









基于Python实现豆瓣电影爬虫
1 基于Python实现豆瓣电影爬虫
1.1 抓取TOP250电影数据
观察链接发现TOP250每页25个电影信息,因此通过拼接URL爬取250部电影信息:
url = f"https://movie.douban.com/top250?start={str(start)}&filter="
import time
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options
from pymongo import MongoClient
from config import MONGODB_URL
client = MongoClient(MONGODB_URL)
db_douban = client['douban']
col_top250 = db_douban['top250']
# 打开firefox浏览器
options = Options()
options.headless = False
driver = webdriver.Firefox(options=options)
driver.set_window_size(1500, 1200)
time.sleep(2)
for start in range(0, 250, 25):
# 访问douban
url = f"https://movie.douban.com/top250?start={str(start)}&filter="
print(">> ", url)
driver.get(url)
time.sleep(2)
ol_movie = driver.find_element(By.CSS_SELECTOR, '.grid_view')
li_movie_list = ol_movie.find_elements(By.TAG_NAME, 'li')
for li_movie in li_movie_list:
# 获取电影海报
pic_url = li_movie.find_element(By.CSS_SELECTOR, '.item > .pic > a > img').get_attribute('src')
# 获取top250排名
rank = li_movie.find_element(By.CSS_SELECTOR, '.item > .pic > em').text
# 获取电影名称
movie_name_list = []
a_movie_name = li_movie.find_element(By.CSS_SELECTOR, '.item > .info > .hd > a')
span_movie_name_list = a_movie_name.find_elements(By.TAG_NAME, 'span')
