







在Hadoop的最初发布版本,遇到的单点故障及资源的利用率问题,而针对于单点问题,系统是怎么解决的呢?
H1版本:NameNode+SNN(Secondary NameNode);
H2版本:NameNode+HANameNode;
H3版本:NameNode+NameNode+NameNode;
在H2及以上的版本,通过NameNode的standby的方式,成功的解决了单点问题。以下来看看SNN与HA的工作机制。
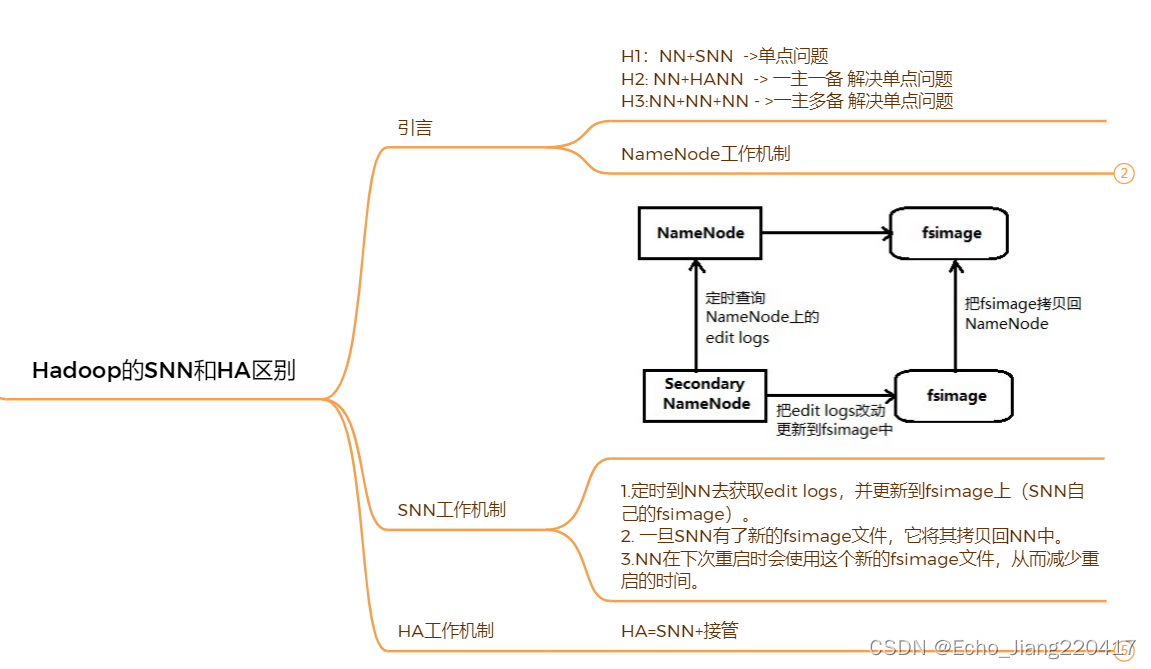
先来了解NameNode 的工作机制
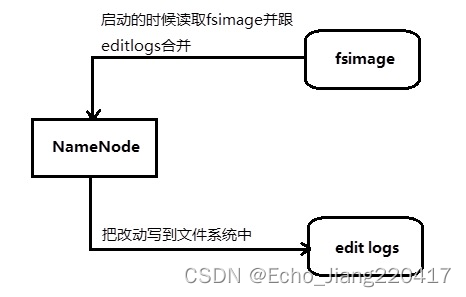
NameNode 用来存储metadata信息,主要有两个部分:
1. fsimage:NN启动时,对整个文件系统的快照。
2. edit logs:NN启动后,对文件系统的改动序列。
SNN工作机制
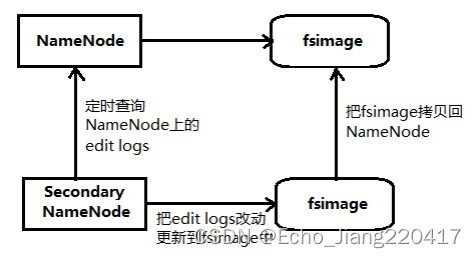
1.定时到NN去获取edit logs,并更新到fsimage上(SNN自己的fsimage)。
2. 一旦SNN有了新的fsimage文件,它将其拷贝回NN中。
3.NN在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
SNN解决了fsimage信息及时同步问题,加速了NameNode的启动,在遇到故障是,可以加速NameNode 的恢复进程。但是,没法解决NN挂掉后的接管问题。这就是H1的单点问题。
HA工作机制
Active和Standby两个NameNode之间的数据交互流程为:
1. NameNode在启动后,会先加载FSImage文件和共享目录上的EditLog Segment文件;
2. Standby NameNode会启动EditLogTailer线程和StandbyCheckpointer线程,正式进入Standby模式;
3. Active NameNode把EditLog提交到JournalNode集群;
4. Standby NameNode上的EditLogTailer 线程定时从JournalNode集群上同步EditLog;
5. Standby NameNode上的StandbyCheckpointer线程定时进行Checkpoint,并将Checkpoint之后的 FSImage文件上传到Active NameNode。
(在Hadoop 2.0中不再有Secondary NameNode这个角色了, StandbyCheckpointer线程的作用其实是为了替代 Hadoop 1.0版本中的Secondary NameNode的功能)
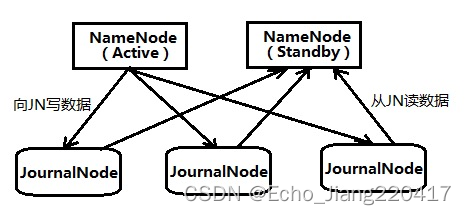
Active NameNode和Standby NameNode之间是通过一组JournalNode(数量是奇数,可以是3,5,7…,2n+1)来共享数据。Active NameNode把最近的edits文件写到2n+1个JournalNode上,只要有n+1个写入成功就认为这次写入操作成功了,然后Standby NameNode就可以从JournalNode上读取了。可以看到,QJM方式有容错机制,可以容忍n个JournalNode的失败。
Hadoop HA高可用的NamaNode主备切换
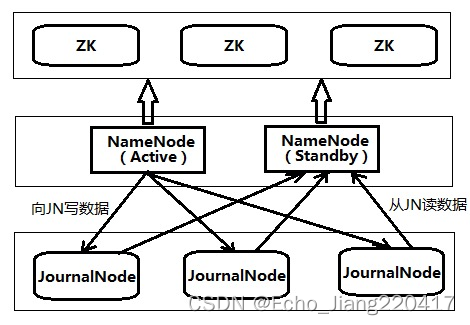
主备NameNode的自动切换需要配置Zookeeper。Active NameNode和Standby NameNode把他们的状态实时记录到Zookeeper中,Zookeeper监视他们的状态变化。当Zookeeper发现Active NameNode挂掉后,会自动把Standby NameNode切换成Active NameNode。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









