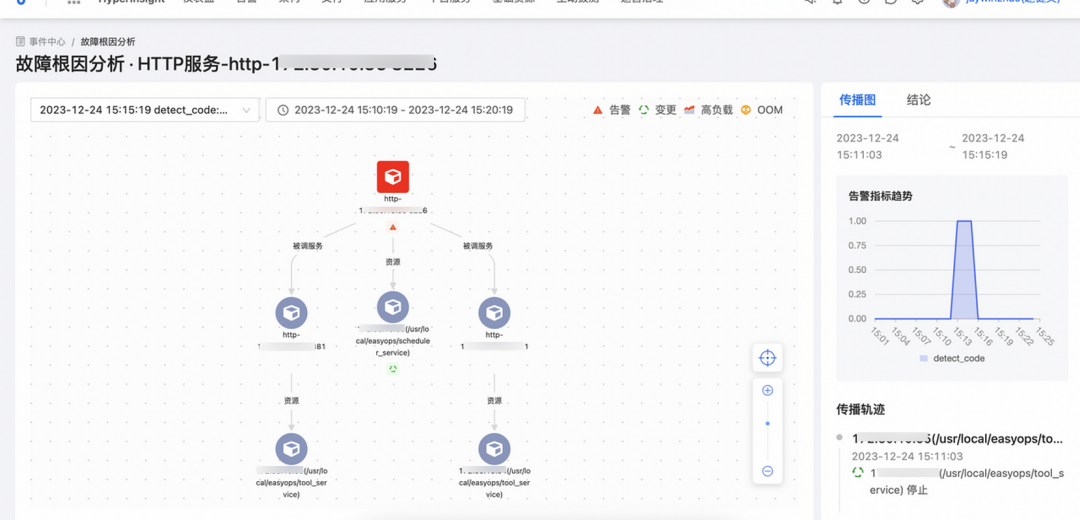
如上图所示:红色为底色的方框代表服务产生的告警,比如端口拨测失败。
而后展示了和此服务关联的其他服务的变更情况,由图可知,是17*.3*.**.**上的scheduler_service发生了变更导致服务告警。
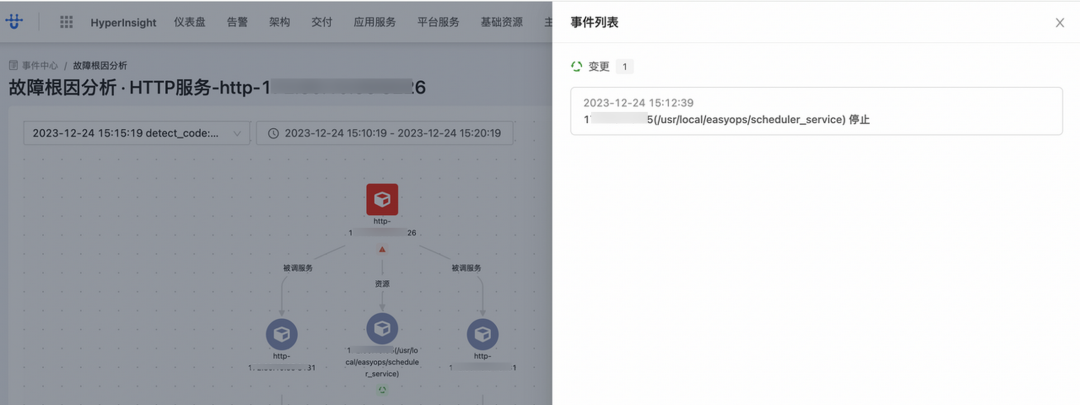
如此可以帮助用户快速排除服务故障的原因是否由于变更产生。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