for title in span_movie_name_list:
movie_name_list.append(title.text)
# 获取电影URL
movie_url = a_movie_name.get_attribute('href')
movie_urls = col.distinct("电影链接")
print(">> ", movie_urls)
if movie_url in movie_urls:
continue
# 获取导演和演员信息
content = li_movie.find_element(By.CSS_SELECTOR, '.item > .info > .bd > p:nth-child(1)').text
content = content.split('\n')
if "导演:" in content[0]:
if "主演:" in content[0]:
temp = content[0].split('导演:')[1]
# print(temp)
director = temp.split('主演:')[0].strip()
actor = temp.split('主演:')[1].strip()
else:
director = content[0].split('导演:')[0].strip()
actor = ""
else:
director = content[0].strip()
actor = ""
# 获取上映时间、制片地区、类型
date = content[1].split(' / ')[0]
location = content[1].split(' / ')[1]
type = content[1].split(' / ')[2]
# 获取电影评分
rating_num = li_movie.find_element(By.CSS_SELECTOR, '.item > .info > .bd > .star > .rating_num').text
# 获取评价人数
rating_prople = li_movie.find_element(By.CSS_SELECTOR, '.item > .info > .bd > .star > span:nth-child(4)').text
print('------------------------')
print(pic_url, content)
print(movie_url, movie_name_list)
print(director, actor, date, location, type, rating_num, rating_prople)
movie = {
'电影海报': pic_url,
'电影名称': movie_name_list,
'电影链接': movie_url,
'导演': director,
'主演': actor,
