







学习目标
-
理解负载均衡是概念,认识常用负载均衡算法
-
RestTemplate应用
-
Ribbon与其他负载均衡组件对比
-
Ribbon集成springcloud
第1章:初识负载均衡
负载均衡:建立在现有网络结构之上,它提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。
负载均衡说白了其实就是伴随着微服务架构的诞生的产物;过去的单体架构,前端页面发起请求,然后后台接收请求直接处理,这个时候不存在什么负载均衡;但是随着单体架构向微服务架构的演变,每个后台服务可能会部署在多台服务器上面,这个时候页面请求进来,到底该由哪台服务器进行处理呢?所以得有一个选择,而这个过程就是负载均衡;同时选择的方案有很多种,例如随机挑选一台或者一台一台轮着来,这就是负载均衡算法。
也可以通过例子来帮助自己记忆,就好比古代皇帝翻牌子,最开始皇帝只有一个妃子,那不存在翻牌子这回事,再怎么翻也只能是这一个妃子侍寝。但是随着妃子多了,就得有选择了,不能同时所有妃子一起侍寝。
1.1 实现方式
1.1.1 HTTP重定向负载均衡
工作原理图如下:
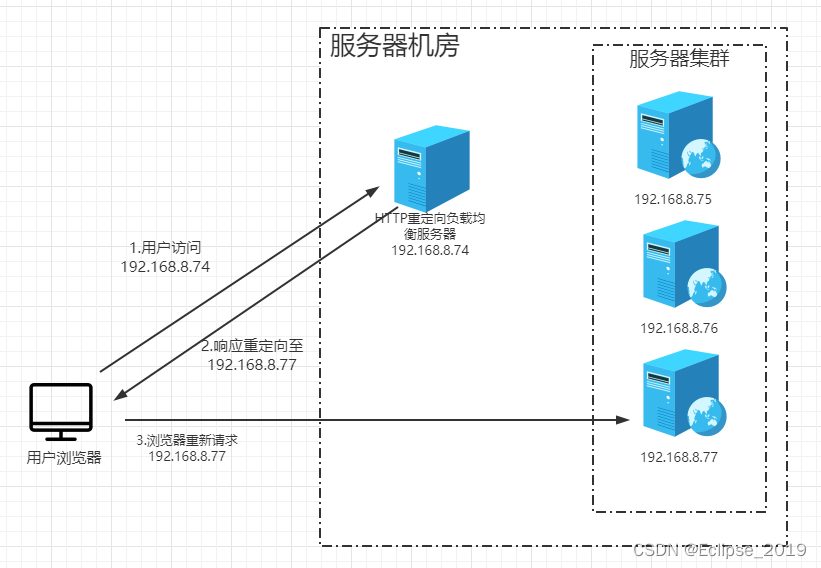
HTTP重定向服务器是一台普通的应用服务器,其唯一个功能就是根据用户的HTTP请求计算出一台真实的服务器地址,并将该服务器地址写入HTTP重定向响应中返回给用户浏览器。用户浏览器在获取到响应之后,根据返回的信息,重新发送一个请求到真实的服务器上。DNS服务器解析到IP地址为192.168.8.74,即HTTP重定向服务器的IP地址。重定向服务器计根据某种负载均衡算法算出真实的服务器地址为192.168.8.77并返回给用户浏览器,用户浏览器得到返回后重新对192.168.8.77发起了请求,最后完成访问。
这种负载均衡方案的有点是比较简单,缺点是浏览器需要两次请求服务器才能完成一次访问,性能较差;同时,重定向服务器本身的处理能力有可能成为瓶颈,整个集群的伸缩性规模有限;因此实践中很少使用这种负载均衡方案来部署。
1.1.2 DNS负载均衡
DNS(Domain Name System)是因特网的一项服务,它作为域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网。人们在通过浏览器访问网站时只需要记住网站的域名即可,而不需要记住那些不太容易理解的IP地址。在DNS系统中有一个比较重要的的资源类型叫做主机记录也称为A记录,A记录是用于名称解析的重要记录,它将特定的主机名映射到对应主机的IP地址上。如果你有一个自己的域名,那么要想别人能访问到你的网站,你需要到特定的DNS解析服务商的服务器上填写A记录,过一段时间后,别人就能通过你的域名访问你的网站了。DNS除了能解析域名之外还具有负载均衡的功能,下面是利用DNS工作原理处理负载均衡的工作原理图:
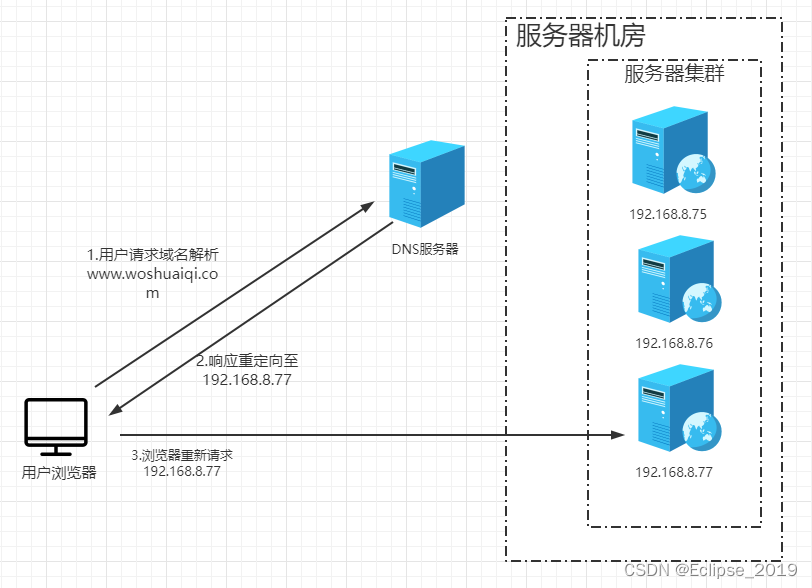
由上图可以看出,在DNS服务器中应该配置了多个A记录,如: www.woshuaiqi.com IN A 192.168.8.75; www.woshuaiqi.com IN A 192.168.8.76; www.woshuaiqi.com IN A 192.168.8.77;
因此,每次域名解析请求都会根据对应的负载均衡算法计算出一个不同的IP地址并返回,这样A记录中配置多个服务器就可以构成一个集群,并可以实现负载均衡。上图中,用户请求www.woshuaiqi.com,DNS根据A记录和负载均衡算法计算得到一个IP地址192.168.8.77,并返回给浏览器,浏览器根据该IP地址,访问真实的物理服务器192.168.8.77。所有这些操作对用户来说都是透明的,用户可能只知道www.woshuaiqi.com这个域名。
DNS域名解析负载均衡有如下优点:
-
将负载均衡的工作交给DNS,省去了网站管理维护负载均衡服务器的麻烦。
-
技术实现比较灵活、方便,简单易行,成本低,使用于大多数TCP/IP应用。
-
对于部署在服务器上的应用来说不需要进行任何的代码修改即可实现不同机器上的应用访问。
-
服务器可以位于互联网的任意位置。
-
同时许多DNS还支持基于地理位置的域名解析,即会将域名解析成距离用户地理最近的一个服务器地址,这样就可以加速用户访问,改善性能。
同时,DNS域名解析也存在如下缺点:
-
目前的DNS是多级解析的,每一级DNS都可能缓存A记录,当某台服务器下线之后,即使修改了A记录,要使其生效也需要较长的时间,这段时间,DNS任然会将域名解析到已下线的服务器上,最终导致用户访问失败。
-
不能够按服务器的处理能力来分配负载。DNS负载均衡采用的是简单的轮询算法,不能区分服务器之间的差异,不能反映服务器当前运行状态,所以其的负载均衡效果并不是太好。
-
.可能会造成额外的网络问题。为了使本DNS服务器和其他DNS服务器及时交互,保证DNS数据及时更新,使地址能随机分配,一般都要将DNS的刷新时间设置的较小,但太小将会使DNS流量大增造成额外的网络问题。 事实上,大型网站总是部分使用DNS域名解析,利用域名解析作为第一级负载均衡手段,即域名解析得到的一组服务器并不是实际提供服务的物理服务器,而是同样提供负载均衡服务器的内部服务器,这组内部负载均衡服务器再进行负载均衡,请请求发到真实的服务器上,最终完成请求。
1.1.3 反向代理负载均衡
请求过程:
用户发来的请求都首先要经过反向代理服务器,服务器根据用户的请求要么直接将结果返回给用户,要么将请求交给后端服务器处理,再返回给用户。
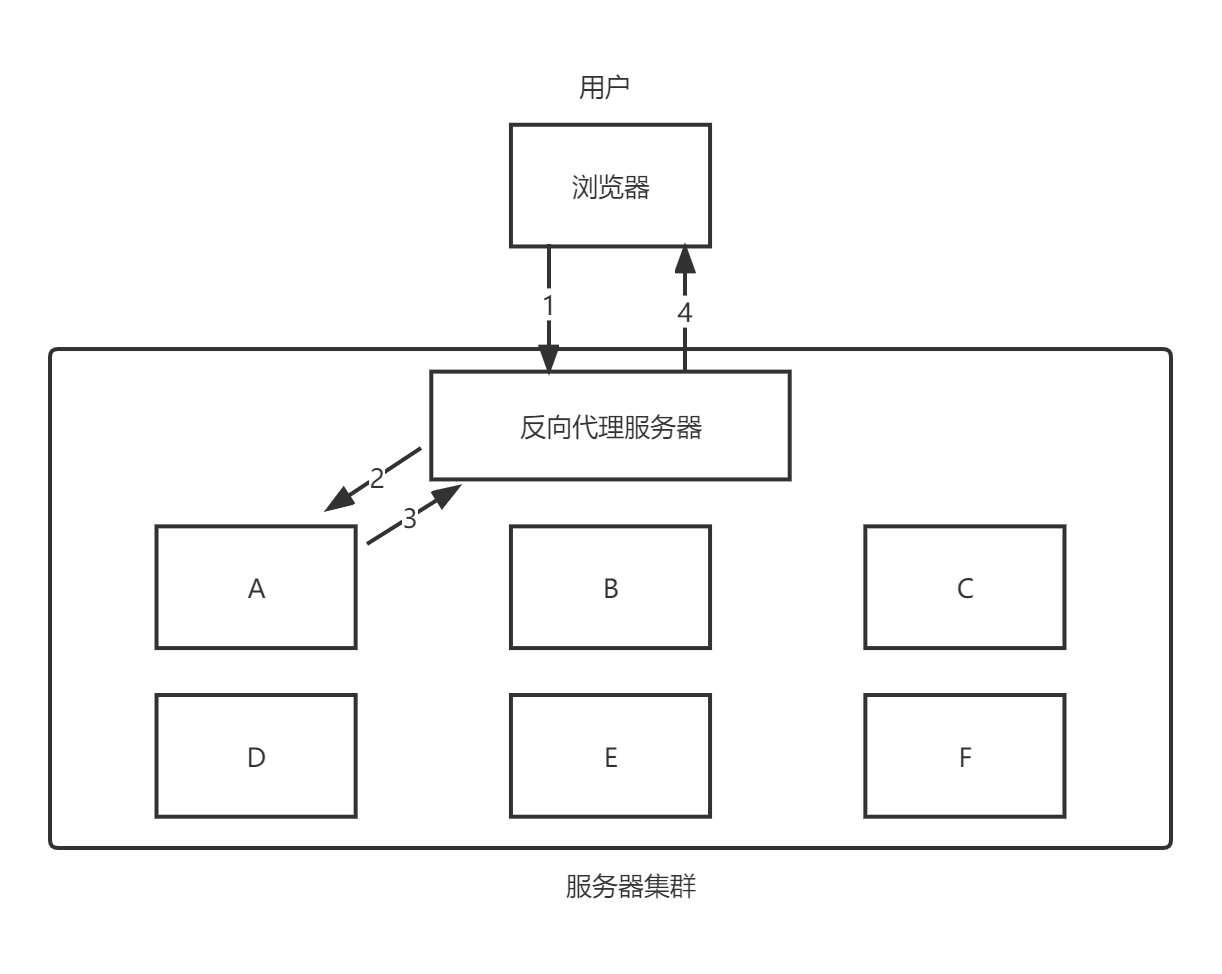
反向代理负载均衡
优点:
-
隐藏后端服务器。与HTTP重定向相比,反向代理能够隐藏后端服务器,所有浏览器都不会与后端服务器直接交互,从而能够确保调度者的控制权,提升集群的整体性能。
-
故障转移。与DNS负载均衡相比,反向代理能够更快速地移除故障结点。当监控程序发现某一后端服务器出现故障时,能够及时通知反向代理服务器,并立即将其删除。
-
合理分配任务 。HTTP重定向和DNS负载均衡都无法实现真正意义上的负载均衡,也就是调度服务器无法根据后端服务器的实际负载情况分配任务。但反向代理服务器支持手动设定每台后端服务器的权重。我们可以根据服务器的配置设置不同的权重,权重的不同会导致被调度者选中的概率的不同。
缺点:
-
调度者压力过大 。由于所有的请求都先由反向代理服务器处理,那么当请求量超过调度服务器的最大负载时,调度服务器的吞吐率降低会直接降低集群的整体性能。
-
制约扩展。当后端服务器也无法满足巨大的吞吐量时,就需要增加后端服务器的数量,可没办法无限量地增加,因为会受到调度服务器的最大吞吐量的制约。
1.2 常见算法
1.2.1 轮询
Round Robin
