







一个快速指南,为您构建一个聊天机器人网站,可以接受外部文档作为上下文。
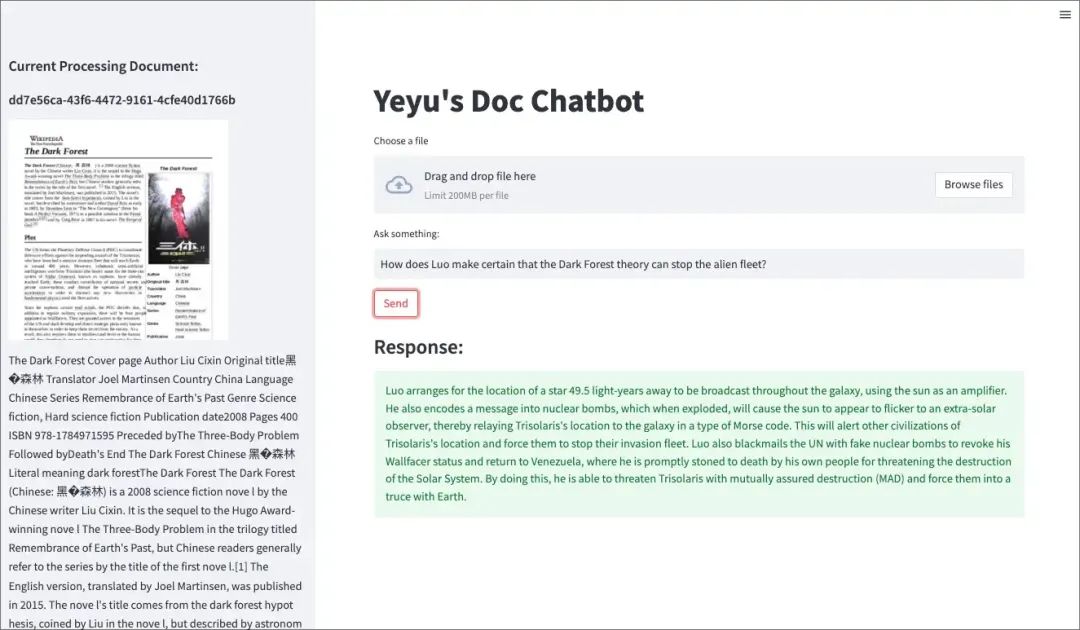
随着每天涌现的信息和知识在我的屏幕上呈现,我们面临着人类阅读和记忆自然限制的挑战,这使得跟上信息更新变得越来越困难。现在,像ChatGPT和Llama这样的大型语言模型(LLMs)提供了一种存储和处理大量信息的潜在解决方案,只需要简单的提示就可以快速直接地获得响应。然而,LLMs的表现取决于它们所训练的数据质量,尽管它们的大部分数据集已经非常庞大,但这些数据仍然属于“昨天”的数据。
我经常感到很困扰,因为我很难阅读用户手册或药品说明书,里面包含了大量陌生的信息,也很难在技术论文或报告中查找特定数据,即使一本新书非常吸引我,我也会很不耐烦地阅读。目前,ChatGPT或Bard无法直接帮助我获取我需要的信息。
在创建了多个基于GPT APIs和其他库的聊天机器人,如私人聊天、语音聊天和图像聊天之后,现在我正在考虑构建一个基于文档的聊天机器人,它可以从各种数据资源中学习新知识,并在我查询时提供准确有用的响应,而且成本可接受。
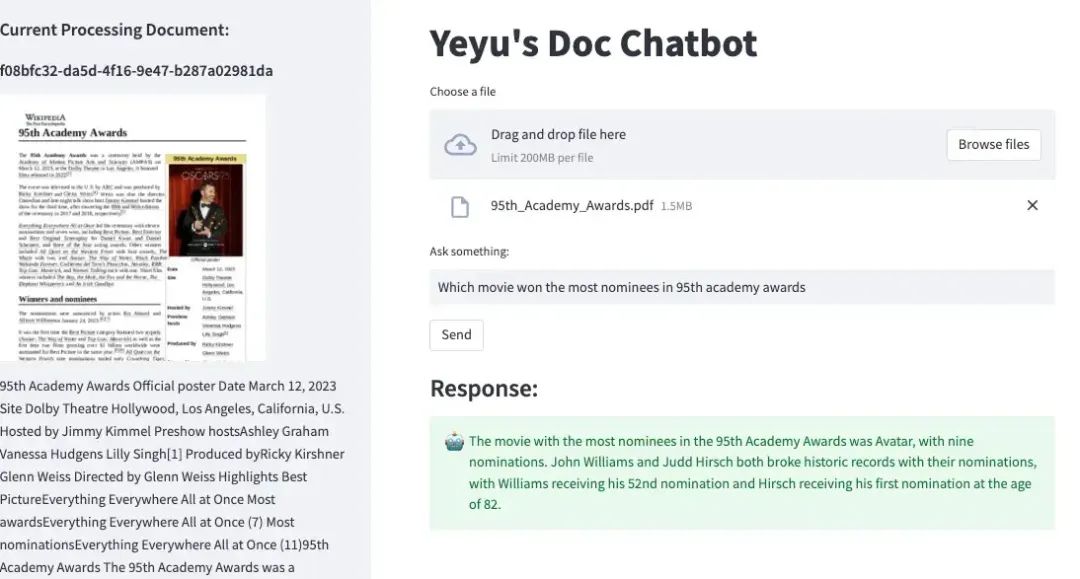
为了实现这个目标,有许多方法可以利用,其中一种是上下文学习,另一种是微调。由于学习领域非常多样化,上下文学习技术是我最好的选择。经过一些研究,我决定使用LlamaIndex作为我的文档聊天机器人的基础,以进行上下文学习,并继续使用OpenAI的完成和嵌入功能进行演示。
在本文中,我将向您介绍开发过程,确保您理解并能够复制您自己的文档聊天机器人。
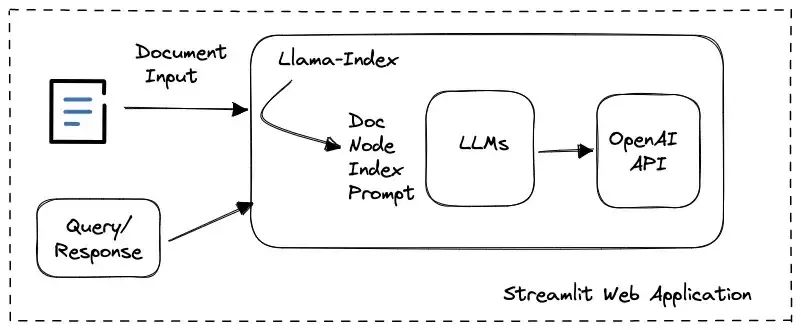