'上映时间': date,
'制片地区': location,
'类型': type,
'评分': rating_num,
'评价人数': rating_prople,
'Top250排名': rank
}
col.insert_one(movie)
1.2 抓取电影分类数据
通过selenium模拟点击加载22个电影分类数据
client = MongoClient(MONGODB_URL)
db_douban = client['douban']
col_movie_types = db_douban['movie_types']
# 打开firefox浏览器
options = Options()
options.headless = False
driver = webdriver.Firefox(options=options)
driver.set_window_size(1500, 1200)
time.sleep(2)
# 访问douban
driver.get('https://movie.douban.com/explore')
time.sleep(2)
# 共22个电影类型
movie_type_list = []
driver.find_element(By.CSS_SELECTOR, 'div.explore-selector-item').click()
time.sleep(3)
ul_type = driver.find_element(By.CSS_SELECTOR, '.tag-group-list')
li_type_list = ul_type.find_elements(By.TAG_NAME, 'li')
for li_type in li_type_list:
movie_type = li_type.find_element(By.CSS_SELECTOR, 'span').text
movie_type_list.append(movie_type)
col.insert_one({'电影类型': movie_type_list})
1.3 抓取所有电影数据
client = MongoClient(MONGODB_URL)
db_douban = client['douban']
col_movies = db_douban['movies']
# 打开firefox浏览器
options = Options()
options.headless = False
driver = webdriver.Firefox(options=options)
driver.set_window_size(1500, 1200)
time.sleep(2)
# 访问douban
driver.get('https://movie.douban.com/explore')
time.sleep(2)