轮询算法按照顺序将新的请求分配给下一个服务器,最终实现平分请求。
优点:
实现简单,无需记录各种服务的状态,是一种无状态的负载均衡策略。
实现绝对公平
缺点:当各个服务器性能不一致的情况,无法根据服务器性能去分配,无法合理利用服务器资源。
代码实现
public class RoundRobinDemo {
@Data
public static class Server {
private int serverId;
private String name;
private String ip;
private int port;
private int weight;
public Server(int serverId, String name, String ip, int port) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
}
public Server(int serverId, String name, String ip, int port, int weight) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
this.weight = weight;
}
@Override
public String toString() {
return "serverId=" + serverId +
", name='" + name + '\'' +
", ip='" + ip + '\'' +
", port=" + port +
", weight=" + weight;
}
}
private static AtomicInteger NEXT_SERVER_COUNTER = new AtomicInteger(0);
//轮询算法的具体实现
private static int select(int modulo) {
for (; ; ) {
int current = NEXT_SERVER_COUNTER.get();
int next = (current + 1) % modulo;
boolean compareAndSet = NEXT_SERVER_COUNTER.compareAndSet(current, next);
if (compareAndSet) {
return next;
}
}
}
public static Server selectServer(List<Server> serverList) {
return serverList.get(select(serverList.size()));
}
public static void main(String[] args) {
List<Server> serverList = new ArrayList<>();
serverList.add(new Server(1, "服务器1","192.168.8.74",8080));
serverList.add(new Server(2, "服务器2","192.168.8.75",8080));
serverList.add(new Server(3, "服务器3","192.168.8.76",8080));
for (int i = 0; i < 10; i++) {
Server selectedServer = selectServer(serverList);
System.out.format("第%d次请求,选择服务器%s\n", i + 1, selectedServer.toString());
}
}
}1.2.2 加权轮询
WeightedRound-Robin
由于不同的服务器配置不同,因此它们处理请求的能力也不同,给配置高的机器配置相对较高的权重,让其处理更多的请求,给配置较低的机器配置较低的权重减轻期负载压力。加权轮询可以较好的解决这个问题。
思路
根据权重的大小让其获得相应被轮询到的机会。
已知:
服务器 权重 s1 1 s2 2 s3 3 可以根据权重我们在内存中创建一个这样的数组{s1,s2,s2,s3,s3,s3},然后再按照轮询的方式选择相应的服务器。
缺点:请求被分配到三台服务器上机会不够平滑。前3次请求都不会落在server3上。
Nginx实现了一种平滑的加权轮询算法,可以将请求平滑(均匀)的分配到各个节点上。
代码实现
public class WeightRoundRobin {
@Data
public static class Server {
private int serverId;
private String name;
private String ip;
private int port;
private int weight;
private int currentWeight;
public Server(int serverId, String name, String ip, int port) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
}
public Server(int serverId, String name, String ip, int port, int weight) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
this.weight = weight;
}
public void selected(int total) {
this.currentWeight -= total;
}
public void incrCurrentWeight() {
this.currentWeight += weight;
}
@Override
public String toString() {
return "serverId=" + serverId +
", name='" + name + '\'' +
", ip='" + ip + '\'' +
", port=" + port +
", weight=" + weight +
", currentWeight=" + currentWeight;
}
}
//加权轮询的核心逻辑
//每次选择权重最大的那个,被选择之后,将当前权重减去总权重,(算法怎么理解呢:
// 理解成排队去领奖,每次领完奖就排到队伍的最后继续排,而排队的总人数是总权重,
// 全重是几表示有多少个你的克隆)
public static Server selectServer(List<Server> serverList) {
int total = 0;
Server selectedServer = null;
int maxWeight = 0;
for (Server server : serverList) {