1、Block Diagram(系统框图)
在这个简单的聊天机器人中,我们使用llama-index作为基础,并开发Streamlit Web应用程序,提供用户输入和文档查询交互的显示。使用llamaIndex工具包,我们不必担心OpenAI中的API调用,因为其内部数据结构和LLM任务管理很容易消除嵌入使用的复杂性或提示大小限制的问题。
2、OpenAI API密钥
LlamaIndex被设计为与各种LLMs兼容,默认情况下,它使用OpenAI的text-davinci-003模型和text-embedding-ada-002-v2进行嵌入操作。因此,当我们决定基于OpenAI GPT模型实现文档聊天机器人时,我们应该向程序提供我们的OpenAI API密钥。插入我们的密钥所需做的唯一事情是通过环境变量提供它:
import os
os.environ["OPENAI_API_KEY"] = '{my-openai_key}'3、LlamaIndex
LlamaIndex是一个Python库,提供了用户私有数据与大型语言模型之间的中心接口。它提供以下功能:
数据连接器:LlamaIndex可以连接各种数据源,包括API、PDF、文档和SQL数据库。这使得您可以在不实现额外代码的情况下,将现有数据与LLMs一起使用。这实际上是我选择它作为应用程序的关键原因。
提示限制:Llam
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2472
2472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