# 共22个电影类型
for num_type in range(1, 23):
driver.find_element(By.CSS_SELECTOR, 'div.explore-selector-item').click()
time.sleep(3)
ul_type = driver.find_element(By.CSS_SELECTOR, '.tag-group-list')
li_type_list = ul_type.find_elements(By.TAG_NAME, 'li')
li_type = li_type_list[num_type]
movie_type = li_type.find_element(By.CSS_SELECTOR, 'span').text
print(num_type, movie_type)
li_type.click()
time.sleep(3)
# 通过pagedown按键滑动加载页面
click_pagedown(driver, 2)
count = 0
while is_element_exist(driver, '.explore-more'):
load_more = driver.find_element(By.CSS_SELECTOR, '.explore-more')
load_more.click()
click_pagedown(driver, 2)
ul_movie = driver.find_element(By.CSS_SELECTOR, '.explore-list')
li_movie_list = ul_movie.find_elements(By.TAG_NAME, 'li')
start = count
end = len(li_movie_list)
for num_movie in range(start, end):
count += 1
li_movie = li_movie_list[num_movie]
# 获取电影URL
CSS_movie_url = 'a:nth-child(1)'
movie_url = li_movie.find_element(By.CSS_SELECTOR, CSS_movie_url).get_attribute('href')
movie_urls = col.distinct("电影链接")
if movie_url in movie_urls:
continue
# 获取电影海报
CSS_pic = 'a:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > img:nth-child(1)'
pic_url = li_movie.find_element(By.CSS_SELECTOR, CSS_pic).get_attribute('src')