total += server.getWeight();
server.incrCurrentWeight();
//选取当前权重最大的一个服务器
if (selectedServer == null || maxWeight < server.getCurrentWeight()) {
selectedServer = server;
maxWeight = server.getCurrentWeight();
}
}
if (selectedServer == null) {
Random random = new Random();
int next = random.nextInt(serverList.size());
return serverList.get(next);
}
selectedServer.selected(total);
return selectedServer;
}
public static void main(String[] args) {
List<Server> serverList = new ArrayList<>();
serverList.add(new Server(1, "服务器1", "192.168.8.74", 8080, 1));
serverList.add(new Server(2, "服务器2", "192.168.8.75", 8080, 3));
serverList.add(new Server(3, "服务器3", "192.168.8.76", 8080, 10));
for (int i = 0; i < 10; i++) {
Server server = selectServer(serverList);
System.out.format("第%d次请求,选择服务器%s\n", i + 1, server.toString());
}
}
}1.2.3 随机
Random
思路:利用随机数从所有服务器中随机选取一台,可以用服务器数组下标获取。
优点:使用简单;
缺点:不适合机器配置不同的场
代码实现
public class RandomLoadBalanceDemo {
@Data
public static class Server {
private int serverId;
private String name;
private String ip;
private int port;
private int weight;
public Server(int serverId, String name, String ip, int port) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
}
public Server(int serverId, String name, String ip, int port, int weight) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
this.weight = weight;
}
@Override
public String toString() {
return "serverId=" + serverId +
", name='" + name + '\'' +
", ip='" + ip + '\'' +
", port=" + port +
", weight=" + weight;
}
}
//轮询算法的具体实现
public static Server selectServer(List<Server> serverList) {
Random selector = new Random();
int next = selector.nextInt(serverList.size());
return serverList.get(next);
}
public static void main(String[] args) {
List<Server> serverList = new ArrayList<>();
serverList.add(new Server(1, "服务器1","192.168.8.74",8080));
serverList.add(new Server(2, "服务器2","192.168.8.75",8080));
serverList.add(new Server(3, "服务器3","192.168.8.76",8080));
for (int i = 0; i < 10; i++) {
Server selectedServer = selectServer(serverList);
System.out.format("第%d次请求,选择服务器%s\n", i + 1, selectedServer.toString());
}
}
}1.2.4 加权随机
Weight Random
思路:这里我们是利用区间的思想,通过一个小于在此区间范围内的一个随机数,选中对应的区间(服务器),区间越大被选中的概率就越大。
已知:
服务器 权重 s1 1 s2 2 s3 3 s1:[0,1] s2:(1,3] s3 (3,6
代码实现
public class WeightRandomDemo {
@Data
public static class Server {
private int serverId;
private String name;
private String ip;
private int port;
private int weight;
public Server(int serverId, String name, String ip, int port) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
}
public Server(int serverId, String name, String ip, int port, int weight) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
this.weight = weight;
}
@Override
public String toString() {
return "serverId=" + serverId +
", name='" + name + '\'' +
", ip='" + ip + '\'' +
", port=" + port +
", weight=" + weight;
}
}
//算法的具体实现
public static Server selectServer(List<Server> serverList) {
