







 本文探讨信息度量的量化难题,特别是在自然语言处理中的重要性。通过吴军先生的足球冠军猜测例子,介绍了香农的信息熵概念,并讨论了如何通过优化猜测策略减少不确定性。同时,解释了互信息和相对熵在衡量信息相关性和分布差异中的作用,以解决如机器翻译中的二义性问题。
本文探讨信息度量的量化难题,特别是在自然语言处理中的重要性。通过吴军先生的足球冠军猜测例子,介绍了香农的信息熵概念,并讨论了如何通过优化猜测策略减少不确定性。同时,解释了互信息和相对熵在衡量信息相关性和分布差异中的作用,以解决如机器翻译中的二义性问题。
就我个人而言觉得信息的度量是十分难量化的。也的确是这样,平日一个人说的一句话有多少信息是很难度量得到的。可是在自然语言处理中,信息度量的量化又十分重要。《数学之美》一书中吴军先生举了一个非常好的例子。他假设了一种情形,他向一个人猜测1-32号足球队伍中哪支队伍是世界杯的冠军,他如果采用五五分的方法逐步缩小范围那么需要五次就能知道哪支队伍是冠军,假设每向对方询问一次需要花费一元,那么谁是世界杯冠军这条信息则需要花费五元。而香农在他的论文“通信的数学原理”中使用比特来度量信息量。
其实在上述例子中,是可以优化的。每次的猜测不一定一定要五五分,可以将少数的夺冠热门分为一组,这样就可以大大降低猜测需要耗费的次数。当每支队伍夺冠希望不等时,香农使用了一个公式来对这种情况的信息进行度量。

其中H为信息熵,单位是比特。p1, p2....分别是这32支队伍夺冠的概率。当概率相同时,信息的熵就是5比特。而对于随机变量X,它的熵定义如下:
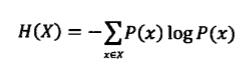
变量的不确定性越大熵也越大
事物往往是有许多不确定性的,这时需要引入信息I,当I>U时我们可以说不确定性被消除了,但是当I<U时,只能说这些信息消除了事物的一部分不确定性。吴军先生举了网页搜索的例子,当用户只输入某些常用关键词,会出来许多的结果,这时需要挖掘隐藏的信息以确定用户真正想要查找的信息从而给用户提供正确的网页。基于上述公式,如果我们知道一些情况Y,那么在Y条件下X的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1929
1929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