# 获取电影名称
CSS_movie_info = 'a:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(1)'
div_movie_info = li_movie.find_element(By.CSS_SELECTOR, CSS_movie_info)
CSS_name = 'div:nth-child(1) > span:nth-child(1)'
movie_name = div_movie_info.find_element(By.CSS_SELECTOR, CSS_name).text
# 获取上映时间、制片地区、类型、导演、演员信息
CSS_content = 'div:nth-child(1) > div:nth-child(2)'
content = div_movie_info.find_element(By.CSS_SELECTOR, CSS_content).text
# 获取电影评分
CSS_rating = 'div:nth-child(2) > span:nth-child(2)'
rating_num = div_movie_info.find_element(By.CSS_SELECTOR, CSS_rating).text
print('------------------------')
print(pic_url, content)
print(movie_url, start, end, num_movie, movie_type, movie_name, rating_num)
movie = {
'电影名称': movie_name,
'分类': movie_type,
'简略信息': content,
'评分': rating_num,
'导演': "",
'主演': "",
'上映时间': "",
'制片地区': "",
'类型': "",
'评价人数': "",
'电影链接': movie_url,
'电影海报': pic_url
}
col.insert_one(movie)
time.sleep(random.randint(1, 3))
2 基于FastAPI搭建可视化网站
效果如下:
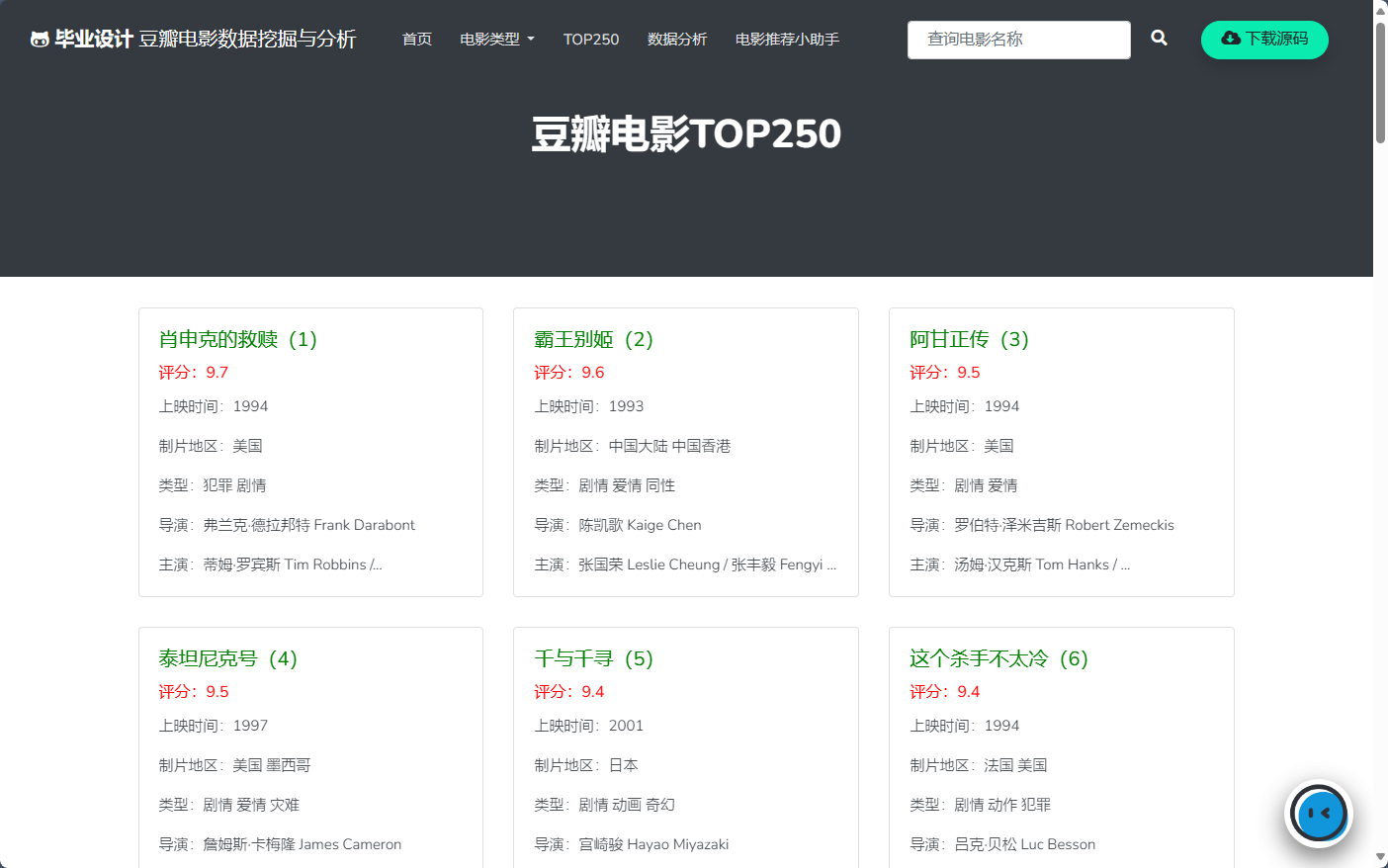
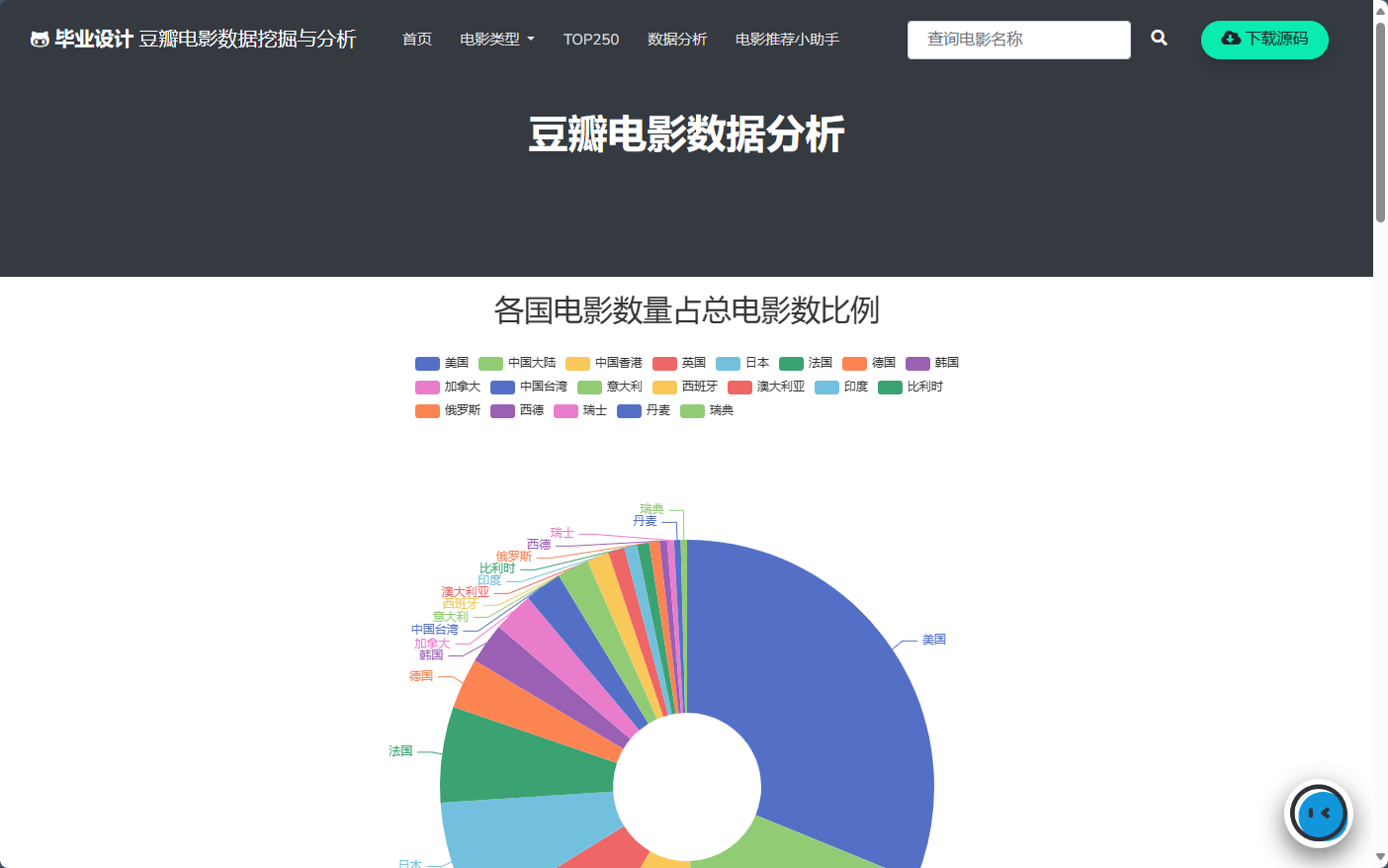
3 基于Gradio搭建问答机器人
基于大语言模型和RAG技术实现电影推荐小助手,通过自然语言为用户推荐电影信息。
效果如下:
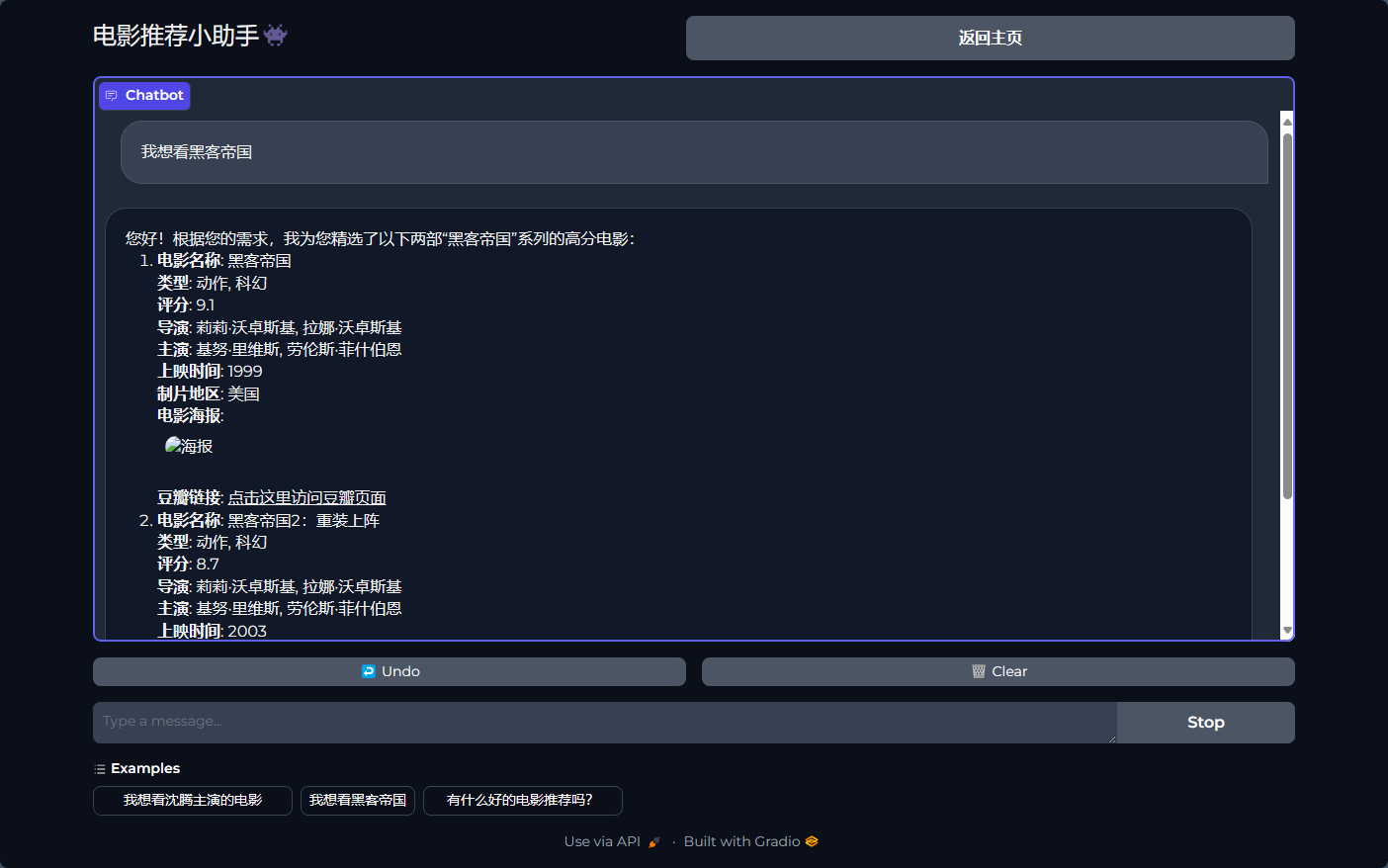
4 欢迎加QQ技术交流,还可获取毕设源码与文章~















 3597
3597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