int sumWeight = 0;
for (Server server : serverList) {
sumWeight += server.getWeight();
}
Random serverSelector = new Random();
int nextServerRange = serverSelector.nextInt(sumWeight);
int sum = 0;
Server selectedServer = null;
for (Server server : serverList) {
if (nextServerRange >= sum && nextServerRange < server.getWeight() + sum) {
selectedServer = server;
}
sum += server.getWeight();
}
return selectedServer;
}
public static void main(String[] args) {
List<Server> serverList = new ArrayList<>();
serverList.add(new Server(1, "服务器1","192.168.8.74",8080,1));
serverList.add(new Server(2, "服务器2","192.168.8.75",8080,5));
serverList.add(new Server(3, "服务器3","192.168.8.76",8080,10));
for (int i = 0; i < 10; i++) {
Server selectedServer = selectServer(serverList);
System.out.format("第%d次请求,选择服务器%s\n", i + 1, selectedServer.toString());
}
}
}1.2.5 Hash
思路:根据每个每个请求ip(也可以是某个标识)ip.hash() % server.size()
优点:将来自同一IP地址的请求,同一会话期内,转发到相同的服务器;实现会话粘滞。
缺点:目标服务器宕机后,会话会丢失;
代码实现
public class IpHashDemo {
@Data
public static class Server {
private int serverId;
private String name;
private String ip;
private int port;
public Server(int serverId, String name, String ip, int port) {
this.serverId = serverId;
this.name = name;
this.ip = ip;
this.port = port;
}
@Override
public String toString() {
return "serverId=" + serverId +
", name='" + name + '\'' +
", ip='" + ip + '\'' +
", port=" + port;
}
}
//算法的具体实现
public static Server selectServer(List<Server> serverList,String ip) {
int ipHash = ip.hashCode();
return serverList.get(ipHash % serverList.size());
}
public static void main(String[] args) {
List<Server> serverList = new ArrayList<>();
serverList.add(new Server(1, "服务器1","192.168.8.74",8080));
serverList.add(new Server(2, "服务器2","192.168.8.75",8080));
serverList.add(new Server(3, "服务器3","192.168.8.76",8080));
List<String> ips = Arrays.asList("192.168.8.74", "192.168.8.75", "192.168.8.76");
for (int i = 0; i < 10; i++) {
for (String ip : ips) {
Server selectedServer = selectServer(serverList, ip);
System.out.format("请求ip:%s,选择服务器%s\n", ip, selectedServer.toString());
}
}
}
}1.2.6 最少链接
思想:将请求分配到连接数最少的服务器上(目前处理请求最少的服务器)。
优点:根据服务器当前的请求处理情况,动态分配;
缺点:算法实现相对复杂,需要监控服务器请求连接数
第2章:RestTemplate应用
2.1 RESTful架构
REST(Representational State Transfer)表象化状态转变(表述性状态转变),基于HTTP、URI、XML、JSON等标准和协议,支持轻量级、跨平台、跨语言的架构设计。是Web服务的一种新的架构风格(一种思想)。
2.1.1 主要原则
-
对网络上所有的资源都有一个资源标志符。
-
对资源的操作不会改变标识符。
-
同一资源有多种表现形式(xml、json)
-
所有操作都是无状态的(Stateless)
符合上述REST原则的架构方式称为RESTful
2.1.2 操作
在Restful之前的操作:
http://127.0.0.1/user/query/1 GET 根据用户id查询用户数据
http://127.0.0.1/user/save POST 新增用户
http://127.0.0.1/user/update POST 修改用户信息
http://127.0.0.1/user/delete/1 GET/POST 删除用户信息
RESTful用法:
http://127.0.0.1/user/1 GET 根据用户id查询用户数据
http://127.0.0.1/user POST 新增用户
http://127.0.0.1/user PUT 修改用户信息
http://127.0.0.1/user DELETE 删除用户信息
之前的操作是没有问题的,大神认为是有问题的,有什么问题呢?你每次请求的接口或者地址,都在做描述,例如查询的时候用了query,新增的时候用了save,其实完全没有这个必要,我使用了get请求,就是查询.使用post请求,就是新增的请求,我的意图很明显,完全没有必要做描述,这就是为什么有了restful.
