







总结上一次学习:
1)搭建hdfs集群可能会出现namenode 、datanode进程会挂掉?
需要查看logs的异常信息在来看
如果namenode没有正常启动,原因可能是没有正确的格式化
如果datanode没有启动,原因可能是namespaceId不一样
正确步骤:
rm -rf 本地hdfs存储目录
执行 ./hadoop namenode -format
执行./start-dfs.sh
2)dfsadmin -setQuota的问题
dfsadmin -setQuota限制文件数量
dfsadmin -setSpaceQuota限制上传文件的磁盘空间
3)小文件的配置?以及如何处理?
hdfs默认的数据库大小是64M,如果文件小于64M可以通过archive的方式来合并文件
数据块大小使用dfs.block.size这个属性来配置
4)start-dfs.sh执行过程中warning信息的说明?
如:Unable to load native-hadoop library for your platform....
usring built-in java class
很多时候可以通过JNI调用c/C++编写的native库,如果没有找到就会使用内置的java code
5) 重复运行wordcount.java会存在提示目录已经存在
可以先删除,直接删除目录或者用hadoop fs -rm 删除
可以在程序中判断,如果存在先删除在提交
可以修改源代码增加目录替换功能
6)默认的hadoop conf路径变成了etc/hadoop
在启动start-dfs.sh时会先去source hadoop-config.sh
然后会去找conf/hadoop-env.sh
如果不存在就会设施成etc/hadoop
存在就会去执行 hadoop-daemon.sh或者hadoop-daemons.sh
然后去找到相应的java程序执行
打开eclipse新建一个项目
导入hadoop1.2.1源代码,先导入core然后导入hdfs
配置相应的依赖包
如果出现
sun.net.util.IPAddressUtil错误时
| 解决了,sun.net包里的类,在eclipse里默认是不让用的。解决办法是自定义access rules 工程上右键->工程属性->java builder path->Libraries标签,点击JRE System Library里面的Access rules,add sun/** 为accessible,如果该项存在,就edit。 |
HDFS优缺点:


SecondNameNode
1)不是Namenode的备份
2)周期性合并fsimagehe editslog,并推送给namenode
editslog是所有操作记录
fsimage是namenode的一个镜像
3)辅助恢复Namenode
4)SecondaryNameNode的作用现在可以被两个节点替换,checkpoint node 与backup node
2.0时代已经被checkpoint node替代 backup node是namenode的完全备份
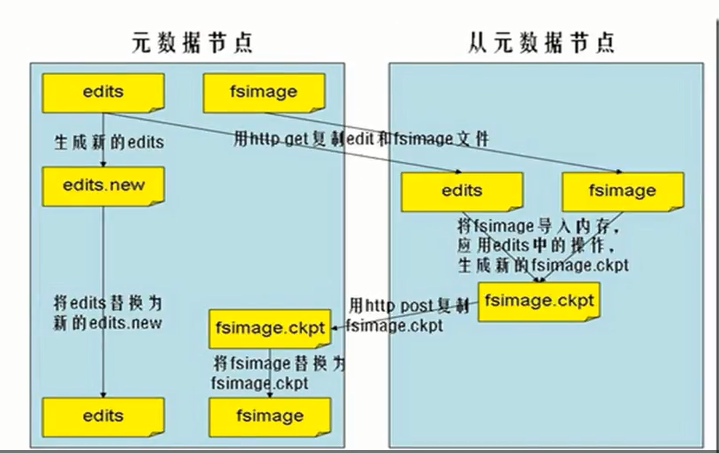
通过配置conf/core-site.xml文件配置checkpoint

jps查看一下是否已经启动dfs如果启动./stop-dfs.sh停掉
然后./hadoop namenode -format
然后重新启动./start-dfs.sh
然后等待30秒,查看/tmp/hadoop/secondarynamenode目录

多出两个目录,查看cat current/VERSION
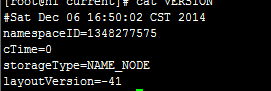

Checkpoint Node 和Scondary NameNodede 作用完全相同
但是在1.x版本是不存在checkpoint Node命令的
启动命令是 bin/hdfs namenode -checkpoint
Backup Node
是真正意义上的备用节点
在内存中维护一份从namenode同步过来的fsimage,同时它还从namenode接受edits文件的日志流
并把它们持久化磁盘
Backup Node在内存中维护和NameNode一样的Matadata数据
启动命令用bin/hdfs namenode -backup















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