| http方法 | 资源操作 | 幂等 | 安全 |
|---|---|---|---|
| GET | SELECT | 是 | 是 |
| POST | INSERT | 否 | 否 |
| PUT | UPDATE | 是 | 否 |
| DELETE | DELETE | 是 | 否 |
幂等性:对同一REST接口的多次访问,得到的资源状态是相同的。
安全性:对该REST接口访问,不会使用服务器端资源的状态发生改变。
2.1.3 SpringMVC实现
SpringMVC原生态的支持了REST风格的架构设计
所涉及到的注解:
---@RequestMapping
---@PathVariable
---@ResponseBody
/**
* @author Eclipse_2019
* @create 2022/2/8 18:04
*/
@RequestMapping("restful/user")
@Controller
public class RestUserController {
@Autowired
private UserServiceImpl userService;
/**
* 根据用户id查询用户数据
*
* @param id
* @return
*/
@RequestMapping(value = "{id}", method = RequestMethod.GET)
@ResponseBody
public ResponseEntity<User> queryUserById(@PathVariable("id") Long id) {
try {
User user = this.userService.queryUserById(id);
if (null == user) {
// 资源不存在,响应404
return ResponseEntity.status(HttpStatus.NOT_FOUND).body(null);
}
// 200
// return ResponseEntity.status(HttpStatus.OK).body(user);
return ResponseEntity.ok(user);
} catch (Exception e) {
e.printStackTrace();
}
// 500
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(null);
}
/**
* 新增用户
*
* @param user
* @return
*/
@RequestMapping(method = RequestMethod.POST)
public ResponseEntity<Void> saveUser(@RequestBody User user) {
try {
this.userService.saveUser(user);
return ResponseEntity.status(HttpStatus.CREATED).build();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 500
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(null);
}
/**
* 更新用户资源
*
* @param user
* @return
*/
@RequestMapping(method = RequestMethod.PUT)
public ResponseEntity<Void> updateUser(@RequestBody User user) {
try {
this.userService.updateUser(user);
return ResponseEntity.status(HttpStatus.NO_CONTENT).build();
} catch (Exception e) {
e.printStackTrace();
}
// 500
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(null);
}
/**
* 删除用户资源
*
* @param id
* @return
*/
@RequestMapping(method = RequestMethod.DELETE)
public ResponseEntity<Void> deleteUser(@RequestParam(value = "id", defaultValue = "0") Long id) {
try {
if (id.intValue() == 0) {
// 请求参数有误
return ResponseEntity.status(HttpStatus.BAD_REQUEST).build();
}
this.userService.deleteUserById(id);
// 204
return ResponseEntity.status(HttpStatus.NO_CONTENT).build();
} catch (Exception e) {
e.printStackTrace();
}
// 500
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(null);
}
}2.1.4 状态码
GET
安全且幂等
获取表示
变更时获取表示(缓存)
200(OK) - 表示已在响应中发出
204(无内容) - 资源有空表示
301(Moved Permanently) - 资源的URI已被更新
303(See Other) - 其他(如,负载均衡)
304(not modified)- 资源未更改(缓存)
400 (bad request)- 指代坏请求(如,参数错误)
404 (not found)- 资源不存在
406 (not acceptable)- 服务端不支持所需表示
500 (internal server error)- 通用错误响应
503 (Service Unavailable)- 服务端当前无法处理请求
POST
不安全且不幂等
使用服务端管理的(自动产生)的实例号创建资源
创建子资源
部分更新资源
如果没有被修改,则不过更新资源(乐观锁)
200(OK)- 如果现有资源已被更改
201(created)- 如果新资源被创建
202(accepted)- 已接受处理请求但尚未完成(异步处理)
301(Moved Permanently)- 资源的URI被更新
303(See Other)- 其他(如,负载均衡)
400(bad request)- 指代坏请求
404 (not found)- 资源不存在
406 (not acceptable)- 服务端不支持所需表示
409 (conflict)- 通用冲突
412 (Precondition Failed)- 前置条件失败(如执行条件更新时的冲突)
415 (unsupported media type)- 接受到的表示不受支持
500 (internal server error)- 通用错误响应
503 (Service Unavailable)- 服务当前无法处理请求
PUT
不安全但幂等
用客户端管理的实例号创建一个资源
通过替换的方式更新资源
如果未被修改,则更新资源(乐观锁)
200 (OK)- 如果已存在资源被更改
201 (created)- 如果新资源被创建
301(Moved Permanently)- 资源的URI已更改
303 (See Other)- 其他(如,负载均衡)
400 (bad request)- 指代坏请求
404 (not found)- 资源不存在
406 (not acceptable)- 服务端不支持所需表示
409 (conflict)- 通用冲突
412 (Precondition Failed)- 前置条件失败(如执行条件更新时的冲突)
415 (unsupported media type)- 接受到的表示不受支持
500 (internal server error)- 通用错误响应
503 (Service Unavailable)- 服务当前无法处理请求
DELETE
不安全但幂等
删除资源
200 (OK)- 资源已被删除
301 (Moved Permanently)- 资源的URI已更改
303 (See Other)- 其他,如负载均衡
400 (bad request)- 指代坏请求
404 (not found)- 资源不存在
409 (conflict)- 通用冲突
500 (internal server error)- 通用错误响应
503 (Service Unavailable)- 服务端当前无法处理请求2.2 RestTemplate
2.2.1 是什么
传统情况下在java代码里访问restful服务,一般使用Apache的HttpClient。不过此种方法使用起来太过繁琐。spring提供了一种简单便捷的模板类来进行操作,这就是RestTemplate。
2.2.2 使用
定义一个简单的restful接口
@RestController
public class TestController
{
@RequestMapping(value = "testPost", method = RequestMethod.POST)
public ResponseBean testPost(@RequestBody RequestBean requestBean)
{
ResponseBean responseBean = new ResponseBean();
responseBean.setRetCode("0000");
responseBean.setRetMsg("succ");
return responseBean;
}
}使用RestTemplate访问该服务
//请求地址
String url = "http://localhost:8080/testPost";
//入参
RequestBean requestBean = new RequestBean();
requestBean.setTest1("1");
requestBean.setTest2("2");
requestBean.setTest3("3");
RestTemplate restTemplate = new RestTemplate();
ResponseBean responseBean = restTemplate.postForObject(url, requestBean, ResponseBean.class); 从这个例子可以看出,使用restTemplate访问restful接口非常的简单粗暴无脑。(url, requestMap, ResponseBean.class)这三个参数分别代表 请求地址、请求参数、HTTP响应转换被转换成的对象类型。
RestTemplate方法的名称遵循命名约定,第一部分指出正在调用什么HTTP方法,第二部分指示返回的内容。本例中调用了restTemplate.postForObject方法,post指调用了HTTP的post方法,Object指将HTTP响应转换为您选择的对象类型。
RestTemplate定义了36个与REST资源交互的方法,其中的大多数都对应于HTTP的方法。其实,这里面只有11个独立的方法,其中有十个有三种重载形式,而第十一个则重载了六次,这样一共形成了36个方法。
-
delete() 在特定的URL上对资源执行HTTP DELETE操作
-
exchange() 在URL上执行特定的HTTP方法,返回包含对象的ResponseEntity,这个对象是从响应体中映射得到的
-
execute() 在URL上执行特定的HTTP方法,返回一个从响应体映射得到的对象
-
getForEntity() 发送一个HTTP GET请求,返回的ResponseEntity包含了响应体所映射成的对象
-
getForObject() 发送一个HTTP GET请求,返回的请求体将映射为一个对象
-
postForEntity() POST 数据到一个URL,返回包含一个对象的ResponseEntity,这个对象是从响应体中映射得到的
-
postForObject() POST 数据到一个URL,返回根据响应体匹配形成的对象
-
headForHeaders() 发送HTTP HEAD请求,返回包含特定资源URL的HTTP头
-
optionsForAllow() 发送HTTP OPTIONS请求,返回对特定URL的Allow头信息
-
postForLocation() POST 数据到一个URL,返回新创建资源的URL
-
put() PUT 资源到特定的URL
实际上,由于Post 操作的非幂等性,它几乎可以代替其他的CRUD操作.
第3章:Ribbon简介与应用
3.1 简介
目前主流的负载方案分为以下两种:
-
集中式负载均衡,在消费者和服务提供方中间使用独立的代理方式进行负载,有硬件的(比如 F5),也有软件的(比如 Nginx)。
-
客户端自己做负载均衡,根据自己的请求情况做负载,Ribbon 就属于客户端自己做负载。
Ribbon 是一个基于 HTTP和TCP的客户端负载均衡工具。通过 Spring Cloud 的封装,可以让我们轻松地将面向服务的 REST 模版请求自动转换成客户端负载均衡的服务调用。
Spring Cloud Ribbon 虽然只是一个工具类框架,它不像服务注册中心、配置中心、API 网关那样需要独立部署,但是它几乎存在于每一个 Spring Cloud 构建的微服务和基础设施中。因为微服务间的调用,API 网关的请求转发等内容,实际上都是通过 Ribbon 来实现的(https://github.com/Netflix/ribbon)。
Ribbon主要提供:
-
客户端负载均衡
-
容错处理
-
支持多协议的异步通信。支持HTTP、TCP、UDP协议。
-
支持缓存和批量处理
Ribbon模块介绍:
-
ribbon: Ribbon功能应用入口。使用Ribbon的功能可以通过初始化应用入口,调用接口实现。该模块依赖其他模版实现所需功能,比如容错处理ribbon依赖Histrix。
-
ribbon-loadbalancer:负载均衡功能入口。如果仅需要负载均衡功能,可以使用单独使用该模块。
-
ribbon-eureka:基于Eureka客户端实现可用服务列表管理
-
ribbon-transport: 具备客户端负载均衡能力的,基于RxNetty框架能够支持HTTP、TCP、UDP协议的通信客户端。
-
ribbon-httpclient: 具备客户端负载均衡能力的,基于Apache HttpClient,支持REST风格的HTTP请求客户端。
-
ribbon-core: 客户端配置APIs和其他共享APIs。
-
ribbon-example:使用例子。
3.2 对比
与Nginx的对比
-
Nginx是一种服务器端负载均衡 ,客户端所有请求统一交给 nginx,由 nginx 进行实现负载均衡请求转发。
-
Ribbon是客户端负载均衡 Ribbon 是从 eureka 注册中心服务器端上获取服务注册信息列表,缓存到本地,然后在本地实现轮询负载均衡策略。既在客户端实现负载均衡。
-
应用场景的区别:
-
Nginx适合于服务器端实现负载均衡比如 Tomcat ,Ribbon适合与在微服务中RPC远程调用实现本地服务负载均衡,比如 Dubbo、SpringCloud 中都是采用本地负载均衡。
-
spring cloud的Netflix中提供了两个组件实现软负载均衡调用:ribbon和feign。
-
Ribbon是一个基于 HTTP 和 TCP 客户端的负载均衡器,它可以在客户端配置 ribbonServerList(服务端列表),然后轮询请求以实现均衡负载。
-
3.3 应用
不含Eureka
-
先创建两个服务,用于负载均衡
Server 1 和Server2 的端口号要不同,不然起不来
Server 1接口如下:
@RestController public class TestController { @GetMapping("/user/{id}") public String Info(@PathVariable Long id) { return "this is client1 ,id=" + id; } }Server 2接口如下:
@RestController public class TestController { @GetMapping("/user/{id}") public String Info(@PathVariable Long id) { return "this is Client2,id=" + id; } }启动类都是一样的,如下:
@SpringBootApplication public class Application { public static void main( String[] args ) { SpringApplication.run(Application.class, args); } } -
创建一个调用方来请求这个接口
引依赖包
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-commons</artifactId> <version>2.2.3.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-ribbon</artifactId> <version>2.2.3.RELEASE</version> </dependency>配置启动类,并注入 RestTemplate
import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.loadbalancer.LoadBalanced; import org.springframework.context.annotation.Bean; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.web.client.RestTemplate; @EnableScheduling @SpringBootApplication public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } @Bean @LoadBalanced public RestTemplate restTemplate() { return new RestTemplate(); } }配置一下 application.properties,如下:
ribbon-test.ribbon.listOfServers=127.0.0.1:2223,127.0.0.1:2222 # ribbon连接超时 default-test.ribbon.ConnectTimeout=500 # ribbon读超时 default-test.ribbon.ReadTimeout=8000 ######## management ######## management.security.enabled=false endpoints.health.sensitive=false -
验证
再创建一个 测试方法来验证是否生效,放在test 目录下面,代码如下:
import com.test.Application; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import org.springframework.web.client.RestTemplate; @RunWith(SpringRunner.class) @SpringBootTest(classes = Application.class) public class RibbonBalanceClientTest { @Autowired private RestTemplate restTemplate; @Test public void contextLoads() { for (int i = 0; i < 10; i++) { String forObject = restTemplate.getForObject("http://ribbon-test/user/1000", String.class); System.out.println("============================"); System.out.println(forObject); } } }先启动 两个server ,然后在 测试 测试类 ,结果如下:
============================ this is Client2,id=1000 ============================ this is client1 ,id=1000 ============================ this is Client2,id=1000 ============================ this is client1 ,id=1000 ============================ this is Client2,id=1000 ============================ this is client1 ,id=1000 ============================ this is Client2,id=1000 ============================ this is client1 ,id=1000 ============================ this is Client2,id=1000 ============================ this is client1 ,id=1000从结果可以看出实现了负载均衡,默认是 轮询策略,Client1和 clien2 依次调用。
3.3.1 请求超时机制配置
Ribbon 中有两种和时间相关的设置,分别是请求连接的超时时间和请求处理的超时时间,设置规则如下:
# 请求连接的超时时间
ribbon.ConnectTimeout=2000 (默认值:2000)
# 请求处理的超时时间
ribbon.ReadTimeout=5000 (默认值:5000)
# 也可以为每个Ribbon客户端设置不同的超时时间, 通过服务名称进行指定:
goods-serviceo.ribbon.ConnectTimeout=2000
goods-service.ribbon.ReadTimeout=50003.3.2 并发连接数
Ribbon可以通过下面的配置项,来限制httpclient连接池的最大连接数量、以及针对不同host的最大连接数量。
Ribbon底层的网络通信,采用的是HttpClient中的PoolingHttpClientConnectionManager连接池,连接池的好处是避免频繁建立连接(针对单个目标地址)带来的性能开销,但是维护过多的链接会对客户端造成内存以及维护上的成本。
所以,可以通过
MaxTotalConnections限制总的连接数量,或者通过MaxConnectionsPerHost限制针对每个host的最大连接数。
# 最大连接数
ribbon.MaxTotalConnections=500 (默认值:200)
# 每个host最大连接数
ribbon.MaxConnectionsPerHost=500 (默认值:50)3.3.3 负载均衡配置
负载均衡的核心,是通过负载均衡算法来实现对目标服务请求的分发。Ribbion中默认提供了7种负载均衡算法:
-
BestAvailableRule,先过滤掉不可用的处于断路器跳闸转态的服务,然后选择一个并发量最小的服务。
-
ZoneAvoidanceRule,
默认负载,复合判断server所在区域的性能和server的可用性进行服务的选择。 -
AvailabilityFilteringRule, 先过滤掉故障实例,再选择并发量较小的实例
-
RoundRobinRule,轮询负载
-
WeightedResponseTimeRule,每30秒计算一次服务器响应时间,以响应时间作为权重,响应时间越短的服务器被选中的概率越大。
-
ResponseTimeWeightedRule(已经过期,改成了WeightedResponseTimeRule),
-
RandomRule,随机负载
-
RetryRule,重试,先按RoundRobinRule进行轮询,如果失败就在指定时间内进行重试
如何指定Ribbon的负载策略呢?
<clientName>.ribbon.NFLoadBalancerRuleClassName: Should implement IRule(负载均衡算法)修改mall-portal项目中的application.properties文件,指定负载均衡算法。
goods-service.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RandomRule验证方法:
-
在
BaseLoadBalancer.chooseServer()方法中加断点public Server chooseServer(Object key) { if (counter == null) { counter = createCounter(); } counter.increment(); if (rule == null) { //断点,查看rule所属实例 return null; } else { } } -
在
RandomRule.choose()方法增加断点,观察请求是否进入。 除此之外,Ribbon还提供了自定义负载均衡的扩展机制,只需要继承AbstractLoadBalancerRule抽象类即可。
3.3.4 自定义负载均衡
自定义负载均衡的实现主要分几个步骤:
-
继承
AbstractLoadBalancerRule抽象类 -
通过配置让Ribbon使用自定义负载策略。
public class DefineIpHashRule extends AbstractLoadBalancerRule {
public Server choose(ILoadBalancer lb, Object key){
if(lb==null){
return null;
}else {
Server server = null;
while (server == null) {
//获取可用的服务实例列表
List<Server> upList = lb.getReachableServers();
//获取所有的服务实例列表
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int index=ipAddressHash(serverCount);
server = upList.get(index);
}
return server;
}
}
private int ipAddressHash(int serverCount){
ServletRequestAttributes requestAttributes=(ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
String remoteAddr=requestAttributes.getRequest().getRemoteAddr();
int code=Math.abs(remoteAddr.hashCode());
return code%serverCount;
}
@Override
public Server choose(Object key) {
return choose(getLoadBalancer(),key);
}
@Override
public void initWithNiwsConfig(IClientConfig iClientConfig) {
}
}ILoadBalancer接口实现类做了以下的一些事情:
维护了存储服务实例Server对象的二个列表。一个用于存储所有服务实例的清单,一个用于存储正常服务的实例清单
初始化得到可用的服务列表,启动定时任务去实时的检测服务列表中的服务的可用性,并且间断性的去更新服务列表,结合注册中心。
选择可用的服务进行调用(这个一般交给IRule去实现,不同的轮询策略)
修改application.properties文件
spring-cloud-user-service.ribbon.NFLoadBalancerRuleClassName=com.mallportal.DefineIpHashRule3.3.5 Ribbon核心之Ping机制
在ribbon负载均衡器中,提供了ping机制,每隔一段时间,就会去ping服务器,由 com.netflix.loadbalancer.IPing 接口去实现。
单独使用ribbon,不会激活ping机制,默认采用DummyPing(在RibbonClientConfiguration中实例化),isAlive()方法直接返回true。
ribbon和eureka集成,默认采用NIWSDiscoveryPing(在EurekaRibbonClientConfiguration中实例化的),只有服务器列表的实例状态为up的时候才会为Alive。
IPing中默认内置了一些实现方法如下。
-
PingUrl: 使用httpClient对目标服务逐个实现Ping操作
-
DummyPing: 默认认为对方服务是正常的,直接返回true
-
NoOpPing:永远返回true
3.3.6 请求重试机制
在网络通信中,有可能会存在由网络问题或者目标服务异常导致通信失败,这种情况下我们一般会做容错设计,也就是再次发起请求进行重试。
Ribbon提供了一种重试的负载策略:RetryRule,可以通过下面这个配置项来实现
spring-cloud-user-service.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RetryRule由于在单独使用Ribbon的机制下,并没有开启Ping机制,所以所有服务默认是认为正常的,则这里并不会发起重试。如果需要演示重试机制,需要增加PING的判断。
-
引入依赖包
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> </dependency> -
创建一个心跳检查的类
public class HealthChecker implements IPing { @Override public boolean isAlive(Server server) { String urlStr = "http://"+server.getId()+"/healthCheck"; boolean isAlive = false; HttpClient httpClient = new DefaultHttpClient(); HttpUriRequest getRequest = new HttpGet(urlStr); try { HttpResponse response = httpClient.execute(getRequest); isAlive = response.getStatusLine().getStatusCode() == 200; }catch (Exception e){ }finally { getRequest.abort(); } return isAlive; } } -
修改
mall-portal中application.properties文件,添加自定义心跳检查实现,以及心跳检查间隔时间。goods-service.ribbon.NFLoadBalancerPingClassName=com.mallportal.HealthChecker goods-service.ribbon.NFLoadBalancerPingInterval=3 -
在
goods-service这个模块中,增加一个心跳检查的接口@GetMapping("/healthCheck") public String health(){ return "SUCCESS"; } -
测试服务启动+停止,对于请求的影响变化。
第4章:Loadbalancer
参考官方文档:Getting Started | Client-Side Load-Balancing with Spring Cloud LoadBalancer
LoadBalancer 是Spring Cloud自研的组件,支持WebFlux。
由于Ribbon停止更新进入维护状态,所以Spring Cloud不得不研发一套新的Loadbalancer机制进行替代。
在Spring Cloud 2020版本之后,Ribbon已经被下掉了,直接用Loadbalancer取代,当然我们仍然可以继续使用Ribbon。
-
引入
Loadbalancer相关jar包<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> </dependency> -
定义一个配置类,这个配置类通过硬编码的方式写死了
goods-service这个服务的实例列表,代码如下@Configuration public class GoodsServiceConfiguration { @Bean ServiceInstanceListSupplier serviceInstanceListSupplier(){ return new GoodsServiceInstanceListSupplier("goods-service"); } } //自定义实例列表 class GoodsServiceInstanceListSupplier implements ServiceInstanceListSupplier{ private final String serviceId; GoodsServiceInstanceListSupplier(String serviceId){ this.serviceId=serviceId; } @Override public String getServiceId() { return serviceId; } @Override public Flux<List<ServiceInstance>> get() { //Flux.just可以指定序列中包含的全部元素。创建出来的 Flux 序列在发布这些元素之后会自动结束 return Flux.just(Arrays.asList(new DefaultServiceInstance(serviceId+"1",serviceId,"localhost",9091,false), new DefaultServiceInstance(serviceId+"2",serviceId,"localhost",9081,false))); } } -
创建一个配置类,注入一个LoadBalancerClient
@Configuration @LoadBalancerClient(name="goods-service",configuration = GoodsServiceConfiguration.class) public class WebClientConfiguration { @Bean @LoadBalanced WebClient.Builder webClientBuilder(){ return WebClient.builder(); } } -
修改测试类
@Slf4j @RestController @RequestMapping("/order") public class OrderController { @Autowired private WebClient.Builder loadBalancedWebClientBuilder; /** * 下单 * WebFlux需要用Mono或者Flux,它是WebFLux的核心。 */ @GetMapping public Mono<String> order(){ log.info("begin order"); return loadBalancedWebClientBuilder.build().get().uri("http://goods-service/getGoodsById").retrieve().bodyToMono(String.class); } } -
为了更好的看到效果,修改
goods-service模块,打印每个服务的端口号码。@RestController public class GoodsController { @Value("${server.port}") private String port; @GetMapping("/getGoodsById") public String getGoodsById(){ System.out.println("我是:"+port); return "返回商品详细信息"; } }
在Spring Cloud 2020.x版本中,Spring Cloud Netflix只留下了Eureka,其他的组件都已经移除了。
下文预告
-
能自己推导出Ribbon的核心流程
-
通过看源码验证这一核心流程
















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











